2022最新版-李宏毅机器学习深度学习课程-P26 自注意力机制
一、应用情境
输入任意长度个向量进行处理。
从输入看
- 文字处理(自然语言处理)
- 将word表示为向量
- one-hot
- word-embedding
- 将word表示为向量
- 声音信号处理
- 每个时间窗口(Window, 25ms)视为帧(Frame),视为向量
- 图
- 每个节点视为一个向量
- Social graph(社交网络图)
- 分子式【one-hot】
- 每个节点视为一个向量
从输出看
- √ 输入输出数量相等【每个向量都有一个标签】⇒sequence Labeling
- 词性标注(POS tagging)
- 语音辨识(每个vector对应phoneme)
- 社交网络(每个节点(人)进行标注【是否推送商品】)
- 整个输入序列只有一个输出
- 文本情感分析
- 语者辨认
- 分子的疏水性
- 由模型决定输出的数目【seq2seq】
- 翻译
- 语音辨识








二、Sequence Labeling
- 对每一个向量,用Fully-connected network分别进行处理
- 问题:忽略了序列上下文的关系
- 同一个向量在序列号中不同的位置、不同的上下文环境下,得到的输出可能不同(需要考虑序列)
- 改进:串联若干个向量
- 问题:
- 只能考虑固定个,不能考虑”任意长度“
- 网络参数大
- 问题:
- 问题:忽略了序列上下文的关系

三、Self-attention

特点:考虑整个序列sequence的所有向量,综合向量序列整体和单个向量个体,得到对每一个向量处理后的向量
⇒将这个向量链接一个FC,FC可以专注于处理这一个位置的向量,得到对应结果。
其中,self-attention 的功能是处理整个 sequence 的信息,而 FC 则是处理某一个位置的信息,
Self-attention+FC可以交替使用
知名文章:Attention is all you need ⇒Transformer

基本原理
输入:一串的 Vector,这个 Vector 可能是整个 Network 的 Input,也可能是某个 Hidden Layer 的 Output
输出:处理 Input 以后,每一个 bi 都是考虑了所有的 ai 以后才生成出来的

具体步骤如下:
1. 以 a1 为例,根据 a1 这个向量,找出整个 sequence 中跟 a1 相关的其他向量 ⇒ 计算哪些部分是重要的,求出 ai 和 a1 的相关性(影响程度大的就多考虑点),用 α 表示

2. 计算相关性:有 点积 和 additive 两种方法计算相关性。
✔️方法一 dot product:
输入的这两个向量分别乘上两个不同的矩阵,左边这个向量乘上矩阵 W^q得到矩阵 q,右边这个向量乘上矩阵 W^k得到矩阵 k;再把 q跟 k做dot product,逐元素相乘后累加得到一个 scalar就是α
方法二 Additive:
得到 q跟 k后,先串接起来,再过一个Activation Function(Normalization),再通过一个Transform,然后得到 α
需要计算:任意两个向量之间的关联性,作softmax【不一定要用,也可以用其他激活函数】,得到

把 a1 乘上 Wq 得到 q,叫做 Query(就像是搜寻相关文章的关键字,所以叫做 Query)
然后将 ai 都要乘 Wq 得到 k,叫做 Key,把这个Query q1 和 Key ki 进行 点积操作 就得到 相关性 α( α 叫做 Attention Score,表示 Attention计算出的 vector 之间的相关性)

attention score 还要经过一层 softmax 才能用于后续处理,其中 softmax 也可以换成其他的 activation function

3. 分别抽取重要信息,根据关联性作加权求和得到 bi
(一次性并行计算出 bi ,不需要依次先后得出)


