【深度学习实验】网络优化与正则化(二):基于自适应学习率的优化算法详解:Adagrad、Adadelta、RMSprop
文章目录
- 一、实验介绍
- 二、实验环境
- 1. 配置虚拟环境
- 2. 库版本介绍
- 三、实验内容
- 0. 导入必要的库
- 1. 随机梯度下降SGD算法
- a. PyTorch中的SGD优化器
- b. 使用SGD优化器的前馈神经网络
- 2.随机梯度下降的改进方法
- a. 学习率调整
- b. 梯度估计修正
- 3. 梯度估计修正:动量法Momentum
- 4. 自适应学习率
- Adagrad算法
- Adadelta算法
- RMSprop算法
- 算法测试
- 5. 代码整合(以RMSprop算法为例)
任何数学技巧都不能弥补信息的缺失。
——科尼利厄斯·兰佐斯(Cornelius Lanczos)匈牙利数学家、物理学家
一、实验介绍
深度神经网络在机器学习中应用时面临两类主要问题:优化问题和泛化问题。
-
优化问题:深度神经网络的优化具有挑战性。
- 神经网络的损失函数通常是非凸函数,因此找到全局最优解往往困难。
- 深度神经网络的参数通常非常多,而训练数据也很大,因此使用计算代价较高的二阶优化方法不太可行,而一阶优化方法的训练效率通常较低。
- 深度神经网络存在梯度消失或梯度爆炸问题,导致基于梯度的优化方法经常失效。
-
泛化问题:由于深度神经网络的复杂度较高且具有强大的拟合能力,很容易在训练集上产生过拟合现象。因此,在训练深度神经网络时需要采用一定的正则化方法来提高网络的泛化能力。
目前,研究人员通过大量实践总结了一些经验方法,以在神经网络的表示能力、复杂度、学习效率和泛化能力之间取得良好的平衡,从而得到良好的网络模型。本系列文章将从网络优化和网络正则化两个方面来介绍如下方法:
- 在网络优化方面,常用的方法包括优化算法的选择、参数初始化方法、数据预处理方法、逐层归一化方法和超参数优化方法。
- 在网络正则化方面,一些提高网络泛化能力的方法包括ℓ1和ℓ2正则化、权重衰减、提前停止、丢弃法、数据增强和标签平滑等。
本文将介绍基于自适应学习率的优化算法:Adagrad、Adadelta、RMSprop
二、实验环境
本系列实验使用了PyTorch深度学习框架,相关操作如下:
1. 配置虚拟环境
conda create -n DL python=3.7
conda activate DL
pip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
conda install matplotlib
conda install scikit-learn
2. 库版本介绍
| 软件包 | 本实验版本 | 目前最新版 |
|---|---|---|
| matplotlib | 3.5.3 | 3.8.0 |
| numpy | 1.21.6 | 1.26.0 |
| python | 3.7.16 | |
| scikit-learn | 0.22.1 | 1.3.0 |
| torch | 1.8.1+cu102 | 2.0.1 |
| torchaudio | 0.8.1 | 2.0.2 |
| torchvision | 0.9.1+cu102 | 0.15.2 |
三、实验内容
0. 导入必要的库
import torch
import torch.nn.functional as F
from d2l import torch as d2l
from sklearn.datasets import load_iris
from torch.utils.data import Dataset, DataLoader
1. 随机梯度下降SGD算法
随机梯度下降(Stochastic Gradient Descent,SGD)是一种常用的优化算法,用于训练深度神经网络。在每次迭代中,SGD通过随机均匀采样一个数据样本的索引,并计算该样本的梯度来更新网络参数。具体而言,SGD的更新步骤如下:
- 从训练数据中随机选择一个样本的索引。
- 使用选择的样本计算损失函数对于网络参数的梯度。
- 根据计算得到的梯度更新网络参数。
- 重复以上步骤,直到达到停止条件(如达到固定的迭代次数或损失函数收敛)。
a. PyTorch中的SGD优化器
Pytorch官方教程
optimizer = torch.optim.SGD(model.parameters(), lr=0.2)
b. 使用SGD优化器的前馈神经网络
【深度学习实验】前馈神经网络(final):自定义鸢尾花分类前馈神经网络模型并进行训练及评价
2.随机梯度下降的改进方法
传统的SGD在某些情况下可能存在一些问题,例如学习率选择困难和梯度的不稳定性。为了改进这些问题,提出了一些随机梯度下降的改进方法,其中包括学习率的调整和梯度的优化。
a. 学习率调整
- 学习率衰减(Learning Rate Decay):随着训练的进行,逐渐降低学习率。常见的学习率衰减方法有固定衰减、按照指数衰减、按照时间表衰减等。
- Adagrad:自适应地调整学习率。Adagrad根据参数在训练过程中的历史梯度进行调整,对于稀疏梯度较大的参数,降低学习率;对于稀疏梯度较小的参数,增加学习率。这样可以在不同参数上采用不同的学习率,提高收敛速度。
- Adadelta:与Adagrad类似,但进一步解决了Adagrad学习率递减过快的问题。Adadelta不仅考虑了历史梯度,还引入了一个累积的平方梯度的衰减平均,以动态调整学习率。
- RMSprop:也是一种自适应学习率的方法,通过使用梯度的指数加权移动平均来调整学习率。RMSprop结合了Adagrad的思想,但使用了衰减平均来减缓学习率的累积效果,从而更加稳定。
b. 梯度估计修正
- Momentum:使用梯度的“加权移动平均”作为参数的更新方向。Momentum方法引入了一个动量项,用于加速梯度下降的过程。通过积累之前的梯度信息,可以在更新参数时保持一定的惯性,有助于跳出局部最优解、加快收敛速度。
- Nesterov accelerated gradient:Nesterov加速梯度(NAG)是Momentum的一种变体。与Momentum不同的是,NAG会先根据当前的梯度估计出一个未来位置,然后在该位置计算梯度。这样可以更准确地估计当前位置的梯度,并且在参数更新时更加稳定。
- 梯度截断(Gradient Clipping):为了应对梯度爆炸或梯度消失的问题,梯度截断的方法被提出。梯度截断通过限制梯度的范围,将梯度控制在一个合理的范围内。常见的梯度截断方法有阈值截断和梯度缩放。
3. 梯度估计修正:动量法Momentum
【深度学习实验】网络优化与正则化(一):优化算法:使用动量优化的随机梯度下降算法(Stochastic Gradient Descent with Momentum)
4. 自适应学习率
Adagrad算法
Adagrad(Adaptive Gradient Algorithm)算法会为每个参数维护一个学习率,该学习率随着时间的推移会逐渐减小。它适用于稀疏数据集,能够有效地处理出现较少的特征。

