BigScience bloom模型
简介
项目叫 BigScience,
模型叫 BLOOM,
BLOOM 的英文全名代表着大科学、大型、开放科学、开源的多语言语言模型。
拥有 1760 亿个参数的模型.
BLOOM 是去年由 1000 多名志愿研究人员,学者 在一个名为“大科学 BigScience”的项目中创建的.
BLOOM 和今天其他可用大型语言模型存在的一个主要区别:该模型可以理解多达 46 种人类语言,包括法语、越南语、普通话、印度尼西亚语、加泰罗尼亚语、13 种印度语言(如印地语)和 20 种非洲语言。超过 30% 的训练数据是英文的。该模型还可以理解 13 种编程语言。
下载部署步奏
新建一个Anaconda conda 环境,然后安装 pytorch >1.3版本
下载模型
模型下载:https://huggingface.co/bigscience
打开以后 Models 模块就可以看到 它不同参数级别的模型 ,B代表英文简写亿 1B1,就代表模型的参数是1亿1千万.1B3好像丢失了下不了.
这里选择单击 bloom-1b1 模型,然后在单击 Files and versions ,下载所有文件,新建文件夹取名1b1,放里面.
加载本地模型,只要写上本地模型所在的目录
#分词
tokenizer = AutoTokenizer.from_pretrained('./1b1/')
#模型
model = AutoModelForCausalLM.from_pretrained('./1b1/')
3.运行代码,代码放到1b1父级目录
cmd调用模型代码
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import pipeline
import torch#从https://huggingface.co/bigscience/bloom-1b1/tree/main
#下载所有文件,放到新创建的文件夹1b1
checkpoint = "./1b1/"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)#分词
model = AutoModelForCausalLM.from_pretrained(checkpoint)#模型
#设置为gpu,推理更快
device = torch.device('cuda')
model.to(device)
#device=0表示使用第一个可用的GPU
generator = pipeline(task="text-generation", model=model, tokenizer=tokenizer, device=0)out = generator("你是谁?", max_length=30)
print(out[0]['generated_text']) #输出 "你是谁?我:她说"因为1B1只是一个文本生成模型,你给一个短语,它接着生成.没有问答功能.而且中文生成效果也不好.
GUI调用代码
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import pipeline
import tkinter as tk
import torchcheckpoint = "./1b1/"
#分词
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
#模型
model = AutoModelForCausalLM.from_pretrained(checkpoint)
#设置为gpu,推理更快
device = torch.device('cuda')
model.to(device)
#device=0表示使用第一个可用的GPU
generator = pipeline(task="text-generation", model=model, tokenizer=tokenizer, device=0)def clean_string(s, substr): #substr=问题,s=回答s = s.replace(substr, '')lst = s.split(',')result_lst = list(set(lst))result_lst.sort()result = ','.join(result_lst) + ','return result# 创建主窗口
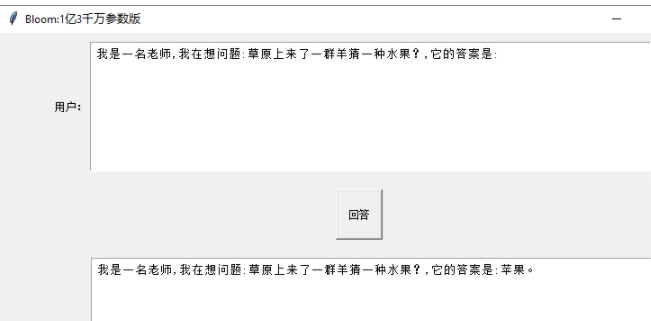
root = tk.Tk()
root.title("Bloom:1亿3千万参数版")
root.geometry("800x600+{}+{}".format(root.winfo_screenwidth() // 2 - 400, root.winfo_screenheight() // 2 - 350))# 创建输入框和滚动条
input_frame = tk.Frame(root)
input_label = tk.Label(input_frame, text="用户:")input_text = tk.Text(input_frame, height=10, width=87,padx=6, pady=6)
input_scrollbar = tk.Scrollbar(input_frame)input_text.config(yscrollcommand=input_scrollbar.set)
input_scrollbar.config(command=input_text.yview)
input_label.pack(side="left")
input_text.pack(side="left",pady=10)
input_scrollbar.pack(side="right", fill="y")
input_frame.pack()# 创建按钮
button_frame = tk.Frame(root)def show_text():#清空 Tkinter Text 组件中的文本output_text.delete('1.0', 'end')input_str = input_text.get("1.0", "end-1c")# 去掉最后一个换行符if input_str.endswith('\n'):input_str = input_str[:-1]out = generator(input_str, max_length=30)print(out[0])anwer = out[0]['generated_text'] #clean_string(out[0]['generated_text']) output_text.insert("end",anwer)button = tk.Button(button_frame, text="回答", command=show_text,width=6, height=3)
button.pack(pady=10)
button_frame.pack()# 创建输出框和滚动条
output_frame = tk.Frame(root)
output_label = tk.Label(output_frame, text="bloom:")
output_text = tk.Text(output_frame, height=26, width=87,padx=6, pady=6)
output_scrollbar = tk.Scrollbar(output_frame)
output_text.config(yscrollcommand=output_scrollbar.set)
output_scrollbar.config(command=output_text.yview)
output_label.pack(side="left",pady=10)
output_text.pack(side="left",pady=10)
output_scrollbar.pack(side="right", fill="y")
output_frame.pack()def copy():global texttext.event_generate("<<Copy>>")def cut():global texttext.event_generate("<<Cut>>")def paste():global texttext.event_generate("<<Paste>>")# 创建右键菜单
menu = tk.Menu(root, tearoff=0)
menu.add_command(label="复制", command=copy)
menu.add_command(label="剪切", command=cut)
menu.add_command(label="粘贴", command=paste)# 创建右键菜单2
menu2 = tk.Menu(root, tearoff=0)
menu2.add_command(label="复制", command=copy)# 绑定鼠标右键(第一个文本框)
def show_menu1(event):global texttext = input_textmenu.post(event.x_root, event.y_root)input_text.bind("<Button-3>", show_menu1)# 绑定鼠标右键(第二个文本框)
def show_menu2(event):global texttext = output_textmenu2.post(event.x_root, event.y_root)output_text.bind("<Button-3>", show_menu2)# 创建按钮
button_frame = tk.Frame(root)
button = tk.Button(button_frame, text="回答", command=show_text,width=6, height=3)
# 响应回车键 绑定 <Return> 事件
root.bind("<Return>", lambda event: show_text())root.lift()
# 运行主循环
root.mainloop()
生成300字效果

