【深度学习】快速制作图像标签数据集以及训练
快速制作图像标签数据集以及训练
制作DataSet
-
先从网络收集十张图片 每种十张
-
定义dataSet和dataloader
import glob
import torch
from torch.utils import data
from PIL import Image
import numpy as np
from torchvision import transforms
import matplotlib.pyplot as plt# 通过创建data.Dataset子类Mydataset来创建输入
class Mydataset(data.Dataset):# init() 初始化方法,传入数据文件夹路径def __init__(self, root):self.imgs_path = root# getitem() 切片方法,根据索引下标,获得相应的图片def __getitem__(self, index):img_path = self.imgs_path[index]# len() 计算长度方法,返回整个数据文件夹下所有文件的个数def __len__(self):return len(self.imgs_path)# 使用glob方法来获取数据图片的所有路径
all_imgs_path = glob.glob(r"./Data/*/*.jpg") # 数据文件夹路径# 利用自定义类Mydataset创建对象brake_dataset
# 将所有的路径塞进dataset 使用每张图片的路径进行索引图片
brake_dataset = Mydataset(all_imgs_path)
# print("图片总数:{}".format(len(brake_dataset))) # 返回文件夹中图片总个数# 制作dataloader
brake_dataloader = torch.utils.data.DataLoader(brake_dataset, batch_size=2) # 每次迭代时返回4个数据
# print(next(iter(break_dataloader)))制作标签
# 为每张图片制作对应标签
species = ['sun', 'rain', 'cloud']
species_to_id = dict((c, i) for i, c in enumerate(species))
# print(species_to_id)id_to_species = dict((v, k) for k, v in species_to_id.items())
# print(id_to_species)# 对所有图片路径进行迭代
all_labels = []
for img in all_imgs_path:# 区分出每个img,应该属于什么类别for i, c in enumerate(species):if c in img:all_labels.append(i)
# print(all_labels)
制作数据和标签一起的dataset和dataloader
- 上面的dataset不够完善
# 将数据转换为张量数据
# 对数据进行转换处理
transform = transforms.Compose([transforms.Resize((256, 256)), # 做的第一步转换transforms.ToTensor() # 第二步转换,作用:第一转换成Tensor,第二将图片取值范围转换成0-1之间,第三会将channel置前
])class Mydatasetpro(data.Dataset):def __init__(self, img_paths, labels, transform):self.imgs = img_pathsself.labels = labelsself.transforms = transform# 进行切片def __getitem__(self, index):img = self.imgs[index]label = self.labels[index]pil_img = Image.open(img) # pip install pillowpil_img = pil_img.convert('RGB')data = self.transforms(pil_img)return data, label# 返回长度def __len__(self):return len(self.imgs)BATCH_SIZE = 4
brake_dataset = Mydatasetpro(all_imgs_path, all_labels, transform)
brake_dataloader = data.DataLoader(brake_dataset,batch_size=BATCH_SIZE,shuffle=True
)imgs_batch, labels_batch = next(iter(brake_dataloader))# 4 X 3 X 256 X 256
print(imgs_batch.shape)plt.figure(figsize=(12, 8))
for i, (img, label) in enumerate(zip(imgs_batch[:10], labels_batch[:10])):img = img.permute(1, 2, 0).numpy()plt.subplot(2, 3, i + 1)plt.title(id_to_species.get(label.item()))plt.imshow(img)
plt.show() # 展示图片制作训练集和测试集
# 划分数据集和测试集
index = np.random.permutation(len(all_imgs_path))# 打乱所有图片的索引
print(index)# 根据索引获取所有图片的路径
all_imgs_path = np.array(all_imgs_path)[index]
all_labels = np.array(all_labels)[index]print("打乱顺序之后的所有图片路径{}".format(all_imgs_path))
print("打乱顺序之后的所有图片索引{}".format(all_labels))# 80%做训练集
s = int(len(all_imgs_path) * 0.8)
# print(s)train_imgs = all_imgs_path[:s]
# print(train_imgs)
train_labels = all_labels[:s]
test_imgs = all_imgs_path[s:]
test_labels = all_labels[s:]# 将训练集和标签 制作dataset 需要转换为张量
train_ds = Mydatasetpro(train_imgs, train_labels, transform) # TrainSet TensorData
test_ds = Mydatasetpro(test_imgs, test_labels, transform) # TestSet TensorData
# print(train_ds)
# print(test_ds)
print("**********")
# 制作trainLoader
train_dl = data.DataLoader(train_ds, batch_size=BATCH_SIZE, shuffle=True) # TrainSet Labels
test_dl = data.DataLoader(train_ds, batch_size=BATCH_SIZE, shuffle=True) # TestSet Labels训练代码
import torch
import torchvision.models as models
from torch import nn
