RT-DERT:在实时目标检测上,DETRs打败了yolo
文章目录
- 摘要
- 1、简介
- 2. 相关研究
- 2.1、实时目标检测器
- 2.2、端到端目标检测器
- 2.3、用于目标检测的多尺度特征
- 3、检测器的端到端速度
- 3.1、 NMS分析
- 3.2、端到端速度基准测试
- 4、实时DETR
- 4.1、模型概述
- 4.2、高效的混合编码器
- 4.3、IoU-aware查询选择
- 4.4、RT-DETR的缩放
- 5、实验
- 5.1、设置
- 5.2、与SOTA方法比较
- 5.3、混合编码器的消融研究
- 5.4、IoU-aware查询选择的消融研究
- 5.5、解码器消融研究
- 6、结论
摘要
论文:https://arxiv.org/pdf/2304.08069.pdf
最近,基于Transformer的端到端检测器(DETRs)取得了显著的成果。然而,DETRs的高计算成本限制了它们的实际应用,并阻止了它们充分利用无后处理(例如非极大值抑制(NMS))的优势。在本文中,我们首先分析了NMS对现有实时目标检测器的准确性和速度的负面影响,并建立了端到端的实时速度基准。为了解决上述问题,我们提出了第一个实时端到端目标检测器——RT-DETR(Real-Time Detection Transformer)。具体来说,我们设计了一个高效的混合编码器,通过分离尺度内的相互作用和跨尺度融合来有效地处理多尺度特征,并提出了IoU-aware查询选择来进一步提高性能,为解码器提供更高质量的初始目标查询。此外,我们提出的检测器支持使用不同的解码层进行灵活的推理速度调整,无需重新训练,这有利于在各种实时场景中的实际应用。我们的RT-DETR-L在COCO val2017上实现了53.0%的AP,在T4 GPU上实现了114 FPS,而RT-DETR-X实现了54.8%的AP和74 FPS,在速度和准确性方面都优于相同规模的YOLO检测器。此外,我们的RT-DETR-R50实现了53.1%的AP和108 FPS,在准确性方面比DINO-DeformableDETR-R50高出2.2%,在FPS方面高出约21倍。源代码和预训练模型可在https://github.com/lyuwenyu/RT-DETR上获得。
1、简介
目标检测是一项基本的视觉任务,涉及到图像中对象的识别和定位。有两种典型的目标检测器架构:基于CNN的和基于Transformer的。在过去的几年中,基于CNN的目标检测器得到了广泛的研究。这些检测器的架构从最初的二阶段[12, 30, 4]演变为单阶段[23, 36, 1, 13, 26, 17, 41, 18, 10, 38, 14],并且出现了两种检测范式,基于锚的[23, 26, 17, 13, 38]和锚自由[36, 10, 41, 18, 14]。这些研究在检测速度和准确性方面取得了重大进展。基于Transformer的目标检测器(DETRs)[5, 34, 39, 49, 27, 40, 24, 20, 46, 6]自提出以来就受到学术界的广泛关注,由于其消除了各种手工组件,例如非极大值抑制(NMS)。该架构极大地简化了目标检测的流程,并实现了端到端的目标检测。
实时目标检测是一个重要的研究领域,具有广泛的应用,如目标跟踪[45, 48]、视频监控[28]、自动驾驶[2, 44]等。现有的实时检测器通常采用基于CNN的架构,这在检测速度和准确性之间达到了合理的折衷。然而,这些实时检测器通常需要使用NMS进行后处理,这通常很难优化且不够鲁棒,导致检测器的推理速度延迟。最近,由于研究人员在加速训练收敛和降低优化难度方面的努力,基于Transformer的检测器取得了显着的性能。然而,DETR的计算成本高的问题没有得到有效解决,限制了DETR的实际应用,无法充分利用其优势。这意味着尽管目标检测管道被简化了,但由于模型本身的计算成本高,难以实现实时目标检测。上述问题自然促使我们考虑是否可以将DETR扩展到实时场景,充分利用端到端检测器来避免NMS对实时检测器造成的延迟。
为了实现上述目标,我们对DETR进行重新思考,并对关键组件进行详细的分析和实验,以减少不必要的计算冗余。具体来说,我们发现,尽管引入多尺度特征有助于加快训练收敛和提高性能[49],但它也导致输入到编码器的序列长度显著增加。因此,由于高昂的计算成本,变压器编码器成为模型的计算瓶颈。为了实现实时目标检测,我们设计了一种高效的混合编码器来替代原始的变压器编码器。通过分离多尺度特征的内部尺度交互和跨尺度融合,编码器可以有效地处理不同尺度的特征。此外,早期的研究[40, 24]表明,解码器的对象查询初始化方案对检测性能至关重要。为了进一步提高性能,我们提出了IoU-aware查询选择,通过在训练过程中提供IoU约束,为解码器提供更高质量的初始对象查询。此外,我们提出的检测器支持使用不同的解码器层进行灵活的推理速度调整,无需重新训练,这得益于DETR架构中解码器的设计,并促进了实时检测器的实际应用。
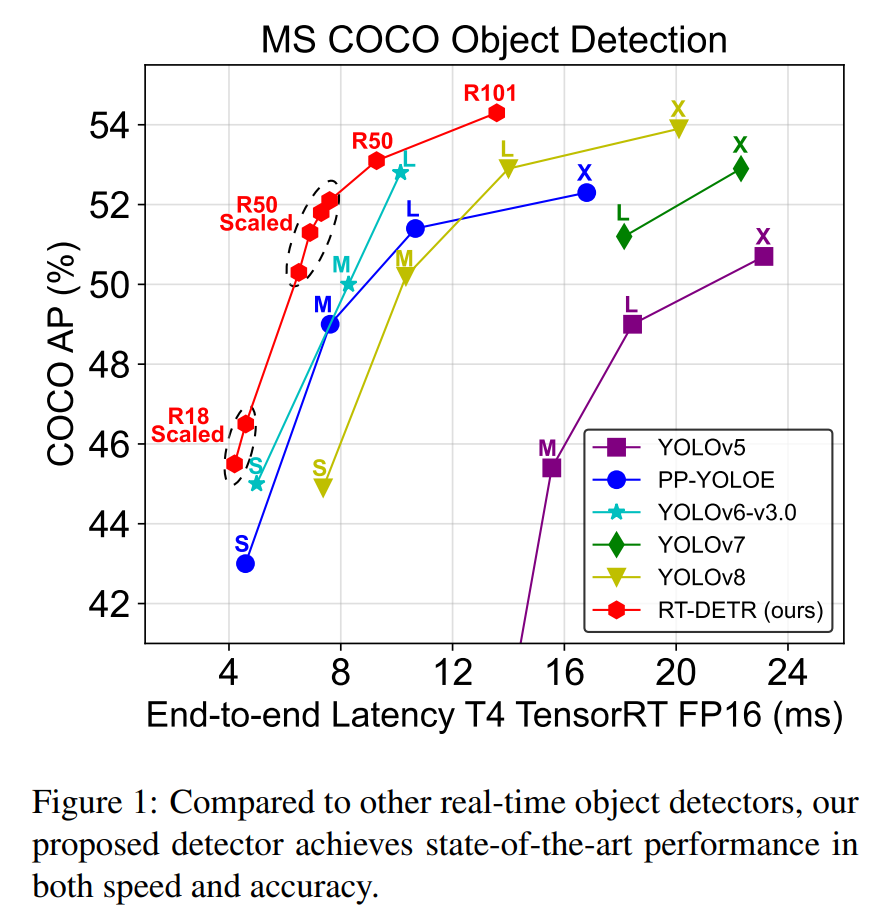
在这篇论文中,我们提出了RT-DETR,这是我们所知第一个实时端到端目标检测器。 RT-DETR不仅在准确率和速度方面优于目前最先进的实时检测器,而且不需要后处理,因此检测器的推理速度不会延迟且保持稳定,充分利用端到端检测管道的优势。 我们提出的RT-DETRL在COCO val2017上实现了53.0%的AP,在NVIDIA Tesla T4 GPU上实现了114 FPS,而RT-DETR-X实现了54.8%的AP和74 FPS,在速度和准确性方面都优于目前同规模的YOLO检测器。 因此,RT-DETR成为新的SOTA实时目标检测器,如图1所示。 此外,我们提出的RT-DETR-R50实现了53.1%的AP和108 FPS,RT-DETR-R101实现了54.3%的AP和74 FPS。 其中,RT-DETR-R50在准确性上比DINODeformable-DETR-R50高2.2%(53.1% AP vs 50.9% AP),在FPS上大约快21倍(108 FPS vs 5 FPS)。
本文的主要贡献总结如下:(i)我们提出了第一个实时端到端目标检测器,不仅在速度和准确性上超越了当前最先进的实时检测器,而且不需要后处理,因此其推理速度不会延迟且保持稳定;(ii)我们详细分析了NMS对实时检测器的影响,并从后处理角度得出关于当前实时检测器的结论;(iii)我们的工作为当前端到端检测器的实时实现提供了一个可行的解决方案,所提出的检测器可以通过使用不同的解码器层来灵活调整推理速度,而无需重新训练,这在现有的实时检测器中是难以实现的。
2. 相关研究
2.1、实时目标检测器
经过多年的持续发展,YOLO系列[29, 1, 37, 26, 17, 13, 10, 41, 18, 38, 14]已经成为实时目标检测器的代名词,它们大致可分为两类:基于锚框的[29, 1, 37, 13, 38]和无锚框的[10, 41, 18, 14]。从这些检测器的性能来看,锚框不再是限制YOLO发展的主要因素。然而,上述检测器产生了大量的冗余边界框,需要在后处理阶段利用NMS来过滤它们。不幸的是,这导致了性能瓶颈,而NMS的超参数对检测器的准确性和速度有重大影响。我们认为这与实时目标检测器的设计理念是不相容的。
2.2、端到端目标检测器
端到端目标检测器[5, 34, 39, 49, 27, 40, 24, 20, 46, 6]以其简洁的管道而闻名。Carion等人[5]首次提出基于Transformer的端到端目标检测器,称为DETR(DEtection TRansformer)。由于其独特的特点,它引起了极大的关注。特别是,DETR消除了传统检测管道中的手工设计的锚点和NMS组件。相反,它采用二部匹配并直接预测一对一的对象集。通过采用这种策略,DETR简化了检测管道并减轻了NMS引起的性能瓶颈。尽管DETR具有明显的优势,但它存在两个主要问题:训练收敛慢和查询难以优化。已经提出了许多DETR变体来解决这些问题。具体来说,Deformable-DETR [49]通过增强注意力机制的效率来加速训练收敛速度。条件DETR [27]和Anchor DETR [40]降低了查询的优化难度。DAB-DETR [24]引入了4D参考点并逐层优化预测框。DN-DETR [20]通过引入查询去噪来加速训练收敛速度。Group-DETR [6]通过引入组到多组的分配来加速训练。DINO [46]在之前的研究基础上取得了最先进的结果。尽管我们正在不断改进DETR的组件,但我们的目标不仅是进一步提高性能,而且是创建一个实时端到端目标检测器。
2.3、用于目标检测的多尺度特征
现代目标检测器已经证明了利用多尺度特征来提高性能的重要性,特别是对于小物体。FPN [22]引入了一个特征金字塔网络,该网络融合了相邻尺度的特征。后续作品[25, 11, 35, 13, 18, 38, 14]扩展和增强了这种结构,它们被广泛应用于实时目标检测器。Zhu等人[49]首次将多尺度特征引入DETR中,并提高了性能和收敛速度,但这也会导致DETR的计算成本显著增加。虽然可变形的注意力机制在一定程度上缓解了计算成本,但多尺度特征的引入仍然导致了高计算负担。为了解决这个问题,一些工作试图设计计算效率高的DETR。高效DETR [43]通过使用密集先验初始化对象查询来减少编码器和解码器的层数。稀疏DETR [32]选择性地更新预期将被解码器引用的编码令牌,从而减少计算开销。Lite DETR [19]通过以交错的方式减少低级特征的更新频率来提高编码器的效率。尽管这些研究降低了DETR的计算成本,但这些工作的目标并不是将DETR推广为实时检测器。
3、检测器的端到端速度
3.1、 NMS分析
NMS是在目标检测中广泛采用的后处理算法,用于消除检测器输出的重叠预测框。NMS需要两个超参数:分数阈值和IoU阈值。特别是,分数低于分数阈值的预测框将直接被过滤掉,每当两个预测框的IoU超过IoU阈值时,分数较低的框将被丢弃。这个过程反复执行,直到每个类别的所有框都被处理完。因此,NMS的执行时间主要取决于输入预测框的数量和两个超参数。

