2022最新版-李宏毅机器学习深度学习课程-P32 Transformer
一、 seq2seq
1. 含义
输入一个序列,机器输出另一个序列,输出序列长度由机器决定。
- 文本翻译:文本至文本;
- 语音识别:语音至文本;
- 语音合成:文本至语音;
- 聊天机器人:语音至语音。
2. 应用
自然语言处理(NLP问题),不过seq2seq有时候不一定是最佳的解决方法。
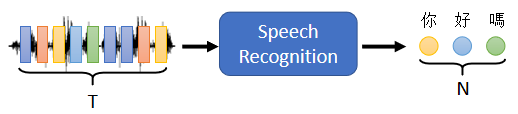
语音辨识
输入是声音讯号的一串的vector,输出是语音辨识的结果,也就是输出的这段声音讯号,所对应的文字⇒输出的长度由机器自己决定
机器翻译
机器读一个语言的句子,输出另外一个语言的句子,
输入的文字的长度是N,输出的句子的长度是N',那N跟N'之间的关系,也要由机器自己来决定

语音翻译

把他听到的英文的声音讯号翻译成中文文字
(动机:世界上有很多语言,他根本连文字都没有,不能用1.+2.串接)
训练数据:乡土剧语音+字幕
新词:硬train一发
语音合成Text-to-Speech (TTS) Synthesis
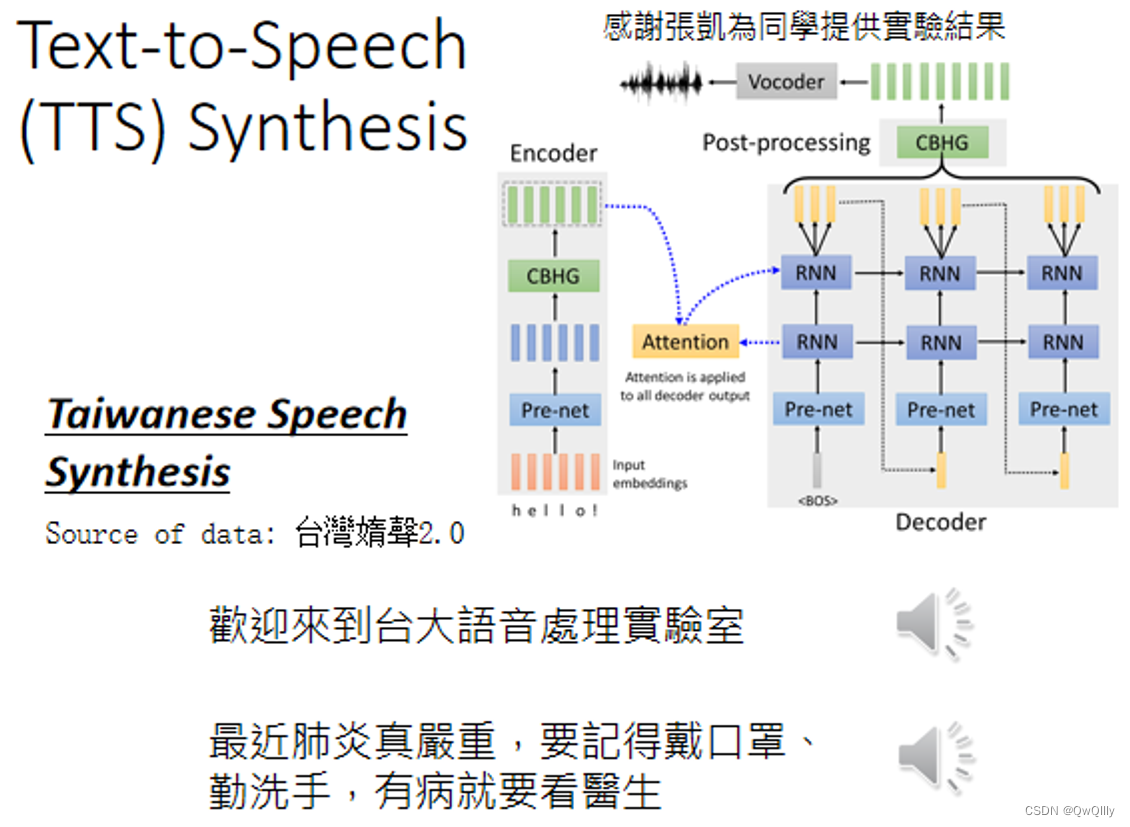
输入文字 输出声音讯号
Chatbot
输入输出都是文字
利用人的对话进行训练
Question Answering (QA)
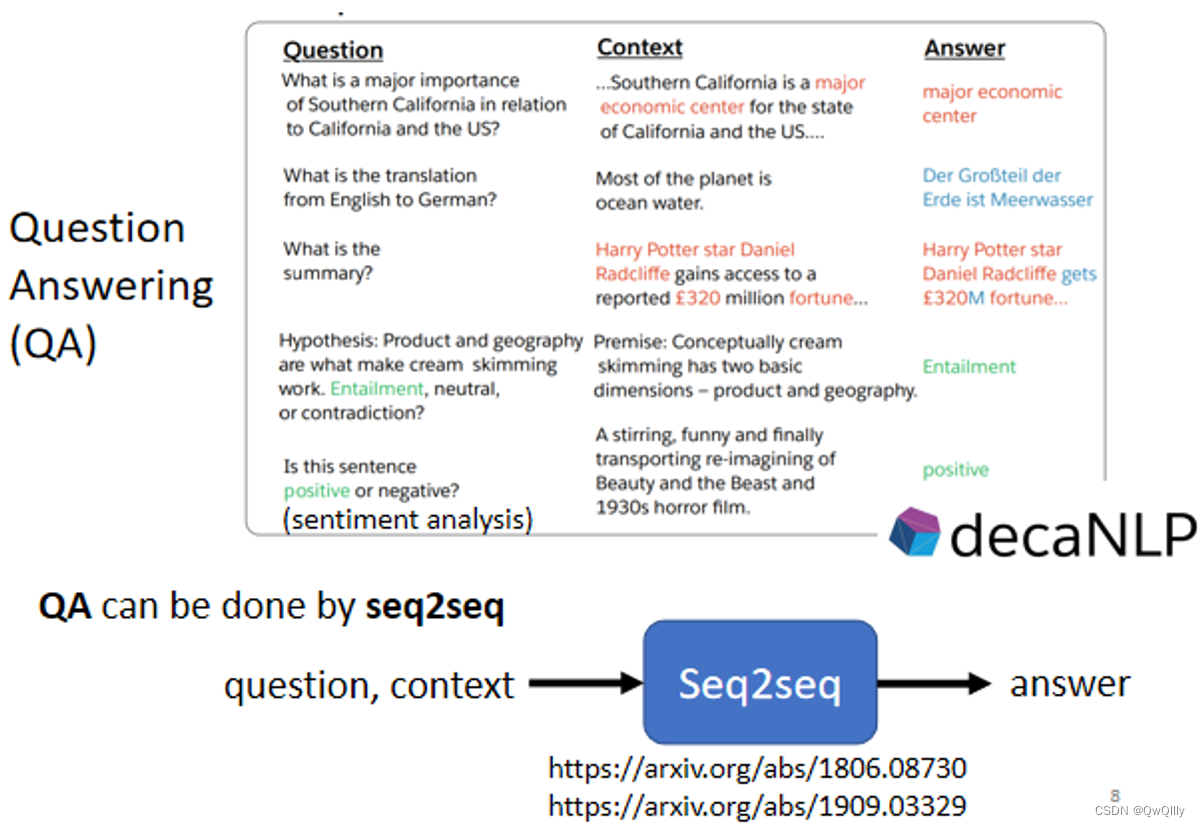
