【离线数仓-9-数据仓库开发DWS层设计要点-1d/nd/td表设计】
离线数仓-9-数据仓库开发DWS层设计要点-1d/nd/td表设计
- 离线数仓-9-数据仓库开发DWS层设计要点-1d/nd/td表设计
- 一、DWS层设计要点
- 二、DWS层设计分析 - 1d/nd
- 1.DWS层设计一:不考虑用户维度
- 2.DWS层设计二:考虑用户维度
- 2.DWS层设计三 :考虑用户+商品维度,形成DWS层汇总表
- 最终建表方案:
- 三、DWS层设计分析 - td 历史至今
- 1.以新增下单人数的需求为例
- 三、DWS层设计分析 - 总结
离线数仓-9-数据仓库开发DWS层设计要点-1d/nd/td表设计
一、DWS层设计要点
- DWS层计算是依托于业务层面的需求来实现的,是需求驱动的。
- 设计要点:
- 1.DWS层的设计参考指标体系;
- 具体参考之前文档笔记:https://blog.csdn.net/weixin_38136584/article/details/129167647?spm=1001.2014.3001.5501
- 从0-1搭建dws层步骤:
- 1.分析现有的每个业务需求,这一步最难,每个业务需求怎样计算,然后分析每个业务需求依赖哪些指标,每个指标依赖的派生指标有哪些,构建出业务需求指标的分析视图。
- 2.从分析出来的业务需求视图里面,可以提炼到表格汇总,然后寻找共用的派生指标有哪些
- 3.根据派生指标,来进行设计DWS层表格,在DWS层创建表格和派生指标关系?一对多;哪些派生指标共用公共派生指标表格呢?
- 将业务过程相同、统计周期相同、统计粒度相同的派生指标汇总到一个派生指标对应的表格中,这样DWS层表格就会减少很多。
- 业务过程相同:来自于同一张事实表
- 统计周期相同:在进行过滤的时候,过滤的分区也相同。
- 不同周期的可以放在一个表格中,但是这样存储的话,在进行数据装载的时候,如果牵涉到历史至今的周期和最近一天的周期,那么会全量扫描dwd层全表,但是最新一天的数据,仅仅跟前一日的分区有关系,数据装载的效率降低。
- 建议将不同周期的存放在不同的表格中,即便是业务过程和统计粒度相同。
- 统计粒度相同: 统计粒度相同的话,派生指标计算完毕的数据都是一个值,对应到的都是统计粒度维度,这些计算完的指标,新增一个字段,将结果存放进去即可。
- 将业务过程相同、统计周期相同、统计粒度相同的派生指标汇总到一个派生指标对应的表格中,这样DWS层表格就会减少很多。
- 2.DWS层的数据存储格式为ORC列式存储 + snappy压缩。
- 3.DWS层表名的命名规范为:dws_数据域_统计粒度_业务过程_统计周期(1d/nd/td)
注:1d表示最近1日,nd表示最近n日,td表示历史至今。
- 1.DWS层的设计参考指标体系;
二、DWS层设计分析 - 1d/nd
1.DWS层设计一:不考虑用户维度
- 1.首先需要对ADS层业务需求进行明确,需求如下:
- 1.各品牌商品交易统计
- 2.各品类商品交易统计
| 统计周期 | 统计粒度 | 指标 |
|---|---|---|
| 最近1、7、30日 | 品牌 | 订单数 |
| 最近1、7、30日 | 品牌 | 订单人数 |
| 最近1、7、30日 | 品牌 | 退单数 |
| 最近1、7、30日 | 品牌 | 退单人数 |
| 统计周期 | 统计粒度 | 指标 |
|---|---|---|
| 最近1、7、30日 | 品类 | 订单数 |
| 最近1、7、30日 | 品类 | 订单人数 |
| 最近1、7、30日 | 品类 | 退单数 |
| 最近1、7、30日 | 品类 | 退单人数 |
-
2.构建指标体系,对于需求进行指标分析,分析出每个需求对应什么类型指标
-
各品牌的指标体系分析
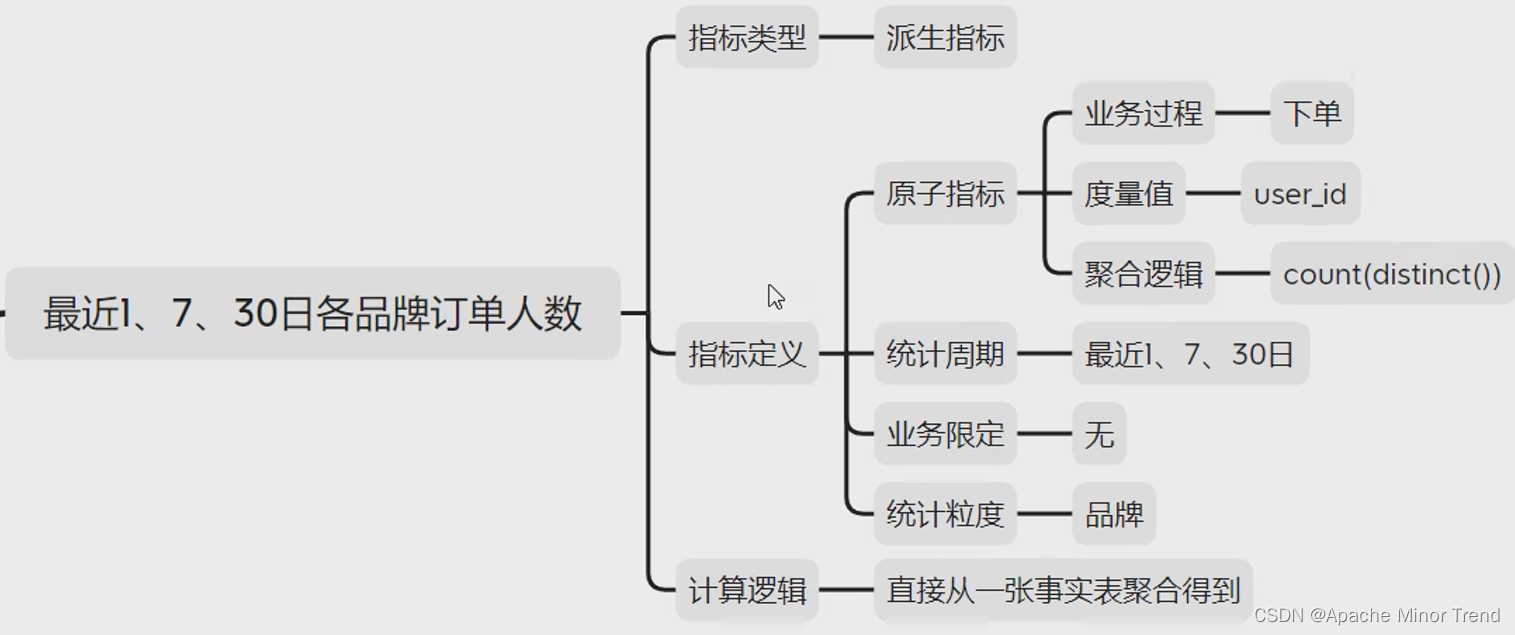
-
各品类的指标体系分析
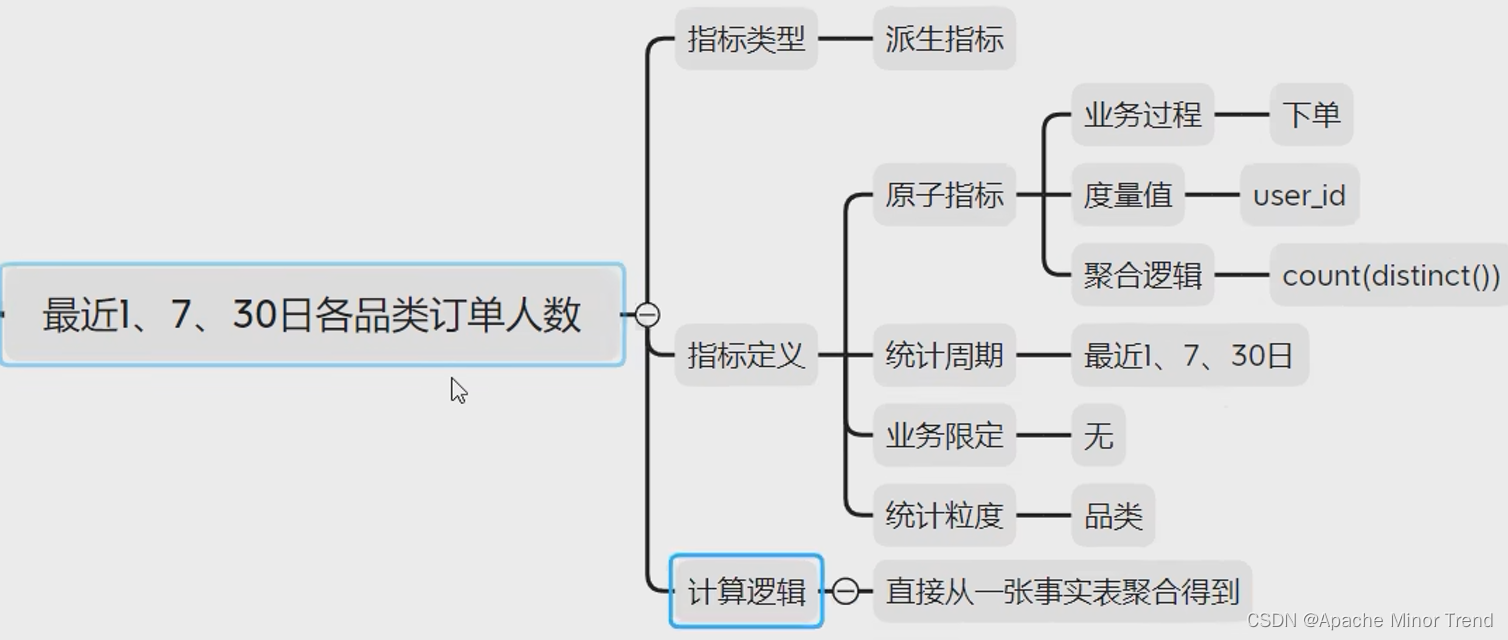
-
-
3.抽取派生指标,将刚刚思维导图中汇总的指标体系,梳理到表格中,抽取共用的派生指标
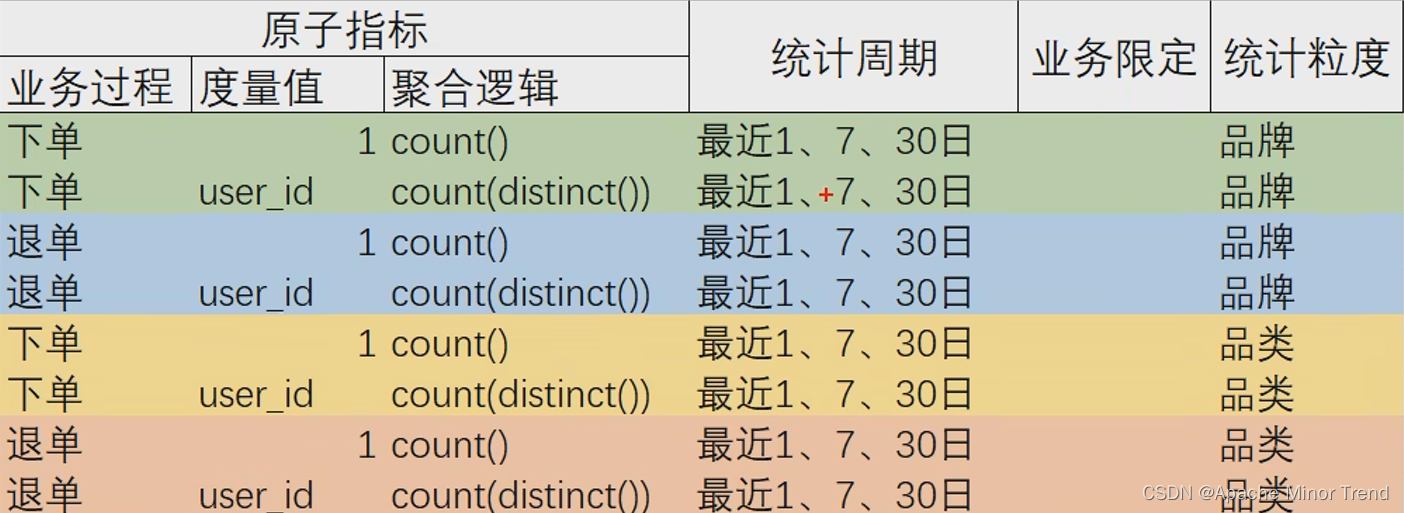
-
4.设计DWS层汇总表,根据刚刚梳理的指标体系表格,梳理出DWS层需要创建哪些表格。
DWS层表名的命名规范为:dws_数据域_统计粒度_业务过程_统计周期(1d/nd/td)- 针对表格第一行和第二行,设计表格名:dwd_trade_tm_order_1d
- 行信息规划:每行代表此品牌最近1天下单总数量
- 列字段规划:品牌id,聚合后的值(下单次数),聚合后的值(下单人数),品牌的名称(可以加,可以不加,直接关联维度表即可)
- 分区规划:每天计算,最近一日的汇总结果。按天创建分区,每天分区里面存放当天的汇总结果
-
5.创建dwd_trade_tm_order_1d表格的DDL语句
- 数仓表格设计的时候,尽量避免后期改表操作,怎么避免?
-
- 在DWS添加指标信息的时候,尽量考虑全面,参考维度是:DWD层的相关的表格的度量值。
-
- 最近1天指标DDL语句如下:
- 数仓表格设计的时候,尽量避免后期改表操作,怎么避免?
create external table dws_trade_tm_order_1d
(tm_id string comment '品牌id',tm_name string comment '品牌名称',order_count bigint comment '最近1日下单次数',order_user_count bigint comment '最近1日下单人数',order_num bigint comment '最近1日下单件数',order_total_amount decimal(16,2) comment '最近1日下单金额'
) comment '交易域品牌粒度订单最近1日汇总事实表'partition by (dt string)stored as orclocation '/warehouse/gmall/dws/dws_trade_tm_order_1d'tblproperties('orc.compress'='snappy')
- 6.对于dwd_trade_tm_order_1d表格进行数据装载
- 装载数据SQL如下:
insert overwrite table dws_trade_tm_order_1d partition(dt='2020-06-14'
SELECTtm_id,tm_name,COUNT(1),count(DISTINCT (user_id)),sum(sku_num),sum(split_total_amount)
from(SELECTsku_id, user_id, sku_num, split_total_amountfromdwd_trade_order_detail_incwheredt = '2020-06-14' )od
left JOIN (selectid, tm_id, tm_nameFROMdim_sku_fullwheredt = '2020-06-14' )sku onod.sku_id = sku.id
GROUP bytm_id,tm_name;- 7.nd表的创建表格DDL语句:
create external table dws_trade_tm_order_nd
(
tm_id string comment '品牌id',
tm_name string comment '品牌名称',
order_count_7d bigint comment '最近7日下单次数',
order_user_count_7d bigint comment '最近7日下单人数',
order_num_7d bigint comment '最近7日下单件数',
order_total_amount_7d decimal(16,2) comment '最近7日下单金额',
order_count_30d bigint comment '最近30日下单次数',