from torch import optim
from DataSetMake import brake_dataloader
from DataSetMake import train_dl, test_dl# 判断是否使用GPU
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 使用resnet 训练
model_ft = models.resnet50(pretrained=True) # 使用迁移学习,加载预训练权in_features = model_ft.fc.in_features
model_ft.fc = nn.Sequential(nn.Linear(in_features, 256),nn.ReLU(),# nn.Dropout(0, 4),nn.Linear(256, 4),nn.LogSoftmax(dim=1))model_ft = model_ft.to(DEVICE) # 将模型迁移到gpu# 优化器
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(DEVICE) # 将loss_fn迁移到GPU# Adam损失函数
optimizer = optim.Adam(model_ft.fc.parameters(), lr=0.003)epochs = 50 # 迭代次数
steps = 0
running_loss = 0
print_every = 10
train_losses, test_losses = [], []for epoch in range(epochs):model_ft.train()# 遍历训练集数据for imgs, labels in brake_dataloader:steps += 1# 标签转换为 tensorlabels = torch.tensor(labels, dtype=torch.long)# 将图片和标签 放到设备上imgs, labels = imgs.to(DEVICE), labels.to(DEVICE)optimizer.zero_grad() # 梯度归零# 前向推理outputs = model_ft(imgs)# 计算lossloss = loss_fn(outputs, labels)loss.backward() # 反向传播计算梯度optimizer.step() # 梯度优化# 累加lossrunning_loss += loss.item()if steps % print_every == 0:test_loss = 0accuracy = 0# 验证模式model_ft.eval()# 测试集 不需要计算梯度with torch.no_grad():# 遍历测试集数据for imgs, labels in test_dl:# 转换为tensorlabels = torch.tensor(labels, dtype=torch.long)# 数据标签 部署到gpuimgs, labels = imgs.to(DEVICE), labels.to(DEVICE)# 前向推理outputs = model_ft(imgs)# 计算损失loss = loss_fn(outputs, labels)# 累加测试机的损失test_loss += loss.item()ps = torch.exp(outputs)top_p, top_class = ps.topk(1, dim=1)equals = top_class == labels.view(*top_class.shape)accuracy += torch.mean(equals.type(torch.FloatTensor)).item()train_losses.append(running_loss / len(train_dl))test_losses.append(test_loss / len(test_dl))print(f"Epoch {epoch + 1}/{epochs}.. "f"Train loss: {running_loss / print_every:.3f}.. "f"Test loss: {test_loss / len(test_dl):.3f}.. "f"Test accuracy: {accuracy / len(test_dl):.3f}")# 回到训练模式 训练误差清0running_loss = 0model_ft.train()
torch.save(model_ft, "aerialmodel.pth")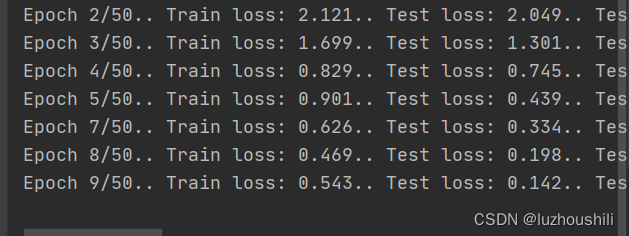
预测代码
import os
import torch
from PIL import Image
from torch import nn
from torchvision import transforms, modelsi = 0 # 识别图片计数
# 这里最好新建一个test_data文件随机放一些上面整理好的图片进去
root_path = r"D:\CODE\ImageClassify\Test" # 待测试文件夹
names = os.listdir(root_path)for name in names:print(name)i = i + 1data_class = ['sun', 'rain', 'cloud'] # 按文件索引顺序排列# 找出文件夹中的所有图片image_path = os.path.join(root_path, name)image = Image.open(image_path)print(image)# 张量定义格式transform = transforms.Compose([transforms.Resize((256, 256)),transforms.ToTensor()])# 图片转换为张量image = transform(image)print(image.shape)# 定义resnet模型model_ft = models.resnet50()# 模型结构in_features = model_ft.fc.in_featuresmodel_ft.fc = nn.Sequential(nn.Linear(in_features, 256),nn.ReLU(),# nn.Dropout(0, 4),nn.Linear(256, 4),nn.LogSoftmax(dim=1))# 加载已经训练好的模型参数model = torch.load("aerialmodel.pth", map_location=torch.device("cpu"))# 将每张图片 调整维度image = torch.reshape(image, (1, 3, 256, 256)) # 修改待预测图片尺寸,需要与训练时一致model.eval()# 速出预测结果with torch.no_grad():output = model(image)print(output) # 输出预测结果# print(int(output.argmax(1)))# 对结果进行处理,使直接显示出预测的种类 根据索引判别是哪一类print("第{}张图片预测为:{}".format(i, data_class[int(output.argmax(1))]))工程目录结构
相关文章:
【深度学习】快速制作图像标签数据集以及训练
快速制作图像标签数据集以及训练 制作DataSet 先从网络收集十张图片 每种十张 定义dataSet和dataloader import glob import torch from torch.utils import data from PIL import Image import numpy as np from torchvision import transforms import matplotlib.pyplot…...