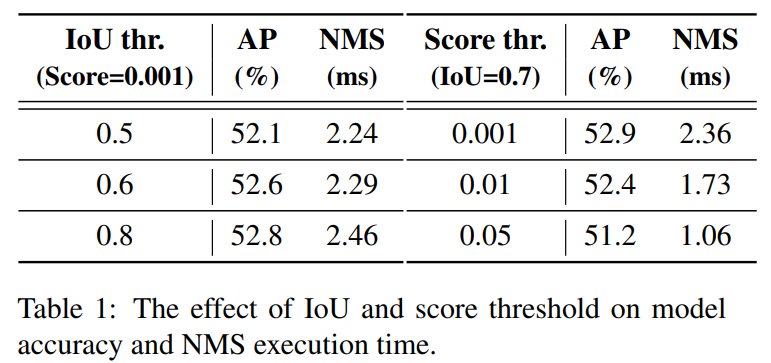
为了验证这一观点,我们利用YOLOv5(基于锚点)和YOLOv8(无锚点)进行实验。我们首先计算了经过不同分数阈值过滤后的输出框中剩余的预测框数量。我们从0.001到0.25选取了一些分数作为阈值,计算了两个检测器中剩余的预测框数量,并将其绘制成直方图,如图2所示,直观地反映了NMS对其超参数的敏感性。此外,以YOLOv8为例,我们评估了该模型在COCO val2017上的准确性,以及在不同NMS超参数下NMS操作的执行时间。请注意,我们在实验中采用的NMS后处理操作参考了TensorRT efficientNMSPlugin,该插件涉及多个CUDA内核,包括EfficientNMSFilter、RadixSort、EfficientNMS等,我们只报告了EfficientNMS内核的执行时间。我们在T4 GPU上测试了速度,上述实验中的输入图像和预处理是一致的。我们使用的超参数及其对应的结果如表1所示。
3.2、端到端速度基准测试
为了公平比较各种实时检测器的端到端推理速度,我们建立了端到端速度测试基准。考虑到NMS的执行时间可能受到输入图像的影响,有必要选择一个基准数据集并计算多个图像的平均执行时间。该基准采用COCO val2017作为默认数据集,为需要后处理的实时检测器添加TensorRT的NMS后处理插件。具体而言,我们根据基准数据集上对应的准确率的超参数测试了检测器的平均推理时间,并排除了IO和Memory-Copy操作。我们利用此基准测试在T4 GPU上测试了基于锚定的检测器YOLOv5 [13]和YOLOv7 [38],以及无锚定检测器PP-YOLOE [41],YOLOv6 [18]和YOLOv8 [14]的端到端速度。测试结果如表2所示。根据结果,我们可以得出结论,对于需要NMS后处理的实时检测器,在同等准确率下,无锚定检测器的性能优于基于锚定的检测器,因为前者比后者需要更少的时间进行后处理,而这一现象在以前的工作中被忽略了。出现这种现象的原因是,基于锚定的检测器产生的预测框数量比无锚定检测器多(在我们测试的检测器中多三倍)。
4、实时DETR
4.1、模型概述
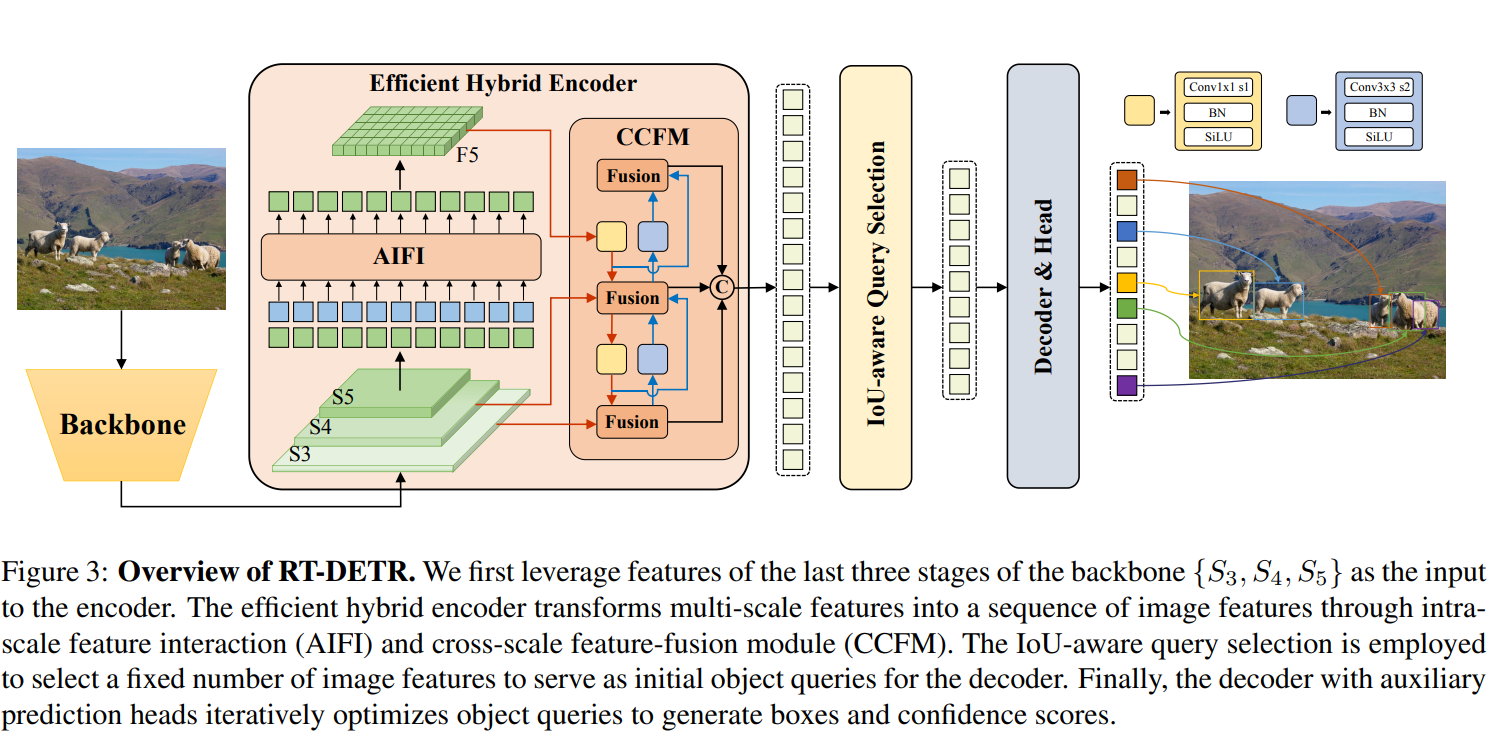
提出的RT-DETR包括一个主干网络、一个混合编码器和具有辅助预测头的变压器解码器。模型架构的概述如图3所示。具体而言,我们利用主干网络最后三个阶段{S3,S4,S5}的输出特征作为编码器的输入。混合编码器通过内部尺度交互和跨尺度融合(在4.2节中描述)将多尺度特征转化为图像特征序列。随后,采用IoU意识查询选择从编码器输出序列中选择固定数量的图像特征作为解码器的初始物体查询(在4.3节中描述)。最后,具有辅助预测头的解码器通过迭代优化物体查询来生成框和置信度分数。
4.2、高效的混合编码器
计算瓶颈分析。为了加速训练收敛和提高性能,Zhu等人[49]建议引入多尺度特征并提出了可变形注意力机制来减少计算。然而,虽然注意力机制的改进减少了计算开销,但输入序列长度的急剧增加仍然导致编码器成为计算瓶颈,阻碍了DETR的实时实现。据[21]报道,在可变形DETR [49]中,编码器占用了49%的GFLOPs,但只贡献了11%的AP。为了克服这一障碍,我们对多尺度Transformer编码器中的计算冗余进行了分析,并设计了一套变量来证明同时进行内部尺度和跨尺度特征交互的计算效率不高。
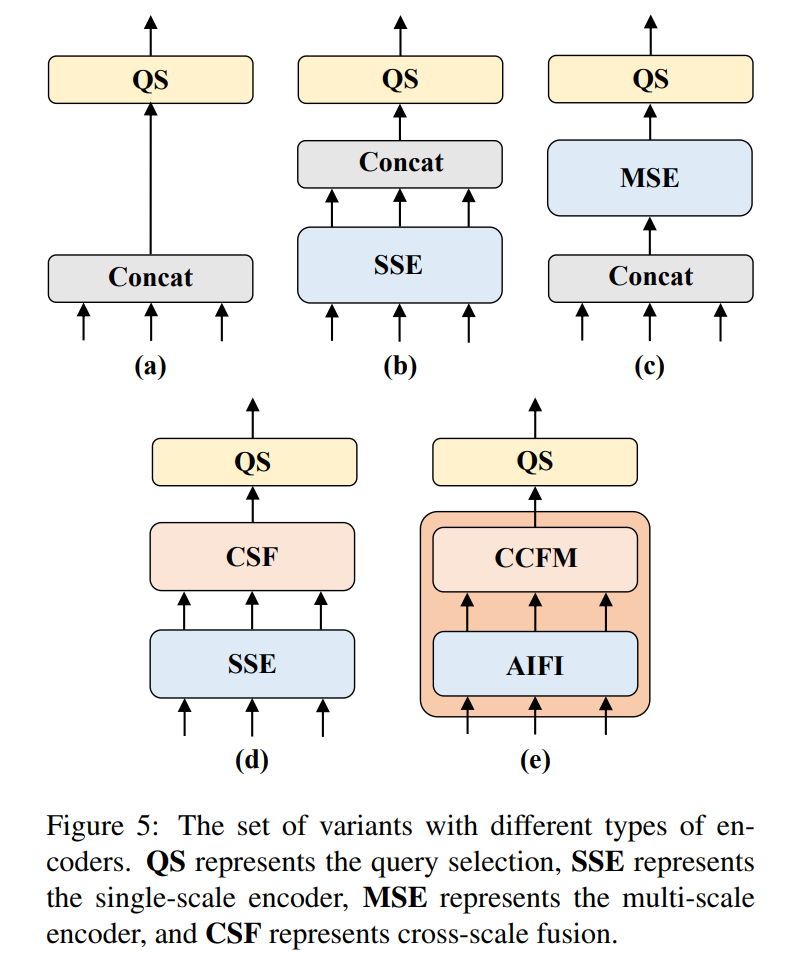
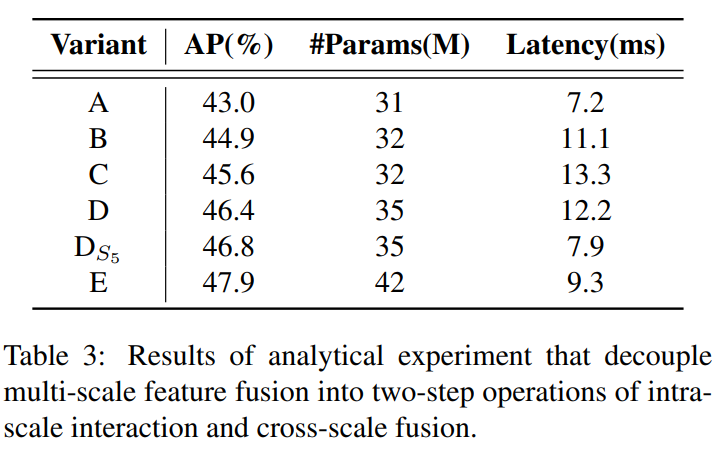
从包含图像中对象丰富语义信息的低级特征中提取高级特征。直观地说,对拼接的多尺度特征进行特征交互是多余的。为了验证这一观点,我们重新思考编码器结构,并设计了一系列具有不同编码器的变体,如图5所示。这些变体逐渐提高了模型精度,同时通过将多尺度特征交互分解为两步操作(内部尺度交互和跨尺度融合)来显著降低计算成本(详见表3)。我们首先去掉DINO-R50[46]中的多尺度Transformer编码器作为基准A。接下来,插入不同形式的编码器以在基准A的基础上产生一系列变体,详述如下:
- A → B:变体B插入单尺度变换器编码器,使用一层变换器块。每个尺度的特征共享用于内部尺度特征交互的编码器,然后将输出的多尺度特征拼接起来。
- B → C:基于B的变体C引入了跨尺度特征融合,并将拼接的多尺度特征馈送到编码器中进行特征交互。
- C → D:变体D将多尺度特征的内部尺度交互和跨尺度融合解耦。首先,使用单尺度变换器编码器执行内部尺度交互,然后使用PANet样式的结构执行跨尺度融合。
- D → E:基于D的变体E进一步优化了多尺度特征的内部尺度交互和跨尺度融合,采用了我们设计的有效混合编码器(详见下文)。
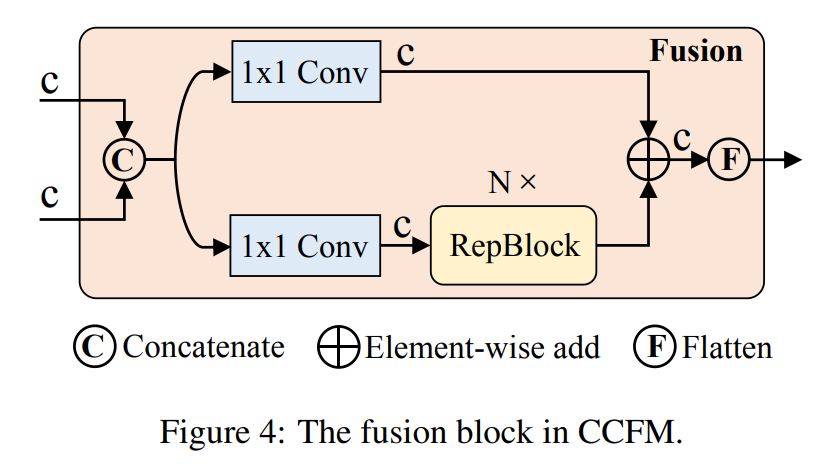