中英翻译 效果 不堪 ,诱导式
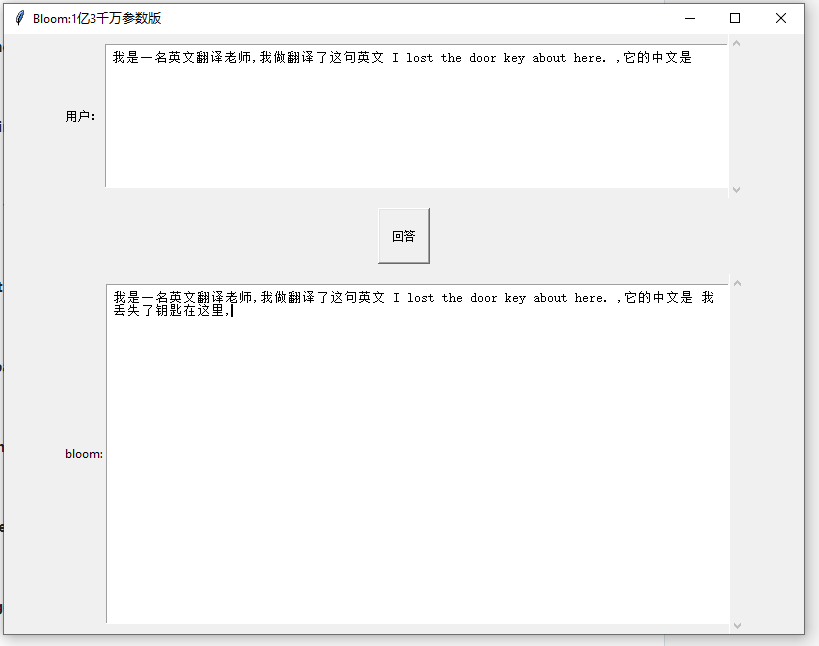
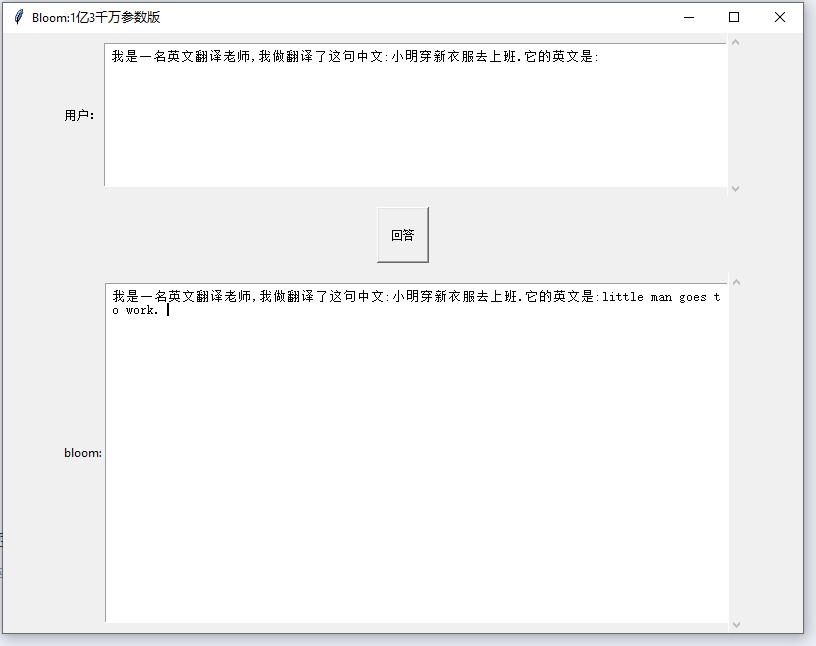
