从InnoDB索引的数据结构,去理解索引
从InnoDB索引的数据结构,去理解索引
- 1、InnoDB 中的 B+Tree
- 1.1、B+Tree 的组成
- 1.2、B+Tree中的数据页
- 2、聚簇索引
- 2.1、聚簇索引的特点
- 2.2、聚簇索引的结构示例
- 2.3、聚簇索引的优缺点
- 3、非聚簇索引
- 3.1、非聚簇索引结构示例
- 3.2、关于回表
- 3.3、聚簇索引和非聚簇索引的区别与代价
- 4、扩展与问答
- 4.1、InnoDB 和 MyISAM 对比
- 4.2、MySQL使用InnoDB存储引擎时,为什么不建议使用过长的字段作为主键 ?
- 4.3、MySQL使用InnoDB存储引擎时,为何不建议使用非单调字段(不是按照递增或递减的顺序进行排列的字段)作为主键 ?
- 4.4、一般情况下,为何我们用到的B+Tree 都不会超过4层 ?
该篇我们都是基于 InnoDB 存储引擎的大前提下讨论的,如文中未明确指出存储引擎,一律说的是 InnoDB.
要知道 InnoDB 的索引数据结构主要是 B+Tree. 按照物理实现方式,可以将索引划分为聚簇索引和非聚簇索引(也称为 二级索引、辅助索引)。
1、InnoDB 中的 B+Tree
1.1、B+Tree 的组成
-
①
根节点:B+Tree的最顶层节点,如果树的高度大于1,则根节点可以有多个子节点。 -
②
内部节点(也称为内节点、非叶子节点):除根节点和叶子节点之外的节点,每个内部节点包含多个键值对和指向子节点的指针。内部节点用于索引,不存储实际的数据。内节点用于存放目录项。InnoDB 的B+Tree中,内节点中的目录项记录必须保证唯一性,所以对于二级索引而言,二级索引(非聚簇索引)中必须包含主键列。 -
③
叶子节点:位于B+Tree最底层的节点,存储实际的数据(用户记录)或索引键值。叶子节点之间通过指针相互连接,形成一个链表结构,便于进行范围查询和排序操作。
不论是存放 用户记录(指这个记录中存储了所有列的值,包括隐藏列)的数据页,还是存放目录项记录的数据页,我们都把它们存放在 B+Tree 这个数据结构中,故我们也称这些数据页为节点。每个节点(包括根节点、内部节点和叶子节点)都包含多个键值对和指向子节点的指针。B+Tree通过这种结构,将数据存储在一个平衡的多路搜索树中,从而提高了查询性能和数据访问的效率。
1.2、B+Tree中的数据页
- 在B+Tree中,页是数据存储的基本单位,也是磁盘I/O操作的最小单元。每个页通常具有固定的大小,例如InnoDB存储引擎中,页的大小默认为16KB。
- 页中包含了节点的键值对数据和指向子节点的指针等信息。
- 通俗来讲,一个叶子节点中有一页数据,一页数据中包含了多条用户记录、主键等信息。每页包含的数据量,与每条用户记录的大小、索引大小等相关。一个非叶子节点中也有一页数据,其包含主键、二级索引字段、下级页码等数据。
在InnoDB的一个数据页中,至少存放两条数据记录。
对于非叶子节点,每个页存储了多个键值对和指向子节点的指针,用于索引和导航到下一层的页。对于叶子节点,每个页存储了实际的数据或索引键值,以及指向相邻叶子节点的指针,用于范围查询和排序操作。通过页的设计,B+Tree可以高效地利用存储空间,减少磁盘I/O操作次数,提高查询性能和数据访问的效率。
2、聚簇索引
InnoDB存储引擎的聚簇索引,是一种按照主键顺序存储数据的索引结构(由于是主键顺序存储,故主键尽量用有序的)。聚簇索引的叶子节点就是数据节点,且数据都是按照主键排序存储的。其特点是将索引和数据行,保存在同一个B+Tree中,因此查询通过聚簇索引可以直接获取数据。二级索引(非聚簇索引)中必须包含主键列,所以如果主键列很大的话,其他的索引也会占用很大的空间。
InnoDB 的一个表,要求必须有聚簇索引,且只能有一个聚簇索引。InnoDB如果没有显示指定,MySQL系统会自动选择一个非空且唯一的列作为聚簇索引,如果不存在这样的列,MySQL 会自动为 InnoDB 表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整型。一般主键即为聚簇索引,建议主键自增。
2.1、聚簇索引的特点
-
使用记录主键值的大小进行记录和页的排序,这包含三方面的含义:
页内的记录是按照主键的大小顺序排成一个单向链表。- 各个存放
用户记录的页也是根据页中用户记录的主键大小顺序排成一个双向链表。 - 存放
目录项记录的页分为不同的层次,在同一层次中的页,也是根据页中目录项记录的主键大小顺序排成一个双向链表。
-
B+Tree 的
叶子节点存储的是完整的用户记录。所谓用户记录,就是指这个记录中存储了所有列的值(包括隐藏列)。
2.2、聚簇索引的结构示例
以下示例使用 tb_table 表为例,tb_table表使用 InnoDB 引擎,其中包含 c1、c2、c3、c4、c5 五个字段,其中 c1 为主键,即聚簇索引。
- 表数据示例:
| c1(主键8) | c2 | c3 | c4 | c5 |
|---|---|---|---|---|
| 1 | 4 | u | 44 | u |
| 3 | 9 | d | 99 | d |
| 4 | 4 | a | 44 | aa |
| 5 | 3 | y | 33 | yy |
| 8 | 7 | a | 71 | aa |
| 10 | 4 | o | 44 | oe |
| 12 | 7 | d | 77 | q |
| 20 | 2 | e | 12 | tt |
| 43 | 9 | x | 32 | xx |
| 59 | 5 | b | 53 | u |
| 76 | 6 | i | 41 | e |
| 87 | 8 | a | 88 | aa |
| 99 | 5 | m | 55 | d |
- 聚簇索引结构示例:

2.3、聚簇索引的优缺点
| 优点 | 缺点 |
|---|---|
数据访问更快,因为聚簇索引将索引和数据保存在同一个B+Tree中,节省大量的 io 操作。 | 插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。所以对于 InnoDB 引擎的表,一般建议 自增的ID列作为主键。 |
聚簇索引对主键的 排序查找 、范围查找 速度非常快。 | 更新主键的代价很高,更新主键会导致被更新的行移动,页分裂调整。一般建议 主键为不可更新。 |
| _ | 二级索引访问需要两次索引查找。使用二级索引查找时,第一次找到主键值,第二次根据主键值找到行数据,这个过程也就是回表。 |
3、非聚簇索引
InnoDB的非聚簇索引也称为二级索引或辅助索引,它是一种基于聚簇索引创建的索引结构。非聚簇索引的叶子节点并不直接存储实际的数据行,而是存储了创建非聚簇索引的字段和聚簇索引的主键值。InnoDB的非聚簇索引也是按照B+Tree的数据结构来组织的,这样可以保证查询的高效性。
3.1、非聚簇索引结构示例
- 非聚簇索引结构示例(表结构数据同 聚簇索引上述示例,其中以 c2 字段作为非聚簇索引字段):

3.2、关于回表
说到非聚簇索引,就不得不说【回表】的概念。
我们根据非聚簇索引(二级索引)列的大小排序的 B+Tree,只能确定我们要查找记录的主键,所以如果我们要根据非聚簇索引去做查询,但查询的字段中,除了该非聚簇索引字段还包括其他字段,那就要根据非聚簇索引先查到相关用户记录的主键,再根据主键去查该用户记录行的完整数据,再筛选出需要查询的字段。
总结一下,通过非聚簇索引查询时,如果查询的字段不仅仅是该非聚簇索引字段时,就需要使用到 2 棵 B+Tree,这个过程就叫回表。
3.3、聚簇索引和非聚簇索引的区别与代价
| 聚簇索引和非聚簇索引的区别 | 索引的代价 |
|---|---|
① 聚簇索引的叶子节点存储的是数据记录,非聚簇索引的叶子节点存储的是 数据位置。非聚簇索引不会影响数据表的物理存储顺序。 | ① 空间上的代价:每建立一个索引都要为它建立一棵 B+Tree 树,每棵 B+Tree 树的每个节点都是一个数据页,一个数据页默认会占用 16KB 的存储空间,一棵 B+Tree 由许多数据页组成,那就是一个比较大的存储空间。 |
② 对于InnoDB存储引擎而言,一个表只能有一个聚簇索引,因为只能有一种排序存储的方式。可以有多个非聚簇索引,也就是多个索引目录提供数据检索。 | ② 时间上的代价:每次对表中的数据进行 增、删、改 操作时,都会去修改各个 B+Tree 索引。B+Tree 每层节点都是按照索引列的值 从小到大的顺序排序 而组成 双向链表。不论是叶子节点中的记录,还是内节点中的记录,都是按照索引列的值,从小到大的顺序而形成的一个单向链表.增删改操作可能会对节点和记录的排序造成破坏,存储引擎需要额外的时间进行记录移位、页面分裂、页面回收等操作来维护好节点和记录的排序。 |
③ 使用聚簇索引的时候,数据的 查询效率高,但是如果对数据进行插入、删除、更新等操作,效率会比非聚簇索引低。 | ③ 一个表上的索引建的越多,就会占用越多的存储空间,在增删改记录的时候性能就越差。 |
4、扩展与问答
4.1、InnoDB 和 MyISAM 对比
