OpenCV实现人脸关键点检测
目录
实现过程
1,代码解读
1.1 导入工具包
1.2导入所需图像,以及训练好的人脸预测模型
1.3 将 dlib 的关键点对象转换为 NumPy 数组,以便后续处理
1.4图像上可视化面部关键点
1.5# 读取输入数据,预处理
1.6进行人脸检测
1.7遍历检测到的框
1.8遍历每个面部
2,所有代码
3,结果展示
实现过程
-
导入工具包:首先导入所需的Python库,包括dlib用于人脸检测和关键点定位,以及OpenCV用于图像处理。
-
参数解析:使用argparse库解析命令行参数,以指定面部关键点预测器的路径和输入图像的路径。
-
定义关键点范围:定义了两个字典(FACIAL_LANDMARKS_68_IDXS和FACIAL_LANDMARKS_5_IDXS),它们包含了不同面部部位的关键点索引范围,用于标识人脸的不同部分。
-
图像预处理:加载输入图像,将其缩放为指定宽度(500像素),并将其转换为灰度图像。这些预处理步骤有助于提高人脸检测的性能和稳定性。
-
人脸检测:使用dlib库的人脸检测器检测灰度图像中的人脸。检测结果是一个包含人脸边界框的列表。
-
遍历检测到的人脸:对于每个检测到的人脸,使用面部关键点定位器获取关键点的坐标。然后,对不同的面部部位进行循环处理。
-
绘制关键点:为了可视化,代码使用OpenCV在图像上绘制关键点。每个关键点以红色圆圈的形式标记在图像上,并标注了各个部位的名称。
-
提取ROI区域:在每个部位上,代码还提取了一个感兴趣区域(ROI),这是通过计算关键点的包围矩形来实现的。ROI区域随后可以用于进一步的分析或显示。
-
调整ROI尺寸:最后,代码调整了ROI区域的尺寸,以确保它们具有一致的宽度(250像素),同时保持高宽比例不变。
1,代码解读
1.1 导入工具包
collections.OrderedDict: 用于创建有序的字典。numpy: 用于处理数值计算。argparse: 用于处理命令行参数。dlib: 一个图像处理库,用于人脸检测和关键点定位。cv2(OpenCV): 用于图像处理。
1.2导入所需图像,以及训练好的人脸预测模型
# 参数
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,
help="path to facial landmark predictor")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
1.3 将 dlib 的关键点对象转换为 NumPy 数组,以便后续处理
'''这个函数用于将 dlib 的关键点对象转换为 NumPy 数组,以便后续处理。
它遍历关键点对象中的每个点,提取其 x 和 y 坐标,然后将坐标保存在 NumPy 数组中。'''
def shape_to_np(shape, dtype="int"):
# 创建68*2
coords = np.zeros((shape.num_parts, 2), dtype=dtype)
# 遍历每一个关键点
# 得到坐标
for i in range(0, shape.num_parts):
coords[i] = (shape.part(i).x, shape.part(i).y)
return coords
1.4图像上可视化面部关键点
这个函数用于在图像上可视化面部关键点。
它接受输入图像、关键点坐标、可选颜色和透明度参数。
在输入图像上绘制关键点,可以为不同面部部位指定不同的颜色。
最后,将可视化的图像与原图像混合以得到输出图像。'''
def visualize_facial_landmarks(image, shape, colors=None, alpha=0.75):
# 创建两个copy
# overlay and one for the final output image
overlay = image.copy()
output = image.copy()
# 设置一些颜色区域
if colors is None:
colors = [(19, 199, 109), (79, 76, 240), (230, 159, 23),
(168, 100, 168), (158, 163, 32),
(163, 38, 32), (180, 42, 220)]
# 遍历每一个区域
for (i, name) in enumerate(FACIAL_LANDMARKS_68_IDXS.keys()):
