Boosting Crowd Counting via Multifaceted Attention之人群密度估计实践
这周闲来无事,看到一篇前不久刚发表的文章,是做密集人群密度估计的,这块我之前虽然也做过,但是主要是基于检测的方式实现的,这里提出来的方法还是比较有意思的,就拿来实践一下。
论文在这里,感兴趣可以看下。



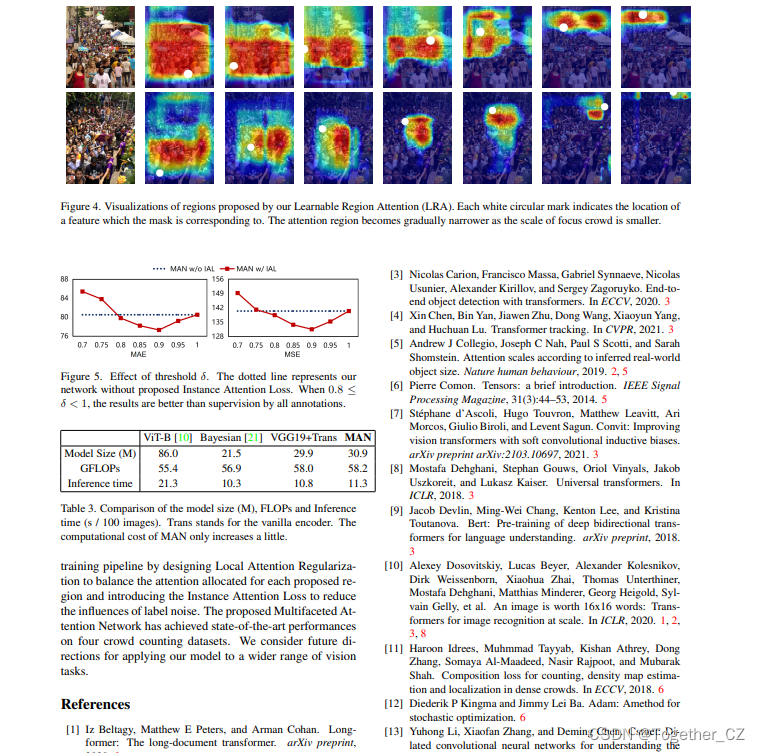
可以看到还是很有意思的。
这里使用的是jhu_crowd_v2.0数据集,如下:

以train为例如下所示:

images目录如下所示:
gt目录如下所示:

实例标注数据如下:
166 228 22 27 1 0
414 218 11 15 1 0
541 232 14 14 1 0
353 213 11 15 1 0
629 222 14 14 1 0
497 243 39 43 1 0
468 222 11 15 1 0
448 227 11 15 1 0
737 220 39 43 1 0
188 228 33 30 1 0
72 198 22 27 1 0
371 214 11 15 1 0
362 242 24 32 1 0
606 260 39 43 1 0
74 228 22 27 1 0
597 226 14 14 1 0
576 213 14 14 1 0数据集详情如下:
This file contains information about the JHU-CROWD++ (v2.0) dataset. -----------------------------------------------------------------------------------------------------
INTRODUCTION
-----------------------------------------------------------------------------------------------------JHU-CROWD++ is a comprehensive dataset with 4,372 images and 1.51 million annotations. In comparison
to existing datasets, the proposed dataset is collected under a variety of diverse scenarios and
environmental conditions. In addition, the dataset provides comparatively richer set of annotations
like dots, approximate bounding boxes, blur levels, etc.-----------------------------------------------------------------------------------------------------
DIRECTORY INFO
-----------------------------------------------------------------------------------------------------
1. The dataset directory contains 3 sub-directories: train, val and test.2. Each of these contain 2 sub-directories (images, gt) and a file "image_labels.txt".3. The "images" directory contains images and the "gt" directory contains ground-truth files corresponding to the images in the images directory.4. The number of samples in train, val and test split are 2272, 500, 1600 respectively.-----------------------------------------------------------------------------------------------------
GROUND-TRUTH ANNOTATIONS: "HEAD-LEVEL"
-----------------------------------------------------------------------------------------------------
1. Each ground-truth file in the "gt" directory contains "space" separated values with each row inidacting x,y,w,h,o,b 2. x,y indicate the head location.3. w,h indicate approximate width and height of the head.4. o indicates occlusion-level and it can take 3 possible values: 1,2,3. o=1 indicates "visible"o=2 indicates "partial-occlusion"o=3 indicates "full-occlusion"5. b indicates blur-level and it can take 2 possible values: 0,1. b=0 indicates no-blur b=1 indicates blur-----------------------------------------------------------------------------------------------------
GROUND-TRUTH ANNOTATIONS: "IMAGE-LEVEL"
-----------------------------------------------------------------------------------------------------
1. Each split in the dataset contains a file "image_labels.txt". This file contains image-level labels.2. The values in the file are comma separated and each row indicates: "filename, total-count, scene-type, weather-condition, distractor"3. total-count indicates the total number of people in the image4. scene-type is an image-level label describing the scene5. weather-condition indicates the weather-degradation in the image and can take 4 values: 0,1,2,3weather-condition=0 indicates "no weather degradation"weather-condition=1 indicates "fog/haze"weather-condition=2 indicates "rain"weather-condition=3 indicates "snow"6. distractor indicates if the image is a distractor. It can take 2 values: 0,1distractor=0 indicates "not a distractor"distractor=1 indicates "distractor"-----------------------------------------------------------------------------------------------------
CITATION
----------------------------------------------------------------------------------------------------- If you find this dataset useful, please consider citing the following work:@inproceedings{sindagi2019pushing,
title={Pushing the frontiers of unconstrained crowd counting: New dataset and benchmark method},
author={Sindagi, Vishwanath A and Yasarla, Rajeev and Patel, Vishal M},
booktitle={Proceedings of the IEEE International Conference on Computer Vision},
pages={1221--1231},
year={2019}
}@article{sindagi2020jhu-crowd,
title={JHU-CROWD++: Large-Scale Crowd Counting Dataset and A Benchmark Method},
author={Sindagi, Vishwanath A and Yasarla, Rajeev and Patel, Vishal M},
journal={Tech Report},
year={2020}
}-----------------------------------------------------------------------------------------------------
LICENSE
----------------------------------------------------------------------------------------------------- This dataset is for academic and non-commercial uses (such as academic research, teaching, scientific
publications, or personal experimentation). All images of the JHU-CROWD++ are obtained from the Internet
which are not property of VIU-Lab, The Johns Hopkins University (JHU). please contact us if you find
yourself or your personal belongings in the data, and we (VIU-Lab) will immediately remove the concernedimages from our servers. By downloading and/or using the dataset, you acknowledge that you have read, understand, and agree to be bound by the following terms and conditions.1. All images are obtained from the Internet. We are not responsible for the content/meaning of these images.
2. Specific care has been taken to reduce labeling errors. Nevertheless, we do not accept any responsibility for errors or omissions.
3. You agree not to reproduce, duplicate, copy, sell, trade, resell or exploit for any commercial purposes, any portion of the images and any portion of derived data.
4. You agree not to use the dataset or any derivative work for commercial purposes as, for example, licensing or selling the data, or using the data with a purpose to procure a commercial gain.
5. All rights not expressly granted to you are reserved by us (VIU-Lab, JHU).
6. You acknowledge that the dataset is a valuable scientific resource and agree to appropriately reference the following papers in any publication making use of the Data & Software:Sindagi et al., "Pushing the frontiers of unconstrained crowd counting: New dataset and benchmark method", ICCV 2019.Sindagi et al., "JHU-CROWD++: Large-Scale Crowd Counting Dataset and A Benchmark Method", Arxiv 2020.首先处理原始数据集如下:

处理完成结果如下:

之后就可以启动模型训练了,因为没有开源出来可用的预训练权重,所以这里是只能自己训练,如下:
from utils.regression_trainer_cosine import RegTrainer
import argparse
import os
import torch
args = Nonedef parse_args():parser = argparse.ArgumentParser(description='Train ')parser.add_argument('--model-name', default='vgg19_trans', help='the name of the model')parser.add_argument('--data-dir', default='./JHU-Train-Val-Test',help='training data directory')parser.add_argument('--save-dir', default='./model',help='directory to save models.')parser.add_argument('--save-all', type=bool, default=False,help='whether to save all best model')parser.add_argument('--lr', type=float, default=5*1e-6,help='the initial learning rate')parser.add_argument('--weight-decay', type=float, default=1e-5,help='the weight decay')parser.add_argument('--resume', default='',help='the path of resume training model')parser.add_argument('--max-model-num', type=int, default=1,help='max models num to save ')parser.add_argument('--max-epoch', type=int, default=120,help='max training epoch')parser.add_argument('--val-epoch', type=int, default=5,help='the num of steps to log training information')parser.add_argument('--val-start', type=int, default=60,help='the epoch start to val')parser.add_argument('--batch-size', type=int, default=8,help='train batch size')parser.add_argument('--device', default='0', help='assign device')parser.add_argument('--num-workers', type=int, default=0,help='the num of training process')parser.add_argument('--is-gray', type=bool, default=False,help='whether the input image is gray')parser.add_argument('--crop-size', type=int, default=512,help='the crop size of the train image')parser.add_argument('--downsample-ratio', type=int, default=16,help='downsample ratio')parser.add_argument('--use-background', type=bool, default=True,help='whether to use background modelling')parser.add_argument('--sigma', type=float, default=8.0, help='sigma for likelihood')parser.add_argument('--background-ratio', type=float, default=0.15,help='background ratio')args = parser.parse_args()return argsif __name__ == '__main__':args = parse_args()torch.backends.cudnn.benchmark = Trueos.environ['CUDA_VISIBLE_DEVICES'] = args.device.strip() # set vis gputrainer = RegTrainer(args)trainer.setup()trainer.train()
训练时间还是很长的,这里等待训练结束后,结果文件如下所示:

日志输出如下所示:
02-14 12:25:04 using 1 gpus
02-14 12:25:10 -----Epoch 0/119-----
02-14 12:27:03 Epoch 0 Train, Loss: 2914.89, MSE: 202.49 MAE: 81.49, Cost 112.6 sec
02-14 12:27:03 -----Epoch 1/119-----
02-14 12:28:45 Epoch 1 Train, Loss: 2691.07, MSE: 128.28 MAE: 44.69, Cost 102.0 sec
02-14 12:28:46 -----Epoch 2/119-----
02-14 12:30:28 Epoch 2 Train, Loss: 2687.40, MSE: 140.69 MAE: 43.30, Cost 102.5 sec
02-14 12:30:29 -----Epoch 3/119-----
02-14 12:32:11 Epoch 3 Train, Loss: 2688.95, MSE: 208.25 MAE: 45.59, Cost 102.1 sec
02-14 12:32:12 -----Epoch 4/119-----
02-14 12:33:55 Epoch 4 Train, Loss: 2682.65, MSE: 163.37 MAE: 39.28, Cost 103.2 sec
02-14 12:33:55 -----Epoch 5/119-----
02-14 12:35:37 Epoch 5 Train, Loss: 2677.02, MSE: 103.38 MAE: 33.43, Cost 102.0 sec
02-14 12:35:38 -----Epoch 6/119-----
02-14 12:37:15 Epoch 6 Train, Loss: 2677.04, MSE: 108.78 MAE: 34.17, Cost 96.5 sec
02-14 12:37:15 -----Epoch 7/119-----
02-14 12:38:58 Epoch 7 Train, Loss: 2676.39, MSE: 97.53 MAE: 33.18, Cost 103.1 sec
02-14 12:38:59 -----Epoch 8/119-----
02-14 12:40:41 Epoch 8 Train, Loss: 2675.40, MSE: 100.08 MAE: 31.75, Cost 102.4 sec
02-14 12:40:42 -----Epoch 9/119-----
02-14 12:42:24 Epoch 9 Train, Loss: 2676.26, MSE: 115.38 MAE: 33.94, Cost 101.8 sec
02-14 12:42:24 -----Epoch 10/119-----
02-14 12:44:07 Epoch 10 Train, Loss: 2674.91, MSE: 107.85 MAE: 31.79, Cost 102.7 sec
02-14 12:44:08 -----Epoch 11/119-----
02-14 12:45:49 Epoch 11 Train, Loss: 2675.62, MSE: 128.87 MAE: 31.46, Cost 101.5 sec
02-14 12:45:50 -----Epoch 12/119-----
02-14 12:47:32 Epoch 12 Train, Loss: 2672.00, MSE: 90.30 MAE: 27.87, Cost 102.0 sec
02-14 12:47:32 -----Epoch 13/119-----
02-14 12:49:14 Epoch 13 Train, Loss: 2671.85, MSE: 93.11 MAE: 28.77, Cost 101.6 sec
02-14 12:49:14 -----Epoch 14/119-----
02-14 12:50:57 Epoch 14 Train, Loss: 2674.60, MSE: 111.70 MAE: 31.27, Cost 102.4 sec为了直观可视化分析,这里我对其结果日志进行可视化展示如下所示:
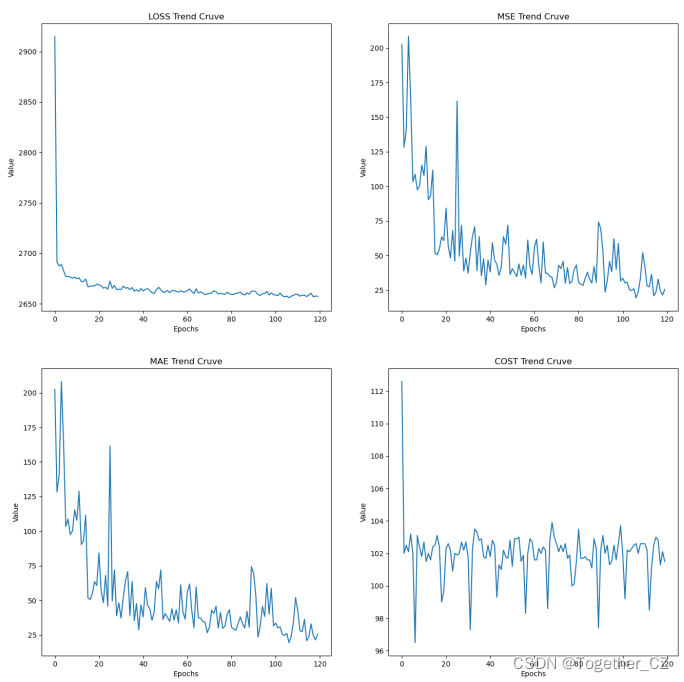
直观来看整体训练还不错。
接下来绘制密度热力图如下:

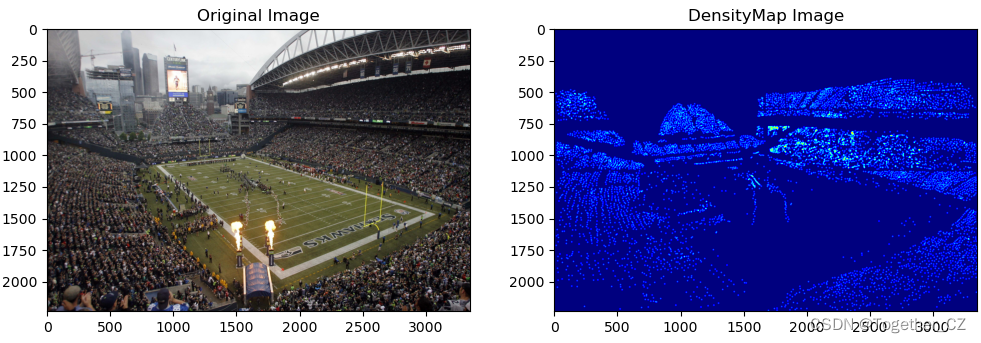
相关文章:
Boosting Crowd Counting via Multifaceted Attention之人群密度估计实践
这周闲来无事,看到一篇前不久刚发表的文章,是做密集人群密度估计的,这块我之前虽然也做过,但是主要是基于检测的方式实现的,这里提出来的方法还是比较有意思的,就拿来实践一下。论文在这里,感兴…...
python之面向对象编程
1、面向对象介绍: 世界万物,皆可分类 世界万物,皆为对象 只要是对象,就肯定属于某种类 只要是对象,就肯定有属性 2、 面向对象的几个特性: class类: 一个类即对一类拥有相同属性的对象的…...
(七))
常见前端基础面试题(HTML,CSS,JS)(七)
同源策略 浏览器有一个重要的安全策略,称之为同源策略 其中,协议、端口号、域名必须一致,,称之为同源,两个源不同,称之为跨源或跨域 同源策略是指,若页面的源和页面运行过程中加载的源不一致…...

产业链金风控基本逻辑
产业链金风控基本逻辑 产业链金融平台作为一个助贷平台,很大程度上是为银行等金融机构进 行引流,贷款的审批本质上还是依赖金融机构的风控。那么,产业链金融 平台是否还有必要建设自己的风控模型呢?笔者给出的答案是肯定的。 一方面&#x…...
Java高级点的知识
Java 集合框架 该框架必须是高性能的。基本集合(动态数组,链表,树,哈希表)的实现也必须是高效的。 该框架允许不同类型的集合,以类似的方式工作,具有高度的互操作性。 对一个集合的扩展和适应…...
MyBatis - 05 - 封装SqlSessionUtil工具类(用于获取SqlSession对象)并测试功能
文章目录1.新建SqlSessionUtils工具类2.编写静态方法3.项目结构及代码项目结构数据库和表pom.xmlParameterMapper接口:User类:ParameterMapper.xmljdbc.propertieslog4j.xml:mybatis-config.xml:ParameterMapperTest测试类:测试结果1.新建Sql…...
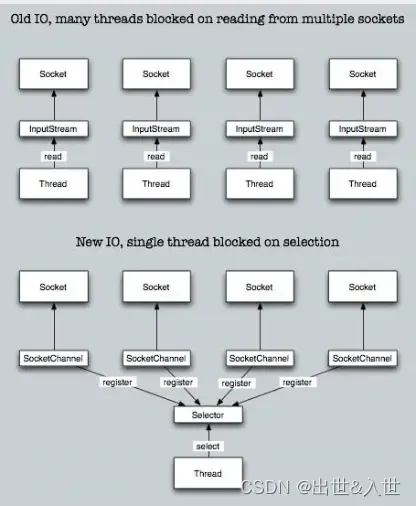
Java中BIO、NIO和AIO的区别和应用场景
IO的方式通常分为几种,同步阻塞的BIO、同步非阻塞的NIO、异步非阻塞的AIO。 一、BIO 在JDK1.4出来之前,我们建立网络连接的时候采用BIO模式,需要先在服务端启动一个ServerSocket,然后在客户端启动Socket来对服务端进行通信&#…...

Python安装教程(附带安装包)
首先,打开python安装包的下载地址,https://www.python.org/downloads/,会有些慢 点击downloads中的windows 左侧是稳定的版本,我这边下的是3.8的,不想去官网下载的可以直接用我下载的这个3.8版本,https://…...

华为OD机试用Python实现 -【信号发射和接收】(2023-Q1 新题)
华为OD机试题 华为OD机试300题大纲信号发射和接收题目描述输入描述输出描述说明示例一输入输出说明示例二输入输出说明Python 代码实现代码运行结果代码编写思路华为OD机试300题大纲 参加华为od机试,一定要注意不要完全背诵代码,需要理解之后模仿写出,通过率才会高。 华为…...

