Ha-NeRF源码解读 train_mask_grid_sample
目录
背景:
(1)Ha_NeRF论文解读
(2)Ha_NeRF源码复现
(3)train_mask_grid_sample.py 运行
train_mask_grid_sample.py解读
1 NeRFSystem 模块
2 forward()详解
3 模型训练tranining_step()详解
4 模型验证validation_step()详解:
5 validation_epoch_end() 详解
6 main() 详解
背景:
(1)Ha_NeRF论文解读
NeRF系列(4):Ha-NeRF: Hallucinated Neural Radiance Fields in the Wild论文解读_LeapMay的博客-CSDN博客文章浏览阅读389次,点赞3次,收藏3次。提出了一个外观幻化模块,用于处理时间变化的外观并将其转移到新视角上。考虑到旅游图像中的复杂遮挡情况,我们引入了一个抗遮挡模块,用于准确地分解静态物体以获取清晰的可见性。https://blog.csdn.net/qq_35831906/article/details/131247784?spm=1001.2101.3001.6650.5&utm_medium=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~Rate-5-131247784-blog-131334579.235%5Ev38%5Epc_relevant_yljh&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~Rate-5-131247784-blog-131334579.235%5Ev38%5Epc_relevant_yljh&utm_relevant_index=6
(2)Ha_NeRF源码复现
Ha-NeRF: Hallucinated Neural Radiance Fields in the Wild 代码复现与解读_LeapMay的博客-CSDN博客文章浏览阅读244次。code:本机环境: python 3.6.3,torch 1.8.1+cu102,pytorch-lightning 1.1.5。https://blog.csdn.net/qq_35831906/article/details/131334579
(3)train_mask_grid_sample.py 运行
python train_mask_grid_sample.py --root_dir ./data/IMC-PT/brandenburg_gate --dataset_name phototourism --save_dir save --img_downscale 2 --use_cache --N_importanc
e 64 --N_samples 64 --num_epochs 20 --batch_size 1024 --optimizer adam --lr 5e-4 --lr_scheduler cosine --exp_name exp_HaNeRF_Brandenburg_Gate --N_emb_xyz 15 --N_vocab 1500 --use_mask --maskrs_max 5e-2 --maskrs_min 6e-3 --maskrs_
k 1e-3 --maskrd 0 --encode_a --N_a 48 --weightKL 1e-5 --encode_random --weightRecA 1e-3 --weightMS 1e-6 --num_gpus 1train_mask_grid_sample.py解读
1 NeRFSystem 模块
# 导入必要的库和模块
import torch
from models.nerf import NeRF # 假设 NeRF 在 models.nerf 模块中定义
from models.networks import E_attr, implicit_mask, PosEmbedding # 导入所需模块# 定义一个名为 NeRFSystem 的 PyTorch Lightning 模块类
class NeRFSystem(LightningModule):def __init__(self, hparams):super().__init__() # 调用 LightningModule 构造函数self.hparams = hparams # 存储模型的超参数self.loss = loss_dict['hanerf'](hparams, coef=1) # 设置损失函数 'hanerf' 并指定系数为 1self.models_to_train = [] # 初始化一个列表,用于存储需要训练的模型self.embedding_xyz = PosEmbedding(hparams.N_emb_xyz - 1, hparams.N_emb_xyz) # 用于 XYZ 坐标的位置编码self.embedding_dir = PosEmbedding(hparams.N_emb_dir - 1, hparams.N_emb_dir) # 用于方向的位置编码self.embedding_uv = PosEmbedding(10 - 1, 10) # 用于 UV 坐标的位置编码self.embeddings = {'xyz': self.embedding_xyz, 'dir': self.embedding_dir} # 将位置编码存储在字典中# 如果需要属性编码if hparams.encode_a:self.enc_a = E_attr(3, hparams.N_a) # 使用指定维度创建属性编码器self.models_to_train += [self.enc_a] # 将编码器添加到需要训练的模型列表中self.embedding_a_list = [None] * hparams.N_vocab # 初始化属性编码列表# 创建具有指定输入通道(XYZ 和方向)的粗糙 NeRF 模型self.nerf_coarse = NeRF('coarse', in_channels_xyz=6 * hparams.N_emb_xyz + 3, in_channels_dir=6 * hparams.N_emb_dir + 3)self.models = {'coarse': self.nerf_coarse} # 将粗糙 NeRF 模型存储在字典中# 如果需要精细 NeRF 模型if hparams.N_importance > 0:# 创建具有指定输入通道(XYZ、方向和外观编码)的精细 NeRF 模型self.nerf_fine = NeRF('fine', in_channels_xyz=6 * hparams.N_emb_xyz + 3, in_channels_dir=6 * hparams.N_emb_dir + 3,encode_appearance=hparams.encode_a, in_channels_a=hparams.N_a,encode_random=hparams.encode_random)self.models['fine'] = self.nerf_fine # 将精细 NeRF 模型存储在模型字典中self.models_to_train += [self.models] # 将模型添加到需要训练的列表中# 如果需要使用遮罩if hparams.use_mask:self.implicit_mask = implicit_mask() # 初始化隐式遮罩模型self.models_to_train += [self.implicit_mask] # 将隐式遮罩添加到需要训练的列表中self.embedding_view = torch.nn.Embedding(hparams.N_vocab, 128) # 创建一个嵌入视图self.models_to_train += [self.embedding_view] # 将嵌入视图添加到需要训练的列表中
NeRFSystem类的初始化函数(__init__):
- 首先调用
super().__init__()来继承LightningModule的初始化方法。self.hparams用于存储模型的超参数。self.loss是模型的损失函数,通过loss_dict字典选择了名为 'hanerf' 的损失函数并初始化它。self.models_to_train是一个模型列表,用于存储需要训练的模型组件。self.embedding_xyz、self.embedding_dir和self.embedding_uv是位置嵌入(Positional Embedding)对象,用于编码不同类型的空间坐标。- 根据超参数的设定,如果
hparams.encode_a为真,将创建属性编码器self.enc_a,并将其加入self.models_to_train列表中。- 通过
NeRF类创建了粗糙(coarse)和精细(fine)NeRF模型,将这些模型添加到self.models字典中,并将需要训练的模型也加入self.models_to_train列表中。- 如果
hparams.use_mask为真,将创建隐式遮罩(implicit_mask)模型和一个嵌入层(embedding layer),同样加入了self.models_to_train列表中。
forward方法和其他训练、验证相关的方法并未在这段代码中提供,这些方法一般用于执行前向传播,定义损失计算方式,指定优化器和学习率调度器,加载数据等等总体来说,这段代码创建了一个 PyTorch Lightning 模型,其中包含了多个 NeRF 相关的组件,根据指定的超参数和需求组织了不同的模型和模型组件,并将它们用于训练过程。这个类的功能主要是提供一个结构化的接口,以便构建和管理神经体积渲染模型,使得模型的训练和验证能够更加方便和易于管理。
2 forward()详解
def forward(self, rays, ts, whole_img, W, H, rgb_idx, uv_sample, test_blender):results = defaultdict(list) # 使用 defaultdict 初始化结果存储kwargs = {} # 初始化空字典 kwargs,用于存储关键字参数# 如果需要对属性进行编码if self.hparams.encode_a:if test_blender:# 如果是测试渲染器kwargs['a_embedded_from_img'] = self.embedding_a_list[0] if self.embedding_a_list[0] is not None else self.enc_a(whole_img)else:# 否则,在图像数据上进行属性编码kwargs['a_embedded_from_img'] = self.enc_a(whole_img)# 如果需要编码随机属性(self.hparams.encode_random为True):# - 获取非空属性编码列表的索引idexlist,其中k为索引,v为属性编码值# - 若idexlist为空,意味着属性编码列表中没有非空值的属性编码# - 将a_embedded_random设置为a_embedded_from_img,表示使用来自整个图像的属性编码# - 否则,从属性编码列表中随机选择一个索引对应的属性编码,作为随机属性编码if self.hparams.encode_random:idexlist = [k for k, v in enumerate(self.embedding_a_list) if v is not None]if len(idexlist) == 0:kwargs['a_embedded_random'] = kwargs['a_embedded_from_img']else:# 随机选择一个非空属性编码,作为随机属性编码random_index = random.choice(idexlist)kwargs['a_embedded_random'] = self.embedding_a_list[random_index]"""Do batched inference on rays using chunk."""B = rays.shape[0] # 获取射线的批量大小for i in range(0, B, self.hparams.chunk):rendered_ray_chunks = render_rays(self.models, # 使用预定义的模型self.embeddings, # 使用预定义的嵌入rays[i:i + self.hparams.chunk], # 批量处理的射线ts[i:i + self.hparams.chunk], # 批量处理的时间点self.hparams.N_samples, # 数值采样self.hparams.use_disp, # 使用视差self.hparams.perturb, # 扰动self.hparams.noise_std, # 噪声标准差self.hparams.N_importance, # 重要性数self.hparams.chunk, # 有效的块大小self.train_dataset.white_back, # 白色背景**kwargs # 关键字参数)for k, v in rendered_ray_chunks.items():results[k] += [v]for k, v in results.items():results[k] = torch.cat(v, 0) # 将结果连接起来if self.hparams.use_mask:if test_blender:results['out_mask'] = torch.zeros(results['rgb_fine'].shape[0], 1).to(results['rgb_fine'])else:uv_embedded = self.embedding_uv(uv_sample)results['out_mask'] = self.implicit_mask(torch.cat((self.embedding_view(ts), uv_embedded), dim=-1))if self.hparams.encode_a:results['a_embedded'] = kwargs['a_embedded_from_img'] # 存储属性编码结果if self.hparams.encode_random:results['a_embedded_random'] = kwargs['a_embedded_random'] # 存储随机属性编码结果rec_img_random = results['rgb_fine_random'].view(1, H, W, 3).permute(0, 3, 1, 2) * 2 - 1results['a_embedded_random_rec'] = self.enc_a(rec_img_random)self.embedding_a_list[ts[0]] = kwargs['a_embedded_from_img'].clone().detach()return results # 返回结果字典
在给定的
forward方法中:
results = defaultdict(list)- 创建一个defaultdict,用于存储模型前向传播的结果,其结构是列表形式的字典。在后续的循环中,这将存储渲染的射线结果。通过
kwargs存储关键字参数,这些参数将在render_rays函数中使用。kwargs会根据不同条件动态更改。对属性编码的处理:
if self.hparams.encode_a:如果需要对属性进行编码。if test_blender:根据条件是否是测试渲染器来确定是否使用整体图像(whole_img)对属性进行编码。if self.hparams.encode_random:如果需要对属性进行随机编码。
- 通过
idexlist获取非空属性编码列表的索引,如果列表为空,则默认使用整体图像对属性进行编码。- 否则,随机选择一个非空属性编码,并存储为随机属性编码。
循环
for i in range(0, B, self.hparams.chunk):这里的代码进行了分块的射线渲染,根据射线的数量和块大小分块进行渲染。得到的结果存储在results中。对结果进行整理:
for k, v in results.items()循环结果字典,将分块的结果连接起来。- 如果需要使用遮罩(
use_mask):
- 通过
if test_blender和else,确定是否使用输出遮罩。遮罩将根据不同的条件生成不同的值。如果需要对属性进行编码:
results['a_embedded']和results['a_embedded_random']存储属性编码的结果。results['a_embedded_random_rec']存储随机属性编码的结果。self.embedding_a_list[ts[0]]更新属性编码列表中的对应索引,将其设置为来自整体图像的属性编码的克隆值。返回结果
results,这些结果包括射线渲染的数据和属性编码的结果。这段代码实现了射线渲染过程中对属性进行编码的功能,并存储了相关结果。
3 模型训练tranining_step()详解
def training_step(self, batch, batch_nb):# 从批处理中提取数据rays, ts = batch['rays'].squeeze(), batch['ts'].squeeze() # 提取射线和时间点rgbs = batch['rgbs'].squeeze() # 提取 RGB 值uv_sample = batch['uv_sample'].squeeze() # 提取 UV 样本# 检查是否需要编码属性或使用掩膜if self.hparams.encode_a or self.hparams.use_mask:whole_img = batch['whole_img'] # 提取整个图像rgb_idx = batch['rgb_idx'] # 提取 RGB 索引else:whole_img = Nonergb_idx = None# 从 RGB 值的平方根计算高度和宽度H = int(sqrt(rgbs.size(0)))W = int(sqrt(rgbs.size(0)))test_blender = False # 设置 test_blender 标志# 执行前向传递以生成预测和损失results = self(rays, ts, whole_img, W, H, rgb_idx, uv_sample, test_blender)loss_d, AnnealingWeight = self.loss(results, rgbs, self.hparams, self.global_step)loss = sum(l for l in loss_d.values()) # 计算总损失# 记录与训练相关的指标with torch.no_grad():typ = 'fine' if 'rgb_fine' in results else 'coarse' # 确定结果类型psnr_ = psnr(results[f'rgb_{typ}'], rgbs) # 计算 PSNR 指标self.log('lr', get_learning_rate(self.optimizer)) # 记录学习率self.log('train/loss', loss) # 记录总损失self.log('train/AnnealingWeight', AnnealingWeight) # 记录 AnnealingWeightself.log('train/min_scale_cur', batch['min_scale_cur']) # 记录最小规模# 记录各个损失for k, v in loss_d.items():self.log(f'train/{k}', v)self.log('train/psnr', psnr_) # 记录 PSNR 指标# 特定步骤的可视化if (self.global_step + 1) % 5000 == 0:# 格式化图像、深度图和蒙版以进行可视化img = results[f'rgb_{typ}'].detach().view(H, W, 3).permute(2, 0, 1).cpu()img_gt = rgbs.detach().view(H, W, 3).permute(2, 0, 1).cpu()depth = visualize_depth(results[f'depth_{typ}'].detach().view(H, W))# 记录图像和可视化到实验日志器if self.hparams.use_mask:mask = results['out_mask'].detach().view(H, W, 1).permute(2, 0, 1).repeat(3, 1, 1).cpu()if 'rgb_fine_random' in results:img_random = results[f'rgb_fine_random'].detach().view(H, W, 3).permute(2, 0, 1).cpu()stack = torch.stack([img_gt, img, depth, img_random, mask])self.logger.experiment.add_images('train/GT_pred_depth_random_mask', stack, self.global_step)else:stack = torch.stack([img_gt, img, depth, mask])self.logger.experiment.add_images('train/GT_pred_depth_mask', stack, self.global_step)elif 'rgb_fine_random' in results:img_random = results[f'rgb_fine_random'].detach().view(H, W, 3).permute(2, 0, 1).cpu()stack = torch.stack([img_gt, img, depth, img_random])self.logger.experiment.add_images('train/GT_pred_depth_random', stack, self.global_step)else:stack = torch.stack([img_gt, img, depth])self.logger.experiment.add_images('train/GT_pred_depth', stack, self.global_step)return loss # 返回计算的损失
以上代码是一个 PyTorch Lightning 中的
training_step方法,用于执行一个训练步骤。它主要执行以下操作:
数据提取和预处理:
- 从传入的批量数据中提取射线、时间、RGB值和UV样本。
- 根据属性编码和掩膜的需求,提取整个图像和RGB索引。
预测和损失计算:
- 对提取的数据执行前向传递,得到预测结果和损失值。
- 根据损失结果计算总损失值,并在不需要梯度计算时计算 PSNR 指标。
记录指标和损失:
- 记录学习率、总损失、
AnnealingWeight、最小规模以及各个损失值。- 记录 PSNR 指标作为训练指标。
特定步骤的可视化:
- 当全局步数是 5000 的倍数时,进行特定步骤的可视化。
- 将图像、深度图像和mask以图像格式准备好。
- 如果存在mask,将mask图、深度图、原始图像、预测图像、随机预测图像以图像堆叠的形式记录到实验日志器中。
- 如果没有mask,将深度图、原始图像和预测图像以图像堆叠的形式记录到实验日志器中。
返回损失:返回计算得到的损失值。
这个方法主要负责训练过程中的模型训练、指标记录和可视化。
4 模型验证validation_step()详解:
def validation_step(self, batch, batch_nb):# 提取输入数据rays, ts = batch['rays'].squeeze(), batch['ts'].squeeze()rgbs = batch['rgbs'].squeeze()# 根据数据集名称设置 uv_sample、W 和 Hif self.hparams.dataset_name == 'phototourism':uv_sample = batch['uv_sample'].squeeze()WH = batch['img_wh']W, H = WH[0, 0].item(), WH[0, 1].item()else:W, H = self.hparams.img_whuv_sample = None# 处理需要属性编码、mask 或去遮挡处理的情况if self.hparams.encode_a or self.hparams.use_mask or self.hparams.deocclusion:if self.hparams.dataset_name == 'phototourism':whole_img = batch['whole_img']else:# 对于非 phototourism 数据集,构建张量表示原始图像whole_img = rgbs.view(1, H, W, 3).permute(0, 3, 1, 2) * 2 - 1rgb_idx = batch['rgb_idx']else:whole_img = Nonergb_idx = None# 根据数据集设置测试渲染器test_blender = (self.hparams.dataset_name == 'blender')# 进行前向传播results = self(rays, ts, whole_img, W, H, rgb_idx, uv_sample, test_blender)# 计算损失和其他评估指标loss_d, AnnealingWeight = self.loss(results, rgbs, self.hparams, self.global_step)loss = sum(l for l in loss_d.values())log = {'val_loss': loss}for k, v in loss_d.items():log[k] = v# 计算 PSNR 和 SSIMtyp = 'fine' if 'rgb_fine' in results else 'coarse'img = results[f'rgb_{typ}'].view(H, W, 3).permute(2, 0, 1).cpu()img_gt = rgbs.view(H, W, 3).permute(2, 0, 1).cpu()# 在第一个 batch 时计算并记录深度图像和 maskif batch_nb == 0:depth = visualize_depth(results[f'depth_{typ}'].view(H, W))if self.hparams.use_mask:mask = results['out_mask'].detach().view(H, W, 1).permute(2, 0, 1).repeat(3, 1, 1).cpu()if 'rgb_fine_random' in results:img_random = results[f'rgb_fine_random'].detach().view(H, W, 3).permute(2, 0, 1).cpu()stack = torch.stack([img_gt, img, depth, img_random, mask])self.logger.experiment.add_images('val/GT_pred_depth_random_mask', stack, self.global_step)else:stack = torch.stack([img_gt, img, depth, mask])self.logger.experiment.add_images('val/GT_pred_depth_mask', stack, self.global_step)elif 'rgb_fine_random' in results:img_random = results[f'rgb_fine_random'].detach().view(H, W, 3).permute(2, 0, 1).cpu()stack = torch.stack([img_gt, img, depth, img_random])self.logger.experiment.add_images('val/GT_pred_depth_random', stack, self.global_step)else:stack = torch.stack([img_gt, img, depth])self.logger.experiment.add_images('val/GT_pred_depth', stack, self.global_step)# 计算 PSNR 和 SSIM 并记录到日志psnr_ = psnr(results[f'rgb_{typ}'], rgbs)ssim_ = ssim(img[None, ...], img_gt[None, ...])log['val_psnr'] = psnr_log['val_ssim'] = ssim_return log # 返回评估指标这段代码是 PyTorch Lightning 中用于执行模型验证步骤的方法。
提取输入数据:
- 从输入批次中提取射线
rays、时间ts和颜色值rgbs。对于特定数据集('phototourism'),还提取了uv_sample和图像宽高信息WH。- 根据数据集名称和条件,设置了
W和H。处理编码、遮罩和去遮挡:
- 根据模型是否需要属性编码、遮罩或者去遮挡,从输入数据中提取相应的参数。对于特定数据集,整个图像
whole_img和颜色索引rgb_idx也会被提取。设置测试渲染器:
- 如果数据集是 'blender',则设置
test_blender为True。执行前向传播:
- 利用模型执行前向传播,计算输出
results。计算损失和评估指标:
- 利用计算得到的输出结果
results计算损失loss和其他评估指标。将损失值和其他指标记录在log字典中。图像和深度可视化:
- 计算得到
results中的图像img和真实图像img_gt,以及可能的深度图像depth。- 在第一个 batch 时,如果使用了 mask,计算
mask和可能的随机图像img_random,并将它们与其他图像一起记录到实验日志中。计算 PSNR 和 SSIM:
- 利用计算得到的结果,计算 PSNR 和 SSIM,并将其记录在
log字典中。返回结果:
- 返回包含评估指标的
log字典。这个方法主要用于执行验证步骤,评估模型在给定数据集上的性能,并记录相应的指标。
5 validation_epoch_end() 详解
def validation_epoch_end(self, outputs):# 检查 outputs 的长度以决定是否更新全局变量的当前 epochif len(outputs) == 1:global_val.current_epoch = self.current_epoch # 当 outputs 的长度为 1 时,将 global_val.current_epoch 设置为当前 self.current_epochelse:global_val.current_epoch = self.current_epoch + 1 # 否则,将 global_val.current_epoch 设置为当前 self.current_epoch + 1# 计算 outputs 中验证集上的损失、PSNR 和 SSIM 的平均值mean_loss = torch.stack([x['val_loss'] for x in outputs]).mean() # 平均验证损失mean_psnr = torch.stack([x['val_psnr'] for x in outputs]).mean() # 平均 PSNRmean_ssim = torch.stack([x['val_ssim'] for x in outputs]).mean() # 平均 SSIM# 记录验证集指标到训练日志中self.log('val/loss', mean_loss) # 记录平均验证损失self.log('val/psnr', mean_psnr, prog_bar=True) # 记录平均 PSNR,并显示在进度条中self.log('val/ssim', mean_ssim, prog_bar=True) # 记录平均 SSIM,并显示在进度条中# 如果使用遮罩,记录其他相关指标if self.hparams.use_mask:self.log('val/c_l', torch.stack([x['c_l'] for x in outputs]).mean()) # 记录 c_l 指标的平均值self.log('val/f_l', torch.stack([x['f_l'] for x in outputs]).mean()) # 记录 f_l 指标的平均值self.log('val/r_ms', torch.stack([x['r_ms'] for x in outputs]).mean()) # 记录 r_ms 指标的平均值self.log('val/r_md', torch.stack([x['r_md'] for x in outputs]).mean()) # 记录 r_md 指标的平均值
这个函数是 PyTorch Lightning 中用于在验证 epoch 结束时执行的方法。它的作用是整合并计算在整个验证集上的损失和指标,以便进行日志记录和报告。
让我们来解释一下这段代码的作用:
全局变量更新:
- 通过检查
outputs的长度来决定是否在全局变量global_val中更新当前 epoch。如果outputs的长度为 1,则将global_val.current_epoch设置为当前的self.current_epoch;否则,将global_val.current_epoch设置为当前的self.current_epoch + 1。计算平均值:
- 从
outputs中提取所有 epoch 的验证损失、PSNR 和 SSIM,并计算它们的平均值。- 将这些平均值记录到训练日志中。
记录其他指标:
- 如果使用了遮罩 (
use_mask),还记录了其他相关指标,如c_l、f_l、r_ms和r_md的平均值。这个方法的主要作用是汇总整个验证集上的指标,并将这些指标记录在训练日志中,以便在训练过程中进行跟踪和分析。
6 main() 详解
def main(hparams):# 创建 NeRFSystem 实例system = NeRFSystem(hparams)# 设置模型保存的检查点配置checkpoint_callback = ModelCheckpoint(filepath=os.path.join(hparams.save_dir, f'ckpts/{hparams.exp_name}', '{epoch:d}'),monitor='val/psnr', # 监控 PSNR 指标mode='max', # 以最大值作为监控模式save_top_k=-1 # 保存所有检查点)# 设置日志记录器logger = TestTubeLogger(save_dir=os.path.join(hparams.save_dir, "logs"), # 日志保存路径name=hparams.exp_name, # 实验名称debug=False, # 调试模式create_git_tag=False, # 是否创建 git taglog_graph=False # 是否记录图表)# 设置训练器 Trainertrainer = Trainer(max_epochs=hparams.num_epochs, # 最大 epoch 数checkpoint_callback=checkpoint_callback, # 检查点配置resume_from_checkpoint=hparams.ckpt_path, # 从检查点路径恢复logger=logger, # 日志记录器weights_summary=None, # 不显示权重摘要progress_bar_refresh_rate=hparams.refresh_every, # 进度条刷新频率gpus=hparams.num_gpus, # GPU 数量accelerator='ddp' if hparams.num_gpus > 1 else None, # 使用分布式数据并行(如果有多个 GPU)num_sanity_val_steps=-1, # 验证步数benchmark=True, # 启用性能基准profiler="simple" if hparams.num_gpus == 1 else None # 使用简单的性能分析器(单 GPU))# 开始模型训练trainer.fit(system)
主函数主要是用于设置训练过程的配置,并调用
Trainer来训练NeRFSystem模型。配置包括模型保存的检查点、日志记录器、训练器的设置等。Trainer类是 PyTorch Lightning 提供的用于管理训练循环的高级接口。
if __name__ == '__main__':# 获取命令行参数作为超参数hparams = get_opts()# 调用主函数开始训练main(hparams)相关文章:
Ha-NeRF源码解读 train_mask_grid_sample
目录 背景: (1)Ha_NeRF论文解读 (2)Ha_NeRF源码复现 (3)train_mask_grid_sample.py 运行 train_mask_grid_sample.py解读 1 NeRFSystem 模块 2 forward()详解 3 模型训练tranining_st…...