# 得到每一个点的坐标
(j, k) = FACIAL_LANDMARKS_68_IDXS[name]
pts = shape[j:k]
# 检查位置
if name == "jaw":
# 用线条连起来
for l in range(1, len(pts)):
ptA = tuple(pts[l - 1])
ptB = tuple(pts[l])
cv2.line(overlay, ptA, ptB, colors[i], 2)
# 计算凸包
else:
hull = cv2.convexHull(pts)
cv2.drawContours(overlay, [hull], -1, colors[i], -1)
# 叠加在原图上,可以指定比例
cv2.addWeighted(overlay, alpha, output, 1 - alpha, 0, output)
return output
1.5# 读取输入数据,预处理
image = cv2.imread(args["image"])
(h, w) = image.shape[:2]
width=500#这一行定义了一个新的宽度,即将图像调整为的目标宽度。
r = width / float(w)
'''这一行创建一个新的图像维度 dim,它是一个元组,包含了目标宽度 width 和一个计算出的新高度。
新高度是原始高度 h 乘以比例 r 并取整数部分'''
dim = (width, int(h * r))
'''最后一行使用OpenCV的 cv2.resize 函数,
将原始图像 image 调整为新的维度 dim,以实现目标宽度为500像素,同时保持高宽比例不变。
interpolation 参数指定了插值方法,这里使用了 cv2.INTER_AREA,它适合缩小图像。'''
image = cv2.resize(image, dim, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
1.6进行人脸检测
'''1 是一个可选参数,它控制人脸检测的程度。
通常,值为 1 表示对图像进行一次粗略的检测。
你也可以尝试使用不同的值,以获得更灵敏或更宽松的人脸检测结果'''
rects = detector(gray, 1)
1.7遍历检测到的框
for (i, rect) in enumerate(rects):
# 对人脸框进行关键点定位
# 转换成ndarray
shape = predictor(gray, rect)
shape = shape_to_np(shape)
1.8遍历每个面部
# 遍历每一个部分
#这段代码针对每个面部部位执行一系列操作
for (name, (i, j)) in FACIAL_LANDMARKS_68_IDXS.items():
clone = image.copy() #这一行创建了图像的一个副本 clone,以便在副本上绘制标记,以保持原始图像不受影响。
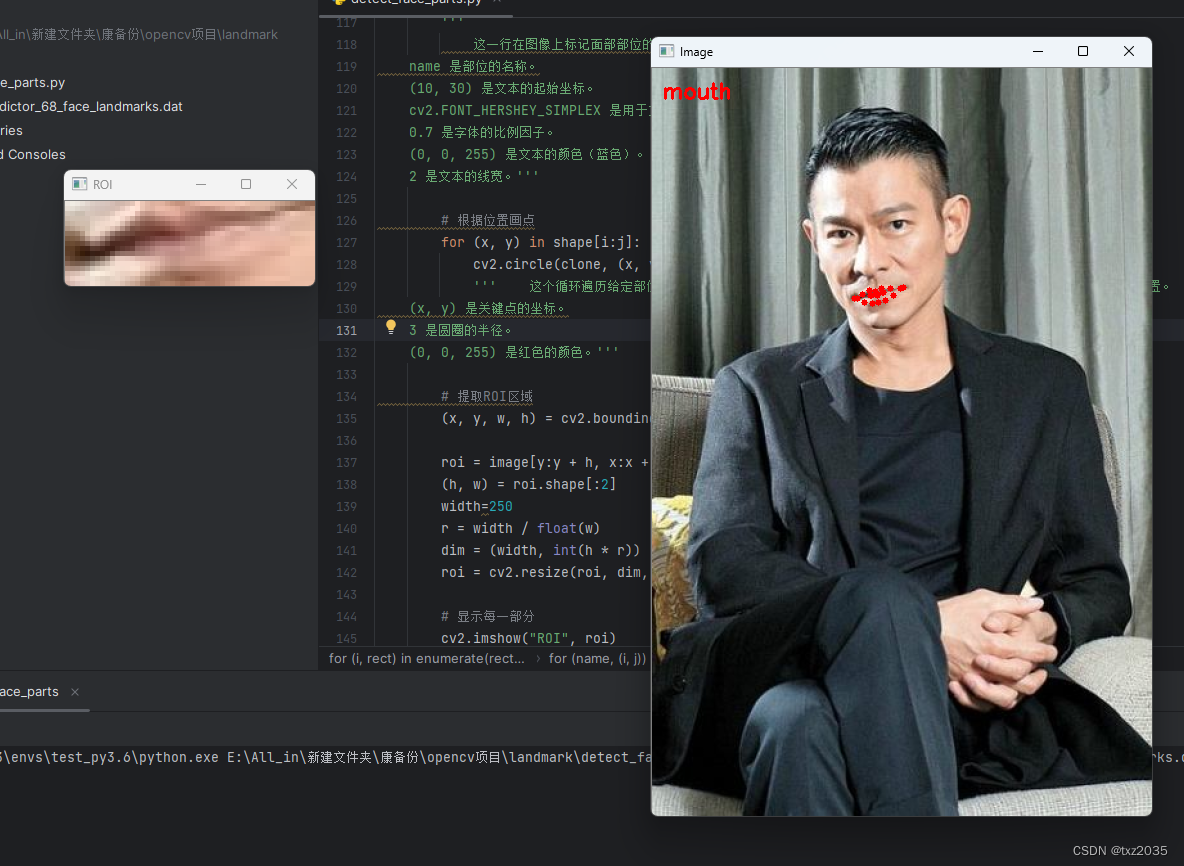
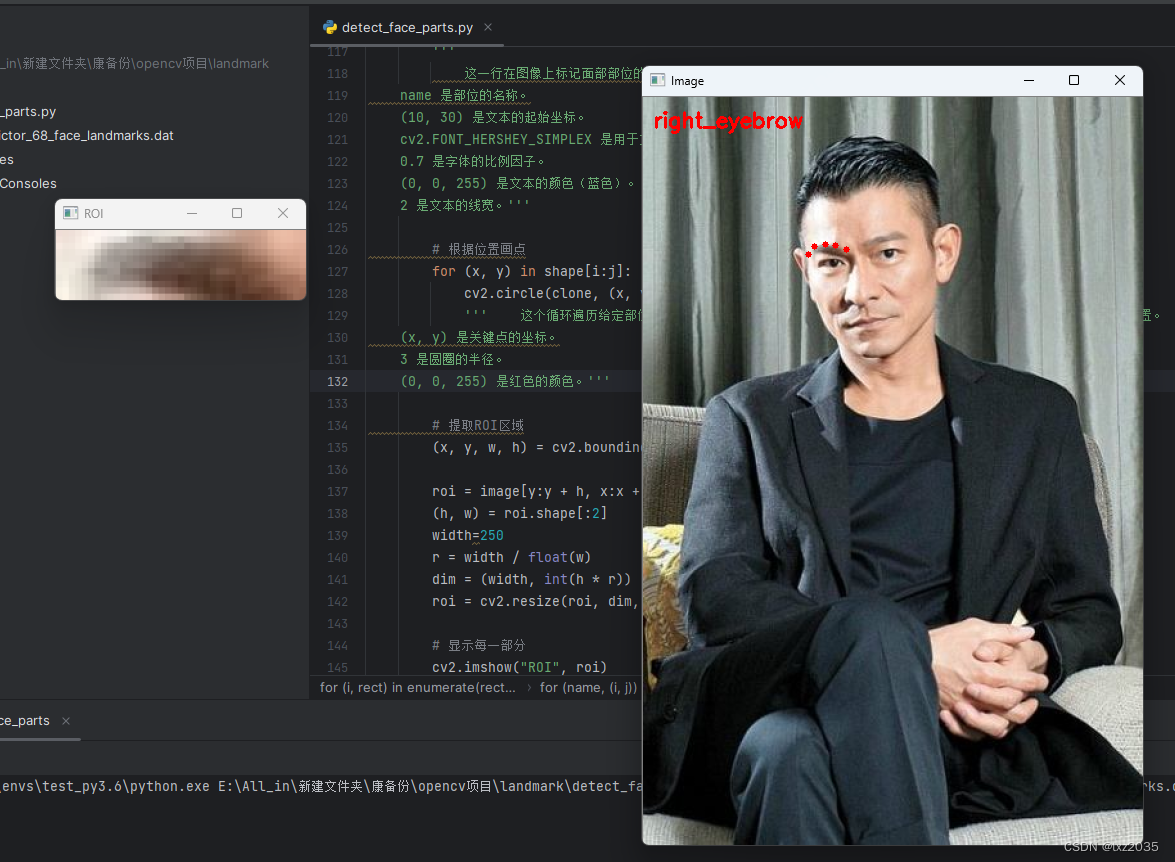
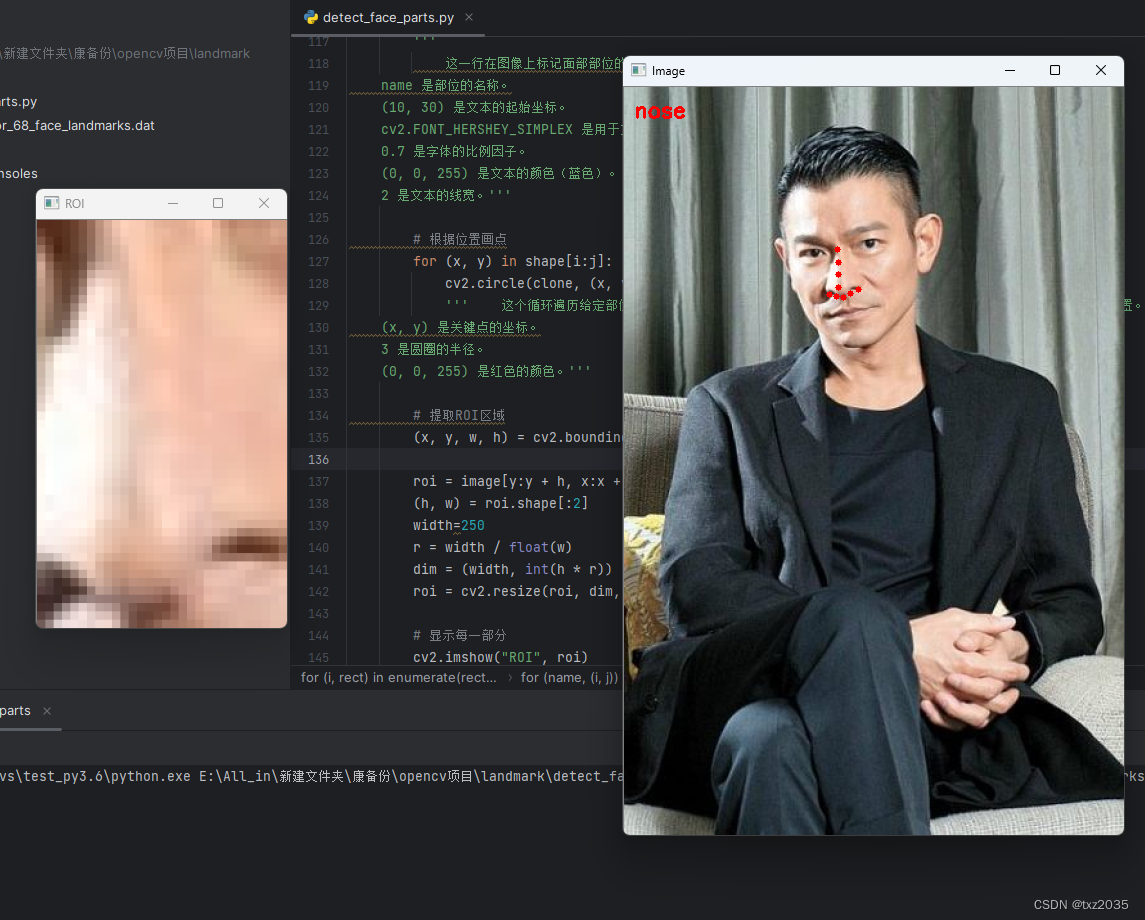
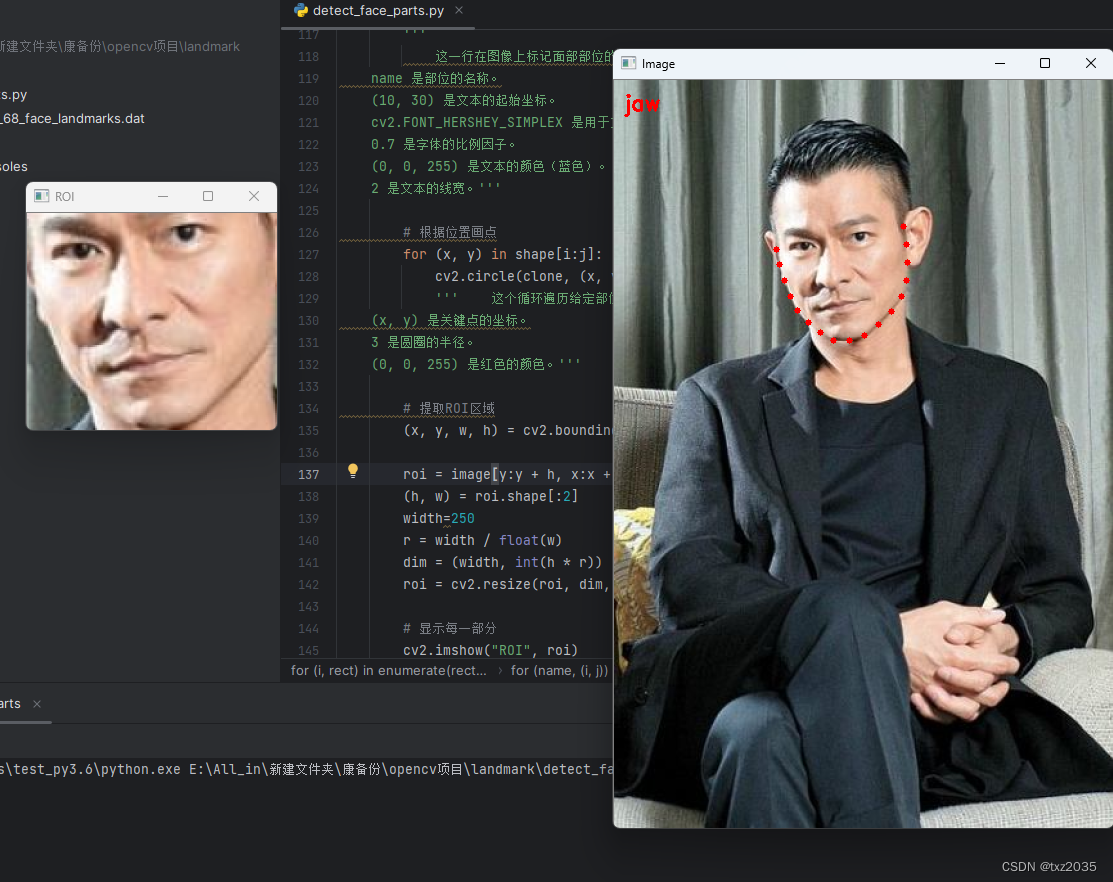
cv2.putText(clone, name, (10, 30), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 0, 255), 2)
'''
这一行在图像上标记面部部位的名称,使用 OpenCV 的 cv2.putText 函数。
name 是部位的名称。
(10, 30) 是文本的起始坐标。
cv2.FONT_HERSHEY_SIMPLEX 是用于文本的字体。
0.7 是字体的比例因子。
(0, 0, 255) 是文本的颜色(蓝色)。
2 是文本的线宽。'''
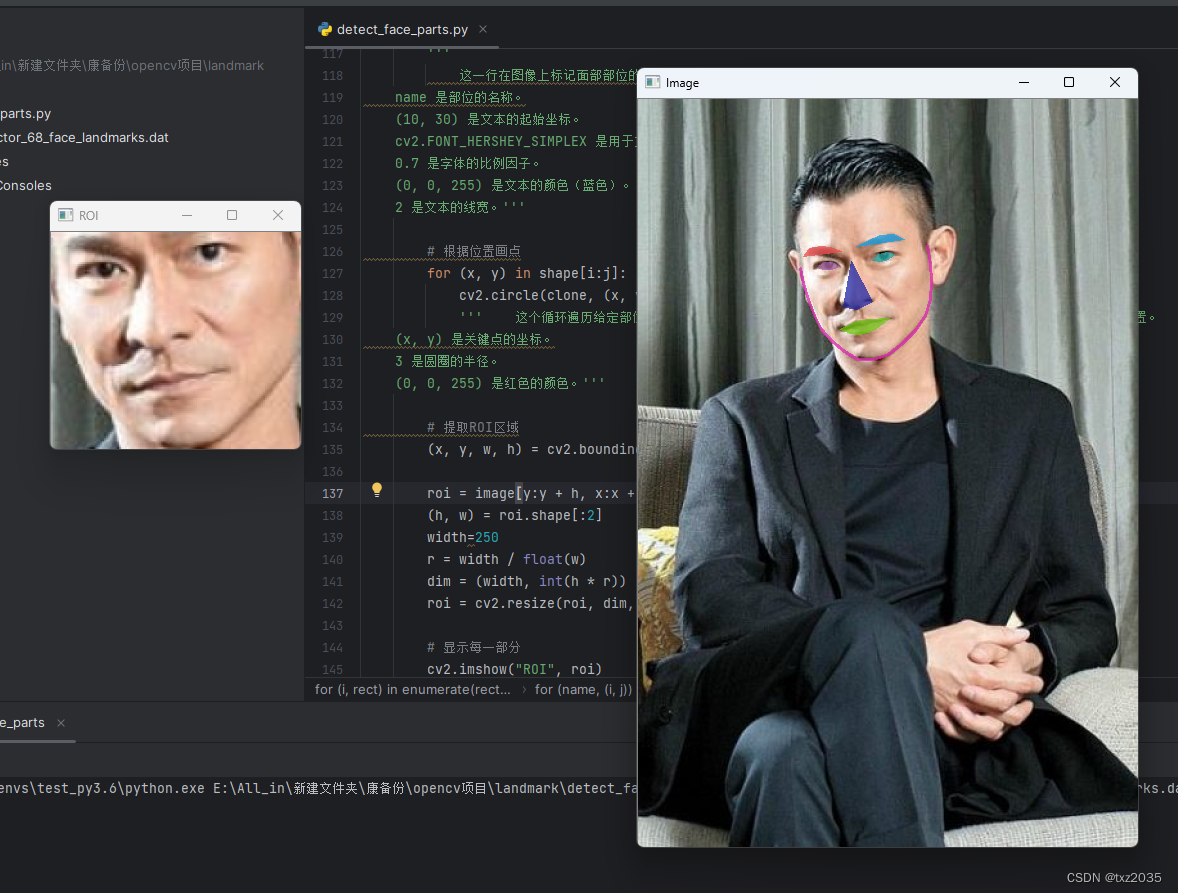
# 根据位置画点
for (x, y) in shape[i:j]:
cv2.circle(clone, (x, y), 3, (0, 0, 255), -1)
''' 这个循环遍历给定部位的关键点坐标 (x, y),并在 clone 图像上绘制红色的小圆圈,以标记关键点的位置。
(x, y) 是关键点的坐标。
3 是圆圈的半径。
(0, 0, 255) 是红色的颜色。'''