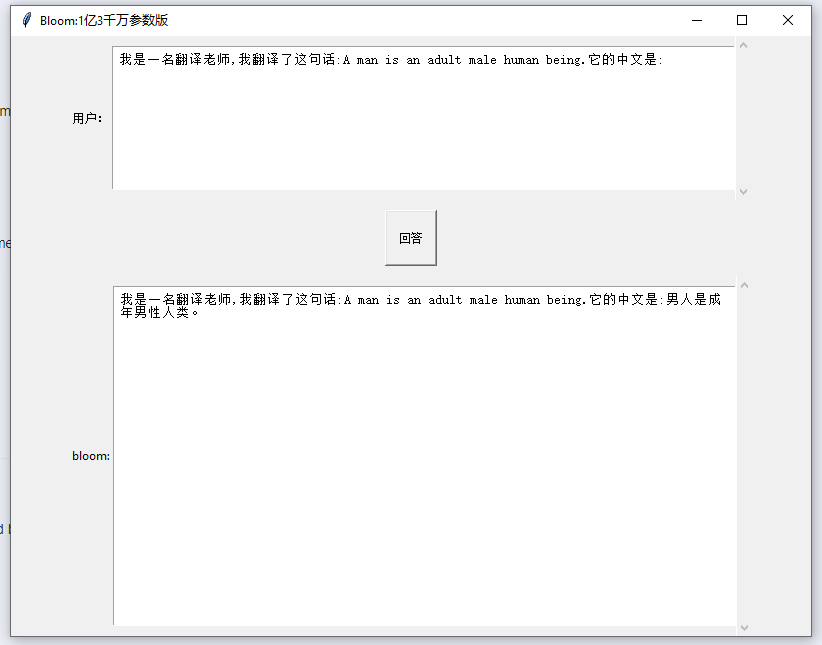
问答
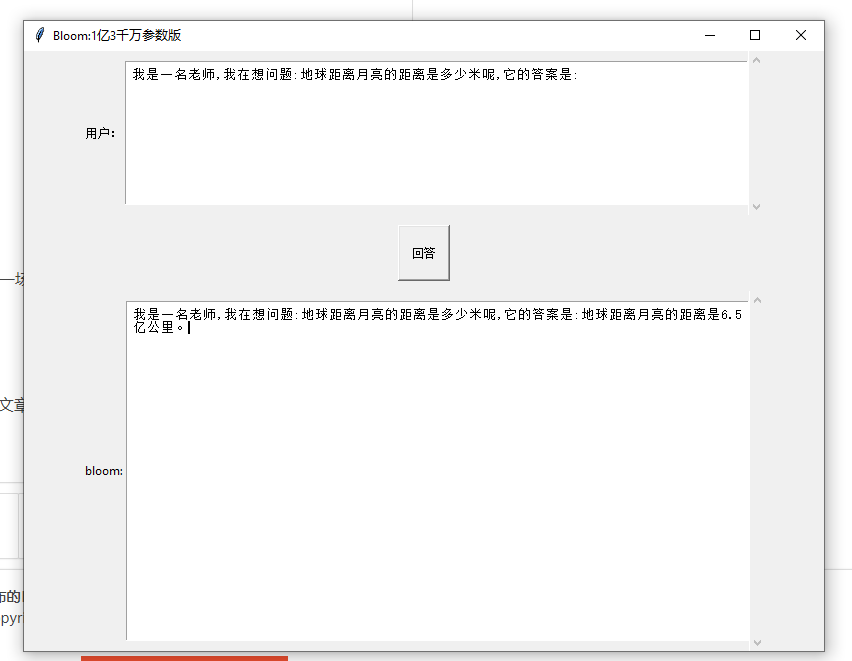