def init_adagrad_states(feature_dim):s_w = torch.zeros((feature_dim, 3))s_b = torch.zeros(3)return (s_w, s_b)def adagrad(params, states, hyperparams):eps = 1e-6for p, s in zip(params, states):with torch.no_grad():s[:] += torch.square(p.grad)p[:] -= hyperparams['lr'] * p.grad / torch.sqrt(s + eps)p.grad.data.zero_()init_adagrad_states函数用于初始化Adagrad算法中的状态。- 创建两个张量
s_w和s_b,分别用于保存权重参数和偏置参数的平方梯度累积和。这些状态张量的形状与对应的参数张量相同。
- 创建两个张量
adagrad函数使用Adagrad算法来更新模型的参数。- 接受三个输入:
params表示模型的参数张量列表,states表示Adagrad算法的状态张量列表,hyperparams表示超参数字典,其中包含学习率lr。 - 在更新参数之前,算法首先定义了一个小量
eps,用于避免除零错误。 - 对于每个参数张量
p和对应的状态张量s,算法执行以下操作:- 计算参数梯度的平方。
- 将平方梯度累积到状态张量
s中。 - 使用自适应学习率更新参数
p。这里使用了累积的平方梯度来调整学习率的大小,以更好地适应不同参数的更新需求。 - 使用
p.grad.data.zero_()将参数梯度置零,以便下一次迭代时重新计算梯度。
- 接受三个输入:
Adadelta算法
Adadelta算法是Adagrad的改进版本,通过限制累积梯度的历史信息,解决了Adagrad学习率递减过快的问题。它对学习率的调整更加平滑,适合于长期训练的模型。