优点:bi 是并行计算得出

矩阵的角度表示 Self-attention 计算过程
① 计算 k,q,v (其中 Wq 、Wk 和 Wv 都是要学习的网络参数矩阵)
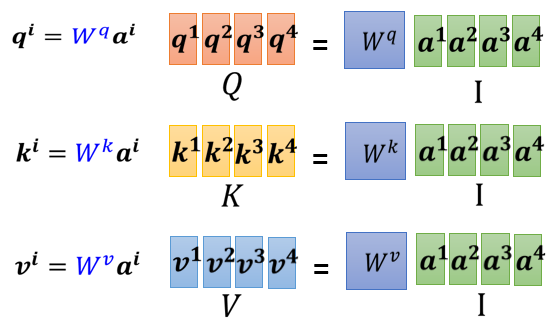
② 计算 α 并 Normalization

③ 计算 b

综合:

其中,
- I 是 Self-attention 的 input(一排 vector),每个 vector 拼起来当作矩阵的 column
- 这个 input 分别乘上三个矩阵, 得到 Q K V
- 接下来 Q 乘上 K 的 transpose,得到 A 。可能会做一些处理,得到 A' ,叫做Attention Matrix ,生成 Q 矩阵就是为了得到 Attention 的 score
- A' 再乘上 V,就得到 O,O 就是 Self-attention 这个 layer 的输出
唯一需要学的参数:三个矩阵
四、Multi-head Self-attention
1. 特点
使用多个 q k v 组合,不同的 q k v 负责不同种类的相关性
例如在下图中,一共有2类, 1类的放在一起算,2类的放在一起算。相关性变多了,所以参数也增加了,原来只需要三个 W 矩阵,现在需要六个 W 矩阵

2. 计算步骤
-
先把 a 乘上一个矩阵得到 q
-
再把 q 乘上另外两个矩阵,分别得到 q1 跟 q2,代表有两个 head;同理可以得到 k1, k2,v1, v2
-
同一个 head 里的 k q v 计算 b.
-

- 将各个 head 计算得到的 bi 拼接,通过一个 transform得到 bi,然后再送到下一层去

3. Positional Encoding
每个向量所处的“位置”需要被编码
方法:每个位置用一个 vector ei 来表示它是 sequence 的第 i 个。加和到原向量中。

如何产生positional encoding vector尚待研究
- 手工设置
- 根据资料学出来
五、Applications

BERT
Self-attention for Speech
问题:
把一段声音讯号,表示成一排向量的话,这排向量可能会非常地长;attention matrix 的计算复杂度是长度的平方需要很大的计算量、很大的存储空间
方法:Truncated Self-attention

要看一整句话,只看一个小的范围就好——辨识这个位置有什麼样的phoneme只要看这句话,跟它前后一定范围之内的资讯就可以判断
Self-attention for Image

每一个 pixel就是一个三维的向量,整张图片其实就是长乘以宽个向量的set
Self-attention GAN1

六、Self-attention 和 CNN RNN GNN
1. 和CNN的对比
CNN 可以看成简化版的 self-attention,CNN 就是只计算感受域中的相关性的self-attention。
- CNN:感知域(receptive field)是人为设定的,只考虑范围内的信息
- Self-attention:考虑一个像素和整张图片的信息 ⇒ 自己学出“感知域”的形状和大小
结论:
CNN 就是 Self-attention 的特例,Self-attention 只要设定合适的参数,就可以做到跟 CNN 一模一样的事情
self attention 是更 flexible 的 CNN
⇒ self-attention需要 更多的数据 进行训练,否则会 欠拟合;否则CNN的性能更好
- Self-attention 它弹性比较大,所以需要比较多的训练资料,训练资料少的时候,就会 overfitting
- 而 CNN 它弹性比较小,在训练资料少的时候,结果比较好,但训练资料多的时候,它没有办法从更大量的训练资料得到好处


