当科技遇上神器:用Streamlit定制AI可视化问答界面
Streamlit是一个开源的Python库,利用Streamlit可以快速构建机器学习应用的用户界面。
本文主要探讨如何使用Streamlit构建大模型+外部知识检索的AI问答可视化界面。
我们先构建了外部知识检索接口,然后让大模型根据检索返回的结果作为上下文来回答问题。
Streamlit-使用说明
下面简单介绍下Streamlit的安装和一些用到的组件。
- Streamlit安装
pip install streamlit
- Streamlit启动
streamlit run xxx.py --server.port 8888
说明:
- 如果不指定端口,默认使用8501,如果启动多个streamlit,端口依次升序,8502,8503,…。
- 设置server.port可指定端口。
- streamlit启动后将会给出两个链接,Local URL和Network URL。
- 相关组件
import streamlit as st
- st.header
streamlit.header(body)
body:字符串,要显示的文本。
- st.markdown
st.markdown(body, unsafe_allow_html=False)
body:要显示的markdown文本,字符串。
unsafe_allow_html: 是否允许出现html标签,布尔值,默认:false,表示所有的html标签都将转义。 注意,这是一个临时特性,在将来可能取消。
- st.write
st.write(*args, **kwargs)
*args:一个或多个要显示的对象参数。
unsafe_allow_html :是否允许不安全的HTML标签,布尔类型,默认值:false。
- st.button
st.button(label, key=None)
label:按钮标题字符串。
key:按钮组件的键,可选。如果未设置的话,streamlit将自动生成一个唯一键。
- st.radio
st.radio(label, options, index=0, format_func=<class 'str'>, key=None)
label:单选框文本,字符串。
options:选项列表,可以是以下类型:
list
tuple
numpy.ndarray
pandas.Series
index:选中项的序号,整数。
format_func:选项文本的显示格式化函数。
key:组件ID,当未设置时,streamlit会自动生成。
- st.sidebar
st.slider(label, min_value=None, max_value=None, value=None, step=None, format=None, key=None)
label:说明文本,字符串。
min_value:允许的最小值,默认值:0或0.0。
max_value:允许的最大值,默认值:0或0.0。
value:当前值,默认值为min_value。
step:步长,默认值为1或0.01。
format:数字显示格式字符串
。
key:组件ID。
- st.empty
st.empty()
填充占位符。
- st.columns
插入并排排列的容器。
st.columns(spec, *, gap="small")
spec: 控制要插入的列数和宽度。
gap: 列之间的间隙大小。
AI问答可视化代码
这里只涉及到构建AI问答界面的代码,不涉及到外部知识检索。
- 导入packages
import streamlit as st
import requests
import json
import sys,osimport torch
import torch.nn as nn
from dataclasses import dataclass, asdict
from typing import List, Optional, Callable
import copy
import warnings
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation.utils import GenerationConfig
from peft import PeftModel
from chatglm.modeling_chatglm import ChatGLMForConditionalGeneration
- 外部知识检索
def get_reference(user_query,use_top_k=True,top_k=10,use_similar_score=True,threshold=0.7):"""外部知识检索的方式,使用top_k或者similar_score控制检索返回值。"""# 设置检索接口SERVICE_ADD = ''ref_list = []user_query = user_query.strip()input_data = {}if use_top_k:input_data['query'] = user_queryinput_data['topk'] = top_kresult = requests.post(SERVICE_ADD, json=input_data)res_json = json.loads(result.text)for i in range(len(res_json['answer'])):ref = res_json['answer'][i]ref_list.append(ref)elif use_similar_score:input_data['query'] = user_queryinput_data['topk'] = top_kresult = requests.post(SERVICE_ADD, json=input_data)res_json = json.loads(result.text)for i in range(len(res_json['answer'])):maxscore = res_json['answer'][i]['prob']if maxscore > threshold: ref = res_json['answer'][i]ref_list.append(ref)return ref_list
- 参数设置
# 设置清除按钮
def on_btn_click():del st.session_state.messages# 设置参数
def set_config():# 设置基本参数base_config = {"model_name":"","use_ref":"","use_topk":"","top_k":"","use_similar_score":"","max_similar_score":""}# 设置模型参数model_config = {'top_k':'','top_p':'','temperature':'','max_length':'','do_sample':""}# 左边栏设置with st.sidebar:model_name = st.radio("模型选择:",["baichuan2-13B-chat", "qwen-14B-chat","chatglm-6B","chatglm3-6B"],index="0",)base_config['model_name'] = model_nameset_ref = st.radio("是否使用外部知识库:",["是","否"],index="0",)base_config['use_ref'] = set_refif set_ref=="是":set_topk_score = st.radio('设置选择参考文献的方式:',['use_topk','use_similar_score'],index='0',)if set_topk_score=='use_topk':set_topk = st.slider('Top_K', 1, 10, 5,step=1)base_config['top_k'] = set_topkbase_config['use_topk'] = Truebase_config['use_similar_score'] = Falseset_score = st.empty()elif set_topk_score=='use_similar_score':set_score = st.slider("Max_Similar_Score",0.00,1.00,0.70,step=0.01)base_config['max_similar_score'] = set_scorebase_config['use_similar_score'] = Truebase_config['use_topk'] = Falseset_topk = st.empty()else:set_topk_score = st.empty()set_topk = st.empty()set_score = st.empty()sample = st.radio("Do Sample", ('True', 'False'))max_length = st.slider("Max Length", min_value=64, max_value=2048, value=1024)top_p = st.slider('Top P', 0.0, 1.0, 0.7, step=0.01)temperature = st.slider('Temperature', 0.0, 2.0, 0.05, step=0.01)st.button("Clear Chat History", on_click=on_btn_click)# 设置模型参数model_config['top_p']=top_pmodel_config['do_sample']=samplemodel_config['max_length']=max_lengthmodel_config['temperature']=temperaturereturn base_config,model_config
- 设置模型输入格式
# 设置不同模型的输入格式
def set_input_format(model_name):# ["baichuan2-13B-chat", "baichuan2-7B-chat", "qwen-14B-chat",'chatglm-6B','chatglm3-6B']if model_name=="baichuan2-13B-chat" or model_name=='baichuan2-7B-chat':input_format = "<reserved_106>{{query}}<reserved_107>"elif model_name=="qwen-14B-chat":input_format = """<|im_start|>system 你是一个乐于助人的助手。<|im_end|><|im_start|>user{{query}}<|im_end|><|im_start|>assistant"""elif model_name=="chatglm-6B":input_format = """{{query}}"""elif model_name=="chatglm3-6B":input_format = """<|system|>You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown.<|user|>{{query}}<|assistant|>"""return input_format
- 加载模型
# 加载模型和分词器
@st.cache_resource