order_user_count_30d bigint comment '最近30日下单人数',
order_num_30d bigint comment '最近30日下单件数',
order_total_amount_30d decimal(16,2) comment '最近30日下单金额'
) comment '交易域品牌粒度订单最近7日和30日汇总事实表'partition by (dt string)stored as orclocation '/warehouse/gmall/dws/dws_trade_tm_order_nd'tblproperties('orc.compress'='snappy')
- 8.nd表的数据装载
- 存在1d表的数据,优先从1d表中获取,否则直接从dwd层事实表中获取。
insert overwrite table dws_trade_tm_order_nd partition(dt='2020-06-14')
select tm_id,tm_name,sum(if(dt>=date_sub('2020-06-14',6),order_count,0)), //计算最近7天的数据sum(if(dt>=date_sub('2020-06-14',6),order_user_count,0)),sum(if(dt>=date_sub('2020-06-14',6),order_num,0)),sum(if(dt>=date_sub('2020-06-14',6),order_total_amount,0)),sum(order_count),sum(order_user_count),sum(order_num),sum(order_total_amount),
from dws_trade_tm_order_1d
where dt >= date_sub('2020-06-14',29)
group by tm_id,tm_name;
- 9.nd表的装载语句存在重复计算的问题,一个下单用户 可能在30个分区都有,但是仅仅是一个下单用户,但在计算的时候,每个分区都有此下单用户,没有进行去重操作,那么相加完毕后,全部一个用户就变成了30个用户了,数据不准确了。
- 怎样解决?
- 1.从dwd层获取原始数据,最近7天,最近30天,dws层直接去重汇总即可。
- 2.降低1d表的维度,之前表格不体现用户维度,现在表格体现用户维度,要重新修改1d表格。
- 怎样解决?
2.DWS层设计二:考虑用户维度
- 1.重新创建1d表 DDL如下:
create external table dws_trade_user_tm_order_1d
(user_id string comment '用户id',tm_id string comment '品牌id',tm_name string comment '品牌名称',order_count bigint comment '最近1日下单次数',order_num bigint comment '最近1日下单件数',order_total_amount decimal(16,2) comment '最近1日下单金额'
) comment '交易域用户品牌粒度订单最近1日汇总事实表'partition by (dt string)stored as orclocation '/warehouse/gmall/dws/dws_trade_tm_order_1d'tblproperties('orc.compress'='snappy')
- 2.1d表数据装载语句
insert overwrite table dws_trade_user_tm_order_1d partition(dt='2020-06-14'
SELECTuser_id,tm_id,tm_name,COUNT(1),sum(sku_num),sum(split_total_amount)
from(SELECTsku_id, user_id, sku_num, split_total_amountfromdwd_trade_order_detail_incwheredt = '2020-06-14' )od
left JOIN (selectid, tm_id, tm_nameFROMdim_sku_fullwheredt = '2020-06-14' )sku onod.sku_id = sku.id
GROUP byuser_id,tm_id,tm_name;
- 3.nd表的创建表格DDL语句:
create external table dws_trade_user_tm_order_nd
(
user_id string comment '用户id',
tm_id string comment '品牌id',
tm_name string comment '品牌名称',
order_count_7d bigint comment '最近7日下单次数',
order_num_7d bigint comment '最近7日下单件数',
order_total_amount_7d decimal(16,2) comment '最近7日下单金额',
order_count_30d bigint comment '最近30日下单次数',
order_num_30d bigint comment '最近30日下单件数',
order_total_amount_30d decimal(16,2) comment '最近30日下单金额'
) comment '交易域用户品牌粒度订单最近7日和30日汇总事实表'partition by (dt string)stored as orclocation '/warehouse/gmall/dws/dws_trade_tm_order_nd'tblproperties('orc.compress'='snappy')
-
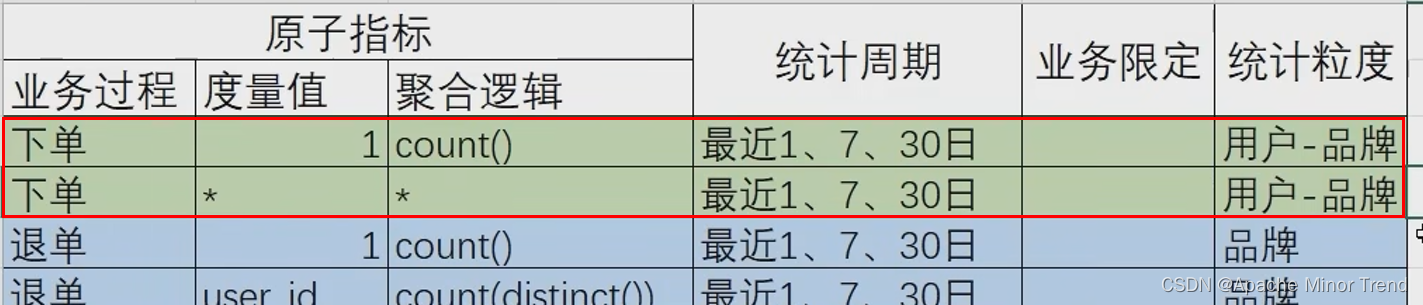
4.指标体系调整:其他指标也需要跟着调整
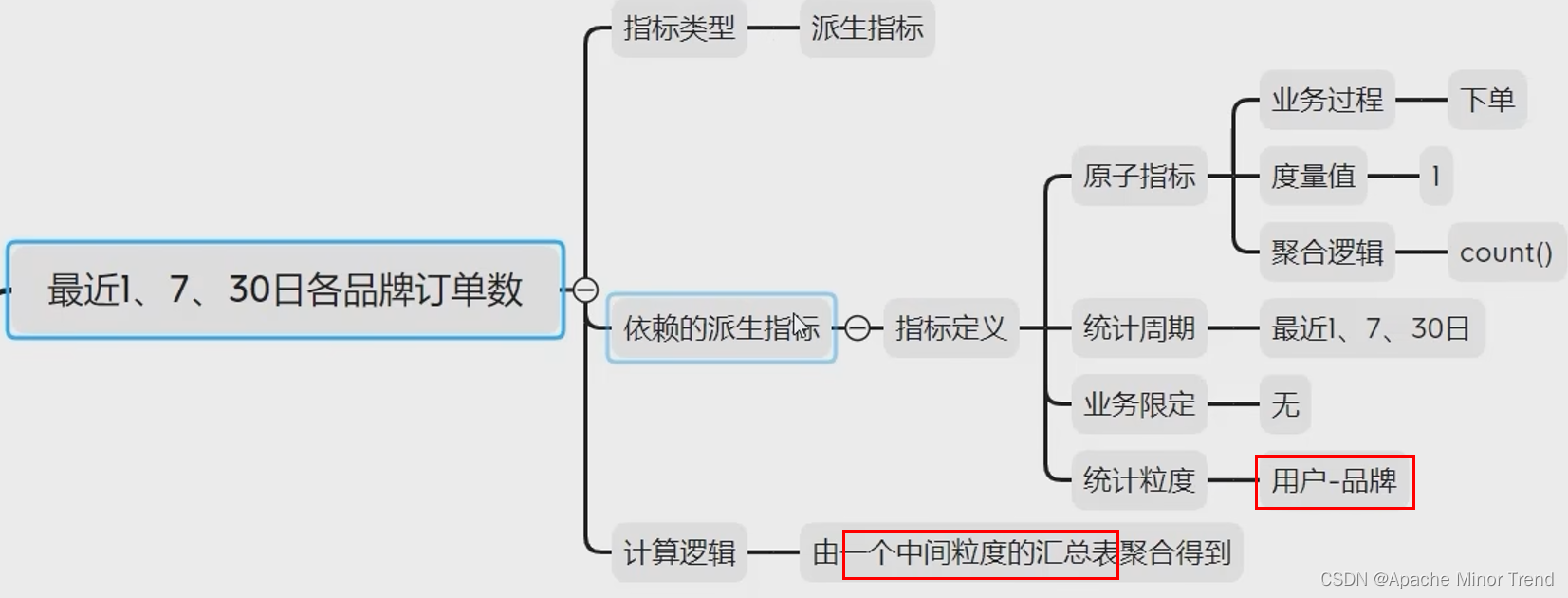
-
5.对应需求矩阵
-
6.nd表的数据装载
- 存在1d表的数据,优先从1d表中获取,否则直接从dwd层事实表中获取。
insert overwrite table dws_trade_user_tm_order_nd partition(dt='2020-06-14')
select user_id ,tm_id,tm_name,sum(if(dt>=date_sub('2020-06-14',6),order_count,0)), //计算最近7天的数据sum(if(dt>=date_sub('2020-06-14',6),order_num,0)),sum(if(dt>=date_sub('2020-06-14',6),order_total_amount,0)),sum(order_count),sum(order_num),sum(order_total_amount),
from dws_trade_tm_order_1d
where dt >= date_sub('2020-06-14',29)
group by user_id ,tm_id,tm_name;
2.DWS层设计三 :考虑用户+商品维度,形成DWS层汇总表
- 直接考虑用户+商品维度,创建的表格,就不需要去考虑建表的时候的品牌维度和品类维度了。
- 只创建一张用户+商品维度的DWS层表格,就可以直接提供给 品牌类需求使用,也可以提供给 品类需求使用,这样比较一下,上面几个设计在处理表的时候,较本设计模式增加了不少工作量;
- 本设计模式,可以只提供一张表,然后供给品牌和品类需求使用。
- 创建的DWS层表格粒度越小,将来服务的表格会越多。
最终建表方案:
- 1.1d建表语句:用户+商品维度建表DDL语句:
DROP TABLE IF EXISTS dws_trade_user_sku_order_1d;
