【python与数据结构】(leetcode算法预备知识)
笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~
python与数据结构
- Python 中常见的数据类型
- 数据结构
- 1.数组(Array)
- 2.链表(Linked List)
- 3.哈希表(Hash Table)
- 4.队列(Queue)
- list
- deque(类似双端队列)
- 5.栈(Stack)
- list
- deque
- 6.堆(Heep)
- 7.树(Tree)
- 数据类型常见操作
- 1.数字类型
- 2.布尔类型
- 3.字符串类型
- 4.列表类型
- 5.元组类型
- 6.集合类型
- 7.字典类型
Python 中常见的数据类型
1.数字类型:
- 整数(int):表示整数值,例如 1、-5、100。
- 浮点数(float):表示带有小数部分的数字,例如 3.14、-0.5、2.0。
- 复数(complex):表示实部和虚部的复数,例如 2+3j。
2.布尔类型(bool):
- 表示真(True)或假(False)的逻辑值。
3.字符串类型(str):
- 表示文本数据,使用单引号或双引号括起来,例如 ‘Hello’、“World”。
4.列表类型(list):
- 表示有序的可变序列,可以包含不同类型的元素,使用方括号括起来,例如 [1, 2, ‘a’, True]。
5.元组类型(tuple):
- 类似于列表,但是不可变,使用圆括号括起来,例如 (1, 2, ‘a’, True)。
6.集合类型(set):
- 表示无序且唯一的元素集合,使用花括号括起来,例如 {1, 2, 3}。
7.字典类型(dict):
- 表示键值对的映射关系,使用花括号括起来,例如 {‘name’: ‘Alice’, ‘age’: 25}。
数据结构
1.数组(Array)
列表类型(list)
2.链表(Linked List)

class ListNode:def __init__(self,x):self.val = xself.next = None
3.哈希表(Hash Table)
字典类型(dict)
4.队列(Queue)

list
进队:append()
出队:pop(0)
l = [1,2,3,4,5]l.append(6)
l
#[1, 2, 3, 4, 5, 6]l.pop(0)
l
#[2, 3, 4, 5, 6]
deque(类似双端队列)
deque 是 Python 中的一个内置模块 collections 中的类,用于实现双端队列(double-ended queue)。双端队列是一种具有队列和栈特性的数据结构,支持在两端进行插入和删除操作。
deque 提供了以下常用操作:
- 创建双端队列:
- 使用
deque()函数创建一个空的双端队列。 - 例如:
from collections import deque,d = deque()。
- 使用
- 在队列两端插入元素:
- 使用
append(item)在队列的右端插入一个元素。 - 使用
appendleft(item)在队列的左端插入一个元素。 - 例如:
d.append(1),d.appendleft(2)。
- 使用
- 在队列两端删除元素:
- 使用
pop()删除并返回队列右端的元素。 - 使用
popleft()删除并返回队列左端的元素。 - 例如:
d.pop(),d.popleft()。
- 使用
- 访问队列两端的元素:
- 使用
[-1]索引访问队列右端的元素。 - 使用
[0]索引访问队列左端的元素。 - 例如:
d[-1],d[0]。
- 使用
- 获取队列长度:
- 使用
len(d)获取队列中的元素个数。
- 使用
- 判断队列是否为空:
- 使用
not d或len(d) == 0判断队列是否为空。
- 使用
deque 还支持其他一些方法,如旋转队列、计数元素出现次数、反转队列等。双端队列在实际应用中常用于需要高效地在两端进行插入和删除操作的场景,比如实现缓存、任务调度等。
右进:append()
右出:pop()
左进:appendleft()
左出:popleft()
from collections import deque
q = deque([1,2,3])q.append(4)
q
#deque([1, 2, 3, 4])q.pop()
q
#deque([1, 2, 3])q.appendleft(4)
q
#deque([4, 1, 2, 3])q.popleft()
q
#deque([1, 2, 3])
使用:先进后出
#使用方法1:队头<--- 队列 <---队尾
#append() 队尾
#popleft() 队头from collections import deque
q = deque([1,2,3])q.append(4)
q
#deque([1, 2, 3, 4])q.popleft()
q
#deque([2, 3, 4])
#使用方法2:队尾---> 队列 --->队头
#appendleft() 队尾
#pop() 队头from collections import deque
q = deque([1,2,3])q.appendleft(4)
q
#deque([4, 1, 2, 3])q.pop()
q
#deque([4, 1, 2])
5.栈(Stack)