def load_model(model_name):if model_name=="baichuan2-13B-chat":model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-13B-Chat",trust_remote_code=True)lora_path = ""tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan2-13B-Chat",trust_remote_code=True)model.to("cuda:0")elif model_name=="qwen-14B-chat":model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-14B-Chat",trust_remote_code=True)lora_path = ""tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-14B-Chat",trust_remote_code=True)model.to("cuda:1")elif model_name=="chatglm-6B":model = ChatGLMForConditionalGeneration.from_pretrained('THUDM/chatglm-6b',trust_remote_code=True)lora_path = ""tokenizer = AutoTokenizer.from_pretrained('THUDM/chatglm-6b',trust_remote_code=True)model.to("cuda:2")elif model_name=="chatglm3-6B":model = AutoModelForCausalLM.from_pretrained('THUDM/chatglm3-6b',trust_remote_code=True)lora_path = ""tokenizer = AutoTokenizer.from_pretrained('THUDM/chatglm3-6b',trust_remote_code=True)model.to("cuda:3")# 加载lora包model = PeftModel.from_pretrained(model,lora_path)return model,tokenizer
- 推理参数设置
def llm_chat(model_name,model,tokenizer,model_config,query):response = ''top_k = model_config['top_k']top_p = model_config['top_p']max_length = model_config['max_length']do_sample = model_config['do_sample']temperature = model_config['temperature']if model_name=="baichuan2-13B-chat" or model_name=='baichuan-7B-chat':messages = []messages.append({"role": "user", "content": query})response = model.chat(tokenizer, messages)elif model_name=="qwen-14B-chat":response, history = model.chat(tokenizer, query, history=None, top_p=top_p, max_new_tokens=max_length, do_sample=do_sample, temperature=temperature)elif model_name=="chatglm-6B":response, history = model.chat(tokenizer, query, history=None, top_p=top_p, max_length=max_length, do_sample=do_sample, temperature=temperature)elif model_name=="chatglm3-6B":response, history= model.chat(tokenizer, query, top_p=top_p, max_length=max_length, do_sample=do_sample, temperature=temperature)return response
- 主程序
if __name__=="__main__":#对话的图标user_avator = "🧑💻"robot_avator = "🤖"if "messages" not in st.session_state:st.session_state.messages = []torch.cuda.empty_cache()base_config,model_config = set_config()model_name = base_config['model_name']use_ref = base_config['use_ref']model,tokenizer = load_model(model_name=model_name)input_format = set_input_format(model_name=model_name)header_text = f'Large Language Model :{model_name}'st.header(header_text)if use_ref=="是":col1, col2 = st.columns([5, 3]) with col1:for message in st.session_state.messages:with st.chat_message(message["role"], avatar=message.get("avatar")):st.markdown(message["content"])if user_query := st.chat_input("请输入内容..."):with col1: with st.chat_message("user", avatar=user_avator):st.markdown(user_query)st.session_state.messages.append({"role": "user", "content": user_query, "avatar": user_avator})with st.chat_message("robot", avatar=robot_avator):message_placeholder = st.empty()use_top_k = base_config['use_topk']if use_top_k:top_k = base_config['top_k']use_similar_score = base_config['use_similar_score']ref_list = get_reference(user_query,use_top_k=use_top_k,top_k=top_k,use_similar_score=use_similar_score) else:use_top_k = base_config['use_topk']use_similar_score = base_config['use_similar_score']threshold = base_config['max_similar_score']ref_list = get_reference(user_query,use_top_k=use_top_k,use_similar_score=use_similar_score,threshold=threshold)if ref_list:context = ""for ref in ref_list:context = context+ref['para']+"\n"context = context.strip('\n')query = f'''上下文:【{context} 】只能根据提供的上下文信息,合理回答下面的问题,不允许编造内容,不允许回答无关内容。问题:【{user_query}】'''else:query = user_queryquery = input_format.replace("{{query}}",query)print('输入:',query)max_len = model_config['max_length']if len(query)>max_len:cur_response = f'字数超过{max_len},请调整max_length。'else:cur_response = llm_chat(model_name,model,tokenizer,model_config,query)fs.write(f'输入:{query}')fs.write('\n')fs.write(f'输出:{cur_response}')fs.write('\n')sys.stdout.flush()if len(query)<max_len:if ref_list:cur_response = f"""大模型将根据外部知识库回答您的问题:{cur_response}"""else:cur_response = f"""大模型将根据预训练时的知识回答您的问题,存在编造事实的可能性。因此以下输出仅供参考:{cur_response}"""message_placeholder.markdown(cur_response)st.session_state.messages.append({"role": "robot", "content": cur_response, "avatar": robot_avator})with col2:ref_list = get_reference(user_query)if ref_list:for ref in ref_list:ques = ref['ques']answer = ref['para']score = ref['prob']question = f'{ques}--->score: {score}'with st.expander(question):st.write(answer)else:for message in st.session_state.messages:with st.chat_message(message["role"], avatar=message.get("avatar")):st.markdown(message["content"])if user_query := st.chat_input("请输入内容..."):with st.chat_message("user", avatar=user_avator):st.markdown(user_query)st.session_state.messages.append({"role": "user", "content": user_query, "avatar": user_avator})with st.chat_message("robot", avatar=robot_avator):message_placeholder = st.empty()query = input_format.replace("{{query}}",user_query)max_len = model_config['max_length']if len(query)>max_len:cur_response = f'字数超过{max_len},请调整max_length。'else:cur_response = llm_chat(model_name,model,tokenizer,model_config,query)fs.write(f'输入:{query}')fs.write('\n')fs.write(f'输出:{cur_response}')fs.write('\n')sys.stdout.flush()cur_response = f"""大模型将根据预训练时的知识回答您的问题,存在编造事实的可能性。因此以下输出仅供参考:{cur_response}"""message_placeholder.markdown(cur_response)st.session_state.messages.append({"role": "robot", "content": cur_response, "avatar": robot_avator})- 可视化界面展示

