【2023年MathorCup高校数学建模挑战赛-大数据竞赛】赛道A:基于计算机视觉的坑洼道路检测和识别 python 代码解析
【2023年MathorCup高校数学建模挑战赛-大数据竞赛】赛道A:基于计算机视觉的坑洼道路检测和识别 python 代码解析
1 题目
坑洼道路检测和识别是一种计算机视觉任务,旨在通过数字图像(通常是地表坑洼图像)识别出存在坑洼的道路。这对于地.质勘探、航天科学和自然灾害等领域的研究和应用具有重要意义。例如,它可以帮助在地球轨道上识别坑洼,以及分析和模拟地球表面的形态。
在坑洼道路检测任务中,传统的分类算法往往不能取得很好的效果,因为坑洼图像的特征往往是非常复杂和多变的。然而,近年来深度学习技术的发展,为坑洼道路检测提供了新的解决方案。
深度学习具有很强的特征提取和表示能力,可以从图像中自动提取出最重要的特征。在坑洼图像分类任务中,利用深度学习可以提取到坑洼的轮廓、纹理和形态等特征,并将其转换为更容易分类的表示形式。同时,还可以通过迁移学习和知识蒸馏等技术进一步提升分类性能。例如,一些研究者使用基于深度学习的方法对路图像进行分类,将其分为正常、坑洼两类;另外,一些研究者还使用基于迁移学习的方法,从通用的预训练模型中学习坑洼图像的特征,并利用这些特征来分类坑洼图像。
本赛题希望通过对已标记的道路图像进行分析、特征提取与建模,从而对于一张新的道路图像能够自动识别坑洼状态。具体任务如下:
初赛问题
问题1: 结合给出的图像文件,提取图像特征,建立一个识别率高、速度快、分类准确的模型,用于识别图像中的道路是正常或者坑洼。
问題2: 对问题1中构建的模型进行训练,并从不同维度进行模型评估。
问题3: 利用已训练的模型识别测试集中的坑洼图像,并将识别结果放在“test_result.csv’'中。(注:测试集将在竞赛结束前48小时公布下载链接,请及时关注报名网站)
附件说明:
附件1:data.zip;
训练数据集,文件中共包含301张图片。
文件名中包含“normal’'字符表示正常道路,否则为坑洼道路。

