论文辅助笔记:t2vec models.py
1 EncoderDecoder
1.1 _init_
class EncoderDecoder(nn.Module):def __init__(self, vocab_size, embedding_size,hidden_size, num_layers, dropout, bidirectional):super(EncoderDecoder, self).__init__()self.vocab_size = vocab_size #词汇表大小self.embedding_size = embedding_size #词向量嵌入的维度大小## the embedding shared by encoder and decoderself.embedding = nn.Embedding(vocab_size, embedding_size,padding_idx=constants.PAD)#词向量嵌入层self.encoder = Encoder(embedding_size, hidden_size, num_layers,dropout, bidirectional, self.embedding)#编码器self.decoder = Decoder(embedding_size, hidden_size, num_layers,dropout, self.embedding)#解码器self.num_layers = num_layers1.2 load_pretrained_embedding
从指定的路径加载预训练的词嵌入权重,并将这些权重复制到模型中的 embedding 层
def load_pretrained_embedding(path):if os.path.isfile(path):w = torch.load(path)#加载预训练的嵌入权重到变量 wself.embedding.weight.data.copy_(w)#将加载的权重 w 复制到模型的嵌入层1.3 encoder_hn2decoder_h0
'''
转换编码器的输出隐藏状态
'''
def encoder_hn2decoder_h0(self, h):"""Input:编码器的输出隐藏状态h (num_layers * num_directions, batch, hidden_size): encoder output hn---Output: 解码器的初始隐藏状态h (num_layers, batch, hidden_size * num_directions): decoder input h0"""if self.encoder.num_directions == 2:num_layers, batch, hidden_size = h.size(0)//2, h.size(1), h.size(2)#根据输入 h 的形状计算 num_layers, batch 和 hidden_sizereturn h.view(num_layers, 2, batch, hidden_size)\.transpose(1, 2).contiguous()\.view(num_layers, batch, hidden_size * 2)'''使用 view 方法将 h 重塑为形状 (num_layers, 2, batch, hidden_size)。这里的 2 对应于双向RNN的两个方向使用 transpose 交换第2和第3维使用 contiguous 确保张量在内存中是连续的使用 view 方法再次重塑张量,将两个方向的隐藏状态连接在一起,形成形状 (num_layers, batch, hidden_size * 2) 的张量'''else:return hpytorch笔记:contiguous &tensor 存储知识_pytorch中的tensor存储是列主布局还是行主布局_UQI-LIUWJ的博客-CSDN博客
1.4 forward
def forward(self, src, lengths, trg):"""Input:src (src_seq_len, batch): source tensor 源序列lengths (1, batch): source sequence lengths 源序列的长度trg (trg_seq_len, batch): target tensor, the `seq_len` in trg is notnecessarily the same as that in src 目标序列需要注意的是,目标序列的长度并不一定与源序列的长度相同---Output:output (trg_seq_len, batch, hidden_size)"""encoder_hn, H = self.encoder(src, lengths)#将源序列src和其长度lengths传递给编码器decoder_h0 = self.encoder_hn2decoder_h0(encoder_hn)#将编码器的输出隐藏状态encoder_hn转换为适合解码器的初始隐藏状态decoder_h0。## for target we feed the range [BOS:EOS-1] into decoderoutput, decoder_hn = self.decoder(trg[:-1], decoder_h0, H)return output2 Encoder
2.1 init
