scanpy赋值问题
今天发现一个很奇怪的bug
import numpy as np
import pandas as pd
import anndata as ad
from scipy.sparse import csr_matrix
print(ad.__version__)counts = csr_matrix(np.random.poisson(1, size=(100, 2000)), dtype=np.float32)
adata1 = ad.AnnData(counts)
print(adata1)def f(adata):adata = adata[:,0:1] # print(adata.shape)f(adata1)
print(adata1.shape)
结果如下

可以看到在函数中,这个adata的结果是变化了,但是并没有改变外部adata的值
import numpy as np
import pandas as pd
import anndata as ad
from scipy.sparse import csr_matrix
print(ad.__version__)counts = csr_matrix(np.random.poisson(1, size=(100, 2000)), dtype=np.float32)
adata1 = ad.AnnData(counts)
print(adata1.X[0:2,0:10])def f(adata):adata = adata[:,0:1] # print(adata.shape)f(adata1)
print(adata1.shape)
print(adata1.X[0:2,0:10])

但是如果一开始我不在函数中操作,而是主程序中,这个结果
import numpy as np
import pandas as pd
import anndata as ad
from scipy.sparse import csr_matrix
print(ad.__version__)counts = csr_matrix(np.random.poisson(1, size=(100, 2000)), dtype=np.float32)
adata1 = ad.AnnData(counts)
print(adata1.X.shape)adata1 = adata1[:,0:1]
print(adata1.shape)
结果如下

这个现象只能解释为adata= adata1[:,0:1]是一个复制的行为,只不过同名了,所以adata的饮用变了,如果
adata2 = adata1[:,0:1],
可以想象,这个结果不会对adata1结果有影响
这仅仅是一个简简单单的例子,下面有一个更奇怪的测试
import scanpy as sc adata= sc.read("/Users/yxk/Desktop/test_dataset/pbmc/pbmc.h5ad")
adata.obs["BATCH"] = adata.obs["batch"].copy()
adata.obs["label"]=adata.obs["celltype"].astype("category").cat.codes
n_classes= len(adata.obs["label"].value_counts())
print(adata)adata1= adata[adata.obs["batch"]=="pbmc_3p"].copy()
adata2= adata[adata.obs["batch"]=="pbmc_5p"].copy()
#print(adata1.X)
#print(adata2.X)## 如果用这种方式,我的结果是这样的
def preprocessNew(adata_A_input, ):'''Performing preprocess for a pair of datasets.To integrate multiple datasets, use function preprocess_multiple_anndata in utils.py'''adata_A = adata_A_inputprint("Finding highly variable genes...")#sc.pp.highly_variable_genes(adata_A, flavor='seurat_v3', n_top_genes=2000)#hvg_A = adata_A.var[adata_A.var.highly_variable == True].sort_values(by="highly_variable_rank").indexprint("Normalizing and scaling...")sc.pp.normalize_total(adata_A, target_sum=1e4)sc.pp.log1p(adata_A)sc.pp.highly_variable_genes(adata_A,n_top_genes=2000)hvg_A = list(adata1.var_names[adata1.var.highly_variable])adata_A = adata_A[:, hvg_A]sc.pp.scale(adata_A, max_value=10)print(adata_A.X[0:1,0:100])print(adata_A.X.shape)# 为啥这些结果是这样的preprocessNew(adata1)
print(adata1.X.shape)
 可以看到adata的结果是没有改变的,还是33694维,但是我在函数中,明明是选择了高变基因的
可以看到adata的结果是没有改变的,还是33694维,但是我在函数中,明明是选择了高变基因的
但是如果采用下面的代码
import scanpy as sc adata= sc.read("/Users/yxk/Desktop/test_dataset/pbmc/pbmc.h5ad")
adata.obs["BATCH"] = adata.obs["batch"].copy()
adata.obs["label"]=adata.obs["celltype"].astype("category").cat.codes
n_classes= len(adata.obs["label"].value_counts())
print(adata)adata1= adata[adata.obs["batch"]=="pbmc_3p"].copy()
adata2= adata[adata.obs["batch"]=="pbmc_5p"].copy()
#print(adata1.X)
#print(adata2.X)def preprocessNew(adata_A_input, ):'''Performing preprocess for a pair of datasets.To integrate multiple datasets, use function preprocess_multiple_anndata in utils.py'''adata_A = adata_A_inputprint("Finding highly variable genes...")#sc.pp.highly_variable_genes(adata_A, flavor='seurat_v3', n_top_genes=2000)#hvg_A = adata_A.var[adata_A.var.highly_variable == True].sort_values(by="highly_variable_rank").indexprint("Normalizing and scaling...")sc.pp.normalize_total(adata_A, target_sum=1e4)sc.pp.log1p(adata_A)sc.pp.highly_variable_genes(adata_A,n_top_genes=2000,subset=True)#adata_A = adata_A[:, hvg_A]sc.pp.scale(adata_A, max_value=10)print(adata_A.X[0:1,0:100])
preprocessNew(adata1)
print(adata1.X.shape)
print(adata1.X[0:1,0:100])
## 但是线则这个问题为啥不是
结果如下