很多natural language processing的任务,都可以想成是question answering,QA的任务。QA的问题,就可以用Seq2Seq model来解
⇒具体来说,Seq2Seq model输入的就是有问题跟文章把它接在一起,输出就是问题的答案
⇒输入一个文字序列→输出一个文字序列
- 翻译
- 摘要
- 情感分析
▶️对多数NLP的任务,或对多数的语音相关的任务而言,往往為这些任务特制化模型,你会得到更好的结果
https://speech.ee.ntu.edu.tw/~hylee/dlhlp/2020-spring.html
Syntactic Parsing句法分析(文法剖析)
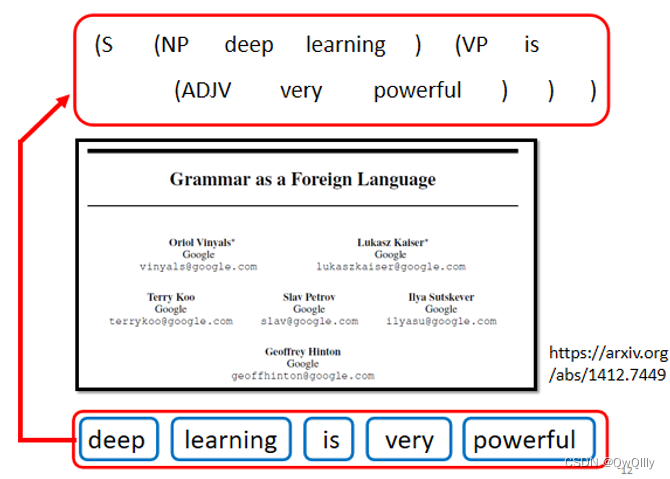
grammar as a Foreign Language
例如,给机器一段文字,Deep learning is very powerful,机器要做的事情是产生一个文法的剖析树 。
输出结果(剖析树)告诉我们,deep 加 learning 合起来是一个名词短语,very 加 powerful 合起来是一个形容词短语,形容词短语加 is 以后会变成一个动词短语,动词短语加名词片语合起来是一个句子
文法剖析要做的事情就是产生这样子的一个 Syntactic tree,所以在用 deep learning 解决 文法剖析的任务里面,输入是一段文字(一个Sequence),输出是一个树状的结构,(可以把他看作是一个Sequence,一个代表句法分析树的序列)

