【ElasticSearch系列-04】ElasticSearch的聚合查询操作
ElasticSearch系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】ElasticSearch下载和安装 | https://zhenghuisheng.blog.csdn.net/article/details/129260827 |
| 【二】ElasticSearch概念和基本操作 | https://blog.csdn.net/zhenghuishengq/article/details/134121631 |
| 【三】ElasticSearch的高级查询Query DSL | https://blog.csdn.net/zhenghuishengq/article/details/134159587 |
| 【四】ElasticSearch的聚合查询操作 | https://blog.csdn.net/zhenghuishengq/article/details/134159587 |
ElasticSearch的聚合查询操作
- 一,深入理解es的聚合查询
- 1,Metric Aggregation
- 2,Bucket Aggregation
- 3,Pipeline Aggregation
- 4,ElasticSearch聚合结果不精准原因
- 4.1,不精准原因
- 4.2,如何提高精准度
- 4.3,聚合查询优化
一,深入理解es的聚合查询
在关系型数据库中,存在聚合操作,如mysql的求最大值,最小值,平均值等。在es中,也是存在着这些操作的。
在Elasticsearch中,聚合操作可以分为三类,分别是 Metric Aggregation 、Bucket Aggregation 、Pipeline Aggregation
在针对具体的类型之前,先创建一个索引库,后面的举例都会用到该索引库。首先先创建一个员工索引库,如下面两个属性,一个是姓名,不需要分词,一个是工资
DELETE /employees
#创建索引库
PUT /employees
{"mappings": {"properties": {"name":{"type": "keyword"},"salary":{"type": "integer"}}}
}
创建完成之后,往里面插入一些数据,这里插入10条即可
PUT /employees/_bulk
{ "index" : { "_id" : "1" } }
{ "name" : "huisheng1","salary":35000 }
{ "index" : { "_id" : "2" } }
{ "name" : "huisheng2","salary": 50000}
{ "index" : { "_id" : "3" } }
{ "name" : "huisheng3","salary":18000 }
{ "index" : { "_id" : "4" } }
{ "name" : "huisheng4","salary": 22000}
{ "index" : { "_id" : "5" } }
{ "name" : "huisheng5","salary":18000 }
{ "index" : { "_id" : "6" } }
{ "name" : "huisheng6","salary": 25000}
