详解--编码(ASCII\Unicode,UTF-8\UTF-16\UTF-32)
本文主要搞清楚编码是怎么回事。
参考链接
| 字符集 | 编码方式 | |
|---|---|---|
| ASCII(American Standard Code for Information Interchange) | ASCII | |
| GB2312 | GB2312 | |
| Unicode | UTF-8 / UTF-16 / UTF-32 |
1.编码基本概念
1.1 字符
- 字符(Character)
- 在计算机和电信技术中,一个字符是一个单位的字形、类字形单位或符号的基本信息。说的简单点字符是各种文字和符号的总称。
- 一个字符可以是一个中文汉字、一个英文字母、一个阿拉伯数字、一个标点符号、一个图形符号或者控制符号等。
1.2 字符集
- 字符集(Character Set):是指多个字符的集合。不同的字符集包含的字符个数不一样、包含的字符不一样、对字符的编码方式也不一样。
- 当前常用字符集:
- ASCII 字符集
只包含了128字符,这个字符集收录的主要字符是英文字母、阿拉伯字母和一些简单的控制字符。 - GB2312 字符集
是中国国家标准的简体中文字符集,GB2312收录简化汉字(6763个)及一般符号、序号、数字、拉丁字母、日文假名、希腊字母、俄文字母、汉语拼音符号、汉语注音字母,共 7445 个图形字符。 - GBK字符集
- Unicode字符集
- ASCII码字符集,总共才能容纳256个字符,为了包含全世界各国语言的所有字符,后来就出现了Unicode字符集。
- Unicode是为整合全世界的所有语言文字而诞生的。任何文字在Unicode中都对应一个值。现在的规模可以容纳100多万个符号。
- 比如,U+0639 表示阿拉伯字母 Ain,U+0041 表示英语的大写字母 A ,U+4E25 表示汉字“严”。
- GB18030字符集、Big5字符集、等等
- ASCII 字符集
- 当前常用字符集:
1.3 字符编码
-
字符编码(Character Encoding)
字符编码是指一种映射规则,根据这个映射规则可以将某个字符映射成其他形式的数据以便在计算机中存储和传输。- 意义
计算机中数据传输都是二进制的01,那么人要看二进制数据01背后的含义(即看到真正的文本信息),那么就要用到编码。
这也就意味着任何计算机上的文件被打开或查看都要经过一次解码,被存储或传输都要经过一次编码.
- 意义
1.4 码点
- 码点(Code Point):有些地方翻译为 码值 或 内码。
- 是指在某个字符集中,根据某种编码规则将字符编码后得到的值。即编码时 二进制数据 和 字符集的映射关系。
- 例:
比如在ASCII字符集中,字母 A 经过 ASCII 编码得到的值是 65,那么 65 就是字符A在ASCII字符集中的码点。
- 例:
- 是指在某个字符集中,根据某种编码规则将字符编码后得到的值。即编码时 二进制数据 和 字符集的映射关系。
2. 详解编码
2.1 ASCII 字符集和 ASCII 编码
详见上文参考链接
2.2 Unicode 字符集 相关编码(UTF-8 \ UTF-16 \ UTF-32)
2.2.1 了解为什么 unicode 字符集编码分 3 种
- Unicode只是一个字符集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何编码如何存储。因此衍生出如下问题:
- 第一个问题是,如何才能区别Unicode和ASCII?
同时计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢? - 第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果 unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是 0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
- 第一个问题是,如何才能区别Unicode和ASCII?
注意:
- 由上面问题衍生出如下三种编码方式,主要是 存储长度 的区别。
- 不同编码方式能容纳的字符个数取决于编码原理的是实现,而不是依赖于字符集的码点。
2.2.2 UTF-8 格式
-
特点:
变长的编码方式。
它可以使用 1~4 个字节表示一个符号,根据不同的符号而变化字节长度(UTF-8编码可以容纳2^21(为什么这么算看下面编码规则更清晰)个字符,总共200多万个字符)。 -
UTF-8 编码规则;
- 对于单字节的符号,字节的第一位设为 0,后面 7 位为这个符号的 unicode 码。因此对于英语字母,UTF-8编码和 ASCII 码是相同的。(对应下面一个字节)
- 对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。(对应下面二三四个字节)
- 如上UTF-8编码规则方式演示
字节数(变长) UTF 字节数 (十六进制) 二进制 编码提示(我自定义的,为了好理解下面的例子) 一个字节 0000 0000 0000 007F 0xxxxxxx 某字符的unicode字符码点为 7 位(二进制 x 的个数)以下的 两个字节 0000 0080 0000 07FF 110xxxxx 10xxxxxx 某字符的 unicode 字符码点为 11 位(二进制 x 的个数)以下的 三个字节 0000 0800 0000 FFFF 1110xxxx 10xxxxxx 10xxxxxx 某字符的 unicode 字符码点为 16 位(二进制 x 的个数)以下的 四个字节 0001 0000 0010 FFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx 某字符的 unicode 字符码点为 21 位(二进制 x 的个数)以下的 - 按如上 UTF-8 编码规则示例,Unicode 字符集中 “严” 的 UTF-8 编码:
- 已知“严”的 unicode 是 \u4E25(100111000100101),这个可以通过在线工具查看
- 根据上表,可以发现 4E25(100111000100101,共 15 位二进制,满足上文三个字节的编码提示)处在第三行的范围内(0000 0800-0000 FFFF),因此“严”的 UTF-8 编码需要三个字节,即格式是“1110xxxx 10xxxxxx 10xxxxxx”。
- 然后,从“严”的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。
这样就得到了,“严”的UTF-8编码是“11100100 10111000 10100101”,转换成十六进制就是 E4B8A5。
- 按如上 UTF-8 编码规则示例,Unicode 字符集中 “严” 的 UTF-8 编码:
2.2.3 Unicode 中名词 UCS-2 和 UCS-4
- Unicode是为整合全世界的所有语言文字而诞生的。任何文字在Unicode中都对应一个值, 这个值称为码点(code point,也称码值)。 码点的值通常写成 U+ABCD 的格式。
- 而文字和代码点之间的对应关系就是 UCS-2(Universal Character Set coded in 2 octets)。
顾名思义,UCS-2 是用两个字节来表示码点,其取值范围为 U+0000~U+FFFF。 - 为了能表示更多的文字,人们又提出了 UCS-4,即用四个字节表示代码点。它的范围为 U+00000000~U+7FFFFFFF,其中 U+00000000~U+0000FFFF和UCS-2是一样的。
- 而文字和代码点之间的对应关系就是 UCS-2(Universal Character Set coded in 2 octets)。
- 注意
- UCS-2 和 UCS-4 只规定了代码点和文字之间的对应关系,并没有规定代码点在计算机中如何存储。
- 规定存储方式的称为
UTF(Unicode Transformation Format),也就是我们提到的对于 unicode 字符集编码的 UTF8 格式以及UTF16、UTF32格式。
2.2.4 UTF-16 格式
-
它使用
两个字节来表示一个码点,完全对应于UCS-2。
即把 UCS-2 规定的码点通过 Big Endian(大端) 或 Little Endian(小端) 方式直接保存下来。 -
分类,UTF-16包括三种
-
UTF-16
UTF-16 就需要通过在文件开头以名为 BOM(Byte Order Mark)的字符来表明文件是 Big Endian 还是 Little Endian。- BOM为 U+FEFF 这个字符。
其实 BOM 是个小聪明的想法。
由于 UCS-2 没有定义 U+FEFF,因此只要出现 FF FE 或者 FE FF 这样的字节序列,就可以认为它是 U+FEFF,并且可以判断出是 Big Endian 还是 Little Endian。
- BOM为 U+FEFF 这个字符。
-
UTF-16BE(Big Endian)
-
UTF-16LE(Little Endian)
-
-
BOM(Byte Order Mark)用来放在文档的开头告诉阅读器该文档的字节序。
- UTF-8 不需要 BOM 来表明字节顺序,但可以用BOM来表明编码方式。
字符 “ZERO WIDTH NO-BREAK SPACE” 的 UTF-8 编码是 EF BB BF。所以如果接收者收到以 EF BB BF 开头的字节流,就知道这是UTF-8编码了。UTF-16 才需要加 BOM。因为它是按 Unicode 顺序编码,在 BMP 范围内是二字节,需要识别是大或小字节序。
- UTF-8 不需要 BOM 来表明字节顺序,但可以用BOM来表明编码方式。
2.2.4 UTF-32 格式
- UTF-32 用固定
四个字节表示代码点,这样就可以完全表示 UCS-4 的所有代码点,而无需像 UTF-8 那样使用复杂的算法。 - 与UTF-16 类似,UTF-32 也包括 UTF-32、UTF-32BE、UTF-32LE 三种编码,UTF-32 也同样需要BOM字符。
3. 文本编辑器怎么知道文本的编码
- 当一个软件打开一个文本时,它要做的第一件事是决定这个文本究竟是使用哪种字符集的哪种编码保存的。
软件一般采用三种方式来决定文本的字符集和编码:
-
检测文件头标识(BOM)
EF BB BF UTF-8FE FF UTF-16/UCS-2, big endianFF FE UTF-16/UCS-2, little endianFF FE 00 00 UTF-32/UCS-4, little endian.00 00 FE FF UTF-32/UCS-4, big-endian. -
软件自己根据编码规则猜测当前文件的编码
-
提示用户自己输入当前文件的编码
myflag
by 2023.11.03 周一 晚不积跬步无以至千里
相关文章:
)
详解--编码(ASCII\Unicode,UTF-8\UTF-16\UTF-32)
本文主要搞清楚编码是怎么回事。 参考链接 字符集编码方式ASCII(American Standard Code for Information Interchange)ASCIIGB2312GB2312UnicodeUTF-8 / UTF-16 / UTF-32 1.编码基本概念 1.1 字符 字符(Character) 在计算机和…...
Linux安装配置awscli命令行接口工具及其从aws上传下载数据
官网技术文档有全面介绍:安装或更新 AWS CLI 的最新版本 - AWS Command Line Interface在系统上安装 AWS CLI。https://docs.aws.amazon.com/zh_cn/cli/latest/userguide/getting-started-install.html#getting-started-install-instructionsawscli常用命令参考&…...