list
进栈:append()
出栈:pop()
l = [1,2,3,4,5]l.append(6)
l
#[1, 2, 3, 4, 5, 6]l.pop()
l
#[1, 2, 3, 4, 5]
deque
右进:append()
右出:pop()
左进:appendleft()
左出:popleft()
使用:先进先出,后进后出
6.堆(Heep)

heapq 是 Python 中的一个内置模块,提供了堆(heap)算法的实现。堆是一种特殊的树形数据结构,满足以下性质:
- 堆是一棵完全二叉树;
- 堆中的每个节点都必须大于等于(或小于等于)其子节点。
Python 中的 heapq 模块提供了以下常用函数:
heapify(iterable):- 将一个可迭代对象转化为堆,时间复杂度为O*(*n)。
- 例如:
heapq.heapify([3, 1, 4, 1, 5, 9])。
heappush(heap, item):- 将一个元素加入堆中,时间复杂度为 O(logn)。
- 例如:
heapq.heappush([3, 1, 4, 1, 5, 9], 2)。
heappop(heap):- 弹出堆中最小的元素,时间复杂度为 O(logn)。
- 例如:
heapq.heappop([1, 1, 3, 4, 5, 9])。
heapreplace(heap, item):- 弹出堆中最小的元素,并将新元素加入堆中,时间复杂度为 O*(*logn)。
- 例如:
heapq.heapreplace([1, 1, 3, 4, 5, 9], 2)。
nlargest(n, iterable[, key]):- 返回可迭代对象中最大的 n 个元素,时间复杂度为 O*(*nlogk),其中 k=min(n,len(iterable))。
- 例如:
heapq.nlargest(3, [1, 2, 3, 4, 5, 6, 7, 8, 9])。
nsmallest(n, iterable[, key]):- 返回可迭代对象中最小的 n 个元素,时间复杂度为 O*(*nlogk),其中 k=min(n,len(iterable))。
- 例如:
heapq.nsmallest(3, [9, 8, 7, 6, 5, 4, 3, 2, 1])。
heapq 模块可以用于实现堆排序、优先队列等算法,同时也可以用于解决一些常见的算法问题,如求 top-k 问题、求中位数等。在使用 heapq 模块时,需要注意元素的比较方式,可以通过传递 key 参数来指定比较函数。
from heapq import * a = [1,2,3,4,5]
heapify(a)
a
#[1, 2, 3, 4, 5]heappush(a,-1)
a
#[-1, 2, 1, 4, 5, 3]heappop(a)
a
#[1, 2, 3, 4, 5]nlargest(3,a)
#[5, 4, 3]nsmallest(3,a)
#[1, 2, 3]
7.树(Tree)

