What is 哈希?
哈希
前言:大一大二就一直听说哈希哈希,但一直都没有真正的概念:What is 哈希?这篇博客就浅浅聊一下作者认知中的哈希。
理解哈希
哈希(Hash)也可以称作散列,实质就是一种映射,过程是将值作为参数输入到哈希函数中,通过一定的算法得到输出值,输入值和输出值几乎是一一对应的(注意这里的几乎),在这个过程中输入是无限的(任意长度),一样的输入对应一样的输出,不同的输入也有可能对应相同的输出(即哈希碰撞),最终结果具有离散均匀性。
根据以上过程可知哈希具有四个特点:
①输入是无限的
②一样的输入对应一样的输出
③不同的输入也可能一样的输出(哈希碰撞)但概率很小
④离散均匀性
这还是很抽象,接下来就举个栗子吧~~
首先根据经典的哈希,假设两个条件:①无穷的输入域(例如任意长度字符串)②有限的输出域S(即输出的结果肯定在S范围中)
现在假设我有一个函数Function(参数为整数),那么我可以试着输入任意数量任意大小整数都会有一个输出,例如Function(1234567)会有一个输出结果,当我再次调用Function(1234567)时输出结果不变(即函数内部不存在随机数的计算),如果给定参数不同,那么输出结果也有可能相同,原因是S是有限的输出域,而我有无限的输入,有可能导致不同的输入经过哈希函数计算得到相同的结果,一般碰撞概率很小,只有当输入数据极大量时才有可能产生碰撞,接着我用一个大圆来抽象表示输出域,输出结果抽象为一个个小黑点,大量数据输入后,产生的图像如下图所示。

可以看到输出结果分布是非常离散且均匀的,此时若用一个小圆在输出域中采样,采样出的数量也是非常均匀的,like下图。

那么能实现以上四个特点的这样一个Function函数就称为哈希函数,经典的哈希函数模板有 MD5 算法:返回值在0~264-1,SHAL算法:返回值在0~2128-1,java中的哈希函数返回值在0~232-1,哈希函数的具体实现算法先不用管(大牛搞出来的)。
加工
日常使用哈希我们不希望输出域太大,此时我们就需要加工一下来使用,具体加工方法是在最后增加一个过程:即样本经过哈希函数得到的输出再模一个值m得到最终输出结果,如下图。

此时最终的输出结果范围就在0~m-1上,并且结果在0~m-1上也同样均匀分布(很简单推),这样我们就人为缩小了哈希的结果域。
用途
问题:
假设有一个大文件,文件中有40亿个的无符号整数(范围在0~42亿+),若只给1G内存,内存中出现最多次的是哪个数?
题解:
此时就有小朋友想用哈希表做了,HashMap中含有一个key和一个value,我们可以用key代表一个无符号整数,value代表这个无符号整数出现的次数,看起来这样好像能轻松解决这个问题。真的是这样吗?我们可以看到该问题给定的要求是1G内存,而在这题中,key的类型是int(4字节),value类型也考虑为int,那么一个HashMap结构至少占8个字节(不考虑哈希表内部索引空间浪费了,就假定为没有该空间),40亿个HashMap最坏情况(即每个数都不一样)那就是需要占用32G的内存,这远远超出了问题中所给定的要求。
那么这时,我们就可以加工了,直接把每一个结果取余100,就能将32G的文件分割为一百份,由于离散均匀性,我们可以将这一百份小文件看成大小相等的一百份,并且每个种类的key都只会出现在其中一份小文件中,那么每一份小文件就只占用32G / 100的内存,即满足题目要求,此时再分别统计所有小文件中的最大值求出最终结果。
哈希表的实现
哈希表是怎么实现的呢,为什么能做到查询的时间复杂度是O(1),假设有一个大小为18的输出域,输入字符串“abc”、”bcd”、“xyz”,若经过哈希函数计算后取模18得到以下结果,可以发现,当得到相同值时,将他们接成一个链表就行。由于离散均匀性,每一个链的长度几乎是均匀变长的。哈希表查询的时候就是相同流程,计算出结果后去对应的位置遍历链表查询,此时就有一个问题,如果输出域太小,链表长度过长,那么查询的时候就无法做到O(1)的时间复杂度,所以当链表长度达到一个阈值,就触发扩容(扩容规则可以是变为两倍),18扩容为36,那么每个链表长度就变为一半,不过此时就需要把所有值重新计算(将模18改为用模36计算)放入输出域。