中国联通携手华为助力长城精工启动商用5G-A柔性产线
[中国,河北,2023年11月3日] 近日,中国联通携手华为助力精诚工科汽车系统有限公司保定自动化技术分公司(简称长城精工自动化)启动5G-A超高可靠性超低时延柔性产线的商用阶段。 在河北保定精工自动化工厂,5G…...
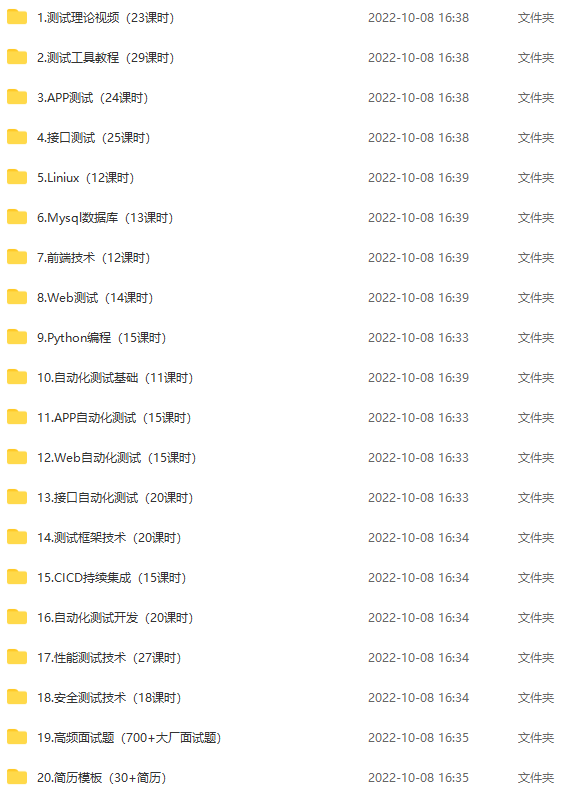
【自动化测试】Java+Selenium自动化测试环境搭建
本主要介绍以Java为基础,搭建Selenium自动化测试环境,并且实现代码编写的过程。 1.Selenium介绍 Selenium 1.0 包含 core、IDE、RC、grid 四部分,selenium 2.0 则是在两位大牛偶遇相互沟通决定把面向对象结构化(OOPP)…...
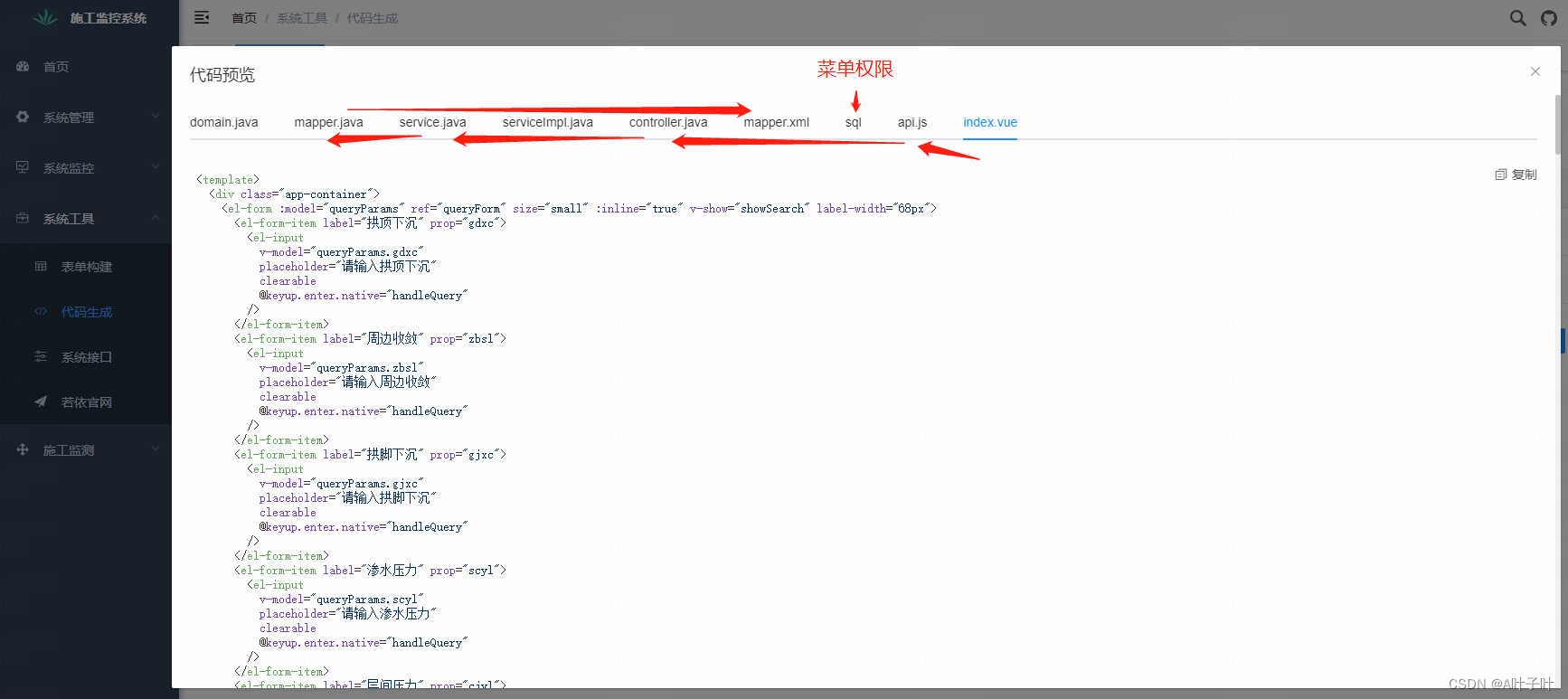
若依笔记(四):代码生成器
已知使用MyBatisPlus代码生成器可以自动生成Entity、Mapper、Service、Controller代码,前提是数据库中有数据表,生成pojo类以及对于该数据表的增删改查命令的代码,若依更进一步能选择表后生成代码、预览、下载,同时可以生产前端代…...

