探索主题建模:使用LDA分析文本主题
在数据分析和文本挖掘领域,主题建模是一种强大的工具,用于自动发现文本数据中的隐藏主题。Latent Dirichlet Allocation(LDA)是主题建模的一种常用技术。本文将介绍如何使用Python和Gensim库执行LDA主题建模,并探讨主题建模的各个方面。
什么是主题建模?
主题建模是一种用于从文本数据中提取主题或话题的技术。主题可以被视为文本数据的概括性描述,它们涵盖了文本中的关键概念。主题建模可以应用于各种领域,如文档分类、信息检索、推荐系统等。
LDA的应用场景
LDA(潜在狄利克雷分配)模型在自然语言处理(NLP)领域中有广泛的应用,以下是一些常见的应用场景.
- 特征生成:LDA可以生成特征供其他机器学习算法使用。例如,LDA为每一篇文章推断一个主题分布;K个主题即是K个数值特征,这些特征可以被用在像逻辑回归或者决策树这样的算法中用于预测任务。
- 新闻质量分类:新闻APP通过各种来源获得到的新闻的质量良莠不齐。我们可以人工设计一些传统特征:新闻来源站点、新闻内容长度、图片数量、新闻热度等等。除了这些人工特征,也可利用主题模型来计算每篇新闻的主题分布,作为附加特征与人工特征一起组成新特征集合。
- 短文本-短文本语义匹配:短文本-短文本的语义匹配在工业界的应用场景非常广泛。例如,在网页搜索中,我们需要度量用户查询 (query) 和网页标题 (web page title) 的语义相关性;在query推荐中,我们需要度量query和其他query之间的相似度。
- 短文本-长文本语义匹配:短文本-长文本语义匹配的应用场景在工业界非常普遍。例如,在搜索引擎中,我们需要计算一个用户查询(query)和一个网页正文(content)的语义相关度。
- 长文本-长文本语义匹配:通过使用主题模型,我们可以得到两个长文本的主题分布,再通过计算两个多项分布的距离来衡量它们之间的相似度。
- 新闻个性化推荐:长文本-长文本的语义匹配可用于个性化推荐的任务中。例如,在新闻个性化推荐中,我们可以将用户近期阅读的新闻(或新闻标题)合并成一篇长“文档”,并将该“文档”的主题分布作为表达用户阅读兴趣的用户画像。
- 垂类新闻CTR预估:新闻推荐服务涉及多个垂类新闻方向,如体育、汽车、娱乐等。在这些方向上,我们往往需要做更精细的个性化推荐。
使用LDA进行主题建模
Latent Dirichlet Allocation(LDA)是一种用于主题建模的概率图模型。它的基本思想是,每个文档是由一组主题混合而成的,每个主题又由一组词汇构成。LDA试图找到最佳的主题和词汇组合,以解释给定的文本数据。
对底层逻辑感兴趣的掘友们可以参考这些文章:
https://zhuanlan.zhihu.com/p/309419680
https://zhuanlan.zhihu.com/p/31470216
以下是如何使用Python和Gensim库执行LDA主题建模的步骤:
步骤1:文本预处理
在进行主题建模之前,需要对文本进行预处理。这包括分词、去除停用词和标点符号等。分词可以使用工具如jieba,去除停用词可以使用nltk库。
样例:
# 中文文本分词
def tokenize(text):return list(jieba.cut(text))# 删除中文停用词
def delete_stopwords(text,tokens):# 分词words = tokens # 假设你已经有分好词的文本,如果没有,你可以使用jieba等工具进行分词# 加载中文停用词stop_words = set(stopwords.words('chinese'))# 去除停用词filtered_words = [word for word in words if word not in stop_words]# 重建文本filtered_text = ' '.join(filtered_words)return filtered_text
