【机器学习】几种常用的机器学习调参方法
在机器学习中,模型的性能往往受到模型的超参数、数据的质量、特征选择等因素影响。其中,模型的超参数调整是模型优化中最重要的环节之一。超参数(Hyperparameters)在机器学习算法中需要人为设定,它们不能直接从训练数据中学习得出。与之对应的是模型参数(Model Parameters),它们是模型内部学习得来的参数。
以支持向量机(SVM)为例,其中C、kernel 和 gamma 就是超参数,而通过数据学习到的权重 w 和偏置 b则 是模型参数。实际应用中,我们往往需要选择合适的超参数才能得到一个好的模型。搜索超参数的方法有很多种,如网格搜索、随机搜索、对半网格搜索、贝叶斯优化、遗传算法、模拟退火等方法,具体内容如下。
一、网格搜索
网格搜索可能是最简单、应用最广泛的超参数搜索算法,通过查找搜索范围内的所有的点来确定最优值。如果采用较大的搜索范围以及较小的步长,网恪搜索很大概率找到全局最优值。 然而,这种搜索方案十分消耗计算资源和时间,特别是需要调优的超参数比较多的时候。
因此, 在实际应用中,网格搜索法一般会先使用较广的搜索范围和较大的步长,来寻找全局最优值可能的位置。然后通过逐渐缩小搜索范围和步长,来寻找更精确的最优值。 这种操作方案可以降低所需的时间和计算量, 但由于目标函数一般是非凸的, 所以很可能会错过全局最优值。
import time
from sklearn.model_selection import KFold
from sklearn.ensemble import RandomForestClassifierrf_param_grid = {'max_depth' : list(range(2,20,2)),'n_estimators': list(range(20,800,100)),'min_samples_split': [2,6,10],'min_samples_leaf': [2,6,10]}
#计算参数空间大小
def count_space(rf_param_grid):no_option=1for i in rf_param_grid:no_option*=len(rf_param_grid[i])return no_option
count_space(rf_param_grid)
参数空间总量为648个。
#网格搜索GridSearchCV
from sklearn.model_selection import GridSearchCV
start_time = time.time()
m = RandomForestClassifier(n_jobs = -1, random_state = 2023)
cv = KFold(n_splits = 5, shuffle = True, random_state = 2023)
m_g = GridSearchCV(param_grid=rf_param_grid,estimator = m,scoring = "roc_auc",cv = cv)
m_g.fit(x_train, y_train)
end_time = time.time()
run_time = end_time - start_time
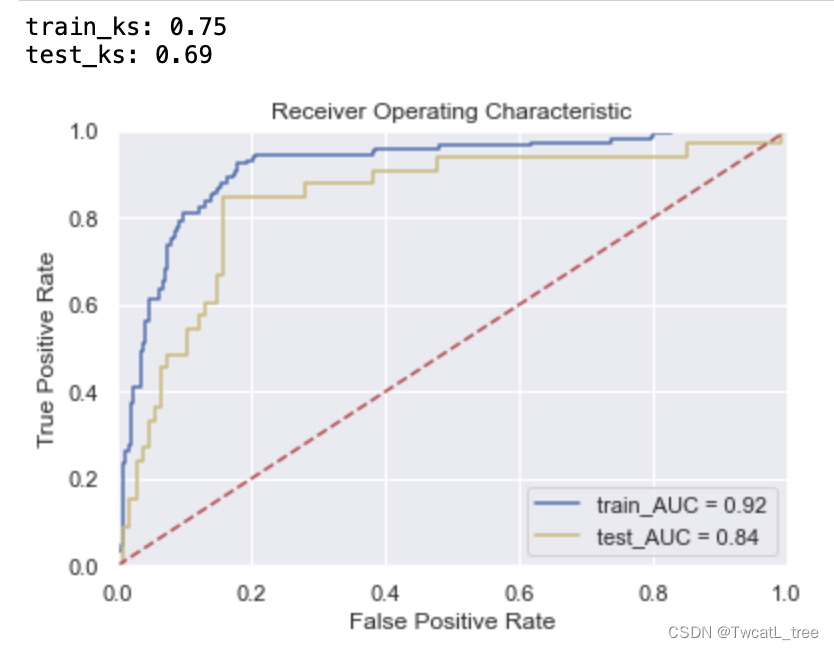
print("GridSearchCV time", run_time)

for key in m_r.best_params_.keys():print('%s = %s'%(key,m_g.best_params_[key]))