Spring Boot Web MVC
文章目录 一、Spring Boot Web MVC 概念二、状态码三、其他注解四、响应操作 一、Spring Boot Web MVC 概念 Spring Web MVC 是⼀个 Web 框架,一开始就包含在Spring 框架里。 1. MVC 定义 软件⼯程中的⼀种软件架构设计模式,它把软件系统分为模型、视…...

设置防火墙
1.RHEL7中的防火墙类型 防火墙只能同时使用一张,firewall底层调用的还是lptables的服务: firewalld:默认 ,基于不同的区域做规则 iptables: RHEL6使用,基于链表 Ip6tables Ebtables 2.防火墙的配置方式 查看防火墙状态: rootlinuxidc -]#systemct…...
3.Docker的客户端指令学习与实战
1.Docker的命令 1.1 启动Docker(systemctl start docker) systemctl start docker1.2 查看docker的版本信息(docker version) docker version1.3 显示docker系统范围的信息(docker info) docker info1.4…...
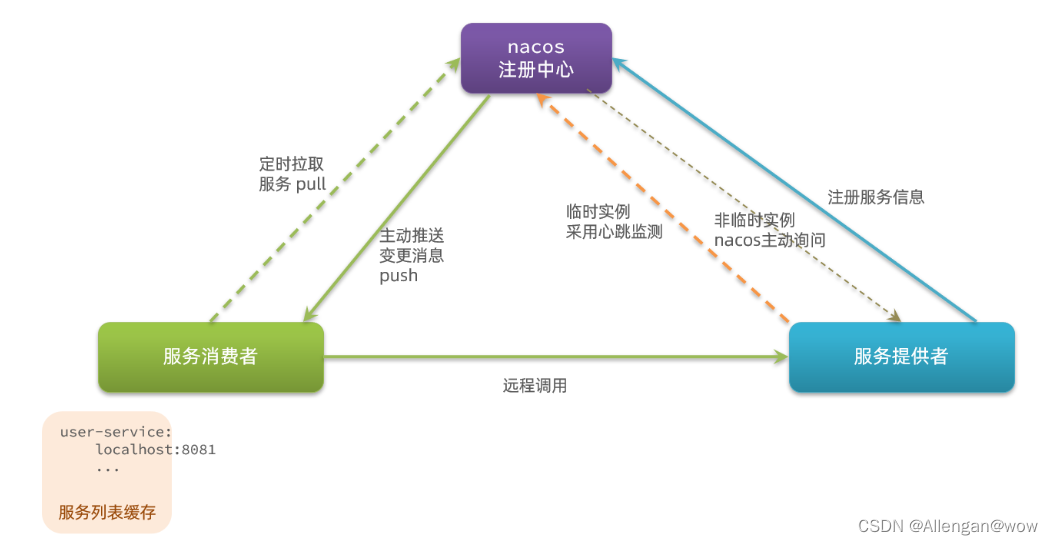
【微服务开篇-RestTemplate服务调用、Eureka注册中心、Nacos注册中心】
本篇用到的资料:https://gitee.com/Allengan/cloud-demo.githttps://gitee.com/Allengan/cloud-demo.git 目录 1.认识微服务 1.1.单体架构 1.2.分布式架构 1.3.微服务 1.4.SpringCloud 1.5.总结 2.服务拆分和远程调用 2.1.服务拆分原则 2.2.服务拆分示例 …...

python if和while的区别有哪些
python if和while的区别有哪些?下面给大家具体介绍: 1、用法 while和if本身就用法不同,一个是循环语句,一个是判断语句。 2、运行模式 if 只做判断,判断一次之后,便不会再回来了。 while 的话…...

Unity计时器
using UnityEngine; using System.Collections;public class Timer : MonoBehaviour {public float duration 1.0f; // 定时器持续时间public bool isLooping false; // 是否循环public bool isPaused false; // 是否暂停计时器private float currentDuration 0.0f; // 当前…...

