NLP之LSTM与BiLSTM
文章目录
- 代码展示
- 代码解读
- 双向LSTM介绍(BiLSTM)
代码展示
import pandas as pd
import tensorflow as tf
tf.random.set_seed(1)
df = pd.read_csv("../data/Clothing Reviews.csv")
print(df.info())df['Review Text'] = df['Review Text'].astype(str)
x_train = df['Review Text']
y_train = df['Rating']
print(y_train.unique())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 23486 entries, 0 to 23485
Data columns (total 11 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 Unnamed: 0 23486 non-null int64 1 Clothing ID 23486 non-null int64 2 Age 23486 non-null int64 3 Title 19676 non-null object4 Review Text 22641 non-null object5 Rating 23486 non-null int64 6 Recommended IND 23486 non-null int64 7 Positive Feedback Count 23486 non-null int64 8 Division Name 23472 non-null object9 Department Name 23472 non-null object10 Class Name 23472 non-null object
[4 5 3 2 1]
from tensorflow.keras.preprocessing.text import Tokenizerdict_size = 14848
tokenizer = Tokenizer(num_words=dict_size)tokenizer.fit_on_texts(x_train)
print(len(tokenizer.word_index),tokenizer.index_word)x_train_tokenized = tokenizer.texts_to_sequences(x_train)
from tensorflow.keras.preprocessing.sequence import pad_sequences
max_comment_length = 120
x_train = pad_sequences(x_train_tokenized,maxlen=max_comment_length)for v in x_train[:10]:print(v,len(v))
# 构建RNN神经网络
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,SimpleRNN,Embedding,LSTM,Bidirectional
import tensorflow as tfrnn = Sequential()
# 对于rnn来说首先进行词向量的操作
rnn.add(Embedding(input_dim=dict_size,output_dim=60,input_length=max_comment_length))
# RNN:simple_rnn (SimpleRNN) (None, 100) 16100
# LSTM:simple_rnn (SimpleRNN) (None, 100) 64400
rnn.add(Bidirectional(LSTM(units=100))) # 第二层构建了100个RNN神经元
rnn.add(Dense(units=10,activation=tf.nn.relu))
rnn.add(Dense(units=6,activation=tf.nn.softmax)) # 输出分类的结果
rnn.compile(loss='sparse_categorical_crossentropy',optimizer="adam",metrics=['accuracy'])
print(rnn.summary())
result = rnn.fit(x_train,y_train,batch_size=64,validation_split=0.3,epochs=10)
print(result)
print(result.history)
代码解读
首先,我们来总结这段代码的流程:
- 导入了必要的TensorFlow Keras模块。
- 初始化了一个Sequential模型,这表示我们的模型会按顺序堆叠各层。
- 添加了一个Embedding层,用于将整数索引(对应词汇)转换为密集向量。
- 添加了一个双向LSTM层,其中包含100个神经元。
- 添加了两个Dense全连接层,分别包含10个和6个神经元。
- 使用
sparse_categorical_crossentropy损失函数编译了模型。 - 打印了模型的摘要。
- 使用给定的训练数据和验证数据对模型进行了训练。
- 打印了训练的结果。
现在,让我们逐行解读代码:
- 导入依赖:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,SimpleRNN,Embedding,LSTM,Bidirectional
import tensorflow as tf
你导入了创建和训练RNN模型所需的TensorFlow Keras库。
- 初始化模型:
rnn = Sequential()
你选择了一个顺序模型,这意味着你可以简单地按顺序添加层。
- 添加Embedding层:
rnn.add(Embedding(input_dim=dict_size,output_dim=60,input_length=max_comment_length))
此层将整数索引转换为固定大小的向量。dict_size是词汇表的大小,max_comment_length是输入评论的最大长度。
- 添加LSTM层:
rnn.add(Bidirectional(LSTM(units=100)))
你选择了双向LSTM,这意味着它会考虑过去和未来的信息。它有100个神经元。
- 添加全连接层:
rnn.add(Dense(units=10,activation=tf.nn.relu))
rnn.add(Dense(units=6,activation=tf.nn.softmax))
这两个Dense层用于模型的输出,最后一层使用softmax激活函数进行6类的分类。
- 编译模型:
rnn.compile(loss='sparse_categorical_crossentropy',optimizer="adam",metrics=['accuracy'])
你选择了一个适合分类问题的损失函数,并选择了adam优化器。
- 显示模型摘要:
print(rnn.summary())
这将展示模型的结构和参数数量。
