【实战Flask API项目指南】之六 数据库集成 SQLAlchemy

实战Flask API项目指南之 数据库集成
本系列文章将带你深入探索实战Flask API项目指南,通过跟随小菜的学习之旅,你将逐步掌握 Flask 在实际项目中的应用。让我们一起踏上这个精彩的学习之旅吧!
前言
在上一篇文章中,我们实现了一个 图书馆里系统API的后端,小菜觉得美中不足的是它使用一个 Python的列表用于存储图书的信息,是一个 本地版图书管理系统后端API。重新启动程序图书的数据就会丢失了。所以这节,我们将用上数据库来帮助小菜解决这一痛点,实现持久化数据存储。
当小菜踏入Flask后端开发的世界时,数据库是存储和管理数据的关键。
Flask并没有内置数据库功能,但是提供了扩展机制,可以方便地集成第三方数据库库。本文将介绍如何在 Flask 项目中集成SQLAlchemy,这是一个流行的Python ORM库。 我们将会在上一节课的基础上改写,让读者朋友们了解如何在 Flask应用中集成数据库。
注意:本文直接直接上代码,干货满满。
SQLAlchemy
1. 安装依赖
在Flask 中,可以使用各种数据库,如SQLite、MySQL、PostgreSQL等。首先,需要安装所需的数据库驱动库,例如flask-sqlalchemy用于集成 SQLAlchemy。
在使用 SQLAlchemy 进行数据库操作时,大部分操作是相似的,无论使用哪种数据库类型。(本文使用的是 MYSQL)
首先我们需要安装对应的依赖库,使用以下命令。
pip install flask-sqlalchemy flask-mysqldb
2. 配置数据库
在 Flask 应用中配置数据库连接信息。在应用的配置中,添加数据库的连接字符串。
- 确保将
username、password、localhost和flask替换为自己的MySQL数据库的用户名、密码、主机和数据库名称。
from flask import Flask
from flask_sqlalchemy import SQLAlchemyapp = Flask(__name__)
# mysql示例
# app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://username:password@localhost/database'
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:123456@localhost/flask'db = SQLAlchemy(app)
3. 定义数据模型
使用SQLAlchemy,可以定义数据模型作为 Python 类。每个类对应一个表,类的属性对应表中的列。数据模型是数据库中表格的抽象表示,它定义了表格的结构和字段。
在下面代码中,定义了一个名为Book的数据模型,它有三列
-
book_id字段作为主键,用作主键(primary key),唯一的,不允许为空 -
title字段表示书籍的标题,字符串类型,最大长度为100字符,不允许为空 -
author字段表示书籍的作者,字符串类型,最大长度为50字符,不允许为空 -
因为在我们的案例中,数据表只需要这三列。
class Book(db.Model):book_id = db.Column(db.Integer, primary_key=True, unique=True, nullable=False)title = db.Column(db.String(100), nullable=False)author = db.Column(db.String(50), nullable=False)
附上SQLAlchemy中常用的列设置选项:
| 选项 | 描述 |
|---|---|
primary_key=True | 将列标记为主键,用于唯一标识每行数据。 |
nullable=False | 指定列不允许为空值。 |
unique=True | 确保列中的值是唯一的,不允许重复值。 |
default=<value> | 为列设置默认值,如果插入数据时未提供值,则使用默认值。 |
index=True | 创建列的索引,以提高检索性能。 |
autoincrement=True | 自动生成递增的值(通常与主键一起使用)。 |
onupdate=<value> | 在更新行时设置列的值为指定的值。 |
server_default=<value> | 设置列的服务器默认值,通常在数据库层面实现。 |
4. 常用数据库操作
