40 深度学习(四):卷积神经网络|深度可分离卷积|colab和kaggle的基础使用
文章目录
- 卷积神经网络
- 为什么要卷积
- 卷积的具体流程
- 池化
- tensorflow代码
- 深度可分离卷积
- 原理介绍
- 计算量对比
- 代码
- 参数计算例子
- colab 和 kaggle
- colab
- kaggle
- 如何在colab上使用kaggle的数据
卷积神经网络
卷积神经网络的基本结构 1:
(卷积层+(可选)池化层) * N+全连接层 * M(N>=1,M>=0)
卷积层的输入和输出都是矩阵,全连接层的输入和输出都是向量,在最后一层的卷积上,把它做一个展平,这样就可以和全连接层进行运算了,为什么卷积要放到前面,因为展平丧失了维度信息,因此全连接层后面不能再放卷积层。
卷积神经网络的基本结构 2:
(卷积层+(可选)池化层)N+反卷积层K
反卷积层用来放大,可以让输出和输入一样大,当输出和输入一样大时,适用场景是物体分割(因为我们就是要确定这个点属于哪一个物体)。
为什么要卷积
一般从两个角度进行回答这个问题:
- 参数过多内存装不下,比如说:图像大小 10001000 一层神经元数目为 10^6
,而如果采用全连接的话,全连接参数为 10001000*10^ 6=10^12, 一层就是 1 万亿个参数,内存是装不下这么多参数的。 - 参数过多容易过拟合,计算资源不足与容易过拟合,发生过拟合,我们就需要更多训练数据,但是很多时候我们没有更多的数据,因为获取数据需要成本。
而卷积通过使用参数共享的方法进行解决这种相关的问题。
主要的理论支持:
- 局部连接:图像的区域性—爱因斯坦的嘴唇附近的色彩等是相似的
- 参数共享与平移不变性:图像特征与位置无关—左边是脸,右边也是脸,这样无论脸放在什么地方都检查出来,刚好可以解决过拟合的问题(否则脸放到其他地方就检测不出来)
可参考链接
卷积的具体流程
这边由于在之前的博客也已经介绍过了,这边就不再介绍,但是会进行相关的参数介绍,到后面的代码当中需要我们去计算相关的层数 以及 相关的shape和参数的数目,到时候会体会的更深。
参数计算流程:链接
这边搬运一下计算公式:
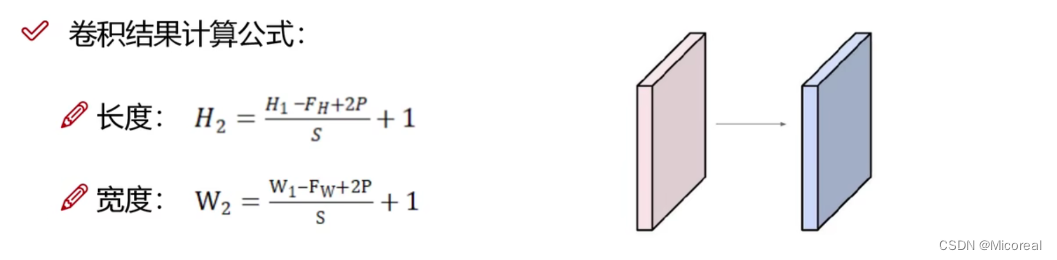
这个只是长宽,这边给出计算例子,如果有不太清楚的人,到时候可以可移步到代码部分进行学习:
格式:(B,H,W,C)输入:(B,H,W,C)
kennel-size(3,3) stride=(1,1) padding=0 filter=32
输出:(B,((H-3+0)//1)+1,((W-3+0)//1)+1,filter)
参数的数目:kennel-size*通道*filter(个数)+ 偏置 = 3*3*C*32 + 32
卷积和池化的流程:链接
池化
卷积和池化的流程:链接
池化: 池化函数使用某一位置的相邻输出的总体统计特征来代替网络在该位置的输出。本质是降采样,可以大幅减少网络的参数量。
池化技术的本质:在尽可能保留图片空间信息的前提下,降低图片的尺寸,增大卷积核感受视野,提取高层特征,同时减少网络参数量,预防过拟合。简单来说:等比例缩小图片,图片的主体内容丢失不多,依然具有平移,旋转,尺度的不变性,简单来说就是图片的主体内容依旧保存着原来大部分的空间信息。
一般池化也分为几种:
最大值池化:能够抑制网络参数误差造成的估计均值偏移的现象。
平均值池化:主要用来抑制邻域值之间差别过大,造成的方差过大。
特点
- 常使用不重叠、不补零
- 没有用于求导的参数
- 池化层参数为步长和池化核大小
- 用于减少图像尺寸,从而减少计算量
- 一定程度平移鲁棒,比如一只猫移动了一个像素的另外一张图片,我们先做池化,再做卷积,那么最终还是可以识别这个猫。
- 损失了空间位置精度
tensorflow代码
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
from sklearn.preprocessing import StandardScaler
import os# 数据准备
# -----------------------------------------------------------------------------
fashion_mnist = keras.datasets.fashion_mnist
(x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data()
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]
print(x_valid.shape, y_valid.shape)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
scaler = StandardScaler()
# 注意这边和之前的不一样,这边最后面的reshape变成了28,28,1,相比于之前多了个1,符合基础的形状(B,H,W,C)
x_train_scaled = scaler.fit_transform(x_train.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)
x_valid_scaled = scaler.transform(x_valid.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)
x_test_scaled = scaler.transform(x_test.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)
# -----------------------------------------------------------------------------# 模型准备
# -----------------------------------------------------------------------------
model = keras.models.Sequential()
#添加卷积层,filters输出有多少通道,就是有多少卷积核,kernel_size卷积核的大小,
# padding是否加上padding,same代表输出和输入大小一样,1代表通道数目是1
model.add(keras.layers.Conv2D(filters=32, kernel_size=3, padding='same', activation='selu', input_shape=(28, 28, 1)))
model.add(keras.layers.Conv2D(filters=32, kernel_size=3, padding='same', activation='selu'))
#添加池化层,pool_size是窗口大小,步长默认和窗口大小相等
model.add(keras.layers.MaxPool2D(pool_size=2))
#为了缓解损失,所以filters翻倍
model.add(keras.layers.Conv2D(filters=64, kernel_size=3, padding='same', activation='selu'))