2. 和 RNN 的对比
recurrent neural network 的角色,很大一部分都可以用 Self-attention 来取代了
Recurrent Neural Network跟 Self-attention 做的事情其实也非常像,它们的 input 都是一个 vector sequence
- 左边是你的 input sequence,你有一个 memory 的 vector
- 然后你有一个 RNN 的 block,吃 memory 的 vector,吃第一个 input 的 vector
- 然后 output hidden layer 的 output
- 然后通过fully connected network,做你想要的 prediction
- 接下来当sequence 裡面第二个 vector 作為 input 的时候,也会把前一个时间点吐出来的东西,当做下一个时间点的输入,再丢进 RNN 裡面,然后再產生新的 vector,再拿去给 fully connected network
RNN 其实也可以是双向的,从而使得 memory 的 hidden output,其实也可以看作是考虑了整个 input 的 sequence
主要区别:
- 对 RNN 来说,最终的输出要考虑最左边一开始的输入 vector,意味着必须要把最左边的输入存到 memory 里面并且在计算过程中一直都不能够忘掉,一路带到最右边,才能够在最后一个时间点被考虑(依次按顺序输出)
- 对 Self-attention 可以在整个 sequence 上非常远的 vector之间轻易地抽取信息
并行输出,速度更快,效率更高:
- Self-attention:四个 vector 是平行產生的,并不需要等谁先运算完才把其他运算出来
- RNN 是没有办法平行化的,必须依次产生
很多的应用都往往把 RNN 的架构,逐渐改成 Self-attention 的架构

3. 和 GNN 的对比
Self-attention for Graph⇒一种GNN
- 在 Graph 上面,每一个 node 可以表示成一个向量
- node 之间是有相连的,每一个 edge 标志着 node 跟 node 之间的关联性
- 比如:在做Attention Matrix 计算的时候,只需计算有 edge 相连的 node
- 因為这个 Graph 往往是人為根据某些 domain knowledge 建出来的,已知这两个向量彼此之间没有关联(图矩阵中对应结点 i 与 结点 j 之间没有数值),就没有必要再用机器去学习这件事情