当使用SQLAlchemy时,有许多常用的数据库操作方法,用于执行CRUD(创建、读取、更新、删除)操作。以下是一些常用的SQLAlchemy操作方法示例:
请注意,这些示例假定你已经正确配置了SQLAlchemy和数据库连接。
-
创建数据(Create):
# 创建一个新对象并将其添加到数据库中 new_book = Book(title="Sample Book", author="John Doe") db.session.add(new_book) db.session.commit() -
读取数据(Read):
# 查询所有书籍 books = Book.query.all()# 根据条件查询书籍 specific_book = Book.query.filter_by(title="Sample Book").first() -
更新数据(Update):
# 查询要更新的对象 book_to_update = Book.query.filter_by(title="Sample Book").first()# 更新对象的属性 book_to_update.author = "New Author" db.session.commit() -
删除数据(Delete):
# 查询要删除的对象 book_to_delete = Book.query.filter_by(title="Sample Book").first()# 从数据库中删除对象 db.session.delete(book_to_delete) db.session.commit() -
过滤和排序(Filter and Sort):
# 查询所有作者是"John Doe"的书籍 johns_books = Book.query.filter_by(author="John Doe").all()# 查询前5本书籍并按书名升序排列 top_books = Book.query.order_by(Book.title).limit(5).all() -
聚合和统计(Aggregate and Count):
# 计算书籍总数 book_count = Book.query.count()# 计算不同作者的书籍数量 author_book_count = db.session.query(Book.author, db.func.count(Book.book_id)).group_by(Book.author).all()
在SQLAlchemy中常用的操作及其描述:
| 操作 | 描述 |
|---|---|
| 定义数据模型 | 使用db.Model定义数据模型,并定义字段及其属性。 |
| 创建数据表 | 使用db.create_all()创建定义的数据模型对应的数据表。 |
| 查询数据 | 使用db.session.query()创建查询对象,并添加查询条件。 |
| 插入数据 | 使用db.session.add()添加新数据对象,并提交更改。 |
| 更新数据 | 获取数据对象,修改属性后使用db.session.commit()提交更改。 |
| 删除数据 | 使用db.session.delete()添加要删除的数据对象,并提交更改。 |
| 过滤条件 | 在查询中使用filter、filter_by等方法添加过滤条件。 |
| 排序 | 使用order_by方法指定查询结果的排序方式。 |
| 限制数量 | 使用limit和offset限制查询结果的数量和偏移量。 |
| 聚合和统计 | 使用func函数进行聚合和统计操作,如func.count()。 |
| 关联表查询 | 使用relationship定义关联关系,使用join进行关联查询。 |
| 事务管理 | 使用db.session.begin()开始事务,使用commit提交更改,或rollback回滚更改。 |
| 批量操作 | 使用db.session.bulk_insert_mappings()进行批量插入,使用db.session.bulk_update_mappings()进行批量更新。 |
| 连接查询 | 使用join进行多表连接查询,使用select_from、outerjoin等方法进行不同类型的连接。 |
| 原始SQL查询 | 使用db.session.execute()执行原始的SQL查询。 |
5. 创建数据表
在app.py的末尾,添加以下代码来创建数据表:
在Flask-SQLAlchemy中,可以使用db.create_all()来创建所有定义的数据模型对应的数据表。在app.py的末尾,添加以下代码:
db.create_all()
但有时候会抛出一个 RuntimeError 的异常,

