I/O性能优化——这一篇就足够啦
背景
继上一篇CPU性能优化文章 ,本次向大家分享关于I/O性能优化的分析套路以及常见措施。后续还有关于内存及网络优化的篇章。
基本概念
对于I/O我们先了解几个概念,文件系统,磁盘,文件。
磁盘
磁盘为系统提供了最基本的持久化存储能力。
磁盘的分类
根据存储介质的不同,磁盘可以分为两类:机械磁盘和固态磁盘。
机械磁盘:由盘片和读写磁头组成。数据就存储在盘片的环状磁道中。当读写数据时,需要先将读写磁头移动到所在的磁道,然后才能访问数据。
固态磁盘:由固态电子元器件组成,固态硬盘不需要磁道寻址。
由上可知
-
机械磁盘当访问的数据不连续时,就会消耗寻道时间,降低效率;而固态磁盘则不会。
-
无论是机械磁盘还是固态磁盘,连续IO要比随机IO快。
-
通用块层策略,可以将连续的IO请求合并,提高效率。
-
利用文件系统的缓存机制。
-
性能指标
磁盘性能的衡量标准,必须要提到五个常见指标。
-
使用率。指磁盘处理I/O的时间百分比。注,使用率100%,磁盘仍可能可以接受新的IO请求。
-
饱和度。指磁盘处理I/O的繁忙程度。注,当饱和度100%,磁盘不能接受新的IO请求。
-
IOPS(Input/Output Per Second)。每秒的IO请求数。
-
吞吐量。指每秒的IO请求大小
-
响应时间。指IO请求发出,到响应的时间间隔。
查看性能指标方式
yihua@ubuntu:~$ iostat -d -x 1
Linux 4.15.0-213-generic (ubuntu) 10/30/2023 _x86_64_ (4 CPU)
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
loop0 0.00 0.00 0.01 0.00 0.00 0.00 0.00 0.00 0.50 0.00 0.00 1.85 0.00 0.02 0.00
loop1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 1.06 0.00 0.00 4.08 0.00 0.00 0.00
loop2 0.00 0.00 0.01 0.00 0.00 0.00 0.00 0.00 0.33 0.00 0.00 2.11 0.00 0.01 0.00
loop3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10.22 0.00 0.00 2.50 0.00 0.00 0.00
loop4 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 1.06 0.00 0.00 4.09 0.00 0.07 0.00
loop5 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 2.57 0.00 0.00 2.57 0.00 0.00 0.00
loop6 0.05 0.00 0.05 0.00 0.00 0.00 0.00 0.00 2.69 0.00 0.00 1.06 0.00 0.05 0.00
loop7 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 1.20 0.00 0.00 2.25 0.00 0.03 0.00
sda 0.38 0.61 11.59 44.20 0.07 0.63 15.21 50.81 0.81 4.16 0.00 30.82 72.85 0.25 0.02
scd0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.08 0.00 0.00 3.75 0.00 0.08 0.00
scd1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.13 0.00 0.00 17.48 0.00 0.13 0.00
loop8 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 10.22 0.00 0.00 2.50 0.00 0.00 0.00
loop9 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.75 0.00 0.00 3.19 0.00 0.02 0.00
loop10 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 11.20 0.00 0.00 2.35 0.00 0.00 0.00
loop11 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.88 0.00 0.00 3.41 0.00 0.06 0.00
loop12 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 4.63 0.00 0.00 2.47 0.00 0.00 0.00
loop13 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 1.23 0.00 0.00 4.51 0.00 0.08 0.00
loop14 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 2.37 0.00 0.00 3.23 0.00 0.44 0.00
loop15 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.68 0.00 0.00 3.39 0.00 0.06 0.00
loop16 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 1.58 0.00 0.00 4.61 0.00 0.19 0.00
loop17 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.80 0.00 0.00 2.23 0.00 0.08 0.00
loop18 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 27.00 0.00 0.00 1.00 0.00 0.00 0.00
loop19 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 1.96 0.00 0.00 2.19 0.00 0.07 0.00
loop20 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 2.82 0.00 0.00 2.41 0.00 0.00 0.00
loop21 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 1.43 0.00 0.00 4.57 0.00 0.07 0.00