相关文章:
BigScience bloom模型
简介项目叫 BigScience,模型叫 BLOOM,BLOOM 的英文全名代表着大科学、大型、开放科学、开源的多语言语言模型。拥有 1760 亿个参数的模型.BLOOM 是去年由 1000 多名志愿研究人员,学者 在一个名为“大科学 BigScience”的项目中创建的.BLOOM 和今天其他可用大型语言模型存在的一…...

Squid服务的缓存概念
Squid缓存概念 squid是一个缓存服务器的守护进程 之前涉及的缓存服务:redis 2-8原则:80%的访问就是从20%的数据提供的;因此把20%的数据给到缓存–>完美解决等待时间; nginx是没有缓存的服务的;那么专业的事情就…...
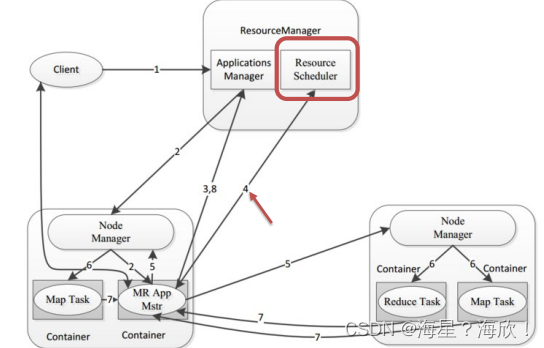
Hadoop YARN
目录Hadoop YARN介绍Hadoop YARN架构、组件程序提交YARN交互流程YARN资源调度器Scheduler调度器策略FIFO SchedulerCapacity SchedulerFair SchedulerHadoop YARN介绍 YARN是一个通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度 上图࿱…...

使用 Macrobenchmark 测试 Android 应用性能
etpack Compose 是推荐用于构建原生 Android 界面的新工具包。后续简称Jetpack Compose为Compose。在了解State之前需要先对Compose及申明性编程式有个大概的了解。State初体验好了,在你有一定了解的基础上,我们先来运行几个Demo,初步了解为何…...
【django】django-simpleui配置后,后台显示空白页解决方法
every blog every motto: You can do more than you think. https://blog.csdn.net/weixin_39190382?typeblog 0. 前言 django后台显示空白页解决方法 1. 正文 添加完simpleui以后,后台显示一片空白,一脸问号??? …...
【035】基于Vue的电商推荐管理系统(含源码数据库、超详细论文)
摘 要:基于Vue+Nodejs+mysql的电商推荐管理系统,这个项目论文超详细,er图、接口文档、功能展示、技术栈等说明特别全!!! (文末附源码数据库、课设论文获取方式࿰…...

【c++】模板1—函数模板
文章目录函数模板语法函数模板注意事项案例—数组选择排序普通函数和函数模板的区别普通函数和函数模板调用规则模板的局限性函数模板语法 函数模板作用: 建立一个通用函数,其函数返回值类型和形参类型可以不具体制定,用一个虚拟的类型来代表…...

windows10 wsl子系统固定ip启动分配网卡法
WSL设置添加固定IP 在Win端添加一个固定IP 192.168.50.99 用于X-Server界面显示.在WSL端添加一个固定IP 192.168.50.16 用于和Win端通讯 在win端创建批处理文件 创建一个批处理文件 我的文件位置是D:\powershell\static_ip.bat 向vEthernet (WSL)网卡添加一个IP 192.168.50.…...