提示说在应用程序上下文之外工作,所以在前面添加 with app.app_context(),如下所示:
# 创建数据表
with app.app_context():db.create_all() # 或其他需要应用上下文的操作
6. 持久化数据存储的图书管理系统
这里将会在上一节课 本地版图书管理系统 的基础上,使用SQLAlchemy 改写成持久化数据存储的图书管理系统。
上代码
# -*- coding: utf-8 -*-from flask_sqlalchemy import SQLAlchemy
from flask import (Flask, jsonify, request)app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:123456@localhost/flask' # 替换为你的数据库 URI
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db = SQLAlchemy(app)# 定义Book模型类
class Book(db.Model):book_id = db.Column(db.Integer, primary_key=True, unique=True, nullable=False)title = db.Column(db.String(100), nullable=False)author = db.Column(db.String(50), nullable=False)# 获取所有书籍
@app.route("/books", methods=["GET"])
def get_all_books():books = Book.query.all()book_list = [{"id": book.book_id, "title": book.title, "author": book.author} for book in books]return jsonify(book_list), 200# 获取特定书籍
@app.route("/books/<int:book_id>", methods=["GET"])
def get_book(book_id):book = Book.query.get(book_id)if book:return jsonify({"id": book.book_id, "title": book.title, "author": book.author}), 200return jsonify({"error": "Book not found."}), 404# 创建新书籍
@app.route("/books", methods=["POST"])
def create_book():data = request.jsonnew_book = Book(title=data["title"], author=data["author"])db.session.add(new_book)db.session.commit()return jsonify({"id": new_book.book_id, "title": new_book.title, "author": new_book.author}), 201# 更新书籍信息
@app.route("/books/<int:book_id>", methods=["PUT"])
def update_book(book_id):book = Book.query.get(book_id)if book:data = request.jsonbook.title = data["title"]book.author = data["author"]db.session.commit()return jsonify({"id": book.book_id, "title": book.title, "author": book.author}), 200return jsonify({"error": "Book not found."}), 404# 删除书籍
@app.route("/books/<int:book_id>", methods=["DELETE"])
def delete_book(book_id):book = Book.query.get(book_id)if book:db.session.delete(book)db.session.commit()return "", 204return jsonify({"error": "Book not found."}), 404if __name__ == "__main__":app.run(debug=True)现在,小菜可以使用GET、POST、PUT和DELETE请求来访问API端点,并对图书数据进行操作。这个例子演示了如何在 Flask 应用中集成数据库、定义数据模型、执行数据库操作以及使用API端点来操作数据。这将帮助小菜更好地理解 Flask 中的数据库集成。
总结
这篇文章深入探讨了在Flask应用中集成数据库的关键步骤,通过引入SQLAlchemy这一流行的Python ORM库,实现了数据的持久化存储。文章首先介绍了安装依赖以及配置数据库的过程,然细讲解了如何定义数据模型以及常见的数据库操作方法。重点强调了如何使用Flask-SQLAlchemy扩展来简化数据库交互的过程。
通过以上步骤,小菜已经成功地在 Flask 应用中集成了MySQL数据库,并实现了图书的增删改查等操作。小菜获得了以下知识:
- 如何配置
Flask应用以连接数据库。 - 如何使用SQLAlchemy定义数据模型和表格结构。
- 如何执行常见的数据库操作,包括创建、读取、更新和删除数据。
- 如何使用Flask-SQLAlchemy扩展简化数据库交互。
通过本文的学习,小菜已经理解了Flask中数据库集成和操作,这为后面小菜需要实现后端API平台打下了扎实的基础!
相关文章:
【实战Flask API项目指南】之六 数据库集成 SQLAlchemy
实战Flask API项目指南之 数据库集成 本系列文章将带你深入探索实战Flask API项目指南,通过跟随小菜的学习之旅,你将逐步掌握 Flask 在实际项目中的应用。让我们一起踏上这个精彩的学习之旅吧! 前言 在上一篇文章中,我们实现了…...
MFC网络通信-Udp服务端
目录 1、UI的布局 2、代码的实现: (1)、自定义的子类CServerSocket (2)、重写OnReceive事件 (3)、在CUdpServerDlg类中处理 (4)、在OnInitDialog函数中 ࿰…...
最简单且有效的msvcp140.dll丢失的解决方法,有效的解决msvcp140.dll丢失
在我们使用电脑的过程中,有时会遇到一些令人困扰的问题,如msvcp140.dll文件丢失。对于许多不熟悉这方面技术的小伙伴来说,遇到msvcp140.dll丢失的问题可能会觉得棘手。其实这是一个很常见的问题,并且解决起来并不复杂。接下来将给…...
HBase理论与实践-基操与实践
基操 启动: ./bin/start-hbase.sh 连接 ./bin/hbase shell help命令 输入 help 然后 <RETURN> 可以看到一列shell命令。这里的帮助很详细,要注意的是表名,行和列需要加引号。 建表,查看表,插入数据&#…...
内存管理设计精要
系统设计精要是一系列深入研究系统设计方法的系列文章,文中不仅会分析系统设计的理论,还会分析多个实际场景下的具体实现。这是一个季更或者半年更的系列,如果你有想要了解的问题,可以在文章下面留言。 持久存储的磁盘在今天已经不…...
Java——StringBuffer与StringBuilder的区别
Java——StringBuffer与StringBuilder的区别 StringBuffer和StringBuilder是Java中用于处理字符串的两个类,它们之间的主要区别在于线程安全性和性能方面。 1. 线程安全性: StringBuffer:StringBuffer 是线程安全的,所有的公共方…...
基于深度学习的菠萝与果叶视觉识别及切断机构设计
收藏和点赞,您的关注是我创作的动力 文章目录 概要 一、课题内容二、总体方案确定2.1 方案选择2.2 菠萝的视觉识别流程2.3 菠萝果叶切断机构设计流程 三 基于深度学习的菠萝检测模型3.1 卷积神经网络简介3.2 YOLO卷积神经网络3.3 图像采集与数据制作3.4 数据训练与…...

