0基础学习PyFlink——使用datagen生成流式数据
大纲
- 可控参数
- 字段级规则
- 生成方式
- 数值控制
- 时间戳控制
- 表级规则
- 生成速度
- 生成总量
- 结构
- 生成环境
- 定义行结构
- 定义表信息
- 案例
- 随机Int型
- 顺序Int型
- 随机型Int数组
- 带时间戳的多列数据
- 完整代码
- 参考资料
在研究Flink的水位线(WaterMark)技术之前,我们可能需要Flink接收到流式数据,比如接入Kafka等。这就要求引入其他组件,增加了学习的难度。而Flink自身提供了datagen连接器,它可以用于生成流式数据,让问题内聚在Flink代码内部,从而降低学习探索的难度。
本节我们就介绍如何使用datagen生成数据。
可控参数
我们可以使用option方法控制生成的一些规则,主要分为“字段级规则”和“表级规则”。
字段级规则
顾名思义,字段级规则是指该规则作用于具体哪个字段,这就需要指明字段的名称——fields.col_name。
生成方式
字段的生成方式由下面的字符串形式来控制(#表示字段的名称,下同)
fields.#.kind
可选值有:
- random:随机方式,比如5,2,1,4,6……。
- sequence:顺序方式,比如1,2,3,4,5,6……。
数值控制
如果kind是sequence,则数值控制使用:
- fields.#.start:区间的起始值。
- fields.#.end:区间的结束值。
如果配置了这个两个参数,则会生成有限个数的数据。
如果kind是random,则数值控制使用:
- fields.#.min:随机算法会选取的最小值。
- fields.#.max:随机算法会选取的最大值。
时间戳控制
fields.#.max-past仅仅可以用于TIMESTAMP和TIMESTAMP_LTZ类型的数据。它表示离现在时间戳最大的时间差,这个默认值是0。TIMESTAMP和TIMESTAMP_LTZ只支持random模式生成,这就需要控制随机值的区间。如果区间太小,我们生成的时间可能非常集中。后面我们会做相关测试。
表级规则
生成速度
rows-per-second表示每秒可以生成几条数据。
生成总量
number-of-rows表示一共可以生成多少条数据。如果这个参数不设置,则表示可以生成无界流。
结构
生成环境
我们需要流式环境,而datagen是Table API的连接器,于是使用流式执行环境创建一个流式表环境。
stream_execute_env = StreamExecutionEnvironment.get_execution_environment()stream_execute_env.set_runtime_mode(RuntimeExecutionMode.STREAMING)stream_table_env = StreamTableEnvironment.create(stream_execution_environment=stream_execute_env)
定义行结构
schame = Schema.new_builder().column('seed', DataTypes.INT()).build()
这个结构以及支持的生成模式是:
| Type | Supported Generators |
|---|---|
| BOOLEAN | random |
| CHAR | random / sequence |
| VARCHAR | random / sequence |
| BINARY | random / sequence |
| VARBINARY | random / sequence |
| STRING | random / sequence |
| DECIMAL | random / sequence |
| TINYINT | random / sequence |
| SMALLINT | random / sequence |
| INT | random / sequence |
| BIGINT | random / sequence |
| FLOAT | random / sequence |
| DOUBLE | random / sequence |
| DATE | random |
| TIME | random |
| TIMESTAMP | random |
| TIMESTAMP_LTZ | random |
| INTERVAL YEAR TO MONTH | random |
| INTERVAL DAY TO MONTH | random |
| ROW | random |
| ARRAY | random |
| MAP | random |
| MULTISET | random |
定义表信息
下面这个例子就是给seed字段按随机模式,生成seed_min和seed_max之间的数值,并且每秒生成rows_per_second行。
table_descriptor = TableDescriptor.for_connector('datagen') \.schema(schame) \.option('fields.seed.kind', 'random') \.option('fields.seed.min', str(seed_min)) \.option('fields.seed.max', str(seed_max)) \.option('rows-per-second', str(rows_per_second)) \.build()
案例
随机Int型
每秒生成5行数据,每行数据中seed字段值随机在最小值0和最大值100之间。由于没有指定number-of-rows,生成的是无界流。
def gen_random_int():stream_execute_env = StreamExecutionEnvironment.get_execution_environment()stream_execute_env.set_runtime_mode(RuntimeExecutionMode.STREAMING)stream_table_env = StreamTableEnvironment.create(stream_execution_environment=stream_execute_env)seed_min = 0seed_max = 100rows_per_second = 5schame = Schema.new_builder().column('seed', DataTypes.INT()).build()table_descriptor = TableDescriptor.for_connector('datagen') \.schema(schame) \.option('fields.seed.kind', 'random') \.option('fields.seed.min', str(seed_min)) \.option('fields.seed.max', str(seed_max)) \.option('rows-per-second', str(rows_per_second)) \.build()stream_table_env.create_temporary_table('source', table_descriptor)table = stream_table_env.from_path('source')table.execute().print()
+----+-------------+
| op | seed |
+----+-------------+
| +I | 25 |
| +I | 28 |
| +I | 73 |
| +I | 68 |
| +I | 40 |
| +I | 55 |
| +I | 6 |
| +I | 41 |
| +I | 16 |
| +I | 19 |
……
顺序Int型
每秒生成5行数据,每行数据中seed字段值从1开始递增,一直自增到10。由于设置了最大和最小值,生成的是有界流。
