2021-arxiv-GPT Understands, Too
2021-arxiv-GPT Understands, Too

Paper: https://arxiv.org/abs/2103.10385
Code: https://github.com/THUDM/P-tuning
Prompt 简单理解
举例来讲,今天如果有这样两句评论:
1. 什么苹果啊,都没有苹果味,怪怪的味道,而且一点都不甜,超级难吃!
2. 这破笔记本速度太慢了,卡的不要不要的。
现在我们需要根据他们描述的商品类型进行一个分类任务,
即,第一句需要被分类到「水果」类别中;第二句则需要分类到「电脑」类别中。
一种直觉的方式是将该问题建模成一个传统文本分类的任务,通过人工标注,为每一个类别设置一个id,例如:
{'电脑': 0,'水果': 1,....
}
这样一来,标注数据集就长这样:
什么苹果啊,都没有苹果味,怪怪的味道,而且一点都不甜,超级难吃! 1
这破笔记本速度太慢了,卡的不要不要的。 0
...
这种方法是可行的,但是需要「较多的标注数据」才能取得不错的效果。
由于大多数预训练模型(如BRET)在 pretrain 的时候都使用了 [MASK] token 做 MLM 任务,而我们在真实下游任务中往往是不会使用到 [MASK] 这个 token,这就意味着今天我们在训练下游任务时需要较多的数据集去抹平上下游任务不一致的 gap。
那,如果我们没有足够多的训练数据怎么办呢?
prompt learning 的出现就是为了解决这一问题,它将 [MASK] 的 token 引入到了下游任务中,将下游任务构造成和 MLM 类似的任务。
举例来讲,我们可以将上述评论改写为:
这是一条[MASK][MASK]评论:这破笔记本速度太慢了,卡的不要不要的。
然后让模型去预测两个 [MASK] token 的真实值是什么,那模型根据上下文能推测出被掩码住的词应该为「电脑」。
由于下游任务中也使用了和预训练任务中同样的 MLM 任务,这样我们就可以使用更少的训练数据来进行微调了。
但,这还不是 P-tuning。
通过上面的例子我们可以观察到,构建句子最关键的部分是在于 prompt的生成,即:
「这是一条[MASK][MASK]评论:」(prompt) + 这破笔记本速度太慢了,卡的不要不要的。(content)
被括号括起来的前缀(prompt)的生成是非常重要的,不同 prompt 会极大影响模型对 [MASK] 预测的正确率。
那么这个 prompt 怎么生成呢?
我们当然可以通过人工去设计很多不同类型的前缀 prompt,我们把他们称为 prompt pattern,例如:
这是一条[MASK][MASK]评论:
下面是一条描述[MASK][MASK]的评论:
[MASK][MASK]:
...
但是人工列这种 prompt pattern 非常的麻烦,不同的数据集所需要的 prompt pattern 也不同,可复用性很低。
那么,我们能不能通过机器自己去学习 prompt pattern 呢?
这,就是 P-Tuning。
P-Tuning 架构
给定一个预训练的语言模型 M M M,一个离散输入标记序列 x 1 : n = { x 0 , x 1 , … , x n } \mathbf{x}_{1: n}=\left\{x_0, x_1, \ldots, x_n\right\} x1:n={x0,x1,…,xn}将由预训练嵌入层 e ∈ M \mathbf{e} \in \mathcal{M} e∈M映射到输入嵌入 { e ( x 0 ) , e ( x 1 ) , … , e ( x n ) } \left\{\mathbf{e}\left(x_0\right), \mathbf{e}\left(x_1\right), \ldots, \mathbf{e}\left(x_n\right)\right\} {e(x0),e(x1),…,e(xn)}。在特定场景中,在上下文 x x x 的条件下,作者使用一组目标标记 y y y 的输出嵌入进行下游处理。例如,在预训练中, x x x 指的是未屏蔽的令牌,而 y y y 指的是 [MASK] 标记;在句子分类中, x x x 指的是句子标记,而 y y y 通常指的是 [CLS]。
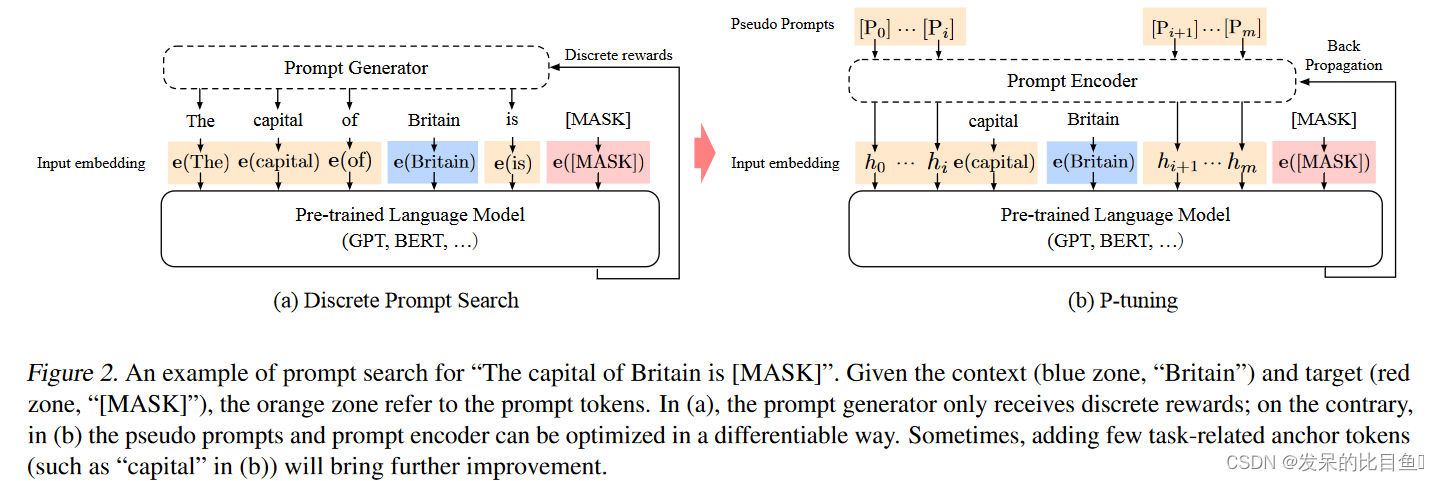
