一文全览各种 ES 查询在 Java 中的实现

2 词条查询
所谓词条查询,也就是ES不会对查询条件进行分词处理,只有当词条和查询字符串完全匹配时,才会被查询到。
2.1 等值查询-term
等值查询,即筛选出一个字段等于特定值的所有记录。
SQL:
select * from person where name = '张无忌';
而使用ES查询语句却很不一样(注意查询字段带上keyword):
GET /person/_search
{
"query": {
"term": {
"name.keyword": {
"value": "张无忌",
"boost": 1.0
}
}
}
}
ElasticSearch 5.0以后,string类型有重大变更,移除了string类型,string字段被拆分成两种新的数据类型: text用于全文搜索的,而keyword用于关键词搜索。
查询结果:
{
"took" : 0,
"timed_out" : false,
"_shards" : { // 分片信息
"total" : 1, // 总计分片数
"successful" : 1, // 查询成功的分片数
"skipped" : 0, // 跳过查询的分片数
"failed" : 0 // 查询失败的分片数
},
"hits" : { // 命中结果
"total" : {
"value" : 1, // 数量
"relation" : "eq" // 关系:等于
},
"max_score" : 2.8526313, // 最高分数
"hits" : [
{
"_index" : "person", // 索引
"_type" : "_doc", // 类型
"_id" : "1",
"_score" : 2.8526313,
"_source" : {
"address" : "光明顶",
"modifyTime" : "2021-06-29 16:48:56",
"createTime" : "2021-05-14 16:50:33",
"sect" : "明教",
"sex" : "男",
"skill" : "九阳神功",
"name" : "张无忌",
"id" : 1,
"power" : 99,
"age" : 18
}
}
]
}
}
Java 中构造 ES 请求的方式:(后续例子中只保留 SearchSourceBuilder 的构建语句)
/**
* term精确查询
*
* @throws IOException
*/
@Autowired
private RestHighLevelClient client;
@Test
public void queryTerm() throws IOException {
// 根据索引创建查询请求
SearchRequest searchRequest = new SearchRequest("person");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询语句
searchSourceBuilder.query(QueryBuilders.termQuery("name.keyword", "张无忌"));
System.out.println("searchSourceBuilder=====================" + searchSourceBuilder);
searchRequest.source(searchSourceBuilder);
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSONObject.toJSON(response));
}
仔细观察查询结果,会发现ES查询结果中会带有_score这一项,ES会根据结果匹配程度进行评分。打分是会耗费性能的,如果确认自己的查询不需要评分,就设置查询语句关闭评分:
GET /person/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"sect.keyword": {
"value": "张无忌",
"boost": 1.0
}
}
},
"boost": 1.0
}
}
}
Java构建查询语句:
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 这样构造的查询条件,将不进行score计算,从而提高查询效率
searchSourceBuilder.query(QueryBuilders.constantScoreQuery(QueryBuilders.termQuery("sect.keyword", "明教")));
2.2 多值查询-terms
多条件查询类似 Mysql 里的IN 查询,例如:
select * from persons where sect in('明教','武当派');
ES查询语句:
GET /person/_search
{
"query": {
"terms": {
"sect.keyword": [
"明教",
"武当派"
],
"boost": 1.0
}
}
}
Java 实现:
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询语句
searchSourceBuilder.query(QueryBuilders.termsQuery("sect.keyword", Arrays.asList("明教", "武当派")));
}
2.3 范围查询-range
范围查询,即查询某字段在特定区间的记录。
SQL:
select * from pesons where age between 18 and 22;
ES查询语句:
GET /person/_search
{
"query": {
"range": {
"age": {
"from": 10,
"to": 20,
"include_lower": true,
"include_upper": true,
"boost": 1.0
}
}
}
Java构建查询条件:
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询语句
searchSourceBuilder.query(QueryBuilders.rangeQuery("age").gte(10).lte(30));
}
2.4 前缀查询-prefix
前缀查询类似于SQL中的模糊查询。
SQL:
select * from persons where sect like '武当%';
ES查询语句:
{
"query": {
"prefix": {
"sect.keyword": {
"value": "武当",
"boost": 1.0
}
}
}
}
Java构建查询条件:
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询语句
searchSourceBuilder.query(QueryBuilders.prefixQuery("sect.keyword","武当"));
}
2.5 通配符查询-wildcard
通配符查询,与前缀查询类似,都属于模糊查询的范畴,但通配符显然功能更强。
SQL:
select * from persons where name like '张%忌';
ES查询语句:
{
"query": {
"wildcard": {
"sect.keyword": {
"wildcard": "张*忌",