Model: "sequential"
_________________________________________________________________Layer (type) Output Shape Param #
=================================================================embedding (Embedding) (None, 120, 60) 890880 bidirectional (Bidirectiona (None, 200) 128800 l) dense (Dense) (None, 10) 2010 dense_1 (Dense) (None, 6) 66 =================================================================
Total params: 1,021,756
Trainable params: 1,021,756
Non-trainable params: 0
_________________________________________________________________
None
- 训练模型:
result = rnn.fit(x_train,y_train,batch_size=64,validation_split=0.3,epochs=10)
你用训练数据集训练了模型,其中30%的数据用作验证,训练了10个周期。
Epoch 1/10
257/257 [==============================] - 74s 258ms/step - loss: 1.2142 - accuracy: 0.5470 - val_loss: 1.0998 - val_accuracy: 0.5521
Epoch 2/10
257/257 [==============================] - 57s 221ms/step - loss: 0.9335 - accuracy: 0.6293 - val_loss: 0.9554 - val_accuracy: 0.6094
Epoch 3/10
257/257 [==============================] - 59s 229ms/step - loss: 0.8363 - accuracy: 0.6616 - val_loss: 0.9321 - val_accuracy: 0.6168
Epoch 4/10
257/257 [==============================] - 61s 236ms/step - loss: 0.7795 - accuracy: 0.6833 - val_loss: 0.9812 - val_accuracy: 0.6089
Epoch 5/10
257/257 [==============================] - 56s 217ms/step - loss: 0.7281 - accuracy: 0.7010 - val_loss: 0.9559 - val_accuracy: 0.6043
Epoch 6/10
257/257 [==============================] - 56s 219ms/step - loss: 0.6934 - accuracy: 0.7156 - val_loss: 1.0197 - val_accuracy: 0.5999
Epoch 7/10
257/257 [==============================] - 57s 220ms/step - loss: 0.6514 - accuracy: 0.7364 - val_loss: 1.1192 - val_accuracy: 0.6080
Epoch 8/10
257/257 [==============================] - 57s 222ms/step - loss: 0.6258 - accuracy: 0.7486 - val_loss: 1.1350 - val_accuracy: 0.6100
Epoch 9/10
257/257 [==============================] - 57s 220ms/step - loss: 0.5839 - accuracy: 0.7749 - val_loss: 1.1537 - val_accuracy: 0.6019
Epoch 10/10
257/257 [==============================] - 57s 222ms/step - loss: 0.5424 - accuracy: 0.7945 - val_loss: 1.1715 - val_accuracy: 0.5744
<keras.callbacks.History object at 0x00000244DCE06D90>
- 显示训练结果:
print(result)
<keras.callbacks.History object at 0x0000013AEAAE1A30>
print(result.history)
{'loss': [1.2142471075057983, 0.9334620833396912, 0.8363043069839478, 0.7795010805130005, 0.7280740141868591, 0.693393349647522, 0.6514003872871399, 0.6257606744766235, 0.5839114189147949, 0.5423741340637207],
'accuracy': [0.5469586253166199, 0.6292579174041748, 0.6616179943084717, 0.6833333373069763, 0.7010340690612793, 0.7156326174736023, 0.7363746762275696, 0.748600959777832, 0.7748783230781555, 0.7944647073745728],
'val_loss': [1.0997602939605713, 0.9553984999656677, 0.932131290435791, 0.9812102317810059, 0.9558586478233337, 1.019730806350708, 1.11918044090271, 1.1349923610687256, 1.1536787748336792, 1.1715185642242432],
'val_accuracy': [0.5520862936973572, 0.609423816204071, 0.6168038845062256, 0.6088560819625854, 0.6043145060539246, 0.5999148488044739, 0.6080045700073242, 0.6099914908409119, 0.6019017696380615, 0.574368417263031]
}
这将展示训练过程中的损失和准确性等信息。
双向LSTM介绍(BiLSTM)