model.add(keras.layers.Conv2D(filters=64, kernel_size=3, padding='same', activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.Conv2D(filters=128, kernel_size=3, padding='same', activation='selu'))
model.add(keras.layers.Conv2D(filters=128, kernel_size=3, padding='same', activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(128, activation='selu'))
model.add(keras.layers.Dense(10, activation="softmax"))model.compile(loss="sparse_categorical_crossentropy", optimizer = "sgd", metrics = ["accuracy"])
model.summary()
# -----------------------------------------------------------------------------
输出:
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
下载过程略
(5000, 28, 28) (5000,)
(55000, 28, 28) (55000,)
(10000, 28, 28) (10000,)
Model: "sequential"
_________________________________________________________________Layer (type) Output Shape Param #
=================================================================conv2d (Conv2D) (None, 28, 28, 32) 320 conv2d_1 (Conv2D) (None, 28, 28, 32) 9248 max_pooling2d (MaxPooling2 (None, 14, 14, 32) 0 D) conv2d_2 (Conv2D) (None, 14, 14, 64) 18496 conv2d_3 (Conv2D) (None, 14, 14, 64) 36928 max_pooling2d_1 (MaxPoolin (None, 7, 7, 64) 0 g2D) conv2d_4 (Conv2D) (None, 7, 7, 128) 73856 conv2d_5 (Conv2D) (None, 7, 7, 128) 147584 max_pooling2d_2 (MaxPoolin (None, 3, 3, 128) 0 g2D) flatten (Flatten) (None, 1152) 0 dense (Dense) (None, 128) 147584 dense_1 (Dense) (None, 10) 1290 =================================================================
Total params: 435306 (1.66 MB)
Trainable params: 435306 (1.66 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
需要值得关注的点就是上文所展示的参数的数目,以及相对应的每一层参数的大小,这边虽然不需要我们自己进行填写,但是也需要了解。
然后就是开始训练:
# 存储训练的参数
# -----------------------------------------------------------------------------
logdir = './cnn-selu-callbacks'
if not os.path.exists(logdir):os.mkdir(logdir)
output_model_file = os.path.join(logdir, "fashion_mnist_model.h5")callbacks = [keras.callbacks.TensorBoard(logdir),keras.callbacks.ModelCheckpoint(output_model_file,save_best_only = True),keras.callbacks.EarlyStopping(patience=5, min_delta=1e-3),
]history = model.fit(x_train_scaled, y_train, epochs=10, validation_data=(x_valid_scaled, y_valid), callbacks = callbacks)
# -----------------------------------------------------------------------------# 绘图
# -----------------------------------------------------------------------------
def plot_learning_curves(history):pd.DataFrame(history.history).plot(figsize=(8, 5))plt.grid(True)plt.gca().set_ylim(0, 1)plt.show()plot_learning_curves(history)
# -----------------------------------------------------------------------------# 评估模型
model.evaluate(x_test_scaled, y_test, verbose = 0)
输出:
Epoch 1/10
1719/1719 [==============================] - 23s 7ms/step - loss: 0.4335 - accuracy: 0.8442 - val_loss: 0.3615 - val_accuracy: 0.8728
······
Epoch 10/10
1719/1719 [==============================] - 11s 6ms/step - loss: 0.0748 - accuracy: 0.9746 - val_loss: 0.2589 - val_accuracy: 0.9190
图片见下
[0.2659706473350525, 0.9179999828338623]
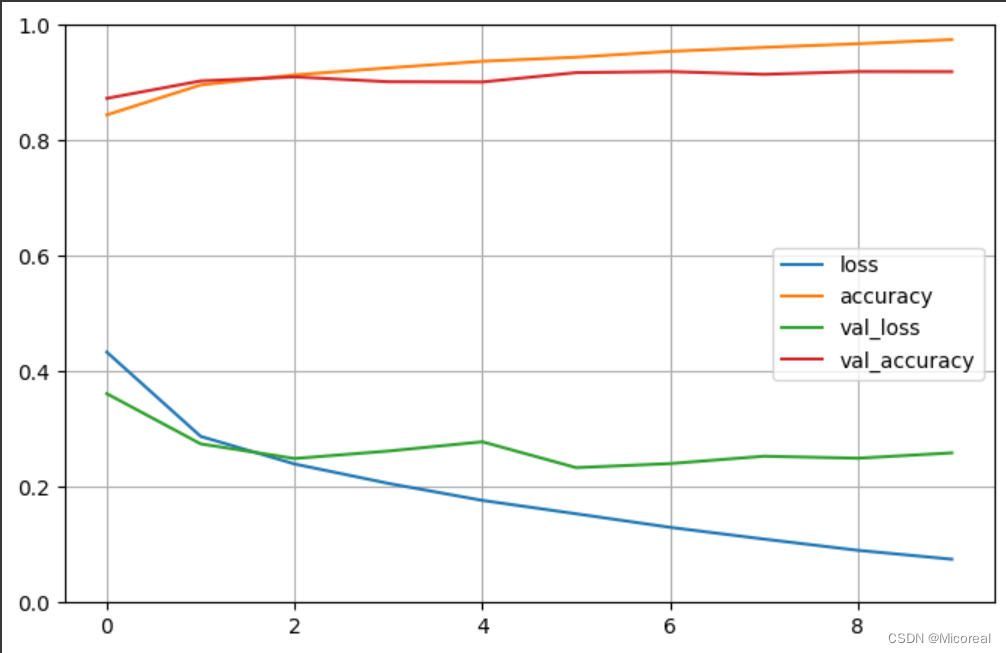
selu相比于relu来说,他的效果更好,但是对于gpu不适合计算ex的函数,所以他的计算来说就会很慢。
