Pytorch 注意力机制解析与代码实现
目录
- 什么是注意力机制
- 1、SENet的实现
- 2、CBAM的实现
- 3、ECA的实现
- 4、CA的实现
什么是注意力机制
注意力机制是深度学习常用的一个小技巧,它有多种多样的实现形式,尽管实现方式多样,但是每一种注意力机制的实现的核心都是类似的,就是注意力。
注意力机制的核心重点就是让网络关注到它更需要关注的地方。
当我们使用卷积神经网络去处理图片的时候,我们会更希望卷积神经网络去注意应该注意的地方,而不是什么都关注,我们不可能手动去调节需要注意的地方,这个时候,如何让卷积神经网络去自适应的注意重要的物体变得极为重要。
注意力机制就是实现网络自适应注意的一个方式。
一般而言,注意力机制可以分为通道注意力机制,空间注意力机制,以及二者的结合。
1、SENet的实现
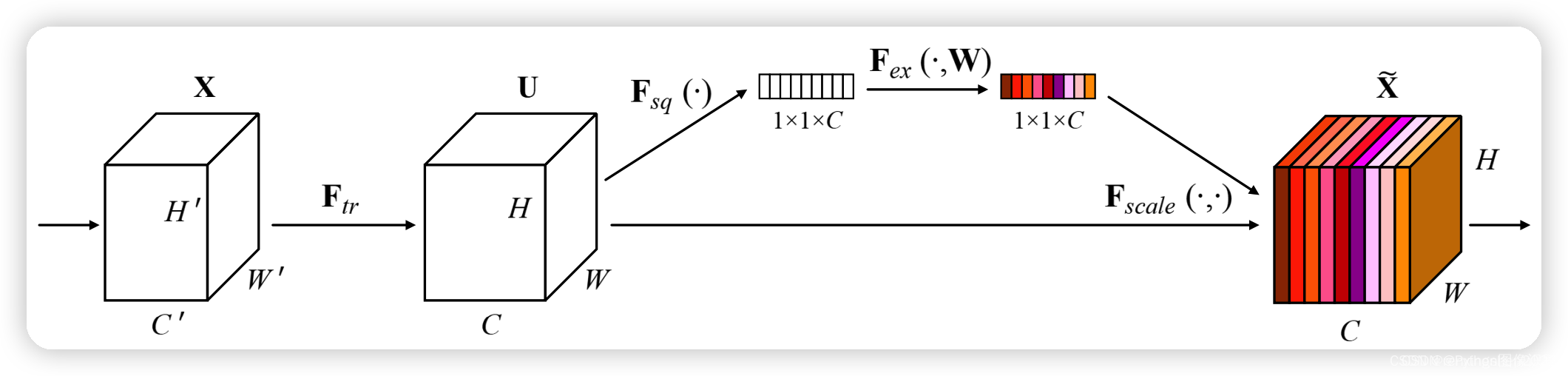
SE注意力模块是一种通道注意力模块,SE模块能对输入特征图进行通道特征加强,且不改变输入特征图的大小。
-
SE模块的S(Squeeze):对输入特征图的空间信息进行压缩
-
SE模块的E(Excitation):学习到的通道注意力信息,与输入特征图进行结合,最终得到具有通道注意力的特征图
-
SE模块的作用是在保留原始特征的基础上,通过学习不同通道之间的关系,提高模型的表现能力。在卷积神经网络中,通过引入SE模块,可以
动态地调整不同通道的权重,从而提高模型的表现能力。
实现方式:
1、对输入进来的特征层进行全局平均池化。
2、然后进行两次全连接,第一次全连接神经元个数较少,第二次全连接神经元个数和输入特征层相同。
3、在完成两次全连接后,我们再取一次Sigmoid将值固定到0-1之间,此时我们获得了输入特征层每一个通道的权值(0-1之间)。
4、在获得这个权值后,我们将这个权值乘上原输入特征层即可。
实现代码
import torch
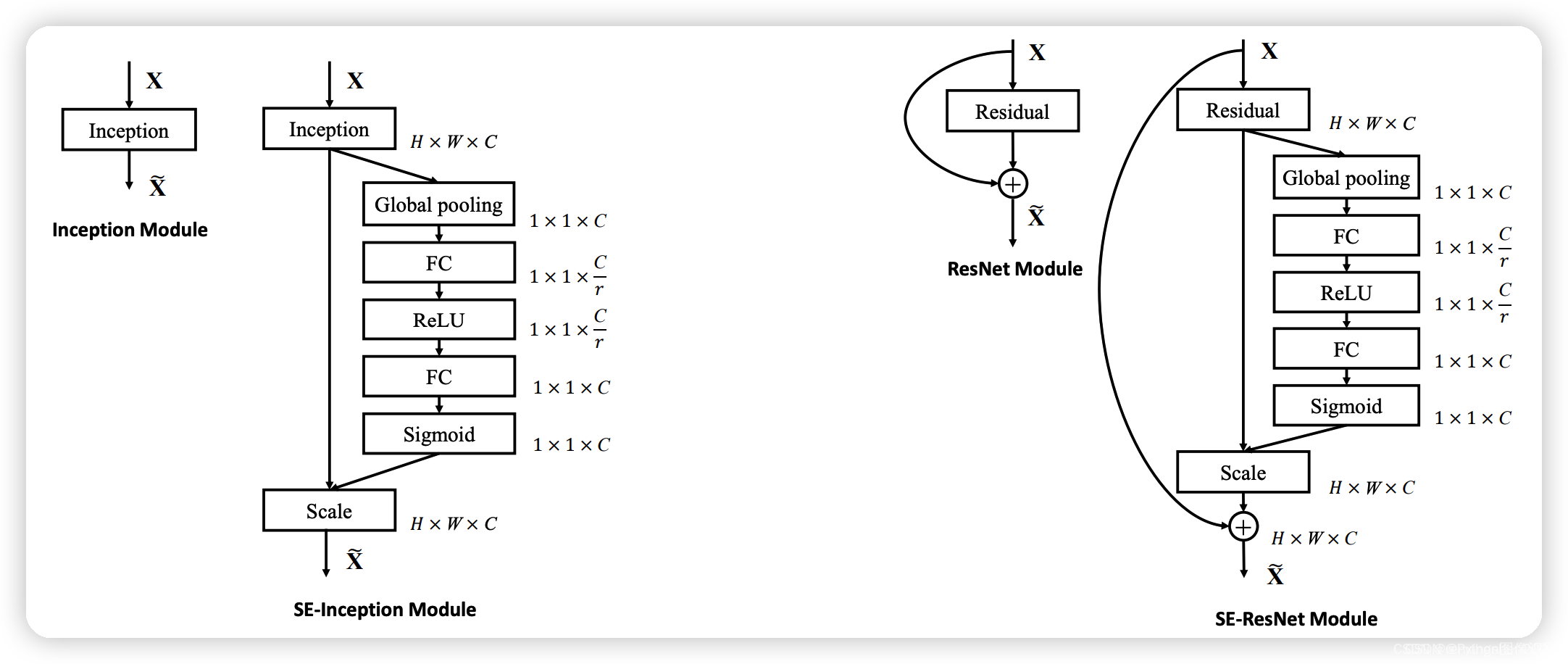
from torch import nnclass SEAttention(nn.Module):def __init__(self, channel=512, reduction=16):super().__init__()# 对空间信息进行压缩self.avg_pool = nn.AdaptiveAvgPool2d(1)# 经过两次全连接层,学习不同通道的重要性self.fc = nn.Sequential(nn.Linear(channel, channel // reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(channel // reduction, channel, bias=False),nn.Sigmoid())def forward(self, x):# 取出batch size和通道数b, c, _, _ = x.size()# b,c,w,h -> b,c,1,1 -> b,c 压缩与通道信息学习y = self.avg_pool(x).view(b, c)# b,c->b,c->b,c,1,1y = self.fc(y).view(b, c, 1, 1)# 激励操作return x * y.expand_as(x)if __name__ == '__main__':input = torch.randn(50, 512, 7, 7)se = SEAttention(channel=512, reduction=8)output = se(input)print(input.shape)print(output.shape)SE模块是一个即插即用的模块,在上图中左边是在一个卷积模块之后直接插入SE模块,右边是在ResNet结构中添加了SE模块。
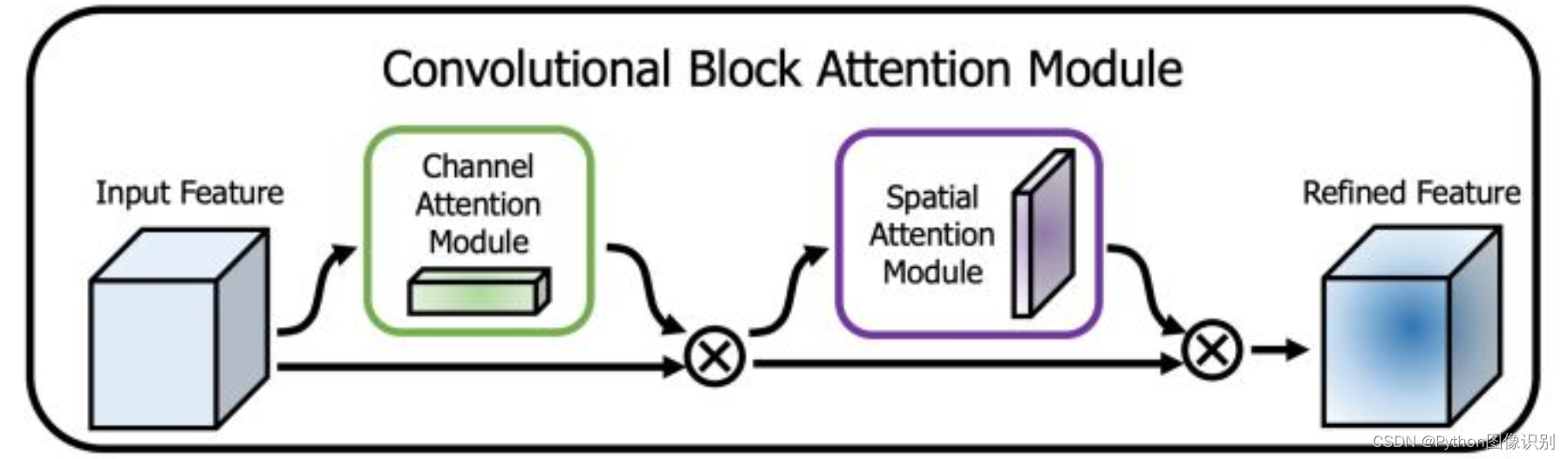
2、CBAM的实现
CBAM将通道注意力机制和空间注意力机制进行一个结合,相比于SENet只关注通道的注意力机制可以取得更好的效果。其实现示意图如下所示,CBAM会对输入进来的特征层,分别进行通道注意力机制的处理和空间注意力机制的处理。