图1:正常道路示例

图2:坑洼道路示例
附件2:test_result.csv;
测试结果提交文件,文件中表头保持不变,数据仅做示例,提交的时候删除后重新填写,字段描述见下表。
表1:test_result表字段说明
| 字段 | 说明 |
|---|---|
| fnames | 测试图片的文件名 |
| label | 分类标识:填写 1 和 0,1 表示正常道路 ;0 表示坑洼道路 |
附件3:test_data.zip
测试数据集,文件中包含几千张图片,具体数量以公布的数据为准。
测试数据集在竞赛结束前48小时公布下载链接,请及时关注报名网站。
2 思路分析
首先,训练集只有301张图片,说明这个一个小样本问题。按照以下流程去建立baseline,之后再在每个部分,逐步优化。
(1)数据预处理:
- 对图像进行尺寸调整:由于深度学习模型对输入图像尺寸要求较为严格,可以使用图像处理算法(如OpenCV库中的resize函数)将图像统一缩放到固定的尺寸。以下例子,统一大小 为224*224。
- 数据增强:可以使用图像增强算法(如OpenCV库中的平移、旋转、翻转等函数)对图像进行增强,以扩充样本数量和增加数据多样性。
(2)特征提取:
- 基于传统计算机视觉算法的特征提取:可以使用传统的图像特征提取算法(如SIFT、HOG、LBP等)来提取图像的局部或全局特征,用于训练深度学习模型。
- 基于深度学习模型的特征提取:可以使用预训练的卷积神经网络(如VGG、ResNet、Inception等)提取图像的高层特征,将这些特征作为输入,用于训练深度学习模型。以下是VGG提取特征为例,见3.3部分。
(3)可视化分析数据集:
- 使用图像处理算法(如OpenCV库中的imshow函数)显示图像:可以随机选择一些正常道路和坑洼道路的样本图像,并使用图像处理算法将它们可视化显示出来,以了解数据集的特点和难点。
- 绘制直方图、散点图等统计图表:可以通过统计学手段,如绘制正常道路和坑洼道路图像像素的直方图、颜色特征的散点图等,来观察数据集的分布情况,判断图像特征是否有区分度。
(4)建立深度学习模型:
- baseline使用卷积神经网络(如VGG、ResNet、Inception等)、自编码器、循环神经网络等,并根据数据集的特点进行微调或迁移学习。
- 其他前沿的图像分类技术包括
- 迁移学习:将在大规模数据集上训练好的模型(如ImageNet)迁移到小样本问题上,通过微调或特征提取来解决分类问题。
- 数据增强:使用图像增强算法(如旋转、平移、翻转、裁剪等)对样本进行扩充,增加样本数量和多样性。
- 生成对抗网络(GAN):通过合成样本数据来增加样本数量,用GAN生成器生成逼真的样本来扩充数据。
- 元学习(Meta Learning):学习如何从有限样本中较快地学习和泛化,通过学习到的先验知识来优化样本的利用效率。
- 半监督学习:利用少量的有标签样本和大量的无标签样本进行训练,提升分类准确率。
- 主动学习(Active Learning):利用主动选择和标注关键样本,以降低标注成本并提高模型性能。
- 小样本学习方法:针对小样本问题提出专门的算法和方法,如Few-shot Learning、One-shot Learning、Zero-shot Learning等。
- 增量学习(Incremental Learning):逐步学习和增量更新模型,以适应新样本的引入和旧样本的遗忘。
- 模型压缩和量化:通过模型剪枝、量化和蒸馏等技术,减少模型参数和计算量,使其适应小样本问题。
- 集成学习:将多个分类器的结果进行结合,提高分类准确率和鲁棒性,如bagging、boosting等。
(5)模型评估和优化:
- 采用交叉验证方法对模型进行评估:可以使用k折交叉验证等方法对模型进行评估,得到准确率、召回率等指标,从而判断模型的性能。
- 对模型进行调参和优化:可以尝试不同的损失函数、优化器、学习率等超参数,以及增加数据集规模、减少模型复杂度等方式来优化深度学习模型。
3 python代码实现
3.1 数据预处理
import os
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Activation, Dropout, Flatten, Dense
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.layers import Convolution2D, MaxPooling2D, ZeroPadding2D
from tensorflow.keras import optimizers
from tensorflow.keras import applications
from tensorflow.keras.models import Model
from IPython.display import Image
from tensorflow.keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
import os
from sklearn.model_selection import train_test_split
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import pandas as pd
from PIL import Image
import os# 将图片统一像素格式,并分别存储到文件夹中# 创建文件夹
processed_normal_dir = "data/processed_normal"
processed_wavy_dir = "data/processed_wavy"
os.makedirs(processed_normal_dir, exist_ok=True)
os.makedirs(processed_wavy_dir, exist_ok=True)# 处理图像
data_dir = "data"
for filename in os.listdir(data_dir):img_path = os.path.join(data_dir, filename)img = Image.open(img_path)# 对图像进行缩放img = img.resize((224, 224))# 决定图像应该存储在哪个文件夹中if "normal" in filename:save_dir = processed_normal_direlse:save_dir = processed_wavy_dir# 保存图像save_path = os.path.join(save_dir, filename)img.save(save_path)(2)数据加载
总共301张图片,选择30张图片作为测试集,1张图片单独拿出来测试,否则不好整数划分。
img_width, img_height = 224, 224
num_classes = 2
batch_size = 10datagen = ImageDataGenerator(rescale=1./255)X = []
y = []
normal_dir = "data/processed_normal"
wavy_dir = "data/processed_wavy"for img_name in os.listdir(normal_dir):img_path = os.path.join(normal_dir, img_name)X.append(img_path)y.append('0')
for img_name in os.listdir(wavy_dir):img_path = os.path.join(wavy_dir, img_name)X.append(img_path)y.append('1')X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.1, random_state=42)
train_df = pd.DataFrame(data={'filename': X_train, 'class': y_train})
val_df = pd.DataFrame(data={'filename': X_val, 'class': y_val})train_generator = datagen.flow_from_dataframe(...略validation_generator = datagen.flow_from_dataframe(...略
Found 270 validated image filenames belonging to 2 classes.
Found 30 validated image filenames belonging to 2 classes.
3.2 卷积模型训练
(1)定义卷积网络
model = Sequential()
model.add(Convolution2D(32, (3, 3), input_shape=(img_width, img_height,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Convolution2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Convolution2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Flatten())
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))model.compile(loss='binary_crossentropy',optimizer='rmsprop',metrics=['accuracy'])
(2)模型训练
epochs = 20
train_samples = 270
validation_samples = 30
batch_size =10
model.fit_generator(train_generator,steps_per_epoch=train_samples // batch_size,epochs=epochs,validation_data=validation_generator,validation_steps=validation_samples// batch_size,)model.save_weights('models/basic_cnn_20_epochs.h5')
model.load_weights('models_trained/basic_cnn_30_epochs.h5')