def remove_punctuation(input_string):import string# 制作一个映射表,其中所有的标点符号都被映射为Noneall_punctuation = string.punctuation + "!?。。"#$%&'()*+,-/:;<=>@[\]^_`{|}~⦅⦆「」、、〃》「」『』【】〔〕〖〗〘〙〚〛〜〝〞〟〰〾〿–—‘’‛“”„‟…‧﹏.\t "translator = str.maketrans('', '', all_punctuation)# 使用映射表来移除所有的标点符号no_punct = input_string.translate(translator)return no_punct
这些函数可以用于文本预处理,以准备文本数据进行自然语言处理任务。以下是函数的说明:
- tokenize(text) : 这个函数使用jieba分词库来将中文文本分成词语。它接受一个文本字符串作为输入,返回一个包含分词结果的列表。
- delete_stopwords(text, tokens) : 这个函数用于删除中文文本中的停用词。它接受两个参数,文本字符串和分好词的文本(词语列表)。函数首先加载了中文停用词表,然后将文本中的停用词去除,最后返回一个去除停用词后的文本字符串。
- remove_punctuation(input_string) : 这个函数用于去除文本中的标点符号。它使用一个映射表,将所有标点符号映射为None,从而删除它们。最后,它返回一个去除标点符号后的文本字符串。
这样就完成了简单的数据预处理.
步骤2:创建字典和文档-词频矩阵
LDA 采用词袋模型。所谓词袋模型,是将一篇文档,我们仅考虑一个词汇是否出现,而不考虑其出现的顺序。在词袋模型中,“我喜欢你”和“你喜欢我”是等价的。与词袋模型相反的一个模型是n-gram,n-gram考虑了词汇出现的先后顺序。
使用Gensim库,可以创建文档的字典和文档-词频矩阵。字典包含了所有文档中的词汇,而文档-词频矩阵表示每个文档中每个词汇的词频。
# 创建字典和文档-词频矩阵
dictionary = corpora.Dictionary([tokens])
corpus = [dictionary.doc2bow(tokens)]
- dictionary = corpora.Dictionary([tokens]) : 这行代码创建了一个文档的词汇表(Dictionary)。词汇表用于将文本中的词语映射到唯一的ID。tokens 是一个包含分好词的文本数据的列表。创建词汇表是为了建立每个词语与一个唯一ID之间的映射,以便后续处理。
- corpus = [dictionary.doc2bow(tokens)] : 这行代码创建了文档-词频矩阵(Corpus)。corpus 是一个包含文档的列表,每个文档都表示为一个词袋(Bag of Words),其中包含了文档中每个词语的ID和词频。doc2bow 方法将文档中的词语转化为词袋表示。
为方便理解这两个类型的数据结构,参考下面代码样例演示:
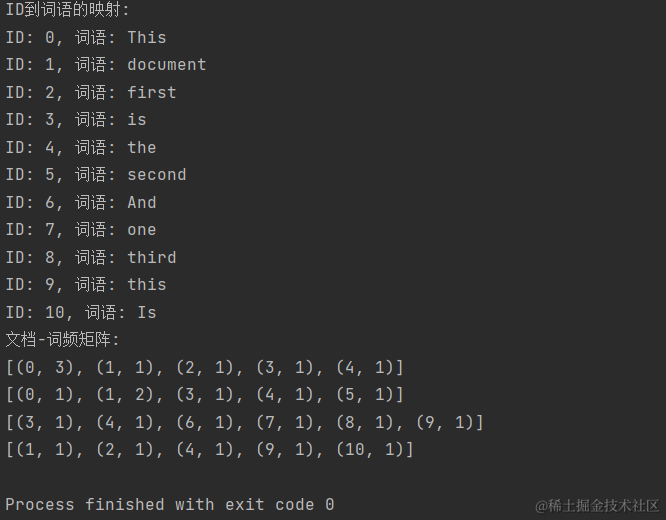
def test():from gensim import corpora# 创建一个样本文本数据sample_texts = ["This is the first document This This ","This document is the second document ","And this is the third one ","Is this the first document "]# 分词并创建词汇表tokenized_texts = [text.split() for text in sample_texts]dictionary = corpora.Dictionary(tokenized_texts)# 获取词汇表中的词语到ID的映射word_to_id = dictionary.token2id# 获取ID到词语的映射id_to_word = {v: k for k, v in word_to_id.items()}# 打印ID到词语的映射print("ID到词语的映射:")for word_id, word in id_to_word.items():print(f"ID: {word_id}, 词语: {word}")# 创建文档-词频矩阵corpus = [dictionary.doc2bow(tokens) for tokens in tokenized_texts]# 打印文档-词频矩阵print("文档-词频矩阵:")for doc in corpus:print(doc)