MyISAM 的索引方式都是非聚簇的;InnoDB有一个聚簇索引,可以有多个非聚簇索引。- 在InnoDB 的数据文件本身就是索引文件;MyISAM 索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。
- 在 InnoDB 存储引擎中,我们只需要根据主键值对 聚簇索引 进行一次查找就能找到对应的记录,而在 MyISAM 中需要进行一次回表操作,意味着 MyISAM 中建立的索引相当于全部都是二级索引。
- InnoDB 的非聚簇索引 data域存储相应记录的主键值,而MyISAM索引记录的是地址。换句话说,InnoDB的所有非聚簇索引都引用主键作为data域。
- MyISAM 的回表操作是十分快速的,因为是拿着地址偏移量直接到文件中取数据的。InnoDB是通过获取主键之后再去聚簇索引里找记录,虽然也不慢,但还是比不上直接拿地址去获取。
InnoDB要求必须有聚簇索引(MyISAM可以没有)。InnoDB如果没有显示指定,MySQL系统会自动选择一个非空且唯一的列作为聚簇索引,如果不存在这样的列,MySQL 会自动为 InnoDB 表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整型。
4.2、MySQL使用InnoDB存储引擎时,为什么不建议使用过长的字段作为主键 ?
答:所有二级索引都引用主键索引(聚簇索引),过长的主键索引会让二级索引变得过大。
4.3、MySQL使用InnoDB存储引擎时,为何不建议使用非单调字段(不是按照递增或递减的顺序进行排列的字段)作为主键 ?
答:InnoDB的数据文件本身就是一颗B+Tree,非单调的主键会造成在插入新记录时,数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效。而使用自增字段作为主键则是一个很好的选择。
4.4、一般情况下,为何我们用到的B+Tree 都不会超过4层 ?
答:可以初步估算一下,单表的数据存储情况。假设所有存放用户记录的叶子节点代表的数据页可以存放 100 条用户记录,所有存放目录项的记录的内节点代表的数据页可以存放1000条目录项记录,那么:
- 如果B+Tree只有 1 层,也就是只有一个用于存放用户记录的节点,最多存放 100条记录。
- 如果B+Tree只有 2 层,最多存放的 1000 * 100 = 100,000 条记录(即十万条)。
- 如果B+Tree只有 3 层,最多存放的 1000 * 1000 * 100 = 100,000,000 条记录(即一亿条)。
- 如果B+Tree只有 4 层,最多存放的 1000 * 1000 * 1000 * 100 = 100,000,000,000 条记录(即一千亿条)。
系列文章:
一: 《搞懂 MySql 的架构和执行流程》
二: 《从InnoDB索引的数据结构,去理解索引》
三: 《从 Hash索引、二叉树、B-Tree 与 B+Tree 对比看索引结构选择》
四: 《MySQL 的索引分类和设计原则》
五: 《MySQL 优化思路篇》
.
相关文章:
从InnoDB索引的数据结构,去理解索引
从InnoDB索引的数据结构,去理解索引 1、InnoDB 中的 BTree1.1、BTree 的组成1.2、BTree中的数据页 2、聚簇索引2.1、聚簇索引的特点2.2、聚簇索引的结构示例2.3、聚簇索引的优缺点 3、非聚簇索引3.1、非聚簇索引结构示例3.2、关于回表3.3、聚簇索引和非聚簇索引的区…...