(3)模型验证
# 将多余出来的一张图片拿出来预测
img = load_img('data/normal1.jpg')
x = img_to_array(img)
prediction = model.predict(x.reshape((1,img_width, img_height,3)),batch_size=10, verbose=0)
print(prediction)
0
model.evaluate_generator(validation_generator, validation_samples)
[0.7280968427658081, 0.8999999761581421]
3.3 数据增强训练
(1)数据增强
通过对训练集应用随机变换,用新的未见过的图像人为地增强了的数据集。减少过拟合,并为我们的网络提供更好的泛化能力。
train_datagen_augmented = ImageDataGenerator(rescale=1./255, # normalize pixel values to [0,1]shear_range=0.2, # randomly applies shearing transformationzoom_range=0.2, # randomly applies shearing transformationhorizontal_flip=True) # randomly flip the imagestrain_generator_augmented = train_datagen_augmented.flow_from_dataframe(...略(2)模型训练
model.fit_generator(train_generator_augmented,steps_per_epoch=train_samples // batch_size,epochs=epochs,validation_data=validation_generator,validation_steps=validation_samples // batch_size,)

(3)模型评估
model.save_weights('models/augmented_20_epochs.h5')
#model.load_weights('models_trained/augmented_30_epochs.h5')model.evaluate_generator(validation_generator, validation_samples)
[0.2453145980834961, 0.8666666746139526]
3.4 预训练模型
通过使用通用的、预训练的图像分类器,可以在性能和效率方面超越以前的模型。这个例子使用了VGG16,一个在ImageNet数据集上训练的模型,该数据集包含了被分类为1000个类别的数百万张图像。
(1)加载VGG模型的权重
model_vgg =
train_generator_bottleneck = datagen.flow_from_dataframe(dataframe=train_df,directory=None,x_col='filename',y_col='class',target_size=(img_width, img_height),batch_size=batch_size,class_mode='binary')validation_generator_bottleneck = datagen.flow_from_dataframe(dataframe=val_df,directory=None,x_col='filename',y_col='class',target_size=(img_width, img_height),batch_size=batch_size,class_mode='binary')
(2)用模型提取特征
bottleneck_features_train = model_vgg.predict_generator(train_generator_bottleneck, train_samples // batch_size)
np.save(open('models/bottleneck_features_train.npy', 'wb'), bottleneck_features_train)bottleneck_features_validation = model_vgg.predict_generator(validation_generator_bottleneck, validation_samples // batch_size)
np.save(open('models/bottleneck_features_validation.npy', 'wb'), bottleneck_features_validation)
(3)读取预处理的数据
train_data = np.load(open('models/bottleneck_features_train.npy', 'rb'))
train_labels = np.array([0] * (train_samples // 2) + [1] * (train_samples // 2))validation_data = np.load(open('models/bottleneck_features_validation.npy', 'rb'))
validation_labels = np.array([0] * (validation_samples // 2) + [1] * (validation_samples // 2))
(4)全连接网络模型训练
model_top = Sequential()
model_top.add(Flatten(input_shape=train_data.shape[1:]))
model_top.add(Dense(256, activation='relu'))
model_top.add(Dropout(0.5))
model_top.add(Dense(1, activation='sigmoid'))model_top.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['accuracy'])model_top.fit(train_data, train_labels,epochs=epochs, batch_size=batch_size,validation_data=(validation_data, validation_labels))model_top.save_weights('models/bottleneck_20_epochs.h5')