运行结果为
步骤3:运行LDA模型
使用Gensim的LdaModel类,可以运行LDA模型。需要指定主题数量、字典和文档-词频矩阵作为输入参数。模型将自动学习主题和词汇的分布。
# 运行LDA模型
lda_model = models.LdaModel(corpus, num_topics=15, id2word=dictionary, passes=50)
- num_topics 表示预期生成的主题数量。在LDA中,这是一个需要预先指定的超参数。我们需要根据你的数据和分析目标来选择合适的主题数量。通常,我们可以根据领域知识或试验来确定主题数量。
- passes 是模型的迭代次数。LDA模型通过多次迭代来优化主题的分布以及文档-主题和词语-主题的分布。增加 passes 的值通常会提高模型的性能,但也会增加训练时间。通常情况下,10-50 之间的 passes 值是常见的选择,具体取决于数据集的大小和复杂性。
步骤4:提取主题
一旦模型训练完成,可以使用show_topics方法提取主题。每个主题由一组高权重词汇表示。
# 提取主题
topics = lda_model.show_topics(num_words=8)# 输出主题
for topic in topics:print(topic)
如下所示:
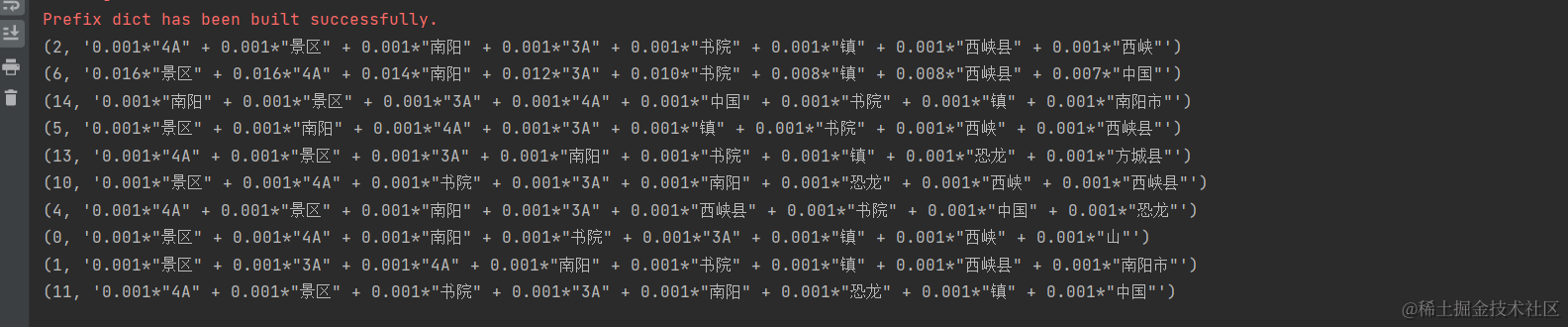
前边的序号为主题id,后边的词是主题相关词,相关词前边的是该相关词在主题中的权重.
步骤5:结果分析
最后,对提取的主题进行分析和解释。可以查看高权重词汇,了解主题的内容,以及使用主题模型进行文档分类、信息检索等应用。
如何保存和加载模型
在实际应用中,通常需要保存训练好的LDA模型,以便下次使用。可以使用Gensim的save和load方法来保存和加载模型。
保存模型:
from gensim import corpora, models
import os# 假设你已经有一个语料库 `corpus` 和字典 `dictionary`,以及训练好的 LDA 模型 `lda_model`# 保存字典
dictionary.save("my_dictionary.dict")# 保存语料库
corpora.MmCorpus.serialize("my_corpus.mm", corpus)# 保存 LDA 模型
lda_model.save("my_lda_model.model")
加载模型:
from gensim import corpora, models# 加载字典
dictionary = corpora.Dictionary.load("my_dictionary.dict")# 加载语料库
corpus = corpora.MmCorpus("my_corpus.mm")# 加载 LDA 模型
lda_model = models.LdaModel.load("my_lda_model.model")
权重值的作用
在LDA模型中,每个词汇都有一个权重值,表示它在主题中的重要性。这些权重值可以用于主题识别、文档分类和信息检索。高权重词汇通常与主题相关,因此可以帮助理解主题内容,或是建立主题词云图.
总结
主题建模是文本挖掘领域的重要技术,可以自动发现文本数据中的主题。LDA是一种常用的主题建模方法,可以通过Python和Gensim库进行实现。通过文本预处理、模型训练和结果分析,可以有效地提取文本数据中的隐藏主题,用于各种应用。
相关文章:
探索主题建模:使用LDA分析文本主题
在数据分析和文本挖掘领域,主题建模是一种强大的工具,用于自动发现文本数据中的隐藏主题。Latent Dirichlet Allocation(LDA)是主题建模的一种常用技术。本文将介绍如何使用Python和Gensim库执行LDA主题建模,并探讨主题…...