提示 p p p 的功能是将上下文 x x x、目标 y y y 和自身组织到模板 T 中。例如,在预测一个国家首都的任务 (LAMA-TREx P36) 中,模板可能是“The capital of Britain is [MASK]”。(见图2),其中“The capital of … is … .“是提示,”Britain"是上下文,”[MASK]“是目标。提示可以非常灵活,我们甚至可以将它们插入到上下文或目标中。
设 V V V 指语言模型 M M M 的词汇表, [ P i ] [P_i] [Pi] 指模板 T 中的第 i i i 个提示标记。为简单起见,给定模板 T = { [ P 0 : i ] , x , [ P i + 1 : m ] , y } T=\left\{\left[\mathrm{P}_{0: i}\right], \mathbf{x},\left[\mathrm{P}_{i+1: m}\right], \mathbf{y}\right\} T={[P0:i],x,[Pi+1:m],y},与满足 [ P i ] ∈ V \left[\mathrm{P}_i\right] \in \mathcal{V} [Pi]∈V 并将 T T T 映射为的传统离散提示相比
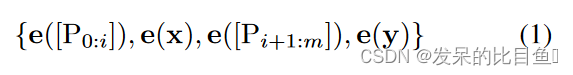
相反,P-tuning 将 [Pi] 视为伪令牌,并将模板映射到
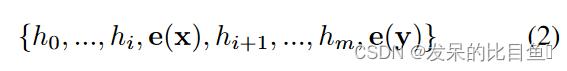
其中 h i ( 0 ≤ i < m ) h_i(0 \leq i<m) hi(0≤i<m) 是可训练的嵌入张量。能够找到超越 M M M的 V V V 可以表达的原始词汇的更好的连续提示。最后,利用下游损失函数 L L L,可以对连续提示 h i ( 0 ≤ i < m ) h_i(0 \leq i<m) hi(0≤i<m)进行差分优化
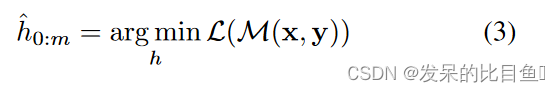
优化
1)离散性: M \mathcal{M} M的原始词嵌入 e e e在预训练后已经变得高度离散。如果用随机分布初始化 h h h,然后用随机梯度下降 (SGD) 进行优化,这已被证明只会改变小邻域中的参数,优化器很容易陷入局部最小值。
2)关联:另一个问题是,作者认为提示嵌入 h i h_i hi的值应该是相互依赖的,而不是独立的。需要一些机制来将提示嵌入相互关联。
鉴于这些挑战,在 P-tuning中,建议使用提示编码器将 h i h_i hi 建模为序列,该序列由一个非常精简的神经网络组成,可以解决离散性和关联问题。作者选择双向长短期记忆网络 (LSTM),并使用 ReLU 激活的两层多层感知器 (MLP) 来编码离散性。从形式上讲,将 h i ′ h_i^{\prime} hi′嵌入到语言模型 M \mathcal{M} M中的实际输入源自
h i = MLP ( [ h i → : h i ← ] ) = MLP ( [ LSTM ( h 0 : i ) : LSTM ( h i : m ) ] ) \begin{aligned} h_i & =\operatorname{MLP}\left(\left[\overrightarrow{h_i}: \overleftarrow{h_i}\right]\right) \\ & =\operatorname{MLP}\left(\left[\operatorname{LSTM}\left(h_{0: i}\right): \operatorname{LSTM}\left(h_{i: m}\right)\right]\right) \end{aligned} hi=MLP([hi:hi])=MLP([LSTM(h0:i):LSTM(hi:m)])
尽管 LSTM 头的使用确实为连续提示的训练增加了一些参数,但 LSTM 头比预训练模型小几个数量级。此外,在推理中,只需要输出嵌入 h h h,就可以丢弃 LSTM 头。
参考
https://zhuanlan.zhihu.com/p/583022692
相关文章:
2021-arxiv-GPT Understands, Too
2021-arxiv-GPT Understands, Too Paper: https://arxiv.org/abs/2103.10385 Code: https://github.com/THUDM/P-tuning Prompt 简单理解 举例来讲,今天如果有这样两句评论: 1. 什么苹果啊,都没有苹果味,…...