def gen_sequence_int():stream_execute_env = StreamExecutionEnvironment.get_execution_environment()stream_execute_env.set_runtime_mode(RuntimeExecutionMode.STREAMING)stream_table_env = StreamTableEnvironment.create(stream_execution_environment=stream_execute_env)seed_min = 1seed_max = 10rows_per_second = 5schame = Schema.new_builder().column('seed', DataTypes.INT()).build()table_descriptor = TableDescriptor.for_connector('datagen') \.schema(schame) \.option('fields.seed.kind', 'sequence') \.option('fields.seed.start', str(seed_min)) \.option('fields.seed.end', str(seed_max)) \.option('rows-per-second', str(rows_per_second)) \.build()stream_table_env.create_temporary_table('source', table_descriptor)table = stream_table_env.from_path('source')table.execute().print()
+----+-------------+
| op | seed |
+----+-------------+
| +I | 1 |
| +I | 2 |
| +I | 3 |
| +I | 4 |
| +I | 5 |
| +I | 6 |
| +I | 7 |
| +I | 8 |
| +I | 9 |
| +I | 10 |
+----+-------------+
10 rows in set
随机型Int数组
每秒生成5行数据,每行数据中seed字段是一个Int型数组,数组里面的每个元素也是随机的。
def gen_random_int_array():stream_execute_env = StreamExecutionEnvironment.get_execution_environment()stream_execute_env.set_runtime_mode(RuntimeExecutionMode.STREAMING)stream_table_env = StreamTableEnvironment.create(stream_execution_environment=stream_execute_env)rows_per_second = 5schame = Schema.new_builder().column('seed', DataTypes.ARRAY(DataTypes.INT())) \.build()table_descriptor = TableDescriptor.for_connector('datagen') \.schema(schame) \.option('fields.seed.kind', 'random') \.option('rows-per-second', str(rows_per_second)) \.build()stream_table_env.create_temporary_table('source', table_descriptor)table = stream_table_env.from_path('source')table.execute().print()
+----+--------------------------------+
| op | seed |
+----+--------------------------------+
| +I | [625785630, -933999461, -48... |
| +I | [2087310154, 1602723641, 19... |
| +I | [1299442620, -613376781, -8... |
| +I | [2051511574, 246258035, -16... |
| +I | [2029482070, -1496468635, -... |
| +I | [1230213175, -1506525784, 7... |
| +I | [501476712, 1901967363, -56... |
……
带时间戳的多列数据
每秒生成5行数据,每行数据中seed字段值随机在最小值0和最大值100之间;timestamp字段随机在当前时间戳和“当前时间戳+max-past”之间。
def gen_random_int_and_timestamp():stream_execute_env = StreamExecutionEnvironment.get_execution_environment()stream_execute_env.set_runtime_mode(RuntimeExecutionMode.STREAMING)stream_table_env = StreamTableEnvironment.create(stream_execution_environment=stream_execute_env)seed_min = 0seed_max = 100rows_per_second = 5schame = Schema.new_builder().column('seed', DataTypes.INT()) \.column('timestamp', DataTypes.TIMESTAMP()) \.build()table_descriptor = TableDescriptor.for_connector('datagen') \.schema(schame) \.option('fields.seed.kind', 'random') \.option('fields.seed.min', str(seed_min)) \.option('fields.seed.max', str(seed_max)) \.option('fields.timestamp.kind', 'random') \.option('fields.timestamp.max-past', '0') \.option('rows-per-second', str(rows_per_second)) \.build()stream_table_env.create_temporary_table('source', table_descriptor)table = stream_table_env.from_path('source')table.execute().print()
由于max-past值为0,所以我们看到上例中每秒生成的timestamp 都极接近。
+----+-------------+----------------------------+
| op | seed | timestamp |
+----+-------------+----------------------------+
| +I | 66 | 2023-11-02 13:53:29.082000 |
| +I | 9 | 2023-11-02 13:53:29.146000 |
| +I | 12 | 2023-11-02 13:53:29.146000 |
| +I | 52 | 2023-11-02 13:53:29.146000 |
| +I | 29 | 2023-11-02 13:53:29.146000 |
| +I | 63 | 2023-11-02 13:53:30.066000 |
| +I | 25 | 2023-11-02 13:53:30.066000 |
| +I | 21 | 2023-11-02 13:53:30.066000 |
| +I | 24 | 2023-11-02 13:53:30.066000 |
| +I | 6 | 2023-11-02 13:53:30.066000 |
| +I | 62 | 2023-11-02 13:53:31.067000 |
| +I | 57 | 2023-11-02 13:53:31.067000 |
| +I | 44 | 2023-11-02 13:53:31.067000 |
| +I | 6 | 2023-11-02 13:53:31.067000 |
| +I | 16 | 2023-11-02 13:53:31.067000 |
……
如果我们把max-past放大到比较大的数值,timestamp也将大幅度变化。
.option('fields.timestamp.max-past', '10000')
+----+-------------+----------------------------+
| op | seed | timestamp |
+----+-------------+----------------------------+
| +I | 89 | 2023-11-02 13:57:17.342000 |