springboot整合七牛云oss操作文件
文章目录 springboot整合七牛云oss操作文件核心代码(记得修改application.yml配置参数⭐)maven依赖QiniuOssProperties配置类UploadControllerResponseResult统一封装响应结果ResponseType响应类型枚举OssUploadService接口QiniuOssUploadServiceImpl实现…...

跨国传输的常见问题与对应解决方案
在今天的全球化时代,跨国数据传输已经成为一个不可或缺的需求。不论是个人还是企业,都需要通过网络将文件或数据从一个国家传输到另一个国家,以实现信息共享、协作、备份等目的。然而,跨国数据传输并不是一项容易的任务࿰…...

Git(七).git 文件夹瘦身,GitLab 永久删除文件
目录 一、问题背景二、问题复现2.1 新建项目2.2 上传大文件2.3 上传结果 三、解决方案3.1 GitLab备份与还原1)备份2)还原 3.2 删除方式一:git filter-repo 命令【推荐】1)安装2)删除本地仓库文件3)重新关联…...
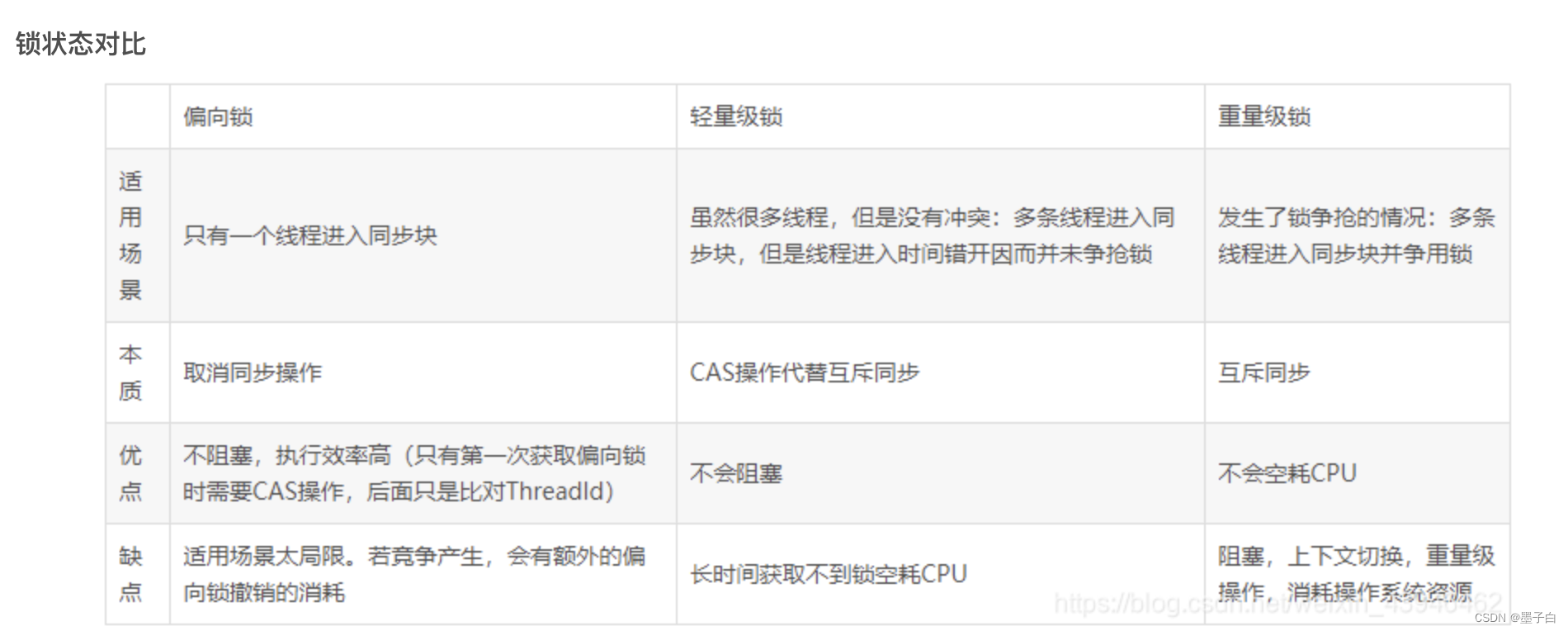
多线程锁的升级原理是什么
在 Java 中,锁共有 4 种状态,级别从低到高依次为:无状态锁,偏向锁,轻量级锁和重量级锁状态,这几个状态会随着竞争情况逐渐升级。锁可以升级但不能降级。 多线程锁锁升级过程 如下图所示 多线程锁的升级过程…...