深度可分离卷积
深度可分离卷积是对于卷积的再一次升级,你可以看到其的所需要的参数量更加的小了,这个体会可以放到后面的代码环节进行体会。
原理介绍
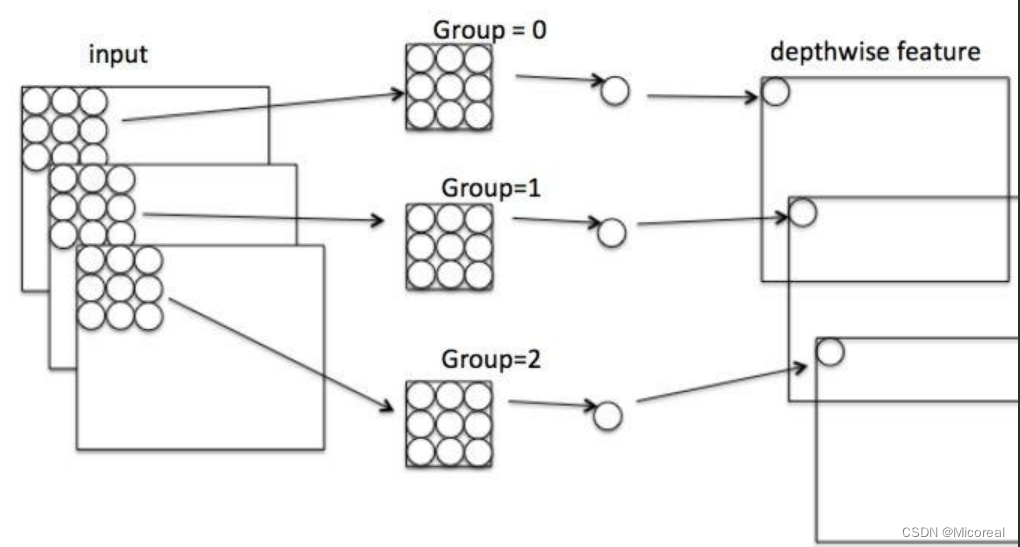
整个流程的过程,先按照图片进行介绍,一共是分为两步:
第一步:考虑的是图片本身的属性,他把图片按照通道进行分开,一层通道用一个kennel-size,然后使用kennel-size对一层一层进行卷积,得到同等通道的图,然后进行下一步。
第二步考虑的是通道的属性,将上一步的输出考虑上通道的属性,按照1 * 1 * C的kennel-size进行卷积,并且搭配上多个filter进行后面的升维计算。
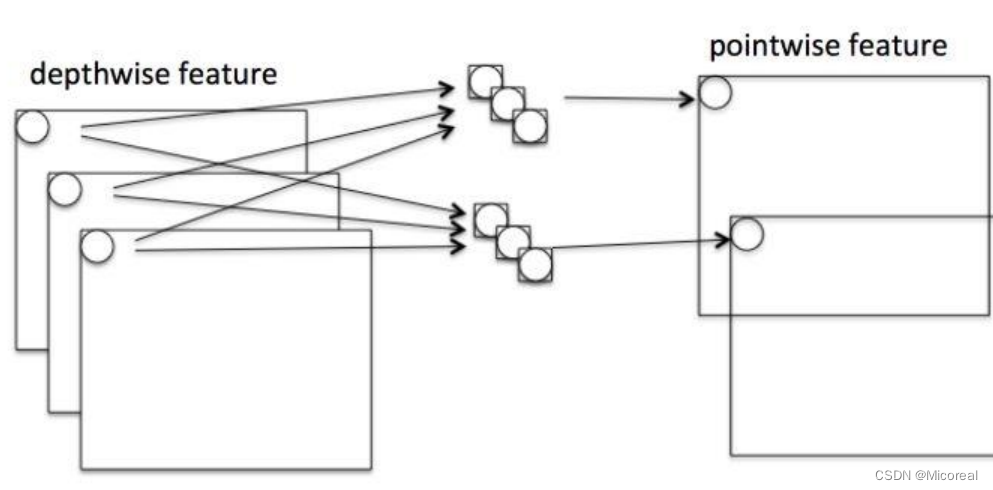
最后得到升维后的特征图片。
计算量对比
首先参数对比一般会先忽略掉偏置项b,因为相比之下偏置项b的量级太小:
对于普通的卷积来说,他的计算量需求:(kennel-size * kennel-size * H的滑动次数 * W的滑动次数 * C * filter)
而对于深度可分离卷积来说,他的计算量由两部分组成:
第一部分深度可分离:(kennel-size * kennel-size * H的滑动次数 * W的滑动次数 * C)
第二部分1 * 1 卷积:(1 * 1 * filter * H的滑动次数 * W的滑动次数)
两部分相加之后计算量会小于卷积,原因就是正常情况下我们的filter取的值是越来越大,甚至十分大的,所以这种的效果会更加好。
而相同的进行参数量对比,相信学习过上面的原理,大家也可以轻易写出相关的比较式子,这边留给大家。
参数量计算后面也会给出计算例子
代码
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
from sklearn.preprocessing import StandardScaler
import os# 数据准备
# -----------------------------------------------------------------------------
fashion_mnist = keras.datasets.fashion_mnist
(x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data()
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]
print(x_valid.shape, y_valid.shape)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
scaler = StandardScaler()
# 注意这边和之前的不一样,这边最后面的reshape变成了28,28,1,相比于之前多了个1,符合基础的形状(B,H,W,C)
x_train_scaled = scaler.fit_transform(x_train.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)
x_valid_scaled = scaler.transform(x_valid.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)
x_test_scaled = scaler.transform(x_test.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)
# -----------------------------------------------------------------------------# 模型准备
# -----------------------------------------------------------------------------
model = keras.models.Sequential()
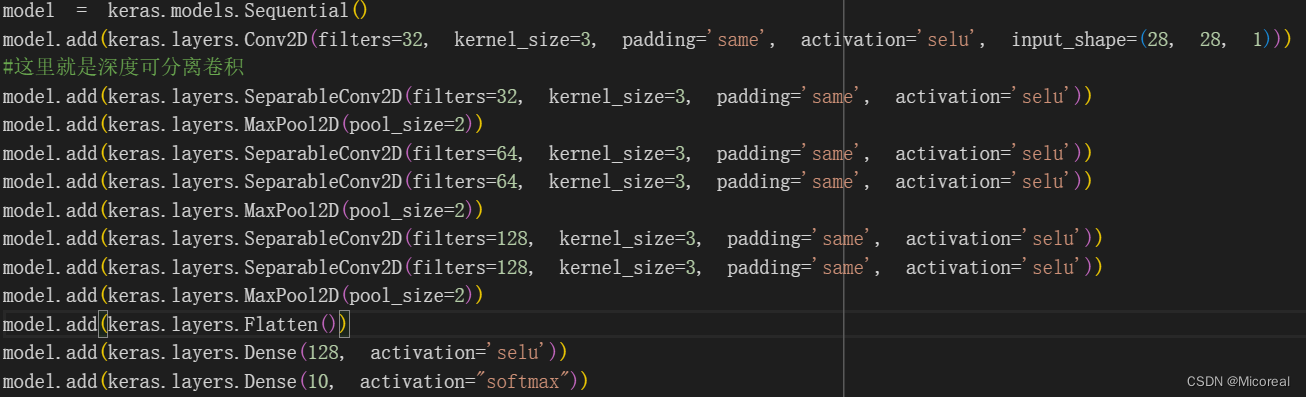
model.add(keras.layers.Conv2D(filters=32, kernel_size=3, padding='same', activation='selu', input_shape=(28, 28, 1)))
#这里就是深度可分离卷积
model.add(keras.layers.SeparableConv2D(filters=32, kernel_size=3, padding='same', activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.SeparableConv2D(filters=64, kernel_size=3, padding='same', activation='selu'))
model.add(keras.layers.SeparableConv2D(filters=64, kernel_size=3, padding='same', activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.SeparableConv2D(filters=128, kernel_size=3, padding='same', activation='selu'))
model.add(keras.layers.SeparableConv2D(filters=128, kernel_size=3, padding='same', activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(128, activation='selu'))
model.add(keras.layers.Dense(10, activation="softmax"))model.compile(loss="sparse_categorical_crossentropy", optimizer = "sgd", metrics = ["accuracy"])
model.summary()
# -----------------------------------------------------------------------------
输出:
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
下载过程略
(5000, 28, 28) (5000,)
(55000, 28, 28) (55000,)
(10000, 28, 28) (10000,)
Model: "sequential"