混合设计。基于上述分析,我们重新思考编码器的结构,并提出了一种新颖的有效混合编码器。如图3所示,提出的编码器由两个模块组成,即基于注意力的内部尺度特征交互模块(AIFI)和CNN的跨尺度特征融合模块(CCFM)。AIFI进一步降低了变体D中的计算冗余,该变体仅在S5上执行内部尺度交互。我们认为,将自注意力操作应用于具有更丰富语义概念的高级特征可以捕获图像中概念实体之间的连接,这有助于后续模块检测和识别图像中的对象。同时,由于缺乏语义概念和与高级特征交互的风险而存在重复和混淆的风险,因此对低级特征的内部尺度交互是不必要的。为了验证这一观点,我们在变体D中仅在S5上执行内部尺度交互,实验结果如表3所示(DS5行)。与原始变体D相比,DS5显着降低了延迟(快35%),但提高了准确性(AP高0.4%)。这一结论对于实时检测器的设计至关重要。CCFM也是基于变体D进行优化,在融合路径中插入几个由卷积层组成的融合块。融合块的作用是将相邻的特征融合成一个新的特征,其结构如图4所示。融合块包含N个RepBlock,两个路径的输出通过逐元素加法进行融合。我们可以将此过程表述如下:
Q = K = V = Flatten ( S 5 ) F 5 = Reshape ( Attn ( Q , K , V ) ) Output = CCFM ( { S 3 , S 4 , F 5 } ) (1) \begin{array}{c} \mathbf{Q}=\mathbf{K}=\mathbf{V}=\operatorname{Flatten}\left(S_{5}\right) \\ F_{5}=\operatorname{Reshape}(\operatorname{Attn}(\mathbf{Q}, \mathbf{K}, \mathbf{V})) \\ \text { Output }=\operatorname{CCFM}\left(\left\{S_{3}, S_{4}, F_{5}\right\}\right) \end{array} \tag{1} Q=K=V=Flatten(S5)F5=Reshape(Attn(Q,K,V)) Output =CCFM({S3,S4,F5})(1)
其中Attn代表多头自注意力机制,Reshape代表将特征的形状恢复为与S5相同的形状,这是Flatten的反操作。
4.3、IoU-aware查询选择
DETR中的对象查询是一组可学习的嵌入,由解码器优化并通过预测头映射到分类分数和边界框。然而,这些对象查询难以解释和优化,因为它们没有明确的物理含义。后续工作[40,24,49,43,46]改进了对象查询的初始化并扩展到内容查询和位置查询(锚点)。其中,[49, 43, 46]都提出了查询选择方案,它们的共同点是利用分类分数从编码器中选择前K个特征来初始化对象查询(或仅位置查询[46])。然而,由于分类分数和位置置信度的不一致分布,一些预测框具有高分类分数但与GT框不接近,导致选择具有高分类分数和低IoU得分的框,而丢弃具有低分类分数和高IoU得分的框。这损害了检测器的性能。为了解决这个问题,我们提出了一种IoU-aware查询选择方法,通过在训练期间约束模型对于高IoU得分的特征产生高分类分数,对于低IoU得分的特征产生低分类分数。因此,根据模型选择的分类分数前K个编码器特征对应的预测框具有高分类分数和高IoU得分。我们将检测器的优化目标重写为:
L ( y ^ , y ) = L b o x ( b ^ , b ) + L c l s ( c ^ , b ^ , y , b ) = L b o x ( b ^ , b ) + L c l s ( c ^ , c , I o U ) (2) \begin{aligned} \mathcal{L}(\hat{y}, y) & =\mathcal{L}_{b o x}(\hat{b}, b)+\mathcal{L}_{c l s}(\hat{c}, \hat{b}, y, b) \\ & =\mathcal{L}_{b o x}(\hat{b}, b)+\mathcal{L}_{c l s}(\hat{c}, c, I o U) \end{aligned} \tag{2} L(y^,y)=Lbox(b^,b)+Lcls(c^,b^,y,b)=Lbox(b^,b)+Lcls(c^,c,IoU)(2)
其中 y ^ \hat{y} y^ 和 y 分别表示预测值和真实值, y ^ = { c ^ , b ^ } \hat{y}= \{\hat{c}, \hat{b}\} y^={c^,b^} 和 y = { c , b } y=\{c, b\} y={c,b},c 和 b 分别表示类别和边界框。我们将IoU分数引入分类分支的目标函数中(类似于VFL [47]),以实现正样本分类和定位的一致性约束。