y_pred_train = m_g.predict_proba(x_train)[:,1]
fpr_train,tpr_train,_ = roc_curve(y_train,y_pred_train)
train_ks = round(abs(fpr_train-tpr_train).max(), 2)
roc_auc_train = auc(fpr_train, tpr_train)
print('train_ks:',train_ks)y_pred = m_g.predict_proba(x_test)[:,1]
fpr_test, tpr_test,_ = roc_curve(y_test,y_pred)
test_ks = round(abs(fpr_test-tpr_test).max(), 2)
roc_auc_test = auc(fpr_test, tpr_test)
print('test_ks:',test_ks)plt.title('Receiver Operating Characteristic')
plt.plot(fpr_train, tpr_train, 'b', label = 'train_AUC = %0.2f' % roc_auc_train)
plt.plot(fpr_test, tpr_test, 'y', label = 'test_AUC = %0.2f' % roc_auc_test)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
二、随机搜索
随机搜索的思想与网格搜索比较相似,只是不再测试上界和下界之间的所有值,而是在搜索范围中随机选取样本点。它的理论依据是,如果样本点集足够大,那么通过随机采样也能大概率地找到全局最优值, 或其近似值。随机搜索一般会比网格搜索要快一些,但是和网格搜索的快速版一样,它的结果也是没法保证的。
# 随机搜索RandomizedSearchCV
from sklearn.model_selection import RandomizedSearchCV
m = RandomForestClassifier(n_jobs = -1, random_state = 2023)
cv = KFold(n_splits = 5, shuffle = True, random_state = 2023)m_r = RandomizedSearchCV(param_distributions=rf_param_grid,estimator = m,scoring = "roc_auc",cv = cv,n_iter=10,verbose=True,n_jobs=-1)
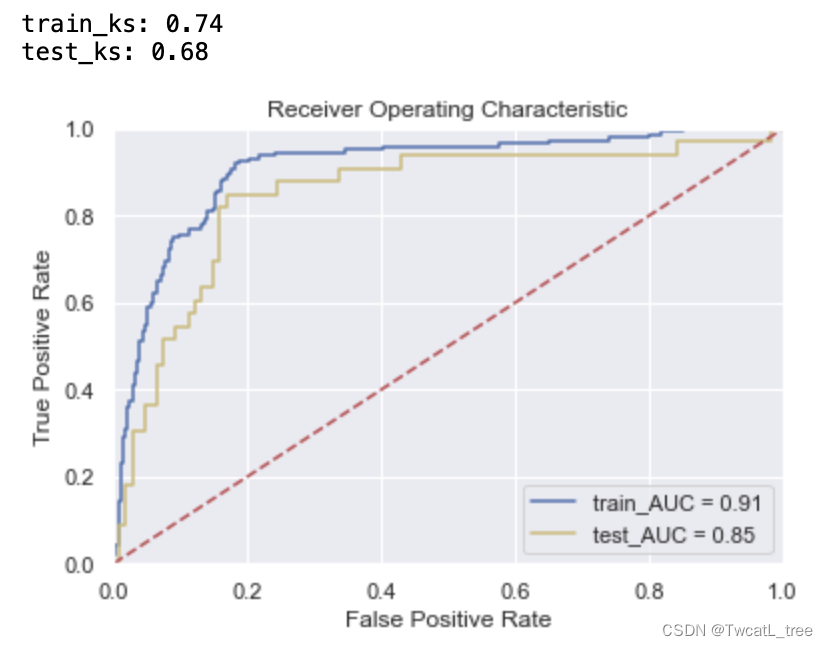
%time m_r.fit(x_train, y_train)

print("best params:", m_r.best_estimator_, "\n","\n", "best cvscore:", m_r.best_score_)

y_pred_train = m_r.predict_proba(x_train)[:,1]
fpr_train,tpr_train,_ = roc_curve(y_train,y_pred_train)
train_ks = round(abs(fpr_train-tpr_train).max(), 2)
roc_auc_train = auc(fpr_train, tpr_train)
print('train_ks:',train_ks)y_pred = m_r.predict_proba(x_test)[:,1]
fpr_test, tpr_test,_ = roc_curve(y_test,y_pred)
test_ks = round(abs(fpr_test-tpr_test).max(), 2)
roc_auc_test = auc(fpr_test, tpr_test)
print('test_ks:',test_ks)plt.title('Receiver Operating Characteristic')
plt.plot(fpr_train, tpr_train, 'b', label = 'train_AUC = %0.2f' % roc_auc_train)
plt.plot(fpr_test, tpr_test, 'y', label = 'test_AUC = %0.2f' % roc_auc_test)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
三、对半网格搜索
面对枚举网格搜索过慢的问题,sklearn中呈现了两种优化方式:其一是调整搜索空间,其二是调整每次训练的数据。调整搜索空间的方法就是随机网格搜索,而调整每次训练数据的方法就是对半网格搜索。
假设现在有数据集D,我们从数据集D中随机抽样出一个子集d。如果一组参数在整个数据集D上表现较差,那大概率这组参数在数据集的子集d上表现也不会太好。反之,如果一组参数在子集d上表现不好,我们也不会信任这组参数在全数据集D上的表现。那么我们可以认为参数在子集与在全数据集上的表现一致。
但在现实数据中,这一假设要成立是有条件的,即任意子集的分布都与全数据集D的分布类似。当子集的分布越接近全数据集的分布,同一组参数在子集与全数据集上的表现越有可能一致。根据之前在随机网格搜索中得出的结论,我们知道子集越大、其分布越接近全数据集的分布,但是大子集又会导致更长的训练时间,因此为了整体训练效率,我们不可能无限地增大子集。这就出现了一个矛盾:大子集上的结果更可靠,但大子集计算更缓慢。
对半网格搜索算法设计了一个精妙的流程,可以很好的权衡子集的大小与计算效率问题,具体流程如下:
首先从全数据集中无放回随机抽样出一个很小的子集 d0 ,并在d0上验证全部参数组合的性能。根据d0上的验证结果,淘汰评分排在后1/2的那一半参数组合。然后,从全数据集中再无放回抽样出一个比 d0大一倍的子集 d1,并在d1上验证剩下的那一半参数组合的性能。根据 d1上的验证结果,淘汰评分排在后1/2的参数组合。再从全数据集中无放回抽样出一个比 d1大一倍的子集 d2,并在 d2上验证剩下1/4的参数组合的性能。根据 d2上的验证结果,淘汰评分排在后1/2的参数组合……,直至到达限制条件。
在这种模式下,只有在不同的子集上不断获得优秀结果的参数组合能够被留存到迭代的后期,最终选择出的参数组合一定是在所有子集上都表现优秀的参数组合。这样一个参数组合在全数据上表现优异的可能性是非常大的,同时也可能展现出比网格、随机搜索得出的参数更大的泛化能力。
然而这个过程当中会存在一个问题:子集越大时,子集与全数据集D的分布会越相似,但整个对半搜索算法在开头的时候,就用最小的子集筛掉了最多的参数组合。如果最初的子集与全数据集的分布差异很大,那么在对半搜索开头的前几次迭代中,就可能筛掉许多对全数据集D有效的参数,因此对半网格搜索最初的子集一定不能太小。
# 对半网格搜索HalvingGridSearchCV
from sklearn.experimental import enable_halving_search_cv
from sklearn.model_selection import HalvingGridSearchCVm = RandomForestClassifier(n_jobs = -1, random_state = 2023)
cv = KFold(n_splits = 5, shuffle = True, random_state = 2023)
m_h = HalvingGridSearchCV(estimator = m,param_grid=rf_param_grid,factor=3,min_resources = 100,scoring='roc_auc',n_jobs = -1,random_state=2023,cv=cv)
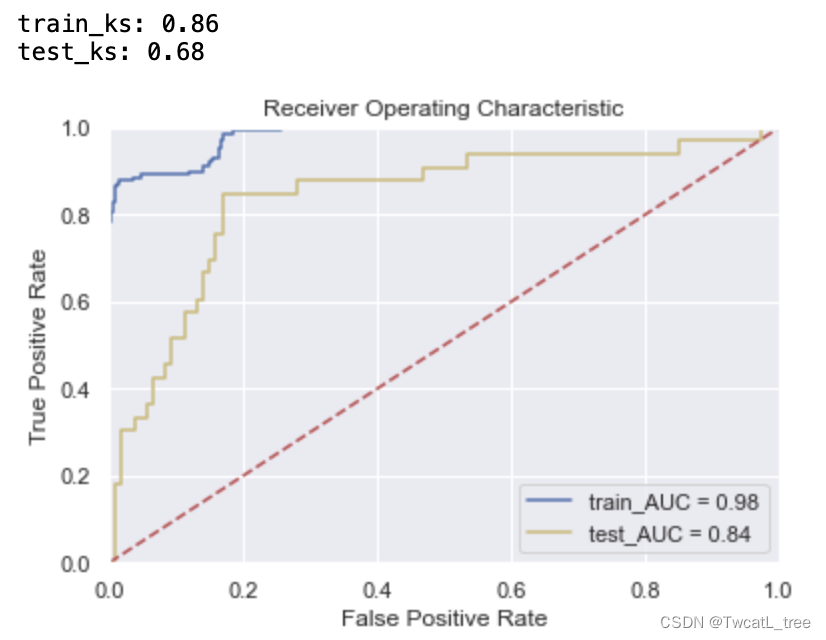
%time m_h.fit(x_train, y_train)