def init_adadelta_states(feature_dim):s_w = torch.zeros((feature_dim, 3))s_b = torch.zeros(3)delta_w = torch.zeros((feature_dim, 3))delta_b = torch.zeros(3)return (s_w, s_b, delta_w, delta_b)def adadelta(params, states, hyperparams):rho, eps = hyperparams['rho'], 1e-6for p, s, delta in zip(params, states[:2], states[2:]):with torch.no_grad():s[:] = rho * s + (1 - rho) * torch.square(p.grad)update = (torch.sqrt(delta + eps) / torch.sqrt(s + eps)) * p.gradp[:] -= updatedelta[:] = rho * delta + (1 - rho) * torch.square(update)p.grad.data.zero_()
init_adadelta_states函数用于初始化Adadelta算法的状态。- 创建了四个张量
s_w、s_b、delta_w和delta_b,分别用于保存权重参数和偏置参数的梯度平方累积和以及参数更新的累积平方梯度。这些状态张量的形状与对应的参数张量相同。
- 创建了四个张量
adadelta函数使用Adadelta算法来更新模型的参数。- 接受三个输入:
params表示模型的参数张量列表,states表示Adadelta算法的状态张量列表,hyperparams表示超参数字典,其中包含衰减率rho。 - 在更新参数之前,算法首先定义了两个小量:
rho表示衰减率,用于平衡历史梯度和当前梯度的贡献,eps用于避免除零错误。 - 对于每个参数张量
p和对应的状态张量s、delta,算法执行以下操作:- 计算参数梯度的平方。
- 使用衰减率
rho更新状态张量s:使用历史梯度和当前梯度的加权平均,以平衡参数更新的速度。 - 计算参数更新的值
update:使用参数更新的累积平方梯度来调整更新的幅度。 - 使用更新值
update更新参数p:根据调整后的学习率大小来更新参数。 - 使用衰减率
rho更新累积平方梯度delta。 - 使用
p.grad.data.zero_()将参数梯度置零,以便下一次迭代时重新计算梯度。
- 接受三个输入:
RMSprop算法
RMSprop(Root Mean Square Propagation)算法是一种针对Adagrad算法的改进方法,通过引入衰减系数来平衡历史梯度和当前梯度的贡献。它能够更好地适应不同参数的变化情况,对于非稀疏数据集表现较好。