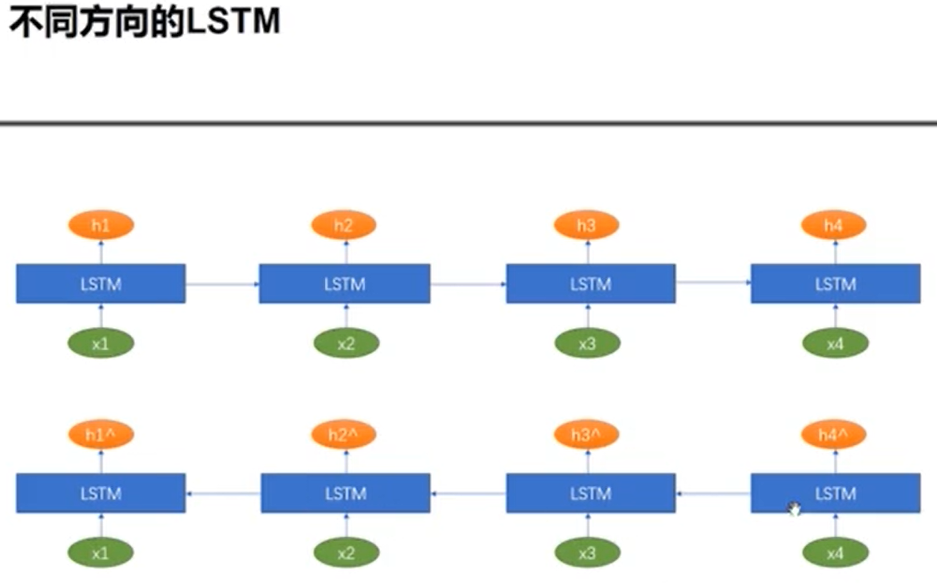
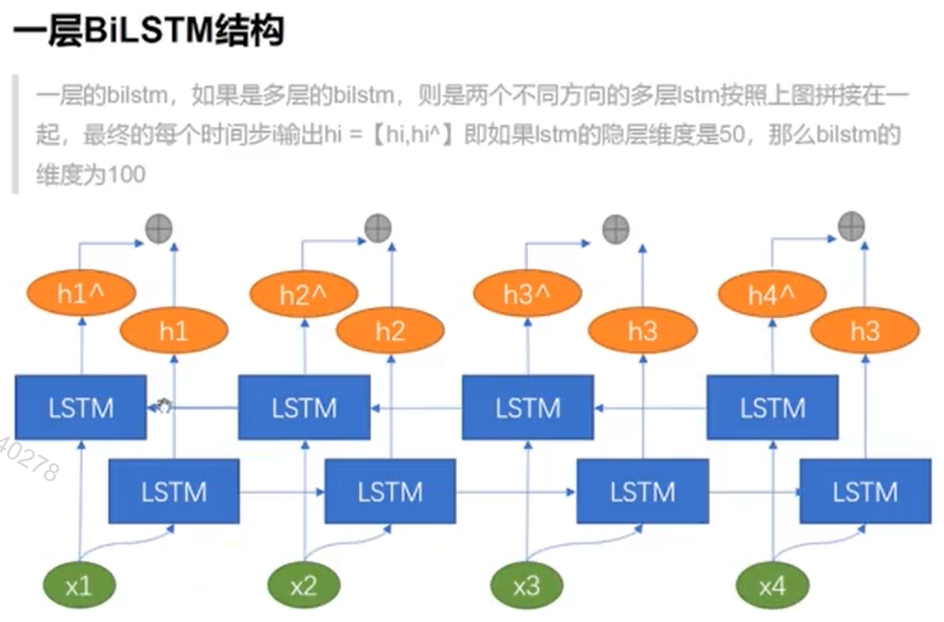
例子:
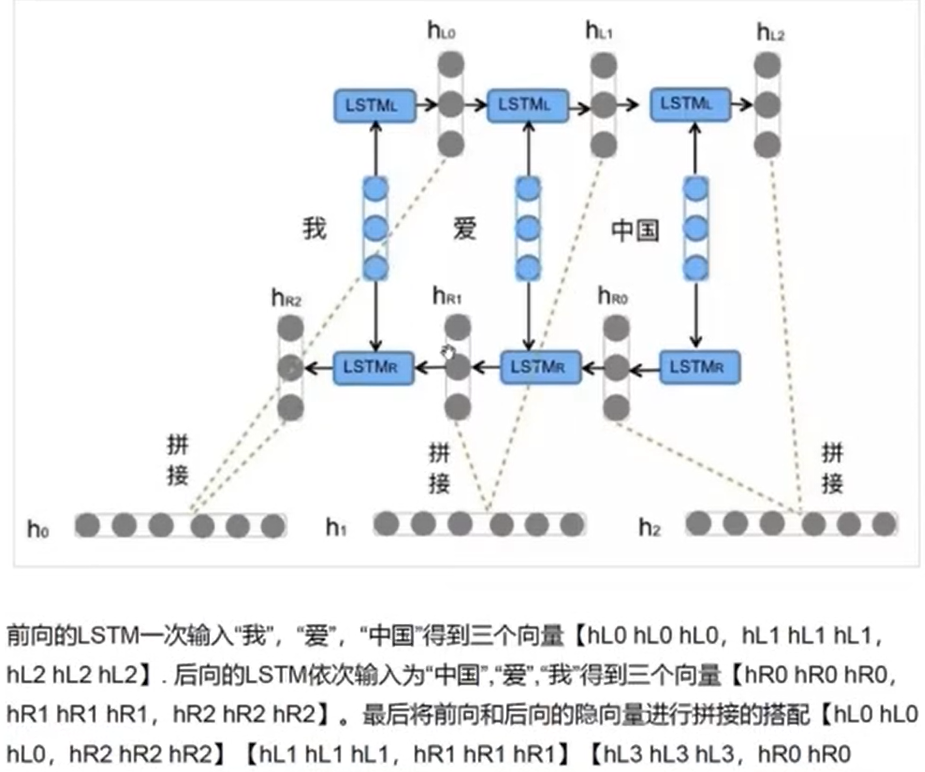
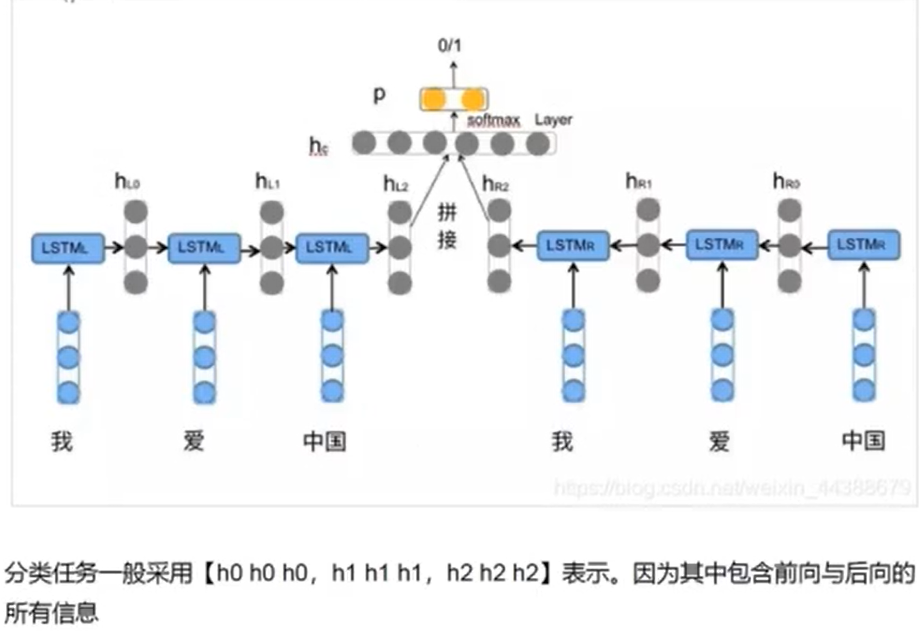
相关文章:
NLP之LSTM与BiLSTM
文章目录 代码展示代码解读双向LSTM介绍(BiLSTM) 代码展示 import pandas as pd import tensorflow as tf tf.random.set_seed(1) df pd.read_csv("../data/Clothing Reviews.csv") print(df.info())df[Review Text] df[Review Text].astyp…...