print("best params:", m_h.best_estimator_, "\n","\n", "best cvscore:", m_h.best_score_)

y_pred_train = m_h.predict_proba(x_train)[:,1]
fpr_train,tpr_train,_ = roc_curve(y_train,y_pred_train)
train_ks = round(abs(fpr_train-tpr_train).max(), 2)
roc_auc_train = auc(fpr_train, tpr_train)
print('train_ks:',train_ks)y_pred = m_h.predict_proba(x_test)[:,1]
fpr_test, tpr_test,_ = roc_curve(y_test,y_pred)
test_ks = round(abs(fpr_test-tpr_test).max(), 2)
roc_auc_test = auc(fpr_test, tpr_test)
print('test_ks:',test_ks)plt.title('Receiver Operating Characteristic')
plt.plot(fpr_train, tpr_train, 'b', label = 'train_AUC = %0.2f' % roc_auc_train)
plt.plot(fpr_test, tpr_test, 'y', label = 'test_AUC = %0.2f' % roc_auc_test)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
四、贝叶斯优化
贝叶斯优化算法在寻找最优值参数时,采用了与网格搜索、随机搜索完全不同的方法。网格搜索和随机搜索在测试一个新点时,会忽略前一个点的信息,而贝叶斯优化算法则充分利用了之前的信息。贝叶斯优化算法通过对目标函数形状进行学习,找到使目标函数向全局最优值提升的参数。
具体来说,它学习目标函数形状的方法是,首先根据先验分布,假设一个搜集函数,每一次使用新的采样点来测试目标函数时,利用这个信息来更新目标函数的先验分布;最后,算法测试由后验分布给出的全局最值最可能出现的位置的点。
对于贝叶斯优化算法,有一个需要注意的地方,一旦找到了一个局部最优值,它会在该区域不断采样,所以很容易陷入局部最优值。为了弥补这个缺陷,贝叶斯优化算法会在探索和利用之间找到一个平衡点,“探索”就是在还未取样的区域获取采样点;而“利用”则是根据后验分布在最可能出现全局最值的区域进行采样。下图为贝叶斯优化框架:

4.1基于高斯过程的贝叶斯优化
bayes-optimization是最早开源的贝叶斯优化库之一,也是为数不多至今依然保留着高斯过程优化的优化库。
#贝叶斯优化Baysian optimization
##BayesianOptimization只支持目标函数最大值,不支持最小值
from bayes_opt import BayesianOptimizationdef randomforest_evaluate(**params):params['max_depth'] = int(round(params['max_depth'],0))params['n_estimators'] = int(round(params['n_estimators'],0))params['min_samples_split'] = int(round(params['min_samples_split'],0))params['min_samples_leaf'] = int(round(params['min_samples_leaf'],0))model = RandomForestClassifier(**params, n_jobs=-1, random_state = 2023)cv = KFold(n_splits = 5, shuffle = True, random_state = 2023)validation_loss = cross_validate(model, x_train, y_train,scoring='roc_auc',cv = cv,verbose=False,n_jobs=-1,error_score='raise') return np.mean(validation_loss['test_score'])
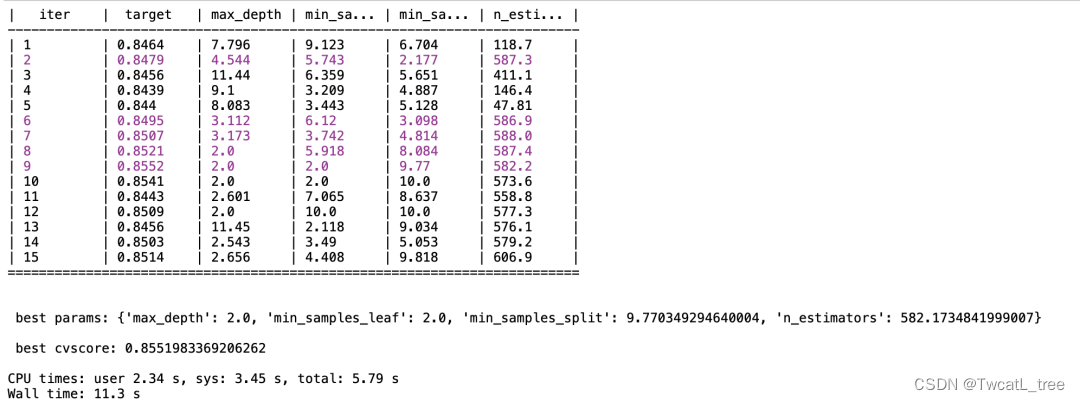
rf_param_grid = {'max_depth' : (2,20),'n_estimators': (20,800),'min_samples_split': (2,10),'min_samples_leaf': (2, 10)}def param_bayes_opt(init_points, n_iter):opt = BayesianOptimization(randomforest_evaluate, rf_param_grid, random_state=2023)opt.maximize(init_points = init_points, n_iter = n_iter)params_best = opt.max['params']score_best = opt.max['target']print("\n","\n", "best params:", params_best,"\n","\n", "best cvscore:", score_best,"\n")%time param_bayes_opt(5, 10)
m_o = RandomForestClassifier(max_depth = 2,min_samples_leaf = 2,min_samples_split = 9,n_estimators = 582,n_jobs = -1,random_state = 2023).fit(x_train, y_train)y_pred_train = m_o.predict_proba(x_train)[:,1]
fpr_train,tpr_train,_ = roc_curve(y_train,y_pred_train)
train_ks = round(abs(fpr_train-tpr_train).max(), 2)
roc_auc_train = auc(fpr_train, tpr_train)
print('train_ks:',train_ks)y_pred = m_o.predict_proba(x_test)[:,1]
fpr_test, tpr_test,_ = roc_curve(y_test,y_pred)
test_ks = round(abs(fpr_test-tpr_test).max(), 2)
roc_auc_test = auc(fpr_test, tpr_test)
print('test_ks:',test_ks)plt.title('Receiver Operating Characteristic')
plt.plot(fpr_train, tpr_train, 'b', label = 'train_AUC = %0.2f' % roc_auc_train)
plt.plot(fpr_test, tpr_test, 'y', label = 'test_AUC = %0.2f' % roc_auc_test)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()

4.2基于TPE的贝叶斯优化
Hyperopt优化器是目前最为通用的贝叶斯优化器之一,Hyperopt中集成了包括随机搜索、模拟退火和TPE(Tree-structured Parzen Estimator Approach)等多种优化算法。可通过参数algo指定搜索算法,如随机搜索hyperopt.rand.suggest、模拟退火hyperopt.anneal.suggest、TPE算法hyperopt.tpe.suggest。
相比于Bayes_opt,Hyperopt的是更先进、更现代、维护更好的优化器,也是我们最常用来实现TPE方法的优化器。在实际使用中,相比基于高斯过程的贝叶斯优化,基于高斯混合模型的TPE在大多数情况下以更高效率获得更优结果,该方法目前也被广泛应用于AutoML领域中。
#贝叶斯优化Tree of Parzen Estimators (TPE)
#Hyperopt只支持寻找目标函数的最小值,不支持寻找最大值
from hyperopt import hp, fmin, tpe, Trials, partial
from hyperopt.early_stop import no_progress_loss# 设定参数空间
space = {'max_depth': hp.quniform('max_depth', 2,20, 2),'n_estimators': hp.quniform('n_estimators', 20, 800, 50),'min_samples_split' : hp.choice('min_samples_split',[2,3,6,9,10]),'min_samples_leaf' : hp.choice('min_samples_leaf',[2,3,6,9,10])}# 设定目标函数_基评估器选择随机森林
def randomforest_evaluate(params):model = RandomForestClassifier(n_estimators = int(params["n_estimators"]),max_depth = int(params["max_depth"]),min_samples_split = int(params["min_samples_split"]),min_samples_leaf = params["min_samples_leaf"],n_jobs=-1, random_state = 2023)cv = KFold(n_splits = 5, shuffle = True, random_state = 2023)validation_loss = cross_validate(model, x_train, y_train,scoring='roc_auc',cv = cv,verbose = False,n_jobs = -1,error_score = 'raise') return np.mean((-1) * validation_loss['test_score'])def param_hyperopt(max_evals):#记录迭代过程trials=Trials()#提前停止early_stop_fn=no_progress_loss(100) #定义代理模型params_best=fmin(randomforest_evaluate,space=space ,algo=tpe.suggest,max_evals=max_evals,trials=trials ,early_stop_fn=early_stop_fn)if params_best["min_samples_split"] <=1:params_best["min_samples_split"] = 2if params_best["min_samples_split"] <=1:params_best["min_samples_leaf"] = 2print('best parmas:',params_best)return params_best,trials%time params_best, trials=param_hyperopt(30)