| +I | 35 | 2023-11-02 13:57:10.915000 |
| +I | 32 | 2023-11-02 13:57:11.045000 |
| +I | 74 | 2023-11-02 13:57:18.407000 |
| +I | 24 | 2023-11-02 13:57:13.603000 |
| +I | 82 | 2023-11-02 13:57:12.139000 |
| +I | 41 | 2023-11-02 13:57:16.129000 |
| +I | 95 | 2023-11-02 13:57:16.592000 |
| +I | 80 | 2023-11-02 13:57:14.364000 |
| +I | 60 | 2023-11-02 13:57:18.994000 |
| +I | 56 | 2023-11-02 13:57:19.330000 |
| +I | 10 | 2023-11-02 13:57:18.876000 |
| +I | 43 | 2023-11-02 13:57:12.449000 |
| +I | 73 | 2023-11-02 13:57:13.183000 |
| +I | 17 | 2023-11-02 13:57:18.736000 |
| +I | 46 | 2023-11-02 13:57:21.368000 |
……
完整代码
from pyflink.datastream import StreamExecutionEnvironment,RuntimeExecutionMode
from pyflink.table import StreamTableEnvironment, TableDescriptor, Schema, DataTypesdef gen_random_int():stream_execute_env = StreamExecutionEnvironment.get_execution_environment()stream_execute_env.set_runtime_mode(RuntimeExecutionMode.STREAMING)stream_table_env = StreamTableEnvironment.create(stream_execution_environment=stream_execute_env)seed_min = 0seed_max = 100rows_per_second = 5schame = Schema.new_builder().column('seed', DataTypes.INT()).build()table_descriptor = TableDescriptor.for_connector('datagen') \.schema(schame) \.option('fields.seed.kind', 'random') \.option('fields.seed.min', str(seed_min)) \.option('fields.seed.max', str(seed_max)) \.option('rows-per-second', str(rows_per_second)) \.build()stream_table_env.create_temporary_table('source', table_descriptor)table = stream_table_env.from_path('source')table.execute().print()def gen_sequence_int():stream_execute_env = StreamExecutionEnvironment.get_execution_environment()stream_execute_env.set_runtime_mode(RuntimeExecutionMode.STREAMING)stream_table_env = StreamTableEnvironment.create(stream_execution_environment=stream_execute_env)seed_min = 1seed_max = 10rows_per_second = 5schame = Schema.new_builder().column('seed', DataTypes.INT()).build()table_descriptor = TableDescriptor.for_connector('datagen') \.schema(schame) \.option('fields.seed.kind', 'sequence') \.option('fields.seed.start', str(seed_min)) \.option('fields.seed.end', str(seed_max)) \.option('rows-per-second', str(rows_per_second)) \.build()stream_table_env.create_temporary_table('source', table_descriptor)table = stream_table_env.from_path('source')table.execute().print()def gen_sequence_string():stream_execute_env = StreamExecutionEnvironment.get_execution_environment()stream_execute_env.set_runtime_mode(RuntimeExecutionMode.STREAMING)stream_table_env = StreamTableEnvironment.create(stream_execution_environment=stream_execute_env)seed_min = 0seed_max = 100rows_per_second = 5schame = Schema.new_builder().column('seed', DataTypes.STRING()).build()table_descriptor = TableDescriptor.for_connector('datagen') \.schema(schame) \.option('fields.seed.kind', 'sequence') \.option('fields.seed.start', str(seed_min)) \.option('fields.seed.end', str(seed_max)) \.option('rows-per-second', str(rows_per_second)) \.build()stream_table_env.create_temporary_table('source', table_descriptor)table = stream_table_env.from_path('source')table.execute().print()def gen_random_char():stream_execute_env = StreamExecutionEnvironment.get_execution_environment()stream_execute_env.set_runtime_mode(RuntimeExecutionMode.STREAMING)stream_table_env = StreamTableEnvironment.create(stream_execution_environment=stream_execute_env)rows_per_second = 5schame = Schema.new_builder().column('seed', DataTypes.CHAR(4)).build()table_descriptor = TableDescriptor.for_connector('datagen') \.schema(schame) \.option('fields.seed.kind', 'random') \.option('rows-per-second', str(rows_per_second)) \.build()stream_table_env.create_temporary_table('source', table_descriptor)table = stream_table_env.from_path('source')table.execute().print()def gen_random_int_and_timestamp():stream_execute_env = StreamExecutionEnvironment.get_execution_environment()stream_execute_env.set_runtime_mode(RuntimeExecutionMode.STREAMING)stream_table_env = StreamTableEnvironment.create(stream_execution_environment=stream_execute_env)seed_min = 0seed_max = 100rows_per_second = 5schame = Schema.new_builder().column('seed', DataTypes.INT()) \.column('timestamp', DataTypes.TIMESTAMP()) \.build()table_descriptor = TableDescriptor.for_connector('datagen') \.schema(schame) \.option('fields.seed.kind', 'random') \.option('fields.seed.min', str(seed_min)) \.option('fields.seed.max', str(seed_max)) \.option('fields.timestamp.kind', 'random') \.option('fields.timestamp.max-past', '10000') \.option('rows-per-second', str(rows_per_second)) \.build()stream_table_env.create_temporary_table('source', table_descriptor)table = stream_table_env.from_path('source')table.execute().print()def gen_random_int_array():stream_execute_env = StreamExecutionEnvironment.get_execution_environment()stream_execute_env.set_runtime_mode(RuntimeExecutionMode.STREAMING)stream_table_env = StreamTableEnvironment.create(stream_execution_environment=stream_execute_env)rows_per_second = 5schame = Schema.new_builder().column('seed', DataTypes.ARRAY(DataTypes.INT())) \.build()table_descriptor = TableDescriptor.for_connector('datagen') \.schema(schame) \.option('fields.seed.kind', 'random') \.option('rows-per-second', str(rows_per_second)) \.build()stream_table_env.create_temporary_table('source', table_descriptor)table = stream_table_env.from_path('source')table.execute().print()def gen_random_map():stream_execute_env = StreamExecutionEnvironment.get_execution_environment()stream_execute_env.set_runtime_mode(RuntimeExecutionMode.STREAMING)stream_table_env = StreamTableEnvironment.create(stream_execution_environment=stream_execute_env)rows_per_second = 5schame = Schema.new_builder().column('seed', DataTypes.MAP(DataTypes.STRING(), DataTypes.INT())) \.build()table_descriptor = TableDescriptor.for_connector('datagen') \.schema(schame) \.option('fields.seed.kind', 'random') \.option('rows-per-second', str(rows_per_second)) \.build()stream_table_env.create_temporary_table('source', table_descriptor)table = stream_table_env.from_path('source')table.execute().print()def gen_random_multiset():stream_execute_env = StreamExecutionEnvironment.get_execution_environment()stream_execute_env.set_runtime_mode(RuntimeExecutionMode.STREAMING)stream_table_env = StreamTableEnvironment.create(stream_execution_environment=stream_execute_env)rows_per_second = 5schame = Schema.new_builder().column('seed', DataTypes.MULTISET(DataTypes.STRING())) \.build()table_descriptor = TableDescriptor.for_connector('datagen') \.schema(schame) \.option('fields.seed.kind', 'random') \.option('rows-per-second', str(rows_per_second)) \.build()stream_table_env.create_temporary_table('source', table_descriptor)table = stream_table_env.from_path('source')table.execute().print()def gen_random_row():stream_execute_env = StreamExecutionEnvironment.get_execution_environment()stream_execute_env.set_runtime_mode(RuntimeExecutionMode.STREAMING)stream_table_env = StreamTableEnvironment.create(stream_execution_environment=stream_execute_env)rows_per_second = 5schame = Schema.new_builder().column('seed', DataTypes.ROW([DataTypes.FIELD("id", DataTypes.BIGINT()), DataTypes.FIELD("data", DataTypes.STRING())])) \.build()table_descriptor = TableDescriptor.for_connector('datagen') \.schema(schame) \.option('fields.seed.kind', 'random') \.option('rows-per-second', str(rows_per_second)) \.build()stream_table_env.create_temporary_table('source', table_descriptor)table = stream_table_env.from_path('source')table.execute().print()if __name__ == '__main__':gen_random_int_and_timestamp()
参考资料
- https://nightlies.apache.org/flink/flink-docs-release-1.19/docs/connectors/table/datagen/
相关文章:

0基础学习PyFlink——使用datagen生成流式数据
大纲 可控参数字段级规则生成方式数值控制时间戳控制 表级规则生成速度生成总量 结构生成环境定义行结构定义表信息 案例随机Int型顺序Int型随机型Int数组带时间戳的多列数据 完整代码参考资料 在研究Flink的水位线(WaterMark)技术之前,我们可…...
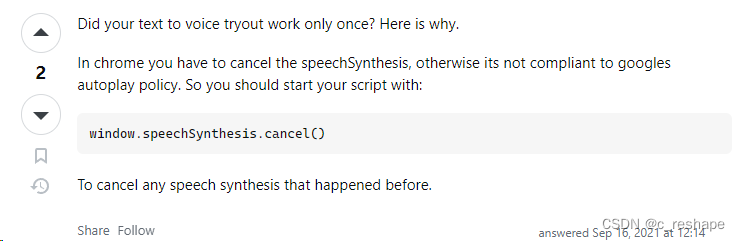
vue使用Web Speech API实现语音播报
SpeechSynthesisUtterance对象用于表示要播放的语音内容,SpeechSynthesis对象则用于控制语音的播放、暂停、停止等操作。 const synth window.speechSynthesis const msg new SpeechSynthesisUtterance() // 语音播放 const playVoice (text) > {synth.canc…...
)
MVC5_Day1(Razor视图引擎)
MVC提供了两种不同的视图引擎:Razor视图引擎、Web Forms视图引擎。 1.代码表达式 1.1 转换字符:核心转换字符,用作标记<>代码之间相互转换的字符。 1.2 两种基本转换:代码表达式、代码块。都是求出值,再写入响…...
超全整理,Jmeter性能测试-脚本error报错排查/分布式压测(详全)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 性能脚本error报错…...
vscode开启emmet语法
需要在setting.json中添加配置 首先进入设置,然后点击右上角 Vue项目添加如下配置 "emmet.syntaxProfiles": { "vue-html": "html", "vue": "html" },React项目添加如下配置 "emmet.includeLanguages&quo…...
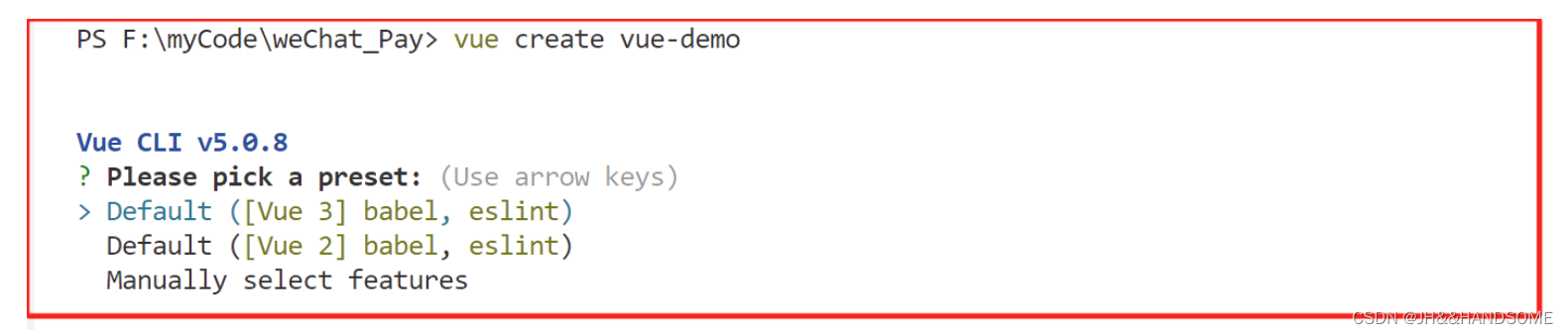
07、vue : 无法加载文件 C:\Users\JH\AppData\Roaming\npm\vue.ps1,因为在此系统上禁止运行脚本。
目录 问题解决: 问题 vue : 无法加载文件 C:\Users\JH\AppData\Roaming\npm\vue.ps1,因为在此系统上禁止运行脚本。 在使用 VSCode 时,创建 Vue 项目报的错 创建不了 Vue 项目 解决: 因为在此系统上禁止运行该脚本࿰…...
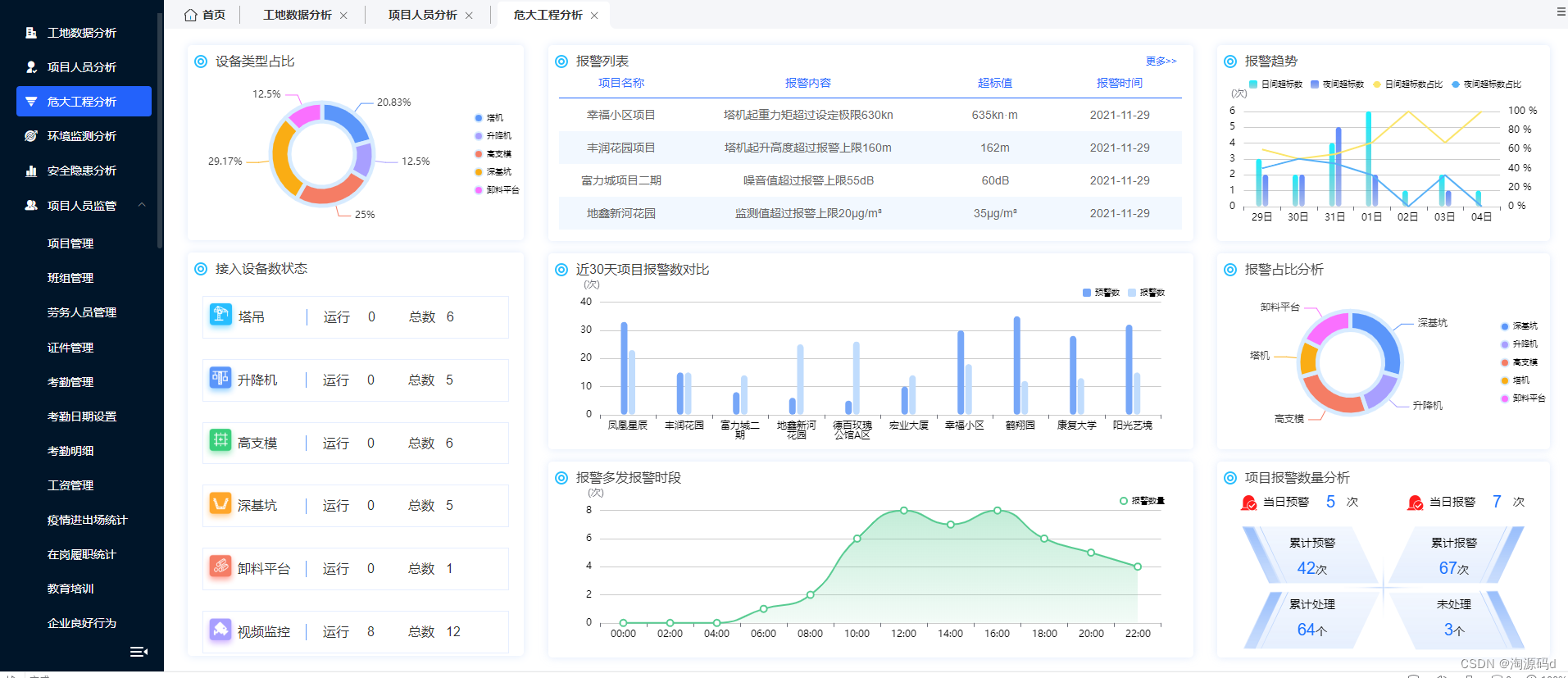
利用移动互联、物联网、智能算法、地理信息系统、大数据分析等信息技术开发的智慧工地云平台源码
智慧工地是指利用移动互联、物联网、智能算法、地理信息系统、大数据挖掘分析等信息技术,提高项目现场的“人•机•料•法•环•安”等施工要素信息化管理水平,实现工程施工可视化智能管理,并逐步实现绿色生态建造。 技术架构:微…...