服务器黑洞,如何秒解
想必这样的短信大家都应该见过吧,这其实是阿里云服务器被攻击后触发的黑洞机制的短信通知。还有很多朋友不知道,为什么要这么做。原因其实很简单啊,当同一个机房的ip段,如果说有一台服务器遭受低道攻击,那么很可能会造…...
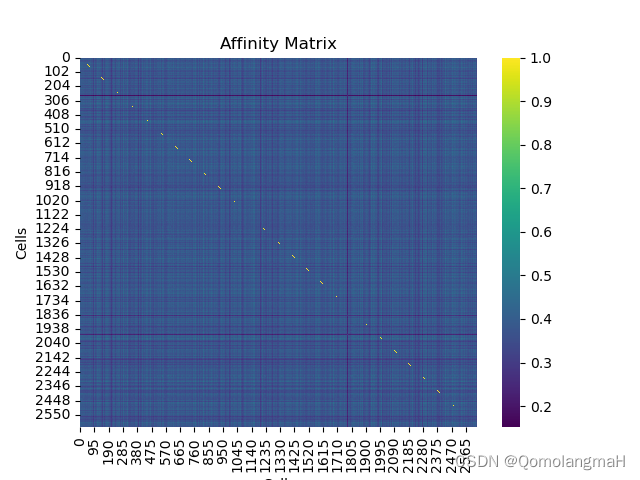
【生物信息学】单细胞RNA测序数据分析:计算亲和力矩阵(基于距离、皮尔逊相关系数)及绘制热图(Heatmap)
文章目录 一、实验介绍二、实验环境1. 配置虚拟环境2. 库版本介绍 三、实验内容0. 导入必要的库1. 读取数据集2. 质量控制(可选)3. 基于距离的亲和力矩阵4. 绘制基因表达的Heatmap5. 基于皮尔逊相关系数的亲和力矩阵6. 代码整合 一、实验介绍 计算亲和力…...
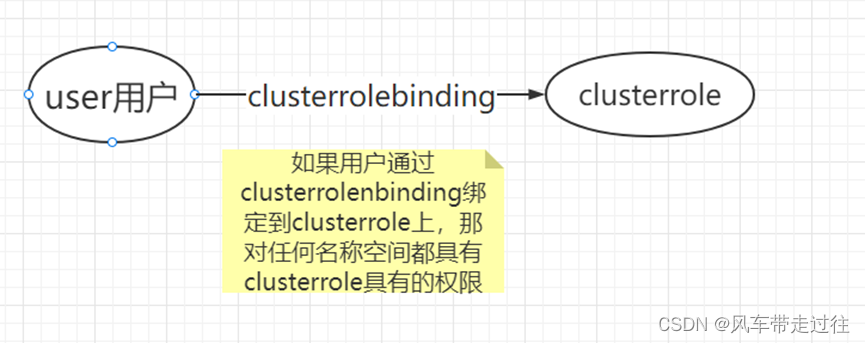
学习笔记三十一:k8s安全管理:认证、授权、准入控制概述SA介绍
K8S安全实战篇之RBAC认证授权-v1 k8s安全管理:认证、授权、准入控制概述认证k8s客户端访问apiserver的几种认证方式客户端认证:BearertokenServiceaccountkubeconfig文件 授权Kubernetes的授权是基于插件形成的,其常用的授权插件有以下几种&a…...