说完实现原理,再说说增删查改时间复杂度O(1)到底是怎么来的?输入的值经过哈希函数计算这个过程时间复杂度是O(1),得到的值再进行模运算时间复杂度同样是O(1),假设链表长度是k,遍历链表的时间复杂度就是O(k),当我们让k的大小始终很小时,就能看作O(1),所以扩容就是为了保证时间复杂度维持在O(1)。
接下来看看扩容的代价,假设有1000个字符串要加进去,设一开始哈希表格子大小为2,每次扩容容量乘2,那么需要经历log1000次扩容,所以扩容的次数理论来说是O(logkN),k为初始容量大小,N为要加入的内容大小,但实际情况远远小于logN,而每次重新计算哈希值的代价是O(N),因为每个值扩容后都要重新计算,故总的扩容代价是O(N*logN),那么单次代价即为O(logN)水平,当我将k的值稍微设计大一些,此时O(logN)就会变成一个特别小的代价值,实际情况N并不会过大,而且哈希表有增有删,删的情况还会减小扩容次数,故O(logN)可以逼近O(1)。Java等一些虚拟机语言还有离线扩容技术,可以不占用用户在线时间进行扩容,进一步加速了哈希表的使用,所以哈希表在实际使用是O(1),理论上是O(logN)。
以上就是哈希表的原理,具体的实现改进还有很多,比如开放地址法等等,这里就不过多赘述。
Tips:java中的HashMap、HashSet就是用哈希原理实现的哈希表,HashMap就只是比HashSet多了一个伴随的value值,原理是相同的,算法时间复杂度为O(1);TreeMap和TreeSet即 java 中利用搜索树实现的 Map 和 Set,实际上用的是红黑树,而红黑树是一棵近似平衡的 二叉搜索树,算法时间复杂度为O(logN)。
布隆过滤器
布隆过滤器是来解决类似黑名单系统、爬虫去重问题的
比如一个网站的黑名单url有100亿个,每个url大小限制为64Byte。需要做到给定一个url,判断该url是否出现在黑名单中,且这个黑名单只有增加和查询的需求,没有删除需求。
如果直接使用HashSet,那么占用空间大概是640G,十分浪费空间,或者搞成硬盘来记录url值,但这样慢的一p,所以咱们还是用内存来实现。
布隆过滤器允许一定的失误率,即有些不位于黑名单的url可能会被判定为在黑名单中(白 -> 黑),但不会出现原本位于黑名单中的url判定为不在黑名单中(黑 -> 白),而且通过人为的设计,可以让失误率很低,让工程上可以接受,例如爬网页,有些网页被杀掉了,没拿到信息,但在其他网页同样能得到信息。
那这么好用的布隆过滤器咋实现?
我们先来看看位图:
位图:一个数组,每个元素所占空间为1bit(bitarr bitmap)
假设我们想操作第178位,具体实现如下:
实现:使用基础类型拼凑
public class BitMap {public static void main(String[] args) {int a = 0;int[] arr = new int[10]; //32bit * 10 -> 320bits//arr[0] 0 ~ 31//arr[1] 32 ~ 63int i = 178; //想取第178位bitint numIndex = i / 32;int bitIndex = i % 32;//拿到第178位的状态int s = (arr[numIndex] >> bitIndex) & 1;//把第178位的状态改为1arr[numIndex] = arr[numIndex] | (1 << bitIndex);//把第178位的状态改为0arr[numIndex] = arr[numIndex] & (~(1 << bitIndex)); }
}
布隆过滤器就是一个大位图,长度为m的bitarr(实际占用空间为m / 8字节)
加入黑名单的步骤:对于每一个url来说,用k个不同的哈希函数算出k个哈希值out,然后将每一个out模m,得到对应于位图中的位置,将该位置设置为1,可以想象成将这些位置描黑,而取k个哈希函数相当于取k个特征,特征越多就越精确,就像一张图片你需要多取一些特征点才能归类为猫而不是归类为动物,从而使结果更精准。
查询黑名单的步骤:对于某一个url来说,算出k个哈希值,然后模m算出对应于位图中的位置,只有这些位置全是1(也就是都被描黑了),这个url才处于黑名单中,只要有一个位置不是1,就代表其不在黑名单中
决定失误率p的因素:位图大小m和哈希函数个数k。n(样本量)假定为100亿,若m越大,p则会越小(类似于反比例函数);当m由p-m图像确定后,k较小时,随着k的增加,p会下降,但到达某一个临界(与m有关)时,随着k的增加,p会上升(类似于二次函数),因为k逼近m,空间占用率太大了。