Unity热更新介绍
打包函数 BuildPipeline.BuildAssetBundles("AssetBundles", BuildAssetBundleOptions.ChunkBasedCompression, BuildTarget.Android);打包策略和方案 按文件夹打包:Bundle数量少,首次下载块,但是后期更新补丁大按文件打包&#…...
在虚拟机centos7中部署docker+jenkins最新稳定版
在虚拟机centos7中部署dockerjenkins最新稳定版 查看端口是否被占用 lsof -i:80 查看运行中容器 docker ps 查看所有容器 docker ps -a 删除容器 docker rm 镜像/容器名称 强制删除 docker rmi -f 镜像名 查看当前目录 pwd 查看当前目录下所有文件名称 ls 赋予权限 chown 777 …...
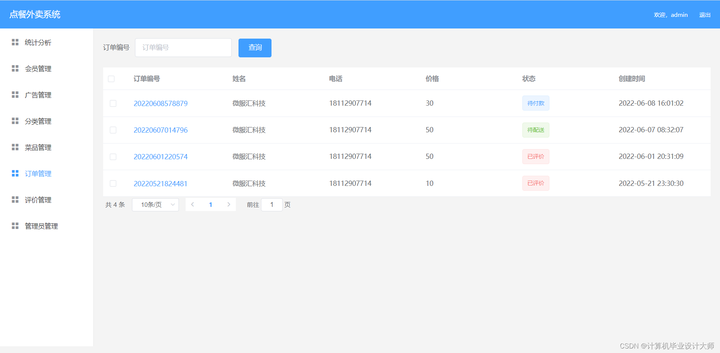
nodejs express vue 点餐外卖系统源码