class Encoder(nn.Module):def __init__(self, input_size, hidden_size, num_layers, dropout,bidirectional, embedding):"""embedding (vocab_size, input_size): pretrained embedding"""super(Encoder, self).__init__()self.num_directions = 2 if bidirectional else 1#根据 bidirectional 参数决定方向数量assert hidden_size % self.num_directions == 0self.hidden_size = hidden_size // self.num_directionsself.num_layers = num_layersself.embedding = embeddingself.rnn = nn.GRU(input_size, self.hidden_size,num_layers=num_layers,bidirectional=bidirectional,dropout=dropout)2.2 forward
'''
数据在编码器中的传播方式,并且考虑了序列的真实长度以处理填充
'''
def forward(self, input, lengths, h0=None):"""Input:input (seq_len, batch): padded sequence tensorlengths (1, batch): sequence lengthsh0 (num_layers*num_directions, batch, hidden_size): initial hidden state---Output:hn (num_layers*num_directions, batch, hidden_size):the hidden state of each layeroutput (seq_len, batch, hidden_size*num_directions): output tensor"""# (seq_len, batch) => (seq_len, batch, input_size)embed = self.embedding(input)#将输入序列索引转换为嵌入表示#input(seq_len,batch)->embed(seq_len,batch,self.embedding_size)lengths = lengths.data.view(-1).tolist()if lengths is not None:embed = pack_padded_sequence(embed, lengths)#使用pack_padded_sequence对填充的序列进行打包,以便RNN可以跳过填充项output, hn = self.rnn(embed, h0)#将嵌入的序列传递给GRU RNNif lengths is not None:output = pad_packed_sequence(output)[0]#使用pad_packed_sequence对输出序列进行解包,得到RNN的完整输出return hn, outputpytorch 笔记:PAD_PACKED_SEQUENCE 和PACK_PADDED_SEQUENCE-CSDN博客
pytorch笔记:PackedSequence对象送入RNN-CSDN博客
3 Decoder
3.1 init
def __init__(self, input_size, hidden_size, num_layers, dropout, embedding):super(Decoder, self).__init__()self.embedding = embeddingself.rnn = StackingGRUCell(input_size, hidden_size, num_layers,dropout)self.attention = GlobalAttention(hidden_size)self.dropout = nn.Dropout(dropout)self.num_layers = num_layers3.2 forward
'''
seq2seq的解码过程,使用了可选的注意力机制
'''
def forward(self, input, h, H, use_attention=True):"""Input:input (seq_len, batch): padded sequence tensorh (num_layers, batch, hidden_size): input hidden stateH (seq_len, batch, hidden_size): the context used in attention mechanismwhich is the output of encoderuse_attention: If True then we use attention---Output:output (seq_len, batch, hidden_size)h (num_layers, batch, hidden_size): output hidden state,h may serve as input hidden state for the next iteration,especially when we feed the word one by one (i.e., seq_len=1)such as in translation"""assert input.dim() == 2, "The input should be of (seq_len, batch)"# (seq_len, batch) => (seq_len, batch, input_size)embed = self.embedding(input)#将输入序列转换为嵌入向量output = []# split along the sequence length dimensionfor e in embed.split(1):#split(1)每次沿着seq_len方法分割一行#即每个e的维度是(1,batch,input_size)e = e.squeeze(0) # (1, batch, input_size) => (batch, input_size)o, h = self.rnn(e, h)#用RNN处理嵌入向量,并得到输出o和新的隐藏状态h#这边的RNN是StackingGRUCell,也即我认为可能是seq_len为1的GRU#o:(batch, hidden_size)#h:(num_layers,batch, hidden_size)if use_attention:o = self.attention(o, H.transpose(0, 1))#如果use_attention为True,将使用注意力机制处理RNN的输出o = self.dropout(o)#为了正则化和防止过拟合,应用 dropoutoutput.append(o)output = torch.stack(output)#将所有的输出叠加为一个张量return output, h#(seq_len, batch, hidden_size)4 StackingGRUCell
个人感觉就是
class StackingGRUCell(nn.Module):"""Multi-layer CRU Cell"""def __init__(self, input_size, hidden_size, num_layers, dropout):super(StackingGRUCell, self).__init__()self.num_layers = num_layersself.grus = nn.ModuleList()self.dropout = nn.Dropout(dropout)self.grus.append(nn.GRUCell(input_size, hidden_size))for i in range(1, num_layers):self.grus.append(nn.GRUCell(hidden_size, hidden_size))def forward(self, input, h0):"""Input:input (batch, input_size): input tensorh0 (num_layers, batch, hidden_size): initial hidden state---Output:output (batch, hidden_size): the final layer output tensorhn (num_layers, batch, hidden_size): the hidden state of each layer"""hn = []output = inputfor i, gru in enumerate(self.grus):hn_i = gru(output, h0[i])#在每一次循环中,输入output会经过一个GRU单元并更新隐藏状态hn.append(hn_i)if i != self.num_layers - 1:output = self.dropout(hn_i)else:output = hn_i#如果不是最后一层,输出会经过一个dropout层。hn = torch.stack(hn)#将hn列表转变为一个张量return output, hn5 GlobalAttention
'''
对于给定的查询向量q,查找上下文矩阵H中哪些向量与其最相关,并使用这些相关性的加权和来生成一个新的上下文向量
'''
class GlobalAttention(nn.Module):"""$$a = \sigma((W_1 q)H)$$$$c = \tanh(W_2 [a H, q])$$"""def __init__(self, hidden_size):super(GlobalAttention, self).__init__()self.L1 = nn.Linear(hidden_size, hidden_size, bias=False)self.L2 = nn.Linear(2*hidden_size, hidden_size, bias=False)self.softmax = nn.Softmax(dim=1)self.tanh = nn.Tanh()def forward(self, q, H):"""Input:q (batch, hidden_size): queryH (batch, seq_len, hidden_size): context---Output:c (batch, hidden_size)"""# (batch, hidden_size) => (batch, hidden_size, 1)q1 = self.L1(q).unsqueeze(2)#使用线性变换L1对查询向量q进行变换,然后增加一个维度以进行后续的批量矩阵乘法# (batch, seq_len)a = torch.bmm(H, q1).squeeze(2)#计算查询向量与上下文矩阵H中的每一个向量的点积。#这将生成一个形状为(batch, seq_len)的张量,表示查询向量与每个上下文向量的相似度a = self.softmax(a)#经过softmax,得到注意力权重# (batch, seq_len) => (batch, 1, seq_len)a = a.unsqueeze(1)#增加一个维度以进行后续的批量矩阵乘法# (batch, hidden_size)c = torch.bmm(a, H).squeeze(1)#使用注意力权重与上下文矩阵H进行加权求和,得到上下文向量c# (batch, hidden_size * 2)c = torch.cat([c, q], 1)#将上下文向量与查询向量连接在一起return self.tanh(self.L2(c))#使用线性变换L2对连接后的向量进行变换,并使用tanh激活函数相关文章:

论文辅助笔记:t2vec models.py
1 EncoderDecoder 1.1 _init_ class EncoderDecoder(nn.Module):def __init__(self, vocab_size, embedding_size,hidden_size, num_layers, dropout, bidirectional):super(EncoderDecoder, self).__init__()self.vocab_size vocab_size #词汇表大小self.embedding_size e…...

R语言如何写一个爬虫代码模版
R语言爬虫是利用R语言中的网络爬虫包,如XML、RCurl、rvest等,批量自动将网页的内容抓取下来。在进行R语言爬虫之前,需要了解HTML、XML、JSON等网页语言,因为正是通过这些语言我们才能在网页中提取数据。 在爬虫过程中,…...
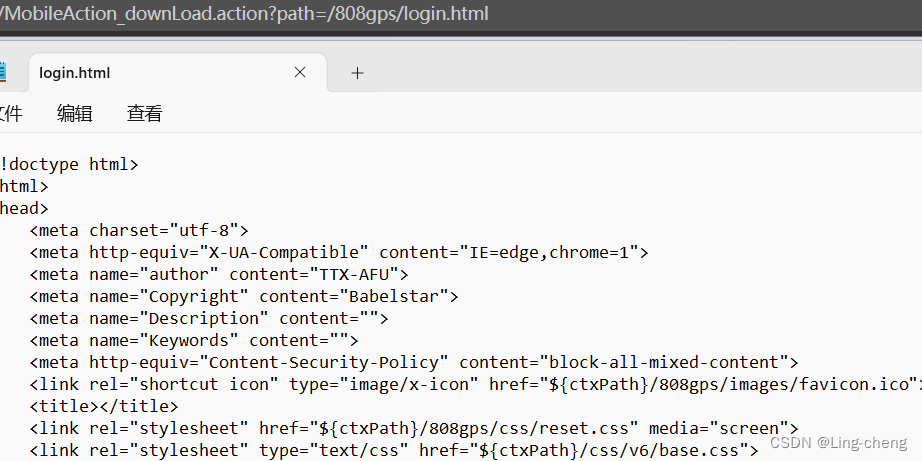
鸿运主动安全云平台任意文件下载漏洞复习
简介 深圳市强鸿电子有限公司鸿运主动安全监控云平台网页存在任意文件下载漏洞,攻击者可通过此漏洞下载网站配置文件等获得登录账号密码 漏洞复现 FOFA语法:body"./open/webApi.html" 获取网站数据库配置文件 POC:/808gps/Mobile…...
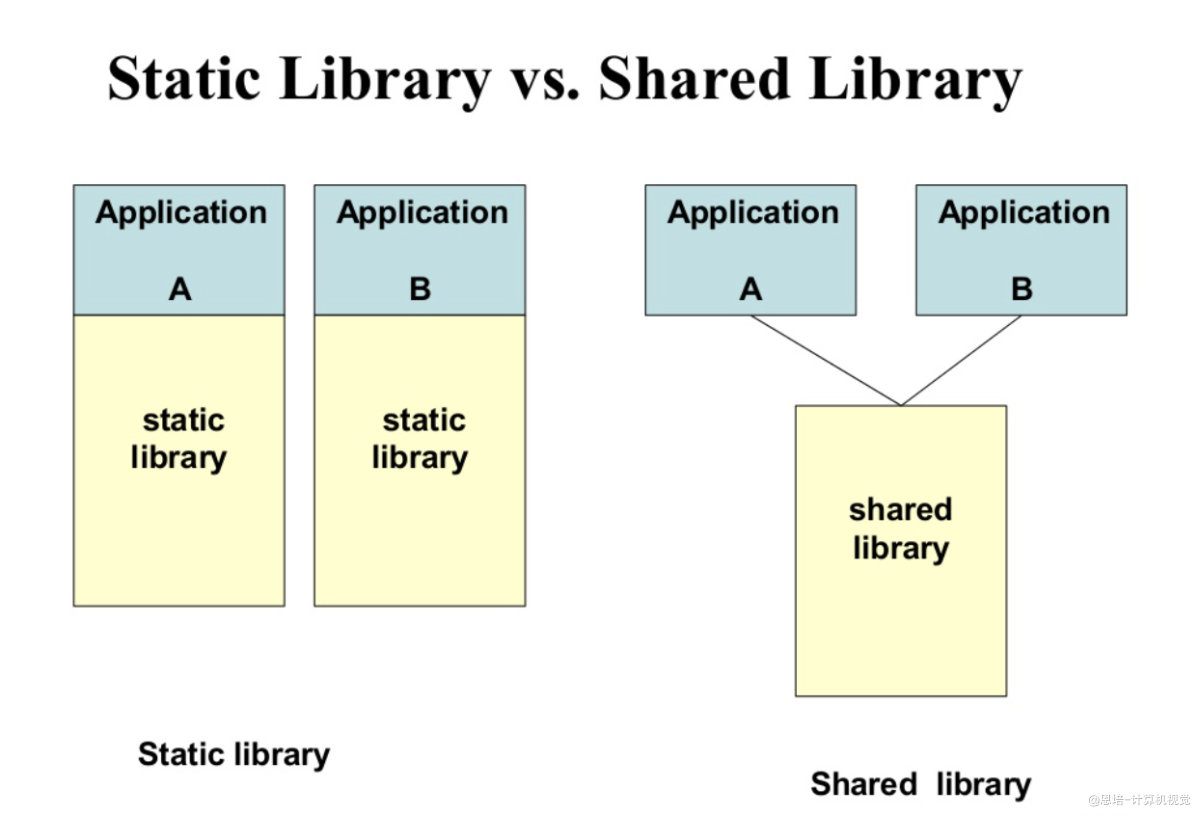
CMake基础【学习笔记(八)】
声明此博客为转载 CMake基础 文章目录 CMake基础一、准备知识1.1 C的编译过程1.2 静态链接库和动态链接库1.3 为什么需要CMake1.3.1 g 命令行编译1.3.2 CMake简介 二、CMake基础知识2.1 安装2.2 第一个CMake例子2.3 语法基础2.3.1 指定版本2.3.2 设置项目2.3.3 添加可执行文件…...