Nacos:动态服务发现与配置管理的终极解决方案
今天我想和大家分享一下Nacos,这是一个由阿里巴巴开源的动态服务发现、配置和服务管理平台。我将详细介绍Nacos的主要特性,并通过实例来演示如何使用它。同时,我还会指出Nacos的优点,希望这篇文章能够帮助大家更好地理解和使用Nac…...
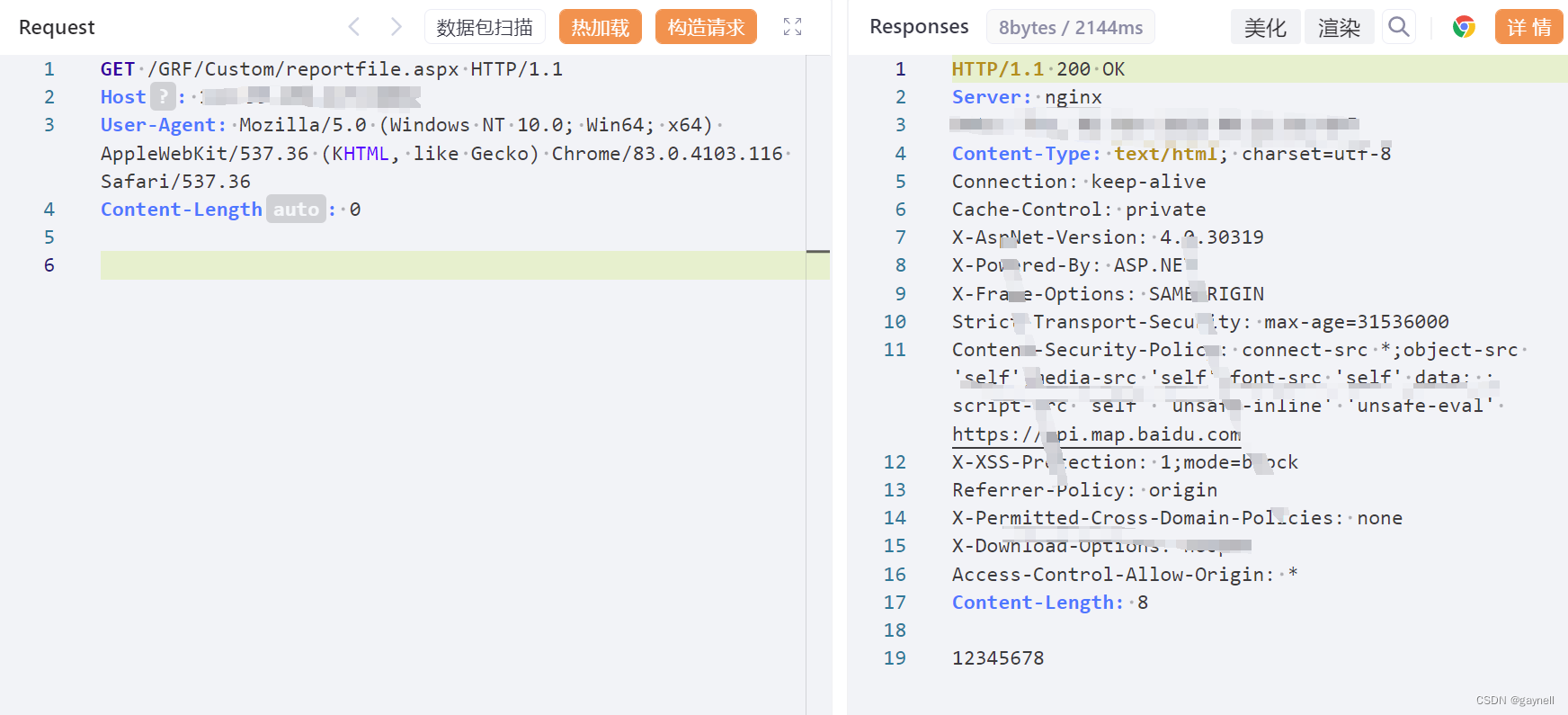
易思无人值守智能物流系统Sys_ReportFile文件上传漏洞复现
文章目录 易思无人值守智能物流系统Sys_ReportFile文件上传漏洞复现0x01 前言0x02 漏洞描述0x03 影响版本0x04 漏洞环境0x05 漏洞复现1.访问漏洞环境2.构造POC3.复现 0x06 修复建议 易思无人值守智能物流系统Sys_ReportFile文件上传漏洞复现 0x01 前言 免责声明:请…...