这里可以看到,我最终的adata1的维度是改变了,这里需要注意
这里使用
sc.pp.highly_variable_genes(adata1,n_top_genes=2000,subset=True),就是对adata的引用改动了,最终导致最开始的atata出现了变化,反正最好还是用scanpy的内置函数了,一旦在函数里赋值就要注意局部对象的问题
import scanpy as sc adata= sc.read("/Users/yxk/Desktop/test_dataset/pbmc/pbmc.h5ad")
adata.obs["BATCH"] = adata.obs["batch"].copy()
adata.obs["label"]=adata.obs["celltype"].astype("category").cat.codes
n_classes= len(adata.obs["label"].value_counts())
print(adata)
adata1= adata[adata.obs["batch"]=="pbmc_3p"].copy()
#adata2= adata[adata.obs["batch"]=="pbmc_5p"].copy()
#print(adata1.X)
#print(adata2.X)
print("Normalizing and scaling...")
sc.pp.normalize_total(adata1, target_sum=1e4)
sc.pp.log1p(adata1)
sc.pp.highly_variable_genes(adata1,n_top_genes=2000,subset=True)
sc.pp.scale(adata1, max_value=10)
print(adata1.X[0:1,0:100])
print(adata1.X.shape)
print(adata1.X[0:1,0:100])
## 但是线则这个问题为啥不是
如果采用了preprocessNew的函数,那么本质上只对adata做了如下变化
import scanpy as sc adata= sc.read("/Users/yxk/Desktop/test_dataset/pbmc/pbmc.h5ad")
adata.obs["BATCH"] = adata.obs["batch"].copy()
adata.obs["label"]=adata.obs["celltype"].astype("category").cat.codes
n_classes= len(adata.obs["label"].value_counts())
print(adata)adata1= adata[adata.obs["batch"]=="pbmc_3p"].copy()
#adata2= adata[adata.obs["batch"]=="pbmc_5p"].copy()
#print(adata1.X)
#print(adata2.X)## 如果用这种方式,我的结果是这样的
def preprocessNew(adata_A_input, ):'''Performing preprocess for a pair of datasets.To integrate multiple datasets, use function preprocess_multiple_anndata in utils.py'''adata_A = adata_A_inputprint("Finding highly variable genes...")#sc.pp.highly_variable_genes(adata_A, flavor='seurat_v3', n_top_genes=2000)#hvg_A = adata_A.var[adata_A.var.highly_variable == True].sort_values(by="highly_variable_rank").indexprint("Normalizing and scaling...")sc.pp.normalize_total(adata_A, target_sum=1e4)sc.pp.log1p(adata_A)sc.pp.highly_variable_genes(adata_A,n_top_genes=2000)hvg_A = list(adata1.var_names[adata1.var.highly_variable])adata_A = adata_A[:, hvg_A]sc.pp.scale(adata_A, max_value=10)print(adata_A.X[0:1,0:100])print(adata_A.X.shape)# 为啥这些结果是这样的preprocessNew(adata1)
print(adata1.X.shape)
print(adata1.X[0:1,0:100])
结果如下
 reproduce result
reproduce result
import scanpy as sc adata= sc.read("/Users/yxk/Desktop/test_dataset/pbmc/pbmc.h5ad")
adata.obs["BATCH"] = adata.obs["batch"].copy()
adata.obs["label"]=adata.obs["celltype"].astype("category").cat.codes
n_classes= len(adata.obs["label"].value_counts())
print(adata)adata2= adata[adata.obs["batch"]=="pbmc_3p"].copy()#print(adata1.X)
#print(adata2.X)## 如果用这种方式,我的结果是这样的print("Normalizing and scaling...")
sc.pp.normalize_total(adata2, target_sum=1e4)
sc.pp.log1p(adata2) # 真正对adata1只有这么多的操作# 为啥这些结果是这样的
print(adata2.X.shape)
print(adata2.X[0:1,0:100])