"boost": 1.0
}
}
}
}
Java构建查询条件:
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询语句
searchSourceBuilder.query(QueryBuilders.wildcardQuery("sect.keyword","张*忌"));
03 负责查询
前面的例子都是单个条件查询,在实际应用中,我们很有可能会过滤多个值或字段。先看一个简单的例子:
select * from persons where sex = '女' and sect = '明教';
这样的多条件等值查询,就要借用到组合过滤器了,其查询语句是:
{
"query": {
"bool": {
"must": [
{
"term": {
"sex": {
"value": "女",
"boost": 1.0
}
}
},
{
"term": {
"sect.keywords": {
"value": "明教",
"boost": 1.0
}
}
}
],
"adjust_pure_negative": true,
"boost": 1.0
}
}
}
Java构造查询语句:
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询语句
searchSourceBuilder.query(QueryBuilders.boolQuery()
.must(QueryBuilders.termQuery("sex", "女"))
.must(QueryBuilders.termQuery("sect.keyword", "明教"))
);
3.1 布尔查询
布尔过滤器(bool filter)属于复合过滤器(compound filter)的一种 ,可以接受多个其他过滤器作为参数,并将这些过滤器结合成各式各样的布尔(逻辑)组合。
bool 过滤器下可以有4种子条件,可以任选其中任意一个或多个。filter是比较特殊的,这里先不说。
{
"bool" : {
"must" : [],
"should" : [],
"must_not" : [],
}
}
must:所有的语句都必须匹配,与 ‘=’ 等价。
must_not:所有的语句都不能匹配,与 ‘!=’ 或 not in 等价。
should:至少有n个语句要匹配,n由参数控制。
精度控制:
所有 must 语句必须匹配,所有 must_not 语句都必须不匹配,但有多少 should 语句应该匹配呢?默认情况下,没有 should 语句是必须匹配的,只有一个例外:那就是当没有 must 语句的时候,至少有一个 should 语句必须匹配。
我们可以通过 minimum_should_match 参数控制需要匹配的 should 语句的数量,它既可以是一个绝对的数字,又可以是个百分比:
GET /person/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"sex": {
"value": "女",
"boost": 1.0
}
}
}
],
"should": [
{
"term": {
"address.keyword": {
"value": "峨眉山",
"boost": 1.0
}
}
},
{
"term": {
"sect.keyword": {
"value": "明教",
"boost": 1.0
}
}
}
],
"adjust_pure_negative": true,
"minimum_should_match": "1",
"boost": 1.0
}
}
}
Java构建查询语句:
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询语句
searchSourceBuilder.query(QueryBuilders.boolQuery()
.must(QueryBuilders.termQuery("sex", "女"))
.should(QueryBuilders.termQuery("address.word", "峨眉山"))
.should(QueryBuilders.termQuery("sect.keyword", "明教"))
.minimumShouldMatch(1)
);
最后,看一个复杂些的例子,将bool的各子句联合使用:
select * from persons where sex = '女' and age between 30 and 40 and sect != '明教' and (address = '峨眉山' OR skill = '暗器')
用 Elasticsearch 来表示上面的 SQL 例子:
GET /person/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"sex": {
"value": "女",
"boost": 1.0
}
}
},
{
"range": {
"age": {
"from": 30,
"to": 40,
"include_lower": true,
"include_upper": true,
"boost": 1.0
}
}
}
],
"must_not": [
{
"term": {
"sect.keyword": {
"value": "明教",
"boost": 1.0
}
}
}
],
"should": [
{
"term": {
"address.keyword": {
"value": "峨眉山",
"boost": 1.0
}
}
},
{
"term": {
"skill.keyword": {
"value": "暗器",
"boost": 1.0
}
}
}
],
"adjust_pure_negative": true,
"minimum_should_match": "1",
"boost": 1.0
}
}
}
用Java构建这个查询条件:
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询语句
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery()
.must(QueryBuilders.termQuery("sex", "女"))
.must(QueryBuilders.rangeQuery("age").gte(30).lte(40))
.mustNot(QueryBuilders.termQuery("sect.keyword", "明教"))
.should(QueryBuilders.termQuery("address.keyword", "峨眉山"))
.should(QueryBuilders.rangeQuery("power.keyword").gte(50).lte(80))
.minimumShouldMatch(1); // 设置should至少需要满足几个条件
// 将BoolQueryBuilder构建到SearchSourceBuilder中
searchSourceBuilder.query(boolQueryBuilder);
3.2 Filter查询
query和filter的区别:query查询的时候,会先比较查询条件,然后计算分值,最后返回文档结果;而filter是先判断是否满足查询条件,如果不满足会缓存查询结果(记录该文档不满足结果),满足的话,就直接缓存结果,filter不会对结果进行评分,能够提高查询效率。