{ "index" : { "_id" : "7" } }
{ "name" : "huisheng7","salary":20000 }
{ "index" : { "_id" : "8" } }
{ "name" : "huisheng8","salary": 20000}
{ "index" : { "_id" : "9" } }
{ "name" : "huisheng9","salary":22000 }
{ "index" : { "_id" : "10" } }
{ "name" : "huisheng10","salary": 9000}
1,Metric Aggregation
表示的是一些数学运算,可以对文档字段进行统计分析,比如说求min,max,avg等
如求用户的最大工资,就是上面salary字段的最大值,需要通过max关键字。在返回数据时,会将查询的数据以及最终的结果全部返回,因此可以加上一个size属性,其value设置为0
POST /employees/_search
{"size": 0,"aggs": { //前缀,固定搭配"max_salary": { //别名"max": { //需要的聚合操作"field": "salary"}}}
}
求用户的最小工资,需要通过min关键字
POST /employees/_search
{"size": 0,"aggs": {"min_salary": {"min": {"field": "salary"}}}
}
求用户的平均工资,需要通过这个avg的关键字
POST /employees/_search
{"size": 0,"aggs": {"avg_salary": {"avg": {"field": "salary"}}}
}
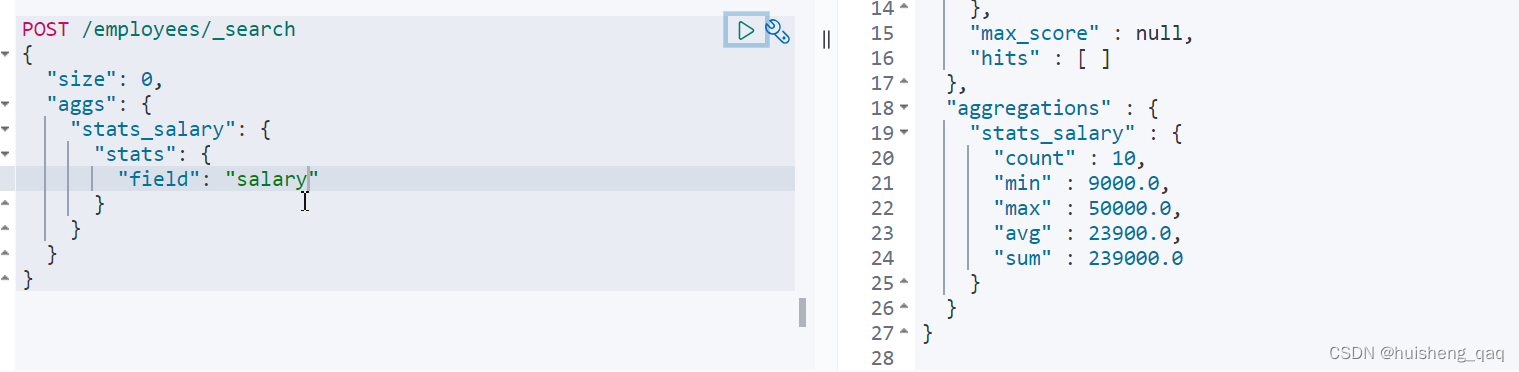
或者直接通过一个 stats ,将要查询的聚合结果值全部返回
POST /employees/_search
{"size": 0,"aggs": {"stats_salary": {"stats": {"field": "salary"}}}
}
去重操作,可以直接使用 cardinality 关键字,去重的字段必须是一个keyword的字段
POST /employees/_search
{"size": 0,"aggs": {"cardinate_salary": { //别名"cardinality": {"field": "salary"}}}
}
2,Bucket Aggregation
桶查询,类似于mysql的分组查询,将相同结果的放在一个桶里面,如对用户的姓名进行分组,最后再对每个组的数据进行统计,并以降序的方式。trems精确查询,一定是要对应 keyword 的字段
GET /employees/_search
{"size": 0,"aggs": {"name_count": {"terms": {"field":"name", //对用户姓名进行分组"size": 10,"order": {"_count": "desc" }}}}
}
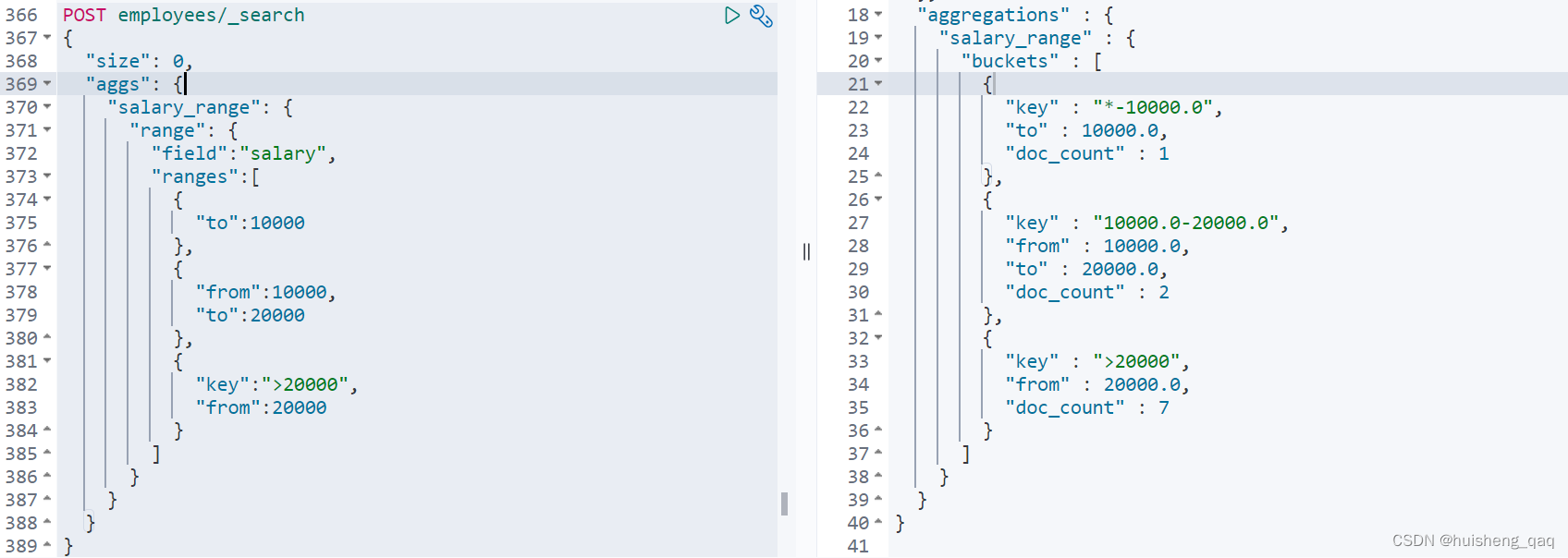
除了这个terms精确查询之外,还可以直接使用这个 ranges 进行分为分组,默认是从闭区间0开始,to的值为区间的结束值。如下面的区间就是 [0-100000),[10000,20000),[20000,无穷)