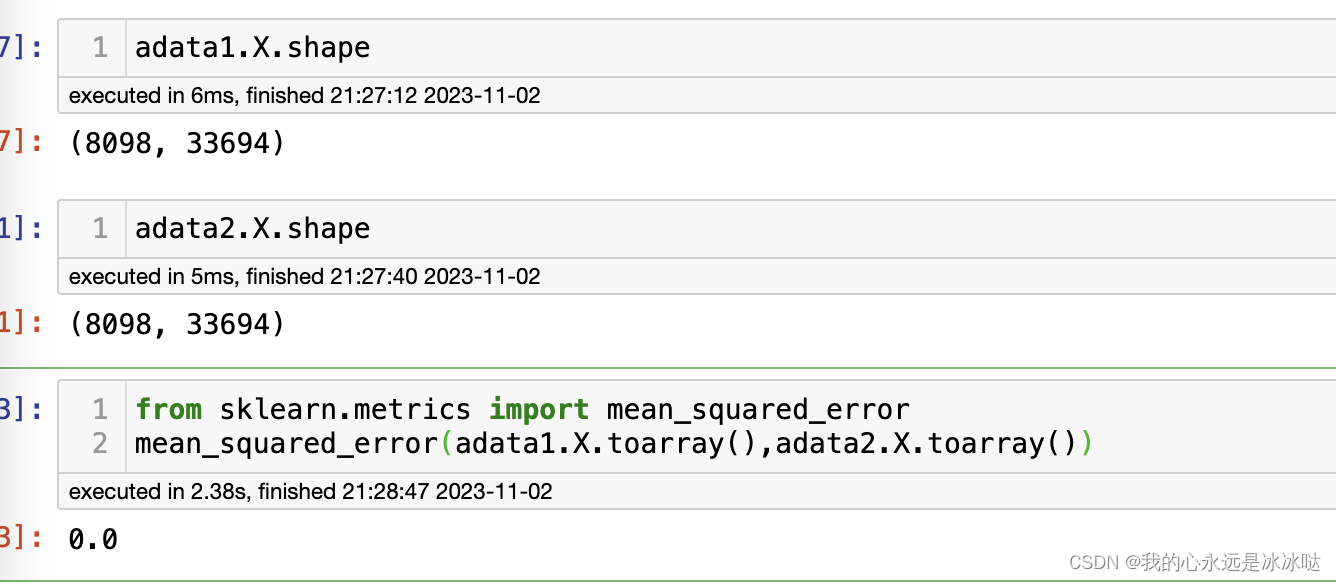
from sklearn.metrics import mean_squared_error
mean_squared_error(adata1.X.toarray(),adata2.X.toarray())
结果如下
相关文章:
scanpy赋值问题
今天发现一个很奇怪的bug import numpy as np import pandas as pd import anndata as ad from scipy.sparse import csr_matrix print(ad.__version__)counts csr_matrix(np.random.poisson(1, size(100, 2000)), dtypenp.float32) adata1 ad.AnnData(counts) print(adata1)…...
腾讯云域名备案后,如何解析到华为云服务器Linux宝塔面板
一、购买域名并且进行备案和解析,正常情况下,购买完域名,如果找不到去哪备案,可以在腾讯云上搜索“备案”关键词就会出现了,所以这里不做详细介绍,直接进行步骤提示: 二、申请ssl证书࿰…...