MORE
冷知识:有人说广义的 Transformer,指的就是 Self-attention
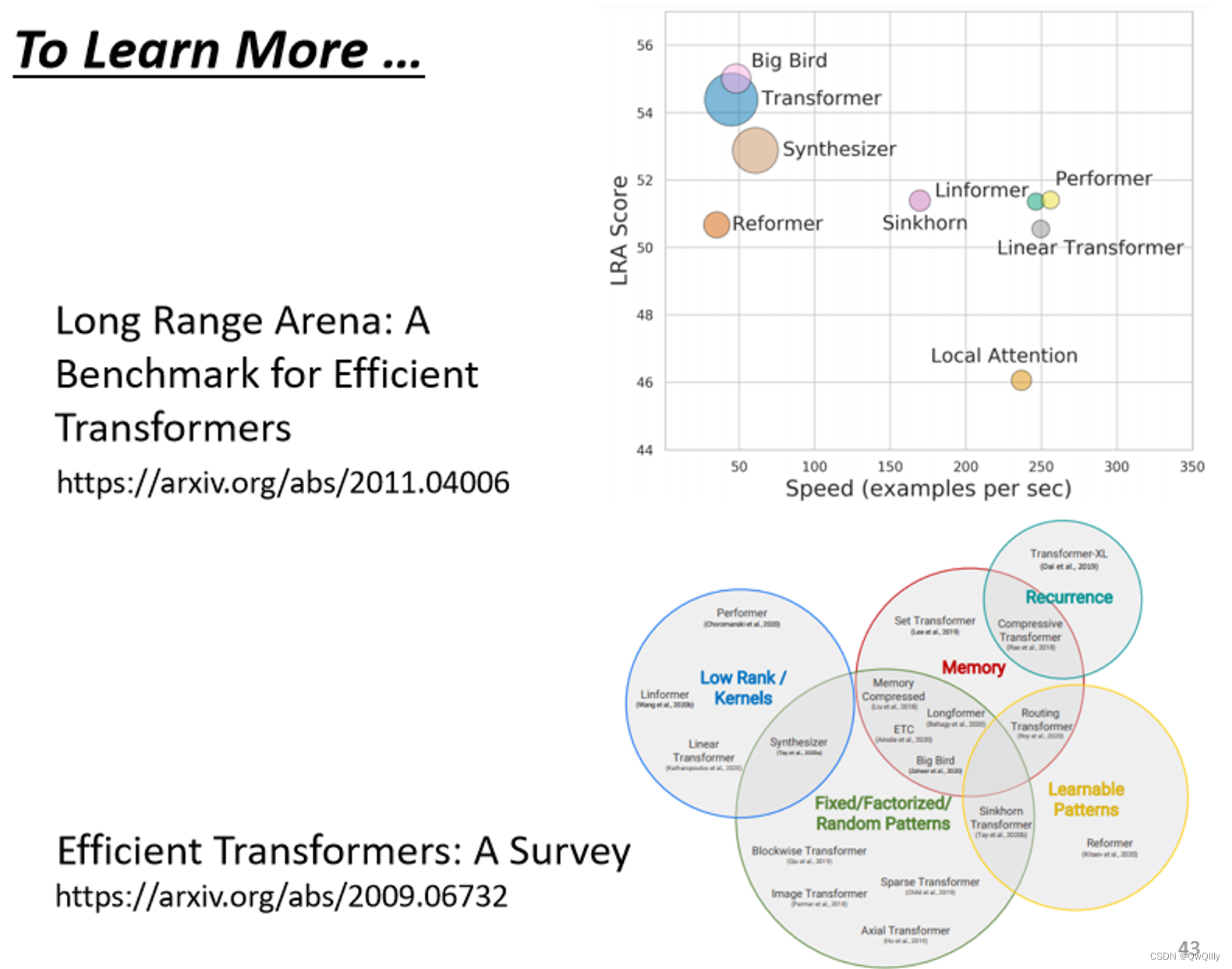
Self-attention 有非常非常多的变形,Self-attention 它最大的问题就是,它的运算量非常地大
paper:Long Range Arena比较了各种不同的 Self-attention 的变形
Efficient Transformers: A Survey 这篇 paper,介绍各式各样 Self-attention 的变形
相关文章:
2022最新版-李宏毅机器学习深度学习课程-P26 自注意力机制
一、应用情境 输入任意长度个向量进行处理。 从输入看 文字处理(自然语言处理) 将word表示为向量 one-hotword-embedding声音信号处理 每个时间窗口(Window, 25ms)视为帧(Frame),视为向量图 每个节点视为…...
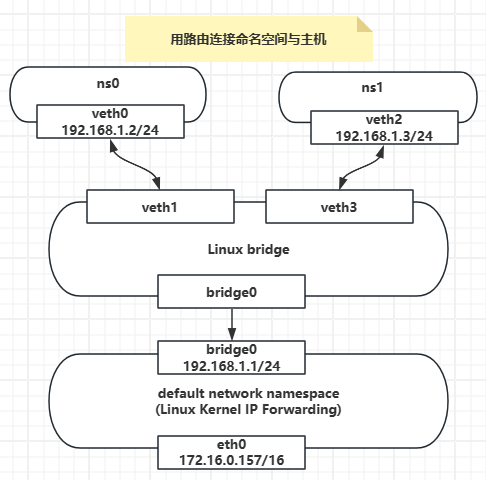
【Docker】Linux路由连接两个不同网段namespace,连接namespace与主机
如果两个namespace处于不同的子网中,那么就不能通过bridge进行连接了,而是需要通过路由器进行三层转发。然而Linux并未像提供虚拟网桥一样也提供一个虚拟路由器设备,原因是Linux自身就具备有路由器功能。 路由器的工作原理是这样的ÿ…...

C语言 DAY10 内存分配
1.引入 int nums[10] {0}; //对 int len 10; int nums[len] {0}; //错 是因为系统的内存分配原则导致的 2.概述 在系统运行时,系统为了更好的管理进程中的内存,所以将内存进行了分配,其分配的机制就称为内存分配 1.静态分配原则 1.特点 1、在程序…...