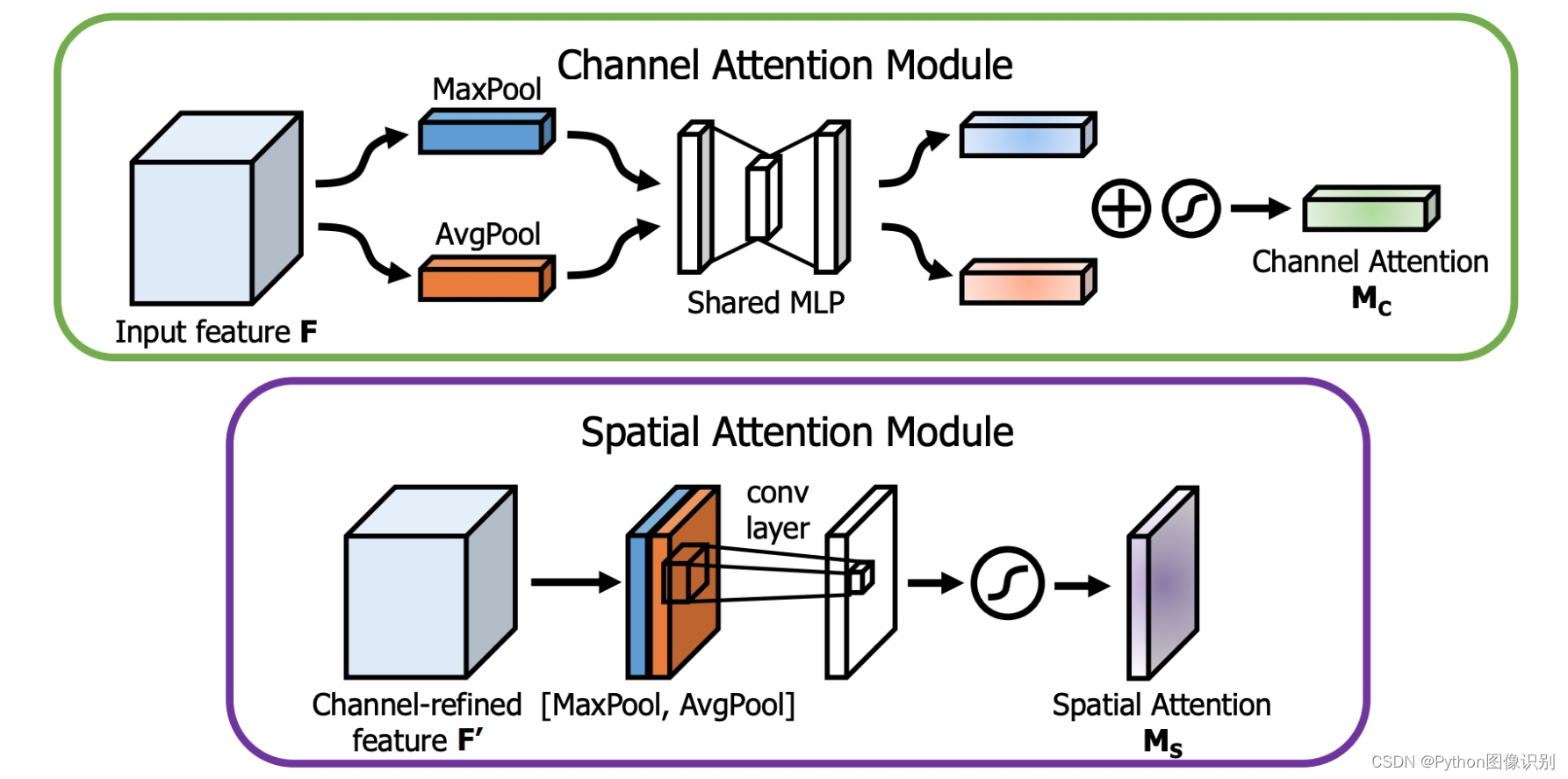
下图是通道注意力机制和空间注意力机制的具体实现方式:
图像的上半部分为通道注意力机制,通道注意力机制的实现可以分为两个部分,我们会对输入进来的单个特征层,分别进行全局平均池化和全局最大池化。之后对平均池化和最大池化的结果,利用共享的全连接层进行处理,我们会对处理后的两个结果进行相加,然后取一个sigmoid,此时我们获得了输入特征层每一个通道的权值(0-1之间)。在获得这个权值后,我们将这个权值乘上原输入特征层即可。
图像的下半部分为空间注意力机制,我们会对输入进来的特征层,在每一个特征点的通道上取最大值和平均值。之后将这两个结果进行一个堆叠,利用一次通道数为1的卷积调整通道数,然后取一个sigmoid,此时我们获得了输入特征层每一个特征点的权值(0-1之间)。在获得这个权值后,我们将这个权值乘上原输入特征层即可。
实现代码:
import torch
from torch import nn
from torch.nn import initclass ChannelAttention(nn.Module):def __init__(self, channel, reduction=16):super().__init__()self.maxpool = nn.AdaptiveMaxPool2d(1)self.avgpool = nn.AdaptiveAvgPool2d(1)self.se = nn.Sequential(nn.Conv2d(channel, channel // reduction, 1, bias=False),nn.ReLU(),nn.Conv2d(channel // reduction, channel, 1, bias=False))self.sigmoid = nn.Sigmoid()def forward(self, x):max_result = self.maxpool(x)avg_result = self.avgpool(x)max_out = self.se(max_result)avg_out = self.se(avg_result)output = self.sigmoid(max_out + avg_out)return outputclass SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super().__init__()self.conv = nn.Conv2d(2, 1, kernel_size=kernel_size, padding=kernel_size // 2)self.sigmoid = nn.Sigmoid()def forward(self, x):max_result, _ = torch.max(x, dim=1, keepdim=True)avg_result = torch.mean(x, dim=1, keepdim=True)result = torch.cat([max_result, avg_result], 1)output = self.conv(result)output = self.sigmoid(output)return outputclass CBAMAttention(nn.Module):def __init__(self, channel=512, reduction=16, kernel_size=7):super().__init__()self.ca = ChannelAttention(channel=channel, reduction=reduction)self.sa = SpatialAttention(kernel_size=kernel_size)def forward(self, x):b, c, _, _ = x.size()out = x * self.ca(x)out = out * self.sa(out)return outif __name__ == '__main__':input = torch.randn(50, 512, 7, 7)kernel_size = input.shape[2]cbam = CBAMAttention(channel=512, reduction=16, kernel_size=kernel_size)output = cbam(input)print(input.shape)print(output.shape)3、ECA的实现