odoo 按钮打印pdf报表
odoo打印一般是在动作里面进行的 所以此方法可用自定义按钮进行打印 <template id"report_sale_line_packing_template"> xxx </template><template id"report_sale_line_packing"><t t-call"web.basic_layout"><t …...

用逻辑分析仪观察串口Uart数据波形
一、概述 只讨论嵌入式编程中较为常用的异步串行接口(Universal Asynchronous Receiver/Transmitter, UART),TTL电平。 串口的参数一般有: 1.波特率,数据传输速率,单位bps(bits per…...

数据结构-栈应用括号匹配
1、顺序栈的定义 2、顺序栈的入栈,出栈,取出栈顶元素,匹配判断函数 3、顺序栈的运行测试 4、实现代码 #include<iostream> using namespace std; #define OK 1 #define ERROR 0 #define OVERFLOW -2 typedef int Status; #define M…...

leetcode做题笔记209. 长度最小的子数组
给定一个含有 n 个正整数的数组和一个正整数 target 。 找出该数组中满足其总和大于等于 target 的长度最小的 连续子数组 [numsl, numsl1, ..., numsr-1, numsr] ,并返回其长度。如果不存在符合条件的子数组,返回 0 。 示例 1: 输入&#…...
【机器学习】几种常用的机器学习调参方法
在机器学习中,模型的性能往往受到模型的超参数、数据的质量、特征选择等因素影响。其中,模型的超参数调整是模型优化中最重要的环节之一。超参数(Hyperparameters)在机器学习算法中需要人为设定,它们不能直接从训练数据…...

使用免费 FlaskAPI 部署 YOLOv8
目标检测和实例分割是计算机视觉中关键的任务,使计算机能够在图像和视频中识别和定位物体。YOLOv8是一种先进的、实时的目标检测系统,因其速度和准确性而备受欢迎。 Flask是一个轻量级的Python Web框架,简化了Web应用程序的开发。通过结合Fla…...
不使用屏幕在树莓派4B安装Ubuntu22.04桌面版(64位)
因为时间有限只说一下基本路径: 1首先安装Ubuntu22.04server版本 2设置服务器版本的SSH和WiFi 3通过服务器版本安装Ubuntu-desktop升级到Ubuntu22.04桌面版 4在桌面版上安装远程控制软件:xrdp; 5使用Windows自带的远程桌面连接访问Ubuntu 6完成...
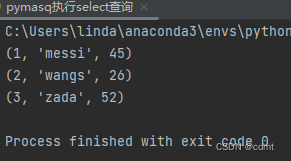
Pymysql模块使用操作
一、pymysql模块安装 二、测试数据库连接 测试数据库连接.py from pymysql import Connectioncon None try:# 创建数据库连接con Connection(host"localhost",port3306,user"root",password"XXXXX")# 测试链接print(con.get_host_info())print…...
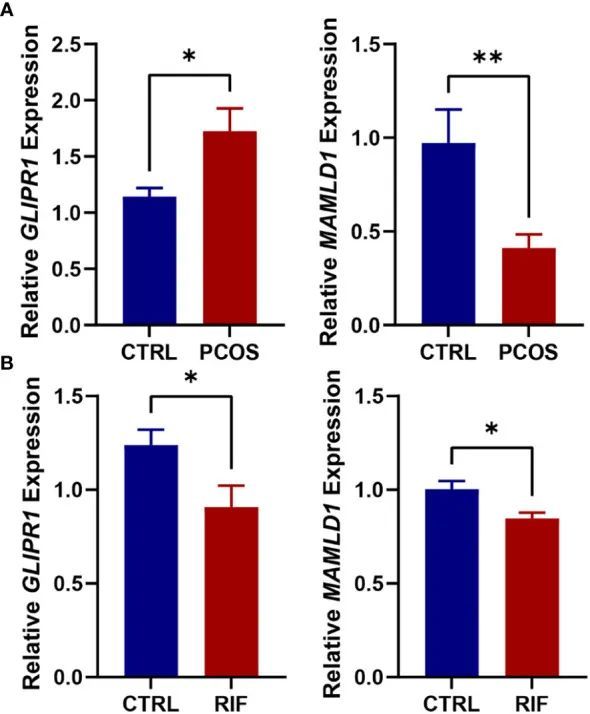
8+双疾病+WGCNA+多机器学习筛选疾病的共同靶点并验证表达
今天给同学们分享一篇双疾病WGCNA多机器学习的生信文章“Shared diagnostic genes and potential mechanism between PCOS and recurrent implantation failure revealed by integrated transcriptomic analysis and machine learning”,这篇文章于2023年5月16日发表…...