Springboot整合 Thymeleaf增删改查一篇就够了
很早之前写过Thymeleaf的文章,所以重新温习一下,非前后端分离,仅仅只是学习 官网: https://www.thymeleaf.org/ SpringBoot可以快速生成Spring应用,简化配置,自动装配,开箱即用。 JavaConfigur…...

BigScience bloom模型
简介项目叫 BigScience,模型叫 BLOOM,BLOOM 的英文全名代表着大科学、大型、开放科学、开源的多语言语言模型。拥有 1760 亿个参数的模型.BLOOM 是去年由 1000 多名志愿研究人员,学者 在一个名为“大科学 BigScience”的项目中创建的.BLOOM 和今天其他可用大型语言模型存在的一…...

Squid服务的缓存概念
Squid缓存概念 squid是一个缓存服务器的守护进程 之前涉及的缓存服务:redis 2-8原则:80%的访问就是从20%的数据提供的;因此把20%的数据给到缓存–>完美解决等待时间; nginx是没有缓存的服务的;那么专业的事情就…...
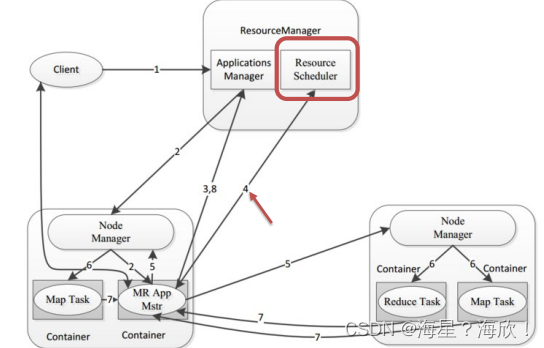
Hadoop YARN
目录Hadoop YARN介绍Hadoop YARN架构、组件程序提交YARN交互流程YARN资源调度器Scheduler调度器策略FIFO SchedulerCapacity SchedulerFair SchedulerHadoop YARN介绍 YARN是一个通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度 上图࿱…...