java Map List转化,通过Map保存数据,通过List排序。取前三名
java Map List转化,通过Map保存数据,通过List排序。取前三名 package yo;import java.util.ArrayList; import java.util.Collections; import java.util.HashMap; import java.util.List; import java.util.Map;public class a {public static void …...

LEECODE 1480一维数组的动态和
class Solution { public:vector<int> runningSum(vector<int>& nums) {vector<int> runningSum;int sum 0;int len nums.size();for(int i 0; i < len; i){sum sum nums[i];runningSum.push_back(sum);}return runningSum;} };...

python文档链接
python与并行计算...

HTTP调试代理工具/Proxyman
Proxyman专为开发人员和网络爱好者设计,它允许用户拦截、查看和修改所有传入和传出的网络请求,并提供详细的分析和调试功能。 Proxyman支持HTTP、HTTPS和WebSocket协议,因此,可以轻松捕获和查看这些协议下的网络流量。用户可以使…...
搭建Qt5.7.1+kylinV10开发环境、运行环境
1.下载Qt源码 Index of / 2.编译Qt 解压缩qt-everywhere-opensource-src-5.7.1.tar.gz 进入到qt-everywhere-opensource-src-5.7.1/qtbase/mkspecs这个目录下, 2.1找到以下目录 复制他,然后改名linux-x86-arrch64,博主这里名字取的有些问…...
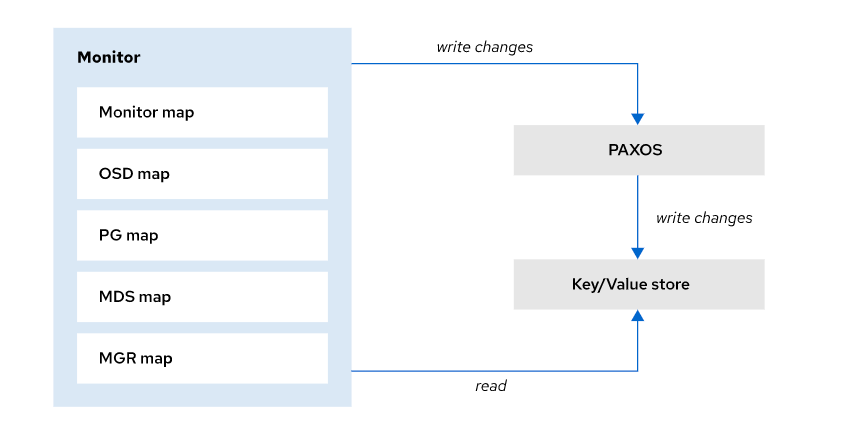
Ceph:关于Ceph 中创建和管理自定义 CRUSH Map
写在前面 准备考试,整理 Ceph 相关笔记博文内容涉及,管理和定制CRUSH Map以及管理OSD Map理解不足小伙伴帮忙指正 对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所…...