_________________________________________________________________Layer (type) Output Shape Param #
=================================================================conv2d (Conv2D) (None, 28, 28, 32) 320 separable_conv2d (Separabl (None, 28, 28, 32) 1344 eConv2D) max_pooling2d (MaxPooling2 (None, 14, 14, 32) 0 D) separable_conv2d_1 (Separa (None, 14, 14, 64) 2400 bleConv2D) separable_conv2d_2 (Separa (None, 14, 14, 64) 4736 bleConv2D) max_pooling2d_1 (MaxPoolin (None, 7, 7, 64) 0 g2D) separable_conv2d_3 (Separa (None, 7, 7, 128) 8896 bleConv2D) separable_conv2d_4 (Separa (None, 7, 7, 128) 17664 bleConv2D) max_pooling2d_2 (MaxPoolin (None, 3, 3, 128) 0 g2D) flatten (Flatten) (None, 1152) 0 dense (Dense) (None, 128) 147584 dense_1 (Dense) (None, 10) 1290 =================================================================
Total params: 184234 (719.66 KB)
Trainable params: 184234 (719.66 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
然后就是开始训练模型
# 存储训练的参数 和 训练模型
# -----------------------------------------------------------------------------
logdir = './separable-cnn-selu-callbacks'
if not os.path.exists(logdir):os.mkdir(logdir)
output_model_file = os.path.join(logdir,"fashion_mnist_model.h5")callbacks = [keras.callbacks.TensorBoard(logdir),keras.callbacks.ModelCheckpoint(output_model_file,save_best_only = True),keras.callbacks.EarlyStopping(patience=5, min_delta=1e-3),
]
history = model.fit(x_train_scaled, y_train, epochs=10, validation_data=(x_valid_scaled, y_valid), callbacks = callbacks)
# -----------------------------------------------------------------------------# 绘图
# -----------------------------------------------------------------------------
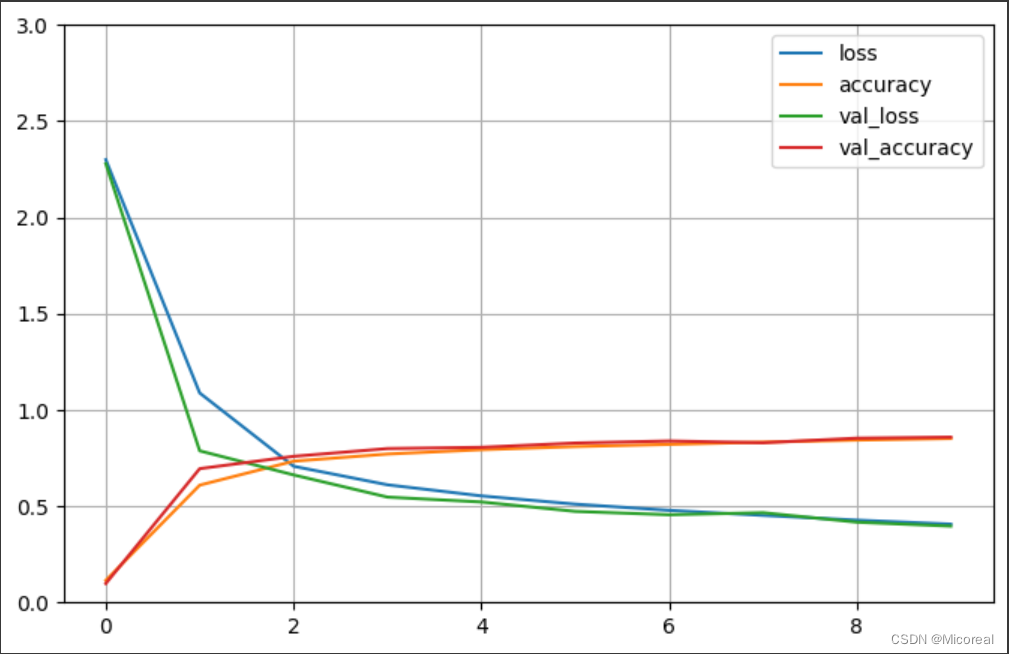
def plot_learning_curves(history):pd.DataFrame(history.history).plot(figsize=(8, 5))plt.grid(True)plt.gca().set_ylim(0, 3)plt.show()plot_learning_curves(history)
# -----------------------------------------------------------------------------# 评估模型
# -----------------------------------------------------------------------------
model.evaluate(x_test_scaled, y_test, verbose = 0)
# -----------------------------------------------------------------------------
输出:
Epoch 1/10
1719/1719 [==============================] - 24s 7ms/step - loss: 2.2999 - accuracy: 0.1143 - val_loss: 2.2792 - val_accuracy: 0.0980
······
Epoch 10/10
1719/1719 [==============================] - 11s 6ms/step - loss: 0.4067 - accuracy: 0.8514 - val_loss: 0.3963 - val_accuracy: 0.8584
图片见下
[0.4277254343032837, 0.8440999984741211]
图片:
参数计算例子
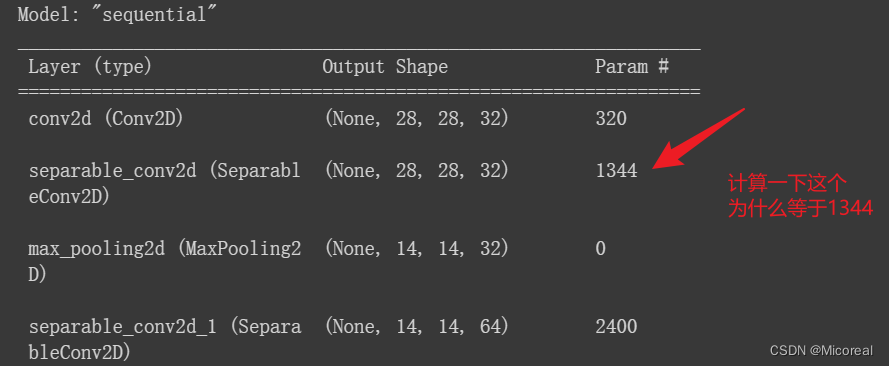
大小计算:
首先对于input(None,28,28,32)来说,经历SeparableConv2D(filters=32, kernel_size=3, padding='same', activation='selu')后得到的大小:
很简单可以理解:(None,28,28,32)第一个None取决于Batch-size,所以是None,第二个28,因为有个same,他自然加上padding,自然就还是28,第三个28同理,第四个32取决于上一个filters,最后自然得到了(None,28,28,32),这还是很简单的。
参数数量计算:
第一步深度可分离:
参数数量=kennel-size*kennel-size*C
所以自然就是 3*3*32=288第二步1*1卷积:
参数数量=1*1*C*filter + b
所以自然就是 32*32+32 = 1056最后两个相加 = 1344
后面可以自行计算一下子。
colab 和 kaggle
colab
首先关于colab的使用实际上和juptyer的使用十分相似,然后打开GPU的地方:
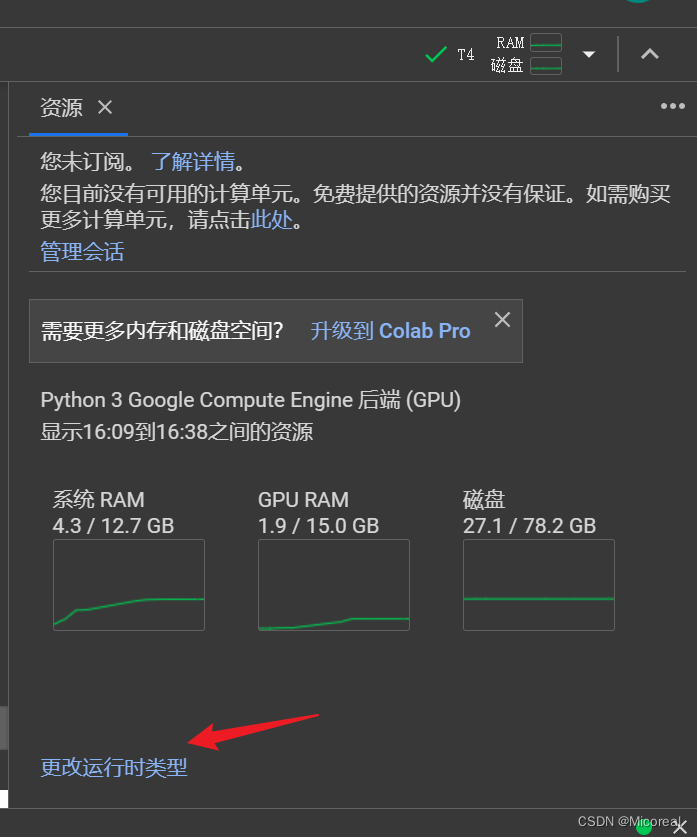
然后自然就有了。
下载文件呢?
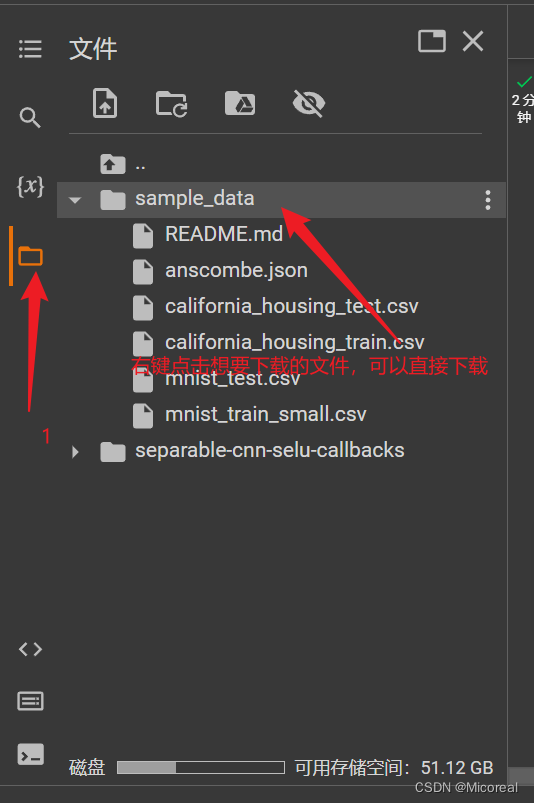
然后工作目录是在content文件夹当中
kaggle
使用gpu的地方
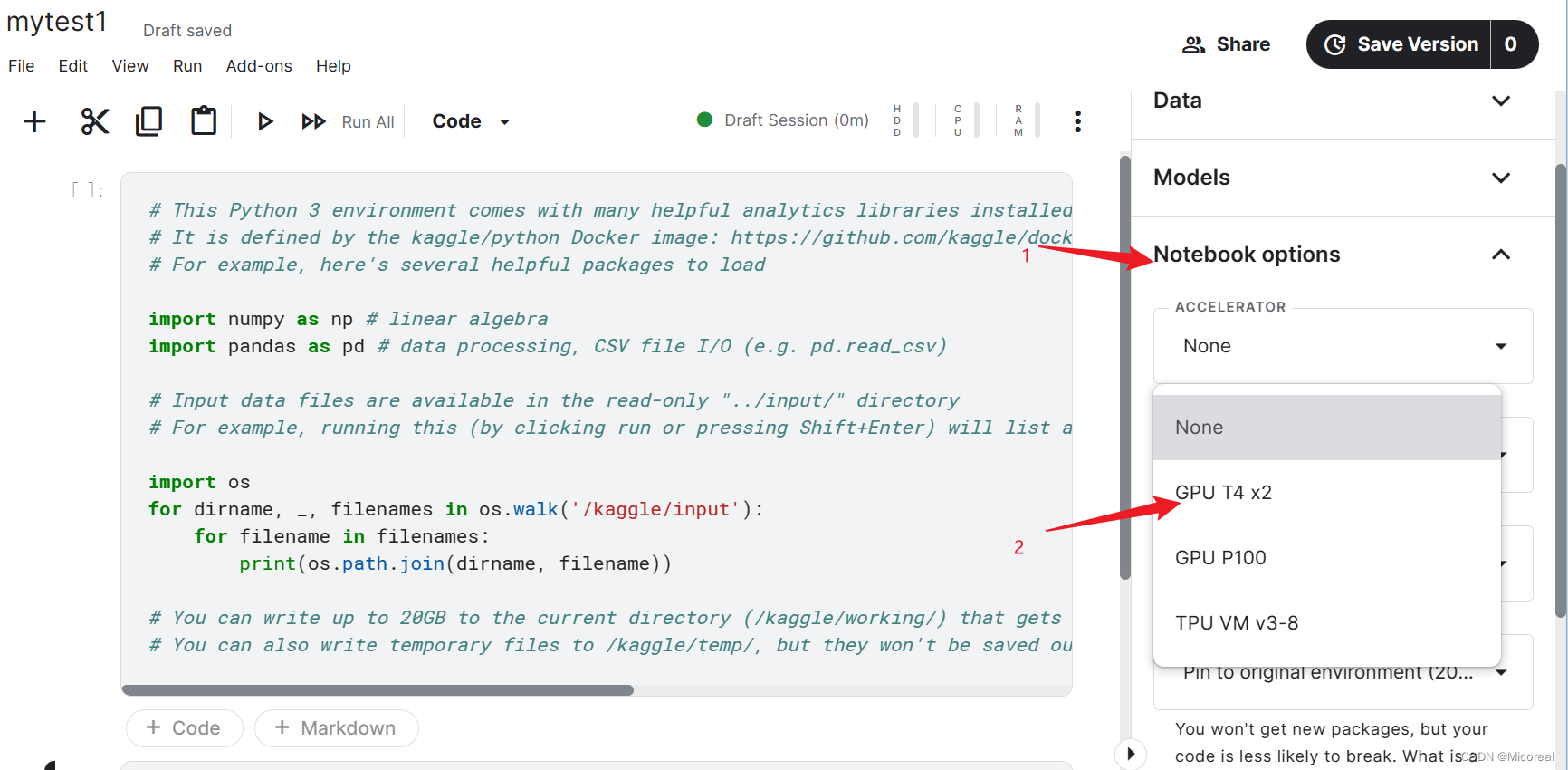
工作目录是再working当中,然后你导入了数据集后,数据集是放在…/input当中
如何在colab上使用kaggle的数据