怎样做好金融投资翻译
我们知道, 金融投资翻译所需的译文往往是会议文献、年终报表、信贷审批等重要企业金融资料,其准确性事关整个企业在今后一段时期内的发展战略与经营成效。尤其像年报,对于上市公司来说更是至关重要的。那么,怎样做好金融投资翻译&…...
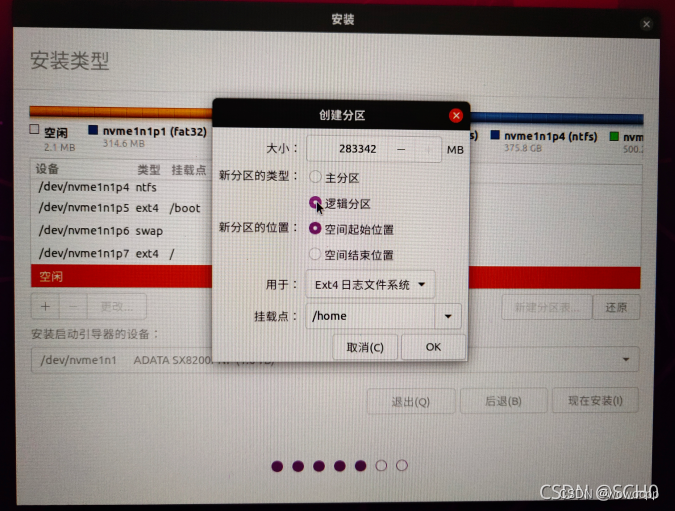
ubuntu 分区 方案
ubuntu 分区 方案 自动分区啥样子的? 手动分区 需要怎么操作? 注意点是啥? swap分区 要和 内存大小 差不多 安装ubuntu系统时硬盘分区方案 硬盘分区概述 一块硬盘最多可以分4个主分区,主分区之外的成为扩展分区。硬盘可以没有…...