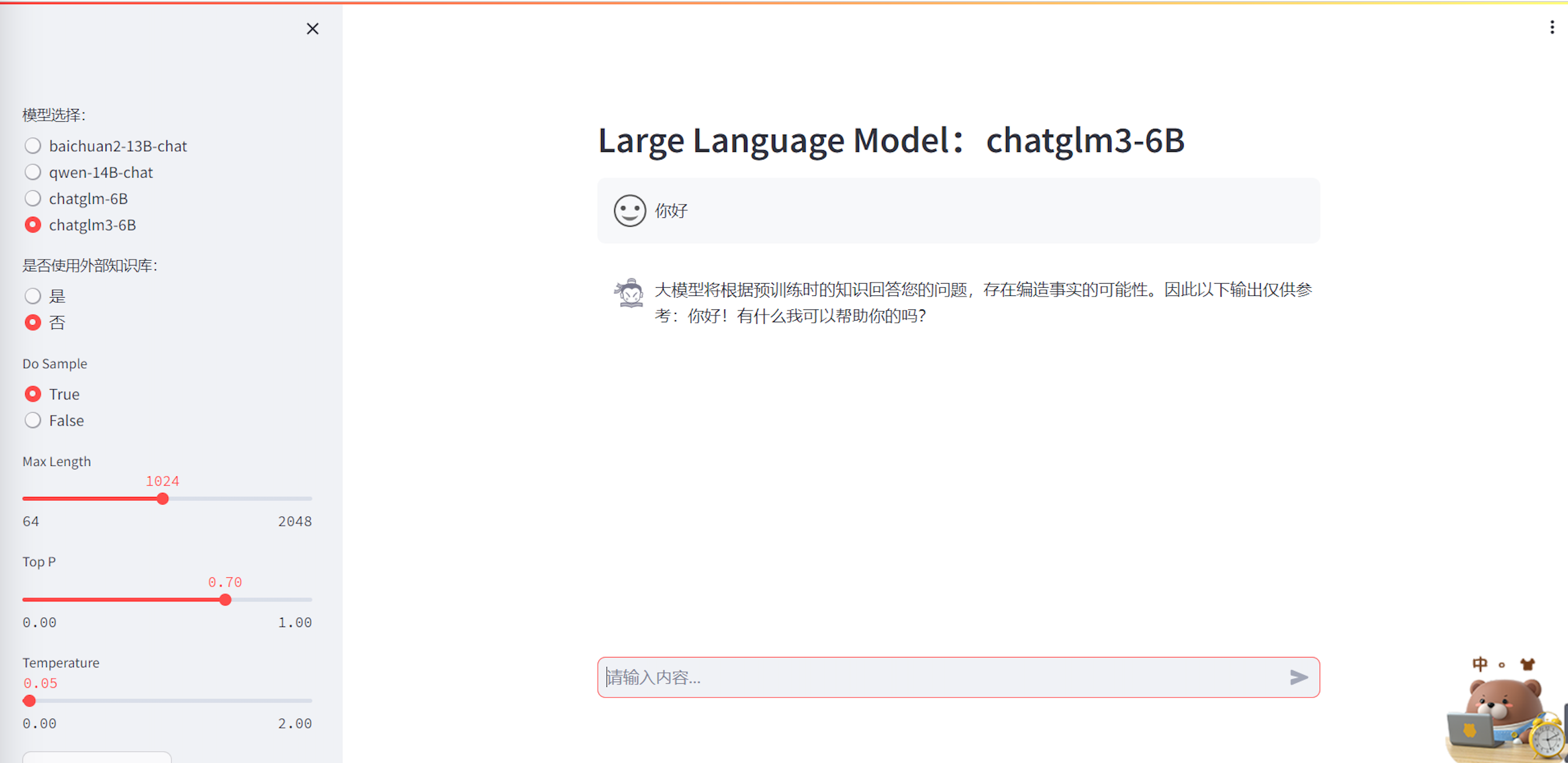
总结
Streamlit工具使用非常方便,说明文档清晰。
这个可视化界面集成了多个大模型+外部知识检索,同时可以在线调整模型参数,使用方便。
完整代码:https://github.com/hjandlm/Streamlit_LLM_QA
参考
[1] https://docs.streamlit.io/
[2] http://cw.hubwiz.com/card/c/streamlit-manual/
[3] https://github.com/hiyouga/LLaMA-Factory/tree/9093cb1a2e16d1a7fde5abdd15c2527033e33143