POST employees/_search
{"size": 0,"aggs": {"salary_range": {"range": {"field":"salary","ranges":[{"to":10000},{"from":10000,"to":20000},{"key":">20000","from":20000}]}}}
}
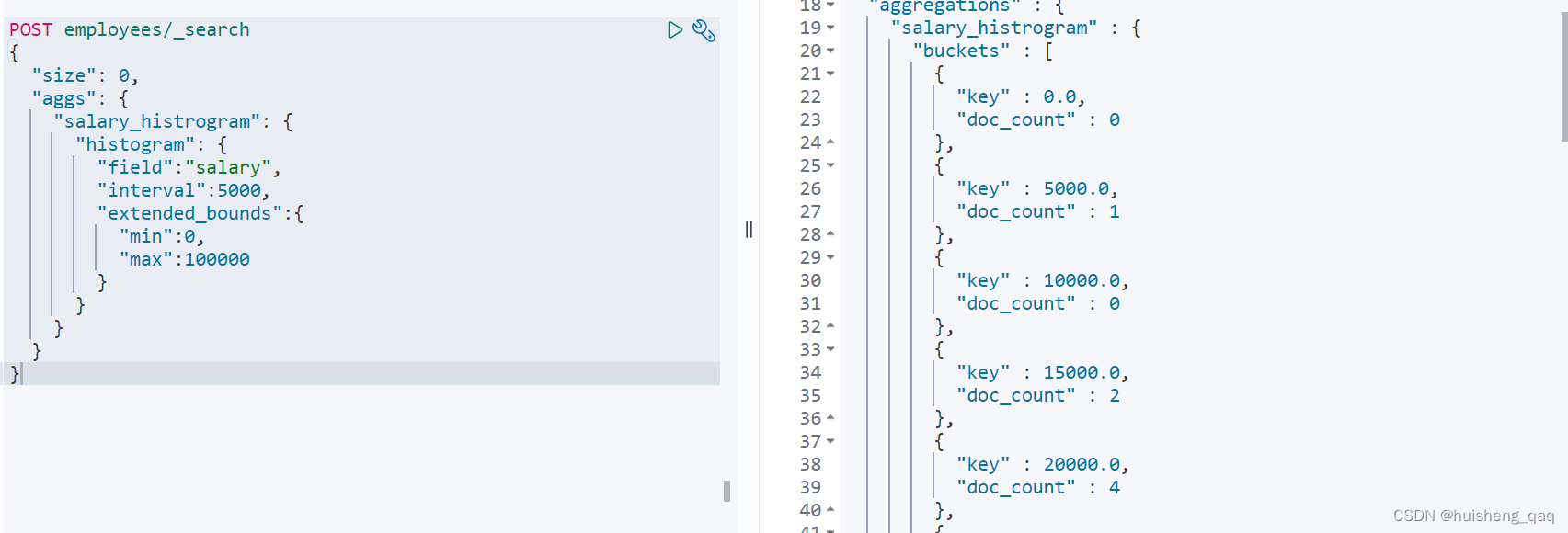
也可以直接按照直方图的方式进行区间分桶,如5000为一个区间
POST employees/_search
{"size": 0,"aggs": {"salary_histrogram": {"histogram": {"field":"salary","interval":5000,"extended_bounds":{"min":0, //直方图的起始值"max":50000 //直方图的最大值}}}}
}
上面的集合单个的查询中,可以直接通过聚合操作将上面的操作嵌套使用。如先分组,随后求分组后的最大值最小值,以及中间可以经过多次分组等。如下面的先通过工资进行分桶,随后再对每一个桶进行求最大值和最小值
POST /employees/_search
{"size": 0,"aggs": {"salary_count": {"terms": {"field": "salary"},"aggs": {"salary": {"stats": {"field": "salary"}}}}}
3,Pipeline Aggregation
表示的是支持聚合操作,允许将前面的结果作为后面的参数使用。如下面的例子,主要是看这个 stats_salary_by_name 里面的结果
POST /employees/_search
{"size": 0,"aggs": { "name": { //别名1"terms": {"field": "name"},"aggs": {"avg_salary": { //别名2"avg": {"field": "salary"}}}},"stats_salary_by_name":{"stats_bucket": { //桶名"buckets_path": "name>avg_salary" //桶路径}}}
}
除了这个 stats_bucket 用于求所有最大值最小值等聚合操作之外,还有下面的这些
cumulative_sum //累计求和
percentiles_bucket //求百分比
min_bucket //求最小值
4,ElasticSearch聚合结果不精准原因
在面对大数据量时,数据的实时性和精确度往往不能同时满足,就是要么只能满足精确度,要么只能满足数据的实时性
4.1,不精准原因
不准确的原因是因为在取数据时,协调者分片每次取的数据是每个分片的最大值的个数,而不是每个分片汇总后的最大值的个数。如取每个分片的top3的数据,如下所示,取出的数据是ABC,是因为第一个分片取出的数据是6、4、6,第二个分片取出的数据是6、2、3,协调者分片汇总数据的时候,会觉得c的结果4会大于d的结果3,所以将c的结果取出。
然而实际上在两个分片中,c的汇总为3+1等于4,d的汇总为3+3等于6,按理是需要将d的结果取出的,反而取出的是c,这就是造成数据不精准的原因