def init_rmsprop_states(feature_dim):s_w = torch.zeros((feature_dim, 3))s_b = torch.zeros(3)return (s_w, s_b)def rmsprop(params, states, hyperparams):gamma, eps = hyperparams['gamma'], 1e-6for p, s in zip(params, states):with torch.no_grad():s[:] = gamma * s + (1 - gamma) * torch.square(p.grad)p[:] -= hyperparams['lr'] * p.grad / torch.sqrt(s + eps)p.grad.data.zero_()init_rmsprop_states函数用于初始化RMSprop算法中的状态。- 创建两个张量
s_w和s_b,分别用于保存权重参数和偏置参数的梯度平方累积和。这些状态张量的形状与对应的参数张量相同。
- 创建两个张量
rmsprop函数使用RMSprop算法来更新模型的参数。- 它接受三个输入:
params表示模型的参数张量列表,states表示RMSprop算法的状态张量列表,hyperparams表示超参数字典,其中包含学习率lr和衰减率gamma。 - 在更新参数之前,算法首先定义了两个小量:
gamma表示衰减率,用于平衡历史梯度和当前梯度的贡献,eps用于避免除零错误。 - 对于每个参数张量
p和对应的状态张量s,算法执行以下操作:- 使用
torch.square(p.grad)计算参数梯度的平方。 - 使用衰减率
gamma更新状态张量s:使用了历史梯度和当前梯度的加权平均,以平衡参数更新的速度。 - 使用自适应学习率更新参数
p:使用了累积的梯度平方来调整学习率的大小,以更好地适应不同参数的更新需求。 - 使用
p.grad.data.zero_()将参数梯度置零,以便下一次迭代时重新计算梯度。
- 使用
- 它接受三个输入:
算法测试
batch_size = 24# 构建训练集
train_dataset = IrisDataset(mode='train')
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)lr = 0.02
train(adagrad, init_adagrad_states(4), {'lr': lr}, train_loader, 4)
# train(rmsprop, init_rmsprop_states(4), {'lr': lr, 'gamma': 0.9}, train_loader, 4)
-
IrisDataset类:
- 参照前文:【深度学习实验】前馈神经网络(七):批量加载数据(直接加载数据→定义类封装数据)
-
train函数:
- 参照前文:【深度学习实验】网络优化与正则化(一):优化算法:使用动量优化的随机梯度下降算法(Stochastic Gradient Descent with Momentum)
5. 代码整合(以RMSprop算法为例)
import torch
from torch import nn
import torch.nn.functional as F
from d2l import torch as d2l
from sklearn.datasets import load_iris
from torch.utils.data import Dataset, DataLoaderclass FeedForward(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(FeedForward, self).__init__()self.fc1 = nn.Linear(input_size, hidden_size)self.fc2 = nn.Linear(hidden_size, output_size)self.act = nn.Sigmoid()def forward(self, inputs):outputs = self.fc1(inputs)outputs = self.act(outputs)outputs = self.fc2(outputs)return outputsdef evaluate_loss(net, data_iter, loss):"""评估给定数据集上模型的损失Defined in :numref:`sec_model_selection`"""metric = d2l.Accumulator(2) # 损失的总和,样本数量for X, y in data_iter:X = X.to(torch.float32)out = net(X)# y = d2l.reshape(y, out.shape)l = loss(out, y.long())metric.add(d2l.reduce_sum(l), d2l.size(l))return metric[0] / metric[1]def train(trainer_fn, states, hyperparams, data_iter, feature_dim, num_epochs=2):"""Defined in :numref:`sec_minibatches`"""# 初始化模型w = torch.normal(mean=0.0, std=0.01, size=(feature_dim, 3),requires_grad=True)b = torch.zeros((3), requires_grad=True)# 训练模型animator = d2l.Animator(xlabel='epoch', ylabel='loss',xlim=[0, num_epochs], ylim=[0.9, 1.1])n, timer = 0, d2l.Timer()# 这是一个单层线性层net = lambda X: d2l.linreg(X, w, b)loss = F.cross_entropyfor _ in range(num_epochs):for X, y in data_iter:X = X.to(torch.float32)l = loss(net(X), y.long()).mean()l.backward()trainer_fn([w, b], states, hyperparams)n += X.shape[0]if n % 48 == 0:timer.stop()animator.add(n / X.shape[0] / len(data_iter),(evaluate_loss(net, data_iter, loss),))timer.start()print(f'loss: {animator.Y[0][-1]:.3f}, {timer.avg():.3f} sec/epoch')return timer.cumsum(), animator.Y[0]def load_data(shuffle=True):x = torch.tensor(load_iris().data)y = torch.tensor(load_iris().target)# 数据归一化x_min = torch.min(x, dim=0).valuesx_max = torch.max(x, dim=0).valuesx = (x - x_min) / (x_max - x_min)if shuffle:idx = torch.randperm(x.shape[0])x = x[idx]y = y[idx]return x, yclass IrisDataset(Dataset):def __init__(self, mode='train', num_train=120, num_dev=15):super(IrisDataset, self).__init__()x, y = load_data(shuffle=True)if mode == 'train':self.x, self.y = x[:num_train], y[:num_train]elif mode == 'dev':self.x, self.y = x[num_train:num_train + num_dev], y[num_train:num_train + num_dev]else:self.x, self.y = x[num_train + num_dev:], y[num_train + num_dev:]def __getitem__(self, idx):return self.x[idx], self.y[idx]def __len__(self):return len(self.x)def init_rmsprop_states(feature_dim):s_w = torch.zeros((feature_dim, 3))s_b = torch.zeros(3)return (s_w, s_b)def rmsprop(params, states, hyperparams):gamma, eps = hyperparams['gamma'], 1e-6for p, s in zip(params, states):with torch.no_grad():s[:] = gamma * s + (1 - gamma) * torch.square(p.grad)p[:] -= hyperparams['lr'] * p.grad / torch.sqrt(s + eps)p.grad.data.zero_()# batch_size = 1
batch_size = 24
# batch_size = 120# 分别构建训练集、验证集和测试集
train_dataset = IrisDataset(mode='train')train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)lr = 0.02
train(rmsprop, init_rmsprop_states(4), {'lr': lr, 'gamma': 0.9}, train_loader, 4)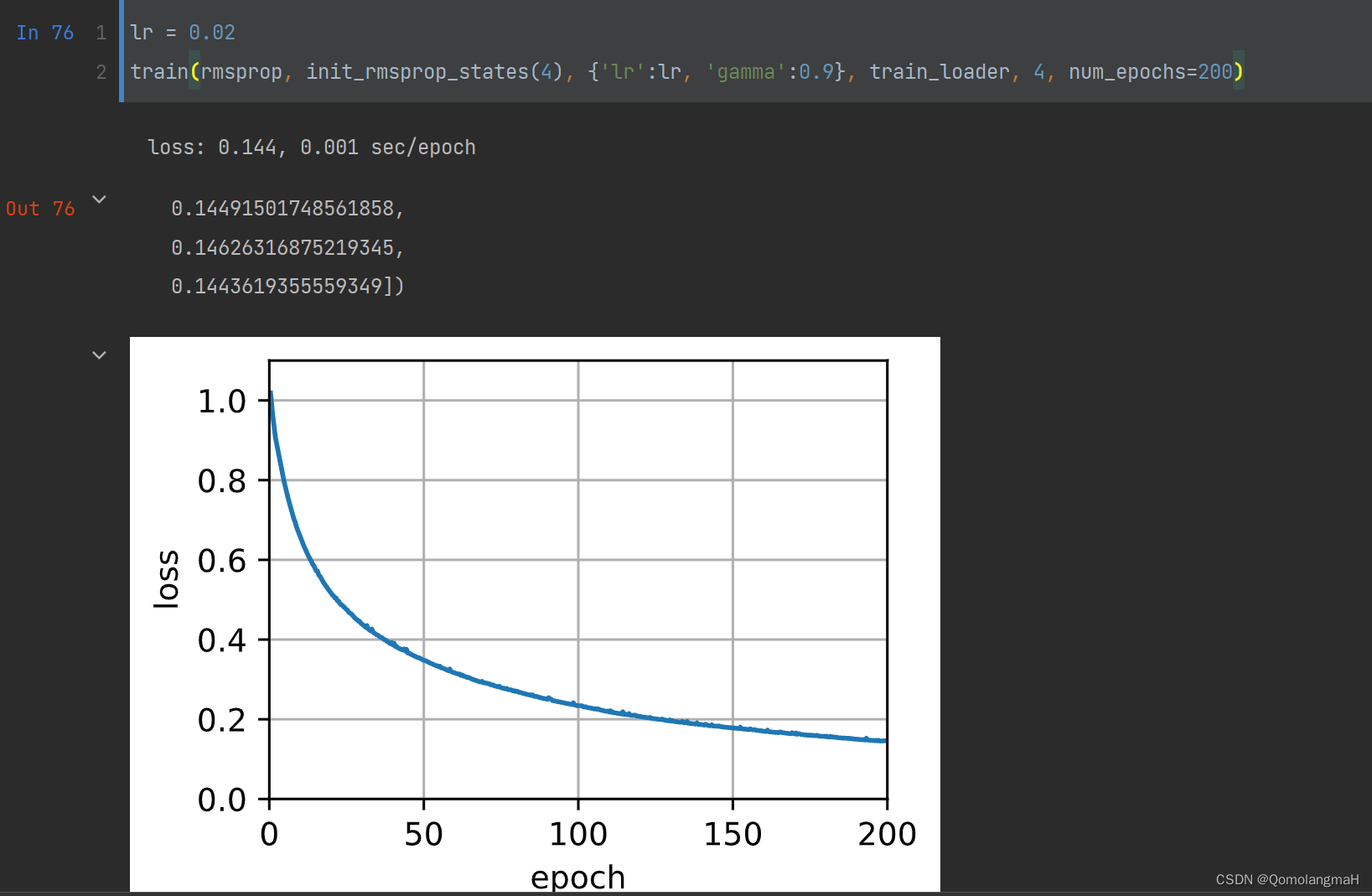
相关文章:
【深度学习实验】网络优化与正则化(二):基于自适应学习率的优化算法详解:Adagrad、Adadelta、RMSprop
文章目录 一、实验介绍二、实验环境1. 配置虚拟环境2. 库版本介绍 三、实验内容0. 导入必要的库1. 随机梯度下降SGD算法a. PyTorch中的SGD优化器b. 使用SGD优化器的前馈神经网络 2.随机梯度下降的改进方法a. 学习率调整b. 梯度估计修正 3. 梯度估计修正:动量法Momen…...