springboot如何获取前端请求头的值并加入ThreadLocal
依赖: <dependency><groupId>org.aspectj</groupId><artifactId>aspectjweaver</artifactId><version>1.9.7</version> </dependency>示例: public class ThreadLocalUtil {private static ThreadLoc…...

程序员想要网上接单却看花了眼?那这几个平台你可得收藏好了!
现在经济压力这么大,但是生活成本还在上升,相信大家都知道“四脚吞金兽”的威力了吧!话虽如此,但是生活总得继续,为了家庭的和谐幸福,为了孩子的未来,不少人选择多干几份工作,赚点外…...

前端食堂技术周刊第 102 期:Next.js 14、Yarn 4.0、State of HTML、SEO 从 0 到 1
美味值:🌟🌟🌟🌟🌟 口味:肥牛宽粉 食堂技术周刊仓库地址:https://github.com/Geekhyt/weekly 大家好,我是童欧巴。欢迎来到前端食堂技术周刊,我们先来看下…...
GPT与人类共生:解析AI助手的兴起
随着GPT模型的崭新应用,如百度的1和CSDN的2,以及AI助手的普及,人们开始讨论AI对就业市场和互联网公司的潜在影响。本文将探讨GPT和AI助手的共生关系,以及我们如何使用它们,以及使用的平台和动机。 GPT和AI助手…...
HTML脚本、字符实体、URL
HTML脚本: JavaScript 使 HTML 页面具有更强的动态和交互性。 <script> 标签用于定义客户端脚本,比如 JavaScript。<script> 元素既可包含脚本语句,也可通过 src 属性指向外部脚本文件。 JavaScript 最常用于图片操作、表单验…...

UOS安装Jenkins
一,环境准备 1.安装jdk 直接使用命令行(sudo apt install -y openjdk-11-jdk)安装jdk11 2.安装maven 参考此篇文章即可 UOS安装并配置Maven工具_uos 安装maven_蓝天下的一员的博客-CSDN博客 不过要注意这篇文章有个小错误,我…...