开发环境及工具: nodejs,vscode(webstorm),大于mysql5.5 技术说明: nodejs express vue elementui 功能介绍: 用户端: 登录注册 首页显示搜索菜品,轮播图…...
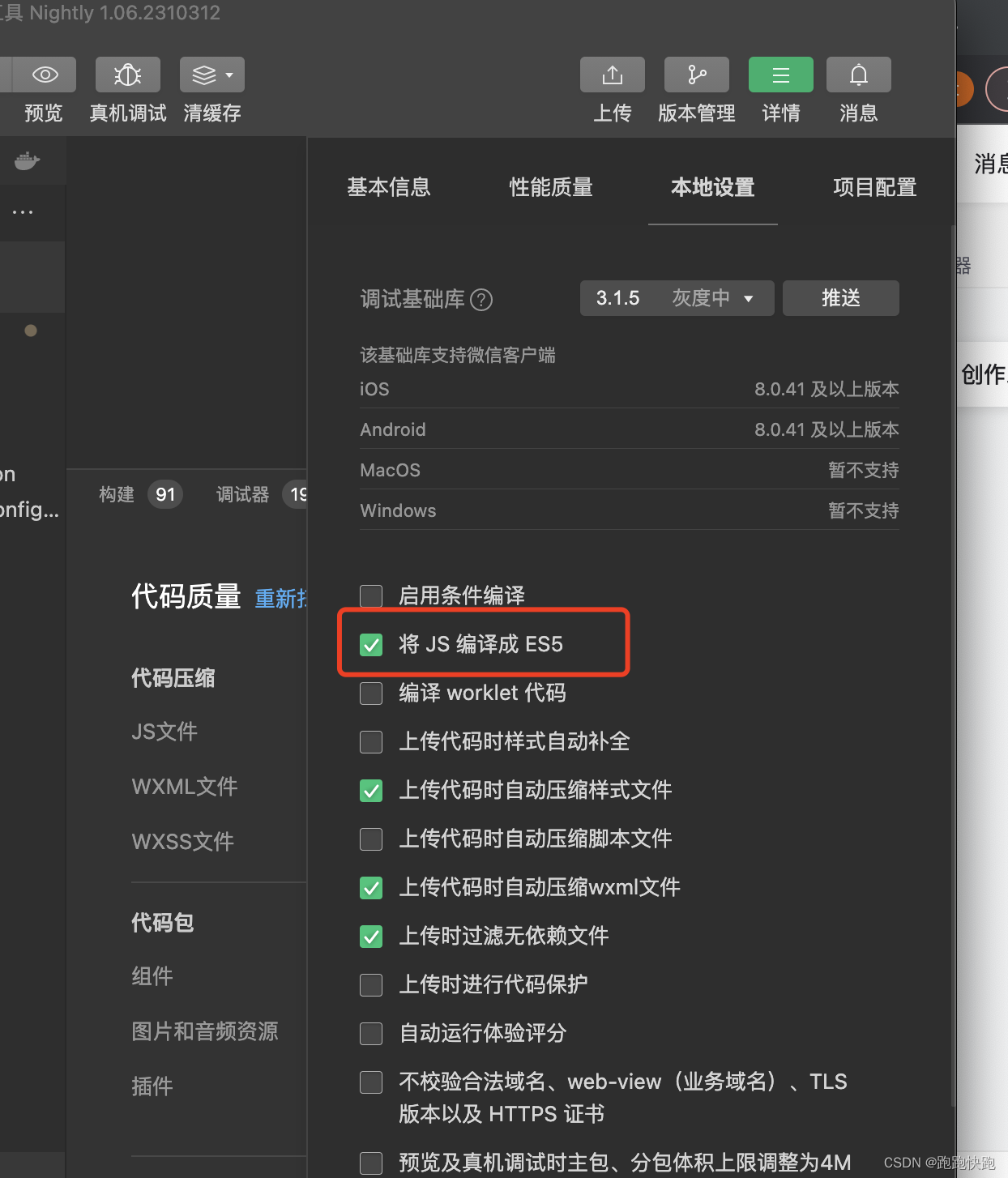
微信小程序导入js使用时候报错
我是引入weapp库时候,导入js会报错。 需要在小程序开发工具里面配置 就可以了。...
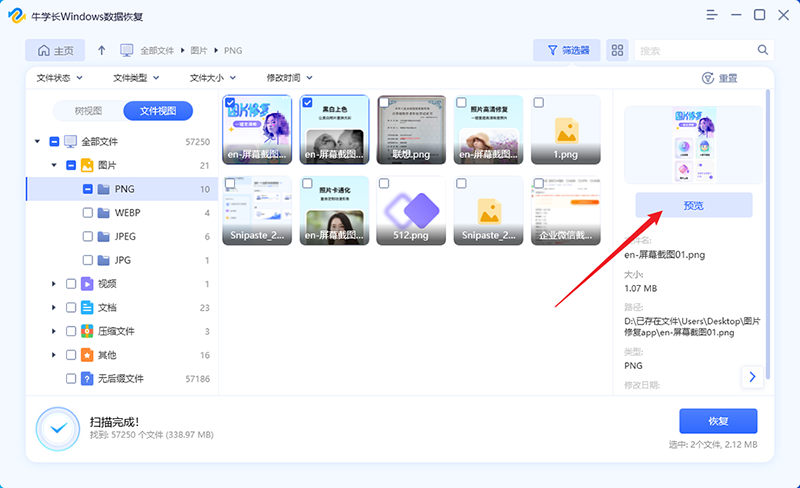
相机存储卡被格式化了怎么恢复?数据恢复办法分享!
随着时代的发展,相机被越来越多的用户所使用,这也意味着更多的用户面临着相机数据丢失的问题,很多用户在使用相机的过程中,都出现过不小心格式化相机存储卡的情况,里面的数据也将一并消失,相机存储卡被格式…...
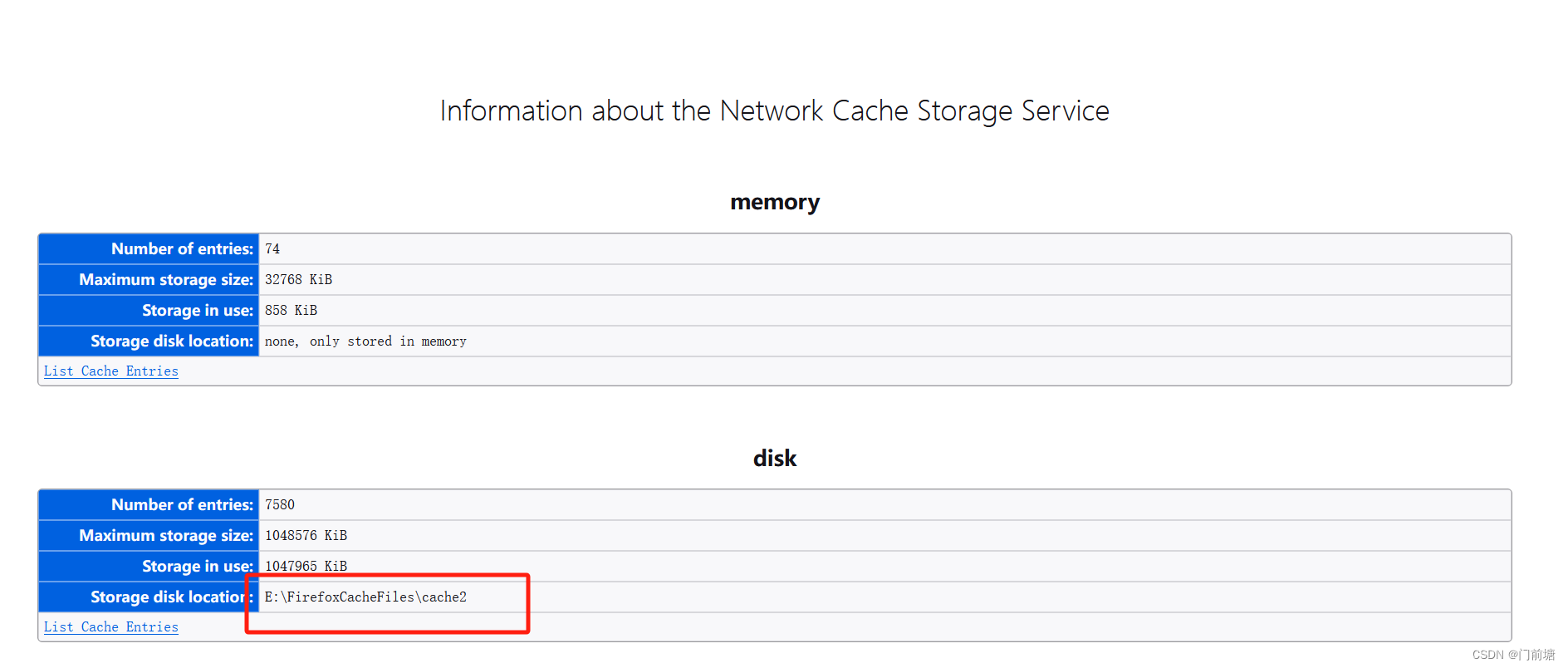
Firefox修改缓存目录的方法
打开Firefox,在地址栏输入“about:config” 查找是否有 browser.cache.disk.parent_directory,如果没有就新建一个同名的字符串,然后修改值为你要存放Firefox浏览器缓存的目录地址(E:\FirefoxCacheFiles) 然后重新…...