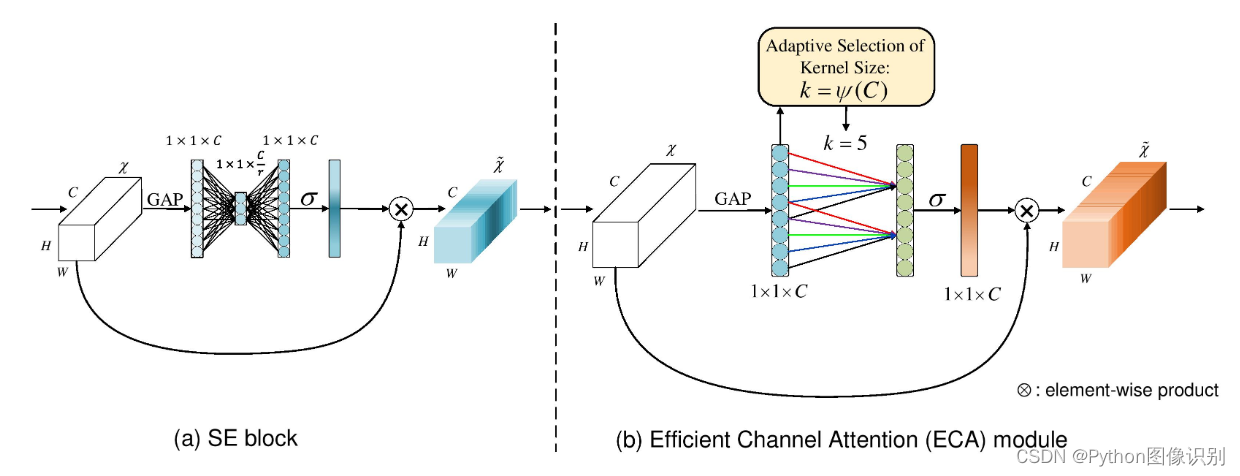
ECANet是也是通道注意力机制的一种实现形式。ECANet可以看作是SENet的改进版。
ECANet的作者认为SENet对通道注意力机制的预测带来了副作用,捕获所有通道的依赖关系是低效并且是不必要的。
在ECANet的论文中,作者认为卷积具有良好的跨通道信息获取能力。
ECA模块的思想是非常简单的,它去除了原来SE模块中的全连接层,直接在全局平均池化之后的特征上通过一个1D卷积进行学习。
既然使用到了1D卷积,那么1D卷积的卷积核大小的选择就变得非常重要了,了解过卷积原理的同学很快就可以明白,1D卷积的卷积核大小会影响注意力机制每个权重的计算要考虑的通道数量。用更专业的名词就是跨通道交互的覆盖率。
如下图所示,左图是常规的SE模块,右图是ECA模块。ECA模块用1D卷积替换两次全连接。
代码实现:
import torch
from torch import nn
from torch.nn import initclass ECAAttention(nn.Module):def __init__(self, kernel_size=3):super().__init__()self.gap = nn.AdaptiveAvgPool2d(1)self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2)self.sigmoid = nn.Sigmoid()def init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None:init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):init.constant_(m.weight, 1)init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):init.normal_(m.weight, std=0.001)if m.bias is not None:init.constant_(m.bias, 0)def forward(self, x):y = self.gap(x) # bs,c,1,1y = y.squeeze(-1).permute(0, 2, 1) # bs,1,cy = self.conv(y) # bs,1,cy = self.sigmoid(y) # bs,1,cy = y.permute(0, 2, 1).unsqueeze(-1) # bs,c,1,1return x * y.expand_as(x)if __name__ == '__main__':input = torch.randn(50, 512, 7, 7)eca = ECAAttention(kernel_size=3)output = eca(input)print(input.shape)print(output.shape)4、CA的实现
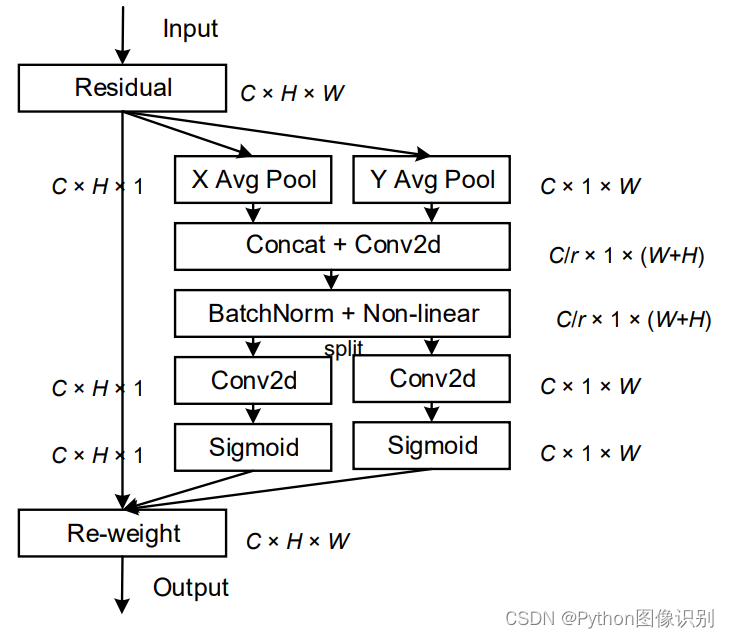
该文章的作者认为现有的注意力机制(如CBAM、SE)在求取通道注意力的时候,通道的处理一般是采用全局最大池化或平均池化,这样会损失掉物体的空间信息。作者期望在引入通道注意力机制的同时,引入空间注意力机制,作者提出的注意力机制将位置信息嵌入到了通道注意力中。
CA注意力的实现如图所示,可以认为分为两个并行阶段:
将输入特征图分别在为宽度和高度两个方向分别进行全局平均池化,分别获得在宽度和高度两个方向的特征图。假设输入进来的特征层的形状为[C, H, W],在经过宽方向的平均池化后,获得的特征层shape为[C, H, 1],此时我们将特征映射到了高维度上;在经过高方向的平均池化后,获得的特征层shape为[C, 1, W],此时我们将特征映射到了宽维度上。
然后将两个并行阶段合并,将宽和高转置到同一个维度,然后进行堆叠,将宽高特征合并在一起,此时我们获得的特征层为:[C, 1, H+W],利用卷积+标准化+激活函数获得特征。
之后再次分开为两个并行阶段,再将宽高分开成为:[C, 1, H]和[C, 1, W],之后进行转置。获得两个特征层[C, H, 1]和[C, 1, W]。
然后利用1x1卷积调整通道数后取sigmoid获得宽高维度上的注意力情况。乘上原有的特征就是CA注意力机制。
实现代码:
import torch
from torch import nnclass CAAttention(nn.Module):def __init__(self, channel, reduction=16):super(CAAttention, self).__init__()self.conv_1x1 = nn.Conv2d(in_channels=channel, out_channels=channel // reduction, kernel_size=1, stride=1,bias=False)self.relu = nn.ReLU()self.bn = nn.BatchNorm2d(channel // reduction)self.F_h = nn.Conv2d(in_channels=channel // reduction, out_channels=channel, kernel_size=1, stride=1,bias=False)self.F_w = nn.Conv2d(in_channels=channel // reduction, out_channels=channel, kernel_size=1, stride=1,bias=False)self.sigmoid_h = nn.Sigmoid()self.sigmoid_w = nn.Sigmoid()def forward(self, x):_, _, h, w = x.size()x_h = torch.mean(x, dim=3, keepdim=True).permute(0, 1, 3, 2)x_w = torch.mean(x, dim=2, keepdim=True)x_cat_conv_relu = self.relu(self.bn(self.conv_1x1(torch.cat((x_h, x_w), 3))))x_cat_conv_split_h, x_cat_conv_split_w = x_cat_conv_relu.split([h, w], 3)s_h = self.sigmoid_h(self.F_h(x_cat_conv_split_h.permute(0, 1, 3, 2)))s_w = self.sigmoid_w(self.F_w(x_cat_conv_split_w))out = x * s_h.expand_as(x) * s_w.expand_as(x)return outif __name__ == '__main__':input = torch.randn(50, 512, 7, 7)eca = CAAttention(512, reduction=16)output = eca(input)print(input.shape)print(output.shape)相关文章:
Pytorch 注意力机制解析与代码实现
目录 什么是注意力机制1、SENet的实现2、CBAM的实现3、ECA的实现4、CA的实现 什么是注意力机制 注意力机制是深度学习常用的一个小技巧,它有多种多样的实现形式,尽管实现方式多样,但是每一种注意力机制的实现的核心都是类似的,就…...