# 提取ROI区域
(x, y, w, h) = cv2.boundingRect(np.array([shape[i:j]]))
2,所有代码
#导入工具包
from collections import OrderedDict
import numpy as np
import argparse
import dlib
import cv2#https://ibug.doc.ic.ac.uk/resources/facial-point-annotations/
#http://dlib.net/files/# 参数
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,help="path to facial landmark predictor")
ap.add_argument("-i", "--image", required=True,help="path to input image")
args = vars(ap.parse_args())
'''这两个字典包含了不同面部部位的关键点索引范围,用于标识人脸的不同部分,例如嘴巴、眼睛、鼻子等。'''
FACIAL_LANDMARKS_68_IDXS = OrderedDict([("mouth", (48, 68)),("right_eyebrow", (17, 22)),("left_eyebrow", (22, 27)),("right_eye", (36, 42)),("left_eye", (42, 48)),("nose", (27, 36)),("jaw", (0, 17))
])FACIAL_LANDMARKS_5_IDXS = OrderedDict([("right_eye", (2, 3)),("left_eye", (0, 1)),("nose", (4))
])
'''这个函数用于将 dlib 的关键点对象转换为 NumPy 数组,以便后续处理。
它遍历关键点对象中的每个点,提取其 x 和 y 坐标,然后将坐标保存在 NumPy 数组中。'''
def shape_to_np(shape, dtype="int"):# 创建68*2coords = np.zeros((shape.num_parts, 2), dtype=dtype)# 遍历每一个关键点# 得到坐标for i in range(0, shape.num_parts):coords[i] = (shape.part(i).x, shape.part(i).y)return coords
'''这个函数用于在图像上可视化面部关键点。它接受输入图像、关键点坐标、可选颜色和透明度参数。在输入图像上绘制关键点,可以为不同面部部位指定不同的颜色。最后,将可视化的图像与原图像混合以得到输出图像。'''
def visualize_facial_landmarks(image, shape, colors=None, alpha=0.75):# 创建两个copy# overlay and one for the final output imageoverlay = image.copy()output = image.copy()# 设置一些颜色区域if colors is None:colors = [(19, 199, 109), (79, 76, 240), (230, 159, 23),(168, 100, 168), (158, 163, 32),(163, 38, 32), (180, 42, 220)]# 遍历每一个区域for (i, name) in enumerate(FACIAL_LANDMARKS_68_IDXS.keys()):# 得到每一个点的坐标(j, k) = FACIAL_LANDMARKS_68_IDXS[name]pts = shape[j:k]# 检查位置if name == "jaw":# 用线条连起来for l in range(1, len(pts)):ptA = tuple(pts[l - 1])ptB = tuple(pts[l])cv2.line(overlay, ptA, ptB, colors[i], 2)# 计算凸包else:hull = cv2.convexHull(pts)cv2.drawContours(overlay, [hull], -1, colors[i], -1)# 叠加在原图上,可以指定比例cv2.addWeighted(overlay, alpha, output, 1 - alpha, 0, output)return output# 加载人脸检测与关键点定位