异常的学习
异常分为编译时期异常与运行时期异常 编译时期异常运行前必须处理,否则代码报错 除了RuntimeException和他的子类,其他都是编译时异常 运行时期异常运行时报错,一般是由参数传递错误导致的报错 异常的作用: 1.异常使用来查询b…...
)
【洛谷 P1101】单词方阵 题解(深度优先搜索)
单词方阵 题目描述 给一 n n n \times n nn 的字母方阵,内可能蕴含多个 yizhong 单词。单词在方阵中是沿着同一方向连续摆放的。摆放可沿着 8 8 8 个方向的任一方向,同一单词摆放时不再改变方向,单词与单词之间可以交叉,因此…...

教师减负神器
在传统的成绩管理模式中,教师需要手动输入、整理、分析成绩数据,工作量大且繁琐。这不仅耗费了教师大量的时间和精力,还容易出现错误。为了解决这个问题,我们可以通过各种代码和Excel来实现学生自助查询成绩的功能。 一、建立成绩…...

Web 开发之前的一些话
我主要是对单页面进行开发,因而VUEFlask的搭配足以满足我的需求; VUE Vue.js - 渐进式 JavaScript 框架 | Vue.js Element-UI Element - The worlds most popular Vue UI framework FLASK 欢迎来到 Flask 的世界 — Flask中文文档(2.3.x)...

git快速入门!!! git的常用命令!!!
git快速入门 git的常用命令1. 初始化一个新的 Git 仓库2. 添加文件到暂存区3. 提交更改4. 查看当前分支的状态5. 创建并切换到新的分支6. 切换回之前的分支7. 合并分支8. 拉取远程仓库的更新9. 推送本地仓库的更新 git remote -v是什么git fetchclone命令详解push指定的分支git…...

C++并发编程实战——01.并发与并行
文章目录 并发并行及其使用原因并发与并行使用与不使用并发的原因C多线程支持 并发并行及其使用原因 本书相关 github翻译地址本书源码下载地址第一版github 翻译地址英文原版PDF不错的笔记所有实例的源代码,可在出版商的网站上进行下载github上下载源码 路线图 …...

PLC如何远程控制、调试?贝锐蒲公英二层组网功能一招搞定
在制造、交通、能源、采矿等领域,工业物联网是热门话题,各类采集、控制器、控制传感器通过网络互联,实现信息实时共享、交互后,不仅能快速了解生产过程数据,还能用于设备远程、调试维护等场景,对优化生产过…...

【大数据】-- flink kubernetes operator 入门与实践
课程链接:https://edu.csdn.net/course/detail/38831 目录 课程链接:https://edu.csdn.net/course/detail/38831https://edu.csdn.net/course/detail/38831 一、你将收获...