数据类型常见操作
1.数字类型
- abs():绝对值
- max()/min():最大值/最小值
- pow(x,y):xy
- sqrt(x):根号x
abs(-5)
#5max(1,3,6)
#6min(1,-1,4)
#-1pow(3,3)
#27import math
math.sqrt(9)
#3.0
2.布尔类型
bool(0)
#Falsebool(2)
#Truebool(-1)
#True
3.字符串类型
- len(s):字符串长度,空格也算
- max(s):最大字符
- max(s):最小字符
- s.count(‘H’):统计H的个数
- s.isupper():是否为大写
- s.islower():是否为小写
- s.isdigit():是否为数字
- s.lower():转换为小写
- s.upper():转换为大写
- s.swapcase():大小写转换
- s.split():分割字符串
s="Hello world"len(s)
#11max(s)
#'w's.count("l")
#3s.isupper()
#Falses.islower()
#Falses.isdigit()
#Falses.lower()
#'hello world's.upper()
#'HELLO WORLD's.swapcase()
#'hELLO WORLD's.split()
#['Hello', 'world']
- s.strip():去除两边字符串
- s.lstrip():去除左边字符串
- s.rstrip():去除右边字符串
- s.replace():交换字符串。
注意:strip()不能去除字符串中间的空格,去除中间空格用replace()
a=' hello world '
a.strip()
#'hello world'a.lstrip()
#'hello world 'a.rstrip()
#' hello world'a.replace(' ','')
#'helloworld'
4.列表类型
a = [1,54,2,22,4]
- 增加
- a.append(元素)
- a.insert(位置,元素)
a.append(25)
a
#[1, 54, 2, 22, 4, 25]a.insert(0,2)
a
#[2, 1, 54, 2, 22, 4, 25]
- 更新
- a[位置]=元素
a[0]=3
a
#[3, 1, 54, 2, 22, 4, 25]
- 删除
- a.pop(位置) 默认最后元素
- a.remove(元素)
a.pop()
#25a.remove(3)
a
#[1, 54, 2, 22, 4]
-
遍历
-
for x in a:
print(x)
-
for i in range(len(a)):
print(a[i])
-
b=[x**2 for x in a]:
print(x)
-
for x in a:print(x)
'''
1
54
2
22
4
'''for i in range(len(a)):print(a[i])
'''
1
54
2
22
4
'''b=[x**2 for x in a]
b
#[1, 2916, 4, 484, 16]
- len(l):列表长度
- max(l):最大元素,列表为同一类型
- max(l):最小元素,列表为同一类型
- l.reverse():翻转
- l.sort(reverse = True) :降序排序
- in:元素是否再列表
- 切片
- l.clear():清空列表
l=[1,2,3,4,5,6]
len(l)
#6max(l)
#6min(l)
#1l.reverse()
l
#[6, 5, 4, 3, 2, 1]l.sort(reverse = False) #降序
l
#[1, 2, 3, 4, 5, 6]4 in l
#Truel[0:2]
#[1, 2]l.clear()
l
#[]
5.元组类型
a=(1,1.5,'abc')
- 查找
a[0]
#1a[2]
#'abc'
- len(a)
- in
- 切片
len(a)
#31 in a
#Truea[0:2]
#(1, 1.5)
6.集合类型
- 增加
- a.add()
- a.update()
- 删除
- a.remove()
a={1,1.5,'abc'}
a.add(2)
a
#{1, 1.5, 2, 'abc'}a.update({4,5})
a
#{1, 1.5, 2, 4, 5, 'abc'}a.remove(1.5)
a
#{1, 2, 4, 5, 'abc'}
- in
- 集合间的操作
- a-b:a有b没有
- a|b:a有或b有
- a&b:a、b都有
- a^b:a、b不同时有
a={1,2,3}
b={3,4,5}a-b
#{1, 2}a|b
#{1, 2, 3, 4, 5}a&b
#{3}a^b
#{1, 2, 4, 5}
7.字典类型
- 增/改
- dict[key]=value
- 删
- dict.pop(key)
- in
- key in dict
s = {'age':18,'name':'小明'}s['age']=19
s
#{'age': 19, 'name': '小明'}s['city']='长沙'
s
#{'age': 19, 'name': '小明', 'city': '长沙'}s.pop('city')
s
#{'age': 19, 'name': '小明'}'age' in s
#True
- 遍历
- key
- value
- k,v
for key in s:print(key)
#age
#namefor value in s.values():print(value)
#19
#小明for k,v in s.items():print(k,v)
#age 19
#name 小明
相关文章:
【python与数据结构】(leetcode算法预备知识)
笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~ python与数据结构 Python 中常见的数据类型数据结构1.数组(Array)2.链表(Linked List)3.哈希表(Hash Table)4.队列(Queue&#x…...

前端+Python实现Live2D虚拟直播姬
写在前面 很早就在b站上看到有虚拟主播的方案,之前看到的方案主要分为3种: ①用的unity+live2d②有的用的steam的Vtube Studio这款软件③也有基于galgame的。基于纯前端和python的我好像没找到,在掘金看到一篇文章:juejin.cn/post/720474… ,使用的pixi-live2d-display这…...

华纳云 宝塔怎么配置香港服务器多ip?
宝塔面板是一款开源的服务器管理面板,提供了简单易用的图形化界面,使用户能够轻松管理和配置服务器。通过切换到香港服务器多IP,用户可以拥有更多的IP资源,提供更灵活的网络服务。 配置香港服务器多IP 1.登录宝塔面板 打开浏览器&…...