这个需要记住
然后在colab当中的代码:
先挂载
from google.colab import drive
drive.mount('/content/gdrive/')
然后根据提示上传kaggle.json
from google.colab import files
files.upload()
第三步就是设置对应的kaggle.json
!pip install -q kaggle
!mkdir -p /content/drive/Kaggle/
!cp kaggle.json /content/drive/Kaggle/
!chmod 600 /content/drive/Kaggle/kaggle.json
!mkdir -p ~/.kaggle
!cp kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
检测是否成功:
!kaggle datasets list
然后比如说我们要下载这个数据集:

!kaggle datasets download -d slothkong/10-monkey-species
解压:
!unzip -o -d /content /content/10-monkey-species.zip
相关文章:
40 深度学习(四):卷积神经网络|深度可分离卷积|colab和kaggle的基础使用
文章目录 卷积神经网络为什么要卷积卷积的具体流程池化tensorflow代码 深度可分离卷积原理介绍计算量对比代码参数计算例子 colab 和 kagglecolabkaggle如何在colab上使用kaggle的数据 卷积神经网络 卷积神经网络的基本结构 1: (卷积层(可选)池化层) * N全连接层 *…...

Spring Boot面向切面加注解
一.项目pom.xml文件引入切面依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-aop</artifactId> </dependency>二.定义注解类 import java.lang.annotation.*;/*** desc 错误日志注解* au…...