Python上下文管理:with语句执行原理
什么是上下文管理器 上下文管理器(Context Manager)是 Python 中用于管理资源分配和释放的一种机制。它允许您在进入和退出代码块时执行特定的操作,例如打开和关闭文件、建立和关闭数据库连接、获取和释放锁等。上下文管理器常常与 with 语句…...
Mac-Java开发环境安装(JDK和Maven)
JDK安装 1、访问oracle官网,下载jdk 点击下载链接:https://www.oracle.com/java/technologies/downloads/#java11-mac 选择Mac版本,下载dmg 打勾点击下载,跳转登陆,没有就注册,输入账号密码即可下载成功…...

mac下的vscode配置编译环境
基础开发环境 创建Dockerfile文件,内容如下: FROM ubuntu:20.04RUN apt update & apt install make gcc cmake git ninja-build -y CMD [ "sleep", "infinity" ]创建docker-compose.yml文件,内容如下: …...

洗衣洗鞋柜洗衣洗鞋小程序
支持:一键投递、上门取衣、自主送店、多种支付方式 TEL: 17638103951(同V) -----------------用户下单-------------- -------------------------多种支付和投递方式------------------------- -----------------商家取鞋--------------...
vi vim 末尾编辑按GA 在最后一行下方新增一行编辑按Go
vim 快速跳到文件末尾 在最后一行下方新增一行 移到末尾,并且进入文本录入模式 GA (大写G大写A) 在一般模式(刚进入的模式,esc模式) GA 或 Shift ga 先 G 或 shiftg 到最后一行 然后 A 或 shifta 到本行末尾 并且进入文本录入模式 在最后一行下方新增一行 (光标换行,文字不…...
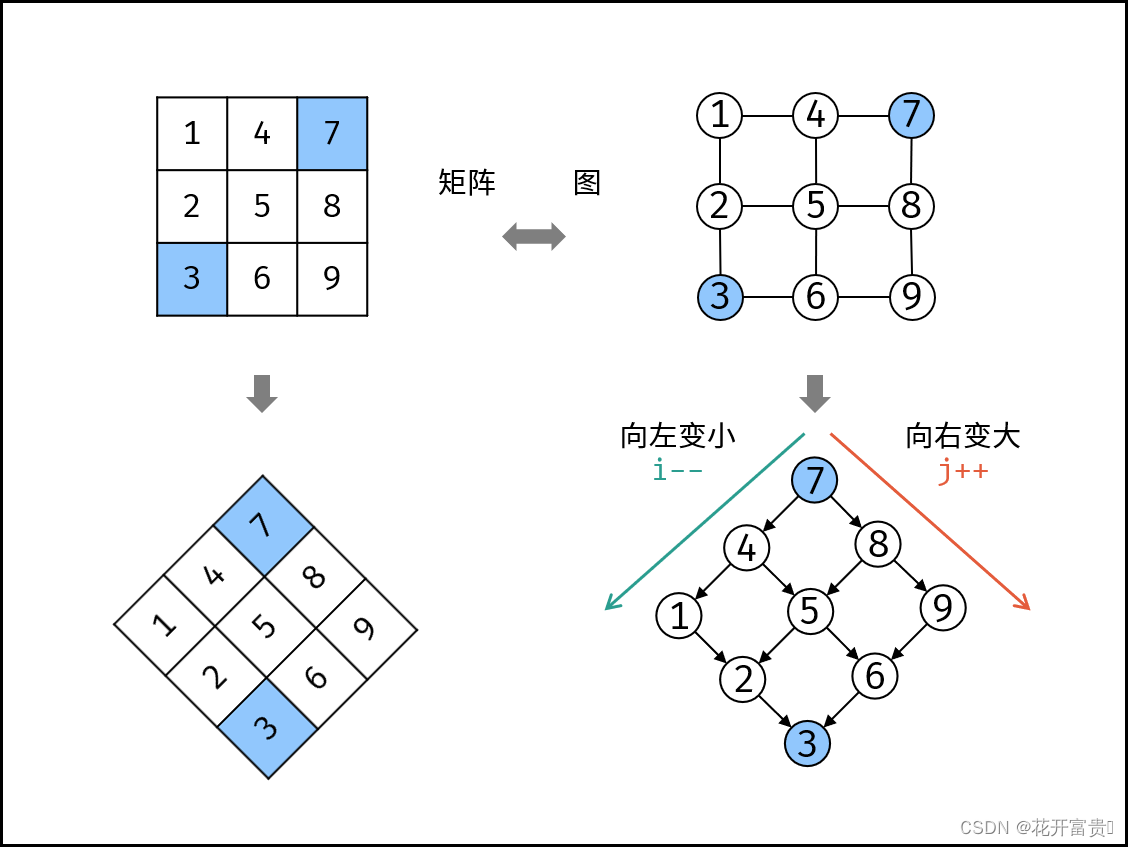
LeetCode热题100 240.搜索二维矩阵||
题目描述: 编写一个高效的算法来搜索 m*n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性: 每行的元素从左到右升序排列。每列的元素从上到下升序排列。 示例1: 输入:matrix [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,2…...