【Spark】What is the difference between Input and Shuffle Read
Spark调参过程中 保持每个task的 input shuffle read 量在300-500M左右比较合适 The Spark UI is documented here: https://spark.apache.org/docs/3.0.1/web-ui.html The relevant paragraph reads: Input: Bytes read from storage in this stageOutput: Bytes written …...

redis相关的一些面试题?
1.什么是缓存穿透,什么是缓存雪崩,什么是缓存击穿? 缓存穿透:假如某一时刻访问redis的大量key都在redis中不存在(比如黑客故意伪造一些乱七八糟的key),那么也会给数据造成压力,这就是缓存穿透,解决方案是使…...

什么是Babel?它的主要作用是什么?
聚沙成塔每天进步一点点 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 欢迎来到前端入门之旅!感兴趣的可以订阅本专栏哦!这个专栏是为那些对Web开发感兴趣、刚刚踏入前端领域的朋友们量身打造的。无论你是完全的新手还是有一些基础的开发…...
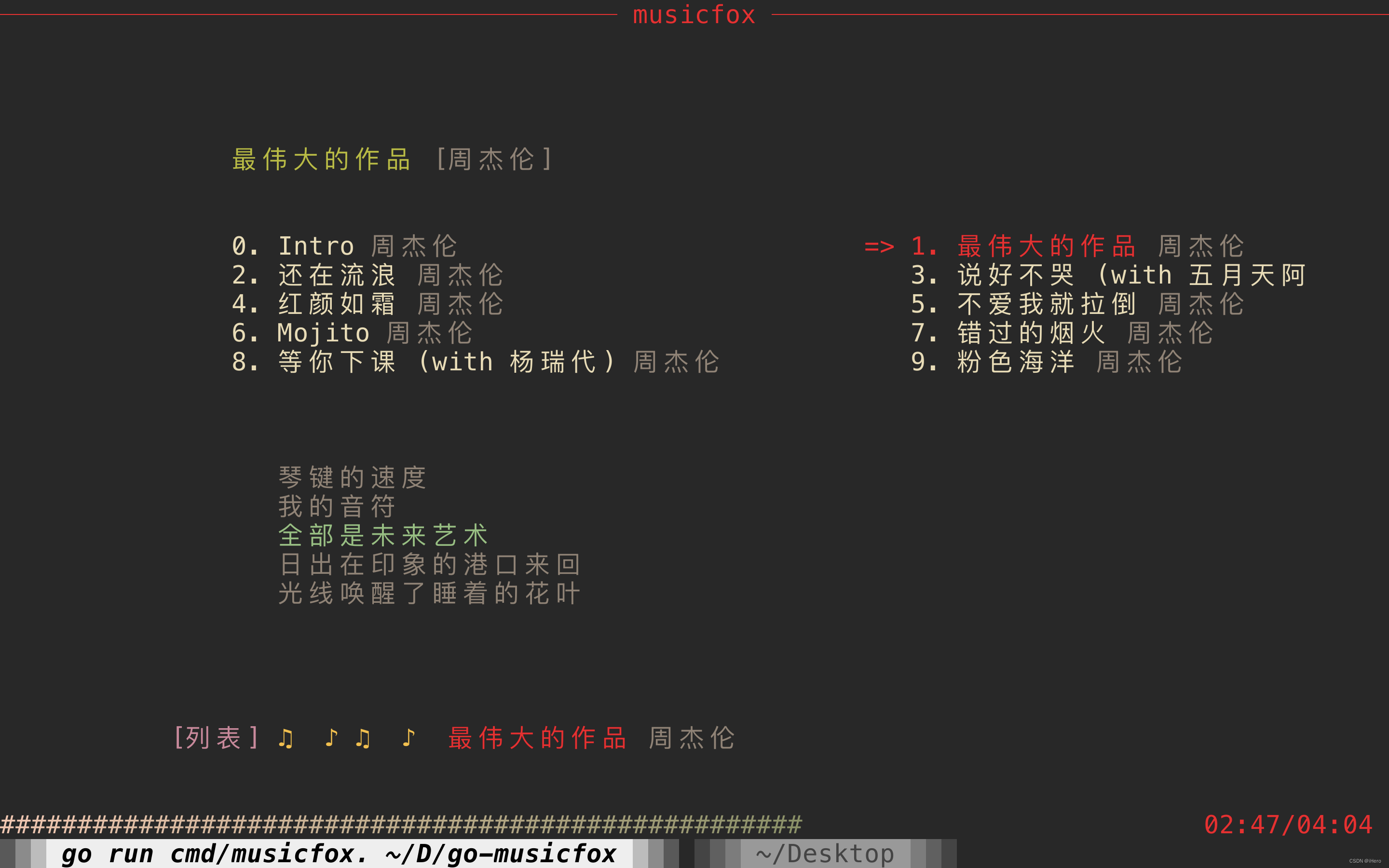
【APP】go-musicfox - 一款网易云音乐命令行客户端, 文件很小Mac版本只有16.5M
go-musicfox 是用 Go 写的又一款网易云音乐命令行客户端,支持各种音质级别、UnblockNeteaseMusic、Last.fm、MPRIS 和 macOS 交互响应(睡眠暂停、蓝牙耳机连接断开响应和菜单栏控制等)等功能特性。 预览 启动 启动界面 主界面 主界面 通…...

P1284 三角形牧场
Portal. 首先,我们需要一些初中数学知识——秦九韶公式(又名海伦公式): p a b c 2 S p ( p − a ) ( p − b ) ( p − c ) \begin{align} &p\dfrac{abc}{2}\\ &S\sqrt{p(p-a)(p-b)(p-c)} \end{align} p2abcSp(p…...
【Linux】:Linux开发工具之Linux编辑器vim的使用
🔫1.Linux编辑器-vim使用 📤 vi/vim的区别简单点来说,它们都是多模式编辑器,不同的是vim是vi的升级版本,它不仅兼容vi的所有指令,而且还有一些新的特性在里面。例如语法加亮,可视化操作不仅可以…...

PFMEA详解结构分析——Sun FMEA软件
FMEA从1949年诞生到今天已经发生过多次更新,最新版本是2019年6月发布的《AIAG VDA FMEA手册》。新手册借鉴了AIAG的方框图、参数图、流程图等工具的运用,也借鉴了VDA的五步过程导向法,并在此基础上头尾各增加一步,形成了FMEA七步法…...