CREATE EXTERNAL TABLE dws_trade_user_sku_order_1d
(`user_id` STRING COMMENT '用户id',`sku_id` STRING COMMENT 'sku_id',`sku_name` STRING COMMENT 'sku名称',`category1_id` STRING COMMENT '一级分类id',`category1_name` STRING COMMENT '一级分类名称',`category2_id` STRING COMMENT '一级分类id',`category2_name` STRING COMMENT '一级分类名称',`category3_id` STRING COMMENT '一级分类id',`category3_name` STRING COMMENT '一级分类名称',`tm_id` STRING COMMENT '品牌id',`tm_name` STRING COMMENT '品牌名称',`order_count_1d` BIGINT COMMENT '最近1日下单次数',`order_num_1d` BIGINT COMMENT '最近1日下单件数',`order_original_amount_1d` DECIMAL(16, 2) COMMENT '最近1日下单原始金额',`activity_reduce_amount_1d` DECIMAL(16, 2) COMMENT '最近1日活动优惠金额',`coupon_reduce_amount_1d` DECIMAL(16, 2) COMMENT '最近1日优惠券优惠金额',`order_total_amount_1d` DECIMAL(16, 2) COMMENT '最近1日下单最终金额'
) COMMENT '交易域用户商品粒度订单最近1日汇总事实表'PARTITIONED BY (`dt` STRING)STORED AS ORCLOCATION '/warehouse/gmall/dws/dws_trade_user_sku_order_1d'TBLPROPERTIES ('orc.compress' = 'snappy');
- 2.nd建表语句:DDL语句
DROP TABLE IF EXISTS dws_trade_user_sku_order_nd;
CREATE EXTERNAL TABLE dws_trade_user_sku_order_nd
(`user_id` STRING COMMENT '用户id',`sku_id` STRING COMMENT 'sku_id',`sku_name` STRING COMMENT 'sku名称',`category1_id` STRING COMMENT '一级分类id',`category1_name` STRING COMMENT '一级分类名称',`category2_id` STRING COMMENT '一级分类id',`category2_name` STRING COMMENT '一级分类名称',`category3_id` STRING COMMENT '一级分类id',`category3_name` STRING COMMENT '一级分类名称',`tm_id` STRING COMMENT '品牌id',`tm_name` STRING COMMENT '品牌名称',`order_count_7d` STRING COMMENT '最近7日下单次数',`order_num_7d` BIGINT COMMENT '最近7日下单件数',`order_original_amount_7d` DECIMAL(16, 2) COMMENT '最近7日下单原始金额',`activity_reduce_amount_7d` DECIMAL(16, 2) COMMENT '最近7日活动优惠金额',`coupon_reduce_amount_7d` DECIMAL(16, 2) COMMENT '最近7日优惠券优惠金额',`order_total_amount_7d` DECIMAL(16, 2) COMMENT '最近7日下单最终金额',`order_count_30d` BIGINT COMMENT '最近30日下单次数',`order_num_30d` BIGINT COMMENT '最近30日下单件数',`order_original_amount_30d` DECIMAL(16, 2) COMMENT '最近30日下单原始金额',`activity_reduce_amount_30d` DECIMAL(16, 2) COMMENT '最近30日活动优惠金额',`coupon_reduce_amount_30d` DECIMAL(16, 2) COMMENT '最近30日优惠券优惠金额',`order_total_amount_30d` DECIMAL(16, 2) COMMENT '最近30日下单最终金额'
) COMMENT '交易域用户商品粒度订单最近n日汇总事实表'PARTITIONED BY (`dt` STRING)STORED AS ORCLOCATION '/warehouse/gmall/dws/dws_trade_user_sku_order_nd'TBLPROPERTIES ('orc.compress' = 'snappy');
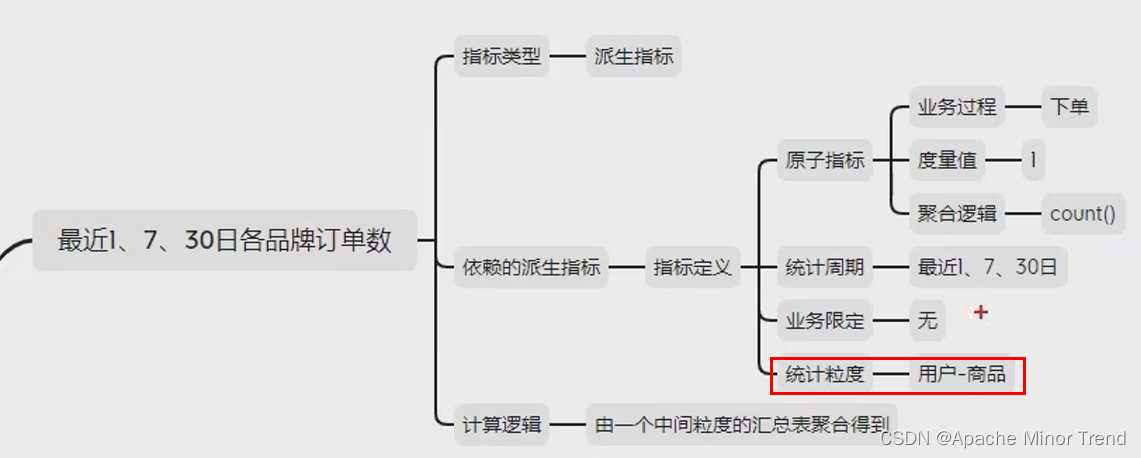
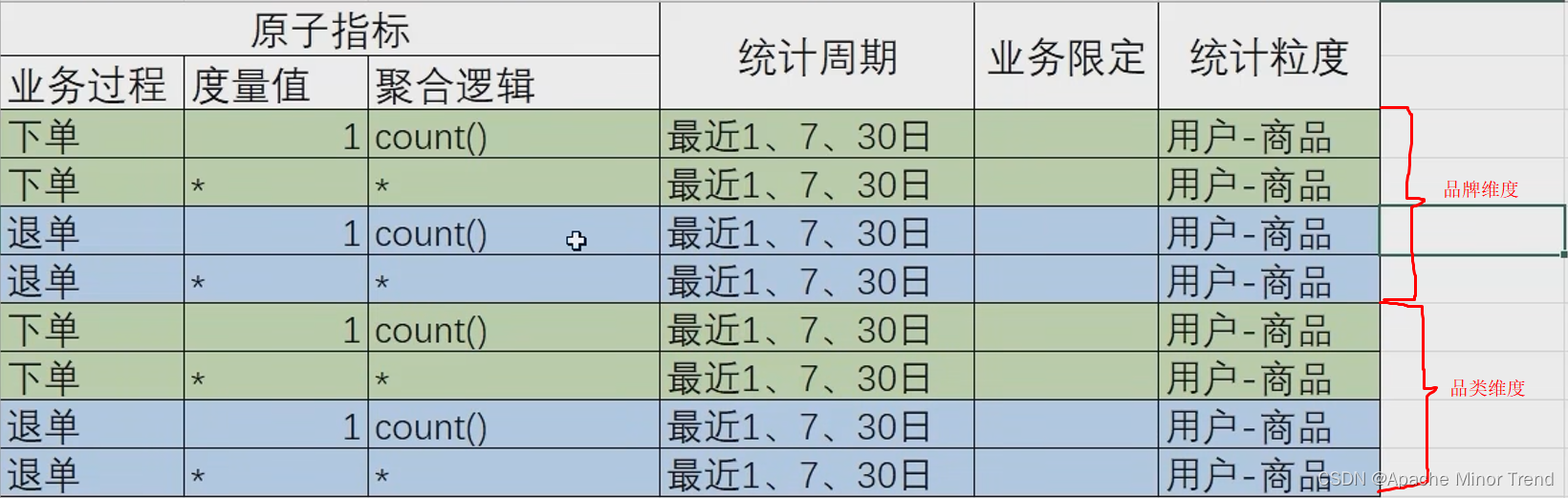
- 3.指标体系和需求矩阵调整后结果
三、DWS层设计分析 - td 历史至今
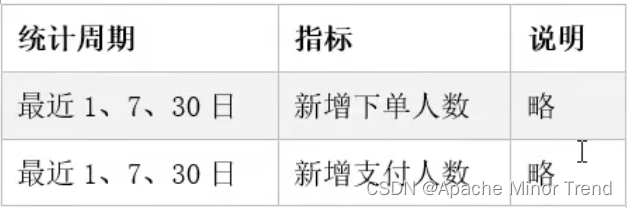
1.以新增下单人数的需求为例
- 需求如下:
- 如果根据需求指标来直接处理的话,可能计算量以及sql复杂程度很高,可以换一种思路来解决此类需求;
- 维护一张表格,首次该用户下单的信息维护到这张表格里面,怎样整合这张表,需要根据dwd层全表数据进行汇总,然后将全量数据,根据需求进行逻辑计算,将所需数据维护到dws层的汇总表中,历史全量数据在首次导入的时候,进行sql处理后录入,每日新增数据只需要判断此表格有没有该用户记录即可,没有该用户直接插入表格。
- 创建表格:表格命名:dws_trade_user_order_td
- 每行代表信息:某用户首次下单信息,以及用户维度其他信息
- 每列信息:与用户相关的维度信息都可以汇总到此表格中
- 分区:按天创建分区,每天存放的数据都是历史至今的最新数据。
- 具体表格创建语句如下:
DROP TABLE IF EXISTS dws_trade_user_order_td;
CREATE EXTERNAL TABLE dws_trade_user_order_td
(`user_id` STRING COMMENT '用户id',`order_date_first` STRING COMMENT '首次下单日期',`order_date_last` STRING COMMENT '末次下单日期',`order_count_td` BIGINT COMMENT '下单次数',`order_num_td` BIGINT COMMENT '购买商品件数',`original_amount_td` DECIMAL(16, 2) COMMENT '原始金额',`activity_reduce_amount_td` DECIMAL(16, 2) COMMENT '活动优惠金额',`coupon_reduce_amount_td` DECIMAL(16, 2) COMMENT '优惠券优惠金额',`total_amount_td` DECIMAL(16, 2) COMMENT '最终金额'