有效性分析。为了分析所提出的IoU意识查询选择的有效性,我们在val2017上可视化了通过查询选择选择的编码器特征的分类分数和IoU分数,如图6所示。具体而言,我们首先根据分类分数选择前K个(实验中K=300)编码器特征,然后可视化分类分数大于0.5的散点图。红色和蓝色点是通过应用普通查询选择和IoU意识查询选择训练的模型计算得出的。点越接近图的上右方,相应特征的质量越高,即分类标签和边界框更有可能描述图像中的真实对象。根据可视化结果,我们发现最显著的特征是大量的蓝色点集中在图的右上侧,而红色点集中在右下侧。这表明使用IoU意识查询选择训练的模型可以产生更多高质量的编码器特征。
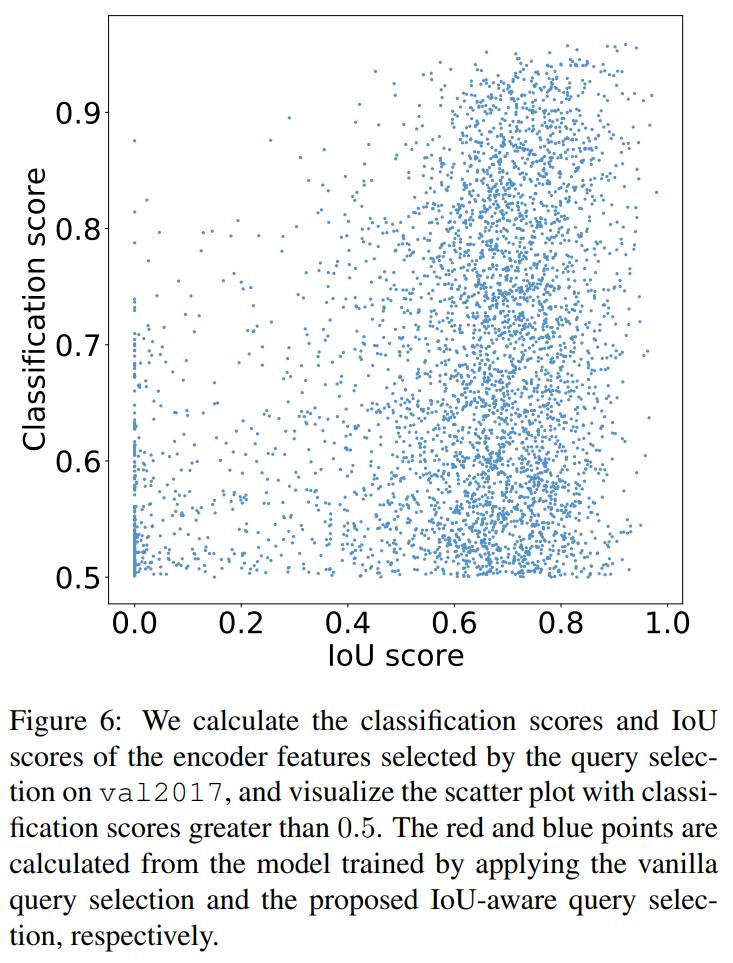
此外,我们还定量分析了这两类点的分布特征。在图中,蓝色点的数量比红色点多出138%,也就是说,红色点中有更多的分类分数小于或等于0.5的低质量特征。然后,我们分析了分类分数大于0.5的特性的IoU分数,我们发现IoU分数大于0.5的蓝色点比红色点多出120%。定量结果进一步证明,IoU-aware查询选择能为对象查询提供更多具有精确分类(高分类分数)和精确定位(高IoU分数)的编码器特征,从而提高检测器的精度。详细的定量结果将在第5.4节中介绍。
4.4、RT-DETR的缩放
为了提供RT-DETR的缩放版本,我们将ResNet [16]后端替换为HGNetv2。我们使用深度乘数和宽度乘数将后端和混合编码器一起缩放。因此,我们得到两个版本的RT-DETR,具有不同的参数数量和FPS。对于我们的混合编码器,我们通过调整CCFM中的RepBlocks数量和编码器的嵌入维度来控制深度乘数和宽度乘数。值得注意的是,我们提出的不同规模的RT-DETR保持了同构解码器,这有利于使用高精度大型DETR模型对轻量级检测器进行蒸馏[7, 31, 46, 50, 3, 42]。这将是一个可探索的未来方向。
5、实验
5.1、设置
数据集。我们在Microsoft COCO数据集上进行实验。我们在COCO train2017上进行训练,并在COCO val2017上进行验证。我们使用标准COCO AP度量,以单尺度图像作为输入。
实现细节。我们使用在ImageNet [33]上预训练的ResNet [15,16]和HGNetv2系列作为我们的主干网络,使用SSLD [8]从PaddleClas 。AIFI包含1个Transformer层,CCMF中的融合块默认包含3个RepBlocks作为基本模型。在IoU-aware查询选择中,我们选择前300个编码器特征来初始化解码器的对象查询。解码器的训练策略和超参数几乎遵循DINO [46]。我们使用AdamW优化器训练我们的检测器,基本学习率=0.0001,权重衰减=0.0001,全局梯度剪切范数=0.1,线性预热步数=2000。主干网络的学习率设置遵循[5]。我们还使用指数移动平均(EMA), ema_decay=0.9999。 1×配置意味着总时期为12个时期,除非特别说明,否则所有消融实验都使用1×配置。报告的最终结果使用6×配置。数据增强包括随机{色彩失真、扩展、裁剪、翻转、调整大小}操作,遵循[41]。
5.2、与SOTA方法比较
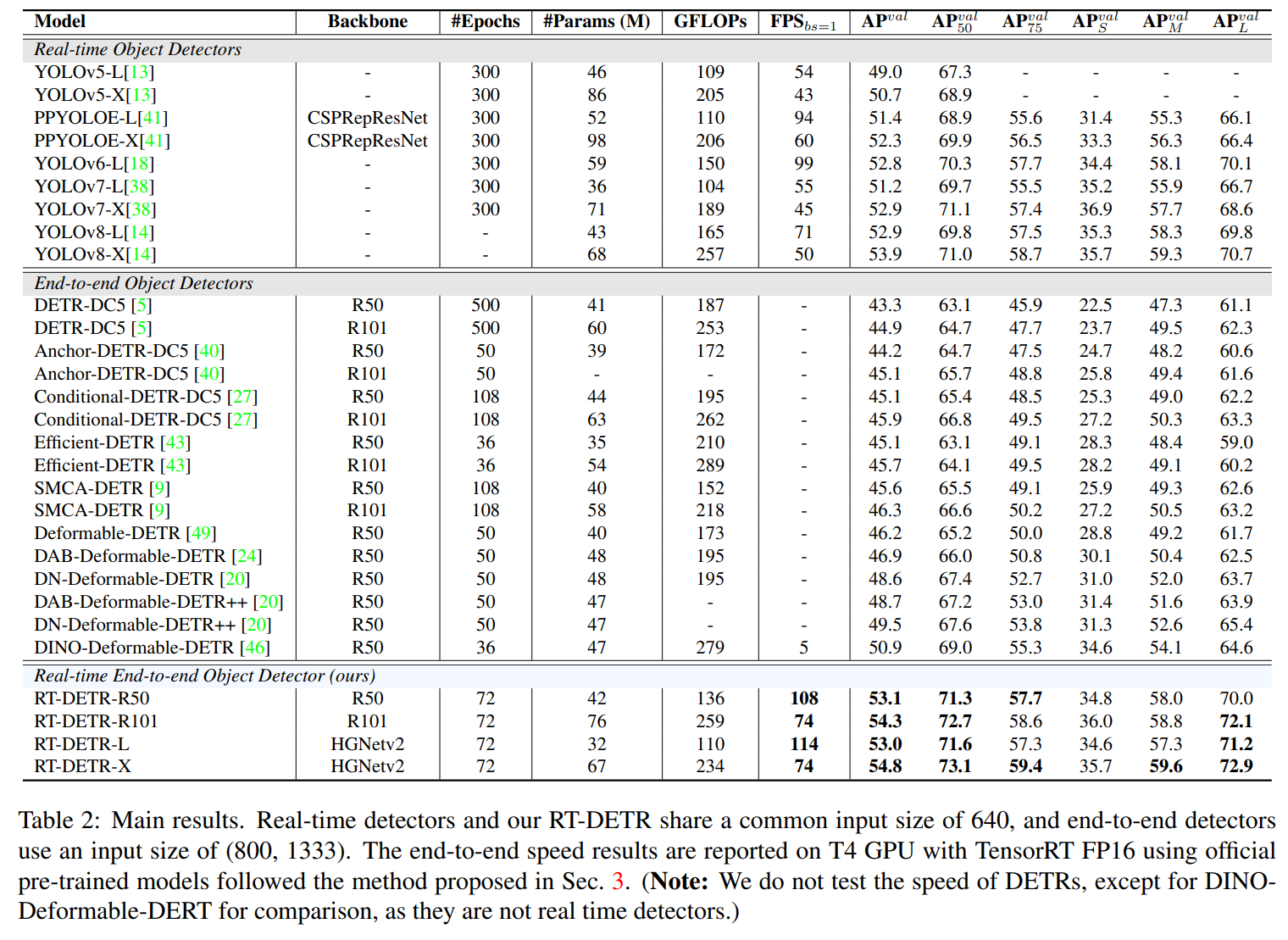
表2比较了提出的RT-DETR与其他实时且端到端的物体检测器。我们提出的RT-DETR-L达到53.0%AP和114 FPS,而RTDETR-X达到54.8%AP和74 FPS,在速度和精度上都优于同规模的当前最先进的YOLO检测器。此外,我们提出的RT-DETR-R50达到53.1%AP和108 FPS,而RT-DETR-R101达到54.3%AP和74 FPS,在速度和精度上都优于相同后端的当前最先进的端到端检测器。
与实时检测器相比,为了进行公平比较,我们将缩放RT-DETR的速度和准确性在与当前端到端实时检测器进行比较(速度测试方法参考第3.2节)。我们将缩放的RT-DETR与YOLOv5 [13]、PP-YOLOE [41]、YOLOv6v3.0(以下称为YOLOv6) [18]、YOLOv7 [38]和YOLOv8 [14]进行了比较。与YOLOv5-L / PP-YOLOE-L / YOLOv7-L相比,RT-DETR-L在准确性上显著提高了4.0%/1.6%/1.8%AP,在FPS上提高了111.1%/21.3%/107.3%,并且减少了30.4%/38.5%/11.1%的参数数量。与YOLOv5-X / PP-YOLOE-X / YOLOv7-X相比,RTDETR-X在准确性上提高了4.1%/2.5%/1.9%AP,在FPS上提高了72.1%/23.3%/64.4%,并且减少了22.1%/31.6%/5.6%的参数数量。与YOLOv6-L / YOLOv8-L相比,RT-DETR-L在准确性上提高了0.2%/0.1%AP,在速度上提高了15.2%/60.6%,并且减少了45.8%/25.6%的参数数量。与YOLOv8-X相比,RT-DETR-X在准确性上提高了0.9%AP,在速度上提高了48.0%,并且减少了1.5%的参数数量。