loop22 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 2.18 0.00 0.00 2.97 0.00 0.37 0.00
loop23 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.56 0.00 0.00 2.17 0.00 0.03 0.00
loop24 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 5.91 0.00 0.00 2.57 0.00 0.00 0.00
loop25 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.37 0.00 0.00 2.91 0.00 0.02 0.00
loop26 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 5.80 0.00 0.00 2.35 0.00 0.00 0.00
loop27 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 1.60 0.00 0.00 0.00文件系统
文件系统是在磁盘的基础上,提供了一个用来管理文件的树状结构。其本身就是对存储设备上的文件进行组织管理的机制。组织方式不同,就会形成不同的文件系统。
文件
为了方便管理,文件系统会为文件分配两个数据结构。索引节点和目录结构。
-
索引节点。简称inode,用来记录文件的元数据,比如inode编号,文件大小,访问权限,修改日期,数据位置等。索引节点和文件一一对应,它跟文件内容一样,都会被持久化存储到磁盘中。所以索引节点会占用磁盘空间。
-
目录项。简称dentry,用来记录文件的名字,索引节点指针以及其他目录项的关联关系。多个关联目录项,就构成了文件系统的目录结构。
由上可知:
索引节点和目录项也是占用磁盘空间的。并且文件系统中的索引节点和目录项是有上限个数的。因此当linux 系统中若存在大量的小文件。可能磁盘空间还有空余,但是已经无法再创建新文件了。
目录项和索引节点的关系是多对一。即一个文件可以有多个别名,比如linux 系统中的硬链接。
文件I/O
根据访问文件的方式不同,导致I/O的分类有多种,常见的有以下四种。
-
缓存IO/非缓存IO。这里的缓存指的是应用层缓存,因为有些标准库会具有缓存机制,减少IO操作次数。比如
printf遇到换行符才会输出,这就是因为换行符之前的内容被标准库缓存了,此时的内容还在应用层,没有到内核。 -
直接IO/非直接IO。文件系统为了加快数据读写操作,会将数据进行缓存,根据特定的机制(缓存满、系统调用、缓存过期、磁盘写入请求或缓存刷新)将缓存写入磁盘,这就是我常说的落盘机制。直接IO则是在系统调用阶段指定
O_DIRECT标识,表示不适用文件系统的缓存机制。 -
阻塞IO/非阻塞IO。指应用程序执行系统调用后,如果没有获取结果,是否阻塞当前线程。比如在访问管道或网络套接字时,设置
O_NONBLOCK标识,就表示用非阻塞方式访问。 -
同步IO/异步IO。指应用程序执行IO操作后,是否需要等待IO完成或响应。比如在操作文件时,如果你设置了
O_DSYNC,就要等待文件数据写入磁盘后,才能返回。
上述描述中,缓存IO和直接IO比较好理解和区分。但是对于阻塞IO 和 同步IO 如何区分呢?
我的理解是:
阻塞IO,是应用程序主动的行为。它会主动释放持有的资源,CPU或文件描述符。
同步IO,是应用程序被动的行为。它一直等待事件满足,在等待过程中不会释放资源。
性能分析
关于文件系统,我们一般在意两个性能参数。容量和缓存。
-
容量
通过df命令可以查看当前文件系统剩余大小。
yihua@ubuntu:~$ df -h
Filesystem Size Used Avail Use% Mounted on
udev 1.9G 0 1.9G 0% /dev
tmpfs 392M 3.6M 389M 1% /run
/dev/sda1 49G 42G 4.5G 91% /
tmpfs 2.0G 0 2.0G 0% /dev/shm
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
/dev/loop1 219M 219M 0 100% /snap/gnome-3-34-1804/93
/dev/loop3 512K 512K 0 100% /snap/gnome-characters/789
/dev/loop2 82M 82M 0 100% /snap/gtk-common-themes/1534
/dev/loop16 106M 106M 0 100% /snap/core/15925
/dev/loop5 1.5M 1.5M 0 100% /snap/gnome-system-monitor/184
/dev/loop10 896K 896K 0 100% /snap/gnome-logs/121
/dev/loop11 141M 141M 0 100% /snap/gnome-3-26-1604/111
/dev/loop12 2.3M 2.3M 0 100% /snap/gnome-calculator/953
/dev/loop8 512K 512K 0 100% /snap/gnome-characters/795
/dev/loop13 74M 74M 0 100% /snap/core22/858
/dev/loop18 128K 128K 0 100% /snap/bare/5
/dev/loop14 350M 350M 0 100% /snap/gnome-3-38-2004/143
/dev/loop19 64M 64M 0 100% /snap/core20/2015
/dev/loop23 64M 64M 0 100% /snap/core20/1974
/dev/loop20 2.2M 2.2M 0 100% /snap/gnome-calculator/950
/dev/loop24 1.7M 1.7M 0 100% /snap/gnome-system-monitor/186
/dev/loop21 74M 74M 0 100% /snap/core22/864
/dev/loop7 56M 56M 0 100% /snap/core18/2790
/dev/loop26 896K 896K 0 100% /snap/gnome-logs/119
/dev/loop25 486M 486M 0 100% /snap/gnome-42-2204/126
/dev/loop15 141M 141M 0 100% /snap/gnome-3-26-1604/104
/dev/loop0 92M 92M 0 100% /snap/gtk-common-themes/1535
/dev/loop4 219M 219M 0 100% /snap/gnome-3-34-1804/90
/dev/loop6 106M 106M 0 100% /snap/core/16202
/dev/loop9 350M 350M 0 100% /snap/gnome-3-38-2004/140