【实现多个接口的使用】
文章目录 前言实现多个接口接口间的继承接口使用实例给对象数组排序创建一个比较器 总结 前言 实现多个接口 Java中不支持多继承,但是一个类可以实现多个接口 下面是自己反复理了很久才敲出来的,涉及到之前学的很多知识点 如果哪看不懂,真…...

Mac收集的几个终端命令
文章目录 转UTF-8编码格式打tag 包 命令:压缩加密文件显示隐藏文件取消Mac电脑安全模式 转UTF-8编码格式 cd到目录下 iconv -f gbk -t utf-8 gbk.txt > utf8.txt打tag 包 命令: cd到目录下 tar -cvf demo.tar.gz demo a demo压缩加密文件 cd 到文…...
206. 反转链表、Leetcode的Python实现
博客主页:🏆看看是李XX还是李歘歘 🏆 🌺每天分享一些包括但不限于计算机基础、算法等相关的知识点🌺 💗点关注不迷路,总有一些📖知识点📖是你想要的💗 ⛽️今…...

VS2022 打包WPF安装程序最新教程(图文详解)
文章目录 前言一、安装打包Installer插件1、单独安装2、VS中在线安装二、使用步骤1、创建安装项目2、安装项目主界面3、添加项目输出4、添加快捷方式图标5、添加卸载项目a、新建项目b、添加项目输出c、创建快捷方式6、给快捷方式添加图标a、在Resource文件夹中添加图标文件b、选…...

清华大模型GLM
2022年,清华大学发布了一款具有重要意义的 GLM 大模型,它不仅在中文语言处理方面取得了显著的进展,还在英文语言处理方面表现出了强大的能力。GLM大模型区别于OpenAI GPT在线大模型只能通过API方式获取在线支持的窘境,GLM大模型属于开源大模型,可以本地部署进行行业微调、…...
实时数仓-hologres使用总结
我们回顾下,Hologres是一款实时HSAP产品,隶属阿里自研大数据品牌MaxCompute,兼容 PostgreSQL 生态、支持MaxCompute数据直接查询,支持实时写入实时查询,实时离线联邦分析,低成本、高时效、快速构筑企业实时…...

博客摘录「 TCP/IP网络编程——习题答案」2023年10月29日
clnt_sdaccept(serv_sd, (struct sockaddr*)&clnt_adr, &clnt_adr_sz);read(clnt_sd, file_name, BUF_SIZE); fpfopen(file_name, "rb"); //尝试打开客户端请求的文件if(fp!NULL) //如果文件存在,则传送给客户端{while(…...

MySQL数据库干货_13—— MySQL查询数据
MySQL查询数据 SELECT基本查询 SELECT语句的功能 SELECT 语句从数据库中返回信息。使用一个 SELECT 语句,可以做下面的事: 列选择:能够使用 SELECT 语句的列选择功能选择表中的列,这些列是想 要用查询返回的。当查询时…...
Docker Consul概述及构建
Docker Consul概述及构建 一、Consul概述1.1、什么是Consul1.2、consul 容器服务更新与发现1.3、服务注册与发现的含义1.4、consul-template概述1.5、registrator的作用 二、consul部署2.1、环境配置2.2、在主节点上部署consul2.3 、配置容器服务自动加入nginx集群2.3.1、安装G…...
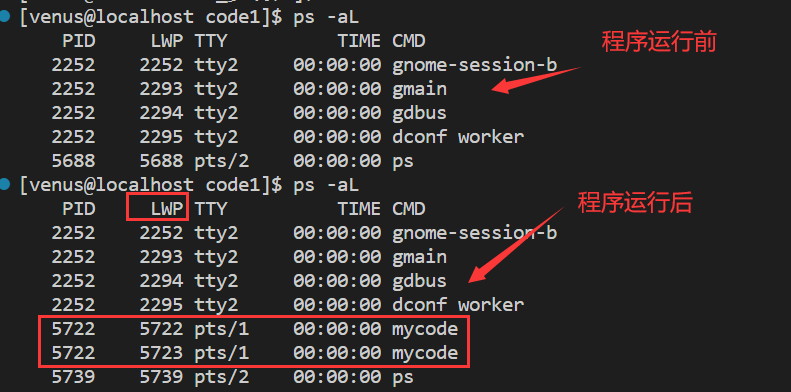
《Linux从练气到飞升》No.25 Linux中多线程概念
🕺作者: 主页 我的专栏C语言从0到1探秘C数据结构从0到1探秘Linux菜鸟刷题集 😘欢迎关注:👍点赞🙌收藏✍️留言 🏇码字不易,你的👍点赞🙌收藏❤️关注对我真的…...