与端到端检测器比较。为了进行公平比较,我们只比较使用相同骨干网络的基于变压器的端到端检测器。考虑到当前的端到端检测器不是实时的,我们没有在T4 GPU上测试它们的速度,但为了比较,我们测试了DINO-DeformableDERT [46]的速度。我们根据在val2017上采取的相应准确度设置来测试检测器的速度,即使用TensorRT FP16测试DINO-Deformable-DETR,输入大小为(800,1333)。表2显示RT-DETR优于具有相同骨干网络的当前最先进的端到端检测器。与DINO-Deformable-DETR-R50 [46]相比,RT-DETR-R50在准确性上显著提高了2.2%AP(53.1%AP vs 50.9%AP),速度提高了21倍(108 FPS vs 5 FPS),并且减少了10.6%的参数数量。与SMCA-DETR-R101 [9]相比RT-DETR-R101显着提高了8.0%AP的准确性。
5.3、混合编码器的消融研究
为了验证我们对编码器的分析的正确性,我们评估了第4.2节中设计的变体集的指标,包括AP、参数数量和延迟。实验结果如表3所示。变体B提高了1.9%AP的准确性,但增加了54%的延迟。这证明内部尺度特征交互是重要的,但是普通的Transformer编码器计算成本很高。变体C相对于B提高了0.7%AP,但增加了20%的延迟。这表明跨尺度特征融合也是必要的。变体D相对于C提高了0.8%AP,但减少了8%的延迟。这表明解耦内部尺度交互和跨尺度融合可以减少计算,同时提高准确性。与变体D相比,D_S5减少了35%的延迟,但提高了0.4%AP。这表明不需要低级特征的内部尺度交互。最后,配备了我们提出的混合编码器的变体E相对于D提高了1.5%AP。尽管参数数量增加了20%,但延迟减少了24%,使编码器更高效。
5.4、IoU-aware查询选择的消融研究
我们对IoU-aware查询选择进行了消融研究,定量实验结果如表4所示。我们采用的查询选择方法根据分类得分选择前K个(K=300)编码器特征作为内容查询,并使用这些选定特征的边界框作为初始位置查询。我们在val2017上比较了两种查询选择所选的编码器特征,并计算了分类得分大于0.5和两者都大于0.5的比例,分别对应于“Prop_{cls}”和“Prop_{both}”列。结果表明,使用IoU-aware查询选择所选的编码器特征不仅增加了高分类得分(0.82%vs 0.35%),而且还提供了更多具有高分类得分和高IoU得分的特征(0.67%vs 0.30%)。我们还评估了使用这两种查询选择训练的检测器在val2017上的准确性,其中IoU-aware查询选择提高了0.8%AP(48.7%AP vs 47.9%AP)。
5.5、解码器消融研究
表5显示了RT-DETR不同解码器层数的每个解码器层的准确性和速度。当解码器层数为6时,检测器的准确率最高,为53.1%AP。我们还分析了每个解码器层对推理速度的影响,并得出结论,每个解码器层消耗约0.5ms。此外,我们发现随着解码器层数的增加,相邻层之间的准确率差异逐渐减小。以6层解码器为例,使用5层进行推理仅损失0.1%AP(53.1%AP vs 53.0%AP),同时将延迟减少了0.5ms(9.3ms vs 8.8ms)。因此,RT-DETR支持在不重新训练推理的情况下通过使用不同数量的解码器层来灵活调整推理速度,这为实时检测器的实际应用提供了便利。
6、结论
在本文中,我们提出了RT-DETR,据我们所知,这是第一个实时端到端的目标检测器。我们首先对NMS进行了详细的分析,并建立了一个端到端的推理速度基准,以验证当前实时检测器的推理速度因NMS而延迟的事实。从NMS的分析中我们还得出结论,与基于锚的检测器相比,无锚检测器具有相同的准确性。为了避免NMS引起的延迟,我们设计了一种包含两个关键改进组件的实时端到端检测器:一种能够有效地处理多尺度特征的混合编码器,以及一种能够改善对象查询初始化的IoU-aware查询选择。大量的实验表明,RT-DETR在速度和准确性方面与其他类似大小的实时检测器和端到端检测器相比达到了最先进水平。此外,我们提出的检测器支持通过使用不同的解码器层来灵活调整推理速度,而无需重新训练,这为实时目标检测器的实际应用提供了便利。我们希望这项工作能够付诸实践,并为研究人员提供启示。
相关文章:
RT-DERT:在实时目标检测上,DETRs打败了yolo
文章目录 摘要1、简介2. 相关研究2.1、实时目标检测器2.2、端到端目标检测器2.3、用于目标检测的多尺度特征 3、检测器的端到端速度3.1、 NMS分析3.2、端到端速度基准测试 4、实时DETR4.1、模型概述4.2、高效的混合编码器4.3、IoU-aware查询选择4.4、RT-DETR的缩放 5、实验5.1、…...