m_t = RandomForestClassifier(max_depth = 2,min_samples_leaf = 4,min_samples_split = 4,n_estimators = 350,n_jobs = -1,random_state = 2023).fit(x_train, y_train)y_pred_train = m_t.predict_proba(x_train)[:,1]
fpr_train,tpr_train,_ = roc_curve(y_train,y_pred_train)
train_ks = round(abs(fpr_train-tpr_train).max(), 2)
roc_auc_train = auc(fpr_train, tpr_train)
print('train_ks:',train_ks)y_pred = m_t.predict_proba(x_test)[:,1]
fpr_test, tpr_test,_ = roc_curve(y_test,y_pred)
test_ks = round(abs(fpr_test-tpr_test).max(), 2)
roc_auc_test = auc(fpr_test, tpr_test)
print('test_ks:',test_ks)plt.title('Receiver Operating Characteristic')
plt.plot(fpr_train, tpr_train, 'b', label = 'train_AUC = %0.2f' % roc_auc_train)
plt.plot(fpr_test, tpr_test, 'y', label = 'test_AUC = %0.2f' % roc_auc_test)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
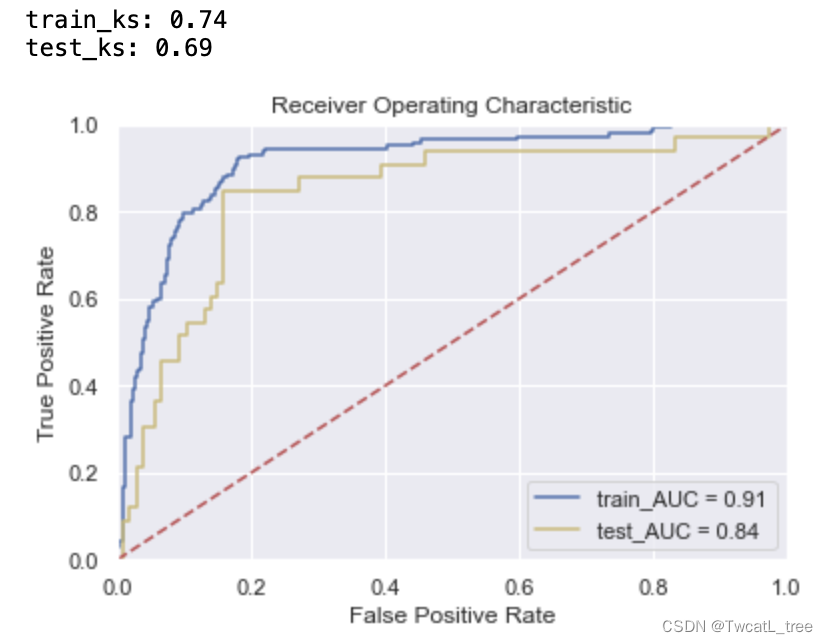
五、遗传算法
受生物进化论的启发,1975年J.Holland提出遗传算法(Genetic Algorithm,GA)。GA是一种基于“适者生存”的高度并行、随机和自适应优化的搜索算法,它将问题的求解表示成“染色体”的适者生存过程。通过“染色体”群的一代代不断进化,使用复制(reproduction)、交叉(crossover)和变异(mutation)等操作,最终收敛到“最适应环境”的个体,从而求得问题最优解。
本文遗传算法调参使用Tree-based Pipeline Optimization Tool库(TPOT,基于树的管道优化工具)。TPOT 基于树的结构来表示预测建模问题的模型管道,包括数据准备和建模算法以及模型超参数。它利用流行的 Scikit-Learn 机器学习库进行数据转换和机器学习算法,并使用遗传编程随机全局搜索过程来有效地发现给定数据集的性能最佳的模型管道。
from tpot import TPOTClassifiern_estimators = [10,11,12,13,14,15,16]
max_depth = [5,10,20,30,40,50,60]
criterion=['entropy', 'gini']
min_samples_leaf=[1, 2, 5, 10]
min_samples_split=[2, 5, 10, 15]
max_features = ['auto', 'sqrt','log2']param = {'n_estimators': n_estimators,'max_features': max_features,'max_depth': max_depth,'min_samples_split': min_samples_split,'min_samples_leaf': min_samples_leaf,'criterion':['entropy','gini']}tpot_classifier = TPOTClassifier(generations= 5, population_size= 24, offspring_size= 12,verbosity= 2, early_stop= 12,config_dict={'sklearn.ensemble.RandomForestClassifier': param}, cv = 4, scoring = 'roc_auc')
%time tpot_classifier.fit(x_train,y_train)
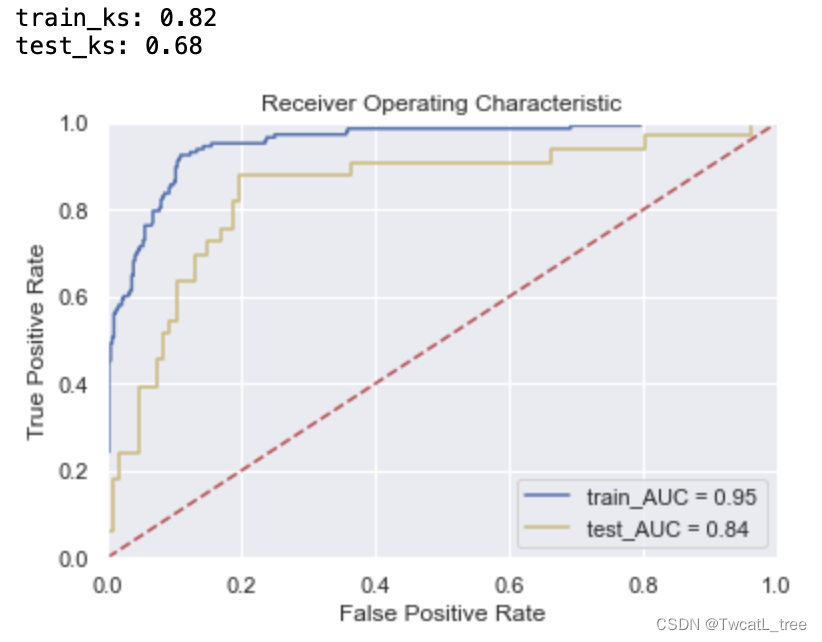
m_a = RandomForestClassifier(max_depth = 5,min_samples_leaf = 1,min_samples_split = 10,n_estimators = 11,criterion='gini',n_jobs = -1,random_state = 2023).fit(x_train, y_train)y_pred_train = m_a.predict_proba(x_train)[:,1]
fpr_train,tpr_train,_ = roc_curve(y_train,y_pred_train)
train_ks = round(abs(fpr_train-tpr_train).max(), 2)
roc_auc_train = auc(fpr_train, tpr_train)
print('train_ks:',train_ks)y_pred = m_a.predict_proba(x_test)[:,1]
fpr_test, tpr_test,_ = roc_curve(y_test,y_pred)
test_ks = round(abs(fpr_test-tpr_test).max(), 2)
roc_auc_test = auc(fpr_test, tpr_test)
print('test_ks:',test_ks)plt.title('Receiver Operating Characteristic')
plt.plot(fpr_train, tpr_train, 'b', label = 'train_AUC = %0.2f' % roc_auc_train)
plt.plot(fpr_test, tpr_test, 'y', label = 'test_AUC = %0.2f' % roc_auc_test)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()
相关文章:
【机器学习】几种常用的机器学习调参方法
在机器学习中,模型的性能往往受到模型的超参数、数据的质量、特征选择等因素影响。其中,模型的超参数调整是模型优化中最重要的环节之一。超参数(Hyperparameters)在机器学习算法中需要人为设定,它们不能直接从训练数据…...