Python自动化测试面试题总结
python有哪些数据类型怎么将两个字典合并python如何将json写到文件里?在except语句中return后还会不会执行finally中的代码?什么是可变、不可变类型?python函数调用时参数的传递是值传递还是引用传递?python深浅拷贝的区别python为…...
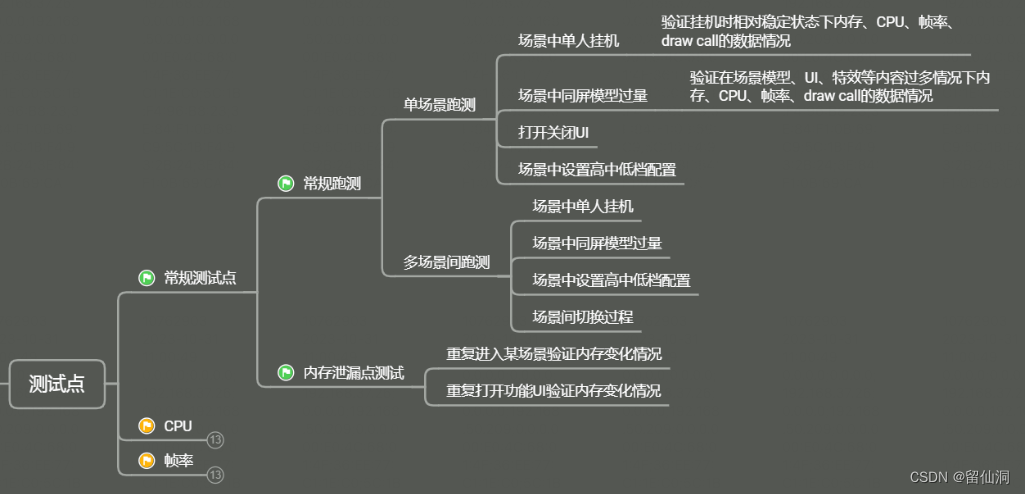
客户端性能测试基础知识
目录 1、客户端性能 1.1、客户端性能基础知识 2、客户端性能工具介绍与环境搭建 2.1.1、perfdog的使用 2.1.2、renderdoc的使用 1、客户端性能 1.1、客户端性能基础知识 客户端性能知识这里对2D和3D类游戏进行展开进行,讲述的有内存、CPU、GPU、帧率这几个模块…...