SpringCloud Gateway 网关的请求体body的读取和修改
SpringCloud Gateway 网关的请求体body的读取和修改 getway需要多次对body 进行操作,需要对body 进行缓存 缓存body 动态多次获取 新建顶层filter,对body 进行缓存 import lombok.extern.slf4j.Slf4j; import org.springframework.cloud.gateway.filt…...

气膜场馆的降噪方法
在现代社会,噪音已经成为我们生活中难以避免的问题,而气膜场馆也不例外。传统的气膜场馆常常因其特殊结构而面临噪音扩散和回声问题,影响了人们的体验和活动效果。然而,随着科技的进步,多功能声学综合馆应运而生&#…...
探索主题建模:使用LDA分析文本主题
在数据分析和文本挖掘领域,主题建模是一种强大的工具,用于自动发现文本数据中的隐藏主题。Latent Dirichlet Allocation(LDA)是主题建模的一种常用技术。本文将介绍如何使用Python和Gensim库执行LDA主题建模,并探讨主题…...

服务器黑洞,如何秒解
想必这样的短信大家都应该见过吧,这其实是阿里云服务器被攻击后触发的黑洞机制的短信通知。还有很多朋友不知道,为什么要这么做。原因其实很简单啊,当同一个机房的ip段,如果说有一台服务器遭受低道攻击,那么很可能会造…...
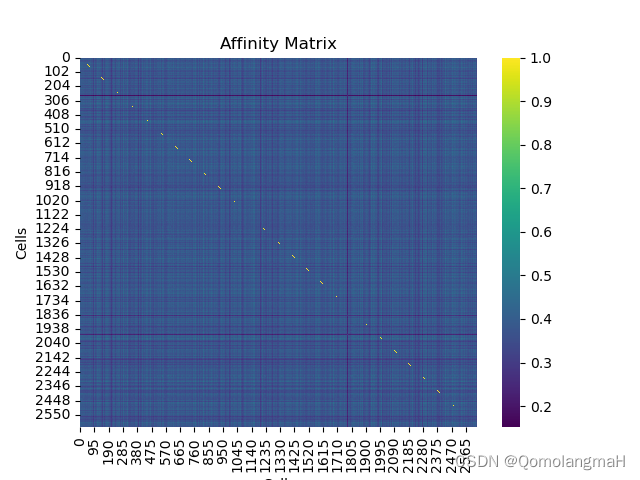
【生物信息学】单细胞RNA测序数据分析:计算亲和力矩阵(基于距离、皮尔逊相关系数)及绘制热图(Heatmap)
文章目录 一、实验介绍二、实验环境1. 配置虚拟环境2. 库版本介绍 三、实验内容0. 导入必要的库1. 读取数据集2. 质量控制(可选)3. 基于距离的亲和力矩阵4. 绘制基因表达的Heatmap5. 基于皮尔逊相关系数的亲和力矩阵6. 代码整合 一、实验介绍 计算亲和力…...
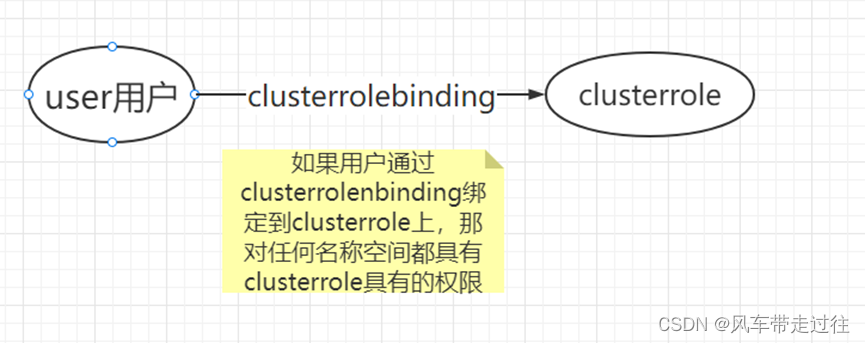
学习笔记三十一:k8s安全管理:认证、授权、准入控制概述SA介绍
K8S安全实战篇之RBAC认证授权-v1 k8s安全管理:认证、授权、准入控制概述认证k8s客户端访问apiserver的几种认证方式客户端认证:BearertokenServiceaccountkubeconfig文件 授权Kubernetes的授权是基于插件形成的,其常用的授权插件有以下几种&a…...