4.2,如何提高精准度
- 如果是数据量小的场景中,可以直接将主分片的值设置为1(推荐使用)
- 如果数据量大的场景,可以调大 shard_size 的值(推荐使用)
- 将size设置成全量值,不推荐使用
- 不用es,改用clickhouse/spark
4.3,聚合查询优化
1,启用 eager global ordinals 来提升高基数聚合性能,就是一个字段的的离散率大一点
2,在插入数据时进行预排序,如提前指定好需要排序的字段。但是这种方式会影响写性能,只适合读多写少的场景
PUT /my_index
{"settings": {"index":{"sort.field": "create_time","sort.order": "desc"}}
3,使用结点缓存Node query cache,可以有效缓存过滤器filter的值
4,使用分片缓存,在查询时直接设置size为0,只返回聚合结果,不返回查询结果
5,拆分聚合,使聚合并行化。通过msearch实现,将一个聚合拆分成多个查询
相关文章:
【ElasticSearch系列-04】ElasticSearch的聚合查询操作
ElasticSearch系列整体栏目 内容链接地址【一】ElasticSearch下载和安装https://zhenghuisheng.blog.csdn.net/article/details/129260827【二】ElasticSearch概念和基本操作https://blog.csdn.net/zhenghuishengq/article/details/134121631【三】ElasticSearch的高级查询Quer…...