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args["shape_predictor"])# 读取输入数据,预处理
image = cv2.imread(args["image"])
(h, w) = image.shape[:2]
width=500#这一行定义了一个新的宽度,即将图像调整为的目标宽度。
r = width / float(w)
'''这一行创建一个新的图像维度 dim,它是一个元组,包含了目标宽度 width 和一个计算出的新高度。
新高度是原始高度 h 乘以比例 r 并取整数部分'''
dim = (width, int(h * r))
'''最后一行使用OpenCV的 cv2.resize 函数,
将原始图像 image 调整为新的维度 dim,以实现目标宽度为500像素,同时保持高宽比例不变。
interpolation 参数指定了插值方法,这里使用了 cv2.INTER_AREA,它适合缩小图像。'''
image = cv2.resize(image, dim, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)# 人脸检测
'''1 是一个可选参数,它控制人脸检测的程度。
通常,值为 1 表示对图像进行一次粗略的检测。
你也可以尝试使用不同的值,以获得更灵敏或更宽松的人脸检测结果'''
rects = detector(gray, 1)# 遍历检测到的框
for (i, rect) in enumerate(rects):# 对人脸框进行关键点定位# 转换成ndarrayshape = predictor(gray, rect)shape = shape_to_np(shape)# 遍历每一个部分#这段代码针对每个面部部位执行一系列操作for (name, (i, j)) in FACIAL_LANDMARKS_68_IDXS.items():clone = image.copy() #这一行创建了图像的一个副本 clone,以便在副本上绘制标记,以保持原始图像不受影响。cv2.putText(clone, name, (10, 30), cv2.FONT_HERSHEY_SIMPLEX,0.7, (0, 0, 255), 2)'''这一行在图像上标记面部部位的名称,使用 OpenCV 的 cv2.putText 函数。name 是部位的名称。(10, 30) 是文本的起始坐标。cv2.FONT_HERSHEY_SIMPLEX 是用于文本的字体。0.7 是字体的比例因子。(0, 0, 255) 是文本的颜色(蓝色)。2 是文本的线宽。'''# 根据位置画点for (x, y) in shape[i:j]:cv2.circle(clone, (x, y), 3, (0, 0, 255), -1)''' 这个循环遍历给定部位的关键点坐标 (x, y),并在 clone 图像上绘制红色的小圆圈,以标记关键点的位置。(x, y) 是关键点的坐标。3 是圆圈的半径。(0, 0, 255) 是红色的颜色。'''# 提取ROI区域(x, y, w, h) = cv2.boundingRect(np.array([shape[i:j]]))roi = image[y:y + h, x:x + w](h, w) = roi.shape[:2]width=250r = width / float(w)dim = (width, int(h * r))roi = cv2.resize(roi, dim, interpolation=cv2.INTER_AREA)# 显示每一部分cv2.imshow("ROI", roi)cv2.imshow("Image", clone)cv2.waitKey(0)# 展示所有区域output = visualize_facial_landmarks(image, shape)cv2.imshow("Image", output)cv2.waitKey(0)3,结果展示
相关文章:
OpenCV实现人脸关键点检测
目录 实现过程 1,代码解读 1.1 导入工具包 1.2导入所需图像,以及训练好的人脸预测模型 1.3 将 dlib 的关键点对象转换为 NumPy 数组,以便后续处理 1.4图像上可视化面部关键点 1.5# 读取输入数据,预处理 1.6进行人脸检测 1…...