【开发新的】apache common BeanUtils忽略null值
前言: BeanUtils默认的populate方法不会忽略空值和null值,在特定场景,我们需要原始的值避免被覆盖,所以这里提供一种自定义实现方式。 package com.hmwl.service.program;import lombok.extern.slf4j.Slf4j; import org.apache.commons.beanu…...

coalesce函数(SQL )
用途: 将控制替换成其他值;返回第一个非空值 表达式 COALESCE是一个函数, (expression_1, expression_2, …,expression_n)依次参考各参数表达式,遇到非null值即停止并返回该值。如果所有的表达式都是空值,最终将返…...

一键报警可视对讲管理机10寸触摸屏管理机
一键报警可视对讲管理机10寸触摸屏管理机 一、管理机技术指标: 1、10寸LCD触摸屏,分辨率1024*600; 2、摄像头1200万像素 3、1000M/100M自适应网口; 4、按键设置:报警/呼叫按键,通话/挂机按键࿰…...

java左右括号
java左右括号 数据结构-栈栈的特点:先进后出代码实现 最近看到有小伙伴去面试,被人问起一道算法题,题目内容大概是:给定一个字符串,如:“[[]]{}”,判断字符串是否为有效的括号。考查的是数据结构…...

接口自动化测试 —— 工具、请求与响应
一、工具: 1.工具介绍 postman :很主流的API测试工具,也是工作里面使用最广泛的研发工具。 JMeter: ApiPost: 2.安装postman: 安装好直接打开,不用注册。 二、通信模式: 1、…...

【LeetCode:2103. 环和杆 | 模拟】
🚀 算法题 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,…...
微信小程序-授权登录(手机号码)
1、WXBizDataCrypt.js-下载地址 2、UNIAPP代码 <template> <view class"work-container"> <view class"login"> <view class"content"> <button class"button_wx&q…...

视觉问答(VQA)12篇顶会精选论文合集,附常用数据集下载
今天来聊聊计算机视觉和自然语言处理交叉的一个热门研究方向:视觉问答(VQA)。 视觉问答的任务是:给出一张图片和一个关于这张图片的自然语言问题,计算机需要根据图片的内容自动回答这个问题。这样的任务考验了计算机在…...
)
详解--编码(ASCII\Unicode,UTF-8\UTF-16\UTF-32)
本文主要搞清楚编码是怎么回事。 参考链接 字符集编码方式ASCII(American Standard Code for Information Interchange)ASCIIGB2312GB2312UnicodeUTF-8 / UTF-16 / UTF-32 1.编码基本概念 1.1 字符 字符(Character) 在计算机和…...
Linux安装配置awscli命令行接口工具及其从aws上传下载数据
官网技术文档有全面介绍:安装或更新 AWS CLI 的最新版本 - AWS Command Line Interface在系统上安装 AWS CLI。https://docs.aws.amazon.com/zh_cn/cli/latest/userguide/getting-started-install.html#getting-started-install-instructionsawscli常用命令参考&…...

中国联通携手华为助力长城精工启动商用5G-A柔性产线
[中国,河北,2023年11月3日] 近日,中国联通携手华为助力精诚工科汽车系统有限公司保定自动化技术分公司(简称长城精工自动化)启动5G-A超高可靠性超低时延柔性产线的商用阶段。 在河北保定精工自动化工厂,5G…...