filter的使用方式比较多样,下面用几个例子演示一下。
方式一,单独使用:
{
"query": {
"bool": {
"filter": [
{
"term": {
"sex": {
"value": "男",
"boost": 1.0
}
}
}
],
"adjust_pure_negative": true,
"boost": 1.0
}
}
}
单独使用时,filter与must基本一样,不同的是filter不计算评分,效率更高。
Java构建查询语句:
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询语句
searchSourceBuilder.query(QueryBuilders.boolQuery()
.filter(QueryBuilders.termQuery("sex", "男"))
);
方式二,和must、must_not同级,相当于子查询:
select * from (select * from persons where sect = '明教')) a where sex = '女';
ES查询语句:
{
"query": {
"bool": {
"must": [
{
"term": {
"sect.keyword": {
"value": "明教",
"boost": 1.0
}
}
}
],
"filter": [
{
"term": {
"sex": {
"value": "女",
"boost": 1.0
}
}
}
],
"adjust_pure_negative": true,
"boost": 1.0
}
}
}
Java:
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询语句
searchSourceBuilder.query(QueryBuilders.boolQuery()
.must(QueryBuilders.termQuery("sect.keyword", "明教"))
.filter(QueryBuilders.termQuery("sex", "女"))
);
方式三,将must、must_not置于filter下,这种方式是最常用的:
{
"query": {
"bool": {
"filter": [
{
"bool": {
"must": [
{
"term": {
"sect.keyword": {
"value": "明教",
"boost": 1.0
}
}
},
{
"range": {
"age": {
"from": 20,
"to": 35,
"include_lower": true,
"include_upper": true,
"boost": 1.0
}
}
}
],
"must_not": [
{
"term": {
"sex.keyword": {
"value": "女",
"boost": 1.0
}
}
}
],
"adjust_pure_negative": true,
"boost": 1.0
}
}
],
"adjust_pure_negative": true,
"boost": 1.0
}
}
}
Java:
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询语句
searchSourceBuilder.query(QueryBuilders.boolQuery()
.filter(QueryBuilders.boolQuery()
.must(QueryBuilders.termQuery("sect.keyword", "明教"))
.must(QueryBuilders.rangeQuery("age").gte(20).lte(35))
.mustNot(QueryBuilders.termQuery("sex.keyword", "女")))
);
04 聚合查询
接下来,我们将用一些案例演示ES聚合查询。
4.1 最值、平均值、求和
案例:查询最大年龄、最小年龄、平均年龄。
SQL:
select max(age) from persons;
ES:
GET /person/_search
{
"aggregations": {
"max_age": {
"max": {
"field": "age"
}
}
}
}
Java:
@Autowired
private RestHighLevelClient client;
@Test
public void maxQueryTest() throws IOException {
// 聚合查询条件
AggregationBuilder aggBuilder = AggregationBuilders.max("max_age").field("age");
SearchRequest searchRequest = new SearchRequest("person");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 将聚合查询条件构建到SearchSourceBuilder中
searchSourceBuilder.aggregation(aggBuilder);
System.out.println("searchSourceBuilder----->" + searchSourceBuilder);
searchRequest.source(searchSourceBuilder);
// 执行查询,获取SearchResponse
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSONObject.toJSON(response));
}
使用聚合查询,结果中默认只会返回10条文档数据(当然我们关心的是聚合的结果,而非文档)。返回多少条数据可以自主控制:
GET /person/_search
{
"size": 20,
"aggregations": {
"max_age": {
"max": {
"field": "age"
}
}
}
}
而Java中只需增加下面一条语句即可:
searchSourceBuilder.size(20);
与max类似,其他统计查询也很简单:
AggregationBuilder minBuilder = AggregationBuilders.min("min_age").field("age");
AggregationBuilder avgBuilder = AggregationBuilders.avg("min_age").field("age");
AggregationBuilder sumBuilder = AggregationBuilders.sum("min_age").field("age");
AggregationBuilder countBuilder = AggregationBuilders.count("min_age").field("age");
4.2 去重查询
案例:查询一共有多少个门派。
SQL:
select count(distinct sect) from persons;
ES:
{
"aggregations": {
"sect_count": {
"cardinality": {
"field": "sect.keyword"
}
}
}
}
Java:
@Test