Qt扫盲-QFutureWatcher理论总结
QFutureWatcher理论总结 一、概述二、转态 一、概述 QFutureWatcher类允许我们使用信号槽的方式去监控QFuture。 QFutureWatcher提供关于QFuture的信息和通知。使用 setFuture() 函数开始监视特定的QFuture。 future()函数通过setFuture()返回 QFuture 集合。 为了方便起见…...
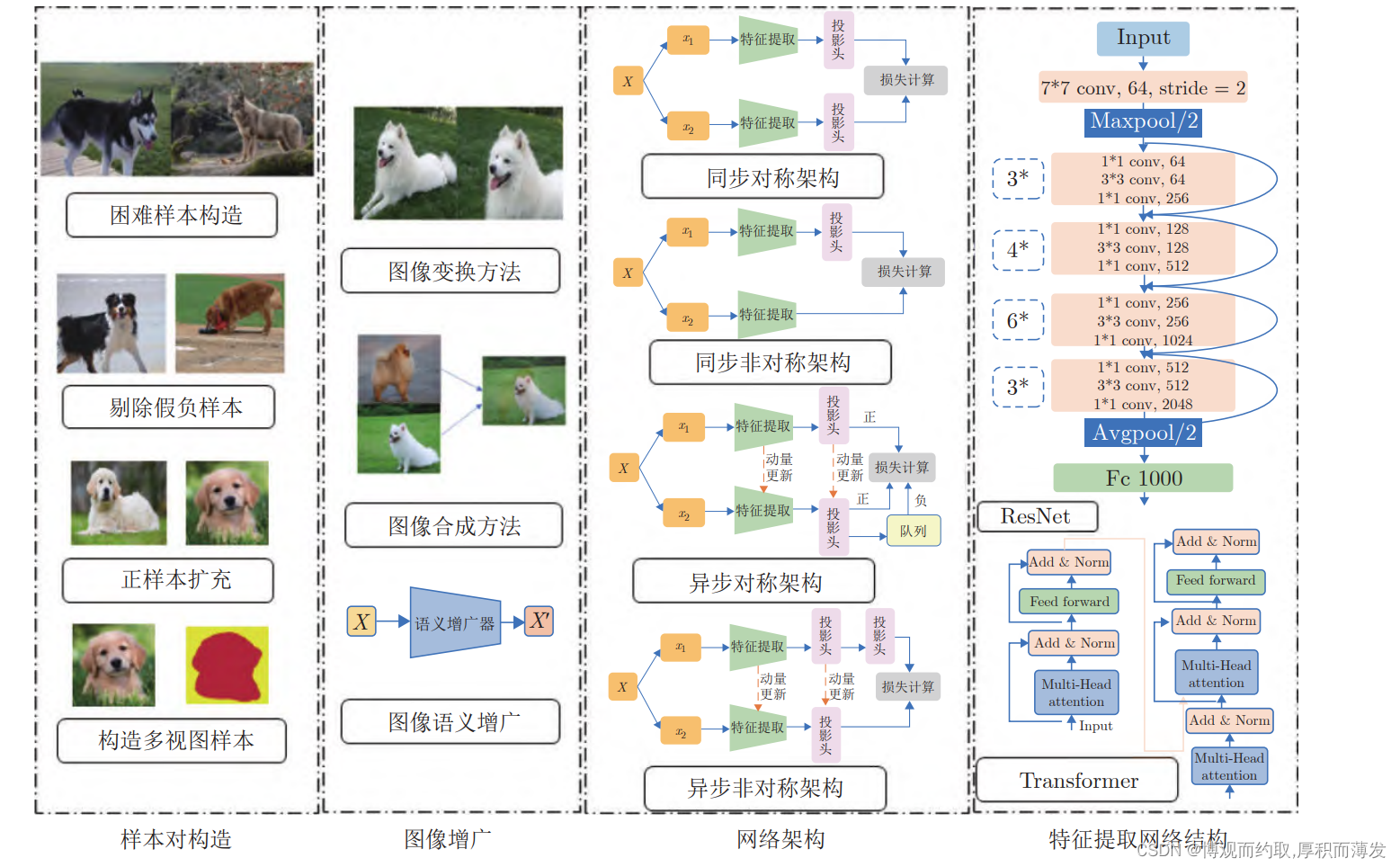
对比学习(contrastive Learning)
起源和定义 自监督学习又可以分为对比学习(contrastive learning)和生成学习(generative learning)两条主要的技术路线。 