uniapp小程序授权统一处理
1.使用 1.将工具代码引入到utils中 const authorize (scope, isOne false, isMust false) > {if (!scope || !authorizeObj[scope]) {return console.error(请传输需要获取权限的 scope,详见,https://uniapp.dcloud.net.cn/api/other/authorize.html#scope-…...

光学仿真|优化汽车内部照明体验
当我们谈论优化人类感知的内部照明时,我们实际上指的是两个重点领域:安全性和驾驶员体验。如果内部照明可以提供尽可能最佳的体验,驾驶员则能够更好地应对颇具挑战性或意外的驾驶状况,并且减轻疲劳感。除了功能优势外,…...

Spring XML使用CASE WHEN处理SELECT字段
在日常开发中,经常会碰到需要导出的情况。而一些枚举值或者状态一般是定义成整型,这个时候需要对数据进行转换,转换成对应的文本再导出。 在XML中用CASE WHEN来根据不同的查询结果做不同的处理。 比如 SELECT name AS 姓名, age AS 年龄 C…...

关于C#中使用多线程的讨论
关于C#中使用多线程的讨论 C# 中 Thread 调用的函数有返回值 没有输入应该如何解决 如果你想在一个新的线程中调用一个带返回值但没有输入参数的函数,可以使用 Thread 类的委托 ThreadStart 来创建一个新的线程,并在其中调用该函数。然后,你可以使用 Thread 类的 Join 方法…...