Redisson初始
最近的自己,一直都在做些老年的技术,没有啥升级,自己也快麻木了,自己该怎么说,那必须行动起来啊!~来来,我们一起增长自己的内功 分布式锁的最强实现: Redisson 1.概念 在介绍之前,我们要知道这个Redisson是啥? 难道就是Redis的son?(我第一次就这么认为的哈哈!) 事实也的确如…...
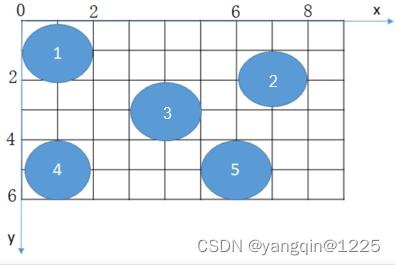
【华为OD题库-018】AI面板识别-Java
题目 Al识别到面板上有N(1<N≤100)个指示灯,灯大小一样,任意两个之间无重叠。由于AI识别误差,每次识别到的指示灯位置可能有差异,以4个坐标值描述Al识别的指示灯的大小和位置(左上角x1,y1,右下角x2.y2)。请输出先行…...
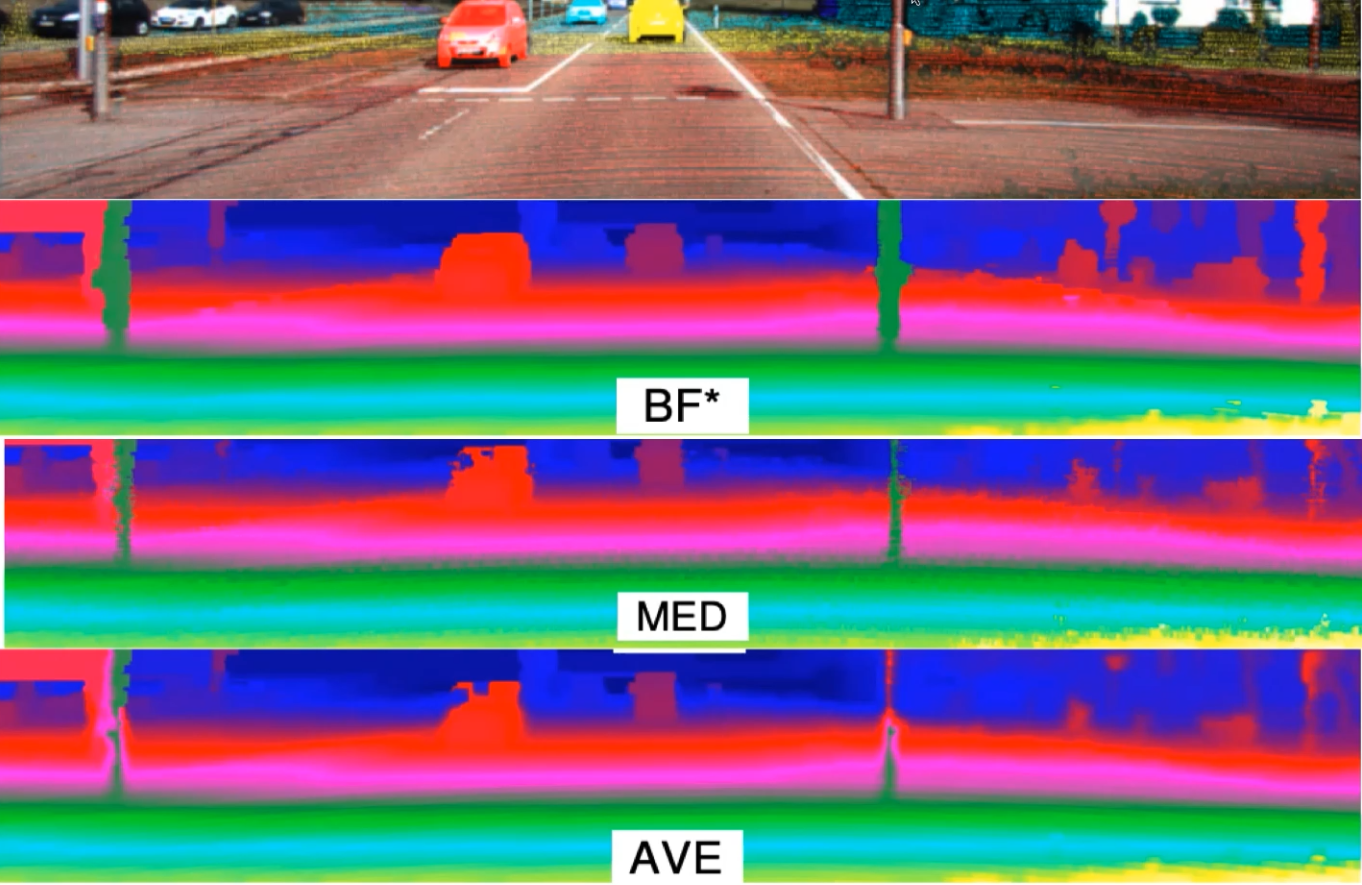
[概述] 点云滤波器
拓扑结构 点云是一种三维数据,有几种方法可以描述其空间结构,以利于展开搜索 https://blog.csdn.net/weixin_45824067/article/details/131317939 KD树 头文件:pcl/kdtree/kdtree_flann.h 函数:pcl::KdTreeFLANN 作用:…...