大数据毕业设计选题推荐-系统运行情况监控系统-Hadoop-Spark-Hive
✨作者主页:IT毕设梦工厂✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Py…...
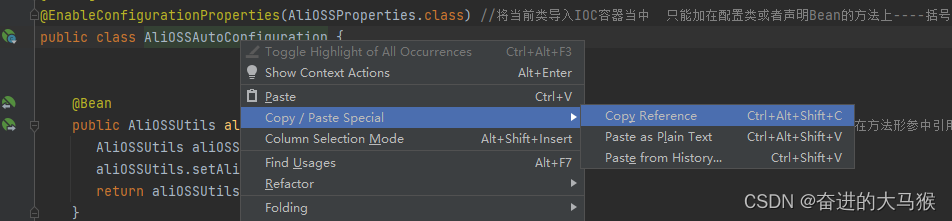
SpringBoot----自定义Start(自定义依赖)
一,为什么要定义Start 向阿里云OSS如果我们要引入的话很麻烦,所以我们可以自定义一些组件, 然后我们只需要在pom文件中引入对应的坐标就可以 二,怎么定义(以阿里云OSS为例) 1, 定义两个组件模块…...
通过条件竞争实现内核提权
条件竞争漏洞(Race Condition Vulnerability)是一种在多线程或多进程并发执行时可能导致不正确行为或数据损坏的安全问题。这种漏洞通常发生在多个线程或进程试图访问和修改共享资源(如内存、文件、网络连接等)时,由于…...