multi-label classification
(多标签分类问题:同一个对象可以属于多个class
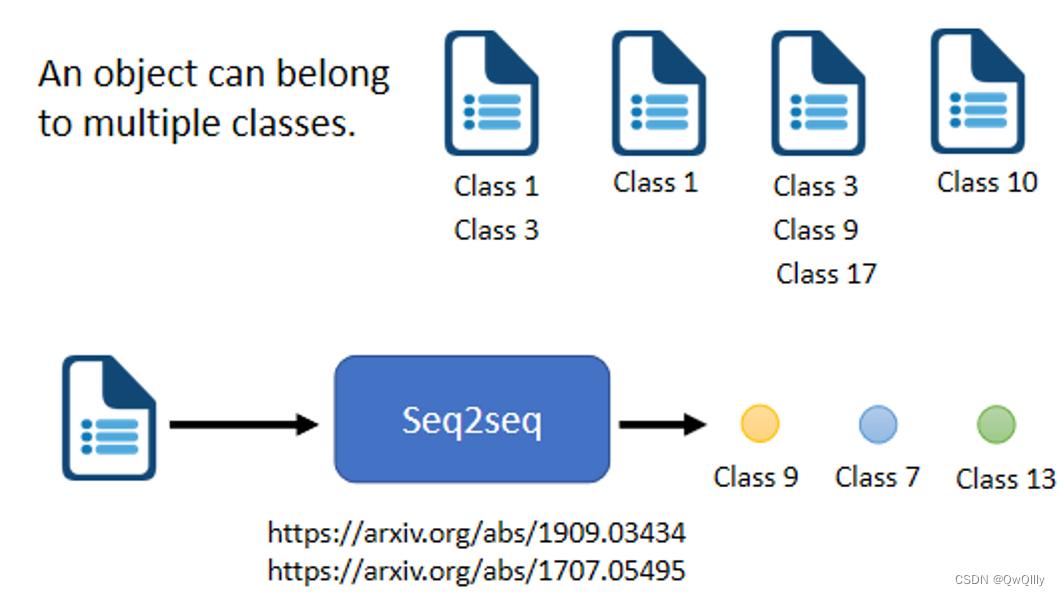
区分:
- multi-class classification:为样本从数个 class 中选择某一个 class(多对一)
- multi-label classification:同一个样本可以属于多个 class (一对多)
难点:每篇文章对应几个 class 不好确定 ⇒ seq2seq 决定要输出几个
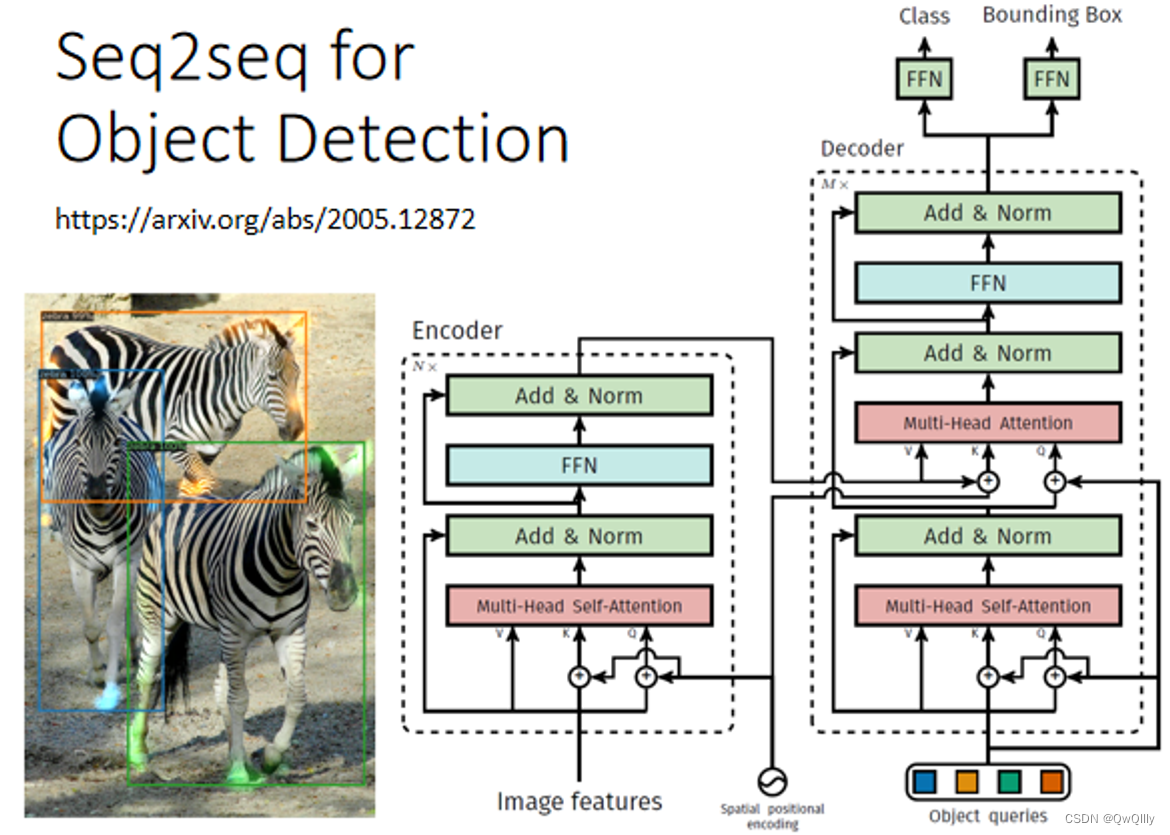
Object Detection 物体检测
图像识别领域
3. Seq2seq 实现方式
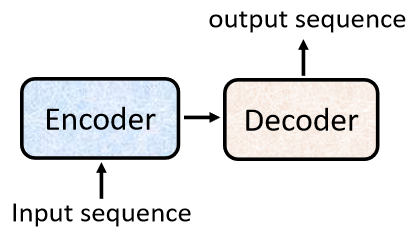
seq2seq's model = Encoder(编码器) + Decoder(解码器)
这两部分可以使用RNN或transformer实现,seq2seq主要是为了解决输入和输出长度不确定的情况。
Encoder:将输入(文字、语音、视频等)编码为单个向量,这个向量可以看成是全部输入的 抽象表示。
Decoder:接受 encoder 输出的向量,逐步解码,一次输出一个结果,每次输出会影响下一次的输出,开头加入 <BOS> 表示开始解码, <EOS> 表示输出结束。
① Encoder
用途:输入一排向量(序列),输出另外一排同样长度的向量(序列)
可以使用:Self-attention,RNN,CNN
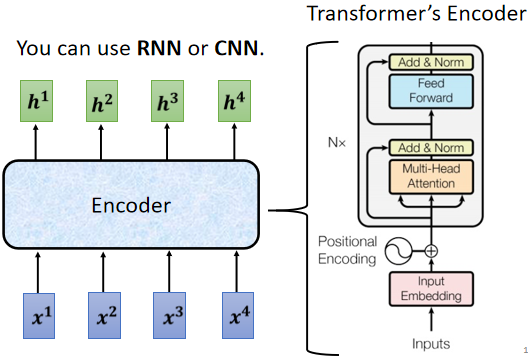
A、encoder 就是通过多层 block(模块),将输入转换成向量。每一个 block 都包含若干层( self-attention 和 fully connect 等网络结构 ),每个 block 输入一排向量,输出相同数量的一排向量。