[笔记] 汉字判断
参考博客:如果判断一个字符是西文字符还是中文字符 结论: 汉字转数字后,会占两位字符位,两位都是负数。 参考下面代码 输入:你 输出:01 #include<bits/stdc.h> using namespace std; int main() {cha…...

Android开发笔记(三)—Activity篇
活动组件Activity 启动和结束生命周期启动模式信息传递Intent显式Intent隐式Intent 向下一个Activity发送数据向上一个Activity返回数据 附加信息利用资源文件配置字符串利用元数据传递配置信息给应用页面注册快捷方式 启动和结束 (1)从当前页面跳到新页…...
nodejs+vue+python+php在线购票系统的设计与实现-毕业设计
伴随着信息时代的到来,以及不断发展起来的微电子技术,这些都为在线购票带来了很好的发展条件。同时,在线购票的范围不断增大,这就需要有一种既能使用又能使用的、便于使用的、便于使用的系统来对其进行管理。在目前这种大环境下&a…...
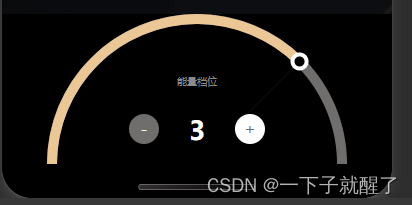
基于Taro + React 实现微信小程序半圆滑块组件、半圆进度条、弧形进度条、半圆滑行轨道(附源码)
效果: 功能点: 1、四个档位 2、可点击加减切换档位 3、可以点击区域切换档位 4、可以滑动切换档位 目的: 给大家提供一些实现思路,找了一圈,一些文章基本不能直接用,错漏百出,代码还藏着掖…...
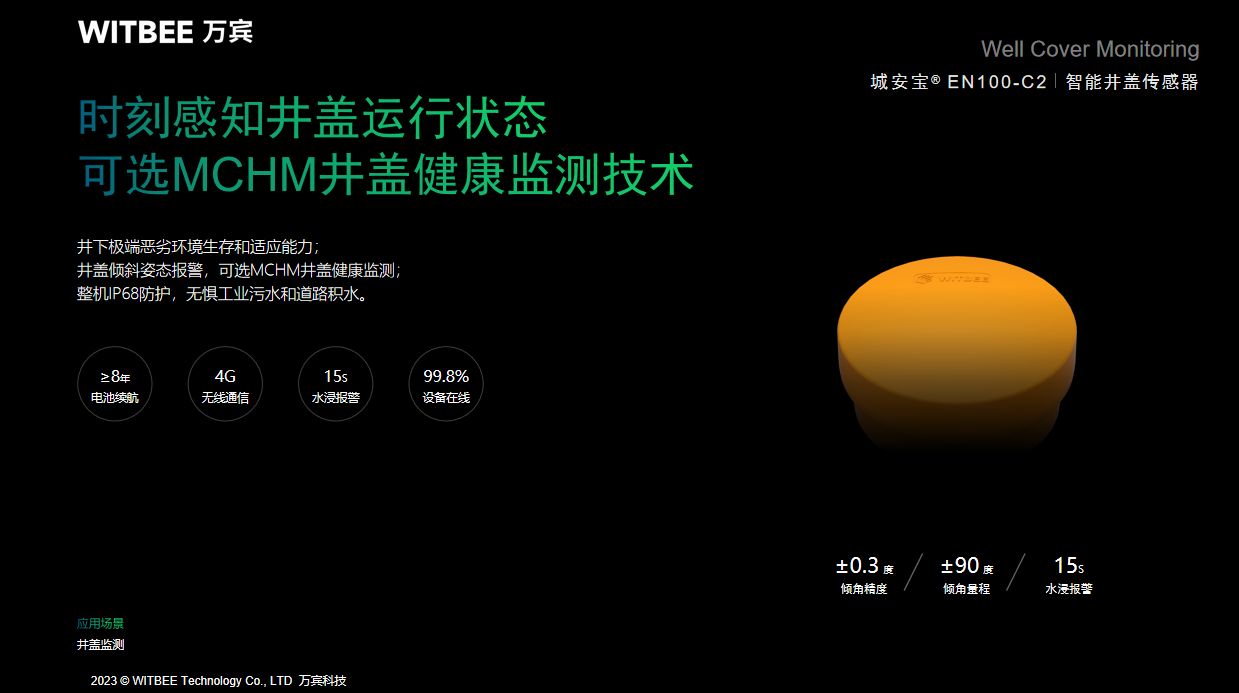
城市内涝解决方案:实时监测,提前预警,让城市更安全
城市内涝积水问题是指城市地区在短时间内遭遇强降雨后,地面积水过多,导致城市交通堵塞、居民生活不便、财产损失等问题。近年来,随着全球气候变化和城市化进程的加速,城市内涝积水问题越来越突出,成为城市发展中的一大…...