使用免费 FlaskAPI 部署 YOLOv8
目标检测和实例分割是计算机视觉中关键的任务,使计算机能够在图像和视频中识别和定位物体。YOLOv8是一种先进的、实时的目标检测系统,因其速度和准确性而备受欢迎。 Flask是一个轻量级的Python Web框架,简化了Web应用程序的开发。通过结合Fla…...
不使用屏幕在树莓派4B安装Ubuntu22.04桌面版(64位)
因为时间有限只说一下基本路径: 1首先安装Ubuntu22.04server版本 2设置服务器版本的SSH和WiFi 3通过服务器版本安装Ubuntu-desktop升级到Ubuntu22.04桌面版 4在桌面版上安装远程控制软件:xrdp; 5使用Windows自带的远程桌面连接访问Ubuntu 6完成...
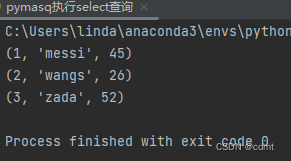
Pymysql模块使用操作
一、pymysql模块安装 二、测试数据库连接 测试数据库连接.py from pymysql import Connectioncon None try:# 创建数据库连接con Connection(host"localhost",port3306,user"root",password"XXXXX")# 测试链接print(con.get_host_info())print…...
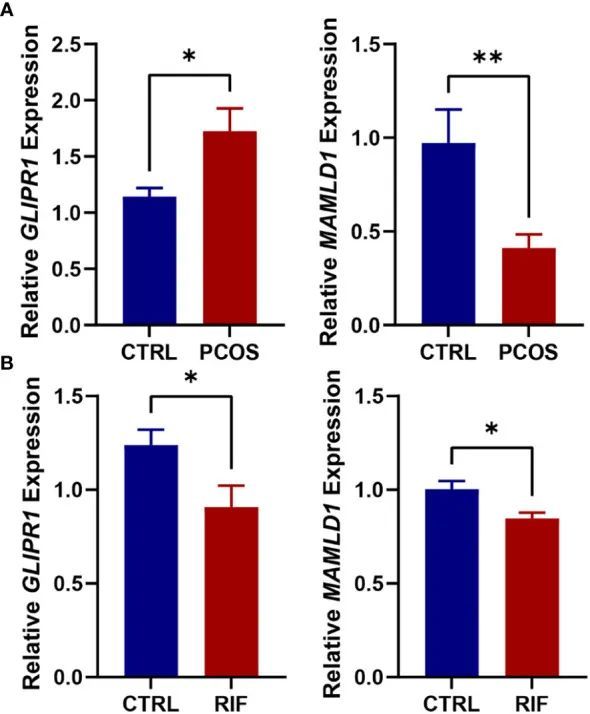
8+双疾病+WGCNA+多机器学习筛选疾病的共同靶点并验证表达
今天给同学们分享一篇双疾病WGCNA多机器学习的生信文章“Shared diagnostic genes and potential mechanism between PCOS and recurrent implantation failure revealed by integrated transcriptomic analysis and machine learning”,这篇文章于2023年5月16日发表…...

springboot如何获取前端请求头的值并加入ThreadLocal
依赖: <dependency><groupId>org.aspectj</groupId><artifactId>aspectjweaver</artifactId><version>1.9.7</version> </dependency>示例: public class ThreadLocalUtil {private static ThreadLoc…...

程序员想要网上接单却看花了眼?那这几个平台你可得收藏好了!
现在经济压力这么大,但是生活成本还在上升,相信大家都知道“四脚吞金兽”的威力了吧!话虽如此,但是生活总得继续,为了家庭的和谐幸福,为了孩子的未来,不少人选择多干几份工作,赚点外…...

前端食堂技术周刊第 102 期:Next.js 14、Yarn 4.0、State of HTML、SEO 从 0 到 1
美味值:🌟🌟🌟🌟🌟 口味:肥牛宽粉 食堂技术周刊仓库地址:https://github.com/Geekhyt/weekly 大家好,我是童欧巴。欢迎来到前端食堂技术周刊,我们先来看下…...
GPT与人类共生:解析AI助手的兴起
随着GPT模型的崭新应用,如百度的1和CSDN的2,以及AI助手的普及,人们开始讨论AI对就业市场和互联网公司的潜在影响。本文将探讨GPT和AI助手的共生关系,以及我们如何使用它们,以及使用的平台和动机。 GPT和AI助手…...
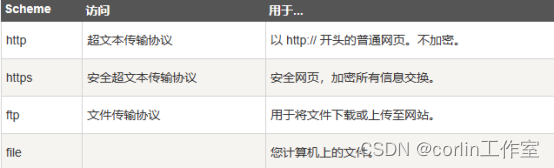
HTML脚本、字符实体、URL
HTML脚本: JavaScript 使 HTML 页面具有更强的动态和交互性。 <script> 标签用于定义客户端脚本,比如 JavaScript。<script> 元素既可包含脚本语句,也可通过 src 属性指向外部脚本文件。 JavaScript 最常用于图片操作、表单验…...