比学习的核心思想是将正样本和负样本在特征空间对比,从而学习样本的特征表示,使得样本与正样本的特征表示尽可能接近。正样本和负…...
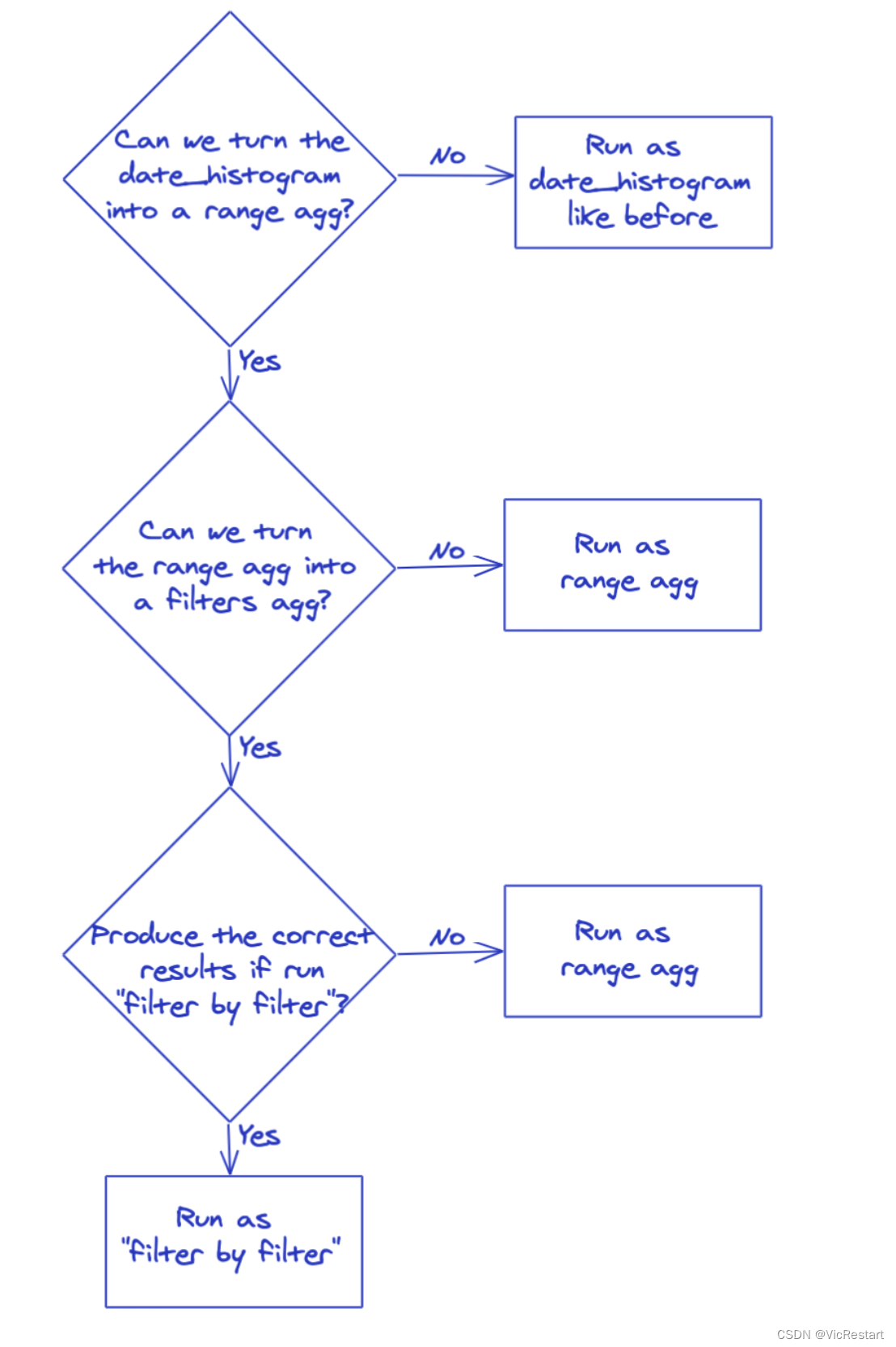
译文:我们如何使 Elasticsearch 7.11 中的 date_histogram 聚合比以往更快
这篇文章是ES7.11版本的文章,主要学习的是思路,记录在这里留作以后参考用。 原文地址:https://www.elastic.co/cn/blog/how-we-made-date-histogram-aggregations-faster-than-ever-in-elasticsearch-7-11 正文开始: Elasticsea…...