B、block 的内部细节构成如下(在 input 送入 block 之前,需先进行 positional encoding,这个知识点在 self - attention 中有提过)。

C 、 它考虑所有输入向量后的输出向量,其中 b 是原来的 input 向量,经过残差网络(residual connection:把 a vector 加上它的 b input vector 作为 output )和标准化后,送到全连接神经网络 FC ,由于在 FC network 中也有 residual 的架构,因此需要再经过一组 残差网络 + 标准化 后得到输出。(注意:这里的标准化是 layer normalization 而不是 batch normalization)。这个输出才是 residual network 里一个 block 的输出。
batch normalization:对 不同的 example 不同 feature 的 同一个 dimention 去计算平均值 mean 和标准差 standard deviation。
layer normalization:对 同一个 example 同一个 feature的 不同 dimention 去计算平均值 mean 和标准差 standard deviation。

To Learn more
1.transformer的encoder变式
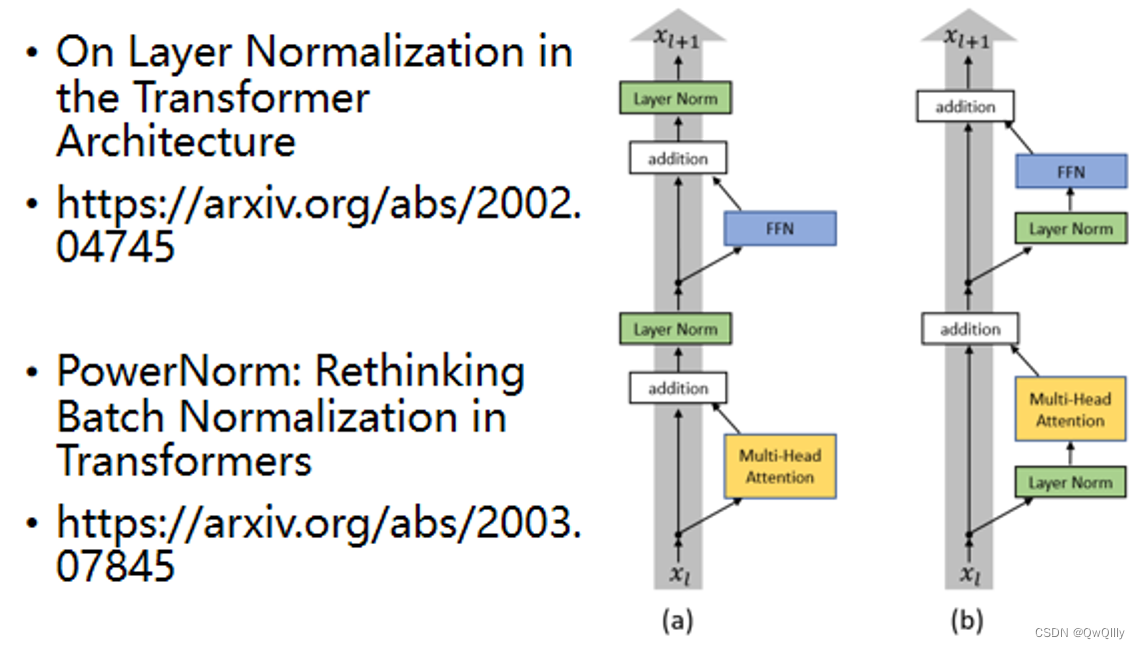
如:Residual与Normalization的顺序调换
2.为什么是layer Norm:Power Norm
Power Norm:Rethinking Batch Normalization In Transformers,
https://arxiv.org/abs/2003.07845
② Decoder
decoder主要有两种:AT(autoregressive)与 NAT(non-autoregressive),Decoder 要做的事情:产生最终的输出结果
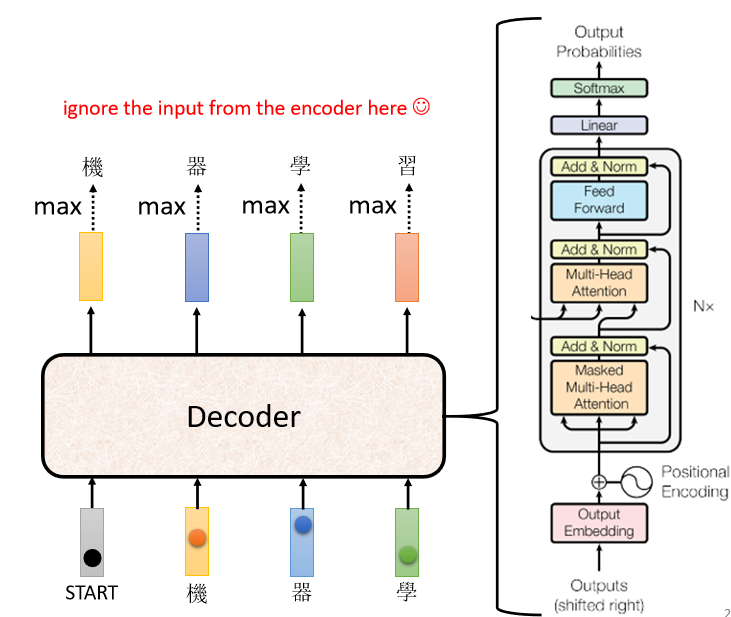
A、autoregressive(AT)decoder :以语音辨识为例