vue实现换肤功能
1、使用scss定义几种需要进行换肤的颜色,例如: .font-color-theme{[color-theme"black"] & {color: #000}[color-theme"white"] & {color: #fff} }2、使用以下代码控制变化; let colorType localStorage.getIt…...
)
嵌入式软件工程师面试题——2025校招社招通用(八)
说明: 面试题来源于网络书籍,公司题目以及博主原创或修改(题目大部分来源于各种公司);文中很多题目,或许大家直接编译器写完,1分钟就出结果了。但在这里博主希望每一个题目,大家都要…...

背包笔记
01背包 朴素版01背包 cin >> n >> m; f[0][0] 0; for(int i 1; i < n; i ) {for(int j 0; j < m; j ){f[i][j] f[i - 1][j];//第i个物品不选if(j - v[i] > 0){f[i][j] max(f[i][j], f[i - 1][j - v[i]] w[i]);//选第i个物品}} }cout << f[n…...
)
【Redis 速通】Redis 在 Linux 上的单机服务快速搭建与部署(附完整流程步骤及命令代码)
Redis 单机版安装与部署 Written By: Xinyao Tian 概述 本文档主要描述了 Redis 的生产环境安装及配置方法。 主要步骤 编译及安装 进入 root 用户并上传 Redis 源码安装包 查看 Redis 源码安装包的上传情况: [rootcentos-host redis]# pwd /opt/redis [root centos-ho…...
前端JavaScript
文章目录 一、JavaScript概述JS简介1.ECMAScript和JavaScript的关系2.ECMAScript的历史3.什么是javas?4.JavaScript的作用? 三者之间的作用JS基础1.注释语法2.引入js的多种方式3.结束符号 变量与常量变量1.JavaScript声明2.var与let的区别常量 基本数据类…...