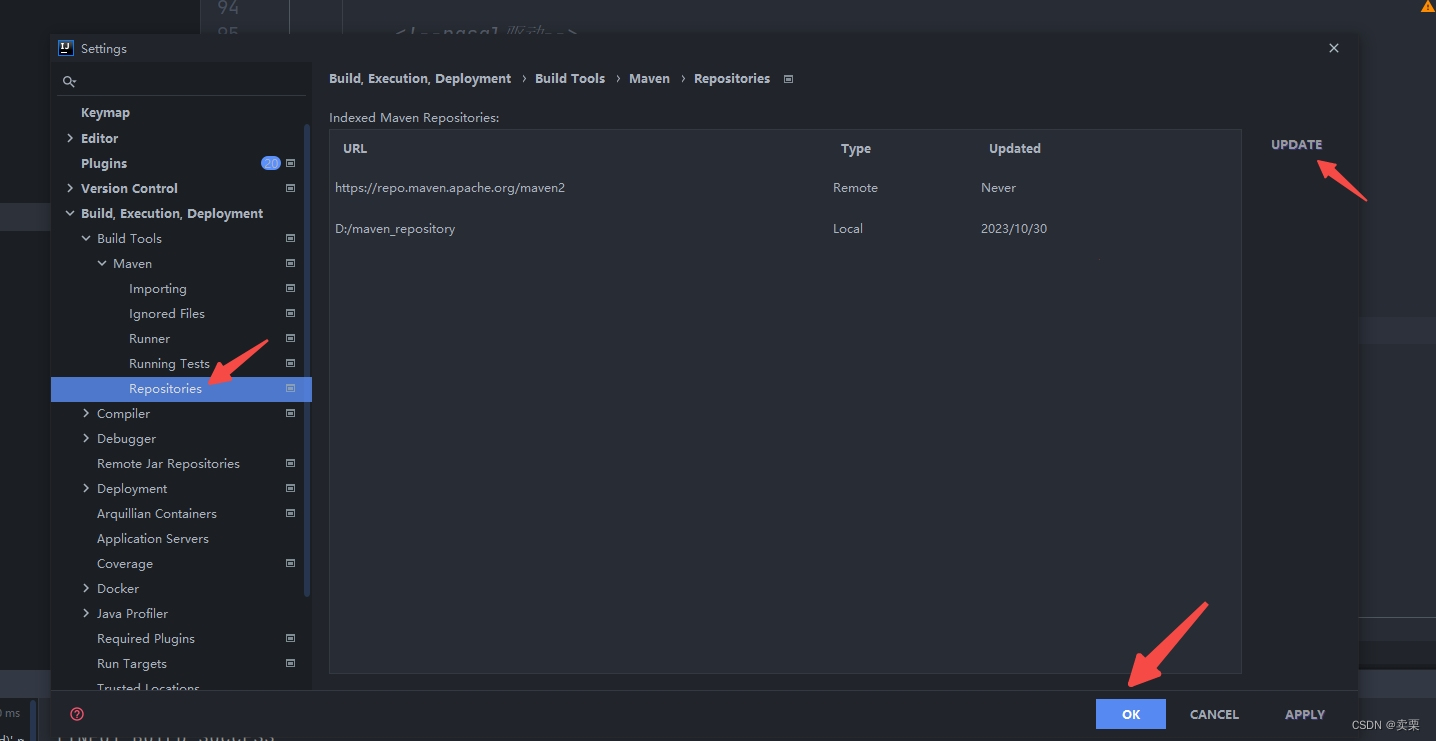
maven子模块无法导入jar包问题
明明本地仓库有jar包 maven子模块无法导入jar包,然后放到父项目的pom.xml则可以导入 可以试试更新仓库后,引入成功...
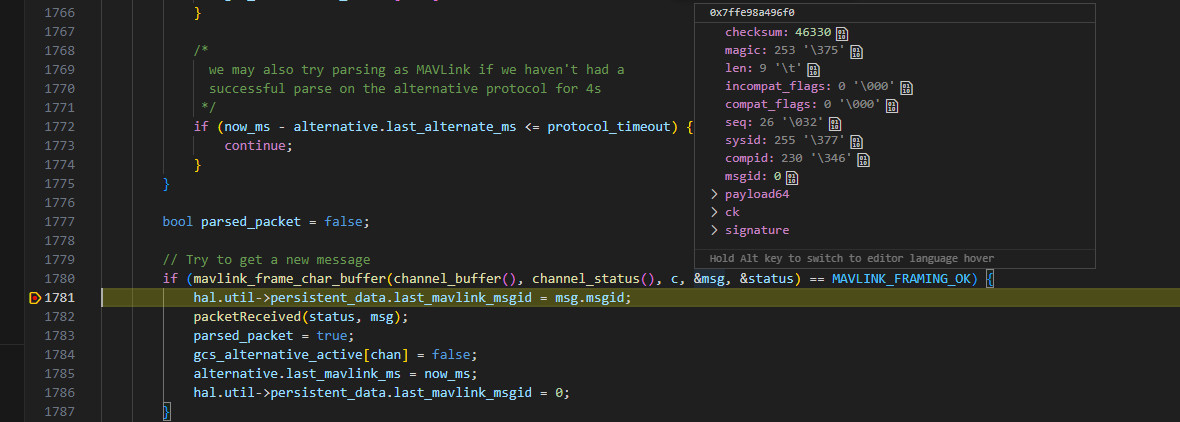
ardupilot开发 --- 代码解析 篇
0. 前言 根据SITL的断点调试和自己阅读代码的一些理解,写一点自己的注释,有什么不恰当的地方请各位读者不吝赐教。 1. GCS::update_send 线程 主动向MavLink system发送消息包。 1.1 不断向地面站发送飞机状态数据 msg_attitude: msg_location: n…...
C++引用概述
变量名实质上是一段连续存储空间的别名,是一个标号(门牌号),程序中通过变量来申请并命 名内存空间,通过变量的名字可以使用存储空间。引用是 C中新增加的概念,引用可以看作 一个已定义变量的别名。 引用的语法: Type&…...