云计算是什么
一文读懂云计算:发展历程、概念技术与现状分析 - 知乎 “现阶段所说的云计算,已经不单单是一种分布式计算,而是分布式计算、效用计算、负载均衡、并行计算、网络存储、热备份冗杂和虚拟化等计算机技术混合演进并跃升的结果。” 云计算的关键…...
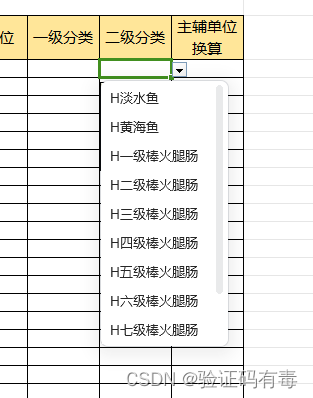
【POI-EXCEL-下拉框】POI导出excel下拉框数据太多导致下拉框不显示BUG修复
RT 最近在线上遇到一个很难受的BUG,我一度以为是我代码逻辑出了问题,用了Arthas定位分析之后,开始坚定了信心:大概率是POI的API有问题,比如写入数据过多。 PS:上图为正常的下拉框。但是,当下拉…...
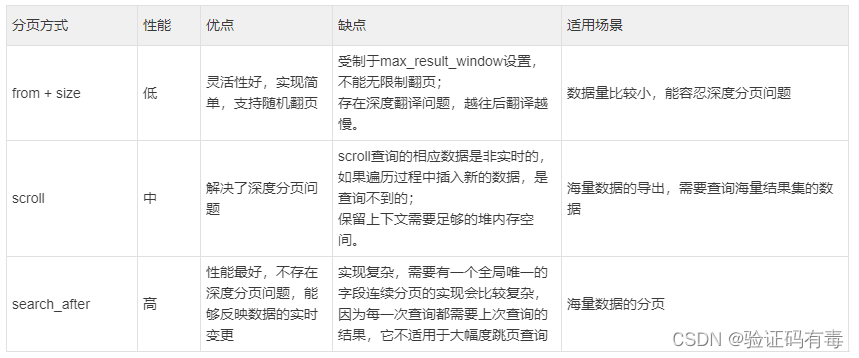
【ES专题】ElasticSearch 高级查询语法Query DSL实战
目录 前言阅读对象阅读导航前置知识数据准备笔记正文一、ES高级查询Query DSL1.1 基本介绍1.2 简单查询之——match-all(匹配所有)1.2.1 返回源数据_source1.2.2 返回指定条数size1.2.3 分页查询from&size1.2.4 指定字段排序sort 1.3 简单查询之——…...

陕西某小型水库雨水情测报及大坝安全监测项目案例
项目背景 根据《陕西省小型病险水库除险加固项目管理办法》、《陕西省小型水库雨水情测报和大坝安全监测设施建设与运行管理办法》的要求,为保障水库安全运行,对全省小型病险水库除险加固,建设完善雨水情测报、监测预警、防汛道路、通讯设备、…...

pte rs练习方法 请介绍一下crank请介绍一下sanctuary请介绍一下solitary请介绍一下coarse请介绍一下deception
目录 pte rs练习方法 请介绍一下crank 请介绍一下sanctuary 请介绍一下solitary 请介绍一下coarse 请介绍一下deception pte rs练习方法 请介绍一下crank “Crank”一词可以个指不同的事物,具体含义视上下文而定。在不同的领域,这个词有不同的解…...
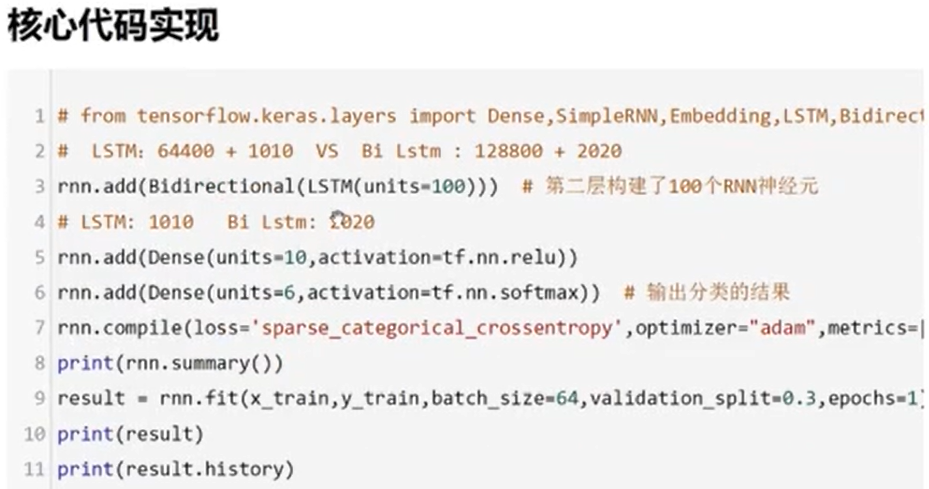
NLP之LSTM与BiLSTM
文章目录 代码展示代码解读双向LSTM介绍(BiLSTM) 代码展示 import pandas as pd import tensorflow as tf tf.random.set_seed(1) df pd.read_csv("../data/Clothing Reviews.csv") print(df.info())df[Review Text] df[Review Text].astyp…...