多模态论文阅读之VLMo
VLMo泛读 TitleMotivationContributionModelExpertimentsSummary Title VLMo:Unified Vision_Langugae Pre-Training with Mixture-of-Modality-Experts Motivation CLIP和ALIGN都采用dual-encoder的方式分别编码图像和文本,模态之间的交互采用cosine similarity…...

休闲类手游还有机会吗?两大策略收割全球玩家
刚刚过去的第三季度,是全球手游市场逆势增长的高光时刻。 买量、营收、下载等多项数据表现优异,其中买量最为突出的产品是休闲类游戏,广告主数占比23.76%断层第一,广告素材占比17.62%,是当之无愧的“广告顶流”。 数…...

Git复制代码
目录 一、常用下载代码 1.登录Git克隆SSH编辑 2.新建文件然后右键点击Git Bash Here 3.git clone Paste 二. 本地下载 1.从本地进入页面 2.生成代码——>导入——>生成代码后下载 3.解压道相应位置 一、常用下载代码 1.登录Git克隆SSH 2.新建文件然后右键点击…...

数据结构笔记——查找、排序(王道408)
文章目录 查找基本概念线性表查找顺序查找折半查找(二分)分块查找 树查找二叉排序树(BST)平衡二叉树(AVL)的插入平衡化复杂度分析 平衡二叉树的删除 红黑树红黑树的定义和性质红黑树定义红黑树性质 红黑树的…...
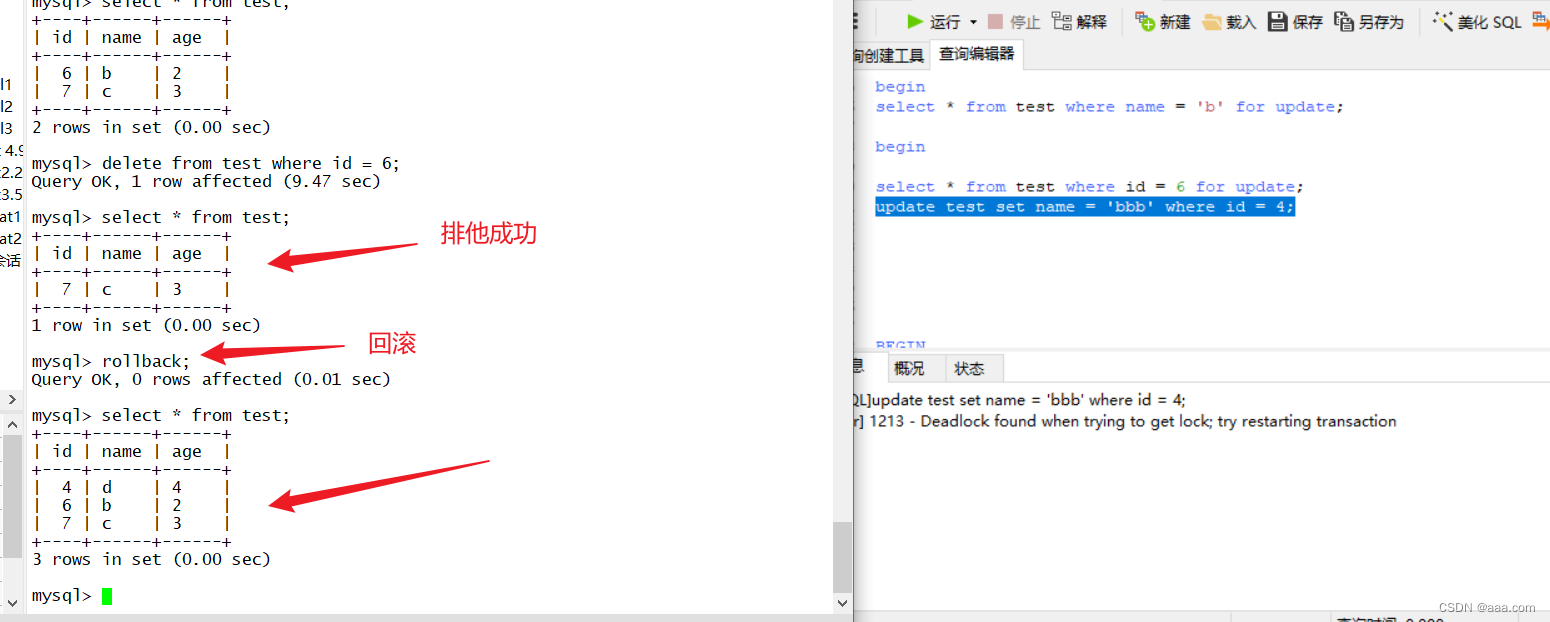
MySQL---搜索引擎