系统韧性研究(3)| 工程系统韧性要求
从最基本的层面上说,系统韧性指的是系统在逆境中继续执行其任务的程度。虽然对操作连续性至关重要,但系统的服务(能力)只是系统继续执行其任务所必须保护的一些资产。该系统必须检测不利因素,对其作出反应,…...
.net 5 发布后swagger页面不显示问题
1:项目右键属性-》生成xml--用于swagger文件读取 2:开启文件配饰swagger读取指定文件...
Spring Boot 3 整合 xxl-job 实现分布式定时任务调度,结合 Docker 容器化部署(图文指南)
目录 前言初始化数据库Docker 部署 xxl-job下载镜像创建容器并运行访问调度中心 SpringBoot 整合 xxl-jobpom.xmlapplication.ymlXxlJobConfig.java执行器注册查看 定时任务测试添加测试任务配置定时任务测试结果 结语附录xxl-job 官方文档xxl-job 源码测试项目源码 前言 xxl-…...

1985-2020年我国30m土地利用覆盖数据介绍
土地覆盖(LC)决定了地球各圈层之间的能量交换、水和碳循环。准确的 LC 信息是环境和气候研究的基本参数。考虑到在过去几十年中,随着经济建设的发展,中国发生了巨大的变化,连续和精细的 LC 监测是迫切需要的。然而,目前࿰…...
Django 社区志愿者管理系统
摘 要 随着社会的发展,社会的各行各业都在利用信息化时代的优势。计算机的优势和普及使得各种信息系统的开发成为必需。 社区志愿者服务管理系统,主要的模块包括查看首页、个人中心、通知公告管理、志愿者管理、普通管理员管理、志愿活动管理、活动宣…...

wordpress如何修改数据库里用户ID下一个自增值的开始数字
有时候我们为了让别人认为网站有很多注册用户,会想把网站用户ID的起始数改大一点,因为WP默认的用户ID是从1开始,注册一个就加1,这样别人就很容易知道网站的用户量。 那么如何改呢?首先进phpmyadmin,找到wp…...