) COMMENT '交易域用户粒度订单历史至今汇总事实表'PARTITIONED BY (`dt` STRING)STORED AS ORCLOCATION '/warehouse/gmall/dws/dws_trade_user_order_td'TBLPROPERTIES ('orc.compress' = 'snappy');
- 装载数据:
- 如果每次都求dwd层表格中全量数据的话, 太损耗计算资源,可以基于前一日计算结果进行计算。这样比较高效解决数据问题。
- 首日全量装载sql:
insert overwrite table dws_trade_user_order_td partition(dt='2020-06-14')
selectuser_id,min(dt) login_date_first,max(dt) login_date_last,sum(order_count_1d) order_count,sum(order_num_1d) order_num,sum(order_original_amount_1d) original_amount,sum(activity_reduce_amount_1d) activity_reduce_amount,sum(coupon_reduce_amount_1d) coupon_reduce_amount,sum(order_total_amount_1d) total_amount
from dws_trade_user_order_1d
group by user_id;
- 每日增量装载sql:
- 方案一:之间使用full outer join ,然后获取的数据进行判断即可
insert overwrite table dws_trade_user_order_td partition(dt='2020-06-15')
selectnvl(old.user_id,new.user_id),if(new.user_id is not null and old.user_id is null,'2020-06-15',old.order_date_first),if(new.user_id is not null,'2020-06-15',old.order_date_last),nvl(old.order_count_td,0)+nvl(new.order_count_1d,0),nvl(old.order_num_td,0)+nvl(new.order_num_1d,0),nvl(old.original_amount_td,0)+nvl(new.order_original_amount_1d,0),nvl(old.activity_reduce_amount_td,0)+nvl(new.activity_reduce_amount_1d,0),nvl(old.coupon_reduce_amount_td,0)+nvl(new.coupon_reduce_amount_1d,0),nvl(old.total_amount_td,0)+nvl(new.order_total_amount_1d,0)
from
(selectuser_id,order_date_first,order_date_last,order_count_td,order_num_td,original_amount_td,activity_reduce_amount_td,coupon_reduce_amount_td,total_amount_tdfrom dws_trade_user_order_tdwhere dt=date_add('2020-06-15',-1)
)old
full outer join
(selectuser_id,order_count_1d,order_num_1d,order_original_amount_1d,activity_reduce_amount_1d,coupon_reduce_amount_1d,order_total_amount_1dfrom dws_trade_user_order_1dwhere dt='2020-06-15'
)new
on old.user_id=new.user_id;
- 方案二:两部分子查询之间使用union all进行关联
SELECTuser_id,min(order_date_first) ,max(order_date_last),sum(order_count_td),sum(order_num_td),sum(original_amount_td),sum(activity_reduce_amount_td),sum(coupon_reduce_amount_td),sum(total_amount_td)
from(selectuser_id, order_date_first, order_date_last, order_count_td, order_num_td, original_amount_td, activity_reduce_amount_td, coupon_reduce_amount_td, total_amount_tdfromdws_trade_user_order_tdwheredt = date_add('2020-06-15',-1)
UNION ALLselectuser_id, '2020-06-15', '2020-06-15', order_count_1d, order_num_1d, order_original_amount_1d, activity_reduce_amount_1d, coupon_reduce_amount_1d, order_total_amount_1dfromdws_trade_user_order_1dwheredt = '2020-06-15'GROUP byuser_id ) t1
group byuser_id ;
-
hive 中sql语法:
- nvl(字段1,字段2) :取两个字段中不为空的那个字段,如果都不为空,取前一个,两个都为空,就不取。
-
开窗和分组
- 开窗:在原有表格列的基础上,添加一列开窗列,可以基于此列进行分析数据
- 分组:改变原有表格的粒度, 结果的粒度跟原来表格的粒度不一样了。
三、DWS层设计分析 - 总结
- dws层设计要点:1d表表结构设计,nd表表结构设计,td表表结构设计,以及对应的数据装载。
- 1d表表结构:
- 行设计:派生指标的粒度决定的
- 列设计:粒度的id,派生指标决定,设计时需要有一定的前瞻性,参考与之对应的dwd层的事实表的度量值
- 分区设计: 按天分区,每天分区放的是当天明细的汇总结果,跟明细表分区对应
- 数据装载:dwd层与之对应的明细表,从明细表中获取一个分区的数据,之后进行汇总,汇总完成后放到汇总表一天的分区里面。
- nd表表结构:
- 行设计:派生指标的粒度决定的
- 列设计:跟1d表相比,多n维度字段,7d的指标,30d的指标
- 分区设计:按天分区,截止当天的,最近N天的汇总数据
- 数据装载:优先从1d表里面取数,如果没有1d表,那就去dwd层明细表取数。
- 直接拿30天的求和,然后在sql里面加个判断,获取最近7天的数据,这样就可以通过一个sql实现不同周期的计算。
- td表表结构:
- 行设计:派生指标的粒度决定的
- 列设计:派生指标决定
- 分区设计:按天分区,每个分区里面存放历史截止当天的汇总数据。
- 数据装载:
- 首日: 从dws层的1d或者dwd层明细表获取全表数据,优先1d表。
- 每日:首先拿前一天的分区结果,然后拿1d表或者明细表里今天的结果,做加法运算,join或者union。
- 1d表表结构:
相关文章:
【离线数仓-9-数据仓库开发DWS层设计要点-1d/nd/td表设计】
离线数仓-9-数据仓库开发DWS层设计要点-1d/nd/td表设计离线数仓-9-数据仓库开发DWS层设计要点-1d/nd/td表设计一、DWS层设计要点二、DWS层设计分析 - 1d/nd1.DWS层设计一:不考虑用户维度2.DWS层设计二:考虑用户维度2.DWS层设计三 :考虑用户商…...