使用 Macrobenchmark 测试 Android 应用性能
etpack Compose 是推荐用于构建原生 Android 界面的新工具包。后续简称Jetpack Compose为Compose。在了解State之前需要先对Compose及申明性编程式有个大概的了解。State初体验好了,在你有一定了解的基础上,我们先来运行几个Demo,初步了解为何…...
【django】django-simpleui配置后,后台显示空白页解决方法
every blog every motto: You can do more than you think. https://blog.csdn.net/weixin_39190382?typeblog 0. 前言 django后台显示空白页解决方法 1. 正文 添加完simpleui以后,后台显示一片空白,一脸问号??? …...
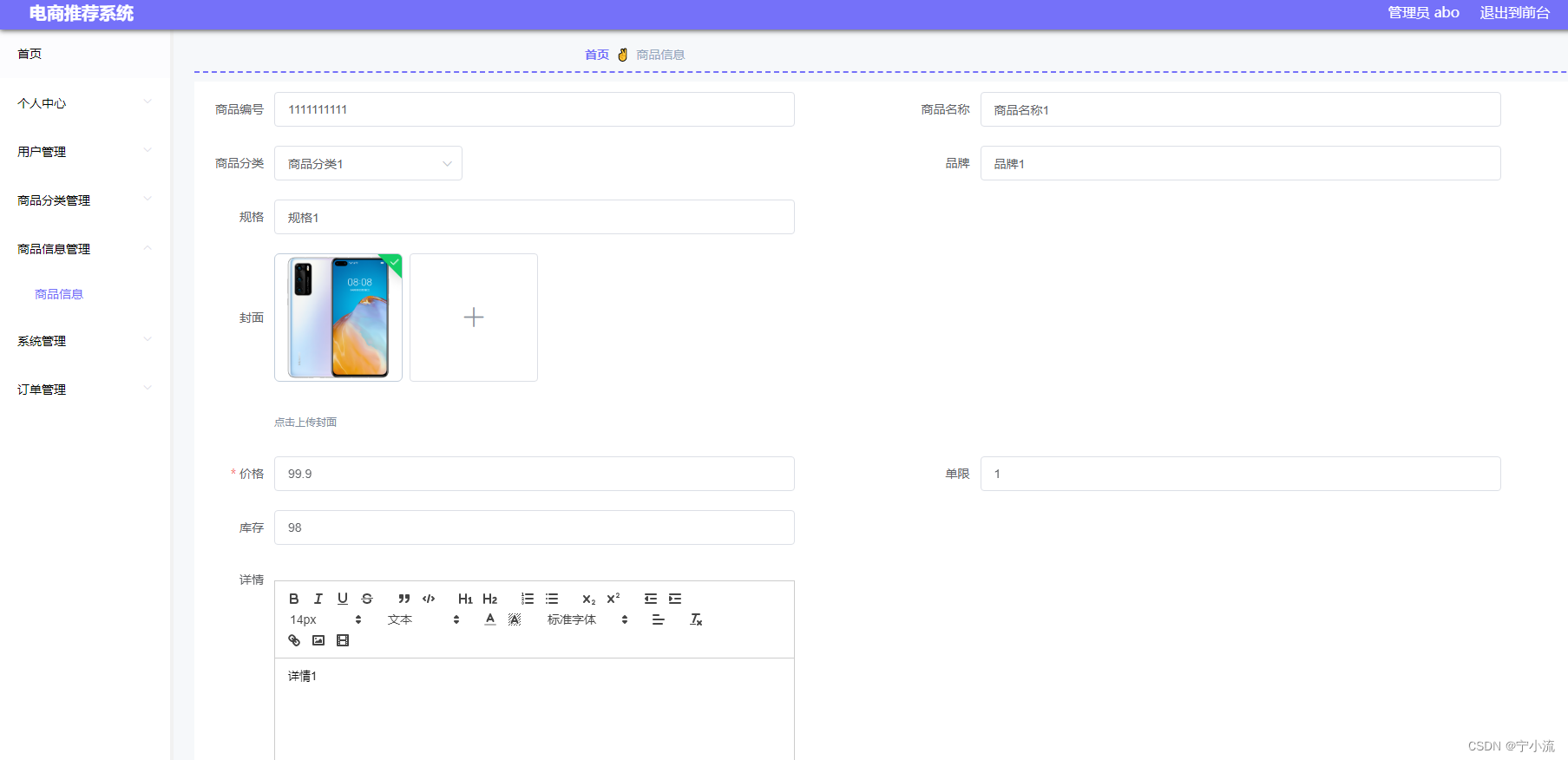
【035】基于Vue的电商推荐管理系统(含源码数据库、超详细论文)
摘 要:基于Vue+Nodejs+mysql的电商推荐管理系统,这个项目论文超详细,er图、接口文档、功能展示、技术栈等说明特别全!!! (文末附源码数据库、课设论文获取方式࿰…...

【c++】模板1—函数模板
文章目录函数模板语法函数模板注意事项案例—数组选择排序普通函数和函数模板的区别普通函数和函数模板调用规则模板的局限性函数模板语法 函数模板作用: 建立一个通用函数,其函数返回值类型和形参类型可以不具体制定,用一个虚拟的类型来代表…...

windows10 wsl子系统固定ip启动分配网卡法
WSL设置添加固定IP 在Win端添加一个固定IP 192.168.50.99 用于X-Server界面显示.在WSL端添加一个固定IP 192.168.50.16 用于和Win端通讯 在win端创建批处理文件 创建一个批处理文件 我的文件位置是D:\powershell\static_ip.bat 向vEthernet (WSL)网卡添加一个IP 192.168.50.…...

ARM+Linux日常开发笔记
ARMLinux开发命令 文章目录ARMLinux开发命令一、虚拟机1.ssh服务项目2.文件相关3.系统相关4. 虚拟机清理内存二、ARM核板1.设备重启三、调试1. 应该调试一、虚拟机 1.ssh服务项目 启动ssh服务 sudo /etc/init.d/ssh restart2.文件相关 查看文件大小显示kb ll -h 查看目录文件…...
在线文档技术-编辑器篇
这是在线文档技术的第二篇文章,本文将对目前市面上所有的主流编辑器和在线文档进行一次深入的剖析和研究,从而使大家对在线文档技术有更深入的了解,也让更多人能够参与其开发与设计中来。 注意:出于对主流文档产品的尊重…...