2021~2023年度长垣起重机博览会最佳产品彩页(修订中)
1.河南恒达 比较完善的起重量限制器产品线分类,提供了监控参数一览表。 2.沪源电机 详细的电机参数,这基本上可以作为电机发展的历史资料来搜集。 3.英威腾 详细的变频器功能 4.杭州浙起 详尽的电动葫芦结构展示,电动葫芦参数展示 5.…...

OpenCV标定演示,及如何生成标定板图片
标定的程序在官方的源码里有, opencv-4.5.5\samples\cpp\tutorial_code\calib3d\camera_calibration 很多小白不知道怎么跑起来,这个也怪OpenCV官方,工作没做完善,其实的default.xml是要自己手动改的,输入的图片也要…...

python venv 虚拟环境使用
查看py版本python --version 创建虚拟环境 venvdemopython -m venv venvdemo 启动虚拟环境创建好虚拟环境后,当前目录会出现 venvdemo文件夹 cd envdemo\Scripts 执行 ./activate 文件 进入虚拟环境 关闭虚拟环境deactivate 如何查看Python虚拟环境位置python -c …...

useCallback和useMemo的区别?
文章目录 前言useCallbackuseMemouseCallback除了缓存回调函数还可以做什么操作?后言 前言 hello world欢迎来到前端的新世界 😜当前文章系列专栏:react.js 🐱👓博主在前端领域还有很多知识和技术需要掌握࿰…...

Angular组件生命周期详解
当 Angular 实例化组件类 并渲染组件视图及其子视图时,组件实例的生命周期就开始了。生命周期一直伴随着变更检测,Angular 会检查数据绑定属性何时发生变化,并按需更新视图和组件实例。当 Angular 销毁组件实例并从 DOM 中移除它渲染的模板时…...