public void cardinalityQueryTest() throws IOException {
// 创建某个索引的request
SearchRequest searchRequest = new SearchRequest("person");
// 查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 聚合查询
AggregationBuilder aggBuilder = AggregationBuilders.cardinality("sect_count").field("sect.keyword");
searchSourceBuilder.size(0);
// 将聚合查询构建到查询条件中
searchSourceBuilder.aggregation(aggBuilder);
System.out.println("searchSourceBuilder----->" + searchSourceBuilder);
searchRequest.source(searchSourceBuilder);
// 执行查询,获取结果
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSONObject.toJSON(response));
}
4.3 分组聚合
4.3.1 单条件分组
案例:查询每个门派的人数
SQL:
select sect,count(id) from mytest.persons group by sect;
ES:
{
"size": 0,
"aggregations": {
"sect_count": {
"terms": {
"field": "sect.keyword",
"size": 10,
"min_doc_count": 1,
"shard_min_doc_count": 0,
"show_term_doc_count_error": false,
"order": [
{
"_count": "desc"
},
{
"_key": "asc"
}
]
}
}
}
}
Java:
SearchRequest searchRequest = new SearchRequest("person");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.size(0);
// 按sect分组
AggregationBuilder aggBuilder = AggregationBuilders.terms("sect_count").field("sect.keyword");
searchSourceBuilder.aggregation(aggBuilder);
4.3.2 多条件分组
案例:查询每个门派各有多少个男性和女性
SQL:
select sect,sex,count(id) from mytest.persons group by sect,sex;
ES:
{
"aggregations": {
"sect_count": {
"terms": {
"field": "sect.keyword",
"size": 10
},
"aggregations": {
"sex_count": {
"terms": {
"field": "sex.keyword",
"size": 10
}
}
}
}
}
}
4.4 过滤聚合
前面所有聚合的例子请求都省略了 query ,整个请求只不过是一个聚合。这意味着我们对全部数据进行了聚合,但现实应用中,我们常常对特定范围的数据进行聚合,例如下例。
案例:查询明教中的最大年龄。这涉及到聚合与条件查询一起使用。
SQL:
select max(age) from mytest.persons where sect = '明教';
ES:
GET /person/_search
{
"query": {
"term": {
"sect.keyword": {
"value": "明教",
"boost": 1.0
}
}
},
"aggregations": {
"max_age": {
"max": {
"field": "age"
}
}
}
}
Java:
SearchRequest searchRequest = new SearchRequest("person");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 聚合查询条件
AggregationBuilder maxBuilder = AggregationBuilders.max("max_age").field("age");
// 等值查询
searchSourceBuilder.query(QueryBuilders.termQuery("sect.keyword", "明教"));
searchSourceBuilder.aggregation(maxBuilder);
另外还有一些更复杂的查询例子。
案例:查询0-20,21-40,41-60,61以上的各有多少人。
SQL:
select
sum(case when age<=20 then 1 else 0 end) ageGroup1,
sum(case when age >20 and age <=40 then 1 else 0 end) ageGroup2,
sum(case when age >40 and age <=60 then 1 else 0 end) ageGroup3,
sum(case when age >60 and age <=200 then 1 else 0 end) ageGroup4
from
mytest.persons;
ES:
{
"size": 0,
"aggregations": {
"age_avg": {
"range": {
"field": "age",
"ranges": [
{
"from": 0.0,
"to": 20.0
},
{
"from": 21.0,
"to": 40.0
},
{
"from": 41.0,
"to": 60.0
},
{
"from": 61.0,
"to": 200.0
}
],
"keyed": false
}
}
}
}
查询结果:
"aggregations" : {
"age_avg" : {
"buckets" : [
{
"key" : "0.0-20.0",
"from" : 0.0,
"to" : 20.0,
"doc_count" : 3
},
{
"key" : "21.0-40.0",
"from" : 21.0,
"to" : 40.0,
"doc_count" : 13
},
{
"key" : "41.0-60.0",
"from" : 41.0,
"to" : 60.0,
"doc_count" : 4
},
{
"key" : "61.0-200.0",
"from" : 61.0,
"to" : 200.0,
"doc_count" : 1
}
]
}
}
原文链接:https://blog.csdn.net/wang20010104/article/details/130482294
相关文章:
一文全览各种 ES 查询在 Java 中的实现
2 词条查询 所谓词条查询,也就是ES不会对查询条件进行分词处理,只有当词条和查询字符串完全匹配时,才会被查询到。  2.1 等值查询-term 等值查询,即筛选出一个字段等于特定值的所有记录。  SQL&…...