C语言程序设计(第五版)谭浩强 第三章课后题答案
第三章 1、假如我国国民生产总值的年增长率为7%, 计算10年后我国国民生产总值与现在相比增长多少百分比。计算公式为 ,其中r为年增长率,n为年数,p为与现在相比的倍数。 #include<stdio.h> #include<math.h>int main(){float r,…...
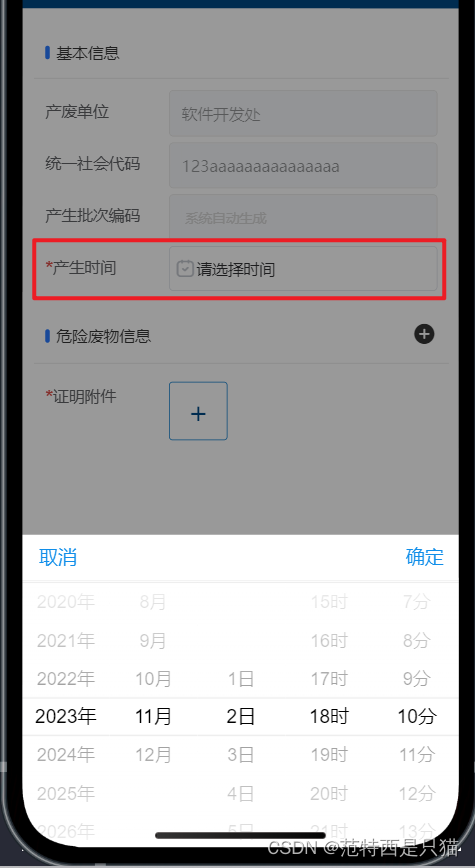
uni-app 解决钉钉小程序日期组件uni-datetime-picker不兼容ios问题
最近在使用uni-app开发 钉钉小程序 ,遇到一个ios的兼容性问题 uni-datetime-picker 组件在模拟器上可以使用,在真机上不生效问题 文章目录 1. 不兼容的写法,uni-datetime-picker 不兼容IOS2. 兼容的写法,使用 dd.datePicker 实现。…...