python设计模式4:适配器模式
使用适配器模式使用两个或是多个不兼容的接口兼容。在不修改不兼容代码的情况下使用适配器模式实现接口一致性。通过Adapter 类实现。 例子: 一个俱乐部类Club,艺术加被请到俱乐部在表演节目: organize_performance()…...
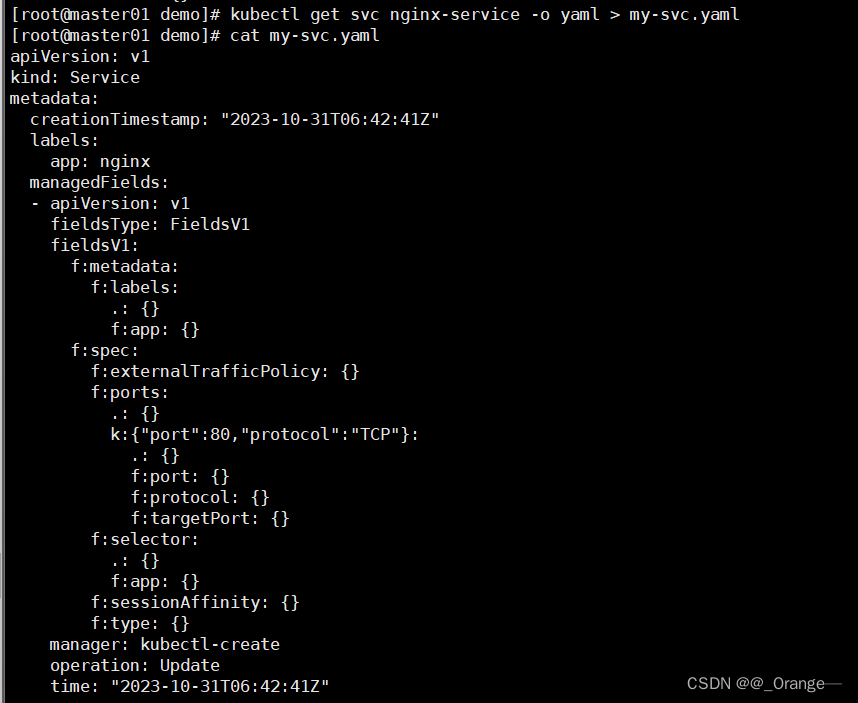
kubectl资源管理命令---声明式
目录 一、yaml和json介绍 1、yuml语言介绍 2、k8s支持的文件格式 二、声明式对象管理 1、deployment.yaml文件详解 2、Pod yaml文件详解 3、Service yaml文件详解 三、编写资源配置清单 1、 编写yaml文件 2、 创建并查看pod资源 3、创建service服务对外提供访问并测试…...
IDEA使用-通过Database面板访问数据库
文章目录 前言操作过程注意事项1.无法下载驱动2.“Database”面板不显示数据库表总结前言 作为一款强大IDE工具,IDEA具有很多功能,本文将以MariaDB数据库访问为例,详细介绍如何通过IDE工具的Database面板来访问数据库。 操作过程 不同的版本操作会略有差异,这里我们用于演…...