Centralized Feature Pyramid for Object Detection解读
Centralized Feature Pyramid for Object Detection 问题 主流的特征金字塔集中于层间特征交互,而忽略了层内特征规则。尽管一些方法试图在注意力机制或视觉变换器的帮助下学习紧凑的层内特征表示,但它们忽略了对密集预测任务非常重要的被忽略的角点区…...
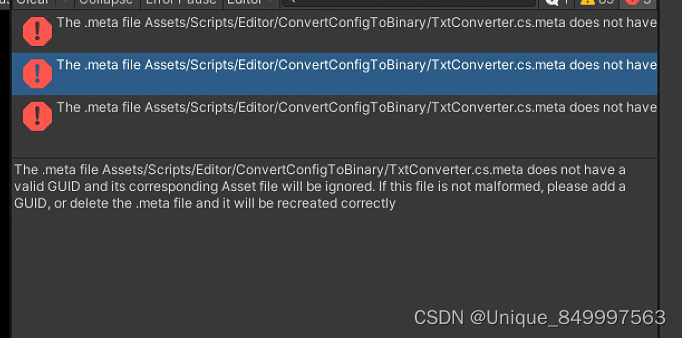
unity中meta文件GUID异常问题
错误信息: The .meta file Assets/Scripts/Editor/ConvertConfigToBinary/TxtConverter.cs.meta does not have a valid GUID and its corresponding Asset file will be ignored. If this file is not malformed, please add a GUID, or delete the .meta file and…...
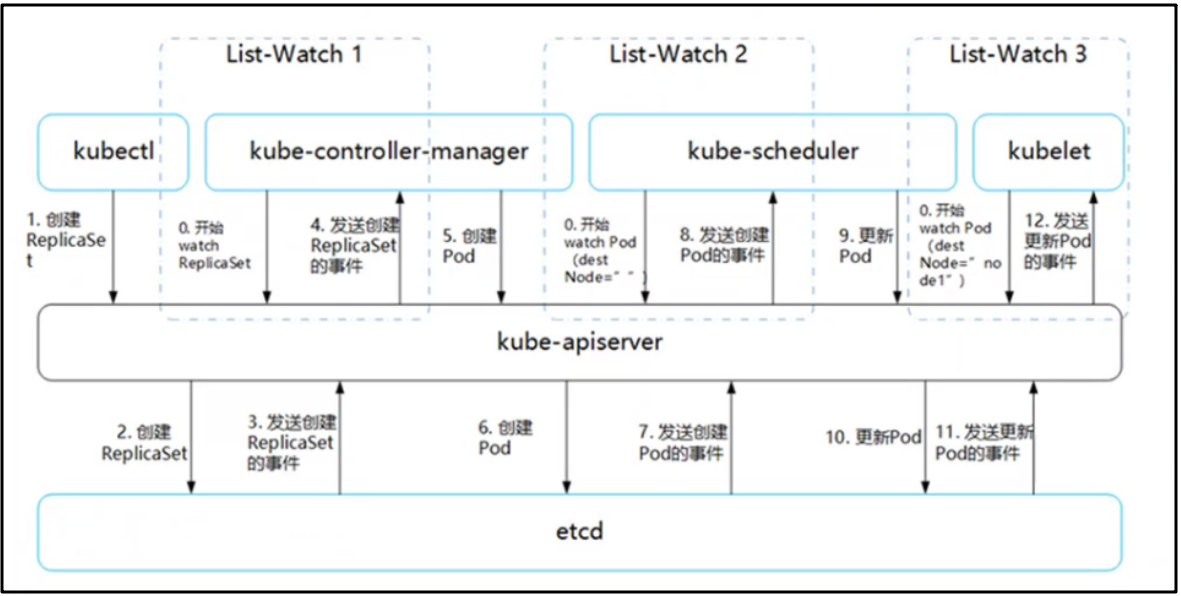
【k8s】pod集群调度
调度约束 Kubernetes 是通过 List-Watch **** 的机制进行每个组件的协作,保持数据同步的,每个组件之间的设计实现了解耦。 用户是通过 kubectl 根据配置文件,向 APIServer 发送命令,在 Node 节点上面建立 Pod 和 Container。…...
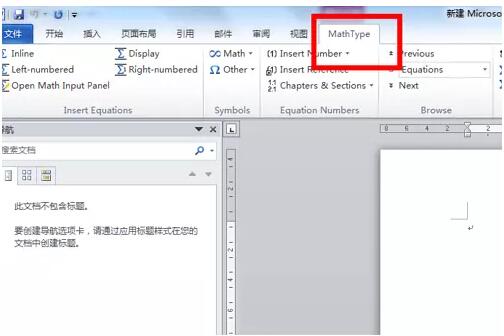
MathType数学公式编辑器2024官方最新版
Mathtype是一款数学公式编辑器,它可以帮助我们在文档中插入各种复杂的数学公式,使得我们的文档更加专业、规范。在使用Mathtype工具时,我们可以采取以下几种方法: 1. 鼠标直接点击插入公式 打开Mathtype后,在需要插入公…...