(5)模型评估
model_top.evaluate(validation_data, validation_labels)
[2.3494818210601807, 0.4333333373069763]
3.5 微调预训练模型
在卷积模型之上建立一个分类器模型。为了进行微调,从一个经过充分训练的分类器开始。将使用早期模型中的权重。然后把这个模型加到卷积基上
weights_path = 'weight/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5'
model_vgg = applications.VGG16(include_top=False, weights=weights_path, input_shape=(224, 224, 3))top_model = Sequential()
top_model.add(Flatten(input_shape=model_vgg.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(1, activation='sigmoid'))top_model.load_weights('models/bottleneck_20_epochs.h5')#model_vgg.add(top_model)
model = Model(inputs = model_vgg.input, outputs = top_model(model_vgg.output))
# 微调,只需要训练几层。这一行将设置前25层(直到conv块)为不可训练的。for layer in model_vgg.layers[:15]:layer.trainable = Falsemodel.compile(loss='binary_crossentropy',optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),metrics=['accuracy'])
数据增强
# 数据增强
train_datagen = ImageDataGenerator(rescale=1./255,shear_range=0.2,zoom_range=0.2,horizontal_flip=True)test_datagen = ImageDataGenerator(rescale=1./255)train_generator = datagen.flow_from_dataframe(...略validation_generator = datagen.flow_from_dataframe(...略
模型微调
# 微调模型
model.fit_generator(train_generator,steps_per_epoch=train_samples // batch_size,epochs=epochs,validation_data=validation_generator,validation_steps=validation_samples // batch_size)model.save_weights('models/finetuning_20epochs_vgg.h5')
model.load_weights('models/finetuning_20epochs_vgg.h5')

模型评估
model.evaluate_generator(validation_generator, validation_samples)
[nan, 0.8666666746139526]
最后这种方式模型不收敛,说明这个网络设置过程中存在不合理的地方,比如冻结参数的层数,使用的网络模型,是否需要数据增强等因素都会影响。提供这种方式,有待同学们去改进。
4 下载完整程序
以上代码是不完整的,需要完整的请下载后源文件
包括训练好的模型和权重文件

相关文章:
【2023年MathorCup高校数学建模挑战赛-大数据竞赛】赛道A:基于计算机视觉的坑洼道路检测和识别 python 代码解析
【2023年MathorCup高校数学建模挑战赛-大数据竞赛】赛道A:基于计算机视觉的坑洼道路检测和识别 python 代码解析 1 题目 坑洼道路检测和识别是一种计算机视觉任务,旨在通过数字图像(通常是地表坑洼图像)识别出存在坑洼的道路。这…...

Mozilla Firefox 119 现已可供下载
Mozilla Firefox 119 开源网络浏览器现在可以下载了,是时候先看看它的新功能和改进了。 Firefox 119 改进了 Firefox View 功能,现在可以提供更多内容,如最近关闭的标签页和浏览历史,你可以按日期或网站排序,还支持查…...