300万美元!澳大利亚昆士兰州投资当地首家量子公司AQC
澳大利亚模拟量子电路公司(AQC)联合创始人 Tom Stace 教授和 Arkady Federov 副教授(图片来源:网络) 澳大利亚风险投资基金会Uniseed为澳大利亚昆士兰大学的两名教授提供了300万美元的资金,资助他们创办了…...
Android Studio打包AAR
注意 依赖的Android Studio版本为4.2.2 更高的Android Studio版本使用方法可能有所不同,gradle的版本和gradle plugins的版本都会影响使用方式。 基于此,本文只能作为参考,而不能作为唯一答案,如果要完全依赖本文,则…...

【Python基础知识四】控制语句
Python基础知识:控制语句 1 条件控制1.1 if语句1.2 match...case语句 2 循环语句2.1 for循环2.2 for...else语句2.3 while循环2.4 while 循环使用 else 语句2.5 无限循环2.6 break 和 continue 语句及循环中的 else 子句2.6.1 break语句2.6.2 continue语句 2.7 pass…...

Jmeter压测 —— 1秒发送1次请求
场景:有时候测试场景需要设置请求频率为一秒一次(或几秒一次)实现方法一:1、首先需要在线程组下设置循环次数(可以理解为请求的次数) 次数设置为请求300次,其中线程数跟时间自行设置 2、在设置…...