【Linux】开发工具——vim多模式编辑器的入土设置sudoers白名单
个人主页点击直达:小白不是程序媛 Linux系列专栏:Linux被操作记 目录 前言: 基本概念 vim基本操作 [正常模式]切换至[插入模式] [插入模式]切换至[正常模式] [正常模式]切换至[末行模式] 三种模式的切换关系图 vim命令模式命令集 进…...
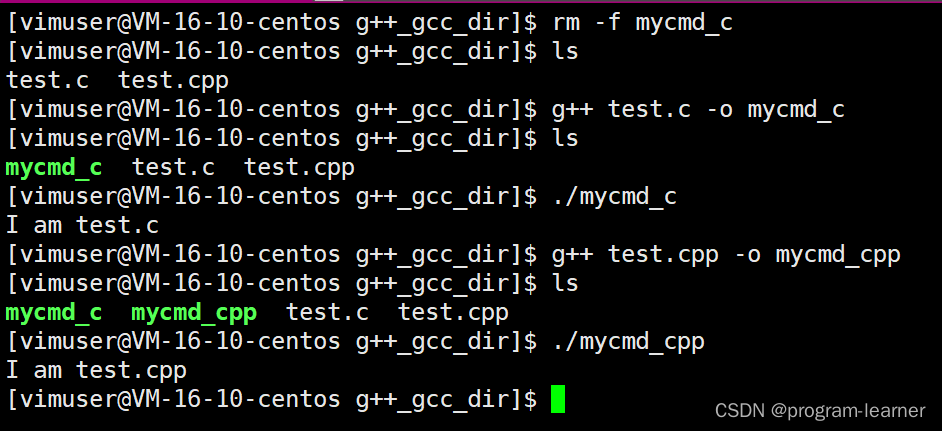
Linux基础环境开发工具的使用(yum,vim,gcc,g++)
Linux基础环境开发工具的使用[yum,vim,gcc,g] 一.yum1.yum的快速入门1.yum安装软件2.yum卸载软件 2.yum的生态环境1.操作系统的分化2.四个问题1.服务器是谁提供的呢?2.服务器上的软件是谁提供的呢?3.为什么要提供呢?4.yum是如何得知目标服务器的地址和下载链接呢?5.软件源 …...

加速软件开发和交付的革命性方法-DevOps
“ 随着信息技术的快速发展,现代软件开发和交付已经经历了巨大的变革。DevOps(Development和Operations的结合)已经成为这一变革的关键推动力,让开发团队和运维团队之间的界限变得模糊,以加速软件的开发、测试和部署过…...
Ha-NeRF源码解读 train_mask_grid_sample
目录 背景: (1)Ha_NeRF论文解读 (2)Ha_NeRF源码复现 (3)train_mask_grid_sample.py 运行 train_mask_grid_sample.py解读 1 NeRFSystem 模块 2 forward()详解 3 模型训练tranining_st…...

大数据毕业设计选题推荐-系统运行情况监控系统-Hadoop-Spark-Hive
✨作者主页:IT毕设梦工厂✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Py…...
SpringBoot----自定义Start(自定义依赖)
一,为什么要定义Start 向阿里云OSS如果我们要引入的话很麻烦,所以我们可以自定义一些组件, 然后我们只需要在pom文件中引入对应的坐标就可以 二,怎么定义(以阿里云OSS为例) 1, 定义两个组件模块…...
通过条件竞争实现内核提权
条件竞争漏洞(Race Condition Vulnerability)是一种在多线程或多进程并发执行时可能导致不正确行为或数据损坏的安全问题。这种漏洞通常发生在多个线程或进程试图访问和修改共享资源(如内存、文件、网络连接等)时,由于…...

vue实现换肤功能
1、使用scss定义几种需要进行换肤的颜色,例如: .font-color-theme{[color-theme"black"] & {color: #000}[color-theme"white"] & {color: #fff} }2、使用以下代码控制变化; let colorType localStorage.getIt…...
)
嵌入式软件工程师面试题——2025校招社招通用(八)
说明: 面试题来源于网络书籍,公司题目以及博主原创或修改(题目大部分来源于各种公司);文中很多题目,或许大家直接编译器写完,1分钟就出结果了。但在这里博主希望每一个题目,大家都要…...