/dev/loop22 497M 497M 0 100% /snap/gnome-42-2204/141
tmpfs 392M 28K 392M 1% /run/user/121
tmpfs 392M 36K 392M 1% /run/user/1000
/dev/sr1 1.9G 1.9G 0 100% /media/yihua/Ubuntu 18.04.1 LTS amd64
/dev/sr0 46M 46M 0 100% /media/yihua/CDROM
/dev/loop27 56M 56M 0 100% /snap/core18/2796注: 文件系统显示的大小并不等于磁盘的大小。
-
缓存
我们可以通过free命令查看当前缓存大小。
yihua@ubuntu:~$ free -htotal used free shared buff/cache available
Mem: 3.8G 1.3G 1.5G 31M 1.1G 2.3G
Swap: 2.0G 87M 1.9G但是我们文件系统中主要有三类缓存,页缓存,索引节点缓存,目录项缓存。这些参数无法直接从free命令中获取。因此,需要从/proc/meminfo中获取详情。
yihua@ubuntu:~$ cat //proc/meminfo
MemTotal: 4013248 kB
MemFree: 1576180 kB
MemAvailable: 2400348 kB
Buffers: 97364 kB
Cached: 906452 kB
SwapCached: 3840 kB
Active: 795076 kB
Inactive: 1181056 kB
Active(anon): 376460 kB
Inactive(anon): 628448 kB其中Cached就是三者缓存和,可以通过slabtop查看更细节内容
Active / Total Objects (% used) : 989070 / 1045443 (94.6%)Active / Total Slabs (% used) : 20382 / 20382 (100.0%)Active / Total Caches (% used) : 84 / 114 (73.7%)Active / Total Size (% used) : 242473.95K / 262634.13K (92.3%)Minimum / Average / Maximum Object : 0.01K / 0.25K / 8.00KOBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME51145 47067 0% 0.60K 965 53 30880K inode_cache56192 55803 0% 0.50K 878 64 28096K kmalloc-512
145020 144307 0% 0.13K 2417 60 19336K kernfs_node_cache17168 13103 0% 1.07K 592 29 18944K ext4_inode_cache93870 76404 0% 0.19K 2235 42 17880K dentry29792 21524 0% 0.57K 532 56 17024K radix_tree_node由上可知,目录项和索引节点缓存约占32M。
I/O栈
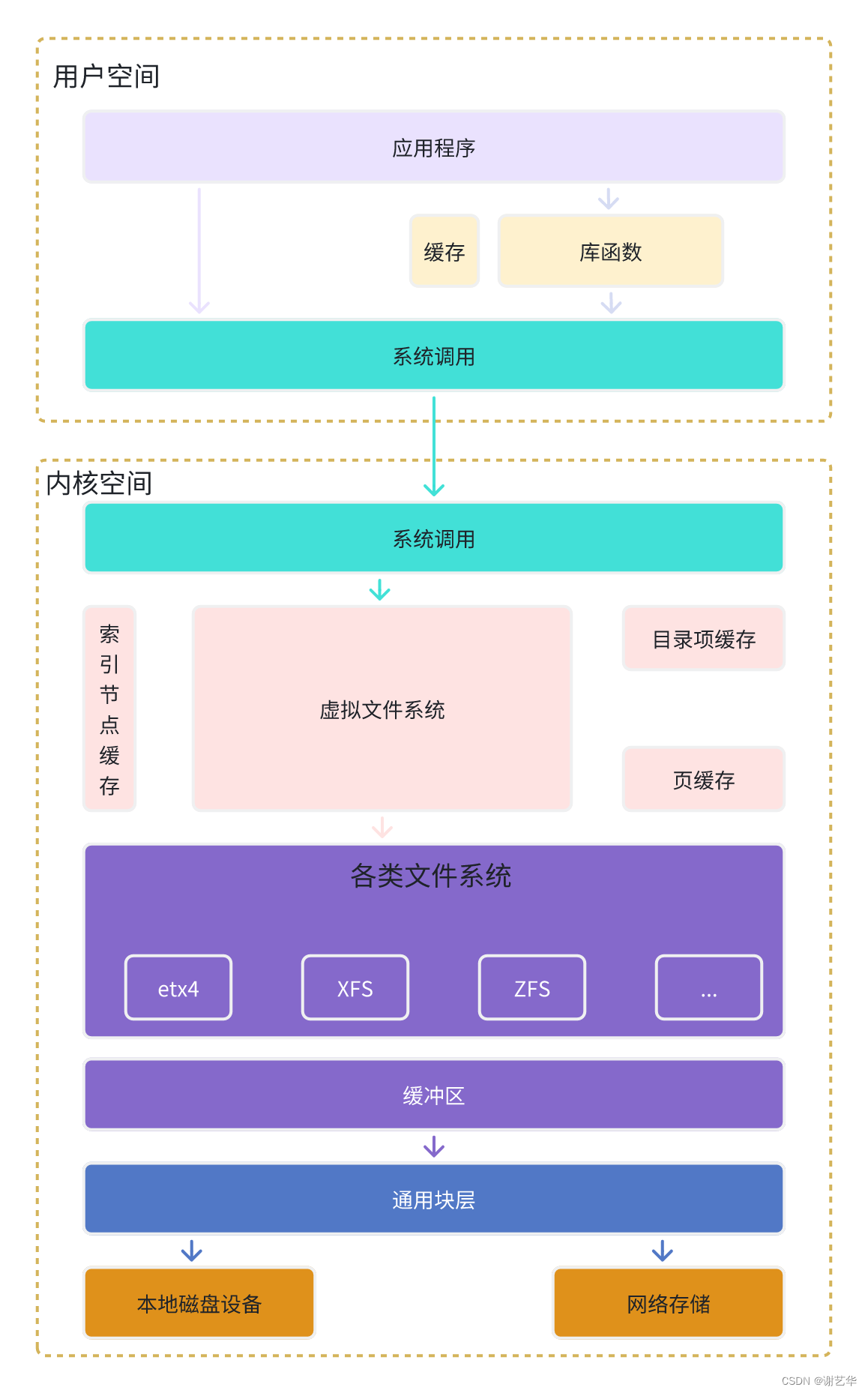
虚拟文件系统
根据上图可知,为了支持不同的文件系统,linux内核在用户空间和文件系统之间,又引入了一个抽象层,也就是虚拟文件系统VFS(Virtual File System)。
VFS定义了所有文件系统都支持的数据结构和标准接口。这样用户进程就不需要和内核中的其他子系统,只需要跟 VFS 提供的统一接口进行交互就可以了,而不需要再关心底层各种文件系统的实现细节。
在 VFS 的下方,Linux 支持各种各样的文件系统。按照存储位置的不同,这些文件系统可以分为三类。
-
第一类是基于磁盘的文件系统,也就是把数据直接存储在计算机本地挂载的磁盘中。常见的 Ext4、XFS、OverlayFS 等,都是这类文件系统。
-
第二类是基于内存的文件系统,也就是我们常说的虚拟文件系统。这类文件系统,不需要任何磁盘分配存储空间,但会占用内存。我们经常用到的 /proc 文件系统,其实就是一种最常见的虚拟文件系统。此外,/sys 文件系统也属于这一类,主要向用户空间导出层次化的内核对象
-
第三类是网络文件系统,也就是用来访问其他计算机数据的文件系统,比如 NFS、SMB、iSCSI 等。
这些文件系统,要先挂载到 VFS 目录树中的某个子目录(称为挂载点),然后才能访问其中的文件。
通用块层
与虚拟文件系统 VFS 类似,为了减小不同块设备的差异带来的影响,Linux 通过一个统一的通用块层,来管理各种不同的块设备。
通用块层处于文件系统和磁盘驱动中间的一个块设备抽象层。它主要有两个功能:
-
向上,为文件系统和应用程序提供访问块设备的标准接口;向下,把各种异构的磁盘设备抽象为统一的块设备,并提供统一框架来管理这些设备的驱动程序。
-
块设备还会将发送过来的I/O请求排队,并通过重新排序,请求合并等方式,提高磁盘的效率。
其中排序的算法有四种,如下:
-
NONE。不做任何处理。
-
NOOP。实际上是一个先进先出的队列,在此基础上做最基本的请求合并。
-
CFQ。完全公平调度器,现在很多发行版默认的I/O调度策略。它为每一个进程维护了一个I/O队列,并按照时间片均匀分布每个进程的I/O请求。
-
DeadLine。分别为读、写请求创建了不同的 I/O 队列,可以提高机械磁盘的吞吐量,并确保达到最终期限(deadline)的请求被优先处理。多用在 I/O 压力比较重的场景,比如数据库等。
工具介绍
在进行IO性能分析的过程中,我们需要用到一些工具,协助我们分析,定位,解决问题。
top
top 命令是我们在分析性能问题时,常用到的一个工具。执行top -d 1 ,-d 参数表示更新频率。默认3s。
yihua@ubuntu:~$ top -d 1
top - 23:36:05 up 22:14, 4 users, load average: 0.48, 0.10, 0.03
Tasks: 330 total, 1 running, 253 sleeping, 0 stopped, 0 zombie