纯CSS实现卡片上绘制透明圆孔
<template><div class"dot-card-wrapper"><div class"top-wrapper"><slot name"top"></slot></div><!-->核心是下面这部分</--><div class"dot-row"><div class"left-…...
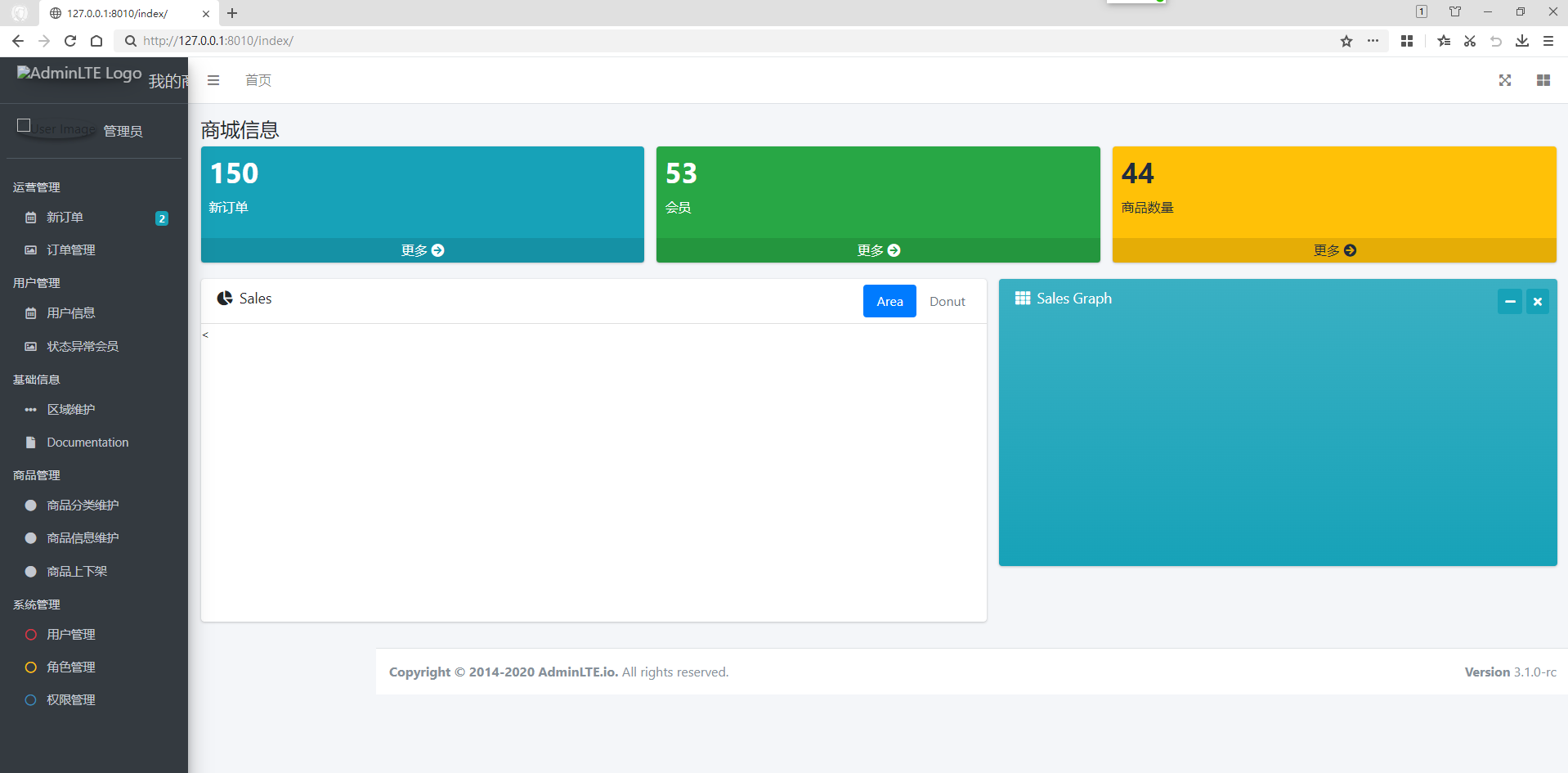
用前端框架Bootstrap的AdminLTE模板和Django实现后台首页的页面
承接博文 用前端框架Bootstrap和Django实现用户注册页面 继续开发实现 后台首页的页面。 01-下载 AdminLTE-3.1.0-rc 并解压缩 以下需要的四个文件夹及里面的文件百度网盘下载链接: https://pan.baidu.com/s/1QYpjOfSBJPmjmVuFZdSgFQ?pwdo9ta 下载 AdminLTE-3.1…...