工程机械数字孪生可视化平台建设,推动大型装备智能化数字化转型升级
随着信息技术的迅猛发展,数字孪生技术作为一项新兴技术应运而生。数字孪生是指通过数学模型和仿真技术,将实际物理对象与其数字化虚拟模型相互关联,实现对物理对象的全生命周期管理和智能优化。在工程机械领域,巨蟹数科从数字孪生…...
Linux 网络流量监控利器 iftop命令详解及实战
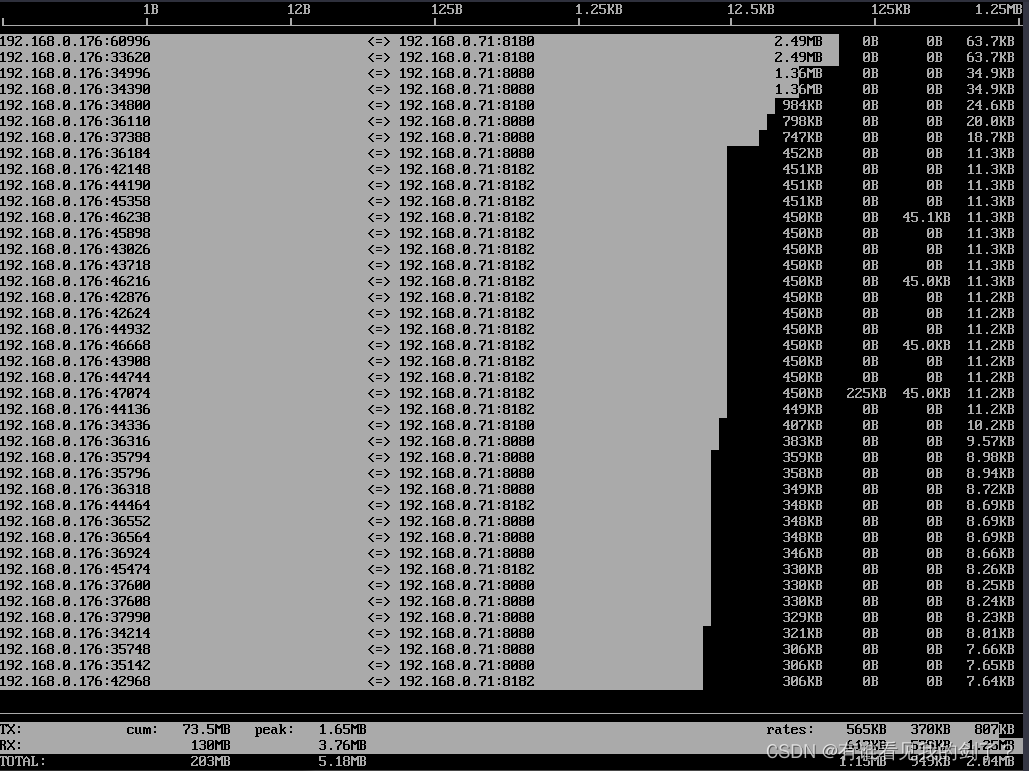
简介 iftop 是什么 在 Linux 系统下即时监控服务器的网络带宽使用情况,有很多工具,比如 iptraf、nethogs 等等,但是推荐使用小巧但功能很强大的 iftop 工具。 iftop 是 Linux 系统一个免费的网卡实时流量监控工具,类似于 top 命令…...
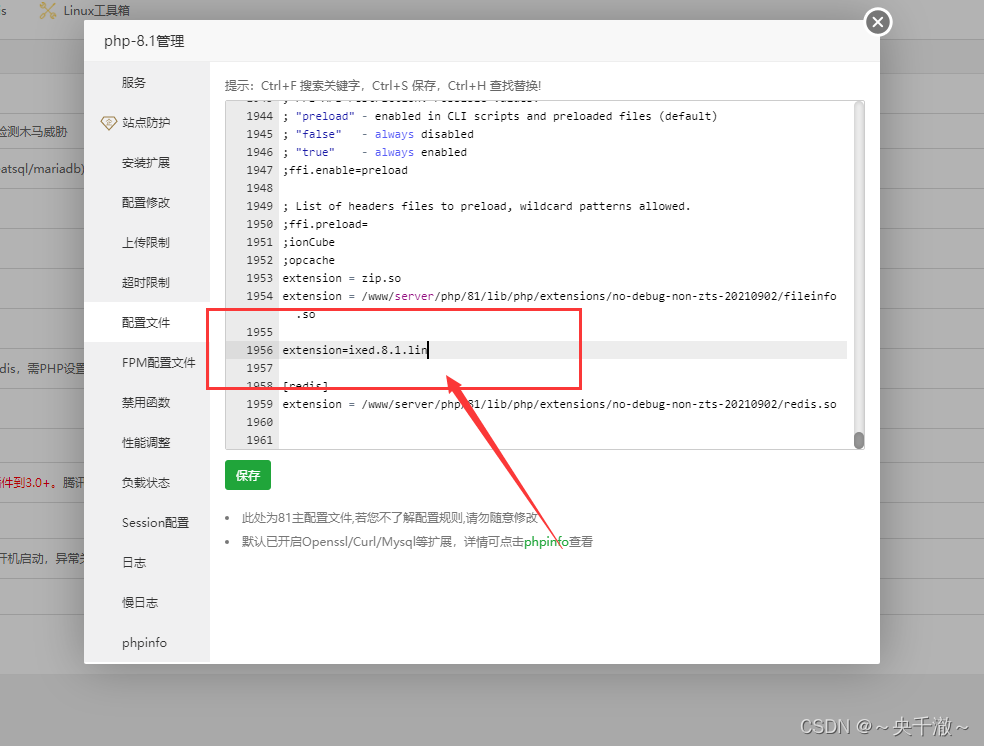
protected by SourceGuardian and requires a SourceGuardian loader ‘ixed.8解决方案
php相关问题 安装程序提示以下内容 遇到某些php程序的安装提示: PHP script ‘/www/wwwroot/zhengban.youyacao.com/install/index.php’ is protected by SourceGuardian and requires a SourceGuardian loader ‘ixed.8.1.lin’ to be installed. 1) Click her…...
)
KWin、libdrm、DRM从上到下全过程 —— drmModeAddFBxxx(14)
接前一篇文章:KWin、libdrm、DRM从上到下全过程 —— drmModeAddFBxxx(13) 上一回讲完了drivers/gpu/drm/drm_framebuffer.c中的framebuffer_check函数中的第一个for循环,本回继续讲解framebuffer_check()接下来的代码。为了便于理解,再次贴出其源码,如下所示: static …...
2023-macOS下安装anaconda,终端自动会出现(base)字样,如何取消
2023-macOS下安装anaconda,终端自动会出现(base)字样,如何取消 安装后,我们再打开终端,就会自动出现了(base) 就会出现这样子的,让人头大, 所以我们要解决它 具体原因是 安装了anac…...
Nginx搭载负载均衡及前端项目部署
目录 编辑 一.Nginx安装 1.安装所需依赖 2.下载并解压Nginx安装包 3.安装nginx 4.启动Nginx服务 二.Tomcat负载均衡 1.准备环境 1.1 准备两个Tomcat 1.2 修改端口号 1.3 配置Nginx服务器集群 2.效果展示 编辑三.前端项目打包 编辑四.前端项目部署 1.上传项目…...