【实现多个接口的使用】
文章目录 前言实现多个接口接口间的继承接口使用实例给对象数组排序创建一个比较器 总结 前言 实现多个接口 Java中不支持多继承,但是一个类可以实现多个接口 下面是自己反复理了很久才敲出来的,涉及到之前学的很多知识点 如果哪看不懂,真…...

Mac收集的几个终端命令
文章目录 转UTF-8编码格式打tag 包 命令:压缩加密文件显示隐藏文件取消Mac电脑安全模式 转UTF-8编码格式 cd到目录下 iconv -f gbk -t utf-8 gbk.txt > utf8.txt打tag 包 命令: cd到目录下 tar -cvf demo.tar.gz demo a demo压缩加密文件 cd 到文…...
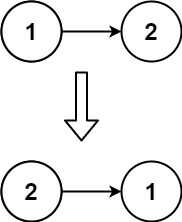
206. 反转链表、Leetcode的Python实现
博客主页:🏆看看是李XX还是李歘歘 🏆 🌺每天分享一些包括但不限于计算机基础、算法等相关的知识点🌺 💗点关注不迷路,总有一些📖知识点📖是你想要的💗 ⛽️今…...

VS2022 打包WPF安装程序最新教程(图文详解)
文章目录 前言一、安装打包Installer插件1、单独安装2、VS中在线安装二、使用步骤1、创建安装项目2、安装项目主界面3、添加项目输出4、添加快捷方式图标5、添加卸载项目a、新建项目b、添加项目输出c、创建快捷方式6、给快捷方式添加图标a、在Resource文件夹中添加图标文件b、选…...

清华大模型GLM
2022年,清华大学发布了一款具有重要意义的 GLM 大模型,它不仅在中文语言处理方面取得了显著的进展,还在英文语言处理方面表现出了强大的能力。GLM大模型区别于OpenAI GPT在线大模型只能通过API方式获取在线支持的窘境,GLM大模型属于开源大模型,可以本地部署进行行业微调、…...
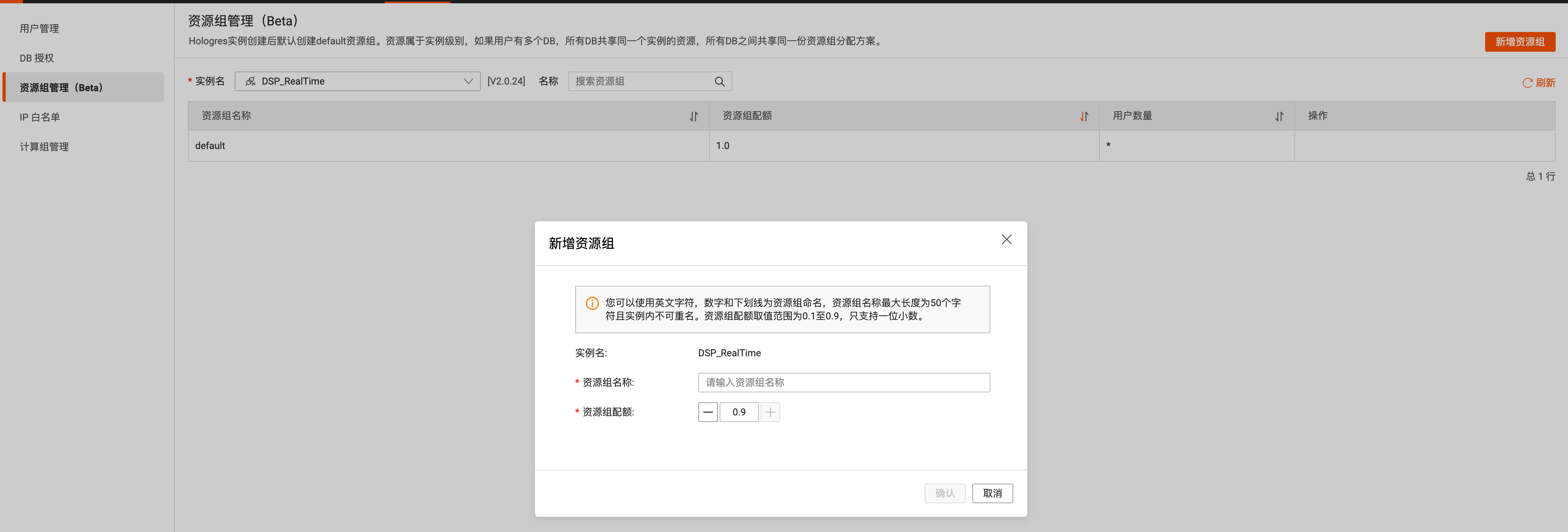
实时数仓-hologres使用总结
我们回顾下,Hologres是一款实时HSAP产品,隶属阿里自研大数据品牌MaxCompute,兼容 PostgreSQL 生态、支持MaxCompute数据直接查询,支持实时写入实时查询,实时离线联邦分析,低成本、高时效、快速构筑企业实时…...