1. 向 Decoder 输入 Encoder 产生的向量
2. 在 Decoder 可能产生的文字库里多加一个标识字符 BEGIN ,它代表 “ Decoder 开始识别” 来提醒机器(BOS: begin of sentence)
NLP 的问题中,每一个 Token 用一个 One-Hot 的 Vector 来表示,其中正确的类别标识是 1,其他都是 0,其中 BEGIN 也是用 One-Hot Vector 来表示
3. 经过 softmax 之后,Decoder 会输出一个和 输入的 Vocabulary Size 一样的向量长度的 向量结果。对比已知文字库,找到相似度最高的字符就是最终输出的字符。(这里“机”字 就是这个 Decoder 的第一个输出)
Vocabulary Size:取决于你输出的单位。比如输出中文,则size是中文方块字的数目。
4. 再把上一步的输出当做下一个的输入。(在本例中,第二次 Decoder 把 “机” 当做是 Decoder 的 Input,在上一步 “机” 是 Decoder 的输出结果)经过一系列相同的操作后我们会得到第二次 Decoder 的输出,再作为第三次的输入,继续输出后续的文字,以此类推……
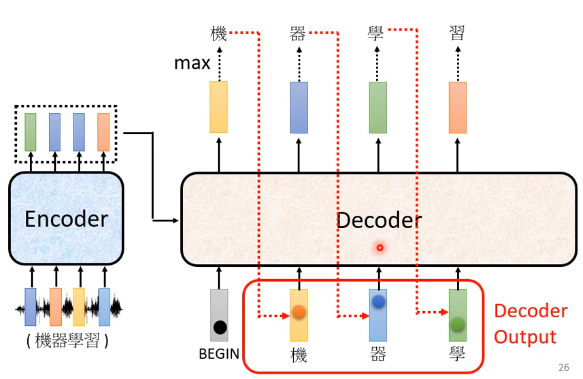
5. 机器自己决定输出的长度:一个特别的标识符 ”END” 代表工作结束
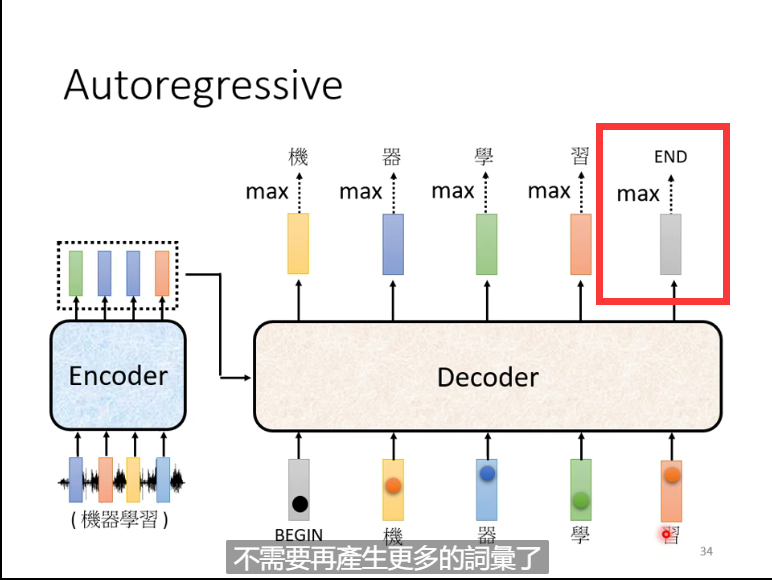
总结: 除了中间的部分,Encoder 跟 Decoder 并没有太大的差别。最后我们可以再做一个 Softmax,可以通过计算输出的概率分布与 Ground Truth 之间的 交叉熵(Cross Entropy)并求梯度实现优化,交叉熵的值越小越好。
缺点:如果Decoder 看到错误的输入,让 Decoder 产生错误的输出并被代入到下一步 Decoder 工作的输入中,会会造成 Error Propagation(一步错,步步错)⇒ 解决:Teacher Forcing技术 (但是测试的时候 显然没有正确答案可以给 Decoder 看)
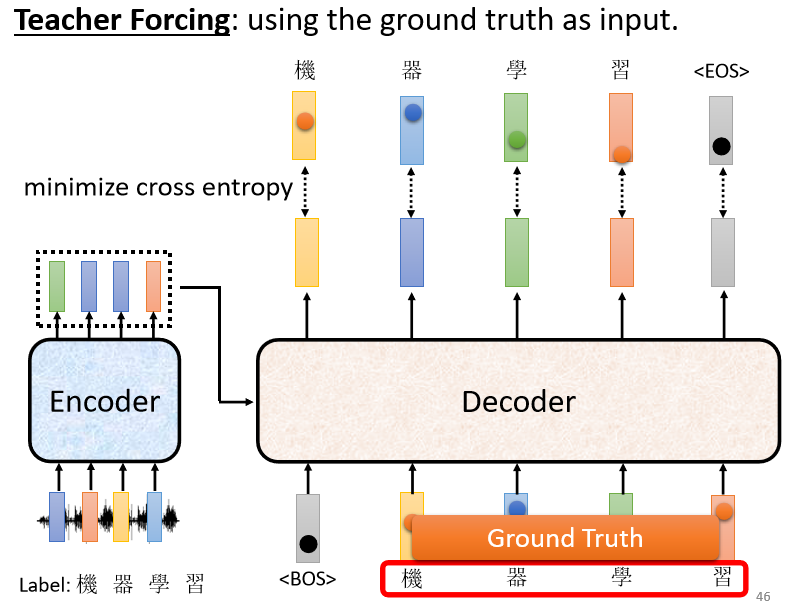
由于 Teacher Forcing的存在,训练跟测试的情景不一致。Decoder 在训练的时候永远只看过正确的东西,但是在测试的时候,仍然会导致一步错、步步错。
解决:给 Decoder 的输入加一些错误的东西 ⇒ Scheduled Sampling(但是也会一定程度损害平行化的能力)