【开发新的】apache common BeanUtils忽略null值
前言: BeanUtils默认的populate方法不会忽略空值和null值,在特定场景,我们需要原始的值避免被覆盖,所以这里提供一种自定义实现方式。 package com.hmwl.service.program;import lombok.extern.slf4j.Slf4j; import org.apache.commons.beanu…...

coalesce函数(SQL )
用途: 将控制替换成其他值;返回第一个非空值 表达式 COALESCE是一个函数, (expression_1, expression_2, …,expression_n)依次参考各参数表达式,遇到非null值即停止并返回该值。如果所有的表达式都是空值,最终将返…...

一键报警可视对讲管理机10寸触摸屏管理机
一键报警可视对讲管理机10寸触摸屏管理机 一、管理机技术指标: 1、10寸LCD触摸屏,分辨率1024*600; 2、摄像头1200万像素 3、1000M/100M自适应网口; 4、按键设置:报警/呼叫按键,通话/挂机按键࿰…...

java左右括号
java左右括号 数据结构-栈栈的特点:先进后出代码实现 最近看到有小伙伴去面试,被人问起一道算法题,题目内容大概是:给定一个字符串,如:“[[]]{}”,判断字符串是否为有效的括号。考查的是数据结构…...

接口自动化测试 —— 工具、请求与响应
一、工具: 1.工具介绍 postman :很主流的API测试工具,也是工作里面使用最广泛的研发工具。 JMeter: ApiPost: 2.安装postman: 安装好直接打开,不用注册。 二、通信模式: 1、…...

【LeetCode:2103. 环和杆 | 模拟】
🚀 算法题 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,…...
微信小程序-授权登录(手机号码)
1、WXBizDataCrypt.js-下载地址 2、UNIAPP代码 <template> <view class"work-container"> <view class"login"> <view class"content"> <button class"button_wx&q…...

视觉问答(VQA)12篇顶会精选论文合集,附常用数据集下载
今天来聊聊计算机视觉和自然语言处理交叉的一个热门研究方向:视觉问答(VQA)。 视觉问答的任务是:给出一张图片和一个关于这张图片的自然语言问题,计算机需要根据图片的内容自动回答这个问题。这样的任务考验了计算机在…...
)
详解--编码(ASCII\Unicode,UTF-8\UTF-16\UTF-32)
本文主要搞清楚编码是怎么回事。 参考链接 字符集编码方式ASCII(American Standard Code for Information Interchange)ASCIIGB2312GB2312UnicodeUTF-8 / UTF-16 / UTF-32 1.编码基本概念 1.1 字符 字符(Character) 在计算机和…...
Linux安装配置awscli命令行接口工具及其从aws上传下载数据
官网技术文档有全面介绍:安装或更新 AWS CLI 的最新版本 - AWS Command Line Interface在系统上安装 AWS CLI。https://docs.aws.amazon.com/zh_cn/cli/latest/userguide/getting-started-install.html#getting-started-install-instructionsawscli常用命令参考&…...