利用chatgpt大语言模型来做数据预处理
数据预处理是机器学习中的一个重要步骤,包括数据清洗、数据转换、特征选择等。这些步骤通常需要人工进行,或者使用专门的数据预处理工具和库,如Python的Pandas库、Scikit-learn库等。 今天我们将利用chatgpt(国内版本-小策智能问答)的辅助帮…...
【机器学习】五、贝叶斯分类
我想说:“任何事件都是条件概率。”为什么呢?因为我认为,任何事件的发生都不是完全偶然的,它都会以其他事件的发生为基础。换句话说,条件概率就是在其他事件发生的基础上,某事件发生的概率。 条件概率是朴…...

k8s 资源管理方式
k8s中资源管理方式可以划分为下面的几种:命令式对象管理、命令式对象配置、声明式对象配置。 命令式对象管理 命令式对象管理:直接使用命令的方式来操作k8s资源, 这种方式操作简单,但是无法审计和追踪。 kubectl run nginx-pod --imagengi…...

Golang Gin 接口返回 Excel 文件
文章目录 1.Web 页面导出数据到文件由后台实现还是前端实现?2.Golang Excel 库选型3.后台实现示例4.xlsx 库的问题5.小结参考文献 1.Web 页面导出数据到文件由后台实现还是前端实现? Web 页面导出表数据到 Excel(或其他格式)可以…...

实战之巧用header头
案例: 遇到过三次 一次是更改accept,获取到tomcat的绝对路径,结合其他漏洞获取到shell。 一次是更改accept,越权获取到管理员的MD5加密,最后接管超管权限。 一次是更改accept,结合参数获取到key。 这里以越…...

[AUTOSAR][诊断管理][ECU][$36] 数据传输
文章目录 一、简介二、服务请求报文定义三、服务请求报文中参数定义(1)blockSequenceCounter(2)transferRequestParameterRecord三、肯定响应(1)blockSequenceCounter(2)transferResponseParameterRecord四、支持的NRC五、示例代码36_transfer_data.c一、简介 这个服务…...
sw 怎么装新版本
我们在安装solidworks时,有时候会提示A newer version of this applic ation is already installed. Installation stopped.如下图所示 这时候需要点继续安装 然后会出现下图所示情况,vba7.1安装未成功 这是因为我们电脑中以前安装过更高版本的solidw…...
正点原子嵌入式linux驱动开发——Linux 音频驱动
音频是最常用到的功能,音频也是linux和安卓的重点应用场合。STM32MP1带有SAI接口,正点原子的STM32MP1开发板通过此接口外接了一个CS42L51音频DAC芯片,本章就来学习一下如何使能CS42L51驱动,并且CS42L51通过芯片来完成音乐播放与录…...

conda相关的命令操作
准备切换conda环境 cd C:\ProgramData\Anaconda3\Scripts查看所有环境 conda info --envs选择环境 activate pytorch安装torch pip install D:\installPackage\torch-1.2.0-cp36-cp36m-win_amd64.whl安装torchvision pip install D:\installPackage\torchvision-0.4.0-cp3…...

如何快速使用Vue3在electron项目开发chrome Devtools插件
1、建立Vue项目 为了方便快速建立项目,我已经写好脚手架,直接clone项目,快速开发 点击快速进入源代码 拉取代码 git clone https://github.com/xygengcn/electron-devtool.git安装依赖 yarn运行项目 yarn dev打包项目 yarn build2、安装…...
干洗店服务预约小程序有什么作用
要说干洗店,近些年的需求度非常高,一方面是人们生活品质提升,另一方面则是各种服饰对洗涤要求提升等,很多人的衣服很多也会通过干洗店进行清洁。 而对从业商家来说,市场庞大一方面需要不断进行市场教育、品牌提升&…...

【跟小嘉学 Rust 编程】三十四、Rust的Web开发框架之一: Actix-Web的进阶
系列文章目录 【跟小嘉学 Rust 编程】一、Rust 编程基础 【跟小嘉学 Rust 编程】二、Rust 包管理工具使用 【跟小嘉学 Rust 编程】三、Rust 的基本程序概念 【跟小嘉学 Rust 编程】四、理解 Rust 的所有权概念 【跟小嘉学 Rust 编程】五、使用结构体关联结构化数据 【跟小嘉学…...
——Xshell安装)
软件安装(1)——Xshell安装
一、前言 本篇文章主要用于介绍Xshell破解版的安装 二、具体步骤 1. 下载Xshell7 链接:https://pan.baidu.com/s/1sFZz1uPb7yeDl6dlM4xtpg 提取码:a7m8 2. 安装Xshell7 选择文件安装目录后安装即可...