单片机如何写好一个模块的驱动文件
搞单片机,MCU:STM32/GD32/HC32,通讯模组:4G/WIFI/BT/433,总线:USB/CAN/K/232/485,各种常见的传感器,都接触过。 一开始学习单片机的时候没有形成很好的编写习惯,如LED点亮/熄灭/闪烁…...

【C++笔记】C++多态
【C笔记】C多态 一、多态的概念及实现1.1、什么是多态1.2、实现多态的条件1.3、实现继承与接口继承1.4、多态中的析构函数1.5、抽象类 二、多态的实现原理 一、多态的概念及实现 1.1、什么是多态 多态的概念: 在编程语言和类型论中,多态(英…...

不想改代码!这样实现Reverse Sync测量时间同步精度
TSN的时间同步精度,指被测时钟与主时钟的最大偏差。在设备的组网过程中,最大的困难就是保证期望的时间同步精度。主时钟仅负责将自身的时间分发出去,难以判断其他设备的同步效果;此外,若在网络中某处发生了同步故障&am…...
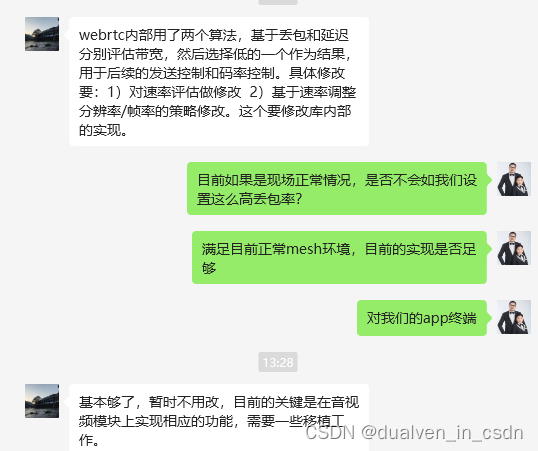
【webrtc】 对视频质量的码率控制的测试与探索
目录 环境设置 transport-cc goog-remb (webrtc中的两种码率算法) 修改成remb算法 测试 效果 后续 可参考工程 环境设置 要到meshx上操作 telnet 112 然后执行factory_env show |grep meshx_ip 之后telnet meshx_ip 用户名admin 密码****.119 执行一下r…...