中国联通携手华为助力长城精工启动商用5G-A柔性产线
[中国,河北,2023年11月3日] 近日,中国联通携手华为助力精诚工科汽车系统有限公司保定自动化技术分公司(简称长城精工自动化)启动5G-A超高可靠性超低时延柔性产线的商用阶段。 在河北保定精工自动化工厂,5G…...
【自动化测试】Java+Selenium自动化测试环境搭建
本主要介绍以Java为基础,搭建Selenium自动化测试环境,并且实现代码编写的过程。 1.Selenium介绍 Selenium 1.0 包含 core、IDE、RC、grid 四部分,selenium 2.0 则是在两位大牛偶遇相互沟通决定把面向对象结构化(OOPP)…...
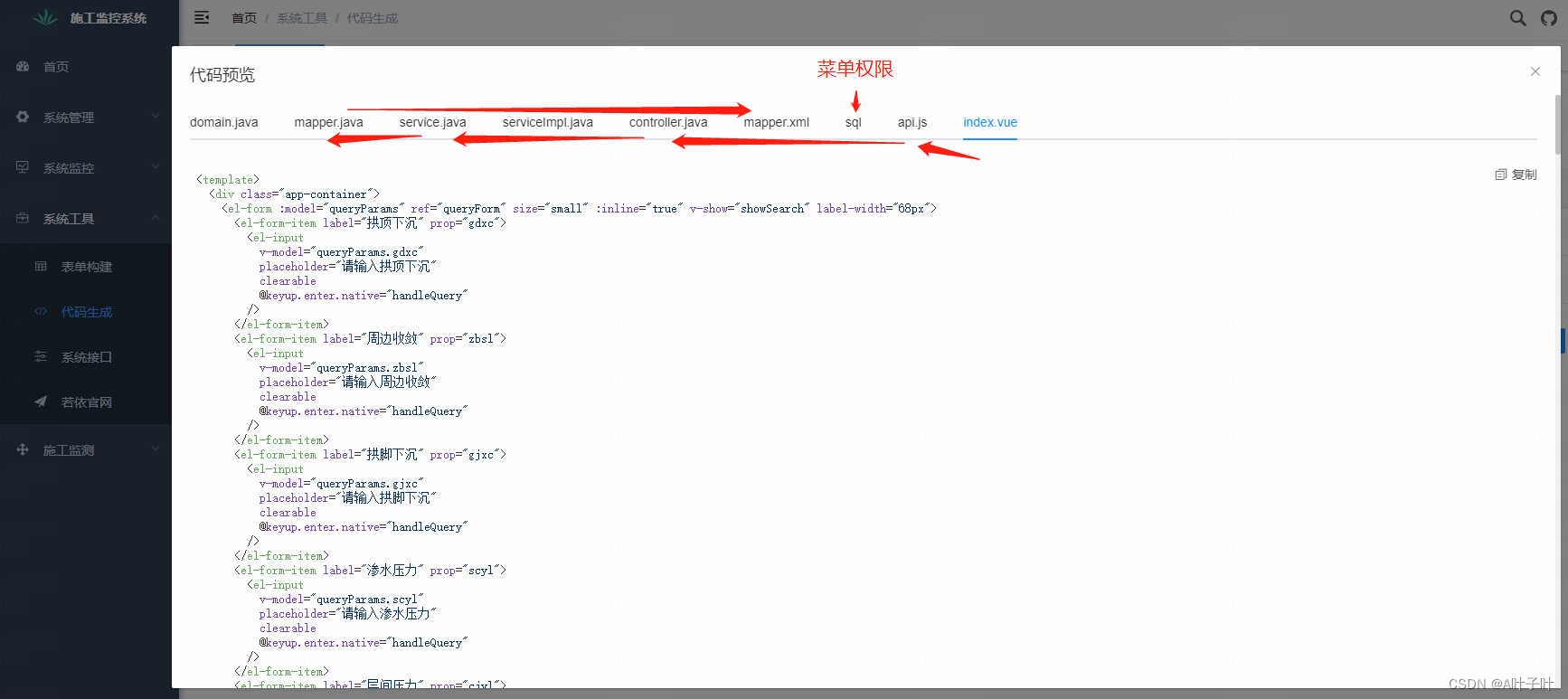
若依笔记(四):代码生成器
已知使用MyBatisPlus代码生成器可以自动生成Entity、Mapper、Service、Controller代码,前提是数据库中有数据表,生成pojo类以及对于该数据表的增删改查命令的代码,若依更进一步能选择表后生成代码、预览、下载,同时可以生产前端代…...

怎样做好金融投资翻译
我们知道, 金融投资翻译所需的译文往往是会议文献、年终报表、信贷审批等重要企业金融资料,其准确性事关整个企业在今后一段时期内的发展战略与经营成效。尤其像年报,对于上市公司来说更是至关重要的。那么,怎样做好金融投资翻译&…...
ubuntu 分区 方案
ubuntu 分区 方案 自动分区啥样子的? 手动分区 需要怎么操作? 注意点是啥? swap分区 要和 内存大小 差不多 安装ubuntu系统时硬盘分区方案 硬盘分区概述 一块硬盘最多可以分4个主分区,主分区之外的成为扩展分区。硬盘可以没有…...