What is 哈希?
哈希 前言:大一大二就一直听说哈希哈希,但一直都没有真正的概念:What is 哈希?这篇博客就浅浅聊一下作者认知中的哈希。 理解哈希 哈希(Hash)也可以称作散列,实质就是一种映射…...
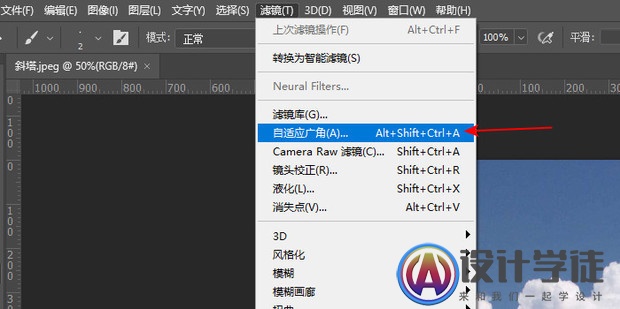
在Photoshop中如何校正倾斜的图片
在Photoshop中如何校正倾斜的图片呢?今天就教大家如何操作。 将需要操作的图片拉到PS软件中,自动形成项目。 点击上方“滤镜”中的“镜头校正”。 进入“镜头校正”窗口,点击左侧的“拉直工具”。文章源自设计学徒自学网-http://www.sx1c.co…...

Maven第六章:Maven的自定义插件开发
Maven第六章:Maven的自定义插件开发 前言 maven不仅仅只是项目的依赖管理工具,其强大的核心来源自丰富的插件,可以说插件才是maven工具的灵魂。本篇文章将对如何自定义maven插件进行讲解,希望对各位读者有所帮助。 Maven插件开发的基本概念 Maven插件是由Maven构建工具本身…...

springboot 注入配置文件中的集合 List
在使用 springboot 开发时,例如你需要注入一个 url 白名单列表,你可能第一想到的写法是下面这样的: application.yml white.url-list:- /test/show1- /test/show2- /test/show3Slf4j RestController RequestMapping("/test") pub…...

springboot整合redis+lua实现getdel操作保证原子性
原始代码 脚本逻辑先获取redis的值,判断是否等于期望值。 条件成立则删除,不成立则返回0 if redis.call(get, KEYS[1]) ARGV[1] thenreturn redis.call(del, KEYS[1]) end return 0 测试代码 根据上面的逻辑加了测试, 在判断成功后等待5…...
win10系统nodejs的安装npm教程
1.在官网下载nodejs,https://nodejs.org/en 2,双击nodejs的安装包 3,点击 next 4,勾选I accpet the terms in…… 5,第4步点击next进入配置安装路径界面 6,点击next,选中Add to PATH ,旁边…...

C语言assert函数:什么是“assert”函数
我一直在学习 OpenCV 教程,遇到了assert函数;它做什么? assert将终止程序(通常带有引用 assert 语句的消息),如果其参数为 false。它通常在调试过程中使用,以使程序在发生意外情况时更明显地失败。 例如&…...

R语言绘图-5-条形图(修改坐标轴以及图例等)
0. 说明: 1. 绘制条形图; 2. 添加文本并调整位置; 3. 调整x轴刻度的字体、角度及颜色; 4. 在导出pdf时,如果没有字体,该怎么解决问题; 1. 结果: 2. 代码: library(ggp…...
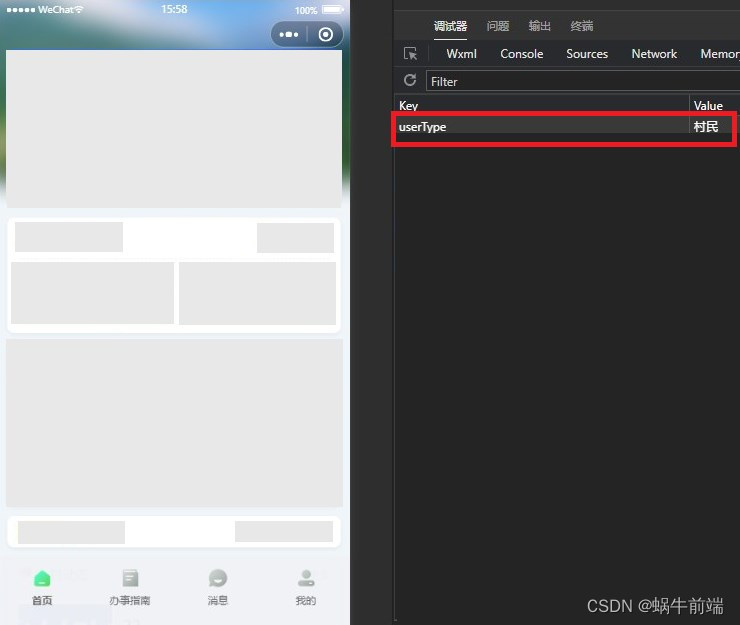
uniapp自定义权限菜单,动态tabbar
已封装为组件,亲测4个菜单项目可以切换, 以下为示例,根据Storage 中 userType 的 值,判断权限菜单 <template><view class"tab-bar pb10"><view class"tabli" v-for"(tab, index) in ta…...