背包笔记
01背包 朴素版01背包 cin >> n >> m; f[0][0] 0; for(int i 1; i < n; i ) {for(int j 0; j < m; j ){f[i][j] f[i - 1][j];//第i个物品不选if(j - v[i] > 0){f[i][j] max(f[i][j], f[i - 1][j - v[i]] w[i]);//选第i个物品}} }cout << f[n…...
)
【Redis 速通】Redis 在 Linux 上的单机服务快速搭建与部署(附完整流程步骤及命令代码)
Redis 单机版安装与部署 Written By: Xinyao Tian 概述 本文档主要描述了 Redis 的生产环境安装及配置方法。 主要步骤 编译及安装 进入 root 用户并上传 Redis 源码安装包 查看 Redis 源码安装包的上传情况: [rootcentos-host redis]# pwd /opt/redis [root centos-ho…...

嘉立创EDA专业版安装避坑指南:从下载到第一个ESP32项目实战
嘉立创EDA专业版安装避坑指南:从下载到第一个ESP32项目实战 第一次打开嘉立创EDA专业版时,那个深蓝色界面让我想起了学生时代第一次接触电路设计的场景。作为国产EDA工具的后起之秀,它用更符合国人习惯的操作逻辑和实惠的打板政策,…...

2026 年招聘效率升级:高匹配候选人推荐的 AI 实践路径
招聘的核心目标是快速找到适配岗位的人才,而简历筛选与候选人推荐是决定招聘效率的关键环节。传统招聘模式下,HR 需手动比对简历与岗位要求,不仅耗时久,还易因主观判断遗漏高匹配候选人。随着 AI 技术在人力资源领域的深度应用&am…...

源代码论文分享|社区养老服务平台的设计与实现!
有些毕业设计题目,听起来不是特别“炫”,但真的很适合做,也很容易写出实际意义。 比如这次分享的这个项目:社区养老服务平台的设计与实现。 现在社区养老、居家养老、智慧养老这些方向本身就很有现实背景,老师看到这…...
)
用随机森林实现手写英文字母识别(Python实战)
1. 项目概述:用随机森林搞定手写信件识别,这事儿比你想象中更接地气 “How To Perform Letter Recognition in Python Using Random Forest Classifier”——这个标题乍看像教科书里的章节名,但实际拆开来看,它直指一个非常具体、…...

用 jose 正确实现 JWT 签发、验签与密钥轮换
1. 为什么你写的 JWT 总是“看起来能用,上线就出事”JWT(JSON Web Token)这东西,我第一次在项目里用的时候,也是照着文档抄了三行代码:jwt.sign(payload, secret)、jwt.verify(token, secret)、res.json({ …...

通过Taotoken审计日志功能追踪团队API使用情况的实际案例
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken审计日志功能追踪团队API使用情况的实际案例 1. 背景与需求 在团队协作开发中,多个成员或项目共享大模型…...

用 Excel 手算一个 1-6-1 MLP:前向传播、损失、反向传播与参数更新
计算示例:本文用一个单输入、6 个隐藏神经元、单输出的多层感知机(MLP)作为例子,展示如何用 Excel 公式完整复现一次训练迭代。配套 Excel 文件中的“MLP计算过程”工作表已经把前向传播、损失计算、反向传播梯度和参数更新全部写…...

华为交换机Telnet配置保姆级教程:从无认证到AAA认证,手把手带你避坑
华为交换机Telnet安全配置全指南:从基础到企业级实践 远程管理网络设备是每位网络工程师的必备技能,而Telnet作为最传统的远程登录协议之一,至今仍在许多企业环境中广泛使用。记得我刚入行时,第一次通过Telnet成功登录到一台核心交…...

ARM TRBMAR_EL1寄存器解析与调试实践
1. ARM TRBMAR_EL1寄存器深度解析在ARMv8/v9架构的调试子系统中,TRBMAR_EL1(Trace Buffer Memory Attribute Register)是一个关键的控制寄存器,专门用于管理Trace Buffer单元对内存的访问特性。作为一位长期从事ARM架构底层开发的…...

上海生成式引擎优化GEO优选:2026品牌实力与全域智能营销
大模型正在重塑企业被发现、被理解、被比较的路径。过去,企业更关注搜索排名、官网访问和媒体曝光;现在,用户会直接向AI工具询问“上海生成式引擎优化公司哪家好”“上海GEO生成式引擎优化服务商哪家好”“某类企业服务是否值得选择”。这使生…...