Python自动化测试面试题总结
python有哪些数据类型怎么将两个字典合并python如何将json写到文件里?在except语句中return后还会不会执行finally中的代码?什么是可变、不可变类型?python函数调用时参数的传递是值传递还是引用传递?python深浅拷贝的区别python为…...

从PyTorch到边缘设备:手把手教你用OpenVINO优化YOLOv5模型并在Jetson Orin上部署
从PyTorch到边缘设备:OpenVINO优化YOLOv5模型与Jetson Orin部署实战 在工业质检、智慧零售等实时场景中,将YOLOv5这类目标检测模型部署到Jetson Orin等边缘设备时,开发者常面临三大挑战:模型体积臃肿导致内存不足、计算资源有限影…...

嵌入式开发实战:软硬件协同设计与深度调试指南
1. 项目概述:嵌入式开发,一场与硬件的深度对话 干了十几年嵌入式,我越来越觉得,这行当本质上就是一场开发者与硬件之间旷日持久的“对话”。你写的每一行代码,最终都要落到那块小小的电路板上,去驱动LED闪烁…...

FPGA与Jetson异构计算:破解机器视觉高带宽实时处理难题
1. 项目概述:当FPGA遇上Jetson,一台为视觉而生的“小钢炮”在机器视觉和工业检测这个行当里干了十几年,我经手过不少号称“高性能”的嵌入式系统。它们要么是体积硕大、功耗惊人的工控机,要么是接口单一、扩展性堪忧的嵌入式板卡。…...

智能车竞赛光电组核心技术解析:从图像处理到PID控制
1. 项目概述:从“智能车”到“光电组”的硬核竞技如果你对嵌入式、自动控制或者机器人竞赛感兴趣,那么“智能车竞赛”这个名字你一定不陌生。它远不止是几个大学生拿着遥控车在赛道上跑圈那么简单,而是一个融合了机械、电子、控制、算法和计算…...

CVAT教程
ubuntu服务器部署 https://blog.csdn.net/qq_48187848/article/details/146040443?spm1001.2101.3001.6661.1&utm_mediumdistribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogOpenSearchComplete%7ERate-1-146040443-blog-145734432.235%5Ev43%5Epc_blog_bottom…...

如何在PowerPoint中高效使用LaTeX进行数学公式排版
如何在PowerPoint中高效使用LaTeX进行数学公式排版 【免费下载链接】latex-ppt Use LaTeX in PowerPoint 项目地址: https://gitcode.com/gh_mirrors/la/latex-ppt 对于需要制作学术演示文稿的科研人员、教师和学生来说,在PowerPoint中排版复杂的数学公式一直…...

Vue3组合式API进阶:深入理解和高效使用Composition API
Vue3组合式API进阶:深入理解和高效使用Composition API 前言 大家好,我是前端老炮儿!今天咱们来聊聊Vue3组合式API的进阶用法。 你以为ref和reactive就够了?那你可太天真了!Vue3的Composition API远比你想象的更强大。…...

电子制造工厂场景,AI自动化方案主流厂商横评:2026年智慧工厂选型深度解析
站在2026年的时间节点回看,电子制造工厂的数字化转型已完成从“单点自动化”向“系统智能化”的跨越。 随着全球供应链波动的常态化,AI自动化方案已不再是锦上添花的“实验室项目”, 而是关乎企业在0.1毫米精度竞争中能否生存的底层基座。 根…...

歌词滚动姬终极指南:免费快速制作专业LRC歌词的完整教程
歌词滚动姬终极指南:免费快速制作专业LRC歌词的完整教程 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 歌词滚动姬(LRC Maker)是…...

智在记录 AI 语音转文字效果全景展示
在日常的工作和生活中,我们常常面临这样的困境:一场长达两小时的头脑风暴会议结束后,整理纪要却要花掉半天时间;课堂上老师语速飞快,笔记记得手忙脚乱,回头复习时却发现关键逻辑断档;或是医生叮…...