【C++入门 三】学习C++缺省参数 | 函数重载 | 引用
C入门 三 1.缺省参数1.1 缺省参数概念1.2 缺省参数分类 2. 函数重载2.1 函数重载概念2.2 C支持函数重载的原理--名字修饰(name Mangling) 3.引用3.1引用概念3.2引用特性3.3 常引用3.4 使用场景1. 做参数2. 做返回值 3.5 传值、传引用效率比较3.6引用和指针的区别 4.引用和指针的…...

视频增强修复软件Topaz Video AI mac中文版支持功能
Topaz Video AI mac是一款使用人工智能技术对视频进行增强和修复的软件。它可以自动降噪、去除锐化、减少压缩失真、提高清晰度等等。Topaz Video AI可以处理各种类型的视频,包括低分辨率视频、老旧影片、手机录制的视频等等。 使用Topaz Video AI非常简单ÿ…...

C# 使用Thread类建线程
C# 使用Thread类建线程 目录 C# 使用Thread类建线程引言Thread类启动线程优先级后台运行线程状态线程名称线程ID最后 引言 线程(thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。线程是我们程序常用的并行运行控制手段,…...

asyncio协程框架
asyncio 基本用法 asyncio 包含以下几个主要的组件:协程 asyncio 支持使用 async/await 语法定义协程(coroutine)。协程是可以暂停和恢复执行的函数,可以实现非阻塞式的异步编程。 import asyncioasync def coroutine():print(H…...
TSINGSEE智慧安防:AI人员入侵检测算法的工作原理及应用场景概述
人员入侵检测算法基于视频分析技术,自动对视频画面进行分析识别,可以对危险区的人员闯入、靠近等行为进行实时进行检测并预警,无需人工干预,协助管理者对场所的安全问题进行监管,可以广泛运用在学校、园区、工地、车站…...
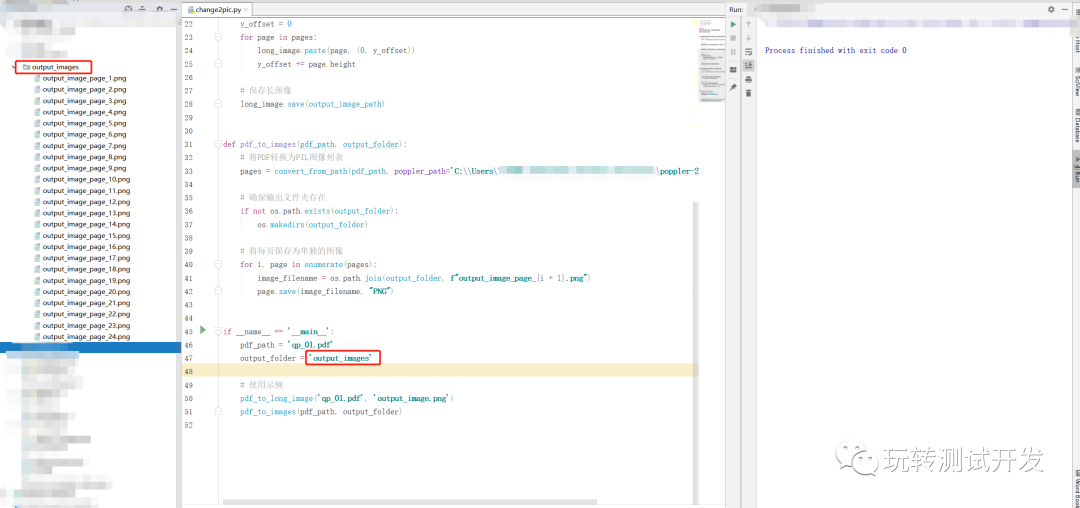
Python:PDF转长图像和分页图像
简介:随着电子化文档的普及,PDF文件的使用频率越来越高。有时我们需要将PDF中的内容转化为图片格式进行分享或编辑,那么如何才能轻松地完成此任务呢?本文将为你展示一个Python工具:如何将PDF文件转化为图片,…...