网络安全在代理技术中的实现与应用
随着互联网技术的飞速发展,网络安全日益受到人们的重视。在这个背景下,代理技术成为了网络安全实现的重要手段之一。本文将针对 SOCKS5 代理、SK5 代理、IP 代理等代理技术,探讨它们在网络安全和爬虫应用中的重要性,并介绍 HTTP 协…...
Nginx搭配负载均衡和动静分离:构建高性能Web应用的完美组合
目录 前言 一、Nginx简介 1.Nginx是什么 2.Nginx的特点 3.Nginx在哪使用 4.如何使用Nginx 5.Nginx的优缺点 6.Nginx的应用场景 二、负载均衡和动静分离 1.负载均衡 2.动静分离 三、Nginx搭载负载均衡并提供前后端分离后台接口数据 1.Nginx安装 2.tomcat负载均衡 …...
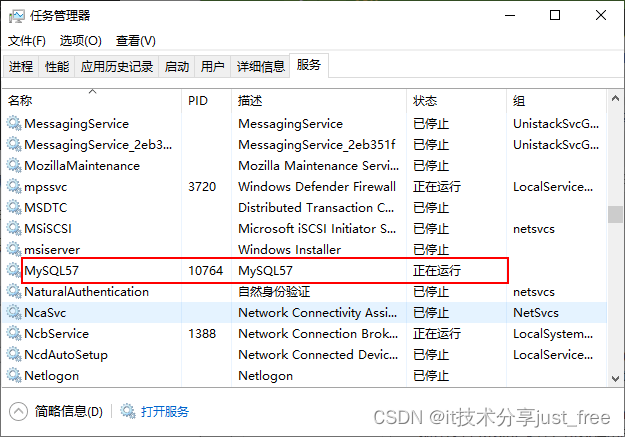
windows 运行 Mysql Command Line Client 自动关闭闪退原因分析
目录 原因分析一 原因分析二 原因分析三 第一次使用 MySQL Command Line Client 有可能输入密码后一按下回车键,程序窗口就自动关闭,出现闪退现象。本节主要分析产生闪退现象的原因以及如何处理这种情况。 原因分析一 首先可以查看程序默认执行文件…...
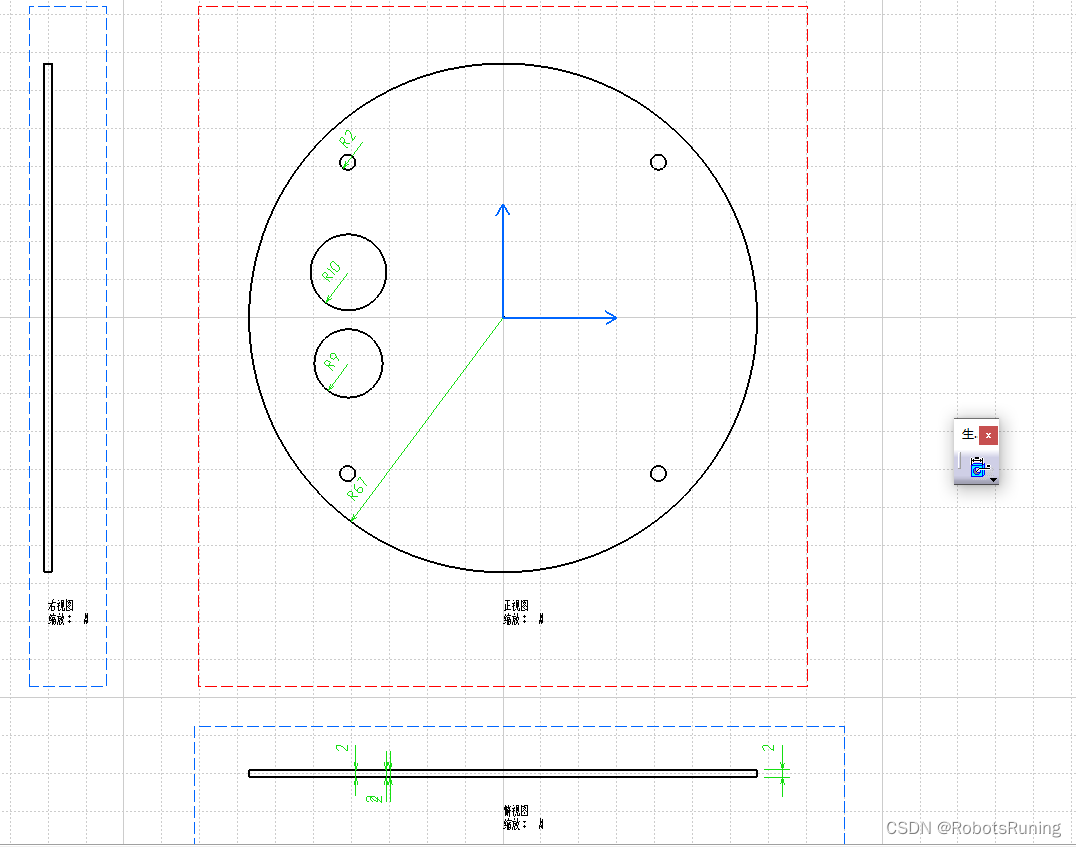
在CATIA工程制图中自动生成尺寸
然后微调即可...