Android照搬,可删
1private void initview() {myradioGroup (RadioGroup) this.findViewById(R.id.MainActivity_RadioGroup);//通过id找到UI中的单选按钮组 2res getResources();// 得到Resources对象,从而通过它获取存在系统的资源 icon_home_true res.getDrawable(R.mipmap.ic…...
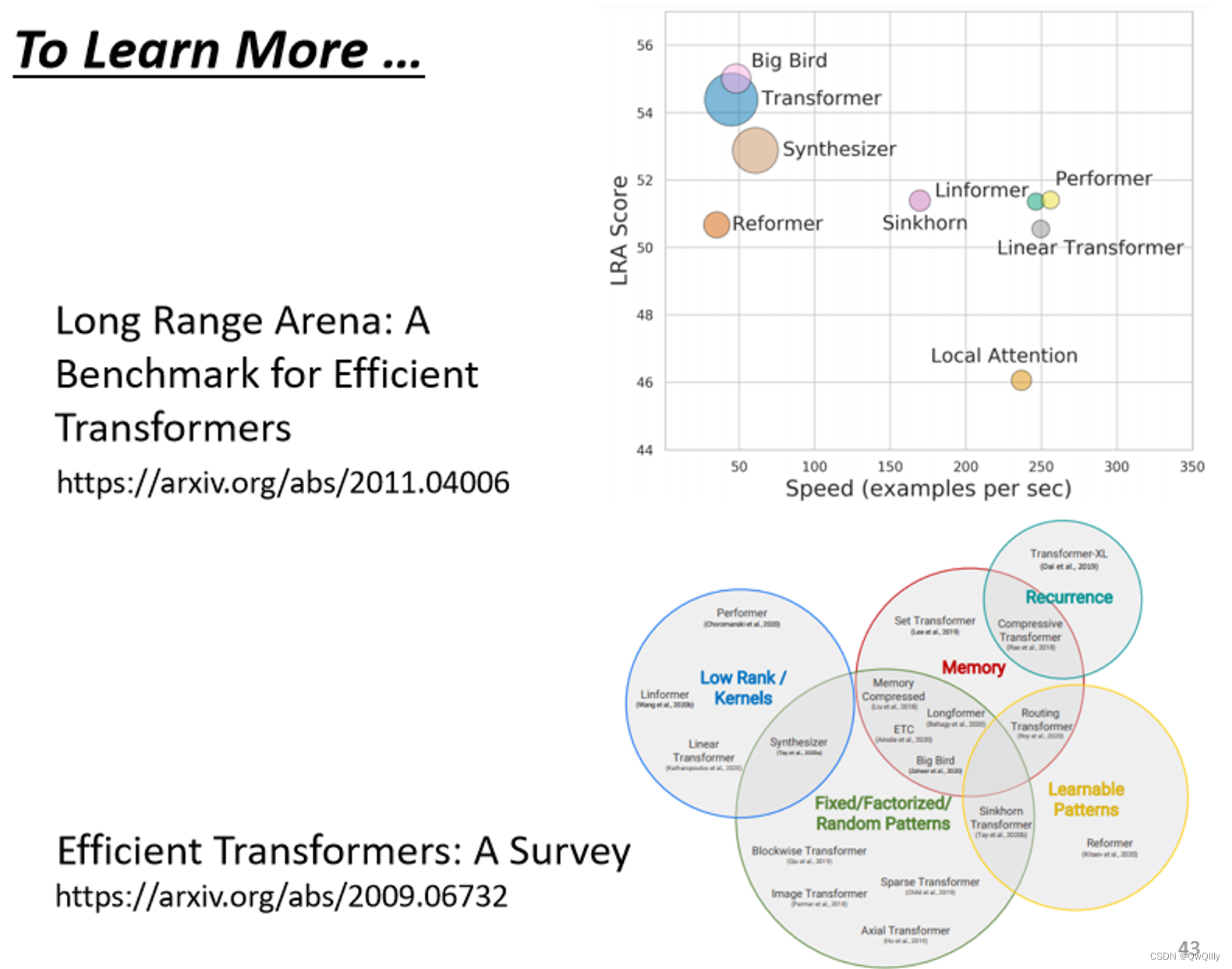
2022最新版-李宏毅机器学习深度学习课程-P26 自注意力机制
一、应用情境 输入任意长度个向量进行处理。 从输入看 文字处理(自然语言处理) 将word表示为向量 one-hotword-embedding声音信号处理 每个时间窗口(Window, 25ms)视为帧(Frame),视为向量图 每个节点视为…...
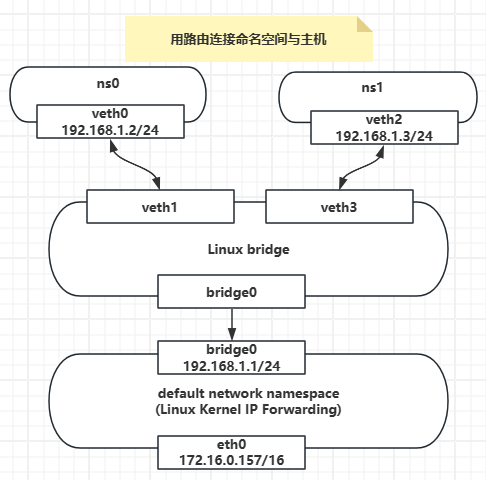
【Docker】Linux路由连接两个不同网段namespace,连接namespace与主机
如果两个namespace处于不同的子网中,那么就不能通过bridge进行连接了,而是需要通过路由器进行三层转发。然而Linux并未像提供虚拟网桥一样也提供一个虚拟路由器设备,原因是Linux自身就具备有路由器功能。 路由器的工作原理是这样的ÿ…...