————————————————p(失误率)与m(位图大小)的关系图————————————————

————————————————p(失误率)与k(哈希函数个数)的关系图————————————————
布隆过滤器只和样本量n、失误率p这两个参数有关,与单样本大小无关(例如url大小),因为最后会被转化为哈希值,只要保证哈希函数能接受这个数值即可。
三个相关的公式:
m = − n ∗ l n p ( l n 2 ) 2 b i t ( 向上取整 ) k = l n 2 ∗ m n ≈ 0.7 ∗ m n 个 ( 向上取整 ) p 真 = ( 1 − e − n ∗ k 真 m 真 ) k 真 m=-\frac{n*lnp}{(ln2)^2}\quad bit(向上取整)\\ k=ln2*\frac{m}{n}≈0.7*\frac{m}{n}\quad 个(向上取整)\\ p_真=(1-e^{-\frac{n*k_真}{m_真}})^{k_真} m=−(ln2)2n∗lnpbit(向上取整)k=ln2∗nm≈0.7∗nm个(向上取整)p真=(1−e−m真n∗k真)k真
当类似于黑名单这个集合结构系统,不需要删除行为,允许有一定失误率,那么就需要设计布隆过滤器,设计布隆过滤器只需要以上三个公式。
已经有的条件:
①样本量n
②失误率p
对于上述黑名单示例,经计算后m的大小理论值大概是26G(原本需要640G),极大地减小了内存的占用,实际使用可以多申请一点比如申请32G内存,实际失误率会更小,计算就是第三个公式。
一致性哈希(Google改变世界技术三架马车之一)
一致性哈希原理:
一致性哈希是用来讨论分布式数据服务器(多台机器)怎么组织的问题
经典组织方式:假设有3台服务器,那么就先将数据转化为哈希值,再模3,分配到对应的服务器上,可以做到数据种类的均匀分配
负载均衡是由高频、中频、低频各自是否达到一定的数量来决定,此时由哈希函数是可以将这些数据均分的(根据离散均匀性,此时哈希函数需要选择种类较多的key,比如人名、身份证,而不适于选择类似于国家名的key)
经典结构的问题:若增加机器或减少机器,所有数据都需要重新计算哈希值,因此数据迁移的代价是全量的(比如原本模3,加了一个机器之后,就需要将全部数据模4重新计算分配,所以像MySQL这种一台机器的就搞不了,太慢了)
**一致性哈希的处理方式:**将哈希值的域比作一个环,先使用一个特定于服务器的哈希函数为每个服务器计算一个哈希值,将这些机器插入到这个环中。此时数据分配的方式是,这个数据所计算出的哈希值在环上顺时针方向最近的机器。实现方式是通过二分的方式查找大于等于当前哈希值中最近的机器,若没有比当前哈希值大的机器,则代表是最小的那个机器(因为是环)逻辑图如下。

在一致性哈希下,若新增或删减了服务器,则只需要迁移部分的数据即可完成数据的迁移,因为此时只用考虑增加或删减的那台机器与邻近机器的那一段数据。
例如下图,新增一个结点五,只需要把结点四到结点五之间的数据从节点一要回给结点五即可。