目标检测YOLO实战应用案例100讲-基于改进YOLOv4算法的自动驾驶场景 目标检测
目录 前言 国内外目标检测算法研究现状 传统目标检测算法的发展现状...
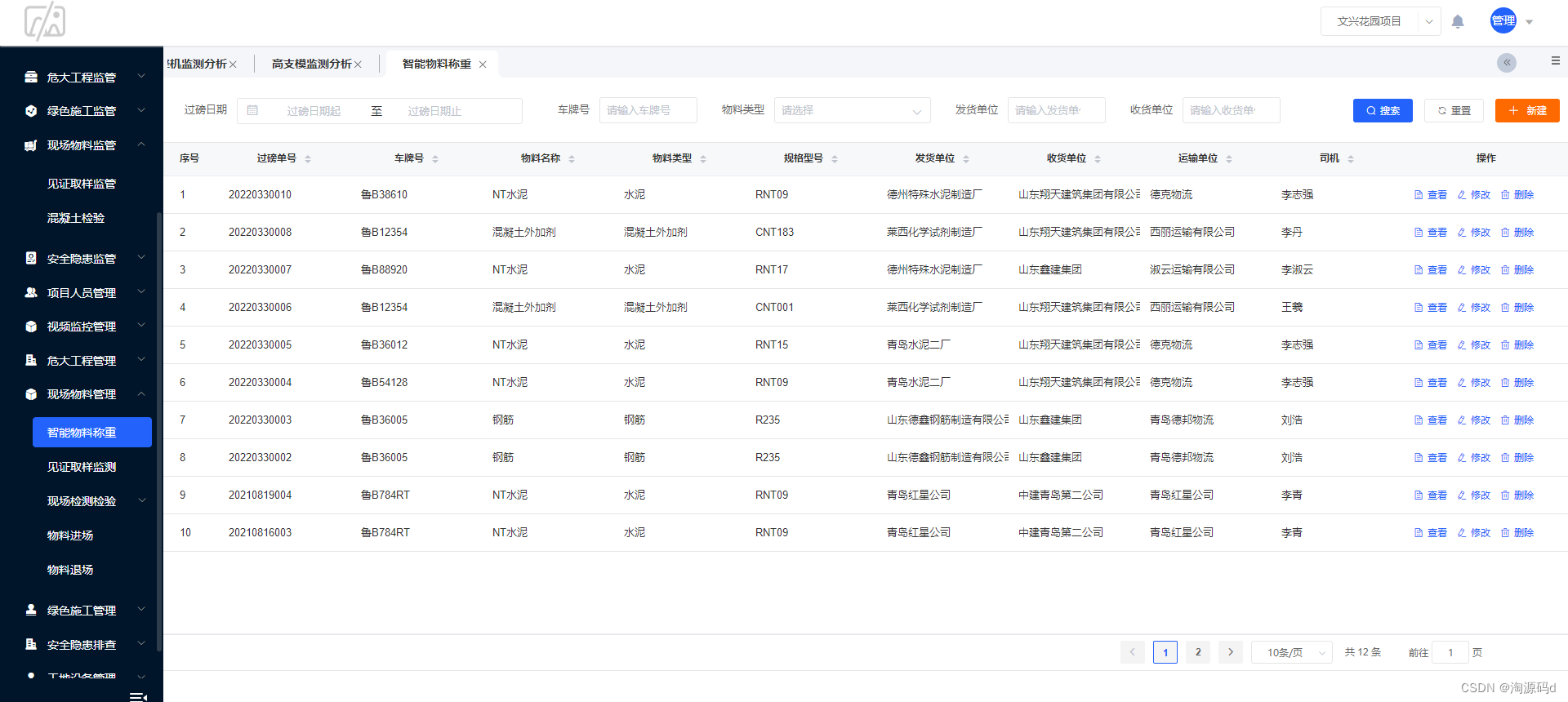
Spring Cloud智慧工地源码,利用计算机技术、互联网、物联网、云计算、大数据等新一代信息技术开发,微服务架构
智慧工地系统充分利用计算机技术、互联网、物联网、云计算、大数据等新一代信息技术,以PC端,移动端,设备端三位一体的管控方式为企业现场工程管理提供了先进的技术手段。让劳务、设备、物料、安全、环境、能源、资料、计划、质量、视频监控等…...
AI视频 | Runway的史诗级更新真的那么震撼吗?来看我的试用体验!
就在昨天,Runway,这个生成式AI的领头羊,正式在X上发布了他们史诗级更新 看下视频 【视频2】 这个确实看起来太棒了 注册个账号,看下效果咋样 地址百度哈,注册登录也比较方便 直接邮箱即可 不过我是直接google账号登录的…...
)
【动作模式识别】实现复合动作模式识别(离线控制模块)
一、思路 一般来说,要实现摸脸动作,需要采集手臂的以下肌肉的肌电信号: 肱二头肌:控制肘关节的屈曲肱三头肌:控制肘关节的伸展前臂屈肌群:控制手腕和手指的屈曲前臂伸肌群:控制手腕和手指的伸…...