Redsync 多 Redis 实例使用 demo
完整代码传送门 package mainimport ("context""fmt""net/http""redis-distributed-lock/redis_client""strconv""github.com/go-redsync/redsync/v4""github.com/go-redsync/redsync/v4/redis/goredis/v9&…...
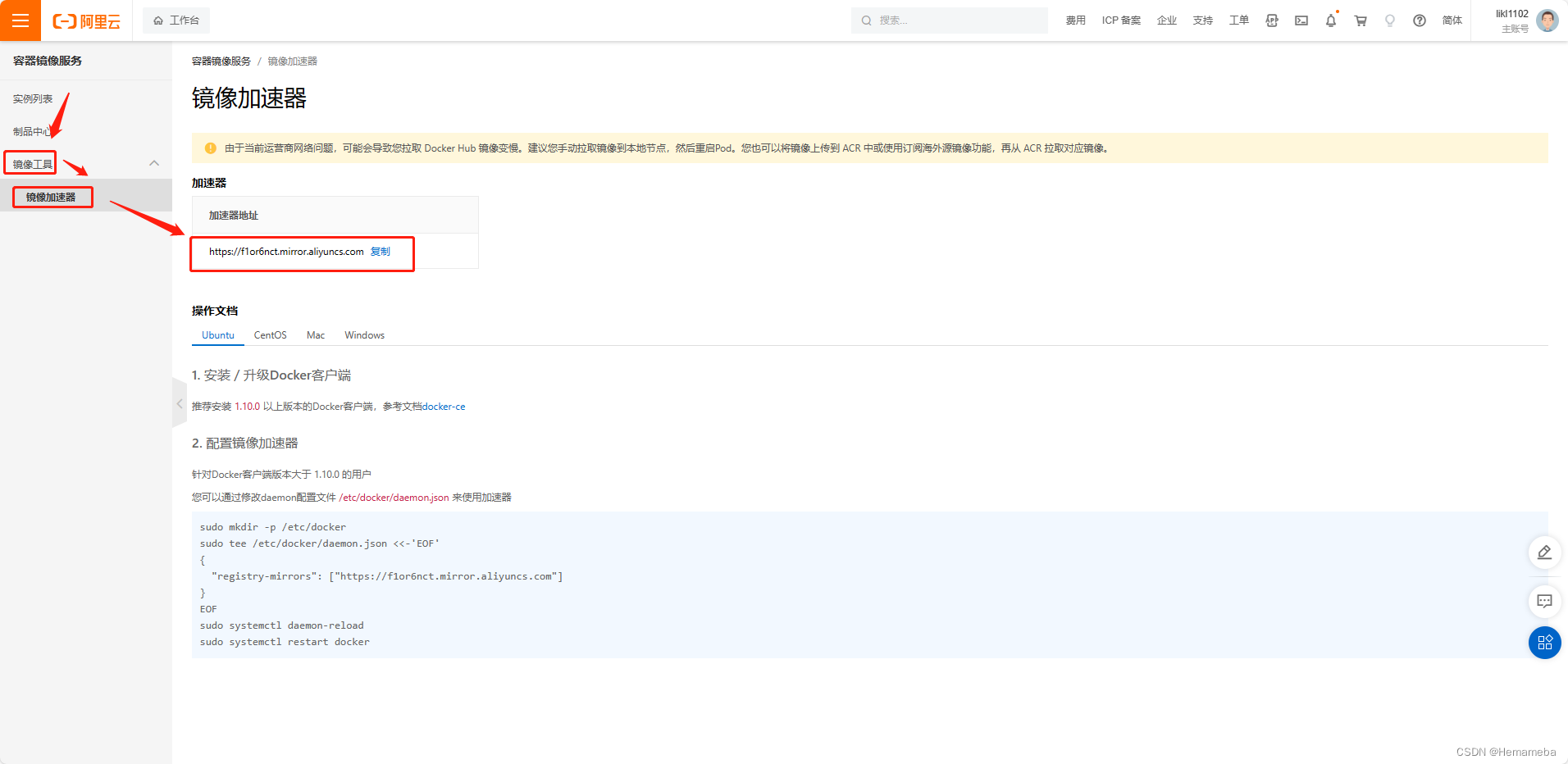
Docker(1)——安装Docker以及配置阿里云镜像加速
目录 一、简介 二、安装Docker 1. 访问Docker官网 2. 卸载旧版本Dokcer 3. 下载yum-utils(yum工具包集合) 4. 设置国内镜像仓库 5. 更新yum软件包索引 6. 安装Docker 7. 启动Docker 8. 卸载Docker 三、阿里云镜像加速 1. 访问阿里云官网 2. …...
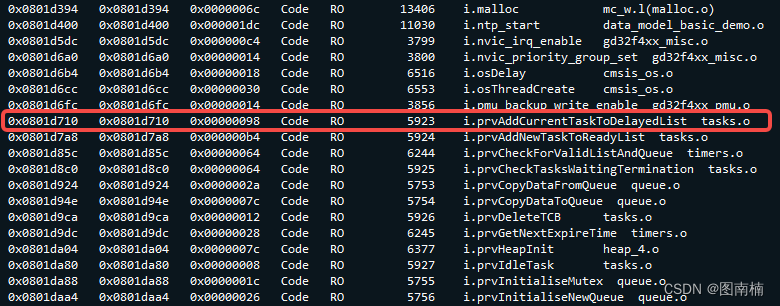
MCU HardFault_Handler调试方法
一.获取内核寄存器的值 1.在MDK的DEBUG模式下,当程序出现跑飞后,确定卡死在HardFault_Handler中断处 2. 通过Register窗口读取LR寄存器的值来确定当前系统使用堆栈是MSP还是PSP LR寄存器值堆栈寄存器0xFFFFFFF9MSP寄存器0xFFFFFFFDPSP寄存器 如下图所…...