python网络数据获取
文章目录1网络爬虫2网络爬虫的类型2.1通用网络爬虫2.1.12.1.22.2聚焦网络爬虫2.2.1 基于内容评价的爬行策略2.2.2 基于链接结构的爬行策略2.2.3基于增强学习的爬行策略2.2.4基于语境图的爬行策略2.3增量式网络爬虫深层网页爬虫3网络爬虫基本架构3.1URL管理模块3.2网页下载模块3…...
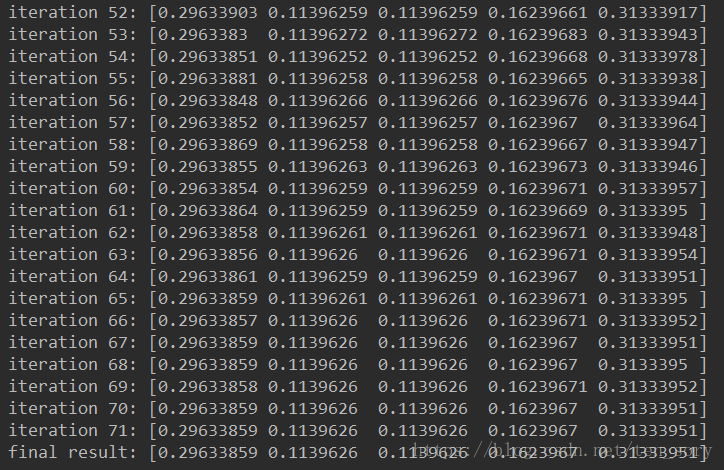
[Datawhale][CS224W]图机器学习(六)
目录一、简介二、概述三、算法四、PageRank的缺点五、Python实现迭代法参考文献一、简介 PageRank,又称网页排名、谷歌左侧排名、PR,是Google公司所使用的对其搜索引擎搜索结果中的网页进行排名的一种算法。 佩奇排名本质上是一种以网页之间的超链接个…...