Anaconda安装及使用教程
前言:鉴于本人曾经学过计算机双学位,近日突然发现电脑上装了Anaconda,然而脑子里对为什么装这个,啥时候装的以及怎么用的都忘记了。因此,想学习了解下这个软件。 1 Anaconda简介 Anaconda,一个开源的Pyth…...
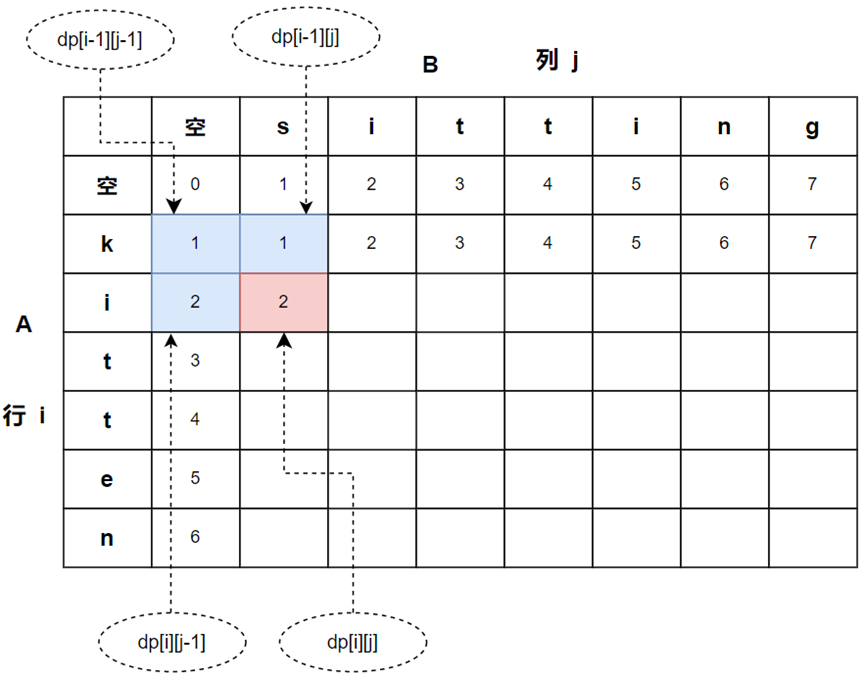
动态规划算法实现------转换(编辑、变换)问题
目录 一、字符串转换问题 1.1问题 1.2确定动态规则(DP、状态转移方程)、初始值 (1)插入操作实现状态转移 (2)删除操作实现状态转移 (3)替换操作实现状态转移 (4)初始值 1.3动态规划算法代码实现 (1)完整代码 (2)程序速度优化 二、矩阵变换问题 2.1问题 2.2矩阵乘法 (1)矩阵相乘…...