ubuntu20.04配置解压版mysql5.7
目录 1.创建mysql 用户组和用户2.下载 MySQL 5.7 解压版3.解压 MySQL 文件4.将 MySQL 移动到适当的目录5.更改mysql目录所属的用户组和用户,以及权限6.进入mysql/bin/目录,安装初始化7.编辑/etc/mysql/my.cnf配置文件8.启动 MySQL 服务:9.建立…...
为null)
【js】vue获取document.getElementById(a)为null
需求 在菜单A页面点击某个元素携带id跳转到B详情页面,B页面获取该id元素的offsetTop, 并自动滚动到该元素处 问题 跳转到B详情页面, 在mounted获取到document.getElementById(a)为null, 因为整个详情页面是从后端获取来渲染的数据, 因此此时dom元素还未渲染出来,…...
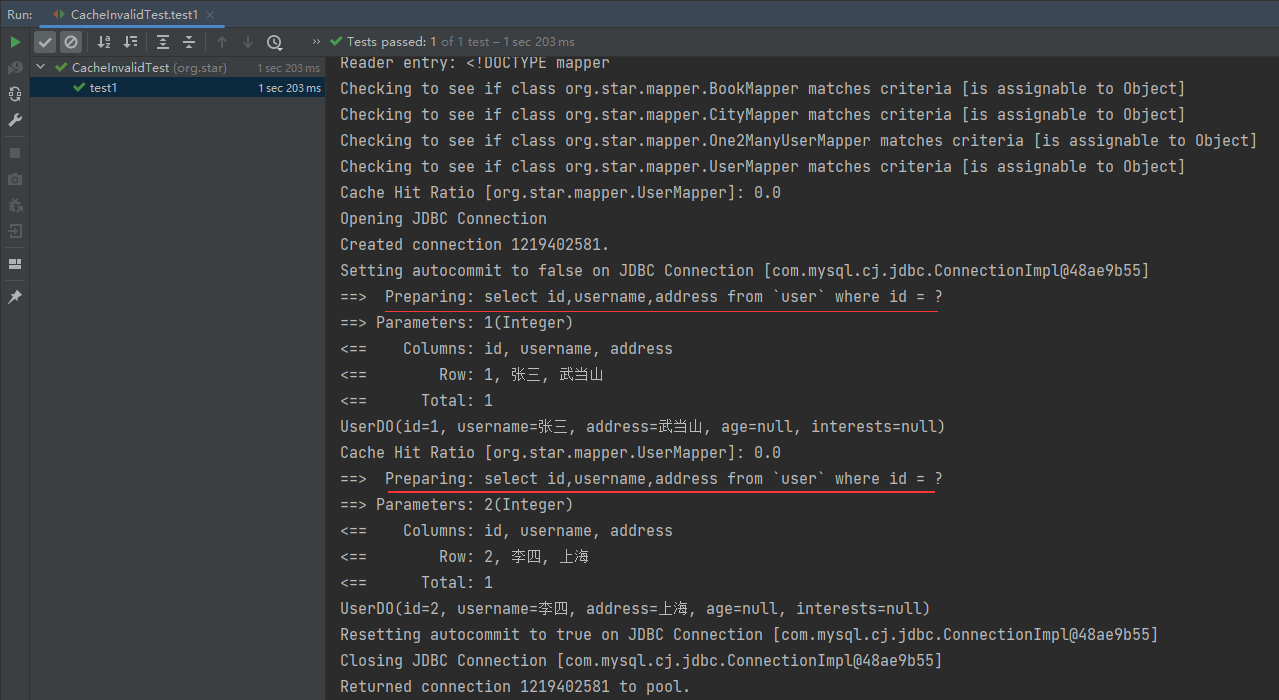
系列六、Mybatis的一级缓存
一、概述 Mybatis一级缓存的作用域是同一个SqlSession,在同一个SqlSession中执行两次相同的查询,第一次执行完毕后,Mybatis会将查询到的数据缓存起来(缓存到内存中), 第二次执行相同的查询时,会…...