uniapp/H5富文本复制文本功能
代码实现: copy() {let replacedContent this.form.resTaskBaseInfoDetail.content;let text readHtml(replacedContent)// #ifdef H5let textarea document.createElement("textarea")textarea.value texttextarea.readOnly "readOnly"d…...

通付盾Web3专题 | 智能账户:数字时代基础单元
2008年10月31日,中本聪(Satoshi Nakamoto)在P2P foundation 网站发布比特币白皮书《比特币:一种点对点的电子现金系统》。转眼距比特币白皮书发布已过去15年。2009年1月比特币网络正式推出,当时每个比特币的价格仅为0.…...
java网上阅读网站系统eclipse定制开发mysql数据库BS模式java编程jdbc
一、源码特点 JSP 网上阅读网站系统是一套完善的web设计系统,对理解JSP java SSM框架 mvc编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为 TOMCAT7.0,eclipse开发,数据库为Mysql5.0&a…...

人工智能基础_机器学习007_高斯分布_概率计算_最小二乘法推导_得出损失函数---人工智能工作笔记0047
这个不分也是挺难的,但是之前有详细的,解释了,之前的文章中有, 那么这里会简单提一下,然后,继续向下学习 首先我们要知道高斯分布,也就是,正太分布, 这个可以预测x在多少的时候,概率最大 要知道在概率分布这个,高斯分布公式中,u代表平均值,然后西格玛代表标准差,知道了 这两个…...
开源播放器GSYVideoPlayer的简单介绍及播放rtsp流的优化
开源播放器GSYVideoPlayer的简单介绍及播放rtsp流的优化 前言一、GSYVideoPlayer🔥🔥🔥是什么?二、简单使用1.First、在project下的build.gradle添加2.按需导入3. 常用代码 rtsp流的优化大功告成 总结 前言 本文介绍,…...
安卓手机数据恢复工具 DiskDigger Pro 中文版-适用于已获得 root 权限的设备!可以从您的存储卡或内存恢复数据
可以从您的存储卡或内存中取消删除和恢复丢失的照片、文档、视频、音乐等。 无论您是不小心删除了文件,还是重新格式化了存储卡,DiskDigger 强大的数据恢复功能都可以找到您丢失的文件并让您恢复它们。 注意:如果您的设备未获得 root 权限&a…...
Python 生成Android不同尺寸的图标
源代码 # -*- coding: utf-8 -*- import sys import os import shutil from PIL import Imagedef generateAndroidIcons():imageSource icon.pngicon Image.open(imageSource)sizes [(android/drawable,512),(android/drawable-hdpi,72),(android/drawable-ldpi,36),(andro…...