C语言 DAY10 内存分配
1.引入 int nums[10] {0}; //对 int len 10; int nums[len] {0}; //错 是因为系统的内存分配原则导致的 2.概述 在系统运行时,系统为了更好的管理进程中的内存,所以将内存进行了分配,其分配的机制就称为内存分配 1.静态分配原则 1.特点 1、在程序…...

SpringCloud Gateway 网关的请求体body的读取和修改
SpringCloud Gateway 网关的请求体body的读取和修改 getway需要多次对body 进行操作,需要对body 进行缓存 缓存body 动态多次获取 新建顶层filter,对body 进行缓存 import lombok.extern.slf4j.Slf4j; import org.springframework.cloud.gateway.filt…...

气膜场馆的降噪方法
在现代社会,噪音已经成为我们生活中难以避免的问题,而气膜场馆也不例外。传统的气膜场馆常常因其特殊结构而面临噪音扩散和回声问题,影响了人们的体验和活动效果。然而,随着科技的进步,多功能声学综合馆应运而生&#…...
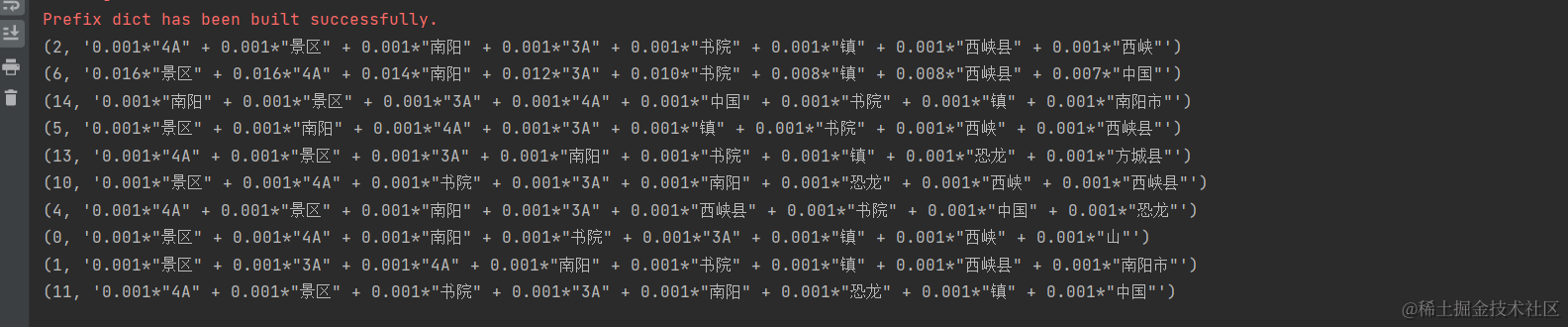
探索主题建模:使用LDA分析文本主题
在数据分析和文本挖掘领域,主题建模是一种强大的工具,用于自动发现文本数据中的隐藏主题。Latent Dirichlet Allocation(LDA)是主题建模的一种常用技术。本文将介绍如何使用Python和Gensim库执行LDA主题建模,并探讨主题…...

服务器黑洞,如何秒解
想必这样的短信大家都应该见过吧,这其实是阿里云服务器被攻击后触发的黑洞机制的短信通知。还有很多朋友不知道,为什么要这么做。原因其实很简单啊,当同一个机房的ip段,如果说有一台服务器遭受低道攻击,那么很可能会造…...
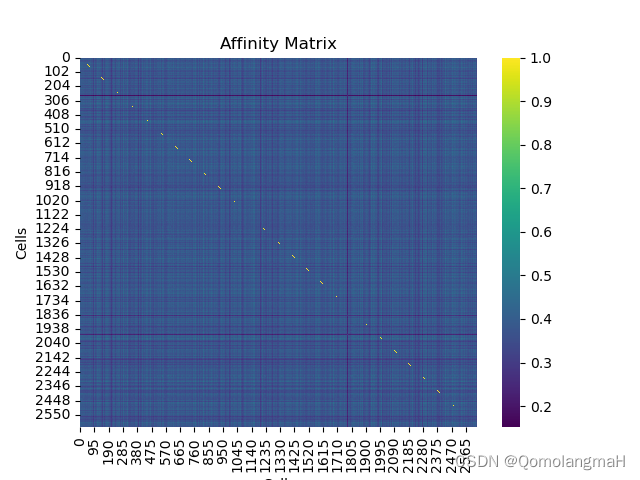
【生物信息学】单细胞RNA测序数据分析:计算亲和力矩阵(基于距离、皮尔逊相关系数)及绘制热图(Heatmap)
文章目录 一、实验介绍二、实验环境1. 配置虚拟环境2. 库版本介绍 三、实验内容0. 导入必要的库1. 读取数据集2. 质量控制(可选)3. 基于距离的亲和力矩阵4. 绘制基因表达的Heatmap5. 基于皮尔逊相关系数的亲和力矩阵6. 代码整合 一、实验介绍 计算亲和力…...
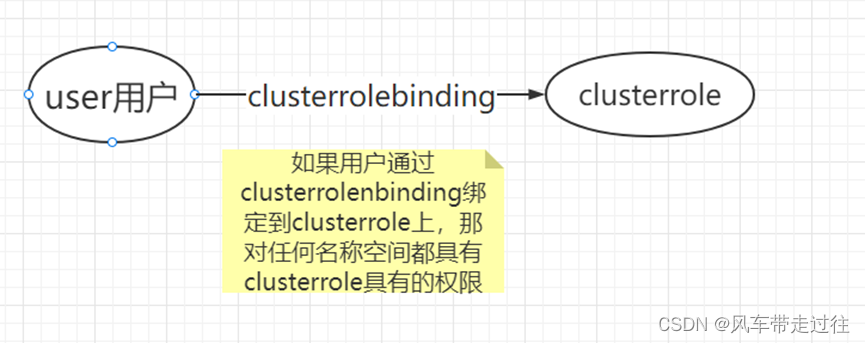
学习笔记三十一:k8s安全管理:认证、授权、准入控制概述SA介绍
K8S安全实战篇之RBAC认证授权-v1 k8s安全管理:认证、授权、准入控制概述认证k8s客户端访问apiserver的几种认证方式客户端认证:BearertokenServiceaccountkubeconfig文件 授权Kubernetes的授权是基于插件形成的,其常用的授权插件有以下几种&a…...