精准努力,提升自己的核心竞争力——中国人民大学与加拿大女王大学金融硕士
步入职场,相信大家都想成为职场的宠儿。经过一番摸爬滚打后,在职场稳固了地位。但想叱咤职场,还需要精准努力,提升自己的核心竞争力。中国人民大学与加拿大女王大学金融硕士项目为你补给能量。 任何资产都有贬值的风险࿰…...

string【C++】
string 是什么 string 是什么 长度可变的字符串。...

【Python爬虫】selenium4新版本使用指南
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera&am…...
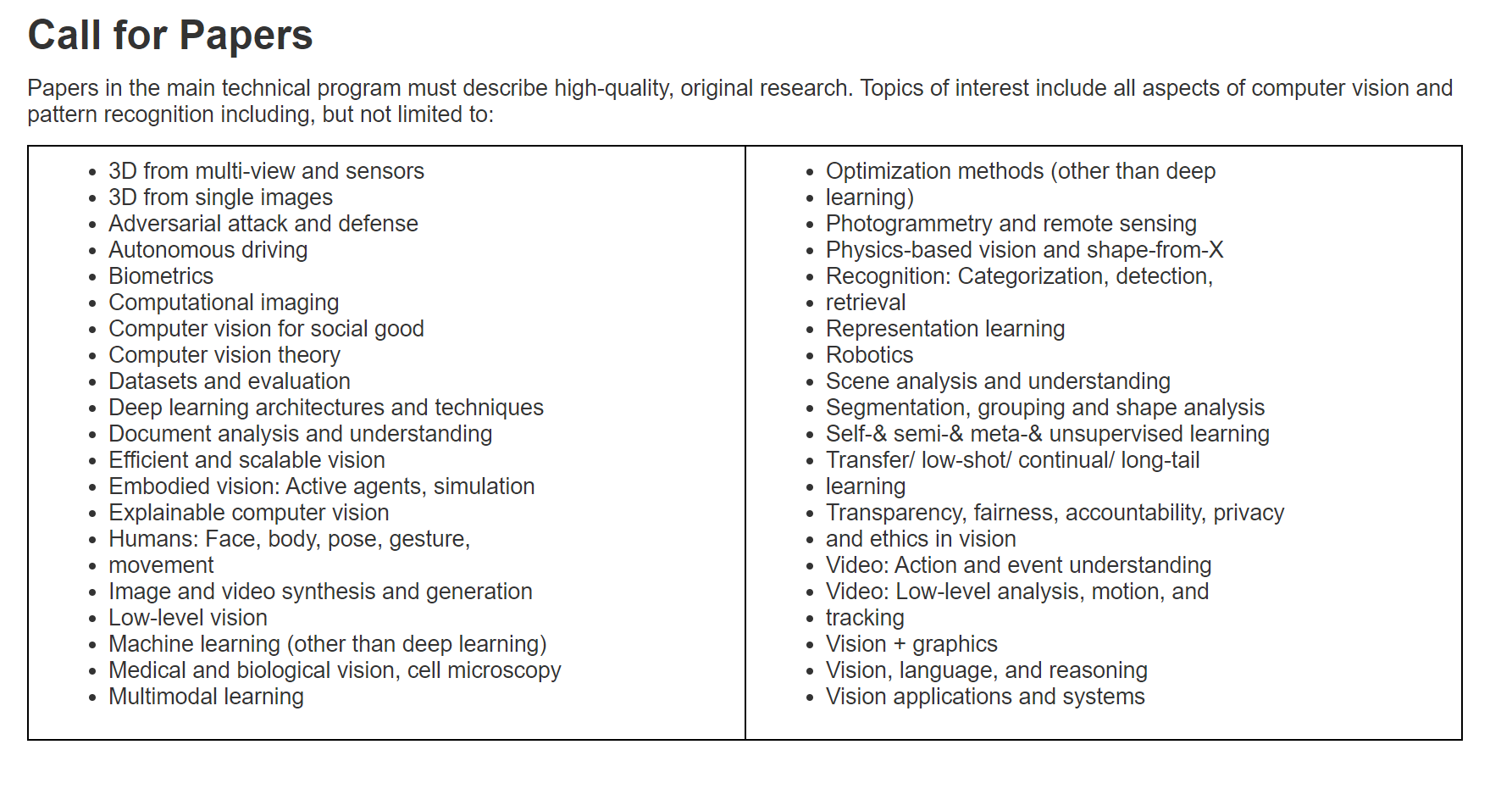
CCF_A 计算机视觉顶会CVPR2024投稿指南以及论文模板
目录 CVPR2024官网: CVPR2024投稿链接: CVPR2024 重要时间节点: CVPR2024投稿模板: WORD: LATEX : CVPR2024_AuthorGuidelines CVPR2024投稿Topics: CVPR2024官网: https://cvpr.thecvf.com/Conferences/2024CV…...