用中文编程工具给澳大利亚客户定制开发的英文版服装进销存软件应用实例
用中文编程工具给澳大利亚客户定制开发的英文版服装进销存软件应用实例 软件从2016年一直用到现在,而且开的分店也是安装的这个软件,上图是定制打印的格式。 该编程工具不但可以连接硬件,而且可以开发大型的软件。 编程系统化课程总目录及明…...

geoserver 的跨域问题怎么解决
文章目录 问题分析问题 geoserver 发生跨域问题报错 分析 要解决 GeoServer 的跨域问题,可以通过配置 GeoServer 的 web.xml 文件来启用跨域资源共享(CORS)。以下是一些简单的步骤来实现这一点: 找到 GeoServer 的安装目录下的 webapps/geoserver/WEB-INF 文件夹。在该文…...

SQL语法实践(一)
文章 原文链接 实践 CREATE TABLE friend(fid INT NOT NULL,NAME VARCHAR(10) NOT NULL,age INT NOT NULL,adress VARCHAR(10) )SHOW TABLES; SELECT * FROM friend; SELECT fid,NAME FROM friend;INSERT INTO friend VALUES(1,Jack,18,Tianjing); INSERT INTO friend VALUE…...

路由器如何设置IP地址
IP地址是计算机网络中的关键元素,用于标识和定位设备和主机。在家庭或办公室网络中,路由器起到了连接内部设备和外部互联网的关键作用。为了使网络正常运行,需要正确设置路由器的IP地址。本文将介绍如何设置路由器的IP地址,以确保…...
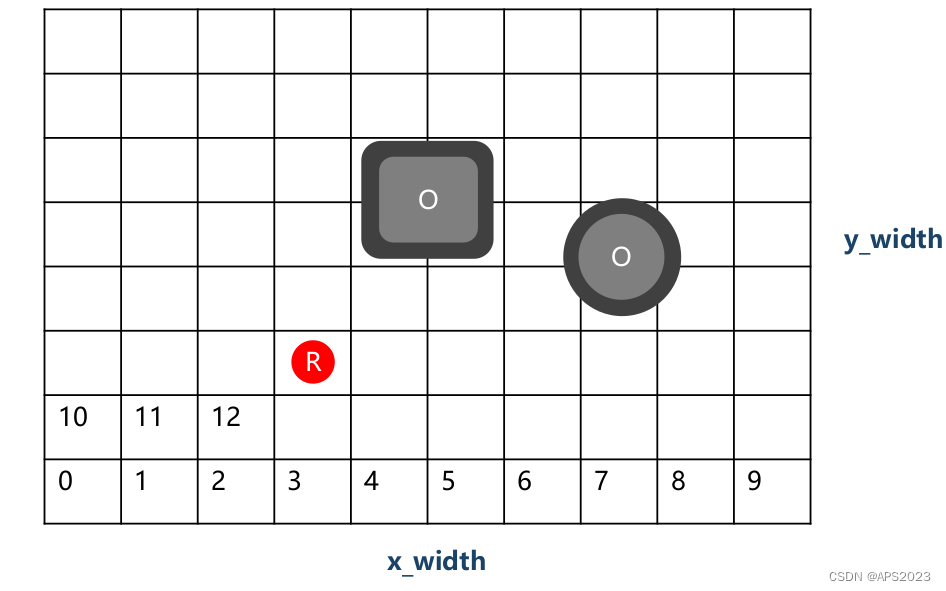
自动驾驶算法(一):Dijkstra算法讲解与代码实现
目录 0 本节关键词:栅格地图、算法、路径规划 1 Dijkstra算法详解 2 Dijkstra代码详解 0 本节关键词:栅格地图、算法、路径规划 1 Dijkstra算法详解 用于图中寻找最短路径。节点是地点,边是权重。 从起点开始逐步扩展,每一步为一…...