蓝桥杯 (C++ 求和 等差数列 顺子日期 灌溉)
目录 1、求和 题目: 思路: 代码: 2、等差数列 题目: 思路: 代码: 3、顺子日期 题目: 思路: 代码: 4、灌溉 题目: 代码: 1、求和…...

Spring AOP基于XML方式笔记整理
XML AOP 加载流程 ClassPathXmlApplicationContext#refreshAbstractApplicationContext#obtainFreshBeanFactoryAbstractRefreshableApplicationContext#refreshBeanFactory创建DefaultListableBeanFactoryAbstractApplicationContext#loadBeanDefinitions(beanFactory)创建Xm…...
 Proxy代理方式连接互联网)
Docker HTTP(S) Proxy代理方式连接互联网
Docker HTTP(S) Proxy 是一种在 Docker 容器内部设置 HTTP(S) 代理的方法,以便于容器内的应用程序可以方便地通过代理访问互联网。设置 HTTP(S) 代理的方法主要有两种:使用 Dockerfile 配置和在使用 docker run 时添加参数。 以下是使用 Docker HTTP(S) …...
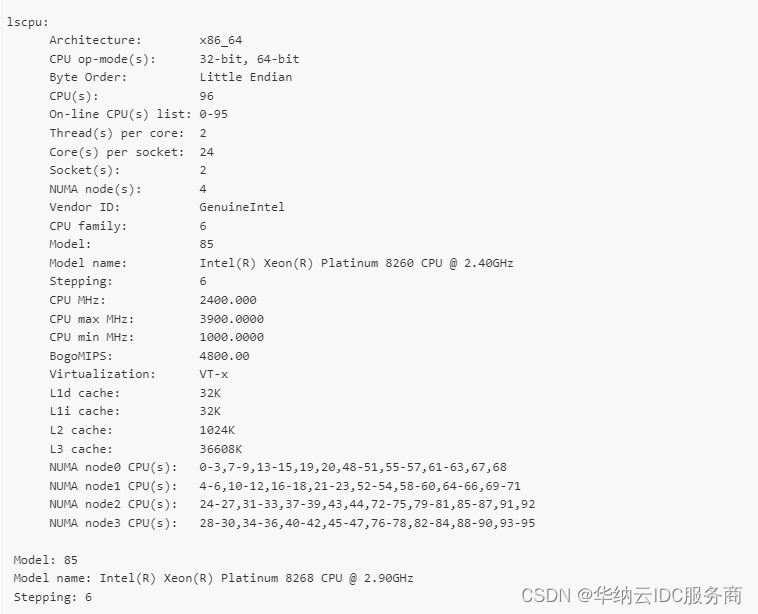
华纳云:centos系统中怎么查看cpu信息?
在CentOS系统中,我们可以使用一些命令来查看CPU的详细信息。下面介绍几个常用的命令: 1. lscpu lscpu命令可以显示CPU的架构、型号、核心数、线程数、频率等信息。 # lscpu 执行以上命令后,会输出类似以下内容: 2. cat /proc/…...