ARM+Linux日常开发笔记
ARMLinux开发命令 文章目录ARMLinux开发命令一、虚拟机1.ssh服务项目2.文件相关3.系统相关4. 虚拟机清理内存二、ARM核板1.设备重启三、调试1. 应该调试一、虚拟机 1.ssh服务项目 启动ssh服务 sudo /etc/init.d/ssh restart2.文件相关 查看文件大小显示kb ll -h 查看目录文件…...
在线文档技术-编辑器篇
这是在线文档技术的第二篇文章,本文将对目前市面上所有的主流编辑器和在线文档进行一次深入的剖析和研究,从而使大家对在线文档技术有更深入的了解,也让更多人能够参与其开发与设计中来。 注意:出于对主流文档产品的尊重…...

top -p pid为什么超过100%
CPU:Cores, and Hyper-Threading 超线程(Hyper-Threading ) 超线程是Intel最早提出一项技术,最早出现在2002年的Pentium4上。单个采用超线程的CPU对于操作系统来说就像有两个逻辑CPU,为此P4处理器需要多加入一个Logic…...

#高光谱图像分类#:分类的方法有哪些?
高光谱图像分类方法可以根据分类粒度的不同分为基于像素的分类和基于对象的分类 高光谱图像分类方法可以根据分类粒度的不同分为基于像素的分类和基于对象的分类。 基于像素的分类:这种分类方法是针对每个像素进行分类,将像素的光谱信息作为输入特征&am…...

观察者模式
观察者模式常常用于以下场景:事件驱动系统:当事件发生时,通知所有对该事件感兴趣的观察者。发布/订阅模型:一个主题(发布者)可以有多个订阅者(观察者),当主题发生改变时&…...
前端组件库自定义主题切换探索-03-webpack-theme-color-replacer webpack 同时替换多个颜色改造
接上一篇《前端组件库自定义主题切换探索-02-webpack-theme-color-replacer webpack 的实现逻辑和原理-02》 这篇我们来开始改造,让这个插件最终能达到我们的目的: 首先修改plugin.config.js。 插件首先要在vue.config.js引用注册,因此先对…...
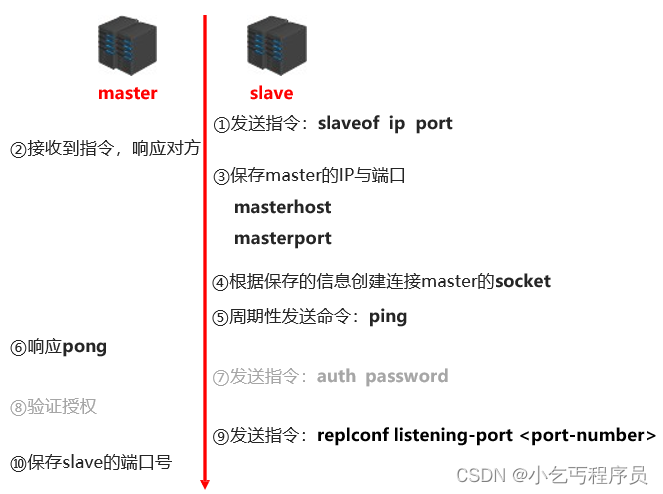
Redis高级-主从复制相关操作
2.1 主从复制简介 2.1.1 高可用 首先我们要理解互联网应用因为其独有的特性我们演化出的三高架构 高并发 应用要提供某一业务要能支持很多客户端同时访问的能力,我们称为并发,高并发意思就很明确了 高性能 性能带给我们最直观的感受就是:速…...

SPI总线设备驱动模型
SPI总线设备驱动模型 文章目录SPI总线设备驱动模型参考资料:一、平台总线设备驱动模型二、 数据结构2.1 SPI控制器数据结构2.2 SPI设备数据结构2.3 SPI设备驱动三、 SPI驱动框架3.1 SPI控制器驱动程序3.2 SPI设备驱动程序致谢参考资料: 内核头文件&…...

开发同事辞职,接手到垃圾代码怎么办?
小王新加入了一家公司,这家公司有点年头,所以连屎山都是发酵过的,味道很冲。和大多数时运不济的程序员一样,到了这种公司,做的大多数工作,就是修补这些祖传代码,为其添砖加瓦。每当被折腾的筋疲…...

gRPC简介
grpc简介 grpc介绍可以参考官网。无论是rpc还是grpc,可以这样理解,都知道过去使用的单单体架构,而在2011年5月威尼斯的一个软件架构会议上提出了微服务架构,围绕业务功能进行组织(organized around business capability)…...

《MySQL系列-InnoDB引擎25》表-InnoDB逻辑存储结构
InnoDB逻辑存储结构 从InnoDB存储引擎的逻辑存储结构看,所有数据都被逻辑地存放在一个空间中,称之为表空间(tablespace)。表空间又由段(segment)、区(extent)、页(page)组成。页在一些文档中有时也称为块(block),InnoDB存储引擎的逻辑存储结构…...