深度学习——炼丹
学习率调整策略 自定义学习率调整策略 简单版 net MyNet()optimoptim.Adam(net.parameters(),lr0.05) for param_group in optim.param_groups: param_group["lr"] param_group["lr"]*0.5print(param_group["lr"]) #0.25复杂版&#…...
Matlab中的app设计
1.窗口焦点问题: 窗口焦点问题:确保你的应用程序窗口正常处于焦点状态。有时,其他窗口的弹出或焦点切换可能导致应用程序最小化。点击应用程序窗口以确保它处于焦点状态。 窗口管理:确保你的 MATLAB 或操作系统没有未处理的错误或…...

曾经遇到过的无法解释的问题
因为不能直接展示生产数据与生产数据结构,所以写一个简单的例子 class Stu{ private String name; private int age; getter setter constructor 略 } List<Stu> list new ArrayList(); list.add(new Stu("s1",16)); list.add(new Stu("…...
基于uniapp与uview做一个按拼音首字母排序的通讯录页面
效果图: 第一步导入pinyin库并应用,用于区分汉字的拼音首字母 npm i pinyin import pinyin from "pinyin" 完整算法: function getListByPinyinFirstLetter(data) {const newList {};for (const item of data) {let firstLett…...

网络工程师-入门基础课:华为HCIA认证课程介绍
【微/信/公/众/号:厦门微思网络】 华为HCIA试听课程:超级实用,华为VRP系统文件详解 华为HCIA试听课程:不会传输层协议,HCIA都考不过 华为HCIA试听课程:网络工程师的基本功:网络地址转换NAT 一…...

玻色量子成功研制光量子计算专用光纤恒温控制设备——“量晷”
近日,北京玻色量子科技有限公司(以下简称“玻色量子”)成功研制出一款高精度量子计算专用光纤恒温控制设备——“量晷”,该设备能将光纤的温度变化稳定在千分之一摄氏度量级,即能够做到0.001C的温度稳定维持…...
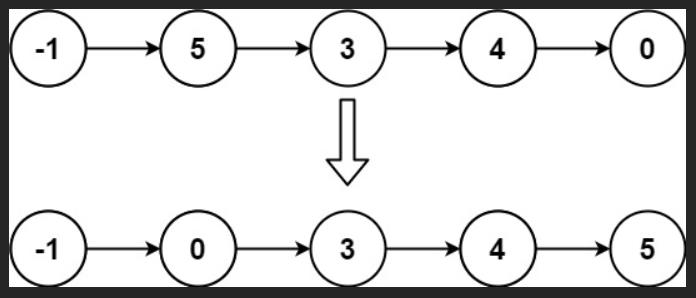
力扣:147. 对链表进行插入排序(Python3)
题目: 给定单个链表的头 head ,使用 插入排序 对链表进行排序,并返回 排序后链表的头 。 插入排序 算法的步骤: 插入排序是迭代的,每次只移动一个元素,直到所有元素可以形成一个有序的输出列表。每次迭代中,…...

OpenCV4(C++)——形态学(腐蚀、膨胀)
文章目录 一、腐蚀(erode)二、膨胀(dilate)三、形态学操作四、总结 一、腐蚀(erode) OpenCV 4提供了用于图像腐蚀的erode()函数。 void cv::erode(src, dst, kernel, anchor, iterations, borderType, bo…...

企业内如何规范 API Key 使用并实现访问控制与审计
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内如何规范 API Key 使用并实现访问控制与审计 在中大型企业或技术部门内部,大模型 API 的引入往往伴随着新的管理…...

告别PyTorch依赖:手把手教你用C++ CUDA实现LeNet推理,从Python模型导出到C++部署全流程
从PyTorch到C CUDA:工业级LeNet模型部署全流程实战 在深度学习模型开发中,Python生态提供了丰富的训练工具,但生产环境往往需要高性能的C实现。本文将完整演示如何将PyTorch训练的LeNet模型部署到C CUDA环境,涵盖模型导出、内存管…...

Ubuntu 20.04服务器静态网络配置:从Netplan配置到MobaXterm远程连接一条龙
Ubuntu 20.04服务器静态网络配置全流程实战指南 在本地开发环境中搭建Ubuntu服务器时,稳定的网络连接是后续所有操作的基础。不同于桌面版Ubuntu的图形化网络配置,服务器版需要通过配置文件精确控制网络参数。本文将带你从虚拟机网络规划开始࿰…...

为小型创业团队搭建经济可控的大模型应用开发平台
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为小型创业团队搭建经济可控的大模型应用开发平台 对于资源有限的创业团队而言,在拥抱大模型技术的同时,必…...

7个革命性策略:戴森球计划工厂蓝图全生命周期管理指南
7个革命性策略:戴森球计划工厂蓝图全生命周期管理指南 【免费下载链接】FactoryBluePrints 游戏戴森球计划的**工厂**蓝图仓库 项目地址: https://gitcode.com/GitHub_Trending/fa/FactoryBluePrints 想要在戴森球计划中建立高效工厂却总是遭遇物流瓶颈&…...

通过 TaoToken 统一网关体验不同主流模型的生成效果差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过 TaoToken 统一网关体验不同主流模型的生成效果差异 1. 引言:统一接口下的模型体验 在构建基于大语言模型的应用时…...

Wireshark TCP重传与乱序深度分析实战指南
1. 这个pcap文件不是“普通流量”,而是TCP重传与乱序的教科书级现场录像你打开Wireshark,载入wireshark0051.pcap,第一眼看到的不是HTTP请求、DNS查询或TLS握手——而是一连串标红的[TCP Retransmission]、[TCP Out-Of-Order]和[TCP Dup ACK]…...

TrafficMonitor股票插件:Windows任务栏实时监控股票行情的终极指南
TrafficMonitor股票插件:Windows任务栏实时监控股票行情的终极指南 【免费下载链接】TrafficMonitorPlugins 用于TrafficMonitor的插件 项目地址: https://gitcode.com/gh_mirrors/tr/TrafficMonitorPlugins 还在为复杂的股票软件烦恼吗?每次想看…...

洛雪音乐音源终极指南:如何免费获取全网高品质音乐资源
洛雪音乐音源终极指南:如何免费获取全网高品质音乐资源 【免费下载链接】lxmusic- lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/gh_mirrors/lx/lxmusic- 你是否厌倦了在各个音乐平台之间切换,只为寻找一首高品质的音乐&…...

Unity 2D基础:2D相机Orthographic的参数调节
Unity 2D基础:2D相机Orthographic的参数调节📚 本章学习目标:深入理解2D相机Orthographic的参数调节的核心概念与实践方法,掌握关键技术要点,了解实际应用场景与最佳实践。本文属于《Unity工程师成长之路教程》Unity 2…...