%Cpu(s): 9.9 us, 66.5 sy, 0.0 ni, 23.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 4013240 total, 1004708 free, 1293040 used, 1715492 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 2398648 avail MemUnknown command - try 'h' for helpPID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND10612 yihua 20 0 120024 7940 6636 S 305.0 0.2 0:21.79 sysbench10623 yihua 20 0 44380 4132 3328 R 1.0 0.1 0:00.03 top1 root 20 0 225544 9332 6636 S 0.0 0.2 0:03.29 systemd2 root 20 0 0 0 0 S 0.0 0.0 0:00.04 kthreadd4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq7 root 20 0 0 0 0 S 0.0 0.0 0:00.09 ksoftirqd/08 root 20 0 0 0 0 I 0.0 0.0 0:00.61 rcu_sched9 root 20 0 0 0 0 I 0.0 0.0 0:00.00 rcu_bh10 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/011 root rt 0 0 0 0 S 0.0 0.0 0:00.09 watchdog/0第三行:%Cpu(s): 9.9 us, 66.5 sy, 0.0 ni, 23.6 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
表示当前CPU的资源消耗状态。参数可参考一下。
user(通常缩写为 us),代表用户态 CPU 时间。注意,它不包括下面的 nice 时间,但包括了 guest 时间。即执行用户态代码。
nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。执行用户态代码。
system(通常缩写为 sys),代表内核态 CPU 时间。执行内核态代码。
idle(通常缩写为 id),代表空闲时间。注意,它不包括等待 I/O 的时间(iowait)。
iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间。进程不可中断状态持续时间。
irq(通常缩写为 hi),代表处理硬中断的 CPU 时间。执行硬中断代码。
softirq(通常缩写为 si),代表处理软中断的 CPU 时间。执行软中断代码。
steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。
通过top 命令,我们可以确认当前系统是否出现了IO 性能问题。
iostat
iostat可以查看系统中所有文件系统的状态。
# -d表示显示I/O性能指标,-x表示显示扩展统计(即所有I/O指标)
$ iostat -x -d 1
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
loop0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda 0.00 64.00 0.00 32768.00 0.00 0.00 0.00 0.00 0.00 7270.44 1102.18 0.00 512.00 15.50 99.20
在磁盘性能指标章节中,衡量磁盘性能指标有使用率,饱和度,IOPS,吞吐量,响应时间。对应关系为
-
使用率 (%util)
-
饱和度,饱和度通常也没有其他简单的观测方法
-
IOPS (r/s + w/s)
-
吞吐量(rkB/s + wkB/s)
-
响应时间(r_await + w_await)
由上可知,当前sda 磁盘出现了性能瓶颈,主要是体现在 使用率高,写请求响应需要7秒。
由上可知,通过iostat 可以快速定位到当前是哪一个磁盘出现了IO性能瓶颈,以及确认是哪一类I/O操作出现了瓶颈。
pidstat
pidstat 可以帮助我们观察进程的IO状态。
$ pidstat -d 1
13:39:51 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
13:39:52 102 916 0.00 4.00 0.00 0 rsyslogd从 pidstat 的输出你能看到,它可以实时查看每个进程的 I/O 情况,包括下面这些内容。
-
用户 ID(UID)和进程 ID(PID) 。每秒读取的数据大小(kB_rd/s) ,单位是 KB。
-
每秒发出的写请求数据大小(kB_wr/s) ,单位是 KB。
-
每秒取消的写请求数据大小(kB_ccwr/s) ,单位是 KB。
-
块 I/O 延迟(iodelay),包括等待同步块 I/O 和换入块 I/O 结束的时间,单位是时钟周期。
由上可知,通过pidstate 我们可以定位到哪一个进程导致了IO负载较高。
strace
strace命令可以查看进程的系统调用。通过I/O栈可知,应用程序必须通过系统调用才可以进入内核态,进行I/O请求。
$ strace -f -p 18940
strace: Process 18940 attached
...
mmap(NULL, 314576896, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f0f7aee9000
mmap(NULL, 314576896, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f0f682e8000
write(3, "2018-12-05 15:23:01,709 - __main"..., 314572844
) = 314572844
munmap(0x7f0f682e8000, 314576896) = 0
write(3, "\n", 1) = 1
munmap(0x7f0f7aee9000, 314576896) = 0
close(3) = 0
stat("/tmp/logtest.txt.1", {st_mode=S_IFREG|0644, st_size=943718535, ...}) = 0 通过strace输出,可以确定,当前I/O操作,主要是write操作,并且对应的文件套接字是3。
由上可知,strace 命令可以观察到进程的系统调用及其关联的文件套接字
lsof
lsof它专门用来查看进程打开文件列表,不过,这里的“文件”不只有普通文件,还包括了目录、块设备、动态库、网络套接字等。
$ lsof -p 18940
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
python 18940 root cwd DIR 0,50 4096 1549389 /
python 18940 root rtd DIR 0,50 4096 1549389 /
…
python 18940 root 2u CHR 136,0 0t0 3 /dev/pts/0
python 18940 root 3w REG 8,1 117944320 303 /tmp/logtest.txt 由上可知,文件套接字3,对应的是/tmp/logtest.txt文件,这样就可以确定相应代码块了。
I/O性能优化套路