海康多相机同步取流保存图片
话不多说,直接上代码。代码里包含了多窗口显示图像和保存图片。 #"rtsp://admin:123456qq192.168.10.192/stream1" # rtsp://admin:Admin123192.168.100.103:554/Streaming/Channels/101 #rtsp://admin:Admin123192.168.100.103:554/cam/realmonitor?ch…...

win10 + vs2017 + cmake3.17编译OSG-3.4.1
参考教程:https://blog.csdn.net/bailang_zhizun/article/details/120992244 1. 下载与解压 2. 修改configure 1)Ungrouped Entries -- 》ACTUAL_3RDPARTY_DIR: 设置为: D:/Depend_3rd_party/OSG341/3rdParty 2) Ungrouped E…...

Excel VBA开发基本语句说明
前言 VBA(Visual Basic for Applications)是一种用于编写宏的编程语言,它广泛应用于Microsoft Office套件中的各种应用程序,如Excel、Word、Access和PowerPoint等。在这些应用程序中,VBA可用于自动化任务、定制功能、…...

应用在智能空调中的数字温度传感芯片
智能空调是具有自动调节功能的空调。智能空调系统能根据外界气候条件,按照预先设定的指标对温度、湿度、空气清洁度传感器所传来的信号进行分析、判断、及时自动打开制冷、加热、去湿及空气净化等功能的空调。适合放在卧室,客厅等地方。 在中央控制系统…...

Qt界面美化之Qt Style Sheets
Qt style sheet 简称QSS style sheet可以在代码中单独对某个控件使用,例如: labelLEDLIN new QLabel("",this); labelLEDLIN->setFixedSize(36,36); labelLEDLIN->setStyleSheet("background-color:red;border-radius:18px;colo…...
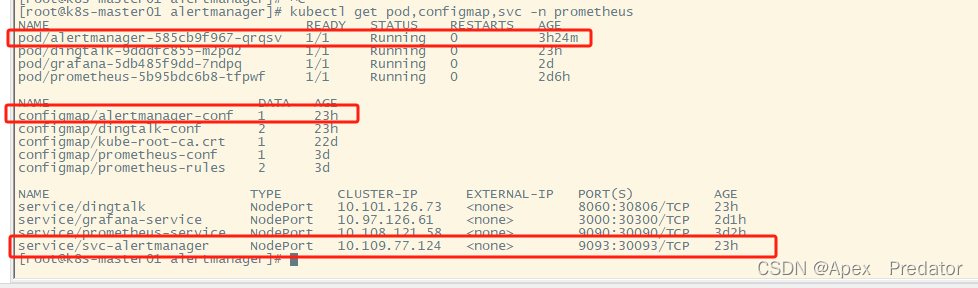
prometheus监控告警部署(k8s内部)
一、部署prometheus 先来说明一下需要用到的组件,需要使用pv、pvc存放prometheus的数据,使用pvc存放数据即使pod挂了删除重建也不会丢失数据,使用configmap挂载prometheus的配置文件和告警规则文件,使用service开放对外访问prometheus服务的端…...

数字孪生特高压电网三维可视化平台实现能源智能管理
电力是现代社会不可或缺的基础能源,而有效管理电力资源对于实现可持续发展至关重要。近年来,随着物联网、大数据、人工智能等技术的快速发展,电网领域的数字化转型已经成为一种趋势。而其中关键的一环便是电网三维数字孪生技术,它…...
12.JavaScript(WebAPI) - JS api文献精解
文章目录 1.WebAPI 背景知识1.1什么是 WebAPI1.2什么是 API1.3API 参考文档 2.DOM 基本概念2.1什么是 DOM2.2DOM 树 3.获取元素3.1querySelector3.2querySelectorAll 4.事件初识4.1基本概念4.2事件三要素4.3简单示例 5.操作元素5.1获取/修改元素内容5.1.1innerText5.1.2innerHT…...