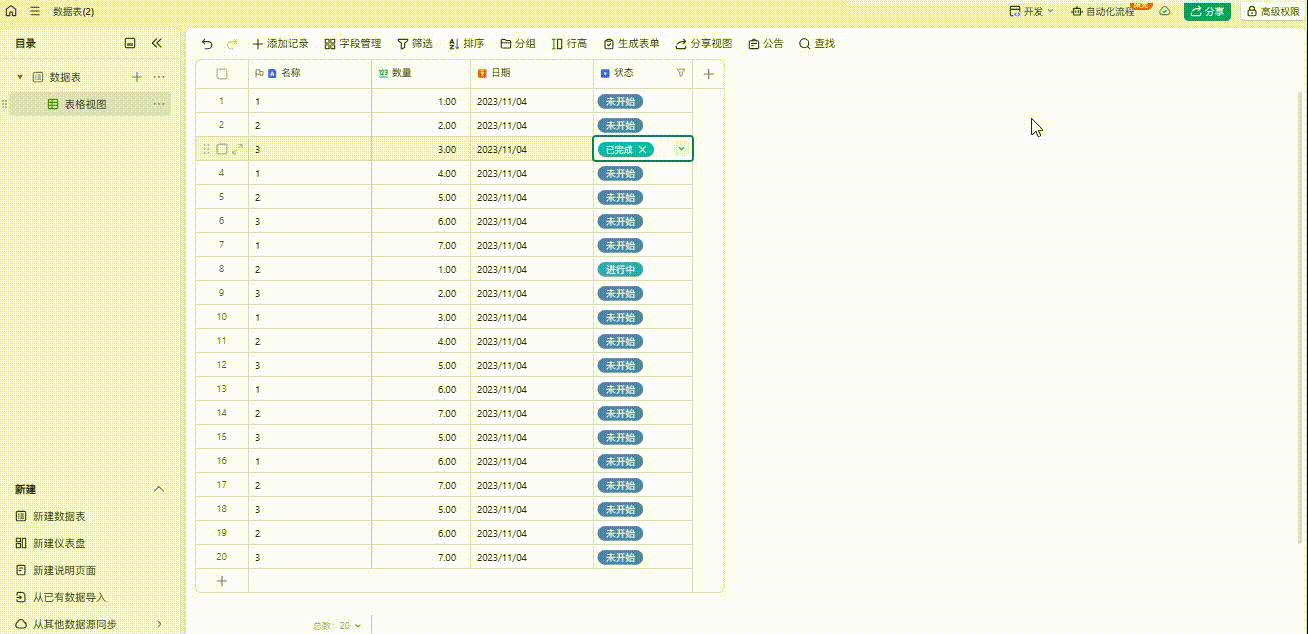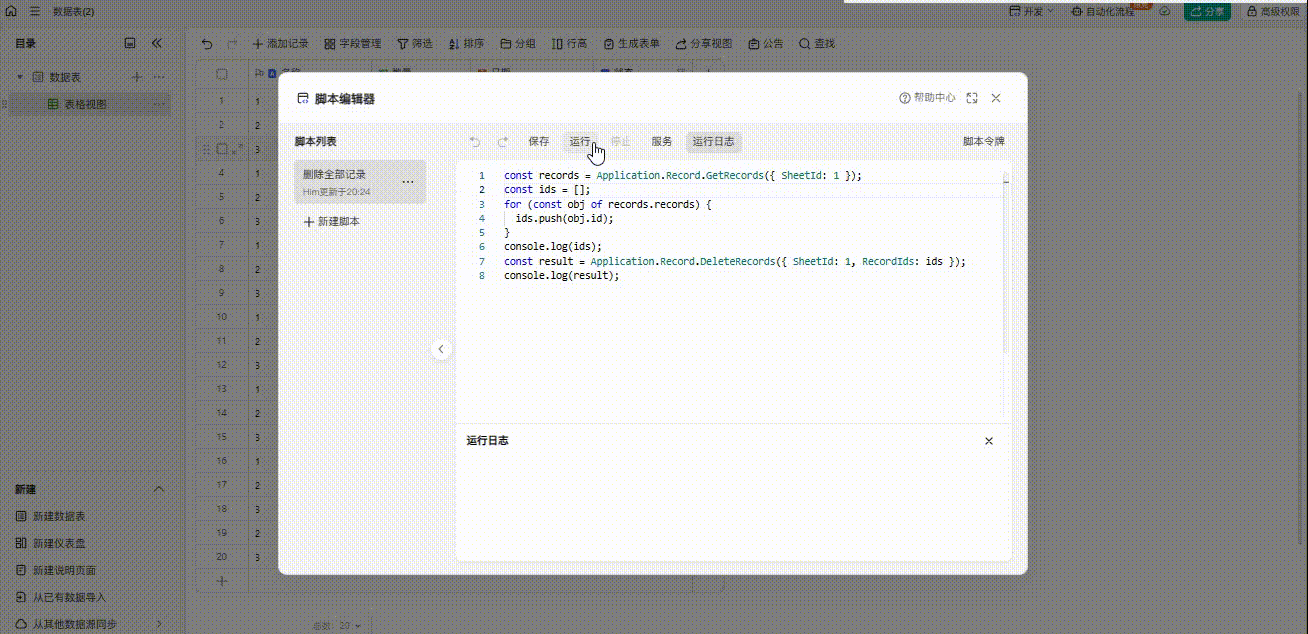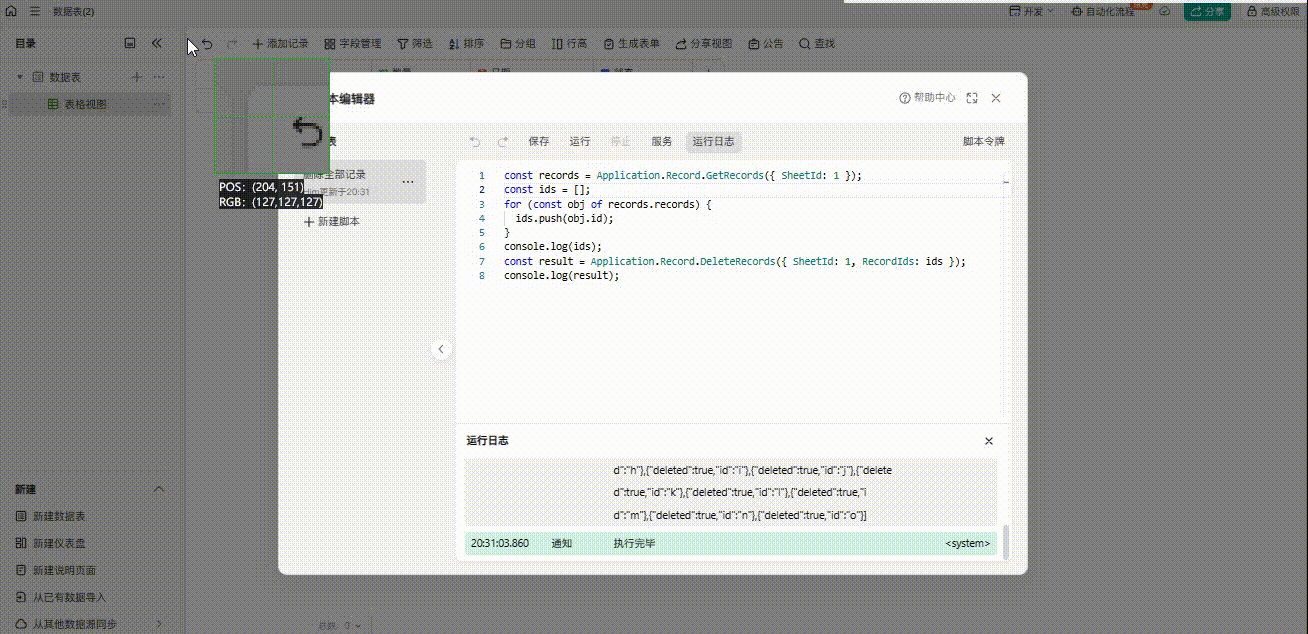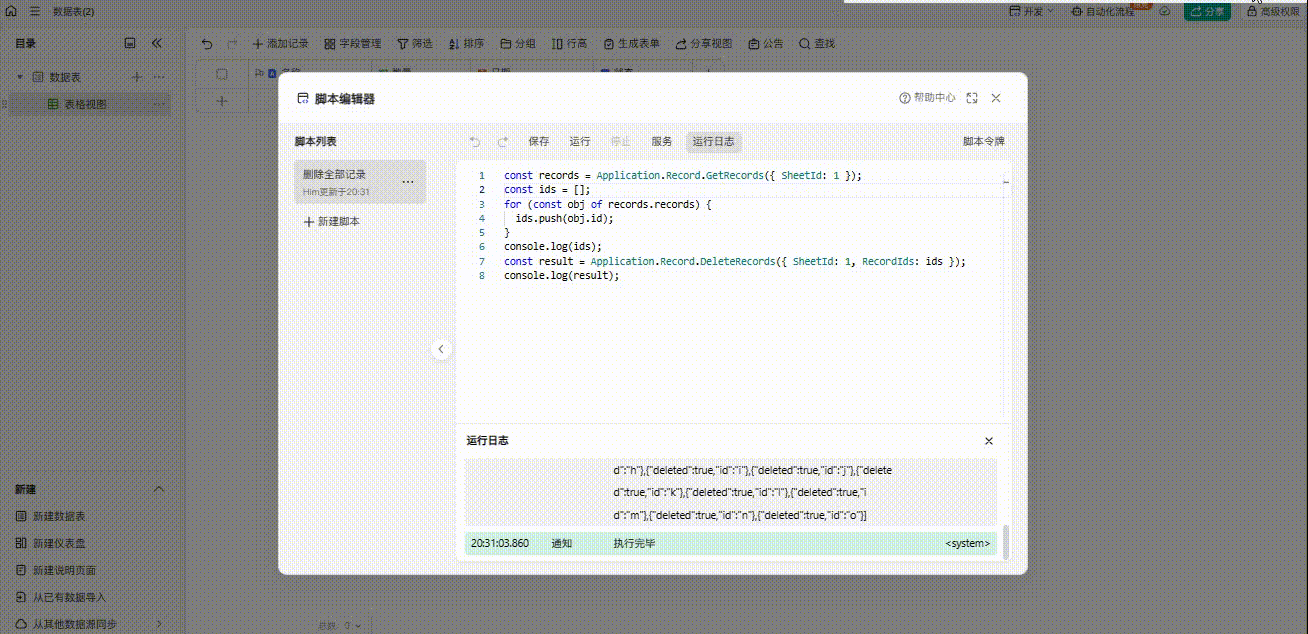
金山文档轻维表之删除所有行记录
目前脚本文档里面的只有删除行记录功能,但是需要指定ID值,不能实现批量删除,很多人反馈但是官方无回应,挺奇怪的 但是批量删除的需求我很需要,最后研究了一下,还是挺容易实现的 测试: 附上脚本…...