第48天:内置对象方法、 前端基础之BOM和DOM
内置对象方法 RegExp对象 // 定义正则表达式两种方式 var reg1 new RegExp("^[a-zA-Z][a-zA-Z0-9]{5,11}"); var reg2 /^[a-zA-Z][a-zA-Z0-9]{5,9}$/;// 正则校验数据 reg1.test(jason666) reg2.test(jason666)/*第一个注意事项,正则表达式中不能有空格…...

CMake系列EP02: 构建可执行程序和库
文章目录 cmake --buildmessage命令切换生成器使用ninja构建项目切换生成器的工作原理 构建和链接静态库和动态库add_library命令add_executable命令构建OBJECT类型的库条件编译opion命令option更多信息 指定编译器构建类型切换构建类型: 设置编译器选项cmake调试设…...

比亚迪今年的薪资。。
大家或许已经对比亚迪在西安的宣讲会有所耳闻,那场面真的是座无虚席。如果你稍微迟到了一些,那么你可能只能在门外或是走廊听了。 事实上,许多人早早地抵达了,只要稍微晚到,就可能错过了室内的位置。 更令人震惊的是&…...

Kettle的优势
Kettle说具有非常强大的数据处理功能,没有做不到只有你想不到或者你还没有学会使用,如果确实做不到的情况下你还可以开发插件来进行数据处理,其中Kettle也提供了广泛的数据处理和转换功能,包括数据抽取、清洗、转换、合并、过滤等…...

你的 FlashAttention 真的在跑吗?几个简单方法确认
之前有个朋友在昇腾 NPU 上部署模型,按文档开了 --enable-flash-attn,跑起来也没报错。但他总觉得延迟不对——跟之前没开的时候差不多。他问我:怎么确认 FlashAttention 真的生效了?不会是静默降级了吧? 这个问题问得…...

Java Web中基于JWT的七层权限控制系统设计
1. 为什么JWT不是“万能钥匙”,而是一个需要精心设计的权限信封在Java Web开发中,一提到权限控制,很多人第一反应就是“加个Spring Security,配个JWT,不就完事了?”我去年接手一个医疗SaaS系统的权限模块重…...

避开BLE开发第一个坑:搞懂广播帧里的TxAdd、ChSel字段,让你的智能硬件不再‘隐身’
避开BLE开发第一个坑:广播帧关键字段解析与实战排查指南 当你第一次将精心编写的固件烧录进蓝牙芯片,满心期待地用手机扫描设备时,却发现屏幕上空空如也——这种"设备隐身"的挫败感,几乎每个BLE开发者都经历过。问题的根…...

Spring Cloud Feign本地调试路由增强方案设计与实现
1. 项目概述:当Feign遇上本地调试的“网络鸿沟”在微服务架构里混迹多年的老手,对OpenFeign这个组件肯定不陌生。它用起来确实爽,一个接口加几个注解,服务间的远程调用就像调用本地方法一样简单,把HTTP通信的复杂性都封…...

【ChatGPT】光纤激光器及其控制系统深度拆解、信息图10张、爆炸图10张、C++代码框架增强版Mermaid 流程图、时序图、类图与成员说明
作者简介:许冲,主要分享各领域系统/设备拆解、代码框架、信息图、爆炸图。深度拆解信息图...

医疗学术会议直播,和你想的不一样
从大学阶梯教室到五星级酒店宴会厅,从脊柱外科到肿瘤学术年会,VideoTV团队这3年做了30场医疗学术会议直播。有些坑踩过一次就不会再踩,有些坑每次都能遇到新花样。这篇文章不讲大道理,直接说我们在执行层面踩过哪些坑、怎么解决的…...

源代码论文分享|基于 Spring Boot 的校园商铺管理系统!
很多同学选毕业设计时都会纠结:题目太简单,怕老师觉得没含金量;题目太复杂,又怕自己做不完。 其实像校园商铺管理系统这种项目,就挺适合拿来做毕设或课程设计。它有真实场景,功能也能展开,技术…...

3个步骤让你的Switch Joy-Con在Windows上焕发新生:JoyCon-Driver完全指南
3个步骤让你的Switch Joy-Con在Windows上焕发新生:JoyCon-Driver完全指南 【免费下载链接】JoyCon-Driver A vJoy feeder for the Nintendo Switch JoyCons and Pro Controller 项目地址: https://gitcode.com/gh_mirrors/jo/JoyCon-Driver 你是否曾想过让闲…...

软件测试会被AI取代吗?我用数据告诉你真相
在探讨“取代”之前,我们先看一组具有代表性的数据。根据Gartner的预测,到2027年,80%的企业将把AI驱动的测试工具整合进其测试流程中,目前这一比例仅为大约20%。与此同时,World Quality Report显示,过去五年…...