亚马逊云科技:让生成式AI真正走向普惠
伴随着ChatGPT的横空出世,生成式AI(Artificial Intelligence Generated Content,也称AIGC)大潮也以锐不可当之势席卷全球。从各行各业的商业领袖,到千千万万的程序员和开发者,都在思考如何借助生成式AI技术…...
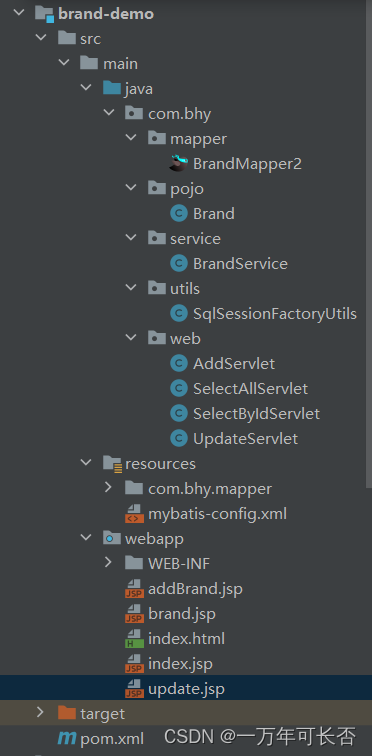
Java web(四):JSP
文章目录 一、JSP1.1 概述1.2 JSP入门1.3 JSP脚本1.4 缺点 二、EI表达式三、JSTL3.1 标签3.2 JSTL使用3.3 代码演示 四、MVC模式和三层架构五、项目实战【完成增删改查】 一、JSP 1.1 概述 JSP(全称:Java Server Pages):Java 服…...

HarmonyOS(二)—— 初识ArkTS开发语言(中)之ArkTS的由来和演进
前言 在上一篇文章HarmonyOS(二)—— 初识ArkTS开发语言(上)之TypeScript入门,我初识了TypeScript相关知识点,也知道ArkTS是华为基于TypeScript发展演化而来。 从最初的基础的逻辑交互能力,到…...
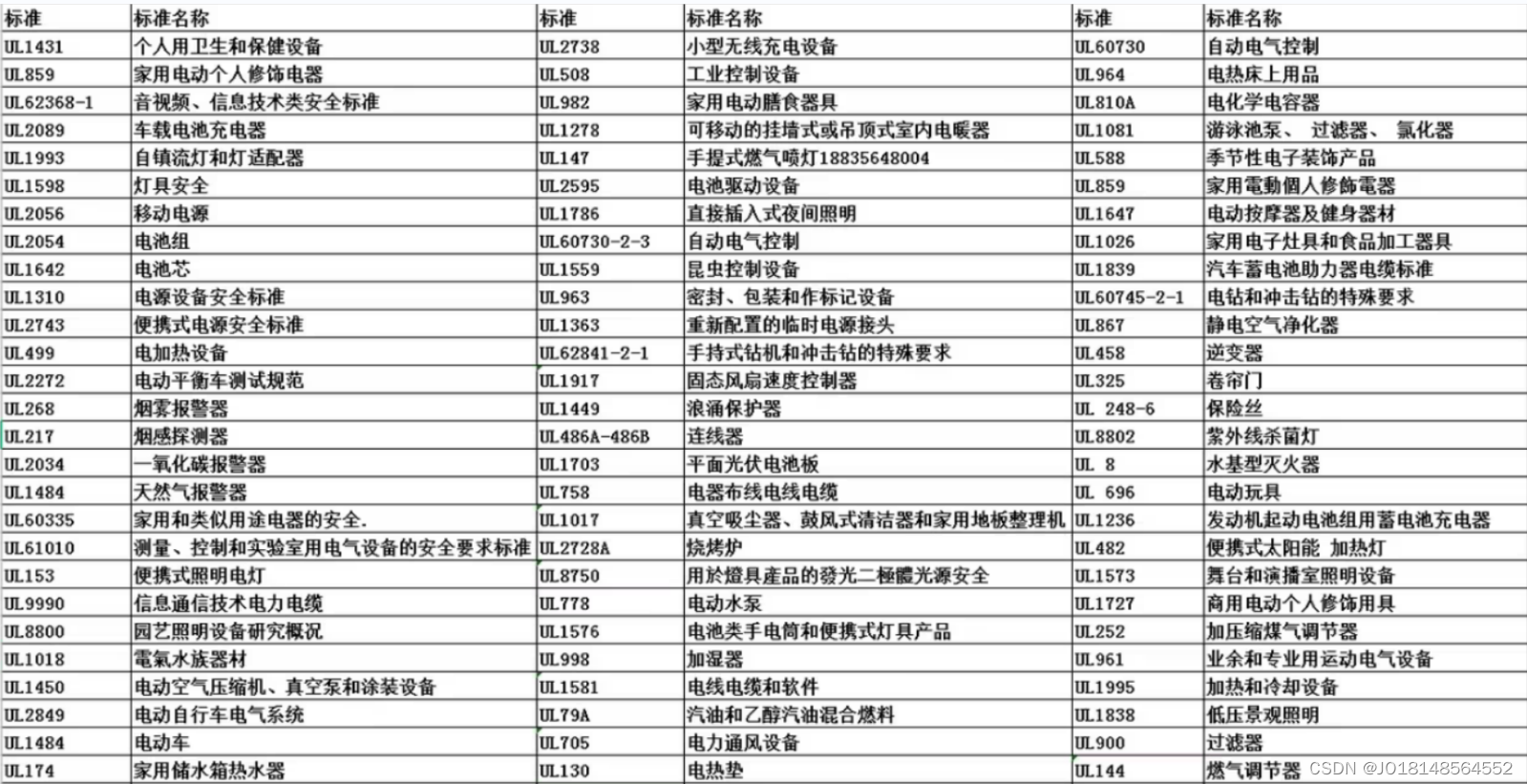
电子产品上架Temu平台需要做什么认证?UL测试报告
2022年8月17日报道,TEMU正在筹备跨境电商平台。9月1日,TEMU跨境电商平台正式在海外上线,首站将面向北美市场,该平台命名为TEMU,App Store应用详情页显示意为“Team Up,Price Down”,即买得人越多…...