一致性哈希的问题:
① 当机器较少时,可能做不到这些机器将环均分
② 即使可以做到机器数量较少时将环均分,也无法保证增加或减少机器后负载均衡
解决方式:虚拟结点技术
虚拟结点技术本质上是按比例去抢环。假设有3台机器,则给这3台机器每个分配1000个字符串,此时不再让机器去占环上的位置,而让虚拟结点去占,即每台机器计算1000个哈希值,让这1000个哈希值占环上。此时这些虚拟结点之间的数据迁移可以用很简单的方式实现。当增加服务器时,则同理给这台服务器添加1000个虚拟结点,由于哈希分配均匀,因此它会均匀地从前3台机器中夺取数据到自己身上。减少机器也同理,减少机器时,自己的数据会均匀地分配到其他机器上。
一致性哈希还可以管理负载。例如若某台机器比较强,则可以分配更多的虚拟结点,而某台机器较弱,则可分配较少的虚拟结点。
以上就是关于作者对哈希的学习和理解,真的很想描述清楚分享给大家,能力有限,觉得写的不好不要见怪,有问题或错误欢迎评论区指出。
相关文章:
What is 哈希?
哈希 前言:大一大二就一直听说哈希哈希,但一直都没有真正的概念:What is 哈希?这篇博客就浅浅聊一下作者认知中的哈希。 理解哈希 哈希(Hash)也可以称作散列,实质就是一种映射…...
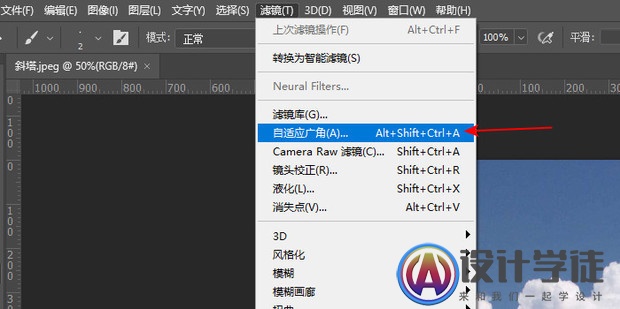
在Photoshop中如何校正倾斜的图片
在Photoshop中如何校正倾斜的图片呢?今天就教大家如何操作。 将需要操作的图片拉到PS软件中,自动形成项目。 点击上方“滤镜”中的“镜头校正”。 进入“镜头校正”窗口,点击左侧的“拉直工具”。文章源自设计学徒自学网-http://www.sx1c.co…...

Maven第六章:Maven的自定义插件开发
Maven第六章:Maven的自定义插件开发 前言 maven不仅仅只是项目的依赖管理工具,其强大的核心来源自丰富的插件,可以说插件才是maven工具的灵魂。本篇文章将对如何自定义maven插件进行讲解,希望对各位读者有所帮助。 Maven插件开发的基本概念 Maven插件是由Maven构建工具本身…...

springboot 注入配置文件中的集合 List
在使用 springboot 开发时,例如你需要注入一个 url 白名单列表,你可能第一想到的写法是下面这样的: application.yml white.url-list:- /test/show1- /test/show2- /test/show3Slf4j RestController RequestMapping("/test") pub…...

springboot整合redis+lua实现getdel操作保证原子性
原始代码 脚本逻辑先获取redis的值,判断是否等于期望值。 条件成立则删除,不成立则返回0 if redis.call(get, KEYS[1]) ARGV[1] thenreturn redis.call(del, KEYS[1]) end return 0 测试代码 根据上面的逻辑加了测试, 在判断成功后等待5…...
win10系统nodejs的安装npm教程
1.在官网下载nodejs,https://nodejs.org/en 2,双击nodejs的安装包 3,点击 next 4,勾选I accpet the terms in…… 5,第4步点击next进入配置安装路径界面 6,点击next,选中Add to PATH ,旁边…...

C语言assert函数:什么是“assert”函数
我一直在学习 OpenCV 教程,遇到了assert函数;它做什么? assert将终止程序(通常带有引用 assert 语句的消息),如果其参数为 false。它通常在调试过程中使用,以使程序在发生意外情况时更明显地失败。 例如&…...