站坑站坑站坑站坑站坑
站坑站坑站坑站坑站坑站坑站坑...
语法来动态加载组件)
在Vue中,你可以使用动态import()语法来动态加载组件
在Vue中,你可以使用动态import()语法来动态加载组件。动态导入允许你在需要时异步加载组件,这样可以提高应用程序的初始加载性能。 下面是一个使用动态导入加载组件的示例: <template> <div> <button click"loadComp…...
)
金蝶云星空表单插件获取日期控件判空处理(代码示例)
文章目录 金蝶云星空表单插件获取日期控件判空处理C#实现 金蝶云星空表单插件获取日期控件判空处理 C#实现 DateTime? deliveryDate (DateTime?)this.View.Model.GetValue("FApproveDate");//审核日期long leadtime 20;//天数if (!deliveryDate.IsNullOrEmpty()…...

通过xshell传输文件到服务器
一、user is not in the sudoers file. This incident will be reported. 参考链接: [已解决]user is not in the sudoers file. This incident will be reported.(简单不容易出错的方式)-CSDN博客 简单解释下就是: 0、你的root需要设置好密码 sudo …...

centos7.9编译安装python3.7.2
联网环境下编译安装python3.7.2,不联网则需要配置cnetos7.9离线源 下载解压软件包 [rootlocalhost ~]# tar -xf Python-3.7.3.tar.gz [rootlocalhost ~]# ls anaconda-ks.cfg Python-3.7.3 Python-3.7.3.tar.gz [rootlocalhost ~]# [rootlocalhost ~]# cd Pytho…...

【教3妹学编程-算法题】2913. 子数组不同元素数目的平方和 I
-----------------第二天------------------------ 面试官 : 好的, 我们再来做个算法题吧。平时工作中会尝试用算法吗, 用到了什么数据结构? 3妹 : 有用到, 用到了 bla bla… 面试官 : 好的, 题目是这样的࿱…...