UOS安装Jenkins
一,环境准备 1.安装jdk 直接使用命令行(sudo apt install -y openjdk-11-jdk)安装jdk11 2.安装maven 参考此篇文章即可 UOS安装并配置Maven工具_uos 安装maven_蓝天下的一员的博客-CSDN博客 不过要注意这篇文章有个小错误,我…...

纯CSS实现卡片上绘制透明圆孔
<template><div class"dot-card-wrapper"><div class"top-wrapper"><slot name"top"></slot></div><!-->核心是下面这部分</--><div class"dot-row"><div class"left-…...
用前端框架Bootstrap的AdminLTE模板和Django实现后台首页的页面
承接博文 用前端框架Bootstrap和Django实现用户注册页面 继续开发实现 后台首页的页面。 01-下载 AdminLTE-3.1.0-rc 并解压缩 以下需要的四个文件夹及里面的文件百度网盘下载链接: https://pan.baidu.com/s/1QYpjOfSBJPmjmVuFZdSgFQ?pwdo9ta 下载 AdminLTE-3.1…...

Linux驱动 编译乱序和执行乱序
编译乱序 现代的高性能编译器在目标码优化上都具备对指令进行乱序优化的能力。编译器可以对访存的指令进行乱序,减少逻辑上不必要的访存,以及尽量提高Cache命中率和CPU的Load/Store单元的工作效率。 因此在打开编译器优化以后,看到生成的汇编…...
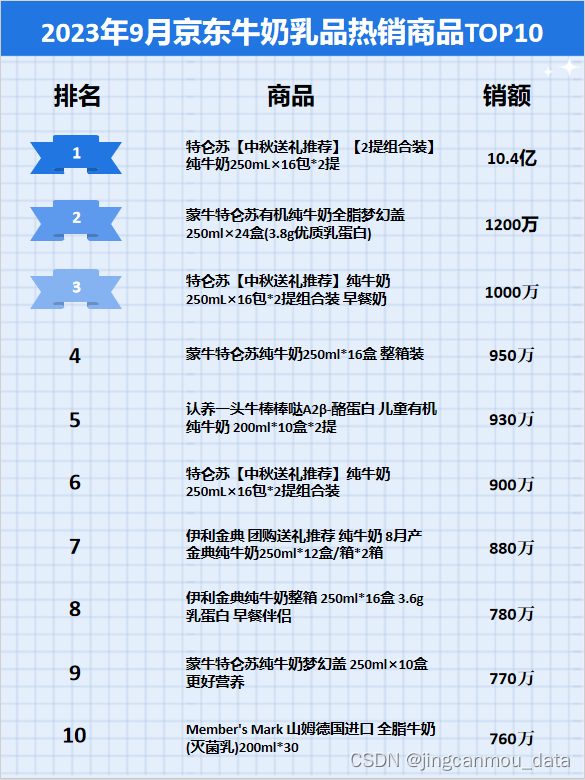
京东大数据平台(京东数据分析):9月京东牛奶乳品排行榜
鲸参谋监测的京东平台9月份牛奶乳品市场销售数据已出炉! 9月份,牛奶乳品市场销售呈大幅上涨。鲸参谋数据显示,今年9月,京东平台牛奶乳品市场的销量为2000万,环比增长约65%,同比增长约3%;销售额为…...
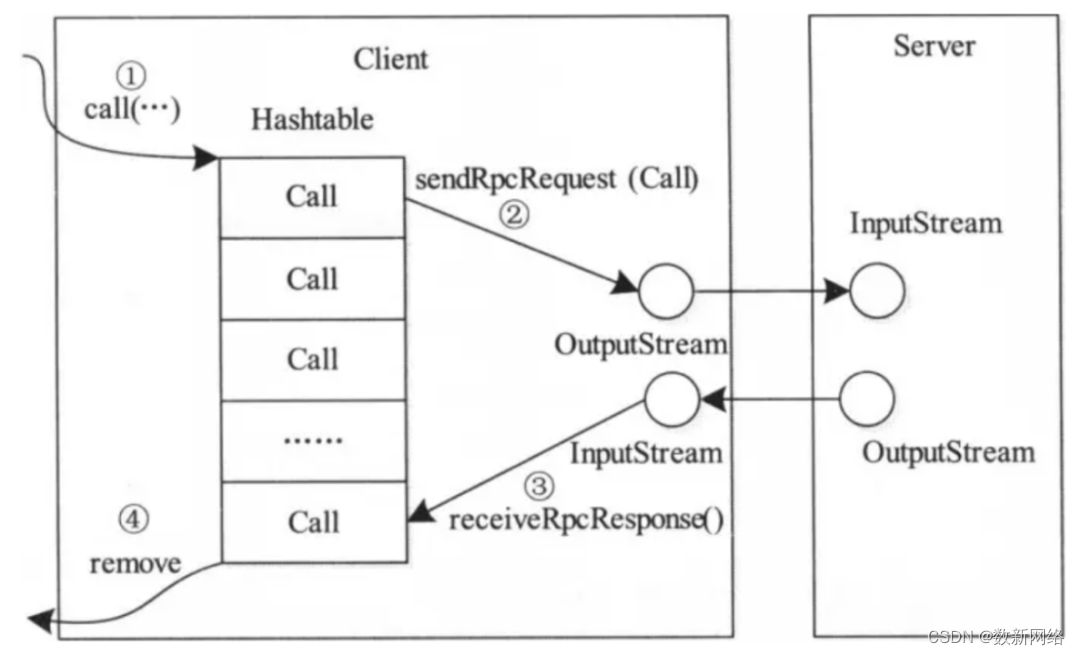
Hadoop RPC简介
数新网络-让每个人享受数据的价值https://www.datacyber.com/ 前 言 RPC(Remote Procedure Call)远程过程调用协议,一种通过网络从远程计算机上请求服务,而不需要了解底层网络技术的协议。RPC它假定某些协议的存在,例…...