R语言绘图-5-条形图(修改坐标轴以及图例等)
0. 说明: 1. 绘制条形图; 2. 添加文本并调整位置; 3. 调整x轴刻度的字体、角度及颜色; 4. 在导出pdf时,如果没有字体,该怎么解决问题; 1. 结果: 2. 代码: library(ggp…...
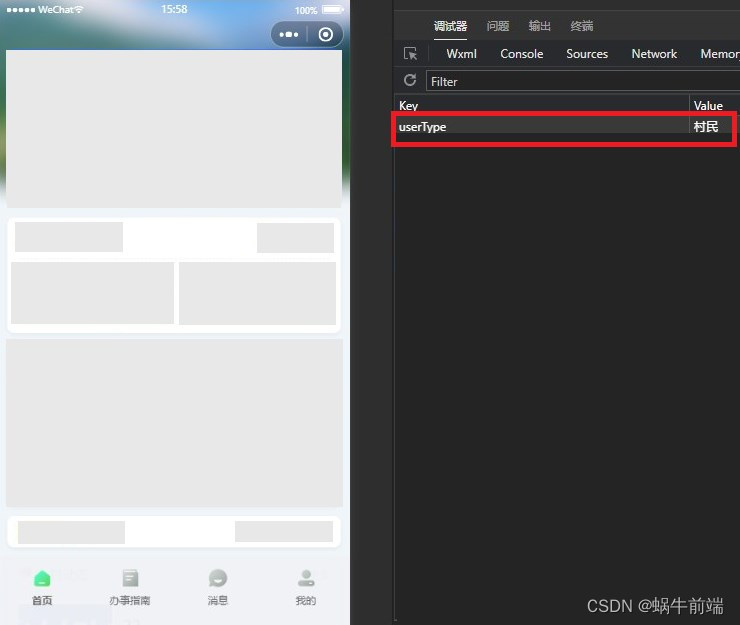
uniapp自定义权限菜单,动态tabbar
已封装为组件,亲测4个菜单项目可以切换, 以下为示例,根据Storage 中 userType 的 值,判断权限菜单 <template><view class"tab-bar pb10"><view class"tabli" v-for"(tab, index) in ta…...

ubuntu20.04配置解压版mysql5.7
目录 1.创建mysql 用户组和用户2.下载 MySQL 5.7 解压版3.解压 MySQL 文件4.将 MySQL 移动到适当的目录5.更改mysql目录所属的用户组和用户,以及权限6.进入mysql/bin/目录,安装初始化7.编辑/etc/mysql/my.cnf配置文件8.启动 MySQL 服务:9.建立…...
为null)
【js】vue获取document.getElementById(a)为null
需求 在菜单A页面点击某个元素携带id跳转到B详情页面,B页面获取该id元素的offsetTop, 并自动滚动到该元素处 问题 跳转到B详情页面, 在mounted获取到document.getElementById(a)为null, 因为整个详情页面是从后端获取来渲染的数据, 因此此时dom元素还未渲染出来,…...
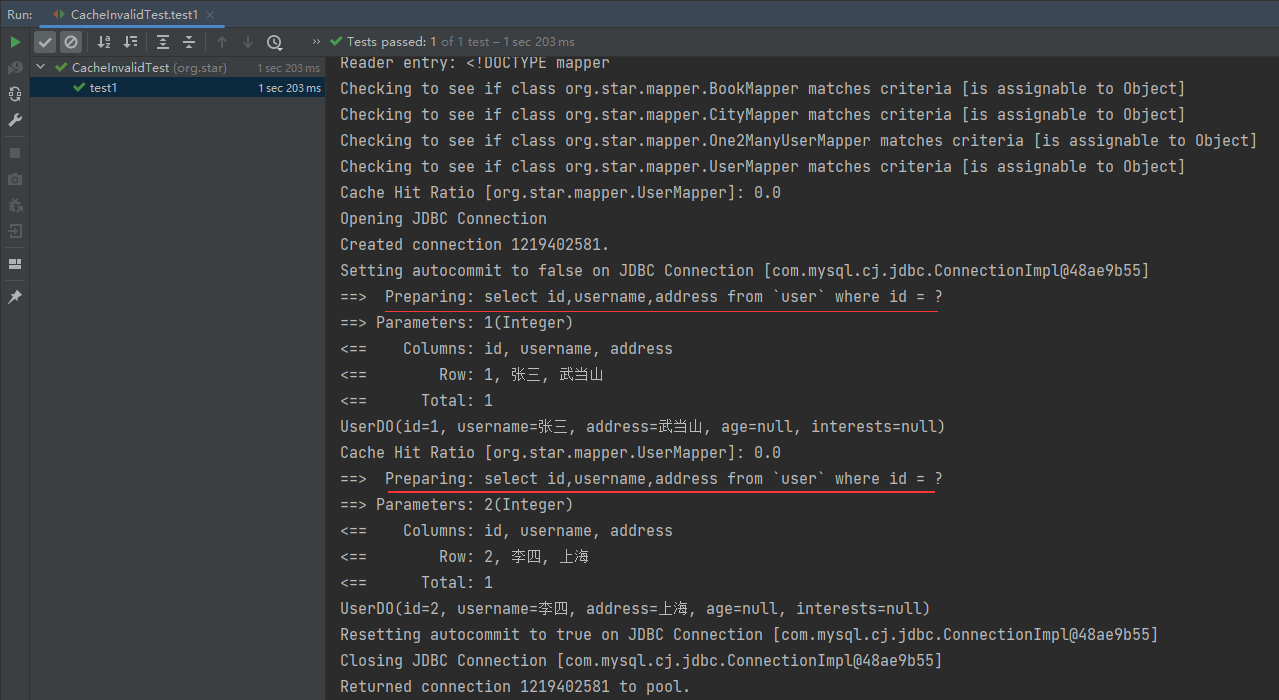
系列六、Mybatis的一级缓存
一、概述 Mybatis一级缓存的作用域是同一个SqlSession,在同一个SqlSession中执行两次相同的查询,第一次执行完毕后,Mybatis会将查询到的数据缓存起来(缓存到内存中), 第二次执行相同的查询时,会…...