Linux驱动 编译乱序和执行乱序
编译乱序 现代的高性能编译器在目标码优化上都具备对指令进行乱序优化的能力。编译器可以对访存的指令进行乱序,减少逻辑上不必要的访存,以及尽量提高Cache命中率和CPU的Load/Store单元的工作效率。 因此在打开编译器优化以后,看到生成的汇编…...

25款经典老芯片回顾:从运放、逻辑门到MCU,重温电子工程基石
1. 引言:一场跨越时代的芯片“认亲大会”最近在整理工作室的旧物料箱,翻出了一堆尘封已久的芯片,从布满灰尘的DIP封装到早已停产的早期逻辑门,每一片都像一张泛黄的老照片,记录着电子工业发展的一个脚印。我随手拍了几…...

GPT5.5每次推理只激活部分参数MoE路由策略完整拆解
做多模型架构对比测试时用了cc.877ai.cn这个AI模型聚合平台,一站接入多个模型方便对比不同架构策略在实际任务中的表现差异。GPT-5.5是OpenAI首个从零完整重训的基础模型。大多数人关注"变强了多少"但更值得关注的是"怎么变强的"。MoE路由策略是…...

F1C100s移植LVGL 8.2避坑指南:从Makefile修改到双缓冲配置
F1C100s移植LVGL 8.2实战手册:从编译优化到显示性能调优 在嵌入式Linux系统开发中,图形用户界面(GUI)的实现往往是最具挑战性的环节之一。对于资源受限的全志F1C100s芯片而言,如何在有限的RAM和CPU性能下实现流畅的图形交互,LVGL(…...

CANN/asc-devkit同步通知API文档
asc_sync_notify 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcod…...

如何用智能弹幕助手告别直播中的重复劳动?B站直播效率提升300%的秘密
如何用智能弹幕助手告别直播中的重复劳动?B站直播效率提升300%的秘密 【免费下载链接】MagicalDanmaku 本仓库及所有相关项目已永久停止开发、维护和任何形式的分发。 项目地址: https://gitcode.com/gh_mirrors/bi/MagicalDanmaku 还在为直播时手忙脚乱而烦…...

SMARTFORM不同模板一起打印
一、背景由于客户提出发货单要加上条形码打印,条形码单独一个模板,加在后面打印,输出PDF并发送邮件。二、效果展示不同模板一起打印效果如下,建立smartforms的表单时,也使用了两个不同的模板三、smartforms建立表单&am…...

ARMv8通用定时器架构与CNTHP_CTL_EL2寄存器详解
1. AArch64通用定时器架构概述在ARMv8架构中,通用定时器系统为操作系统和应用程序提供了精确的时间基准。这套计时系统由一组相互关联的组件构成,包括物理计数器、虚拟计数器以及多个比较器。作为系统程序员,理解这套机制对开发底层系统软件至…...

Onekey Steam清单下载工具:3步搞定游戏清单管理的终极指南
Onekey Steam清单下载工具:3步搞定游戏清单管理的终极指南 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 在Steam游戏生态中,清单文件是连接游戏客户端与服务器资源的关…...

开源鸿蒙OpenHarmony在微纳卫星上的航天级改造与应用实践
1. 项目概述:当开源鸿蒙“遇见”微纳卫星最近在航天圈里有个挺有意思的事儿,开源鸿蒙OpenHarmony系统,就是咱们手机、平板上那个鸿蒙系统的开源版本,现在已经成功“上天”了。这事儿不是概念验证,而是实打实地应用在了…...

Kimi LeetCode 2547. 拆分数组的最小代价 C++实现
这道题的核心思路是动态规划 记忆化搜索。我们定义 dfs(i) 为从下标 i 开始拆分数组的最小代价,答案即为 dfs(0)。关键观察子数组的重要性 k trimmed(subarray).length。其中 trimmed 操作会移除子数组中只出现一次的数字。如果我们用 cnt[x] 记录数字 x 在当前子…...