B、Non-autoregressive (NAT) decoder
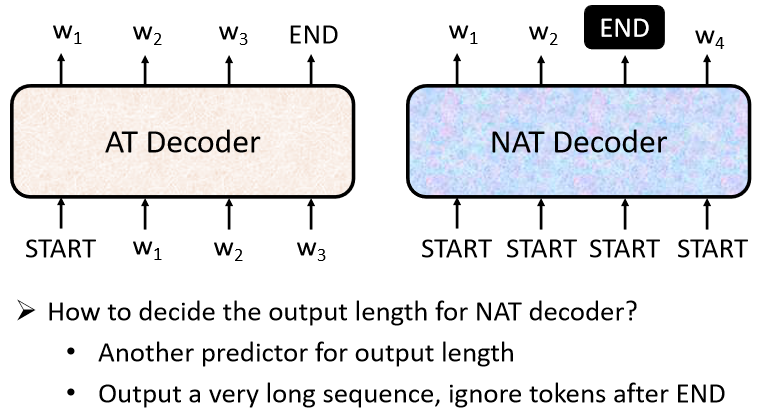
① 特点:NAT 不是依次有序进行 decoder 工作并挨个输出,而是一次性在输入时赋予 整个句子 一整排的 “ BEGIN ” 标识,把整个句子的 decoder 结果一次性都输出
② 思路:如何确定BEGIN的个数:
- 另外训练一个 Classifier,输入 Encoder 的 Input vector,输出是一个数字(代表 Decoder 应该要输出的长度)
- 给它若干个 BEGIN 的 Token,比如输出句子的最大长度不超过 300,就给 input 300 个 BEGIN token,然后就会相应地一次性输出 300 个字(遇到有输出 END 时表示这个句子输出结束),但是可能会比较耗费内存空间
③ 好处:
- 并行化。NAT 的 Decoder 不管 input 句子的长度大小,都是一次性输出完整的句子结果,所以在执行速度上 NAT 的 Decoder 比 AT 的 Decoder 要快
- 容易控制输出长度。
④ 应用:
常用在语音合成,例如:利用其中一个 决定 NAT 的 Decoder 应该输出的长度的 Classifier,我们可以通过设置这个输出长度的大小以调整语音的速度。(如果要让输出的语音讲快一点,就把 Classifier 输出的长度数值 除以 N,它讲话速度就变成 N 倍速;同理,如果想要合成的语音变为慢速,就把 Classifier 输出的长度数值乘 N 倍)
⑤ 缺点:虽然 NAT 看起来有很多优点(尤其是并行化),但是 NAT 的 Decoder 实际上 Performance 往往都不如 AT 的 Decoder。为什么NAT 没有 AT 实际效果好 ⇒ Multi-Modality 参考链接
相关文章:
2022最新版-李宏毅机器学习深度学习课程-P32 Transformer
一、 seq2seq 1. 含义 输入一个序列,机器输出另一个序列,输出序列长度由机器决定。 文本翻译:文本至文本; 语音识别:语音至文本; 语音合成:文本至语音; 聊天机器人&#…...

如何使用商品详情API接口获取商品数据:一篇详尽的论述
一、引言 商品详情API接口是一种用于获取商品详细信息的应用程序接口。通过调用该接口,我们可以获取商品的名称、价格、描述、图片以及其他相关属性。对于电商平台、价格比较网站、数据分析等应用场景来说,商品详情API接口提供了便捷的数据获取方式。本…...

华为:手机王者归来,汽车起死回生
作为一家全球知名的科技公司,华为在通信、智能手机、平板电脑等领域拥有很高的市场份额和品牌影响力。而随着华为开始进军汽车领域,通过自主研发和合作,不断提升自己在汽车领域的竞争力,华为便也开始受到更为广泛的关注。 只不过…...

Vue3.0 provide与inject依赖注入:VCA
简介 provide 与 inject 是一种跨层级组件(祖孙)通信方式。当组件多层嵌套时,不需要将数据一层一层的向下传递,通过它俩可以实现跨层级组件通信。 provide:提供者 注入一个值,可以被后代组件接收。 prov…...

前端react入门day02-React中的事件绑定与组件
(创作不易,感谢有你,你的支持,就是我前行的最大动力,如果看完对你有帮助,请留下您的足迹) 目录 React中的事件绑定 React 基础事件绑定 使用事件对象参数 传递自定义参数 同时传递事件对象和自定义参…...