aws ecr 使用golang实现的简单镜像转换工具
https://pkg.go.dev/github.com/docker/docker/client#section-readme 通过golang实现一个简单的镜像下载工具 总体步骤 启动一台海外区域的ec2实例安装docker和awscli配置凭证访问国内ecr仓库编写web服务实现镜像转换和自动推送 安装docker和awscli sudo yum remove awsc…...

【20230225】【剑指1】分治算法(中等)
1.重建二叉树class Solution { public:TreeNode* traversal(vector<int>& preorder,vector<int>& inorder){if(preorder.size()0) return NULL;int rootValuepreorder.front();TreeNode* rootnew TreeNode(rootValue);//int rootValuepreorder[0];if(preo…...
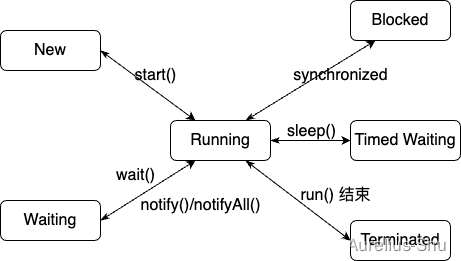
「JVM 高效并发」Java 线程
进程是资源分配(内存地址、文件 I/O 等)的基本单位,线程是执行调度(处理器资源调度)的基本单位; Loom 项目若成功为 Java 引入纤程(Fiber),则线程的执行调度单位可能变为…...