PHP使用GuzzleHttp进行HTTP请求
1,composer安装 composer require guzzlehttp/guzzle:~7.0 2,设置过期时间和跳过ssl验证 use GuzzleHttp\Client;$clientnew Client([timeout > 5, verify > false]);2,get请求 use GuzzleHttp\Client;$clientnew Client([timeout > 5, verif…...

pytorch笔记:allclose,isclose,eq,equal
1 allclose 1.1介绍 torch.allclose是一个PyTorch函数,用于检查两个张量是否在某个容忍度范围内近似相等 torch.allclose(input, other, rtol1e-05, atol1e-08, equal_nanFalse)input (Tensor) – 第一个输入张量other (Tensor) – 第二个输入张量rtol (float) –…...

YoloV8修改检测框为中心点
代码实现参考: https://github.com/computervisioneng/train-yolov8-custom-dataset-step-by-step-guide/blob/master/local_env/predict_video.py from ultralytics import YOLO from PIL import Image import cv2 import numpy as npmodel YOLO("/home/ps…...
文言一心中将C语言归类为低级语言,这对么?
文言一心中将C语言归类为低级语言,这对么? 以下是文言一心中的回答:C语言属于低级语言。低级语言通常指的是接近于机器语言的编程语言,它们与计算机硬件的交互更加直接,能够更高效地利用计算机资源。最近很多小伙伴找我ÿ…...
[补题记录] Codeforces Round 906 (Div. 2)(A~D)
URL:https://codeforces.com/contest/1890 目录 A Problem/题意 Thought/思路 Code/代码 B Problem/题意 Thought/思路 Code/代码 C Problem/题意 Thought/思路 Code/代码 D Problem/题意 Thought/思路 Code/代码 A Problem/题意 给出一个数组 A…...

Kubernetes yaml文件
目录 yaml文件 Pod yaml文件详解 deployment.yaml文件详解 Service yaml文件详解 文件 Kubernetes 支持 YAML 和 JSON 格式管理资源对象 JSON 格式:主要用于 api 接口之间消息的传递 YAML 格式:用于配置和管理,YAML 是一种简洁的非标记性…...
Linux——切换CUDA版本
一、查看本地cuda版本 cd /usr/local/ ls当前cuda为软连接,指向指定的cuda版本 stat cuda # 查看当前cuda状态信息二、切换CUDA版本 # 删除原有软连接 sudo rm -rf /usr/local/cuda # 建立需要切换的cuda软连接版本 sudo ln -s /usr/local/cuda-**.* /usr/l…...