C#使用Oracle.ManagedDataAccess.dll
1、添加引用 在网上下载一个Oracle.ManagedDataAccess.dll,引用即可,视操作系统的位数,最重要的是减少了Oracle客户端的安装; 2、web.config字串 <appSettings> <add key"hrp" value"Data Source (…...

分享88个工作总结PPT,总有一款适合您
分享88个工作总结PPT,总有一款适合您 88个工作总结PPT下载链接:https://pan.baidu.com/s/1y08X9RMdIOCncbs28aMgDw?pwd8888 提取码:8888 Python采集代码下载链接:采集代码.zip - 蓝奏云 蓝色水彩风年终总结PPT模板 清新水彩简…...

【华为OD题库-002】最佳植树距离-Java
题目 小明在直线的公路上种树,现在给定可以种树的坑位的数星和位置,以及需要种多少棵树苗,问树苗之间的最小间距是多少时,可以保证种的最均匀(两棵树苗之间的最小间距最大) 输入描述 输入三行: 第一行一个整数:坑位的数…...

【python与数据结构】(leetcode算法预备知识)
笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~ python与数据结构 Python 中常见的数据类型数据结构1.数组(Array)2.链表(Linked List)3.哈希表(Hash Table)4.队列(Queue&#x…...

前端+Python实现Live2D虚拟直播姬
写在前面 很早就在b站上看到有虚拟主播的方案,之前看到的方案主要分为3种: ①用的unity+live2d②有的用的steam的Vtube Studio这款软件③也有基于galgame的。基于纯前端和python的我好像没找到,在掘金看到一篇文章:juejin.cn/post/720474… ,使用的pixi-live2d-display这…...

华纳云 宝塔怎么配置香港服务器多ip?
宝塔面板是一款开源的服务器管理面板,提供了简单易用的图形化界面,使用户能够轻松管理和配置服务器。通过切换到香港服务器多IP,用户可以拥有更多的IP资源,提供更灵活的网络服务。 配置香港服务器多IP 1.登录宝塔面板 打开浏览器&…...

云计算是什么
一文读懂云计算:发展历程、概念技术与现状分析 - 知乎 “现阶段所说的云计算,已经不单单是一种分布式计算,而是分布式计算、效用计算、负载均衡、并行计算、网络存储、热备份冗杂和虚拟化等计算机技术混合演进并跃升的结果。” 云计算的关键…...
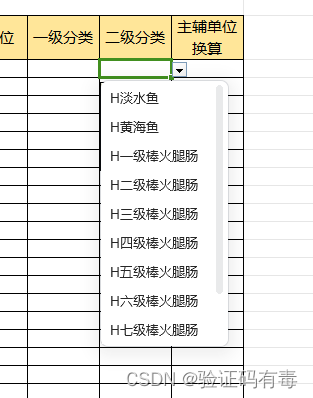
【POI-EXCEL-下拉框】POI导出excel下拉框数据太多导致下拉框不显示BUG修复
RT 最近在线上遇到一个很难受的BUG,我一度以为是我代码逻辑出了问题,用了Arthas定位分析之后,开始坚定了信心:大概率是POI的API有问题,比如写入数据过多。 PS:上图为正常的下拉框。但是,当下拉…...
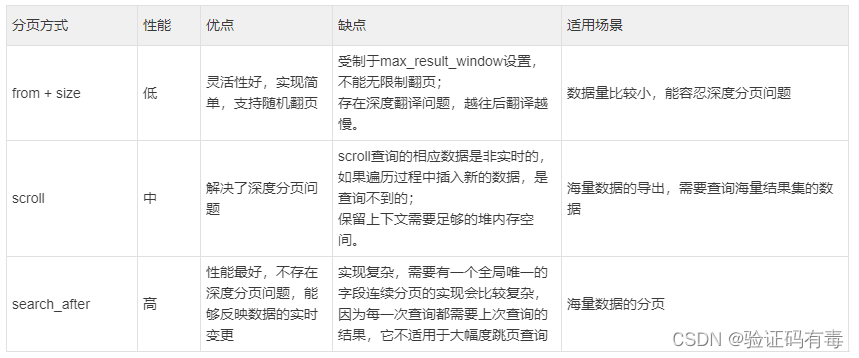
【ES专题】ElasticSearch 高级查询语法Query DSL实战
目录 前言阅读对象阅读导航前置知识数据准备笔记正文一、ES高级查询Query DSL1.1 基本介绍1.2 简单查询之——match-all(匹配所有)1.2.1 返回源数据_source1.2.2 返回指定条数size1.2.3 分页查询from&size1.2.4 指定字段排序sort 1.3 简单查询之——…...