Python基础学习009——类的封装
# 面向对象是一种编程思想,还有另一种是面向过程 # 面向过程,具体步骤的实现,所有功能都自己书写 # 面向对象,使用一个个工具(函数),帮助完成各项任务 # 类:对多个特性相同或相似的食物的统称,根据特征不同一个事物可以属于多个类 # 对象:由类实例化的一个事物,指代1个 # 类的组…...

前端开发和后端开发,你更倾向于哪一种?
作为一个Web开发者,你是否曾经面临过这样的选择:是专注于前端开发,还是转向后端开发?前端开发和后端开发是Web开发中的两个不同的领域,它们各有各的特点和优势,也各有各的挑战和难点。那么,你应…...

Selenium 基本功能
#driver.quit()from selenium import webdriver from selenium.webdriver.chrome.service import Service# 尝试传参 s Service("chromedriver.exe") driver webdriver.Chrome(services)driver.get(https://www.baidu.com/) input()#1/导入Selenium库 from seleniu…...
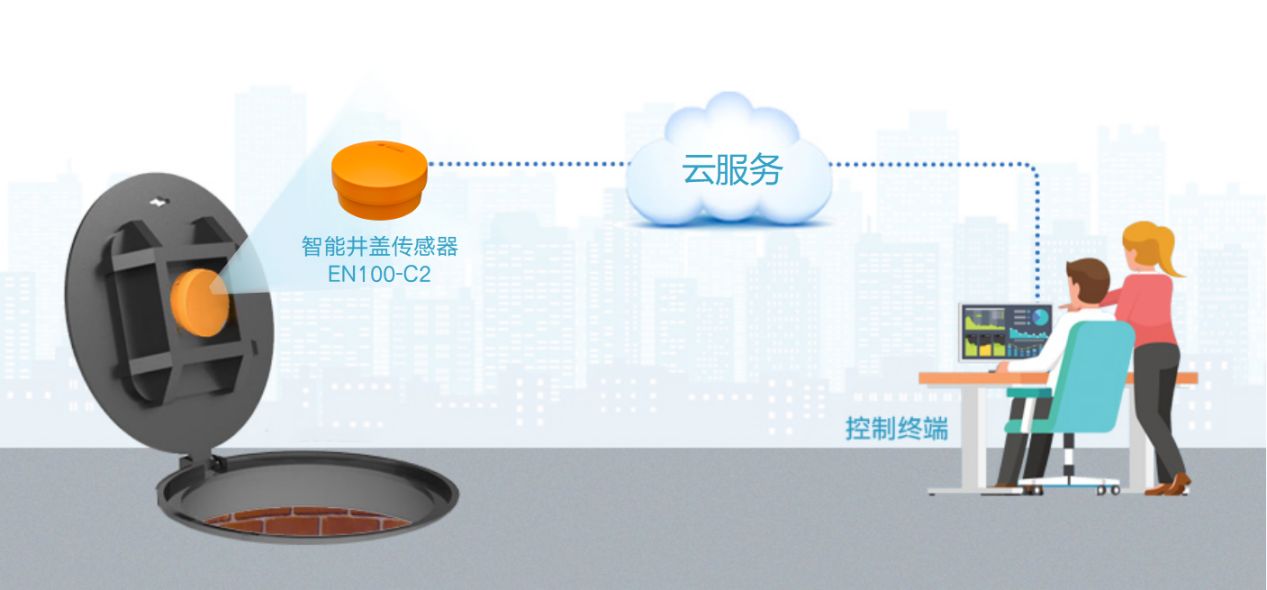
智能井盖传感器有哪些?万宾科技智能井盖效果
在城市治理过程之中,小小的井盖却成为影响民生的一个重要方面,因为井盖一旦出现问题,会严重影响市民的生命安全,并且传统的井盖一般都会采用人工巡检的方式,这就导致了巡检的难度较大,从而不能对城市各个角…...
视频增强和修复工具 Topaz Video AI mac中文版功能
Topaz Video AI mac是一款使用人工智能技术对视频进行增强和修复的软件。它可以自动降噪、去除锐化、减少压缩失真、提高清晰度等等。Topaz Video AI可以处理各种类型的视频,包括低分辨率视频、老旧影片、手机录制的视频等。 使用Topaz Video AI非常简单,…...