相关文章:
当科技遇上神器:用Streamlit定制AI可视化问答界面
Streamlit是一个开源的Python库,利用Streamlit可以快速构建机器学习应用的用户界面。 本文主要探讨如何使用Streamlit构建大模型外部知识检索的AI问答可视化界面。 我们先构建了外部知识检索接口,然后让大模型根据检索返回的结果作为上下文来回答问题。…...

毛泽东思想和中国特色社会主义理论概论平时作业四
毛泽东思想和中国特色社会主义理论概论平时作业四 1.单选题 1.1人民代表大会制度是中国人民当家作主的基本政治制度,是我国的国体。(b) a.正确 b.错误 人民代表大会制度是中国人民当家作主的根本政治制度,是我国的政体。1.2我国的政体是人民民主专政。…...
微信怎么设置自动通过好友申请?
当开展引流获客活动时,员工会在一段时间内频繁收到好友添加的申请,手动同意好友请求费时费力还容易出现漏加的情况,那么微信能自动通过好友请求吗? 如何设置快速自动通过好友申请呢? 当微信号在系统登录,…...
)
亲测解决Pytorch TypeError: object of type ‘numpy.int64‘ has no len()
这个问题是小虎在初始化自适应平均池化的时候遇到的,解决方法是限制初始化时池化大小的类型。 问题原文 Exception has occurred: TypeError object of type numpy.int64 has no len()File "D:\Complier\LEF\lib\model\segmentation\heads\modules\fgModules…...