MS5910PA为行业内领先的可配置10bit到16bit分辨率的旋变数字转换器,可替代AD2S1210
MS5910PA 是一款可配置 10bit 到 16bit 分辨率的旋 变数字转换器。片上集成正弦波激励电路,正弦和余弦 允许输入峰峰值幅度为 2.3V 到 4.0V ,频率范围为 2kHz 至 20kHz 。 转换器可并行或串行输出角度和速度对应的 数字量。 MS5910PA 采…...

高校生必备的AI论文写作软件有哪些?
国内高校学生普遍使用的AI论文写作工具,以功能全面的本土化软件为主,结合通用大模型与专业辅助工具,覆盖选题构思、框架搭建、初稿撰写、内容降重、查重检测、格式排版等关键环节,以下是主流工具详解与对比: 一、本土全…...

暗黑破坏神2存档编辑器终极指南:5分钟掌握Diablo Edit2核心功能
暗黑破坏神2存档编辑器终极指南:5分钟掌握Diablo Edit2核心功能 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾经因为暗黑破坏神2中角色技能点分配失误而苦恼?是否…...

9 款 AI 毕业论文工具硬核横评:okbiye 领衔,解锁高效合规写作新路径
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 毕业季的本科论文写作,向来是耗时耗力的 “攻坚战”。选题迷茫、大纲混乱、格式反复出错、查重屡屡超标、AI 痕迹过重难通过检测…...

如何彻底解决Mac设备滚动方向冲突:Scroll Reverser终极配置指南
如何彻底解决Mac设备滚动方向冲突:Scroll Reverser终极配置指南 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是不是经常在Mac上同时使用触控板和鼠标࿰…...

链路层协议
链路层协议要解决哪些问题。有哪些二层网络,其链路层协议是什么 链路层(数据链路层,OSI模型第二层)的主要功能是在物理层提供的物理连接基础上,提供可靠的数据传输服务。它负责将原始的物理连接转化为无差错、有逻辑结…...

智慧树自动刷课插件终极指南:5分钟快速上手,告别手动刷课烦恼
智慧树自动刷课插件终极指南:5分钟快速上手,告别手动刷课烦恼 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台繁琐的视频操作而…...

跨境电商作图不纠结!风格全覆盖, AI 工具帮你省超多心
做跨境电商这么多年,最头疼的从来不是选品和运营,而是作图!不同平台风格要求不一样、不同国家审美差异大、小白没设计基础、外包贵还改到崩溃… 相信不少跨境卖家都跟我一样,在作图这件事上踩过无数坑。今天就以老卖家的身份&…...

地平线6正式上线!UU远程云电脑工作日也能全高画质飙车
《极限竞速:地平线6》5月18日正式全球发售!该作将舞台设在超燃的日本东京,从东京涩谷的霓虹璀璨,到秋名山的晨雾缭绕与漂移快感;从北海道的茫茫雪原越野,到富士山下的樱花赛道浪漫驰骋,每一处场景都细节拉满…...

从‘延迟’到‘精准’:聊聊风力发电机液压偏航控制中的那些坑与优化思路
从‘延迟’到‘精准’:风力发电机液压偏航控制的实战优化指南 引言:当风向变化比控制指令更快 在内蒙古某风电场,一台2.5MW机组在春季大风季节出现了令人费解的现象:尽管偏航系统持续运转,发电量却比相邻机组低12%。现…...

Redis——string类型相关指令
添加键值对SET [key] [value] [EX seconds|PX milliseconds] [NX|XX] //添加一个键值对SETNX [key] [value] //setNX的组合命令,不支持EX/PX选项SETEX [key] [value] //setEX的组合命令,不支持NX/XX选项PSETEX [key] [value] //setPX的组合命令ÿ…...