陕西某小型水库雨水情测报及大坝安全监测项目案例
项目背景 根据《陕西省小型病险水库除险加固项目管理办法》、《陕西省小型水库雨水情测报和大坝安全监测设施建设与运行管理办法》的要求,为保障水库安全运行,对全省小型病险水库除险加固,建设完善雨水情测报、监测预警、防汛道路、通讯设备、…...

pte rs练习方法 请介绍一下crank请介绍一下sanctuary请介绍一下solitary请介绍一下coarse请介绍一下deception
目录 pte rs练习方法 请介绍一下crank 请介绍一下sanctuary 请介绍一下solitary 请介绍一下coarse 请介绍一下deception pte rs练习方法 请介绍一下crank “Crank”一词可以个指不同的事物,具体含义视上下文而定。在不同的领域,这个词有不同的解…...

为Claude Code配置Taotoken稳定通道避免封号与Token不足
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置Taotoken稳定通道避免封号与Token不足 对于频繁使用Claude Code作为编程助手的开发者而言,直接使用官…...

揭秘K12课堂AI转型真相:3个被90%学校忽略的PlayAI部署陷阱及72小时应急修复指南
更多请点击: https://intelliparadigm.com 第一章:PlayAI教育领域应用案例 PlayAI 作为面向教育场景的轻量级AI交互平台,已在多个教学实践中展现出显著的适配性与可扩展性。其核心优势在于无需深度编程基础即可构建个性化学习路径、实时学情…...

别再乱用电容了!从稳压芯片电路入手,搞懂电解电容和贴片电容到底该怎么搭配
电解电容与贴片电容的黄金组合:稳压电路设计实战解析 在电子电路设计中,稳压芯片的输入输出端常见一大一小两个电容并联的经典配置,这种设计看似简单却蕴含着深刻的电路原理。对于刚入行的硬件工程师或电子爱好者来说,理解这种组…...

ESXi勒索防护实战:堵住配置天窗,构建三层纵深防御
1. 这不是“又一起”勒索事件,而是ESXi生态链断裂的警报 2023年底开始,全球范围内大量VMware ESXi服务器被植入名为 ESXiArgs (也称 KPOT )的勒索软件,攻击波及金融、医疗、教育、制造等数十个行业。这不是传统意义…...

免费开源AMD Ryzen调试工具:SMUDebugTool完全指南与实用教程
免费开源AMD Ryzen调试工具:SMUDebugTool完全指南与实用教程 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: http…...

微信小程序逆向工程终极指南:wxappUnpacker完整实战解析
微信小程序逆向工程终极指南:wxappUnpacker完整实战解析 【免费下载链接】wxappUnpacker forked from https://github.com/qwerty472123/wxappUnpacker 项目地址: https://gitcode.com/gh_mirrors/wxappu/wxappUnpacker 微信小程序逆向工程是安全研究人员和技…...

视频硬字幕提取革命:87种语言本地OCR识别,让字幕提取从未如此简单
视频硬字幕提取革命:87种语言本地OCR识别,让字幕提取从未如此简单 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含…...

linux学习笔记之linux文件管理
#文件系统及Shell的基本概念#文件及目录操作命令#VI的使用#软件包的管理一、文件系统及Shell的基本概念 1.文件系统的含义文件系统是用来管理和组织保存在磁盘驱动器上数据的系统软件 2.Linux的文件系统Linux系统采用虚拟文件系统技术(VFS&am…...
)
别再硬编码IP了!用LabVIEW类+队列实现仪器参数动态管理(附网口类实战代码)
告别硬编码:LabVIEW面向对象编程在仪器参数管理中的实战应用 在工业自动化和测试测量领域,工程师们经常面临一个共同的挑战:如何高效管理各类仪器的配置参数。传统开发方式中,IP地址、端口号等关键参数往往直接硬编码在程序里&…...

Conductor工作流引擎:5个步骤构建企业级分布式任务编排系统
Conductor工作流引擎:5个步骤构建企业级分布式任务编排系统 【免费下载链接】conductor Distributed workflow server 项目地址: https://gitcode.com/gh_mirrors/cond/conductor 在当今复杂的微服务架构中,分布式任务编排已经成为企业数字化转型…...