前端模拟实现可编辑的表格table插件
在做项目中遇到了一个供货记录的功能,要求用户自己编辑添加删除表格数据,接下来我们就模拟下前端如何实现该功能 <!DOCTYPE html> <html lang"zh"><head><meta charset"UTF-8"><meta http-equiv"X-…...

PerfectPixel 插件,前端页面显示优化工具
1.简介 PerfectPixel 插件是一款适用于 Chrome 浏览器的网页前端页面显示优化工具,该插件能够帮助开发人员和标记设计人员在开发时将设计图直接加载至网页中,与已成型的网页进行重叠对比,以规范网页像素精度 作为一款可以优化前端页面显示的…...
mysql迁移data目录(Linux-Centos)
随着时间的推移,mysql的数据量越越大,使用yum默认安装的目录为系统盘 /var/lib/mysql,现重新挂载了一个硬盘,需要做数据目录的迁移到 /mnt/data/。以解决占用系统盘过高情况。 1.强烈建议这种操作。镜像一个一样的Centos系统&…...

linux-等保测评
#查看审计规则 #auditctl -l #添加审计规则 #auditctl -w /etc/passwd -p rwxa(注意:用 auditd 添加审计规则是临时的,立即生效,但是系统重启失效。) #-w path : 指定要监控的路径,上面的命令指定了监控的文…...