学习规划需要定期调整吗?
在当今竞争激烈的教育环境中,学习规划对于学生的成长和发展起着至关重要的作用。作为一名在学习规划领域深耕十年的专家,我见证了无数学生在学习规划的指引下取得优异成绩,也看到了一些学生因为规划不合理而走了不少弯路。那么,学…...

为什么我劝你放弃FLANN 1.9.2?聊聊源码编译那些坑与1.9.1版的真香选择
为什么FLANN 1.9.1才是开发者更明智的选择:深度解析编译陷阱与版本决策 在开源库的世界里,"最新版本"往往被默认为"最佳选择",但FLANN 1.9.2却打破了这个常规认知。作为一名经历过无数次深夜调试的开发者,我必…...

TI WEBENCH滤波器设计工具:从理论到实战的电路设计加速器
1. WEBENCH滤波器设计工具:从概念到成品的“加速器”在模拟电路设计,尤其是信号调理领域,滤波器设计一直是个既基础又颇具挑战性的环节。无论是为了滤除电源噪声,还是从复杂的传感器信号中提取有效成分,一个性能优良的…...

MobaXterm自定义语法高亮进阶:修复绿色失效与打造个性化终端
1. 为什么你的MobaXterm绿色高亮总是不亮? 第一次用MobaXterm时我就被它的彩色终端吸引了,特别是成功操作会显示醒目的绿色,失败提示则是刺眼的红色。但用了两周后突然发现:所有成功操作的绿色提示全都消失了!这就像开…...

保姆级避坑指南:树莓派4B+Ubuntu 22.04 LTS + 3.5寸屏,从开机到远程桌面一次搞定
树莓派4B与Ubuntu 22.04 LTS完美适配实战:从零搭建带屏远程开发环境 第一次接触树莓派和Ubuntu Server的新手们,往往会在搭建开发环境时遇到各种"坑"。本文将手把手带你绕过这些常见陷阱,用树莓派4B、3.5寸屏和Ubuntu 22.04 LTS打造…...

免费图表数据提取神器:5分钟学会WebPlotDigitizer核心用法
免费图表数据提取神器:5分钟学会WebPlotDigitizer核心用法 【免费下载链接】WebPlotDigitizer Computer vision assisted tool to extract numerical data from plot images. 项目地址: https://gitcode.com/gh_mirrors/we/WebPlotDigitizer 还在为从科研图表…...
)
别再手动忽略.git和.svn了!WinMerge过滤器保姆级配置指南(附常用正则模板)
WinMerge高效过滤指南:彻底告别版本控制与构建文件干扰 接手新项目时,你是否曾被满屏的.git、.svn和.class文件对比结果淹没?WinMerge的过滤器功能正是解决这一痛点的利器。本文将带你从零开始配置专属过滤规则,让文件对比回归核心…...

Knot高级技巧:局域网设备抓包和跨设备数据同步
Knot高级技巧:局域网设备抓包和跨设备数据同步 【免费下载链接】Knot 一款iOS端基于MITM(中间人攻击技术)实现的HTTPS抓包工具,完整的App,核心代码使用SwiftNIO实现 项目地址: https://gitcode.com/gh_mirrors/kn/Knot Knot是一款iOS端…...

如何用Lano Visualizer打造智能音频可视化桌面:从音乐爱好者到专业用户的完整指南
如何用Lano Visualizer打造智能音频可视化桌面:从音乐爱好者到专业用户的完整指南 【免费下载链接】Lano-Visualizer A simple but highly configurable visualizer with rounded bars. 项目地址: https://gitcode.com/gh_mirrors/la/Lano-Visualizer 你是否…...
)
别再只用MSE了!PyTorch中SmoothL1Loss的保姆级使用指南(附代码对比)
深度学习回归任务中SmoothL1Loss的实战应用与MSE对比解析 在目标检测、房价预测等回归任务中,选择合适的损失函数往往决定了模型的收敛速度和最终性能。许多初学者会习惯性选择最熟悉的均方误差(MSE)损失函数,但当数据中存在离群点时,MSE的二…...