AI大神Karpathy的学习心法,普通人也能直接抄作业
美国时间2026年5月19日,AI 圈被一条重磅消息刷屏:大牛 Andrej Karpathy 在社交媒体上正式宣布加入 Anthropic。对于整个科技圈而言,他的动向影响力堪比当年乔丹宣布重返 NBA 大联盟 。这一次,他加入了 Anthropic 的预训练团队&…...

LoRA参数高效微调:低秩适配原理与可视化实战
1. 项目概述:这不是调参,是给大模型“打补丁”的手艺活LoRA(Low-Rank Adaptation)不是什么新潮概念,它本质上是一种参数高效微调(PEFT)的工程实践智慧——当你要让一个百亿参数的GPT或BERT模型去…...

2026年最新实测15款降AIGC平台红黑榜!
2026 年的毕业季注定不平凡。教育部最新发布的《学术诚信管理规范》明确指出,本科毕业论文 AIGC 率不得超过 35%,而重点高校如清华、北大等已将标准压至 25% 以内,硕士及以上学位论文更是严格控制在 18% 以下。与此同时,各大检测平…...

Flutter 混合栈开发完全指南:原理、架构与双向跳转实战
在企业级移动端迭代中,几乎没人会把成熟的原生 App 全部重写为 Flutter。绝大多数场景都是 原有原生工程 部分 Flutter 新页面 的混合开发模式。而混合开发中最棘手、最核心的问题不是视图嵌入,也不是通道通信,而是 页面栈混乱:原…...

如何快速安装elan:Lean版本管理器的完整指南
如何快速安装elan:Lean版本管理器的完整指南 【免费下载链接】elan The Lean version manager 项目地址: https://gitcode.com/gh_mirrors/el/elan elan是一个专门为Lean定理证明器设计的版本管理工具,它能让你轻松管理多个Lean安装版本。无论你是…...

KMS_VL_ALL_AIO:三步永久激活Windows和Office的智能解决方案
KMS_VL_ALL_AIO:三步永久激活Windows和Office的智能解决方案 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office文档突然…...

Awesome Video终极指南:从零开始掌握流媒体视频技术栈
Awesome Video终极指南:从零开始掌握流媒体视频技术栈 【免费下载链接】awesome-video A curated list of awesome streaming video tools, frameworks, libraries, and learning resources. 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-video 流媒…...

中兴光猫工厂模式解锁工具:3分钟获得完全控制权
中兴光猫工厂模式解锁工具:3分钟获得完全控制权 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾因中兴光猫的限制而无法进行高级配置?想要深度管理设备…...

企业级应用如何通过Taotoken聚合API管理多个大模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级应用如何通过Taotoken聚合API管理多个大模型调用 在构建企业级AI应用时,一个常见的需求是同时接入多个不同厂商的…...

G-Helper:轻量级开源硬件控制工具的深度技术解析
G-Helper:轻量级开源硬件控制工具的深度技术解析 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Expertb…...