一、React基础知识
一、环境安装 第一种:使用原生搭建(可以从国内下载配置镜像、也可以从国外下载) 指令:1.国内下载:(1:npm config set registry https://r.npm.taobao.org// (2:npm install -g create-react-app…...

RocketMQ入门示例-生产者
大家好,本文主要是按照官网的教程把消费者和生产者的示例写下来,开箱即用。 RocketMQ安装 安装请参考官方安装教程: 快速开始 | RocketMQhttps://rocketmq.apache.org/zh/docs/quickStart/01quickstart 本人安装的是最新版本5.x,…...
2023面试知识点三
1、强软弱虚引用 强引用 当内存不足的时候,JVM开始垃圾回收,对于强引用的对象,就算是出现了OOM也不会对该对象进行回收,打死也不回收~! 强引用是我们最常见的普通对象引用,只要还有一个强引用指向一个对象…...

【hcie-cloud】【1】华为云Stack解决方案介绍、华为文档获取方式 【上】
文章目录 华为文档获取方式前言云计算发展背景国家政策、社会发展驱动数字经济开启新时代深化数字化转型提升效率,国家数字主权云进入落地阶段从Cloud-Based到Cloud-Native,两种模式长期并存适合政企智能升级的云华为云Stack,政企智能升级首选…...

JS-类型转换
...

centos7计划任务crontab
当你需要在CentOS 7上定期执行一些任务时,crontab是一个非常有用的工具。它允许你按照预定的时间表自动运行脚本或命令。 1. 查看和编辑crontab 在CentOS 7上,每个用户都有一个自己的crontab文件,用于管理其定时任务。要查看当前用户的cron…...
pycharm 断点调试python Flask
以flask框架为例,其启动命令为 python app.py runserver 后面需要拼接runserver 点击开始断点 参考:https://www.cnblogs.com/bigtreei/p/14742015.html...

Jtti:redis出现太多连接错误怎么解决
Redis出现太多连接错误通常是由于一些常见问题引起的,这些问题可能会导致连接超限、性能下降或服务不可用。以下是一些可能导致Redis连接错误的原因以及如何解决它们的建议: 1. 连接泄漏: 连接泄漏是指在使用完Redis连接后没有正确关闭它们。…...
iOS实现弹簧放大动画
效果图 实现代码 - (void)setUpContraints {CGFloat topImageCentery (SCREEN_HEIGHT - 370 * PLUS_SCALE) / 2;[self.topIconView mas_makeConstraints:^(MASConstraintMaker *make) {make.centerX.mas_equalTo(0);make.centerY.equalTo(self.view.mas_top).with.offset(t…...

③ 软件工程CMM、CMMI模型【软考中级-软件设计师 考点】
个人简介:Java领域新星创作者;阿里云技术博主、星级博主、专家博主;正在Java学习的路上摸爬滚打,记录学习的过程~ 个人主页:.29.的博客 学习社区:进去逛一逛~ ③ 软件工程CMM、CMMI模型【软考中级-软件设计…...

JumpServer开源堡垒机与万里安全数据库完成兼容性认证
近日,中国领先的开源软件提供商FIT2CLOUD飞致云宣布,JumpServer开源堡垒机已经与万里安全数据库软件GreatDB完成兼容性认证。针对产品的功能、性能、兼容性方面,经过双方共同测试,万里安全数据库软件(简称:…...