ATxmega时钟与GPIO配置详解:从原理到实战代码
1. 项目概述:从零开始认识ATxmage的时钟与GPIO最近在整理一些嵌入式开发的入门资料,发现很多刚接触ATxmage系列微控制器的朋友,拿到开发板后往往第一步就卡在了最基础的时钟配置和引脚操作上。这其实很正常,因为这两个模块是整个系…...

解锁本科论文高效创作新思路,okbiye 赋能毕业生轻松完成学术撰稿
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 引言 步入毕业季,本科阶段最后的学术考核毕业论文,成为众多应届学子面前最大的难题。从前期选题构思、框架梳理&…...

A型流感病毒广谱中和抗体与广谱通用疫苗研究进展
摘要流感作为全球性的公共卫生问题,对人类健康构成严重威胁。接种流感疫苗是预防和控制流感流行的关键手段,但当前通用流感疫苗的研究尚处于初级阶段。本文聚焦于A型流感病毒,综述了广谱中和抗体的研究进展以及其在广谱通用疫苗研发中的潜在应…...
)
蓝桥杯省赛真题解析:用动态规划搞定‘积木画’问题(附Python/Java/C++三种代码)
蓝桥杯竞赛实战:动态规划解积木画问题的多语言实现 第一次参加蓝桥杯的选手往往会被"积木画"这类动态规划题目难住——看似简单的图形拼接背后隐藏着精妙的状态转移逻辑。这道题考察的不仅是编码能力,更是对问题抽象和数学建模的深刻理解。本文…...
)
别再纠结IO口了!手把手教你用三极管实现RS485自动收发(附电路图与阻值计算)
三极管驱动RS485自动收发电路设计实战指南 在嵌入式系统开发中,RS485通信因其抗干扰能力强、传输距离远等优势被广泛应用。然而传统RS485电路需要额外GPIO控制收发方向,当面临IO资源紧张或底层驱动不可控时,硬件工程师常陷入两难境地。本文将…...
别再死记硬背公式了!用大白话和动图拆解Transformer的注意力机制
用生活场景拆解Transformer:注意力机制就像一场高效会议 想象你正在主持一场跨国团队会议,成员们用不同语言讨论项目进展。作为主持人,你需要快速捕捉每个人的发言重点,判断谁的意见最关键,并协调不同观点之间的关系—…...

从协议到实战:深度剖析WiFi Deauth攻击的底层原理与Kali工具链应用
1. WiFi Deauth攻击的本质:从协议层理解管理帧 当你用手机连接咖啡厅的WiFi时,背后其实在进行一场精密的无线协议对话。802.11标准中定义了三种关键帧类型:数据帧负责传输网页内容,控制帧协调信道占用,而管理帧则是连…...

终极指南:如何彻底禁用iPhone过热降频,告别游戏卡顿和屏幕变暗
终极指南:如何彻底禁用iPhone过热降频,告别游戏卡顿和屏幕变暗 【免费下载链接】thermalmonitordDisabler A tool used to disable iOS daemons. 项目地址: https://gitcode.com/gh_mirrors/th/thermalmonitordDisabler 你是否在玩高画质游戏时突…...

音乐自由革命:如何用MusicFree插件打造你的专属免费音乐宇宙
音乐自由革命:如何用MusicFree插件打造你的专属免费音乐宇宙 【免费下载链接】MusicFreePlugins MusicFree播放插件 项目地址: https://gitcode.com/gh_mirrors/mu/MusicFreePlugins 你是否厌倦了在不同音乐平台间来回切换?是否对VIP限制和付费歌…...

【限时开放】Perplexity医疗知识图谱API密钥申请通道关闭倒计时——全球仅剩47个三甲机构白名单资格
更多请点击: https://intelliparadigm.com 第一章:Perplexity医疗信息搜索 Perplexity 是一款以实时网络检索与引用溯源为核心能力的AI搜索工具,在医疗健康领域展现出独特价值。它不同于传统搜索引擎,能直接解析PubMed、NEJM、CD…...