工业5G路由器;小体积 千兆高速通信组网
计讯物联工业路由器TR232,5G高速网络,超低时延、高可靠性,小体积、易安装、强兼容,串口/网口多设备接入联网,为用户提供高速稳定的数据传输通道 。 小体积5G工业路由器TR323,外形1047824mm࿰…...
【深度学习基础】从R-CNN到Fast R-CNN,再到MaskR-CNN,发展历程讲清楚!
📢:如果你也对机器人、人工智能感兴趣,看来我们志同道合✨ 📢:不妨浏览一下我的博客主页【https://blog.csdn.net/weixin_51244852】 📢:文章若有幸对你有帮助,可点赞 👍…...
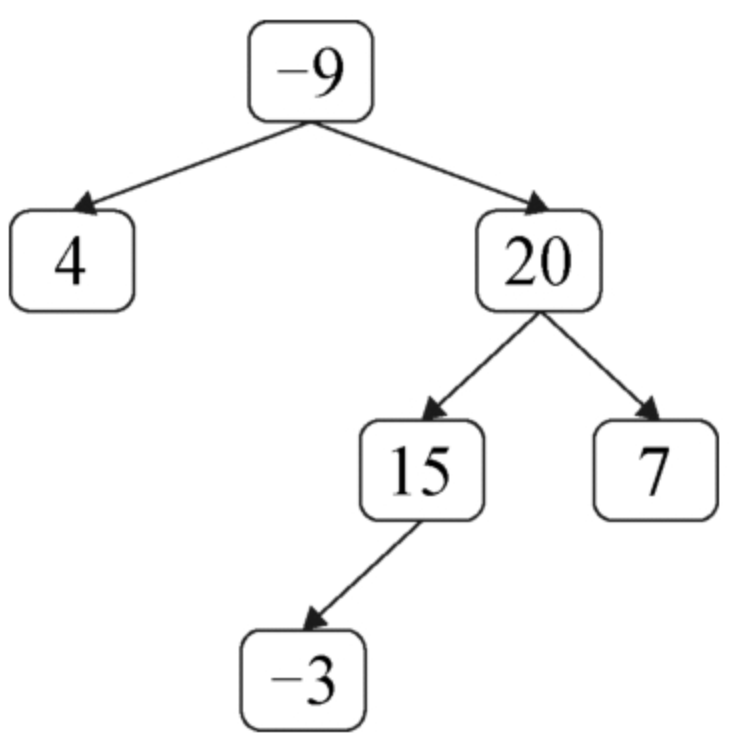
面试算法51:节点值之和最大的路径
题目 在二叉树中将路径定义为顺着节点之间的连接从任意一个节点开始到达任意一个节点所经过的所有节点。路径中至少包含一个节点,不一定经过二叉树的根节点,也不一定经过叶节点。给定非空的一棵二叉树,请求出二叉树所有路径上节点值之和的最…...

阿里云 k8s 容器服务 设置节点为不可调度的两种方法有什么区别?
两种方法的区别在于:drain 会驱逐原来节点上的所有 pod,而 cordon 只是停止调度, 禁止新的 pod 调度进来,但旧的 pod 不会受影响。...

新一代数据质量平台datavines
在我实习的第一家公司的时候,有幸参与Apache Griffin的开发,也先后在一起其他公司使用过数据质量平台,同时也调研过一些开源的数据质量平台。 最近和朋友一起参与开发了datavines数据质量平台,随着在数据行业越呆越久,…...

建议收藏《2023华为海思实习笔试-数字芯片真题+解析》(附下载)
华为海思一直以来是从业者想要进入的热门公司。但是岗位就那么多,在面试的时候,很多同学因为准备不充分,与岗位失之交臂,无缘进入该公司。今天为大家带来《2023华为海思实习笔试-数字芯片真题解析》题目来源于众多网友对笔试的记录…...

【详细教程】关于如何使用GitGitHub的基本操作汇总GitHub的密钥配置 ->(个人学习记录笔记)
文章目录 1. Git使用篇1.1 下载安装Git1.2 使用Git 2. GitHub使用篇2.1 如何git与GitHub建立联系呢?2.2 配置公钥 1. Git使用篇 1.1 下载安装Git 点击 官网链接 后,进入Git官网,下载安装包 然后根据系统类型进行下载,一般为wind…...
HTML样式CSS、图像
HTML样式-CSS: CSS (Cascading Style Sheets) 用于渲染HTML元素标签的样式。CSS可以通过以下方式添加到HTML中:1)、内联方式:在HTML元素中使用“style”属性;2)、内部样式表:在HTML文档头部<head>区…...

智能电表瞬时电量是什么意思?
智能电表已经成为我们进行能源管理的重要工具。其中,瞬时电量这一概念逐渐走进大众视野。那么,智能电表瞬时电量究竟是什么意思?它对我们的生活和能源管理又有哪些影响呢?下面,小编就来为大家介绍一下瞬时电量…...

Redis之 redis.config配置文件
文章目录 前言一、基本配置1.单位2.包含3.网络配置4.通用5.快照6.安全7.限制8.仅追加模式 二、总体主要介绍总结 前言 行家一出手,就知有没有,让一起学习redis.config配置文件。 一、基本配置 Redis 的配置文件位于 Redis 安装目录下,文件名…...

BIOS开发笔记 - CMOS
CMOS原来指的是一种生产电子电路的工艺,在PC上一般指的是RTC电路单元,因为早期它是由这种工艺生产出来的,所以又把RTC称作了CMOS。 RTC(Real Time Clock)即实时时钟,用于保存记录时间和日期,也可以用来做定时开机功能。RTC靠一组独立的电源给它供电,这样设计的目的就是…...