利用云计算和微服务架构开发可扩展的同城外卖APP
如今,同城外卖APP已经成为了人们点餐的主要方式之一。然而,要构建一款成功的同城外卖APP,不仅需要满足用户的需求,还需要具备可扩展性,以适应快速增长的用户和订单量。 一、了解同城外卖APP的需求 在着手开发同城外卖…...
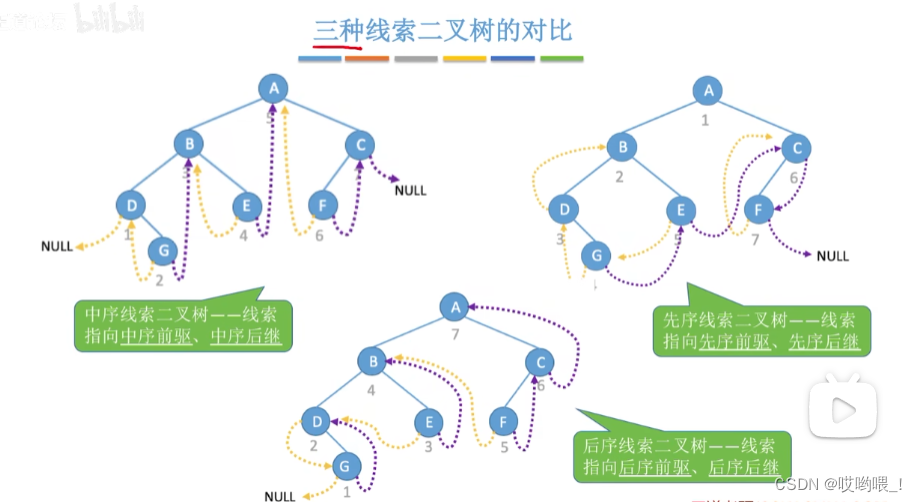
数据结构详细笔记——二叉树
文章目录 二叉树的定义和基本术语特殊的二叉树满二叉树完全二叉树二叉排序树平衡二叉树 二叉树的常考性质完全二叉树的常考性质二叉树的存储结构顺序存储链式存储 二叉树的先中后序遍历先序遍历(空间复杂度:O(h))中序遍…...
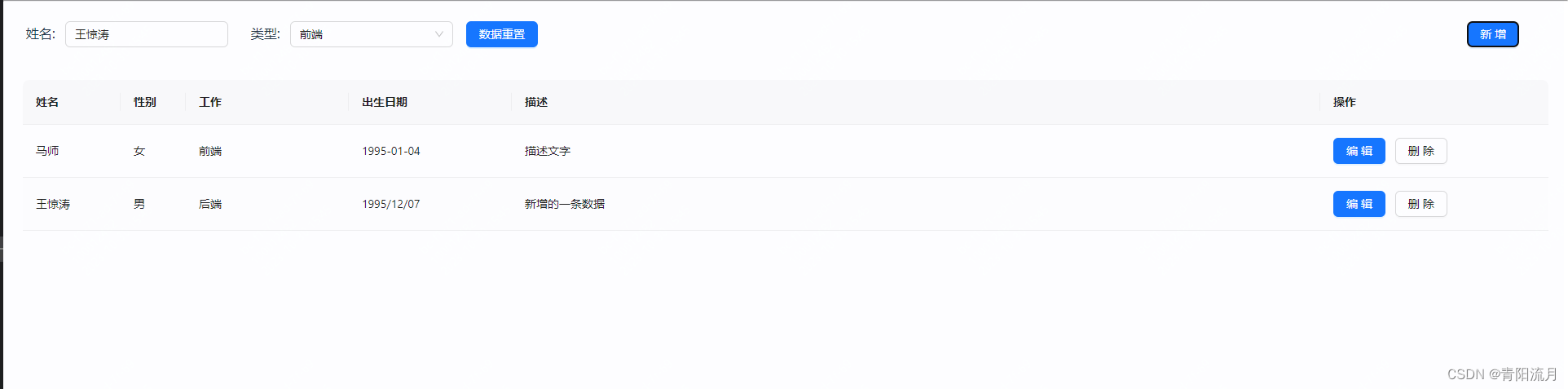
react实现列表增删改查的小demo(class组件版)
前言 react的语法上就是比vue麻烦不少,既然要开手动挡,那就开吧,一个基础的demo 效果图 列表 新增弹窗 编辑弹框 新增一条数据后的效果 代码 根组件 index.jsx import React, { Component,createRef} from react import withRouter from ../../utils/withRouter import G…...
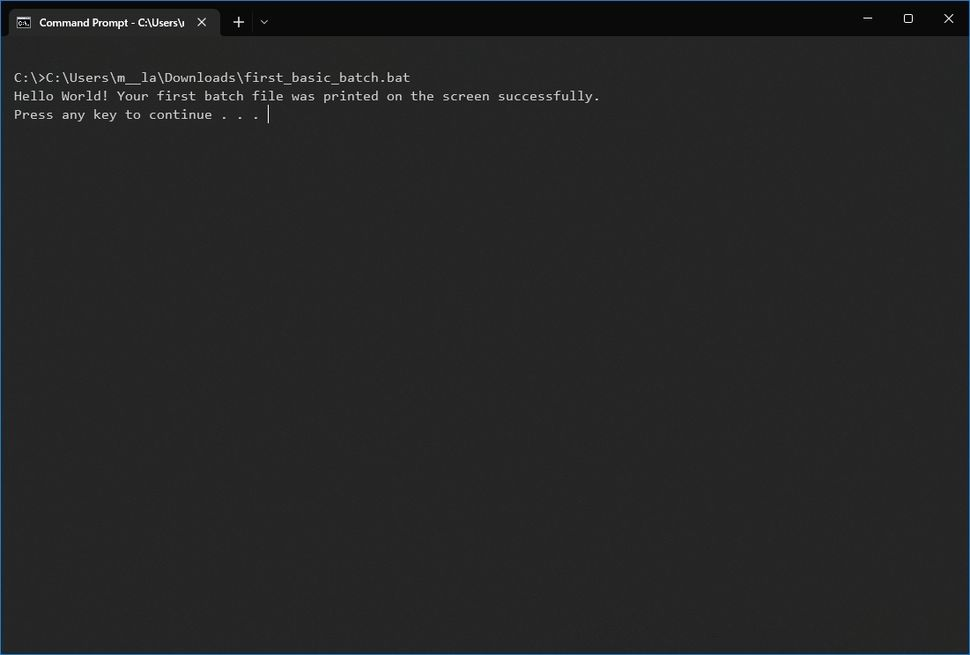
运行批处理文件,Windows 10至少提供了三种方法,有的可以设置定时运行
Windows 10至少有三种写入批处理文件的方法。你可以使用命令提示符或文件资源管理器按需运行它们。你可以使用任务计划程序配置脚本,以便按计划运行。或者,你可以将批处理文件保存在“启动”文件夹中,让系统在你登录帐户后立即运行它们。 如果要按需运行脚本,可以使用文件…...

C++ detach线程的归属权和控制权交给runtime library的原因
在C中,std::thread的detach操作将线程的归属权和控制权都转移给了C运行时库(runtime library)。这是因为detach操作的目的是告诉C运行时库,你不再关心这个线程的状态,它可以在后台独立运行,而不需要等待主线…...

初步认识假设检验
下面内容摘录自《用R探索医药数据科学》专栏文章的部分内容(原文6102字) 2篇3章3节:从案例中认识假设检验_认识参数假设检验-CSDN博客 假设检验是统计学中一种用于判断数据是否支持某一特定假设的常用方法。在数据分析中,假设检验…...

终极突破指南:三步解锁原神PC版帧率限制,让你的显卡火力全开
终极突破指南:三步解锁原神PC版帧率限制,让你的显卡火力全开 【免费下载链接】genshin-fps-unlock unlocks the 60 fps cap 项目地址: https://gitcode.com/gh_mirrors/ge/genshin-fps-unlock 你是否曾经在提瓦特大陆上驰骋时,感觉自己…...

Windows虚拟机完美运行macOS:OSX-Hyper-V终极实践指南
Windows虚拟机完美运行macOS:OSX-Hyper-V终极实践指南 【免费下载链接】OSX-Hyper-V OpenCore configuration for running macOS on Windows Hyper-V. 项目地址: https://gitcode.com/gh_mirrors/os/OSX-Hyper-V 你是否曾经梦想在一台Windows电脑上同时拥有m…...

taotoken token plan套餐详解如何节省大模型调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken Token Plan 套餐详解:如何节省大模型调用成本 对于频繁使用大模型 API 的企业开发者或个人用户而言ÿ…...

终极指南:如何在3DS上原生运行GBA游戏,告别模拟器卡顿
终极指南:如何在3DS上原生运行GBA游戏,告别模拟器卡顿 【免费下载链接】open_agb_firm open_agb_firm is a bare metal app for running GBA homebrew/games using the 3DS builtin GBA hardware. 项目地址: https://gitcode.com/gh_mirrors/op/open_a…...

OpenRocket:开源火箭设计与飞行仿真的终极指南
OpenRocket:开源火箭设计与飞行仿真的终极指南 【免费下载链接】openrocket Model-rocketry aerodynamics and trajectory simulation software 项目地址: https://gitcode.com/GitHub_Trending/op/openrocket 你是否曾经梦想设计自己的火箭,但又…...

手把手教你用Wireshark抓包分析:一个Easymesh设备到底是怎么‘发现’并‘加入’你家网络的?
用Wireshark解密Easymesh组网:从设备发现到网络接入的全流程解析 当你在客厅新添置了一台支持Easymesh的路由器,通电后它就像有自主意识般自动加入了现有的家庭网络——这种看似"魔法"般的体验背后,其实是一系列精密的协议交互在发…...

3分钟掌握md2pdf:离线Markdown转PDF的终极指南
3分钟掌握md2pdf:离线Markdown转PDF的终极指南 【免费下载链接】md2pdf Offline markdown to pdf, choose -> edit -> transform 🥂 项目地址: https://gitcode.com/gh_mirrors/md/md2pdf 你是否经常需要将Markdown文档转换为PDF格式&#…...

如何5分钟掌握SD-PPP:Photoshop AI插件完整入门指南
如何5分钟掌握SD-PPP:Photoshop AI插件完整入门指南 【免费下载链接】sd-ppp A Photoshop AI plugin 项目地址: https://gitcode.com/gh_mirrors/sd/sd-ppp SD-PPP是一款革命性的Photoshop AI插件,它将强大的AI绘图能力无缝集成到Adobe Photoshop…...

谷歌 AI Studio 一下午开发三款应用,游戏体验却差强人意?
谷歌 AI Studio 助力开发应用 昨天,我开发出了自己的第一款 Android 应用程序,紧接着又做了两个,一个下午就完成了三款应用。其中一款应用,我在网页浏览器里输入 148 个单词后,十分钟后手机上就有了新应用。开启手机 U…...