蓝桥杯每日一题2023.10.31
题目描述 全球变暖 - 蓝桥云课 (lanqiao.cn) 题目分析 果然有关连通块类的问题使用dfs都较为好写~~ 我们可以通过判断连通块的代码来加上部分条件算出被完全淹没的岛屿个数 在岛屿中如果有为"#"的a[i][j]上下左右全部是"#"则说明此岛屿一定不会被完全…...
)
【限时解密】Perplexity未公开的“诗眼定位算法”:仅0.3秒锁定《春江花月夜》中17处意象跃迁节点(内附可复现Prompt模板)
更多请点击: https://intelliparadigm.com 第一章:Perplexity诗词歌赋搜索 Perplexity 作为一款以推理深度见长的 AI 搜索工具,其在古典文学领域的检索能力尤为突出。不同于传统关键词匹配引擎,Perplexity 能够理解“孤帆远影碧空…...

论性能测试
性能测试 随着互联网应用规模化、业务场景复杂化,系统在高并发、大数据量场景下的性能表现直接影响用户体验与业务连续性一一 响应延迟、并发处理能力不足、资源耗尽等问题可能导致用户流失或重大业务损失。性能测试作为软件质量保障的核心环节,通过模拟…...

小白程序员必备:从零基础到大模型实战,这份学习路线图请收藏!
本文结合530名开发者的经验,为AI初学者提供从零基础到项目实战的完整学习路线。核心内容包括:Python编程、数学基础、机器学习、深度学习框架(PyTorch)、科学计算库(NumPy)等关键技能,并避开了常…...
/α-萘酚温敏水凝胶,ZnPc/α-Naphthol)
负载锌酞菁(ZnPc)/α-萘酚温敏水凝胶,ZnPc/α-Naphthol
名称:负载锌酞菁(ZnPc)/α-萘酚温敏水凝胶,ZnPc/α-Naphthol 一、材料概览:双重功能的精妙融合 负载锌酞菁(ZnPc)/α-萘酚温敏水凝胶,是将具有优异光催化活性的锌酞菁(Zn…...

VirtualBox虚拟机里Win10远程桌面黑屏?手把手教你改组策略搞定它
VirtualBox虚拟机Win10远程桌面黑屏终极解决方案:从策略组到网络优化的全链路排查 当你正沉浸在VirtualBox虚拟机的Windows 10环境中进行关键开发工作,突然发现远程桌面连接后只剩一片漆黑——这种体验就像在重要会议前突然失声。不同于物理机的远程连接…...

Android 相机有线连接开发复盘:PTP/MTP 协议适配与稳定性实践
一、项目背景在做一个相机互联类 App 的过程中,我们需要在 Android 设备上通过 USB 有线方式 连接相机,实现:遥控拍摄实时获取照片稳定地进行文件同步最初评估时以为只要调用系统 API 就能跑起来,但实际开发中发现,标…...

利用Taotoken多模型能力为内容生成平台提供弹性AI服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken多模型能力为内容生成平台提供弹性AI服务 应用场景类,设想一个内容生成平台需要根据任务复杂度选择不同能…...
)
小米手机解锁BL保姆级教程:无需社区5级,用PHP脚本绕过HyperOS限制(附常见错误码解决)
小米手机解锁BL实战指南:突破HyperOS限制的完整方案 手里的小米13升级到HyperOS后,解锁Bootloader突然变得遥不可及?社区等级5和答题门槛让不少技术爱好者望而却步。本文将带你深入探索一种巧妙的技术方案,无需满足小米社区的苛刻…...

从VOC到YOLO:用Labelimg标注后,一键转换数据格式的完整避坑指南
从VOC到YOLO:数据格式转换的工程化实践与避坑指南 当你用Labelimg完成目标检测任务的标注工作,看着满屏的XML文件,是否觉得离模型训练还差"最后一公里"?这恰恰是许多初学者从标注到训练的关键断裂点。本文将带你深入VOC…...

Vivado编译加速:Jobs与Threads参数配置实战指南
1. 项目概述:从一次编译卡顿说起那天下午,我正在赶一个FPGA项目的最后集成,Vivado里点下“Run Implementation”,进度条就像被冻住了一样,半天不动。电脑风扇倒是转得挺欢,可CPU占用率看着也就50%上下。我第…...