leetcode_117 填充每个节点的下一个右侧节点指针 II
文章目录 1. 题意2. 题解2.1 BFS2.2 BFS空间优化2.3 DFS序层次记录 3. Ref 1. 题意 在一颗树的同层之间用指针把他们链接起来。 填充每个节点的下一个右侧节点指针 II 2. 题解 2.1 BFS 用一个变量记录下同层最右侧的节点,当遍历到时更新下一层的最右侧节点即可…...
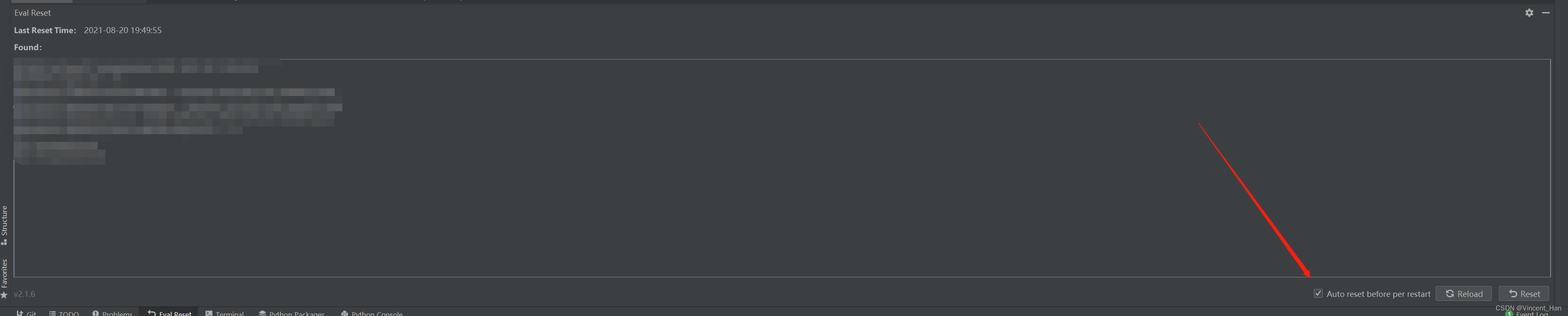
亲测 IDEA Pycharm 全家桶 自动重置免费30天
理论上是通用的 插件市场安装 添加第三方插件仓库地址 在Settings/Preferences... -> Plugins 内手动添加第三方插件仓库地址:https://plugins.zhile.io 搜索:IDE Eval Reset插件进行安装。如果搜索不到请注意是否做好了上一步?网络是否…...

Marp: 将 Markdown 变为 PPT 式样的 VScode 插件
样例代码: --- marp: true size: 16:9 theme: default header: footer: --- <!-- _footer: Jia ming<br>Gansu University of Political Science and Law --> <!-- _backgroundColor: lightskyblue --> ## <!-- fit --> 笔记检验概述>…...

根据正则表达式截取字串符,这个办法打败99%程序员
作为一名程序员,常常会在以下情况下使用函数功能根据正则表达式截取字符串: 1.字符串处理:当需要使用正则表达式匹配和提取字符串中的特定模式时,可以使用该函数。例如,从一段文本中提取电子邮件地址、电话号码或网站…...

PHP主流框架
PHP主流框架概述 PHP作为广泛使用的服务器端脚本语言,拥有多个成熟的开发框架,适用于不同规模和类型的项目。以下是当前主流的PHP框架及其特点: Laravel Laravel是目前最流行的PHP框架之一,以其优雅的语法和丰富的功能著称。它提供了强大的路由系统、ORM(Eloquent)、模…...

Windows 和 Ubuntu 安装 Hermes Agent 全攻略
文章目录【开场白】【先说重点:Hermes 和 OpenClaw 装机区别】【Windows 安装:5 步搞定】第 1 步:装 WSL2第 2 步:更新 Ubuntu 系统第 3 步:一键装 Hermes第 4 步:让环境变量生效第 5 步:初始化…...

还在为百度网盘Mac版龟速下载烦恼?3分钟破解SVIP限制,速度提升70倍!
还在为百度网盘Mac版龟速下载烦恼?3分钟破解SVIP限制,速度提升70倍! 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS …...

Zynq开发中XSA文件更新全流程:从硬件修改到软件调试
1. 项目概述:为什么需要更新XSA文件?在基于Xilinx Zynq系列SoC的开发流程里,XSA文件(Xilinx Support Archive)是一个承上启下的核心枢纽。它本质上是一个压缩包,里面封装了硬件平台(Hardware Pl…...

提前两小时,救一条命——从约翰·霍普金斯AI败血症预警系统看AI医疗的工程化之路
2026年5月12日,美国食品药品监督管理局(FDA)批准了一款来自约翰霍普金斯大学、由Bayesian Health商业化的AI败血症早期预警系统——Targeted Real-Time Early Warning System(以下简称TRWS)。这是FDA批准的首个持续监测…...

为GitHub开源项目配置统一的大模型调用与成本管控方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为GitHub开源项目配置统一的大模型调用与成本管控方案 对于开源项目的维护者而言,为项目集成AI能力正变得越来越普遍。…...

小红书无水印下载工具XHS-Downloader:3分钟掌握高效内容保存技巧
小红书无水印下载工具XHS-Downloader:3分钟掌握高效内容保存技巧 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用…...

华为鸿蒙与欧拉操作系统:全场景战略下的技术架构与生态构建
1. 从“备胎”到“主干”:华为操作系统的战略突围之路 最近科技圈里关于华为的消息,大家讨论得最多的,除了孟晚舟女士的归国,可能就是华为在软件领域接连放出的几个“大招”了。作为一名在ICT行业摸爬滚打了十几年的老兵ÿ…...

六月学术盛宴启幕 | 2026年6月国际学术会议重磅来袭
2026年6月学术会议列表 | 会议亮点总结 顶尖大咖云集:学界领军人物、资深学者倾情助阵,汇聚全球科研力量现场分享前沿成果 顶尖院校强力赋能:北航、桂林电子科技大学、南方科技大学、华南理工大学等众多名校联合组织 正规出版渠道 & 高…...

FF14副本动画跳过插件终极指南:3分钟告别冗长等待
FF14副本动画跳过插件终极指南:3分钟告别冗长等待 【免费下载链接】FFXIV_ACT_CutsceneSkip 项目地址: https://gitcode.com/gh_mirrors/ff/FFXIV_ACT_CutsceneSkip 你是否曾在《最终幻想14》国服副本中,看着那些无法跳过的动画感到无比焦虑&…...