YOLOv8之C2f模块——与YOLOv5的C3模块对比
一、源码对比 YOLOv8完整工程代码下载:ultralytics/ultralytic C2f模块源码在ultralytics/nn/modules.py下,源码如下: class C2f(nn.Module):# CSP Bottleneck with 2 convolutionsdef __init__(self, c1, c2, n1, shortcutFalse, g1, e…...

从愚人节玩笑到工程实践:四个软硬件结合的创意项目技术拆解
1. 从愚人节玩笑到工程师的创意沙盘每年四月一日,总有些介于荒诞与现实之间的“产品”构想冒出来,在工程师社区里引发一阵会心一笑。但如果你仔细琢磨,会发现这些看似玩笑的点子,往往藏着一丝对技术边界、用户体验乃至市场需求的犀…...

为LibraVDB定制内存池:提升稀疏体素数据处理性能
1. 项目概述:一个为LibraVDB设计的开源内存管理库最近在搞一些基于体素的数据处理项目,特别是用到了LibraVDB这个开源的稀疏体素数据库。玩过VDB格式的朋友都知道,它的核心优势在于对稀疏体数据的极致压缩和高效访问,但这也带来了…...
终极配置指南:5步打造专业级网络视频传输系统)
DistroAV(原OBS-NDI)终极配置指南:5步打造专业级网络视频传输系统
DistroAV(原OBS-NDI)终极配置指南:5步打造专业级网络视频传输系统 【免费下载链接】obs-ndi DistroAV (formerly OBS-NDI): NDI integration for OBS Studio 项目地址: https://gitcode.com/gh_mirrors/ob/obs-ndi 你是否曾为OBS Stud…...

别再死记硬背截止、放大、饱和了!用Arduino+面包板,5分钟直观理解NPN/PNP三极管三种状态
用Arduino点亮三极管:5分钟可视化实验理解电子开关的三种状态 你是否曾被三极管的"截止"、"放大"、"饱和"这些术语困扰?教科书上的电压公式和载流子运动图虽然精确,却难以形成直观认知。今天我们将用Arduino和…...

全栈AI智能体开发实战:基于LangGraph与Next.js的工程化模板解析
1. 项目概述:一个全栈AI智能体模板的诞生 最近在GitHub上看到一个挺有意思的项目,叫 vstorm-co/full-stack-ai-agent-template 。光看名字,你可能会觉得这又是一个“AI全栈”的缝合怪,或者是一个过度包装的概念。但作为一个在AI…...

英雄联盟Akari助手:从青铜到王者的智能游戏革命
英雄联盟Akari助手:从青铜到王者的智能游戏革命 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄联盟中的重复操作和信息…...

【研报 A110】物理AI时代的具身数据采集需求研究:国家级训练场落地,开源生态加速建设
摘要:物理AI时代,具身智能与世界模型的发展,推动具身数据采集成为下一代数据基建的核心浪潮。具身大模型对数据有着EB级的海量需求,同时对多模态、异构性与质量要求极高,当前数据缺口成为制约具身智能发展的核心瓶颈&a…...

004 LVGL应用场景与案例概览
004 LVGL应用场景与案例概览 上周帮一个做智能家居的朋友调屏,他用的STM32F407+4.3寸RGB屏,LVGL跑得挺欢,但一加上WiFi联网和MQTT协议栈,屏幕刷新就开始卡顿,触摸响应延迟明显。我打开他的代码一看,好家伙,lv_task_handler()直接放在主循环里裸奔,没有任何优先级管理。…...

在vSphere ESXi 7.0上跑MacOS Big Sur?这份保姆级避坑指南帮你一次搞定
在vSphere ESXi 7.0上部署macOS Big Sur的深度避坑指南 虚拟化环境中运行macOS一直是技术爱好者和企业开发者的热门需求。本文将深入探讨在vSphere ESXi 7.0平台上安装macOS Big Sur时可能遇到的各种技术难题及其解决方案,帮助您避开那些让大多数用户头疼的"坑…...
)
Abaqus 6.12 保姆级教程:手把手教你搞定悬臂梁的动力学仿真(附阻尼设置与结果动画)
Abaqus 6.12 悬臂梁动力学仿真全流程实战:从阻尼优化到动画渲染 悬臂梁作为结构动力学分析的经典案例,在机械振动、建筑抗震等领域具有广泛的应用价值。本文将基于Abaqus 6.12平台,通过一个完整的动力学仿真案例,深入解析从模型建…...