MySQL的存储引擎是什么 MySQL当中数据用各种不同的技术存储在文件中,每一种技术都使用不同的存储机制,索引技巧 锁定水平,以及最终提供的不同的功能和能力,这些就是我们说的存储引擎。 MySQL存储引擎的功能 1.MySQL将数据存储在文…...
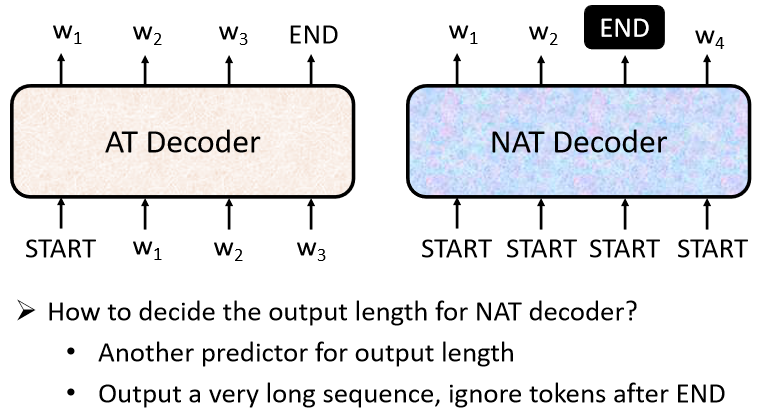
2022最新版-李宏毅机器学习深度学习课程-P32 Transformer
一、 seq2seq 1. 含义 输入一个序列,机器输出另一个序列,输出序列长度由机器决定。 文本翻译:文本至文本; 语音识别:语音至文本; 语音合成:文本至语音; 聊天机器人&#…...

如何使用商品详情API接口获取商品数据:一篇详尽的论述
一、引言 商品详情API接口是一种用于获取商品详细信息的应用程序接口。通过调用该接口,我们可以获取商品的名称、价格、描述、图片以及其他相关属性。对于电商平台、价格比较网站、数据分析等应用场景来说,商品详情API接口提供了便捷的数据获取方式。本…...

华为:手机王者归来,汽车起死回生
作为一家全球知名的科技公司,华为在通信、智能手机、平板电脑等领域拥有很高的市场份额和品牌影响力。而随着华为开始进军汽车领域,通过自主研发和合作,不断提升自己在汽车领域的竞争力,华为便也开始受到更为广泛的关注。 只不过…...

Vue3.0 provide与inject依赖注入:VCA
简介 provide 与 inject 是一种跨层级组件(祖孙)通信方式。当组件多层嵌套时,不需要将数据一层一层的向下传递,通过它俩可以实现跨层级组件通信。 provide:提供者 注入一个值,可以被后代组件接收。 prov…...