通过iostat查看系统磁盘的I/O状态。若出现IO性能瓶颈,正常会出现响应时间比较高。
- 若存在吞吐量,IOPS,使用率比较高,则说明存在进程进行IO操作导致的
- 通过
pidstat可以快速定位到是哪一个进程进行IO操作。-
若是内核进程。一般是外部环境导致,比如外部设备交互频繁,网络环境异常。
-
若是应用进程。通过
strace+lsof确认当前进程在做什么。-
若是正在进行网络通信,则分析网络环境。
-
进行文件操作或操作磁盘。则分析应用程序。
-
-
- 通过
-
若仅是响应时间比较高,但是吞吐量,IOPS,使用率正常,则有可能是内存导致的,因为内存不足时,也会导致IO响应delay。
-
通过
vmstate+/proc/meminfo分析是哪一缓存出现异常。根据情况进行处理。
-
常见优化措施
应用层优化
-
用追加写替代随机写,减少寻址开销
-
借助缓存I/O,充分利用系统缓存,降低实际I/O的次数。比如打开文件不使用O_DIRECT 参数。
-
创建应用程序缓存,类似Redis这类外部缓存系统,比如C标准库提供了fopen,fread等库函数,都会利用标准库的缓存,减少磁盘操作。
-
频繁读写时,可以用mmap替代read/write,减少内存拷贝次数。
-
尽量将写请求合并,而不是将每一个请求同步写入磁盘,既可以用fsync(),取代O_SYNC。
-
根据业务场景的需求,设置IO调度算法。若是CFQ算法,可以设置应用程序的优先级。
文件系统优化
-
根据负载不同,选择最适合的文件系统。比如相比于 ext4 ,xfs 支持更大的磁盘分区和更大的文件数量,如 xfs 支持大于 16TB 的磁盘。但是 xfs 文件系统的缺点在于无法收缩,而 ext4 则可以。
-
优化文件系统的缓存。
-
在不需要持久化时,还可以使用内存文件系统tmpfs
磁盘优化
-
换性能更好的磁盘。比如用SDD 替换HDD。
-
对应用程序的数据,进行磁盘级别的隔离。比如日志和数据库程序,都需要进行频繁的读写操作。我们可以单独配置磁盘。
-
在顺序读比较多的场景中,我们可以增大磁盘的预读数据。调整内核选项
/sys/block/sdb/queue/read_ahead_kb,默认大小是 128 KB,单位为 KB。 -
优化内核块设备I/O的选项。比如调整磁盘队列的长度。/sys/block/sdb/queue/nr_requests,适当增大队列长度,可以提升磁盘的吞吐量。
-
dmesg 查看是否有硬件I/O故障的日志。
总结
以上便是我总结,若有好的想法或案例,欢迎各位同学分享,补充。