【开发新的】apache common BeanUtils忽略null值
前言: BeanUtils默认的populate方法不会忽略空值和null值,在特定场景,我们需要原始的值避免被覆盖,所以这里提供一种自定义实现方式。 package com.hmwl.service.program;import lombok.extern.slf4j.Slf4j; import org.apache.commons.beanu…...

coalesce函数(SQL )
用途: 将控制替换成其他值;返回第一个非空值 表达式 COALESCE是一个函数, (expression_1, expression_2, …,expression_n)依次参考各参数表达式,遇到非null值即停止并返回该值。如果所有的表达式都是空值,最终将返…...

一键报警可视对讲管理机10寸触摸屏管理机
一键报警可视对讲管理机10寸触摸屏管理机 一、管理机技术指标: 1、10寸LCD触摸屏,分辨率1024*600; 2、摄像头1200万像素 3、1000M/100M自适应网口; 4、按键设置:报警/呼叫按键,通话/挂机按键࿰…...

java左右括号
java左右括号 数据结构-栈栈的特点:先进后出代码实现 最近看到有小伙伴去面试,被人问起一道算法题,题目内容大概是:给定一个字符串,如:“[[]]{}”,判断字符串是否为有效的括号。考查的是数据结构…...

接口自动化测试 —— 工具、请求与响应
一、工具: 1.工具介绍 postman :很主流的API测试工具,也是工作里面使用最广泛的研发工具。 JMeter: ApiPost: 2.安装postman: 安装好直接打开,不用注册。 二、通信模式: 1、…...

重塑知识连接:探索Obsidian模板驱动的Zettelkasten思维系统
重塑知识连接:探索Obsidian模板驱动的Zettelkasten思维系统 【免费下载链接】Obsidian-Templates A repository containing templates and scripts for #Obsidian to support the #Zettelkasten method for note-taking. 项目地址: https://gitcode.com/gh_mirror…...

2026年需求管理工具盘点:主流软件对比、测评与选型实用指南
本文盘点 ONES、Tower、Jira、Azure DevOps、Asana、ClickUp、monday.com、Notion、Linear、YouTrack 这 10 款需求管理工具,围绕需求收集、拆解、优先级、追踪闭环和团队协作展开测评,帮助选型人员更快判断哪类工具适合自己的团队。刚做项目经理时&…...

M9A:重返未来1999终极解放双手指南 - 智能助手让你的游戏体验更轻松
M9A:重返未来1999终极解放双手指南 - 智能助手让你的游戏体验更轻松 【免费下载链接】M9A 重返未来:1999 小助手 | Assistant For Reverse: 1999 项目地址: https://gitcode.com/gh_mirrors/m9/M9A 你是否曾经为《重返未来:1999》的日…...

B站视频转换终极指南:3分钟掌握m4s转MP4永久保存技巧
B站视频转换终极指南:3分钟掌握m4s转MP4永久保存技巧 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾因B站视频突然下架而痛…...

告别复杂配置,使用Taotoken CLI一键生成多工具环境配置文件
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 告别复杂配置,使用Taotoken CLI一键生成多工具环境配置文件 在接入多个大模型工具时,开发者常常需要为每个…...

避坑指南:PnetLab导入锐捷镜像时,关于qemu_options和权限的那些‘坑’
PnetLab锐捷镜像部署深度排障手册:从参数解析到权限修复实战 当你在深夜的机房里盯着屏幕上闪烁的命令行,第十次尝试启动PnetLab中的锐捷镜像却依然遭遇连接失败时,那种挫败感我深有体会。这不是又一篇按部就班的安装教程,而是一…...

无人机载RIS混合能量收集系统设计与优化
1. 无人机载RIS混合能量收集系统概述 在6G物联网通信场景中,无人机搭载可重构智能表面(RIS)的技术组合正在重塑无线网络架构。这种创新方案通过将RIS的被动波束赋形能力与无人机的三维机动性相结合,有效解决了传统地面基站覆盖范围有限、部署不灵活的痛点…...
)
别再只抄datasheet了!TPS5430降压电路PCB布局的5个实战避坑点(附15V转12V/负压案例)
TPS5430降压电路PCB布局的5个实战避坑指南:从理论到15V转12V/负压案例 在硬件设计领域,TPS5430作为一款经典的Buck型DC-DC转换芯片,其性能表现与PCB布局质量密切相关。许多工程师虽然能正确绘制原理图,却在PCB实现阶段因忽视关键…...

第11代酷睿工业主板PICO-TGU4:边缘AI与机器视觉的紧凑型解决方案
1. 项目概述:当紧凑型工业主板遇上第11代酷睿在工业自动化、边缘计算和智能零售这些领域里,我们常常面临一个经典的矛盾:一方面,应用场景对计算性能的要求越来越高,无论是机器视觉的实时图像处理,还是AI推理…...

用VSCode+ESP-IDF给机器人装“关节”:PCA9685驱动16路舵机保姆级配置流程
用VSCodeESP-IDF给机器人装“关节”:PCA9685驱动16路舵机保姆级配置流程 在机器人开发中,精确控制多个舵机是实现复杂动作的基础。想象一下,一个六足机器人需要协调18个关节的运动,或者一个机械臂要完成精准抓取动作——这些场景都…...