蒙特卡洛方法赋能智能体决策:原理、实现与工程实践
1. 项目概述:一个为智能体注入“蒙特卡洛”思想的工具箱最近在探索智能体(Agent)开发时,我一直在思考一个问题:如何让智能体的决策过程不那么“一根筋”?我们常见的基于规则或简单LLM调用的智能体ÿ…...

一人一书一时代:《凰标》是海棠山铁哥的东方文明宣言@凤凰标志
一人执笔,一书立世,一作定时代。 ——《凰标》题记一、破题:当网文只剩“爽点”,谁来承载文明?行业通病《凰标》回应娱乐至死以笔墨思考时代碎片叙事构建完整文明体系功利写作以文载道,以书传文明 二、个人…...

德国工业4.0工程师指南:从系统融合到职业发展
1. 项目概述:为什么德国是工业工程师的理想目的地?如果你是一名工业、自动化或机器人领域的工程师,正在寻找一个能将你的技术抱负与前沿产业实践深度结合的职业舞台,那么德国很可能就是你一直在寻找的答案。这不仅仅是因为德国拥有…...
图灵测试作为智能与否的标准)
图解人工智能(8)图灵测试作为智能与否的标准
有人不同意将图灵测试作为智能与否的标准。他们认为,就算机器表现得和人一样,也不能说机器拥有了智能,因为它只是一堆电路,和人的思维方式完全不同。你是否赞同这种说法?说说你赞同或反对的理由。开放讨论题。有几种观…...

芯片测试中的扫描压缩技术解析与应用
1. 扫描压缩技术概述在当今纳米级芯片设计中,扫描压缩技术已成为降低测试成本、保证测试质量的必备手段。随着芯片复杂度呈指数级增长,传统扫描测试方法面临两大核心挑战:测试数据量(Test Data Volume)爆炸式增长导致测…...

用PTA题库学C语言:手把手教你拆解‘选择与循环’的嵌套逻辑
用PTA题库学C语言:手把手教你拆解‘选择与循环’的嵌套逻辑 学习C语言时,最让初学者头疼的莫过于那些层层嵌套的选择结构和循环结构。面对一堆if-else和for/while语句,很多人会感到无从下手。本文将通过PTA题库中的典型题目,教你一…...

《凰标》与《第一大道》:同一宇宙下的龙凤双璧@凤凰标志
龙凤双璧:海棠山铁哥文学宇宙宣言——《第一大道》《凰标》世界观联动白皮书一、时代之问:当网文只剩“单兵”市场痛点铁哥答案单兵叙事双IP共生世界观割裂同源宇宙IP不成体系闭环叙事 二、宇宙基石:一破一立的双璧格局 #mermaid-svg-A2eFhZn…...

研发交付管理:资源化与项目制的实践思考
说明(阅读前):本文系 方法论层面的归纳,依据常见软件研发组织实践整理,不涉及任何特定企业的内部制度、人数或薪酬细节;文中角色名称(如研发经理、项目发起人)为 通用称谓࿰…...

题目五:抽象类 + 接口 混合实现
编程要求:抽象类 Machine:抽象方法 work(),普通方法 start();接口 Clean:抽象方法 clean();类 Robot继承抽象类 Machine 实现接口 Clean;实现所有未实现的方法;测试创建机器人对象&…...

如何快速掌握ComfyUI图像修复插件:终极完整使用指南
如何快速掌握ComfyUI图像修复插件:终极完整使用指南 【免费下载链接】comfyui-inpaint-nodes Nodes for better inpainting with ComfyUI: Fooocus inpaint model for SDXL, LaMa, MAT, and various other tools for pre-filling inpaint & outpaint areas. 项…...