用中文编程工具给澳大利亚客户定制开发的英文版服装进销存软件应用实例
用中文编程工具给澳大利亚客户定制开发的英文版服装进销存软件应用实例 软件从2016年一直用到现在,而且开的分店也是安装的这个软件,上图是定制打印的格式。 该编程工具不但可以连接硬件,而且可以开发大型的软件。 编程系统化课程总目录及明…...

geoserver 的跨域问题怎么解决
文章目录 问题分析问题 geoserver 发生跨域问题报错 分析 要解决 GeoServer 的跨域问题,可以通过配置 GeoServer 的 web.xml 文件来启用跨域资源共享(CORS)。以下是一些简单的步骤来实现这一点: 找到 GeoServer 的安装目录下的 webapps/geoserver/WEB-INF 文件夹。在该文…...

SQL语法实践(一)
文章 原文链接 实践 CREATE TABLE friend(fid INT NOT NULL,NAME VARCHAR(10) NOT NULL,age INT NOT NULL,adress VARCHAR(10) )SHOW TABLES; SELECT * FROM friend; SELECT fid,NAME FROM friend;INSERT INTO friend VALUES(1,Jack,18,Tianjing); INSERT INTO friend VALUE…...

路由器如何设置IP地址
IP地址是计算机网络中的关键元素,用于标识和定位设备和主机。在家庭或办公室网络中,路由器起到了连接内部设备和外部互联网的关键作用。为了使网络正常运行,需要正确设置路由器的IP地址。本文将介绍如何设置路由器的IP地址,以确保…...
自动驾驶算法(一):Dijkstra算法讲解与代码实现
目录 0 本节关键词:栅格地图、算法、路径规划 1 Dijkstra算法详解 2 Dijkstra代码详解 0 本节关键词:栅格地图、算法、路径规划 1 Dijkstra算法详解 用于图中寻找最短路径。节点是地点,边是权重。 从起点开始逐步扩展,每一步为一…...

MS5910PA为行业内领先的可配置10bit到16bit分辨率的旋变数字转换器,可替代AD2S1210
MS5910PA 是一款可配置 10bit 到 16bit 分辨率的旋 变数字转换器。片上集成正弦波激励电路,正弦和余弦 允许输入峰峰值幅度为 2.3V 到 4.0V ,频率范围为 2kHz 至 20kHz 。 转换器可并行或串行输出角度和速度对应的 数字量。 MS5910PA 采…...
Random指定随机种子遇到的坑
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言指定随机种子出现的问题?总结 前言 业务中,之前有一个抽奖的需求,之初想让固定的奖品和玩家绑定一个固定的池子,…...