相关文章:
I/O性能优化——这一篇就足够啦
背景 继上一篇CPU性能优化文章 ,本次向大家分享关于I/O性能优化的分析套路以及常见措施。后续还有关于内存及网络优化的篇章。 基本概念 对于I/O我们先了解几个概念,文件系统,磁盘,文件。 磁盘 磁盘为系统提供了最基本的持久化存…...

【蓝桥杯选拔赛真题44】python小蓝晨跑 青少年组蓝桥杯python 选拔赛STEMA比赛真题解析
目录 python小蓝晨跑 一、题目要求 1、编程实现 2、输入输出 二、算法分析...
摩托车商家做展示预约小程序的作用
摩托车与电动车是人们短距离出行的主要工具,而其使用寿命一般是3年左右及以上、一家可能有多个,市场人群庞大且复购属性强,所以其经营商家也非常多。 如今互联网深入,在品牌宣传、客户获取、信息承载、营销等方面需要车辆经营商家…...
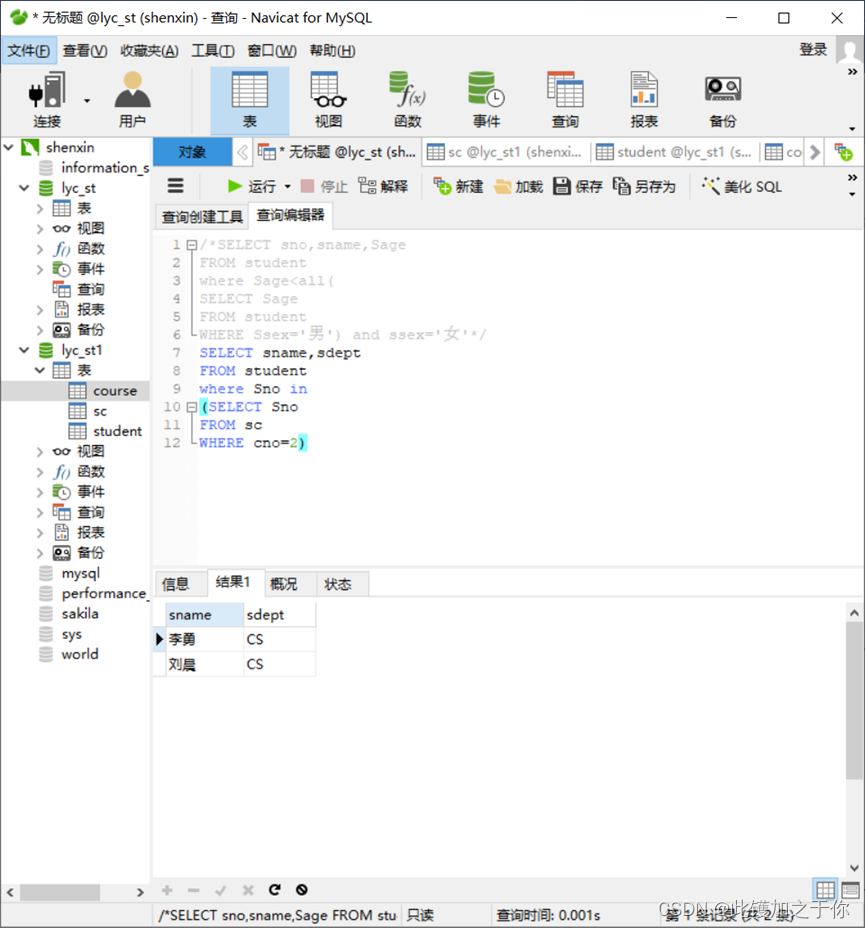
数据库实验:SQL的多表数据查询
目录 实验目的实验内容实验要求实验过程实验代码结果示意 书接上文,但是感觉之前的形式不太好用,至少不是很方便观看,所以这篇尝试改变一下写法,希望可以提升一些观感 实验目的 (1) 掌握RDBMS的数据多表查询功能 (2) 掌握SQL语言…...
【使用Python编写游戏辅助工具】第一篇:概述
引言 欢迎阅读本系列文章,本系列将带领读者朋友们使用Python来实现一个简单而有趣的游戏辅助工具。 写这个系列的缘由源自笔者玩了一款游戏。正巧,笔者对Python编程算是有一定的熟悉,且Python语言具备实现各种有趣功能的能力,因…...