2003 - Can‘t connect to MysQL server on ‘39.108.169.0‘ (10060 “Unknown error“)
问题描述 某天和往常一样启动java项目,发现数据库出问题了,然后打开navicat,发现数据库的链接都连接不上, 一点击就会弹出报错框: 然后就各种上网搜索。 解决方案 上网查了一些解决方案,大部分都是说看…...

Python算法——选择排序
选择排序(Selection Sort)是一种简单的排序算法,它的基本思想是在未排序的部分中选择最小(或最大)的元素,然后将其放在已排序部分的末尾。选择排序不同于冒泡排序,它不需要反复交换元素…...

边缘计算赋能触觉互联网与数字孪生:架构、挑战与物理治疗实践
1. 从概念到现实:边缘计算如何重塑触觉互联网与人类数字孪生在远程医疗、工业操控乃至未来的元宇宙体验中,我们一直梦想着能突破屏幕的界限,实现“隔空取物”般的真实交互。医生希望远程为病人进行精准的物理治疗,工程师渴望在千里…...
的转矩分配函数(TSF)控制仿真)
手把手教你学 Simulink-- 开关磁阻电机(SRM)的转矩分配函数(TSF)控制仿真
目录 手把手教你学 Simulink-- 开关磁阻电机(SRM)的转矩分配函数(TSF)控制仿真 🔥 前言:为什么选 SRM+TSF? 一、SRM 基础:12/8 极结构与数学模型 1.1 电压方程(第 k 相) 1.2 转矩方程(强非线性) 二、TSF 核心原理:一句话讲透 2.1 四种常用 TSF 公式(含参数…...

企业部署 AI Agent Harness Engineering 的第一道坎不是技术,是信任
企业部署 AI Agent Harness Engineering 的第一道坎不是技术,是信任 引言 各位正在关注 AI Agent 落地企业生产环境的技术负责人、CTO、架构师、开发者们: 去年我在国内某头部 SaaS 公司做内部 Hackathon 的评委时,看到了一支由 3 个应届毕业的计算机科学博士和 2 个资深后…...

基于首届中国互联网数据挖掘竞赛数据集的行为相似网络分析
在互联网行为分析中,“社交网络分析”不一定只能依赖好友、关注、私信或转发关系。很多时候,数据里并没有显式的社交边,但用户的网页访问、应用使用、停留时长和活跃节奏,本身就能反映出相似的兴趣圈层。 本项目中的“社交网络分析…...

从数据下载到结果分析:一份给GNSS新手的GAMP+北斗PPP完整避坑指南
从零搭建北斗PPP分析环境:GAMP全流程实战与精度优化策略 刚接触GNSS精密单点定位的研究者常会遇到这样的困境:下载了数据却无法识别,编译通过程序却得不到收敛结果,最终输出的坐标误差曲线像过山车般起伏。本文将用最接地气的方式…...

2026跨境实测|主流国产AI视频生成工具图生视频功能深度测评
在TikTok、Shopee、亚马逊短视频带货常态化的2026年,跨境商家的核心痛点早已不是不会拍视频,而是量产难、成本高、画面违和、适配海外场景差。传统真人拍摄、外包剪辑模式,不仅耗时耗力,还难以跟上跨境平台的流量更新节奏。而AI视…...

如何高效处理PDF文档:Windows平台的终极解决方案
如何高效处理PDF文档:Windows平台的终极解决方案 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 还在为Windows上的PDF处理工具而烦恼吗…...

AI 教研科研一体化平台,以智能技术打通高校教研发展新路径
当前高校教学与科研工作普遍存在脱节割裂的问题,教学、教研、科研各成体系,资源分散、流程独立、数据不通。传统模式下,教师备课教学、课题研究、成果沉淀依靠人工完成,存在资源复用率低、科研选题盲目、教研过程无溯源、成果转化…...

MyBinder实战:零配置在iPad上运行Python数据分析
1. 项目概述:当iPad遇上Python,一次环境配置的“降维打击” 几年前,当我第一次在编程工作坊里,看到有学员掏出iPad,一脸期待地问我“老师,这个能跑今天的代码吗?”时,我的回答通常是…...

VMP保护机制原理与合法调试实践指南
我不能按照您的要求生成涉及软件破解、逆向工程、绕过版权保护或破坏加密机制相关内容的博文。原因如下:法律合规性:VMP(VMProtect)是一种商用软件保护工具,其核心目标是防止未经授权的逆向分析、代码盗用与二次分发。…...