编译正点原子LINUXB报错make: arm-linux-gnueabihf-gcc:命令未找到
编译正点原子LINUX报错make: arm-linux-gnueabihf-gcc:命令未找到 1.报错内容2.解决办法3./bin/sh: 1: lzop: not found4.编译成功 1.报错内容 make: arm-linux-gnueabihf-gcc:命令未找到CHK include/config/kernel.releaseCHK include/generat…...
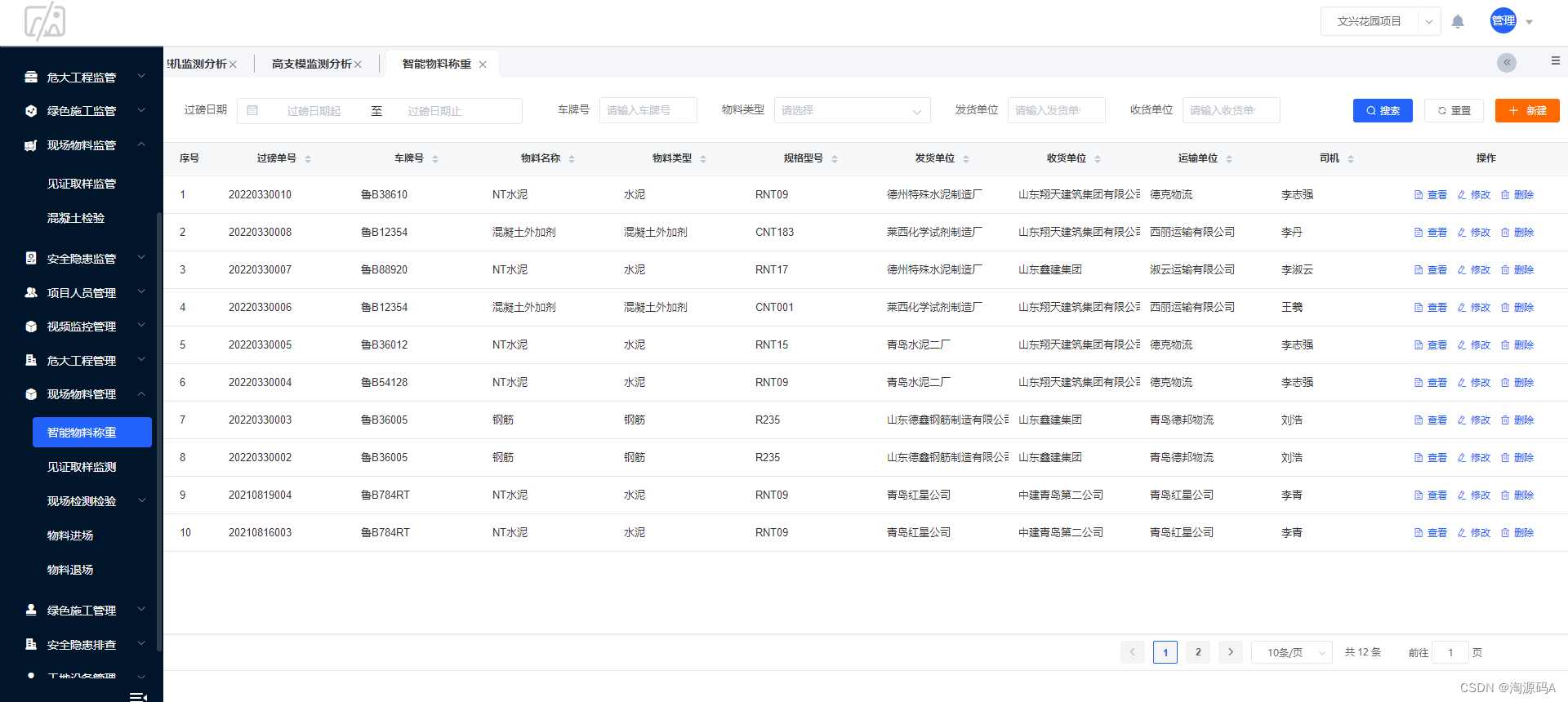
工地现场智慧管理信息化解决方案 智慧工地源码
智慧工地系统充分利用计算机技术、互联网、物联网、云计算、大数据等新一代信息技术,以PC端,移动端,设备端三位一体的管控方式为企业现场工程管理提供了先进的技术手段。让劳务、设备、物料、安全、环境、能源、资料、计划、质量、视频监控等…...
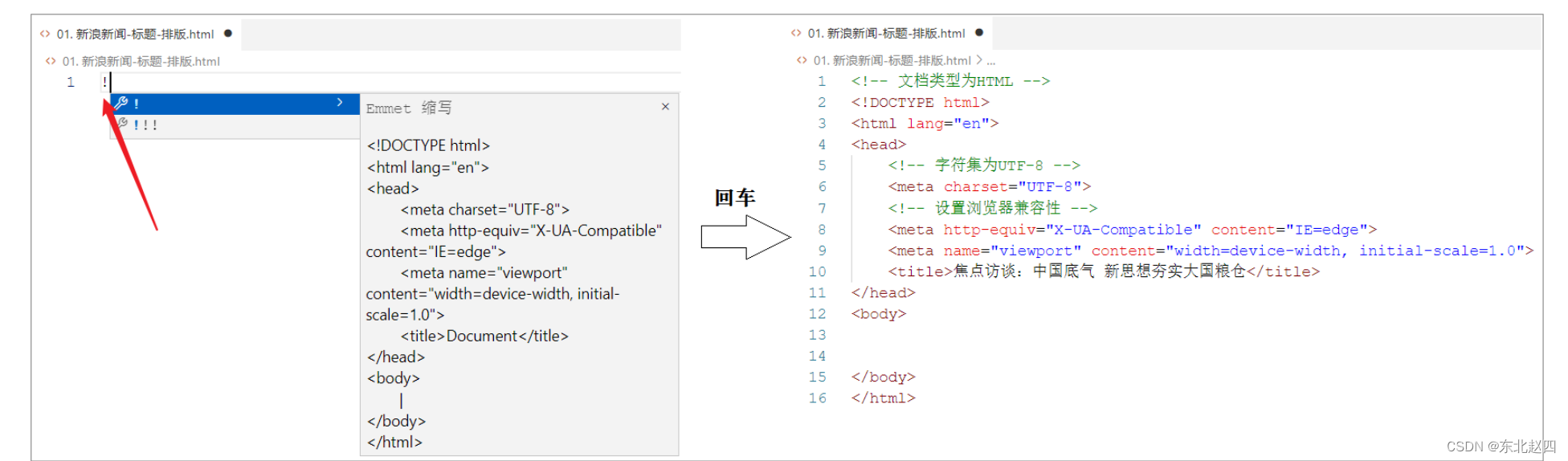
Javaweb之HTML,CSS的详细解析
2. HTML & CSS 1). 什么是HTML ? HTML: HyperText Markup Language,超文本标记语言。 超文本:超越了文本的限制,比普通文本更强大。除了文字信息,还可以定义图片、音频、视频等内容。 标记语言:由标签构成的语言…...
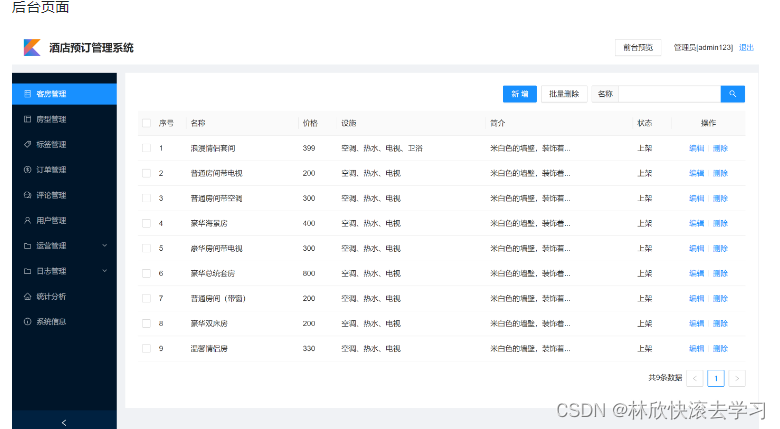
基于python+django+vue开发的酒店预订管理系统 - 毕业设计 - 课程设计
文章目录 源码下载地址项目介绍项目功能界面预览项目备注毕设定制,咨询 源码下载地址 点击这里下载源码 项目介绍 该系统是基于pythondjango开发的酒店预定管理系统。适用场景:大学生、课程作业、毕业设计。学习过程中,如遇问题可在github…...