2023云栖大会:属于开发者的狂欢
就在10月31日这天,杭州云栖小镇热闹非凡,第八届云栖大会在杭州云栖小镇盛大举行。这次大会以“聚焦大模型与生成式AI”为主题,开发者们齐聚一堂,共同探讨前沿技术趋势,以及如何将这些技术应用到实际业务场景中。 当然…...

FFXVIFix终极指南:解锁《最终幻想16》的完美游戏体验
FFXVIFix终极指南:解锁《最终幻想16》的完美游戏体验 【免费下载链接】FFXVIFix Migrated to https://codeberg.org/Lyall/FFXVIFix 项目地址: https://gitcode.com/gh_mirrors/ff/FFXVIFix FFXVIFix是一款专门为《最终幻想16》设计的全方位优化工具…...
)
软件工程师在智能体视觉时代的机遇(22)
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

从零搭建CXL设备模拟器:手把手实现CXL.cache协议的关键Opcode
从零搭建CXL设备模拟器:手把手实现CXL.cache协议的关键Opcode 在异构计算架构快速发展的今天,CXL(Compute Express Link)协议正成为连接CPU与加速器设备的关键纽带。作为CXL三大协议之一,CXL.cache协议通过定义设备与主…...

2025最权威的五大降重复率神器实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 处于内容营销范畴当中,标题属于勾引用户去点击的首个关卡。伴随AIGC也就是人工智…...

影刀RPA跨境店群自动化实战:Python协同Chromium打破风控「垄断」的高并发调度系统架构
定了。彻底打破传统商业指纹浏览器的生态「垄断」与电商巨头风控体系的「底层封锁」,我们用一套完全“自主可控”的、基于 Python 深度协同的分布式微服务调度架构,重塑了跨境千店矩阵的自动化底座。 这几天,科技圈被“DeepSeek V4 首发华为…...

Best Practice for AI Agents Project _ Chapter 1
很高兴he大家分享,《AI智能体项目最佳实践》内容,系统覆盖从单智能体工程基础,到私有知识注入、能力扩展、安全设计,再到多智能体协同的完整企业AI落地路径。本次分享第一章:从模型调用到可靠的单智能体(Fr…...

[特殊字符] 零基础搭建「知识科普讲师」数字人|魔珐星云实战指南
在短视频、知识付费、自媒体赛道,知识科普、职场干货、生活常识、读书分享内容需求越来越大。真人出镜成本高、拍摄慢、文案难量产,而AI 数字人讲师可以做到:文案好写、生成快、24 小时可播、风格稳定、形象专业。 本文基于魔珐星云具身智能…...

告别‘偏科’模型:用CAST双流架构搞定视频动作识别,兼顾时空理解
时空双流协同:CAST架构如何重塑视频动作识别的平衡之道 视频动作识别正面临一个关键瓶颈——现有模型往往在时空理解上"偏科"。就像人类大脑需要左右半球协同工作才能完整理解世界一样,理想的视频理解模型也需要同时具备敏锐的空间感知和精准的…...

LDDC歌词工具:5分钟掌握专业级歌词下载与格式转换完整指南
LDDC歌词工具:5分钟掌握专业级歌词下载与格式转换完整指南 【免费下载链接】LDDC 简单易用的精准歌词(逐字歌词/卡拉OK歌词)下载匹配工具|A simple and user-friendly tool for downloading and matching precise lyrics (word-by-word lyrics/Karaoke lyrics) 项…...

深入解析PyTorch-FCN架构:FCN32s、FCN16s、FCN8s模型对比分析
深入解析PyTorch-FCN架构:FCN32s、FCN16s、FCN8s模型对比分析 【免费下载链接】pytorch-fcn PyTorch Implementation of Fully Convolutional Networks. (Training code to reproduce the original result is available.) 项目地址: https://gitcode.com/gh_mirro…...