热点报告 | 健身人群抵抗入冬肥,Dirtyfit引领23秋冬潮流?
您是否曾有以下困惑?打开小红书首页推荐,似乎已经被算法教育成了成熟的信息茧房,想要找到下一个热点,又忧虑一叶以障目;看着搜索框热词,又担心无法掌握热词背后的话题命脉,难以在浮光掠影中寻找…...

网络安全有哪些岗位?如何成为一名优秀的网络安全工程师?
网络安全有哪些岗位?如何成为一名优秀的网络安全工程师? 网络安全是什么? 首先说一下什么是网络安全?其中,网络安全工程师工作内容具体有哪些? 网络安全 确保网络系统的硬件、软件及其系统中的数据受到保护…...
)
别再只会if-else了!用状态机思路重构你的STM32寻迹小车代码(附工程源码)
从if-else到状态机:重构STM32寻迹小车的工程化实践 当三个红外传感器同时检测到黑色轨迹时,你的小车应该左转还是右转?当传感器短暂丢失信号时,是紧急刹车还是保持原有动作?这些问题在初学者用if-else堆砌的代码中往往…...

Perplexity学校信息检索终极手册:覆盖K12/高职/高校的12类典型场景+27个可复用Prompt模板
更多请点击: https://codechina.net 第一章:Perplexity学校信息检索终极手册导论 在教育数字化加速演进的今天,高校师生亟需一种高效、可信且语义精准的信息获取方式。Perplexity 作为融合实时网络检索与大语言模型推理能力的智能问答平台&…...

RAG我懂你:从架构到知识库构建
导航 传统大语言模型主要依赖参数中的隐式知识进行回答,容易受到知识过期、幻觉和领域知识不足等问题影响。RAG 的核心思想是:在生成答案之前,先从外部知识库中检索相关信息,再将这些信息作为上下文提供给大语言模型,从…...

CVAT管理员必看:用户权限、任务分割与Datumaro数据导入导出全流程详解
CVAT管理员实战指南:权限配置、任务优化与数据流转全解析 1. 权限管理的艺术:从基础配置到高级控制 在CVAT平台中,权限管理是确保数据安全与协作效率的核心机制。不同于普通标注员视角,管理员需要掌握三个关键权限层级:…...

终极游戏加速指南:如何使用OpenSpeedy免费提升游戏体验
终极游戏加速指南:如何使用OpenSpeedy免费提升游戏体验 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否厌倦了游戏中漫长的等待时间?是否想在单…...
)
实测!Gemini+ChatGPT赋能学术写作:我的论文写作SOP(附提示词)
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 为什么ChatGPT逻辑清晰却写不长?为什么Gemini能深入分析但废话连篇? …...

嵌入式边缘AI论坛参会全攻略:从技术趋势到实战社交
1. 论坛核心价值与参会目标拆解“6天倒计时!”这个标题,精准地抓住了所有技术从业者在面对一个高价值行业活动时,那种既兴奋又略带紧迫感的共同心理。这不仅仅是一个简单的会议通知,它更像是一份来自同行的“战前简报”。对于嵌入…...

深度拆解Pulse算法三大剪枝策略:如何让你的路径搜索快10倍?
深度拆解Pulse算法三大剪枝策略:如何让你的路径搜索快10倍? 在解决复杂的组合优化问题时,如车辆路径规划(VRP)或旅行商问题(TSP),算法的效率往往决定了实际应用的可行性。Pulse算法作…...

FFXIV TexTools终极指南:5步轻松掌握《最终幻想14》模组制作与安装
FFXIV TexTools终极指南:5步轻松掌握《最终幻想14》模组制作与安装 【免费下载链接】FFXIV_TexTools_UI 项目地址: https://gitcode.com/gh_mirrors/ff/FFXIV_TexTools_UI 你是否曾经梦想过在《最终幻想14》中拥有独一无二的角色外观?想要定制专…...