【深度学习】AUTOMATIC1111 / stable-diffusion-webui docker
代码:https://github.com/AUTOMATIC1111/stable-diffusion-webui/ CUDA 11.8 制作了一个镜像,可以直接开启stable diffusion的web ui 服务。 确定自己的显卡支持CUDA11.8,启动此镜像方式: docker run -it --networkhost --gpu…...

构建企业级AI对话平台:Open WebUI部署架构深度解析
构建企业级AI对话平台:Open WebUI部署架构深度解析 【免费下载链接】open-webui User-friendly AI Interface (Supports Ollama, OpenAI API, ...) 项目地址: https://gitcode.com/GitHub_Trending/op/open-webui 在AI技术快速发展的今天,如何构建…...

5大长期记忆系统终极横评!谁是AI Agent的「最强大脑」
🚀 5大长期记忆系统终极横评!谁是AI Agent的「最强大脑」? AI Agent 的「长期记忆」能力,决定了它能否真正拥有"持续学习"和"深度理解"的核心竞争力。 我们耗时数周,对 虾觅 Xiami、AgentMemory…...

Unity开发者为何转向VSCode:效率提升26倍的工程实践
1. 为什么我三年前就彻底卸载了Visual Studio——一个Unity老手的真实效率账在Unity项目里打开Visual Studio,等它加载完所有C#项目、符号、IntelliSense、Rider插件、Resharper缓存、NuGet包索引……这个过程平均耗时47秒——这是我用Stopwatch在2021年到2023年连续…...

充电桩行业转型:从规模竞争到质量竞争,CCC认证锚定新赛道
过去五年,中国充电桩行业的核心叙事只有一个字:铺。谁能更快拿点位,谁能更快建站,谁能更快完成城市、县域、高速、社区的覆盖,谁就有资格坐上牌桌。功率数字不断攀升,铺设数量不断刷新,市场份额…...

webMAN-MOD终极指南:PS3自制系统的完整解决方案与实用技巧
webMAN-MOD终极指南:PS3自制系统的完整解决方案与实用技巧 【免费下载链接】webMAN-MOD Extended services for PS3 console (web server, ftp server, netiso, ntfs, ps3mapi, etc.) 项目地址: https://gitcode.com/gh_mirrors/we/webMAN-MOD webMAN-MOD是一…...

3步实现Adobe全家桶完整激活:终极破解方案详解
3步实现Adobe全家桶完整激活:终极破解方案详解 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP是一款专业的Adobe软件激活工具,能…...

Maxwell 磁芯损耗模型怎么选?Power Ferrite vs B-P Curve
🔖 开篇一句话总结 Power Ferrite:用斯坦梅茨公式算损耗,简单高效,适合标准铁氧体材料快速估算。 B-P Curve:直接用实测数据点插值,精度更高,适合非标准材料或追求极致仿真的场景。 一、底层逻辑有什么不一样? 🔹 Power Ferrite:公式拟合的 “标准模板” 它基于经…...

TrollInstallerX:iOS越狱生态的智能安装革命
TrollInstallerX:iOS越狱生态的智能安装革命 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX 还在为复杂的越狱安装流程而烦恼吗?TrollInstallerX…...

城通网盘下载速度慢?3分钟学会ctfileGet终极免费提速方案
城通网盘下载速度慢?3分钟学会ctfileGet终极免费提速方案 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否曾经被城通网盘的龟速下载折磨得抓狂?面对50KB/s的限速、无尽的验…...
)
告别命令行!用VSCode插件一键搞定ESP-IDF环境(ESP32/S3保姆级教程)
告别命令行!用VSCode插件一键搞定ESP-IDF环境(ESP32/S3保姆级教程) 当一块崭新的ESP32开发板躺在桌面上时,许多开发者会陷入两难:既渴望体验这款低功耗Wi-Fi/蓝牙双模芯片的强大性能,又对繁琐的环境配置望而…...