ADAS-可见光相机之Cmos Image Sensor
引言 “ 可见光相机在日常生活、工业生产、智能制造等应用有着重要的作用。在ADAS中更是扮演着重要的角色,如tesla model系列全车身10多个相机,不断感知周围世界。本文着重讲解下可见光相机中的CIS(CMOS Image Sensor)。” 定义 光是一种电磁波&…...

【ESP 保姆级教程】玩转emqx MQTT篇③ ——封装 EmqxIoTSDK,快速在项目集成
忘记过去,超越自己 ❤️ 博客主页 单片机菜鸟哥,一个野生非专业硬件IOT爱好者 ❤️❤️ 本篇创建记录 2023-02-26 ❤️❤️ 本篇更新记录 2023-02-26 ❤️🎉 欢迎关注 🔎点赞 👍收藏 ⭐️留言📝🙏 此博客均由博主单独编写,不存在任何商业团队运营,如发现错误,请…...

Python自动化测试面试题-编程篇
前言 随着行业的发展,编程能力逐渐成为软件测试从业人员的一项基本能力。因此在笔试和面试中常常会有一定量的编码题,主要考察以下几点。 基本编码能力及思维逻辑基本数据结构(顺序表、链表、队列、栈、二叉树)基本算法…...

CIT 594 Module 7 Programming AssignmentCSV Slicer
CIT 594 Module 7 Programming Assignment CSV Slicer In this assignment you will read files in a format known as “comma separated values” (CSV), interpret the formatting and output the content in the structure represented by the file. Q1703105484 Learning …...
链路追踪——【Brave】第一遍小结
前言 微服务链路追踪系列博客,后续可能会涉及到Brave、Zipkin、Sleuth内容的梳理。 Brave 何为Brave? github地址:https://github.com/openzipkin/brave Brave是一个分布式追踪埋点库。 #mermaid-svg-riwF9nbu1AldDJ7P {font-family:"…...
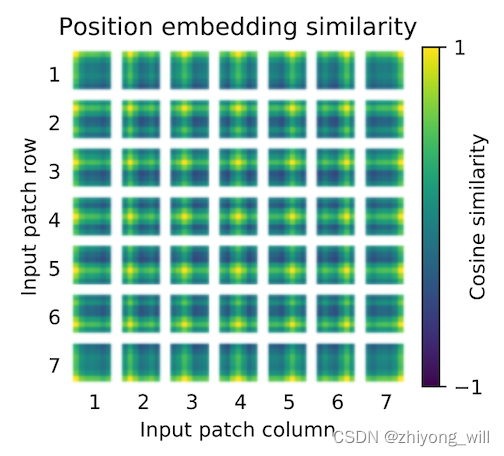
Vision Transformer(ViT)
1. 概述 Transformer[1]是Google在2017年提出的一种Seq2Seq结构的语言模型,在Transformer中首次使用Self-Atttention机制完全代替了基于RNN的模型结构,使得模型可以并行化训练,同时解决了在基于RNN模型中出现了长距离依赖问题,因…...

104-JVM优化
JVM优化为什么要学习JVM优化: 1:深入地理解 Java 这门语言 我们常用的布尔型 Boolean,我们都知道它有两个值,true 和 false,但你们知道其实在运行时,Java 虚拟机是 没有布尔型 Boolean 这种类型的&#x…...