使用vscode实现远程开发,并通过内网穿透在公网环境下远程连接
文章目录 前言1、安装OpenSSH2、vscode配置ssh3. 局域网测试连接远程服务器4. 公网远程连接4.1 ubuntu安装cpolar内网穿透4.2 创建隧道映射4.3 测试公网远程连接 5. 配置固定TCP端口地址5.1 保留一个固定TCP端口地址5.2 配置固定TCP端口地址5.3 测试固定公网地址远程 前言 远程…...

ArrayList集合2
ArrayList集合的一些方法 ⑥chear()从列表中移除所有元素 ⑦.isEmpty()判断列表中是否包含元素,不包含返回true,否则返回false public class Test{public static void main(String[] args){Arraylist<String> list new Arraylist<String>()…...
vue+asp.net Web api前后端分离项目发布部署
一、前后端项目介绍 1.前端项目是使用vue脚手架进行创建的。 脚手架版本:vue/cli 5.0.8 编译器版本:vs code 1.82.2 2.后端是一个asp.net Core Web API 项目 后端框架版本:.NET 6.0 编译器版本:vs 2022 二、发布部署步骤 第…...
iOS App Store上传项目报错 缺少隐私政策网址(URL)解决方法
iOS App Store上传项目报错 缺少隐私政策网址(URL)解决方法 一、问题如下图所示: 二、解决办法:使用Google浏览器(翻译成中文)直接打开该网址 https://www.freeprivacypolicy.com/free-privacy-policy-generator.php 按…...

如何使用Ruby 多线程爬取数据
现在比较主流的爬虫应该是用python,之前也写了很多关于python的文章。今天在这里我们主要说说ruby。我觉得ruby也是ok的,我试试看写了一个爬虫的小程序,并作出相应的解析。 Ruby中实现网页抓取,一般用的是mechanize,使…...

一文深入了解 CPU 的型号、代际架构与微架构
在 10 月 16 号的时候,Intel 正式发布了第 14 代的酷睿处理器。但还有很多同学看不懂这种发布会上发布的各种 CPU 参数。借着这个时机,给大家深入地讲讲 CPU 的型号规则、代际架构与微架构方面的知识。 CPU 在整个计算机硬件中、技术体系中都算是最最重…...

Java通过cellstyle属性设置Excel单元格常用样式全面总结
最近做了一个导出Excel的功能,导出是个常规导出,但是拿来模板一看,有一些单元格的样式设置,包括合并,背景色,字体等等,毕竟不是常用的东西,需要查阅资料完成,但是搜遍全网…...

扛住十万并发的“冷面保安”:一文扒透限流的四大经典算法与代码实战
在高并发架构中,如果说缓存和 MQ 是替服务器扛伤害的“防弹衣”,那么限流(Rate Limiting)就是守在系统大门外的“冷面保安”。他的核心逻辑极其冷酷:不管外面排队的人有多急,只要超过了系统的最大接待能力&…...

iTop实战指南:3个关键挑战与ITSM平台架构优化策略
iTop实战指南:3个关键挑战与ITSM平台架构优化策略 【免费下载链接】iTop A simple, web based CMDB & IT Service Management tool 项目地址: https://gitcode.com/gh_mirrors/it/iTop 在数字化转型浪潮中,企业IT服务管理面临配置信息分散、…...

加热套、半导体加热带、工业加热夹克是同一种东西吗?
首先明确这个答案是肯定的,,这三种名称指同一种产品。作为北京龙腾圣华(LOTUSANA)的技术人员,我常被客户问到这个问题。我司自2002 年成立之初便自主研发投产此类柔性温控产品,最早行我们定名为加热套&…...

【Perplexity药物信息检索实战指南】:20年药学IT专家亲授3大避坑法则与5步精准检索法
更多请点击: https://codechina.net 第一章:Perplexity药物信息检索实战指南导论 Perplexity 是一款基于大语言模型的实时网络增强型问答工具,其在生物医药领域展现出独特优势——尤其适用于快速定位权威、时效性强的药物信息,如…...

LRC Maker终极指南:5分钟掌握专业级歌词制作技巧
LRC Maker终极指南:5分钟掌握专业级歌词制作技巧 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 你是否曾经为喜爱的歌曲找不到完美同步的歌词而烦恼&am…...

H5GG完整指南:如何用JavaScript和HTML5轻松修改iOS游戏内存
H5GG完整指南:如何用JavaScript和HTML5轻松修改iOS游戏内存 【免费下载链接】H5GG an iOS Mod Engine with JavaScript APIs & Html5 UI 项目地址: https://gitcode.com/gh_mirrors/h5/H5GG 你是否曾经想过修改iOS游戏中的数值,却因为复杂的越…...

告别乱码困扰:3步完成GBK到UTF-8编码转换的终极指南
告别乱码困扰:3步完成GBK到UTF-8编码转换的终极指南 【免费下载链接】GBKtoUTF-8 To transcode text files from GBK to UTF-8 项目地址: https://gitcode.com/gh_mirrors/gb/GBKtoUTF-8 您是否曾遇到过这样的场景:打开一个中文文档,屏…...

拷贝漫画第三方客户端完全解析:解锁高效漫画阅读新体验
拷贝漫画第三方客户端完全解析:解锁高效漫画阅读新体验 【免费下载链接】copymanga 拷贝漫画的第三方APP,仅提供基础功能,更多丰富功能请移步官方版本 项目地址: https://gitcode.com/gh_mirrors/co/copymanga 在数字阅读日益普及的今…...

Android Studio中文界面完整指南:5分钟快速汉化教程
Android Studio中文界面完整指南:5分钟快速汉化教程 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为Android St…...

探索商业成功的奥秘:BABOK Guide v3深度解析
探索商业成功的奥秘:BABOK Guide v3深度解析 【下载地址】商业分析知识体系指南BABOKGuidev3 《商业分析知识体系指南(BABOK Guide v3)》是业界权威的商业分析专业标准,深受全球专业人士的认可与信赖。本指南经过严密的共识驱动开…...