前端react入门day02-React中的事件绑定与组件
(创作不易,感谢有你,你的支持,就是我前行的最大动力,如果看完对你有帮助,请留下您的足迹) 目录 React中的事件绑定 React 基础事件绑定 使用事件对象参数 传递自定义参数 同时传递事件对象和自定义参…...

工业5G路由器;小体积 千兆高速通信组网
计讯物联工业路由器TR232,5G高速网络,超低时延、高可靠性,小体积、易安装、强兼容,串口/网口多设备接入联网,为用户提供高速稳定的数据传输通道 。 小体积5G工业路由器TR323,外形1047824mm࿰…...

如何高效使用Avogadro 2:5个实用技巧带你掌握开源分子建模软件
如何高效使用Avogadro 2:5个实用技巧带你掌握开源分子建模软件 【免费下载链接】avogadroapp Avogadro is an advanced molecular editor designed for cross-platform use in computational chemistry, molecular modeling, bioinformatics, materials science, an…...
)
解放双手!用STAR-CCM+的3D-CAD模块快速清理与简化仿真几何(保姆级教程)
解放双手!用STAR-CCM的3D-CAD模块快速清理与简化仿真几何(保姆级教程) 在CAE仿真领域,几何模型的质量往往直接决定仿真效率与结果可靠性。许多工程师都有过这样的经历:从设计部门拿到一个细节完美的CAD模型,…...

为Claude Code配置Taotoken作为备用模型服务商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置Taotoken作为备用模型服务商 对于经常使用Claude Code进行编程辅助的开发者而言,直接依赖单一服务商…...

为什么英语是编程最重要的前置技能?Newbie-Guideline揭示成功秘诀
为什么英语是编程最重要的前置技能?Newbie-Guideline揭示成功秘诀 【免费下载链接】Newbie-Guideline 컴퓨터과학/공학 신입생 및 비전공자 신입을 위한 지침서 项目地址: https://gitcode.com/gh_mirrors/ne/Newbie-Guideline 在编程学习的道路上࿰…...

GPT-4高考全真模拟测试:能力边界、技术原理与教育启示
1. 项目缘起与核心目标最近,我身边不少朋友,尤其是家里有考生的,都在讨论一个话题:现在这些大语言模型,比如GPT-4,到底有多“聪明”?它能不能像人一样思考,甚至去参加我们的高考&…...

国产电池包传感监测芯片:从AFE设计到BMS系统实战解析
1. 项目概述:从“芯”守护,让每一度电都安全在电动汽车的心脏——动力电池包里,温度、电压、电流这些关键参数哪怕出现一丝一毫的异常,都可能从量变引发质变,最终导致热失控等严重安全事故。因此,对电池包内…...

从无人机云台到机械臂关节:聊聊FOC力矩控制在机器人里的那些实战坑
从无人机云台到机械臂关节:FOC力矩控制在机器人中的实战精要 当无人机云台在强风中依然保持画面稳定,当机械臂关节能够感知鸡蛋壳的脆弱并精准施力——这些看似简单的动作背后,都离不开一项关键技术:磁场定向控制(FOC&…...

auditd:Linux 系统审计日志,记录谁动了你的服务器
auditd:Linux 系统审计日志,记录谁动了你的服务器 服务器被入侵后,管理员面临的第一个问题往往不是"怎么修复",而是"到底发生了什么"——攻击者登录了哪个账号?修改了哪些文件?执行了什…...

自动驾驶汽车三维路径规划与路径跟踪控制方法【附代码】
✨ 长期致力于自动驾驶汽车、三维路径规划、路径跟踪控制、深度强化学习、预瞄跟随、模糊推理、神经网络模型预测控制研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 ࿰…...

如何用开源工具LibreDWG解决CAD文件格式兼容性问题?
如何用开源工具LibreDWG解决CAD文件格式兼容性问题? 【免费下载链接】libredwg Official mirror of libredwg. With CI hooks and nightly releases. PRs ok 项目地址: https://gitcode.com/gh_mirrors/li/libredwg 你是否曾遇到过不同CAD软件之间无法互相打…...