你没有见过的 git log 风格
背景 git大家都不陌生,git log 也是大家经常用的指令,今天分享三种 git log的美化格式,大家看看哪种更易读。 git log -15 --graph --decorate --oneline 带有 pretty 格式的git log 风格 log --color --graph --prettyformat:‘%Cred%h%C…...

轻松搭建个人邮件服务器:实现远程发送邮件的hMailServer配置
文章目录 前言1. 安装hMailServer2. 设置hMailServer3. 客户端安装添加账号4. 测试发送邮件5. 安装cpolar6. 创建公网地址7. 测试远程发送邮件8. 固定连接公网地址9. 测试固定远程地址发送邮件 前言 hMailServer 是一个邮件服务器,通过它我们可以搭建自己的邮件服务,通过cpola…...

刷题笔记day08-字符串01
344. 反转字符串 思路1:使用双指针的方法,前后交换 func reverseString(s []byte) {// 思路1:使用双指针进行交换// 思路2:使用库函数进行交换for i, j : 0, len(s) - 1; i < j; {s[i], s[j] s[j], s[i]ij--} }思路2&…...

Pure-Pursuit 跟踪双移线 Gazebo 仿真
Pure-Pursuit 跟踪双移线 Gazebo 仿真 主要参考学习下面的博客和开源项目 自动驾驶规划控制(A*、pure pursuit、LQR算法,使用c在ubuntu和ros环境下实现) https://github.com/NeXTzhao/planning Pure-Pursuit 的理论基础见今年六月…...

告别焦虑等待!Elsevier投稿状态自动追踪插件,让你的科研进度一目了然
告别焦虑等待!Elsevier投稿状态自动追踪插件,让你的科研进度一目了然 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 还在每天刷新Elsevier投稿页面,只为查看论文审稿状态吗&…...

国家数据局印发《2026年数字经济发展工作要点》:八项任务背后的数据治理信号
大家好,我是独孤风。5月19日,国家数据局印发《2026年数字经济发展工作要点》。这不是一份泛泛谈数字经济的文件,而是对 2026 年数字经济工作的重点部署。从文件内容看,2026 年数字经济工作的关键词并不只是“上云、用数、用 AI”&…...

Android Method Tracing深度解析:Unity性能瓶颈跨层归因实战
1. 为什么Method Tracing不是“点一下就出报告”的银弹,而是Android性能诊断的听诊器在Unity项目上线前的最后两周,我接手了一个卡顿严重的AR应用——启动后3秒内帧率从60掉到22,用户滑动模型时UI直接冻结。团队里有人立刻打开Profiler&#…...

RTA-OS任务实战:从AUTOSAR规范到嵌入式汽车软件调度
1. 项目概述与核心价值在嵌入式汽车软件开发领域,AUTOSAR标准已经成为了事实上的行业规范,它定义了从应用软件到基础软件的完整架构。在这个庞大的体系中,操作系统(OS)作为最底层、最核心的软件组件之一,负…...

TBP-9000-R0AE无风扇工控机:6网口4PoE+,严苛工业环境下的边缘计算与机器视觉平台
1. 项目概述:一台为严苛环境而生的工业“大脑”在工业自动化、机器视觉、轨道交通这些领域里,选一台靠谱的工控机,远比在办公室挑台电脑复杂得多。它不仅要算力够用,更得扛得住震动、耐得了高低温、接得了五花八门的工业设备&…...
)
Navicat密码忘了别慌!手把手教你用Java小工具找回(支持15/16版本)
Navicat密码找回实战指南:零基础也能操作的Java解密方案 上周五凌晨两点,李工程师在部署紧急热修复时突然发现——Navicat里保存的生产数据库密码居然记不清了。这个场景对于经常需要管理多个数据库连接的开发者来说并不陌生。本文将详细介绍一套经过验证…...
)
从V2L到V2G:深度解析双向OBC的HIL测试如何模拟真实用车场景(含CANoe SmartCharging配置)
从露营供电到电网互动:双向OBC的HIL测试实战指南 清晨的山谷里,一辆新能源车静静停驻在营地旁。车主取出便携式电烤盘,将充电枪插入车辆交流充电口,几分钟后烤盘上的牛排开始滋滋作响——这看似简单的场景背后,是双向O…...

mPDF实战指南:PHP环境下HTML转PDF的高性能解决方案深度解析
mPDF实战指南:PHP环境下HTML转PDF的高性能解决方案深度解析 【免费下载链接】mpdf PHP library generating PDF files from UTF-8 encoded HTML 项目地址: https://gitcode.com/gh_mirrors/mp/mpdf 在当今数字化办公环境中,PDF文档生成已成为企业…...

终极GTA5安全防护菜单:YimMenu新手完整使用指南
终极GTA5安全防护菜单:YimMenu新手完整使用指南 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMenu …...

SpringBoot+Vue房屋买卖平台源码+论文
代码可以查看文章末尾⬇️联系方式获取,记得注明来意哦~🌹 分享万套开题报告任务书答辩PPT模板 作者完整代码目录供你选择: 《SpringBoot网站项目》1800套 《SSM网站项目》1500套 《小程序项目》1600套 《APP项目》1500套 《Python网站项目》…...