博客摘录「 TCP/IP网络编程——习题答案」2023年10月29日
clnt_sdaccept(serv_sd, (struct sockaddr*)&clnt_adr, &clnt_adr_sz);read(clnt_sd, file_name, BUF_SIZE); fpfopen(file_name, "rb"); //尝试打开客户端请求的文件if(fp!NULL) //如果文件存在,则传送给客户端{while(…...

MySQL数据库干货_13—— MySQL查询数据
MySQL查询数据 SELECT基本查询 SELECT语句的功能 SELECT 语句从数据库中返回信息。使用一个 SELECT 语句,可以做下面的事: 列选择:能够使用 SELECT 语句的列选择功能选择表中的列,这些列是想 要用查询返回的。当查询时…...
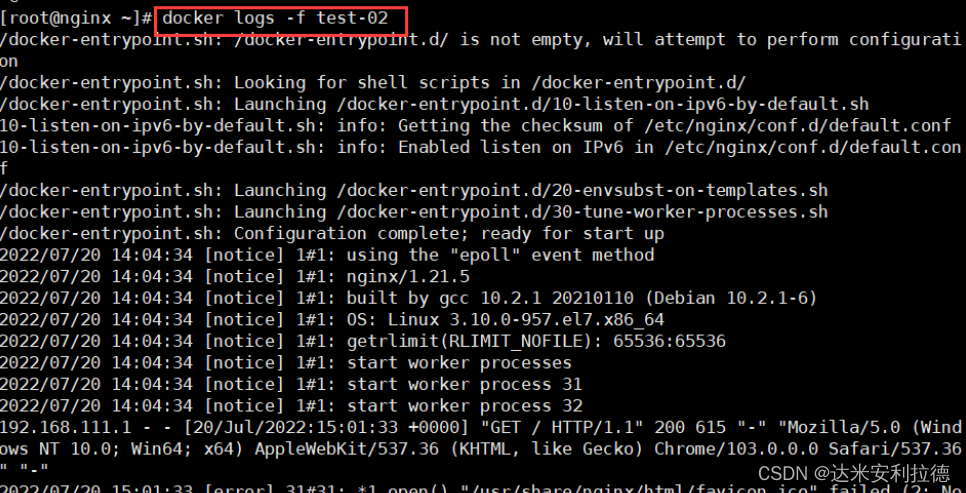
Docker Consul概述及构建
Docker Consul概述及构建 一、Consul概述1.1、什么是Consul1.2、consul 容器服务更新与发现1.3、服务注册与发现的含义1.4、consul-template概述1.5、registrator的作用 二、consul部署2.1、环境配置2.2、在主节点上部署consul2.3 、配置容器服务自动加入nginx集群2.3.1、安装G…...
《Linux从练气到飞升》No.25 Linux中多线程概念
🕺作者: 主页 我的专栏C语言从0到1探秘C数据结构从0到1探秘Linux菜鸟刷题集 😘欢迎关注:👍点赞🙌收藏✍️留言 🏇码字不易,你的👍点赞🙌收藏❤️关注对我真的…...