Android与IOS渲染流程对比
目录 Android CPU计算图元信息 GPU干预 几何阶段等后处理 Android APP通过WindowManager统一提供所有Surface的缓冲区【不管是SurfaceView还是普通的布局流程都会将数据提交到Surface的BufferQuene中】 Java中的Surface是null,最终都是由Native层的Surface处理。…...

正则表达式以及 pattern 的撰写方式
正则表达式的撰写方法 在Python中,可以使用re模块来进行正则表达式的撰写和匹配。下面是一个基本的正则表达式撰写方法示例: 导入re模块: python import re定义正则表达式模式: python pattern = r正则表达式其中,r表示原始字符串,可以避免转义字符的问题。 使用re模…...
K8s Error: ImagePullBackOff 故障排除
Error: ImagePullBackOff 故障排除 1. 起因 起因是要在一组k8s环境下做个Prometheus的测试,当时虚拟机用完直接暂停了. 启动完master和node节点后重启了这些节点. 当检查dashboard时候发现Pod处于ImagePullBackOff状态,使用命令查看详细情况 kubectl describe pods -n kuber…...

爬虫之爬虫介绍、requests模块、携带请求参数、url 编码和解码、携带请求头
爬虫介绍 爬虫是什么? 网页蜘蛛,网络机器人,spider在互联网中 通过 程序 自动的抓取数据 的过程根上:使用程序 模拟发送http请求 ⇢ \dashrightarrow ⇢ 得到http响应 ⇢ \dashrightarrow ⇢ 把响应的数据解析出来 ⇢ \dashr…...

pytorch笔记:split
torch.split 是 PyTorch 中的一个函数,用于将张量按指定的大小或张量数量进行分割 1 基本使用方法 torch.split(tensor, split_size_or_sections, dim0)tensor要分割的输入张量split_size_or_sections以是整数或整数列表。 如果是整数,那么它表示每个分…...

K8S运维 解决openjdk:8-jdk-alpine镜像时区和字体问题
目录 一、问题 二、解决 三、完整代码 一、问题 由于项目的Dockerfile中使用openjdk:8-jdk-alpine作为基础镜像来部署服务,此镜像存在一定问题,例如时差8小时问题,或是由于字体问题导致导出excel文件,图片处理内容为空等。 二…...
)
Kubectl详解(陈述式、声明式)
目录 1、陈述式资源管理方法 1.1 基本信息查看 1.2 项目的生命周期:创建-->发布-->更新-->回滚-->删除 1.3 金丝雀发布(Canary Release) 2、声明式管理方法 1、陈述式资源管理方法 1.kubernetes 集群管理集群资源的唯一入口是…...

使用HttpClient库的爬虫程序
使用HttpClient库的爬虫程序,该爬虫使用C#来抓取内容。 using System; using System.Net.Http; using System.Threading.Tasks; namespace CrawlerProgram {class Program{static void Main(string[] args){// 创建HttpClient对象using (HttpClient client new…...
VSIX:C#项目 重命名所有标识符(Visual Studio扩展开发)
出于某种目的(合法的,真的合法的,合同上明确指出可以这样做),我准备了一个重命名所有标识符的VS扩展,用来把一个C#库改头换面,在简单的测试项目上工作很满意,所有标识符都被准确替换…...
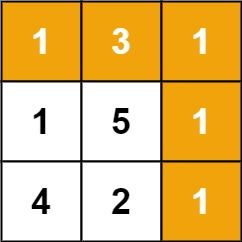
【CSDN 每日一练 ★★☆】【动态规划】最小路径和
【CSDN 每日一练 ★★☆】【动态规划】最小路径和 动态规划 题目 给定一个包含非负整数的 m x n 网格 grid ,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。 说明:每次只能向下或者向右移动一步。 示例 示例 1&#x…...
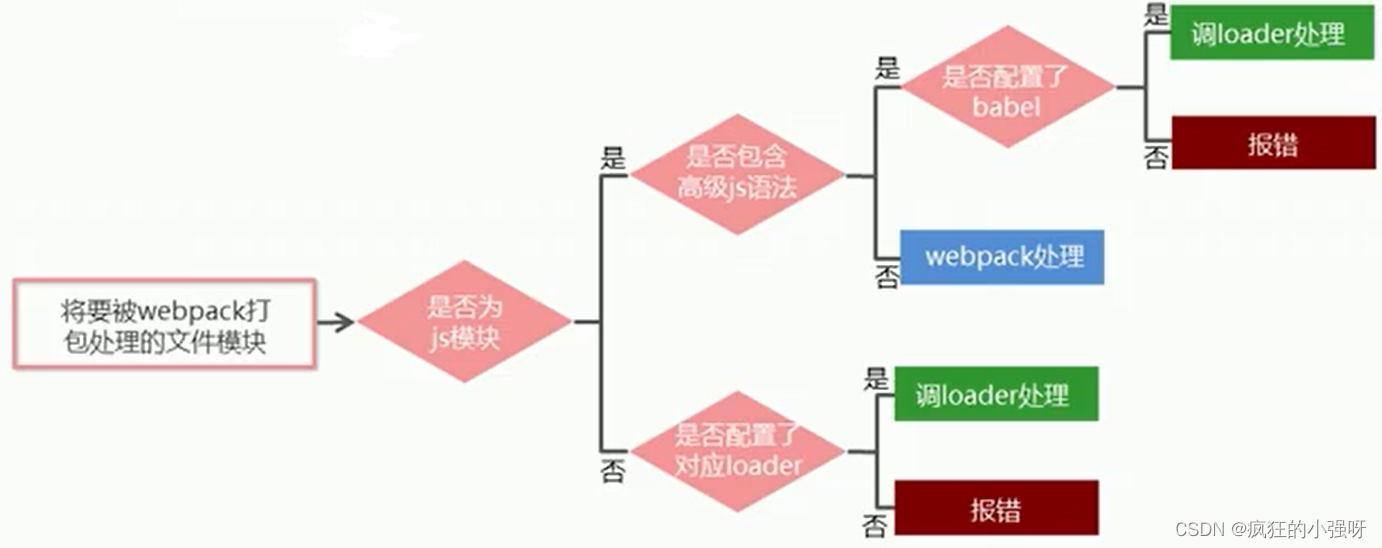
前端学习之webpack的使用
概述 webpack是一个流行的前端项目构建工具(打包工具),可以解决当前web开发中所面临的问题。 webpack提供了友好的模块化支持,以及代码压缩混淆、处理js兼容问题、性能优化等强大的功能,从而让程序员把工作重心放到具…...