是否会有 GPT-5 的发布?
本心、输入输出、结果 文章目录 是否会有 GPT-5 的发布?前言围绕 GPT-5 的信息OpenAI 期待增长GPT-5 - 到底是真的在训练,还是一个虚构的故事Sam Altman字里行间包含的信息我们在什么时候可以期待 GPT-5 的发布GPT-5 预计将在哪些方向努力GPT-5 在听觉领域GPT-5 在视频处理领…...

使用 Selenium Python 检查元素是否存在
像 Selenium 这样的自动化工具使我们能够通过不同的语言和浏览器自动化 Web 流程并测试应用程序。 Python 是它支持的众多语言之一,并且是一种非常简单的语言。 它的Python客户端帮助我们通过Selenium工具与浏览器连接。 Web 测试对于开发 Web 应用程序至关重要&am…...

写给前端的 CANN-acl:昇腾应用开发接口到底是啥?
写给前端的 CANN-acl:昇腾应用开发接口到底是啥? 之前有兄弟问我:“哥,我想直接调用昇腾的底层API,不用 PyTorch 这些框架,怎么搞?” 好问题。今天一次说清楚。 acl 是啥? acl Asce…...

软件架构分析方法SAAM、ATAM与CBAM
一、SAAM(软件架构分析方法) 1. 核心思路 基于场景,评估架构对可修改性(以及可移植性、可扩充性)的支持程度。 关键是区分 直接场景(现有架构直接支持)和 间接场景(需要修改架构)。 通过分析间接场景的数量与修改代价,定位高风险、高耦合的模块。 2. 典型案例:内…...

大模型的“文字障眼法“:FlipAttack 文本反转越狱技术全解析
一、先打个比方:你听说过"倒着说话"绕过安检吗? 想象一下,有个调皮的小孩想带进游乐园一个违禁品。安检人员耳朵很尖,一听到"炸弹""刀具"这些词就会拦人。于是小孩想了个办法——把话说反。 “我要…...

OpenHTMLtoPDF终极指南:三步实现专业PDF文档生成
OpenHTMLtoPDF终极指南:三步实现专业PDF文档生成 【免费下载链接】openhtmltopdf An HTML to PDF library for the JVM. Based on Flying Saucer and Apache PDF-BOX 2. With SVG image support. Now also with accessible PDF support (WCAG, Section 508, PDF/UA)…...

CANN/asc-devkit MakeNDLayout函数
MakeNDLayout 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.c…...

Unity SLG框架解析:Clash Engine六维系统架构与工程实践
1. 这不是“又一个SLG模板”,而是把“部落冲突”式玩法真正拆开揉碎的工程实践你有没有试过在Unity里搭一个像《部落冲突》那样的SLG?不是那种只有几个按钮、拖拽兵种就完事的Demo,而是真正能跑通资源采集→建筑升级→兵种训练→多线程战斗→…...

Godot 4.3 RTS开发实战:事件驱动架构与指令队列优化
1. 这不是又一个“Hello World”教程:RTS游戏在Godot里到底难在哪?你点开过十几个“Godot RTS教程”,结果发现前两分钟还在画UI按钮,第三分钟就跳到“接下来我们用NavigationServer实现寻路”——然后卡住。你翻遍官方文档&#x…...

基于“点击化学”的聚合物荧光标记定制合成
当化学成为“纽带”:基于点击化学的聚合物荧光标记定制合成关于我们的定制在生物医学成像与材料科学的前沿研究中,获得一种既能稳定发光、又能精准标记目标分子的探针,往往是实验成功的关键。我们专注于为客户提供基于点击化学的聚合物荧光标…...

CANN 算子调优:榨干昇腾硬件性能
一、算子性能分析基础 1.1 算子执行模型 昇腾上每个算子的执行都会经历:编译时优化 → 运行时调度 → 硬件执行。任何一个环节出问题都会导致性能下降。 ┌────────────────────────────────────────┐ │ 算子执…...

ElevenLabs波斯文TTS落地难题全破解:从Unicode乱码、音节切分失败到自然语调合成的5大技术卡点
更多请点击: https://codechina.net 第一章:ElevenLabs波斯文TTS落地难题全破解:从Unicode乱码、音节切分失败到自然语调合成的5大技术卡点 波斯文(Farsi)作为右向左(RTL)、连字密集、元音隐含…...