2021~2023年度长垣起重机博览会最佳产品彩页(修订中)
1.河南恒达 比较完善的起重量限制器产品线分类,提供了监控参数一览表。 2.沪源电机 详细的电机参数,这基本上可以作为电机发展的历史资料来搜集。 3.英威腾 详细的变频器功能 4.杭州浙起 详尽的电动葫芦结构展示,电动葫芦参数展示 5.…...
)
从原理图到Ping通:我的STM32F407 RMII以太网调试笔记(含LAN8720硬件差异处理)
从原理图到Ping通:我的STM32F407 RMII以太网调试笔记(含LAN8720硬件差异处理) 第一次点亮STM32F407的以太网接口时,那种成就感至今难忘。但在此之前,我经历了整整两周的煎熬——原理图反复检查、PCB打样两次、软件调试…...

Dark Reader动态主题修复终极指南:自动化解决网站适配难题
Dark Reader动态主题修复终极指南:自动化解决网站适配难题 【免费下载链接】darkreader Dark Reader Chrome and Firefox extension 项目地址: https://gitcode.com/gh_mirrors/da/darkreader Dark Reader是一款广受欢迎的浏览器扩展,能帮助你将任…...

在多模型间切换使用时对响应速度与一致性的感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多模型间切换使用时对响应速度与一致性的感受 作为一名需要频繁调用大模型API的开发者,我的日常工作离不开与各类模型…...

Play Integrity API Checker:三步快速检测你的Android设备安全完整指南 [特殊字符]
Play Integrity API Checker:三步快速检测你的Android设备安全完整指南 🔐 【免费下载链接】play-integrity-checker-app Get info about your Device Integrity through the Play Intergrity API 项目地址: https://gitcode.com/gh_mirrors/pl/play-i…...

技术解密:Godot RE Tools - 游戏逆向工程的智能解决方案
技术解密:Godot RE Tools - 游戏逆向工程的智能解决方案 【免费下载链接】gdsdecomp Godot reverse engineering tools 项目地址: https://gitcode.com/GitHub_Trending/gd/gdsdecomp Godot RE Tools 是一款专业的Godot游戏逆向工程工具,能够从AP…...

Display Driver Uninstaller完整攻略:显卡驱动清理的终极解决方案
Display Driver Uninstaller完整攻略:显卡驱动清理的终极解决方案 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-u…...

基于 Vibe Coding 的 OJ 平台
基于 Vibe Coding 的 OJ 平台 Github: https://github.com/wjlwjlwjlwjl-cmd/vibe-coding-based-oj-platform Gitee: https://gitee.com/wangs-joyful-home/vibe-coding-based-oj-platform 一个类 LeetCode 的在线编程评测平台,支持题目管理、代码提交、自动判题、提…...

Windows到Linux数据传输实战:WinSCP、SCP、Samba与rsync全解析
1. 项目概述:跨越操作系统的数据搬运在混合开发或运维环境中,从Windows向Linux服务器传输数据,是每个开发者、运维工程师甚至数据分析师都绕不开的日常操作。这看似简单的“复制粘贴”,背后却涉及网络协议、权限管理、文件系统差异…...

RV1126B平台I2C驱动ADS1115实战:从硬件接线到应用层代码
1. 项目概述与核心思路最近在折腾瑞芯微RV1126B这块板子,用的是EASY-EAI Nano-TB开发套件。项目里需要接几个传感器和一个小屏幕,I2C总线是绕不开的。虽然Linux内核已经把I2C驱动封装得很好了,但真要在应用层把它用起来、用稳了,特…...
)
保姆级教程:用Stata处理2000-2021年A股上市公司控制变量(附完整代码与数据)
Stata实战:A股上市公司控制变量构建全流程解析 第一次接触实证研究时,最让我头疼的不是模型设定,而是数据清洗。记得研一那年,导师扔给我一份从CSMAR导出的原始数据,要求两周内完成控制变量构建。面对密密麻麻的Excel表…...