【java学习—十一】泛型(1)
文章目录 1. 为什么要有泛型Generic2. 泛型怎么用2.1. 泛型类2.2. 泛型接口2.3. 泛型方法 3. 泛型通配符3.1. 通配符3.2. 有限制的通配符 1. 为什么要有泛型Generic 泛型,JDK1.5新加入的,解决数据类型的安全性问题,其主要原理是在类声明时通过…...

CN考研真题知识点二轮归纳(4)
持续更新,上期目录: CN考研真题知识点二轮归纳(4)https://blog.csdn.net/jsl123x/article/details/134135134?spm1001.2014.3001.5501 1.既可以扩展网段又是二层的设备 网段一般指一个计算机网络中使用同一物理层设备ÿ…...
ROS学习笔记(4):ROS架构和通讯机制
前提 前4篇文章以及帮助大家快速入门ROS了,而从第5篇开始我们会更加注重知识积累。同时我强烈建议配合B站大学的视频一起服用。 1.ROS架构三层次: 1.基于Linux系统的OS层; 2.实现ROS核心通信机制以及众多机器人开发库的中间层;…...

深度新闻稿件怎么写?新闻稿怎么写得有深度?
深度新闻稿件,顾名思义,是对新闻事件进行深入挖掘和分析的稿件。它不仅仅是对事件的简单报道,更注重对事件背后的社会现象、原因、影响等方面进行深度剖析,从而使读者能够全面、深入地了解事件。这种稿件要求作者具备较高的新闻敏…...

模型加速全景图:从“瘦身”到“飞驰”的知识图谱
文章目录知识图谱:模型加速的三大维度维度一:模型自身优化(让模型更“瘦”)维度二:计算过程优化(让计算更“顺”)维度三:硬件与系统优化(让硬件更“忙”)如何…...

Unity游戏配置管线实战:Luban Schema与Data分离设计
1. 为什么表格配置不是“偷懒”,而是Unity项目规模化生存的刚需在Unity游戏开发里,我见过太多团队把角色属性、武器参数、任务对话全写死在C#脚本里——刚上线时改个血量要改三处代码,策划提个新武器需求得等程序员下班后加字段,版…...

5个核心技术:深度掌握Sollumz在GTA V建模中的架构设计与实战应用
5个核心技术:深度掌握Sollumz在GTA V建模中的架构设计与实战应用 【免费下载链接】Sollumz Grand Theft Auto V modding suite for Blender. This add-on allows the creation of modded game assets: 3D models, maps, interiors, animations, etc. 项目地址: ht…...

article-extractor项目架构解析:模块化设计与可扩展性指南
article-extractor项目架构解析:模块化设计与可扩展性指南 【免费下载链接】article-extractor To extract main article from given URL with Node.js 项目地址: https://gitcode.com/gh_mirrors/ar/article-extractor article-extractor是一个强大的Node.j…...

意识的“调谐客观还原”理论
“调谐客观还原”理论,通常称为 Orch-OR,是诺贝尔物理学奖得主罗杰彭罗斯与麻醉学家斯图尔特哈梅罗夫于20世纪90年代初提出的一种极具争议的意识假说。该理论的核心观点是:意识并非产生于神经元之间的经典电化学连接,而是源于神经…...

百度网盘下载加速终极指南:3步实现高速下载的完整教程
百度网盘下载加速终极指南:3步实现高速下载的完整教程 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘几十KB/s的龟速下载而烦恼吗?作为…...

TMS320VC5502PGF300:TI TMS320C55x系列定点DSP,300MHz,176-LQFP封装
TMS320VC5502PGF300:C55x低功耗DSP的300MHz经典音频处理方案在语音识别、音频编解码和通信基带处理等实时信号处理应用中,处理器的能效比(单位功耗下的算力)往往是系统设计的核心约束。高性能处理器虽然算力强劲,但较高…...

以灵活测试方案打造共享实验室,强化槟城IC设计生态系统
益莱储(Electro Rent) InvestPenang|IC 设计验证与特性表征共享实验室马来西亚槟城正积极推进其成为亚洲领先的半导体枢纽。在 InvestPenang 主导的「Penang Silicon Design 5KM(PSD5KM)」计划下,全新的 I…...

告别臃肿:Win11Debloat让你的Windows 11系统焕然一新
告别臃肿:Win11Debloat让你的Windows 11系统焕然一新 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter and cus…...

别再傻傻分不清了!GIS新手必看:WGS84和UTM到底怎么选?附QGIS/ArcGIS实操对比
GIS坐标系选择指南:WGS84与UTM的核心差异与实战决策 刚接触地理信息系统(GIS)时,坐标系的选择往往令人困惑。为什么同样的位置数据,在不同坐标系下显示的数值完全不同?为什么测量同一个区域的面积会得到差异巨大的结果?…...