0基础学习PyFlink——使用datagen生成流式数据
大纲 可控参数字段级规则生成方式数值控制时间戳控制 表级规则生成速度生成总量 结构生成环境定义行结构定义表信息 案例随机Int型顺序Int型随机型Int数组带时间戳的多列数据 完整代码参考资料 在研究Flink的水位线(WaterMark)技术之前,我们可…...
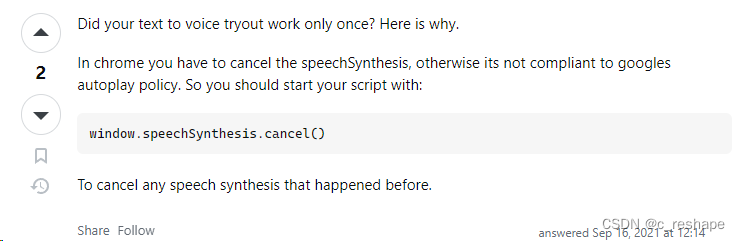
vue使用Web Speech API实现语音播报
SpeechSynthesisUtterance对象用于表示要播放的语音内容,SpeechSynthesis对象则用于控制语音的播放、暂停、停止等操作。 const synth window.speechSynthesis const msg new SpeechSynthesisUtterance() // 语音播放 const playVoice (text) > {synth.canc…...
)
MVC5_Day1(Razor视图引擎)
MVC提供了两种不同的视图引擎:Razor视图引擎、Web Forms视图引擎。 1.代码表达式 1.1 转换字符:核心转换字符,用作标记<>代码之间相互转换的字符。 1.2 两种基本转换:代码表达式、代码块。都是求出值,再写入响…...
超全整理,Jmeter性能测试-脚本error报错排查/分布式压测(详全)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 性能脚本error报错…...
vscode开启emmet语法
需要在setting.json中添加配置 首先进入设置,然后点击右上角 Vue项目添加如下配置 "emmet.syntaxProfiles": { "vue-html": "html", "vue": "html" },React项目添加如下配置 "emmet.includeLanguages&quo…...
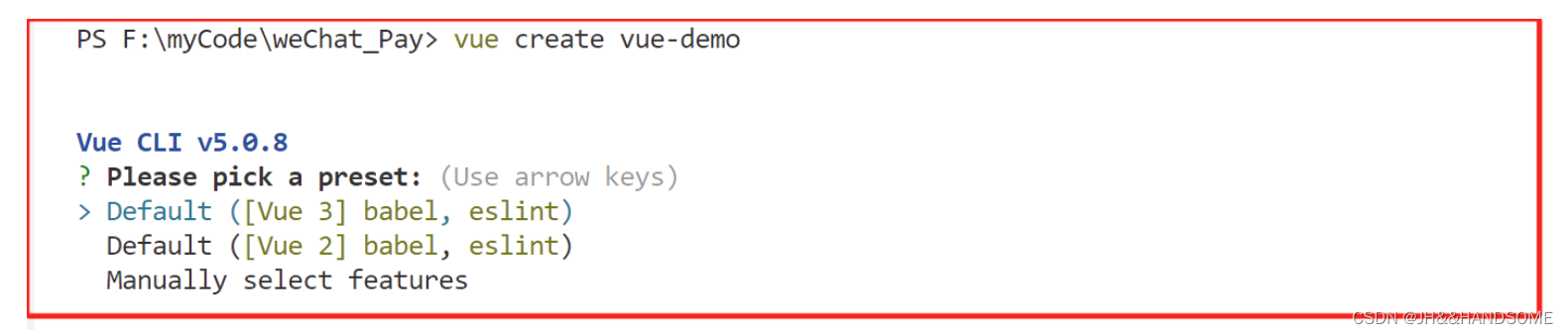
07、vue : 无法加载文件 C:\Users\JH\AppData\Roaming\npm\vue.ps1,因为在此系统上禁止运行脚本。
目录 问题解决: 问题 vue : 无法加载文件 C:\Users\JH\AppData\Roaming\npm\vue.ps1,因为在此系统上禁止运行脚本。 在使用 VSCode 时,创建 Vue 项目报的错 创建不了 Vue 项目 解决: 因为在此系统上禁止运行该脚本࿰…...

【信号处理】基于高斯函数的Caputo-Fabrizio分数阶导数闭式表达式及其在信号处理中的应用附matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量m…...
)
告别手写轮播!用vue-j-scroll插件5分钟搞定Vue列表无缝滚动(含鼠标悬停控制)
5分钟极速集成:用vue-j-scroll实现Vue列表智能滚动方案 在数据密集型的现代Web应用中,动态列表展示几乎成为标配需求。无论是后台管理系统的操作日志、金融平台的实时交易流水,还是新闻客户端的资讯推送,流畅的自动滚动效果不仅能…...

Perplexity体验真相曝光:92%用户忽略的3个隐藏缺陷及2024最新优化方案
更多请点击: https://intelliparadigm.com 第一章:Perplexity用户评论汇总 主流平台高频反馈主题 用户在Reddit、Product Hunt及App Store等平台对Perplexity的评价呈现显著两极分化:专业用户高度认可其引用溯源能力与无幻觉回答质量&#…...

当贝盒子H5 64G版618首销TOP1!多平台登顶,凭什么这么火?
2026年5月14日,当贝官方发布了618抢先购首日当贝盒子H5 64G版的首销战报。据官方数据显示,这款重磅升级的电视盒子在京东、天猫、抖音三大主流电商平台的电视盒子类目热销榜中,全部拿下TOP1席位,成为今年618大促第一天的现象级爆款…...

如何新建自己的应用
建议步骤如下。 1 创建 WPF 项目 项目文件至少包含: <TargetFramework>net7.0-windows</TargetFramework> <UseWPF>true</UseWPF>2 引用基础库 至少引用: HeBianGu.Base.WpfBaseHeBianGu.General.WpfControlLib 根据需要再…...
)
告别手写代码!用Roboflow的Auto-Orient和Mosaic增强你的YOLO数据集(附完整流程)
零代码实现YOLO数据集增强:Roboflow自动化工具全解析 在目标检测领域,数据质量往往直接决定模型性能上限。传统数据增强方法需要开发者手动编写Python脚本调整图像方向、处理标注格式,不仅耗时耗力,还容易因格式兼容性问题导致训练…...

CTF夺旗赛利器:手把手教你用GitHack挖掘.git泄露背后的Web漏洞
CTF夺旗赛利器:手把手教你用GitHack挖掘.git泄露背后的Web漏洞 在CTF竞赛和实战渗透测试中,.git目录泄露一直是Web安全领域的经典漏洞场景。这种看似简单的配置错误,往往能成为攻击者打开系统后门的金钥匙。本文将带您深入探索如何利用GitHac…...

Windows电脑运行安卓应用终极指南:APK安装器完整教程
Windows电脑运行安卓应用终极指南:APK安装器完整教程 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想过,在Windows电脑上直接运行安…...
)
新手避坑指南:用CCS10和LaunchXL-F28379D点亮第一个LED(GPIO输出两种方法详解)
从零点亮LED:LaunchXL-F28379D开发板GPIO实战避坑手册 刚拿到LaunchXL-F28379D开发板时,那种既兴奋又忐忑的心情我至今记忆犹新。作为TI C2000系列中的明星产品,这块板子强大的DSP性能与丰富的外设令人跃跃欲试,但面对密密麻麻的英…...

用AI Agent + 亚马逊实时数据API打破大卖家数据垄断:架构设计与完整实现
Tags: Amazon API AI Agent LangChain Python 电商数据 实时数据 难度: 中级 | 阅读时长: 15分钟背景与问题 亚马逊大卖家(年GMV 1000万)的核心竞争优势之一是实时数据能力:每15-30分钟采样竞品BSR、价格、库存&#x…...