JMeter并发与持续性压测:从瞬时吞吐到系统韧性的工程实践
1. 为什么“并发持续”不是简单叠加,而是压测成败的分水岭 很多人第一次做接口性能测试时,会下意识把JMeter当成“高级curl”——写个HTTP请求,加个线程组,跑50个用户,看响应时间飘不飘。结果报告一出来,平…...

告别黄牛票:用DamaiHelper脚本轻松抢到大麦网演唱会门票
告别黄牛票:用DamaiHelper脚本轻松抢到大麦网演唱会门票 【免费下载链接】DamaiHelper 大麦网演唱会演出抢票脚本。 项目地址: https://gitcode.com/gh_mirrors/dama/DamaiHelper 还在为抢不到心仪的演唱会门票而烦恼吗?面对秒光的票源和黄牛的高…...

3分钟为Blender相机添加真实抖动:Camera Shakify新手完全指南
3分钟为Blender相机添加真实抖动:Camera Shakify新手完全指南 【免费下载链接】camera_shakify 项目地址: https://gitcode.com/gh_mirrors/ca/camera_shakify 想让你的Blender动画瞬间拥有电影级的真实感吗?Camera Shakify这款神奇的插件就是你…...

为Nodejs后端服务配置Taotoken多模型聚合API调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Nodejs后端服务配置Taotoken多模型聚合API调用 基础教程类,指导Nodejs开发者将Taotoken服务集成到现有后端项目中&am…...

taotoken token plan套餐如何为初创公司降低ai实验与原型开发成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 taotoken token plan套餐如何为初创公司降低AI实验与原型开发成本 对于初创公司而言,在AI驱动的产品原型开发与功能验证…...

在OpenClaw中配置Taotoken实现多模型Agent工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在OpenClaw中配置Taotoken实现多模型Agent工作流 OpenClaw是一个流行的开源Agent框架,它允许开发者构建和编排基于大语…...
)
【仅限头部AI团队内部流通】DeepSeek-Coder 33B代码生成延迟优化白皮书(含vLLM 0.6.3 patch补丁包)
更多请点击: https://kaifayun.com 第一章:DeepSeek-Coder 33B模型架构与延迟瓶颈全景分析 DeepSeek-Coder 33B 是一款专为代码理解与生成优化的开源大语言模型,基于标准 LLaMA 架构演进,采用 64 层 Transformer 解码器堆叠&…...

分布式接口幂等性设计:唯一索引、Token 与分布式锁
接口幂等性解决的是“同一个请求被执行多次,会不会造成重复业务效果”的问题。用户重复点击、网络重试、MQ 重复消费,都可能让同一业务被重复执行。 一句话概括:幂等就是多次调用和一次调用的业务结果一致;查询和按唯一值删除天然…...

030、PCB封装设计规范与3D模型导入
PCB封装设计规范与3D模型导入 一块板子差点报废的教训 去年做一款工业控制板,LDO的散热焊盘封装画错了。板子打样回来,焊接完上电,LDO烫得能煎鸡蛋。查了半天,发现封装里散热焊盘的阻焊层开窗尺寸比数据手册小了0.3mm,焊膏流不进去,芯片底部悬空,热量全憋在肚子里。更…...

3步搞定无人机影像处理:ODM免费开源工具完全指南
3步搞定无人机影像处理:ODM免费开源工具完全指南 【免费下载链接】ODM A command line toolkit to generate maps, point clouds, 3D models and DEMs from drone, balloon or kite images. 📷 项目地址: https://gitcode.com/gh_mirrors/od/ODM …...