QML 颜色表示法
作者: 一去、二三里 个人微信号: iwaleon 微信公众号: 高效程序员 如果你经常需要美化样式(最常见的有:文本色、背景色、边框色、阴影色等),那一定离不开颜色。而在 QML 中,颜色的表示方法有多种:颜色名、十六进制颜色值、颜色相关的函数,一起来学习一下吧。 老规矩…...
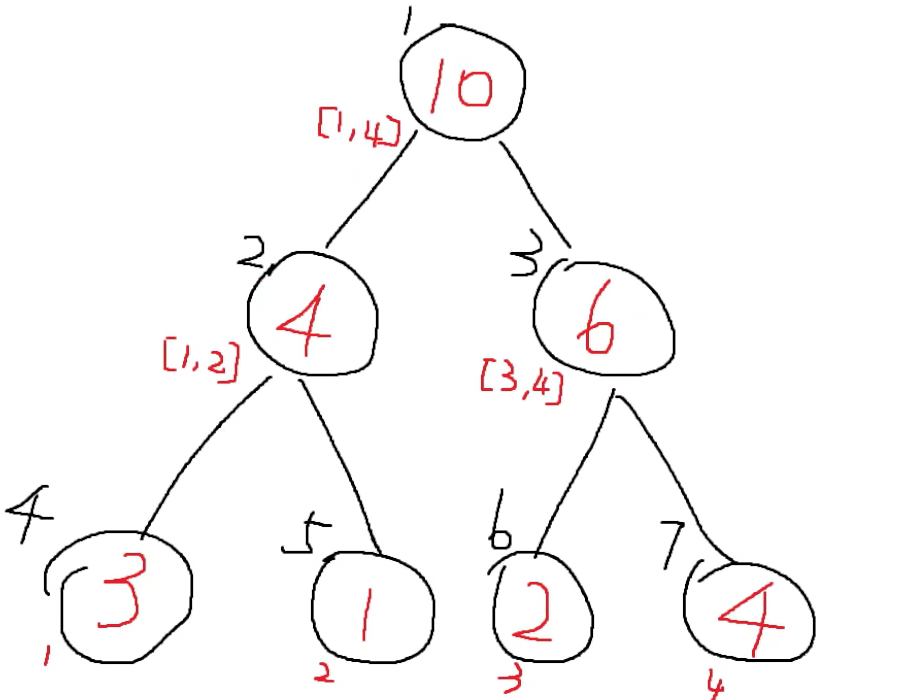
基础数据结构--线段树(Python版本)
文章目录前言特点操作数据存储updateLazy下移查询实现前言 月末了,划个水,赶一下指标(更新一些活跃值,狗头) 本文主要是关于线段树的内容。这个线段树的话,主要是适合求解我们一个数组的一些区间的问题&am…...

【micropython】SPI触摸屏开发
背景:最近买了几块ESP32模块,看了下mircopython支持还不错,所以买了个SPI触摸屏试试水,记录一下使用过程。硬件相关:SPI触摸屏使用2.4寸屏幕,常见淘宝均可买到,驱动为ILI9341,具体参…...
【云原生】k8s中Pod进阶资源限制与探针
一、Pod 进阶 1、资源限制 当定义 Pod 时可以选择性地为每个容器设定所需要的资源数量。 最常见的可设定资源是 CPU 和内存大小,以及其他类型的资源。 当为 Pod 中的容器指定了 request 资源时,调度器就使用该信息来决定将 Pod 调度到哪个节点上。当还…...
AI - stable-diffusion(AI绘画)的搭建与使用
最近 AI 火的一塌糊涂,除了 ChatGPT 以外,AI 绘画领域也有很大的进步,以下几张图片都是 AI 绘制的,你能看出来么? 一、环境搭建 上面的效果图其实是使用了开源的 AI 绘画项目 stable-diffusion 绘制的,这是…...
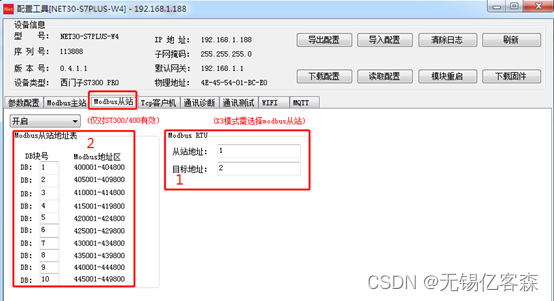
应用场景五: 西门子PLC通过Modbus协议连接DCS系统
应用描述: 西门子PLC(S7200/300/400/200SMART)通过桥接器可以支持ModbusRTU串口和ModbusTCP以太网(有线和无线WIFI同时支持)两种通讯方式连接DCS系统,不需要编程PLC通讯程序,直接在模块中进行地…...

我继续问了ChatGPT关于SAP顾问职业发展前景的问题,大家感受一下
目录 SAP 顾问 跟其他IT工作收入情况相比是怎么样的? 如何成为SAP FICO 优秀的顾问 要想成为SAP FICO 优秀的顾问 ,需要ABA开发技能吗 SAP 顾问中哪个类型收入最多? 中国的ERP软件能够取代SAP吗? 今天我继续撩 ChatGPT。随便问…...

避坑指南:Unity游戏在Linux上运行报错?OpenCV依赖和文件权限问题排查实录
Unity游戏Linux部署避坑指南:从权限修复到OpenCV依赖全解析 当你在Ubuntu上双击那个刚导出的Unity游戏.x86_64文件时,屏幕却弹出一行冰冷的错误信息——这种从云端跌入谷底的体验,每个跨平台开发者都经历过。不同于Windows的一键运行…...

从零到一:基于GD32E230核心板的PCB设计实战与模块化解析
1. GD32E230核心板硬件设计基础 第一次拿到GD32E230这颗国产MCU时,说实话有点小激动。作为兆易创新基于Cortex-M23内核的拳头产品,它用55nm工艺把芯片面积压缩到了惊人的3x3mm,却集成了5个定时器、2个SPI、2个I2C这些实用外设。我在去年一个智…...

Go语言AI编程助手SDK:提升Cursor代码理解与生成精准度
1. 项目概述:一个为AI编程而生的Go语言SDK如果你是一名Go语言开发者,同时又在深度使用Cursor这样的AI辅助编程工具,那么你很可能已经感受到了一个痛点:如何让AI更精准、更高效地理解你的代码库,并在此基础上进行智能操…...

5分钟免费获取:开源鼠标连点器MouseClick完整使用指南
5分钟免费获取:开源鼠标连点器MouseClick完整使用指南 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,…...

Arm CoreLink PCK-600电源管理架构与寄存器编程详解
1. Arm CoreLink PCK-600电源控制架构解析在嵌入式系统设计中,电源管理单元(PMU)是实现高效能耗控制的核心组件。Arm CoreLink PCK-600作为业界领先的电源控制解决方案,其架构设计体现了现代SoC电源管理的先进理念。PCK-600系列采…...
)
乌尔都语语音合成落地难?揭秘ElevenLabs未公开的ur-PK语言代码陷阱与ISO 639-3双标适配规范(仅限首批127家认证开发者知晓)
更多请点击: https://intelliparadigm.com 第一章:乌尔都语语音合成落地难?揭秘ElevenLabs未公开的ur-PK语言代码陷阱与ISO 639-3双标适配规范(仅限首批127家认证开发者知晓) ElevenLabs 官方文档中仅标注 ur 为乌尔…...

轻量级服务器监控面板:从原理到部署实战
1. 项目概述:一个开源监控面板的诞生最近在折腾服务器和容器化应用,发现一个挺普遍的需求:当你手头有几台服务器,上面跑着几个Docker容器,或者一些自己写的服务,你总想知道它们现在“活”得怎么样。CPU是不…...

基于语义搜索的AI代码理解工具copaw-code深度解析
1. 项目概述:一个面向代码搜索与理解的AI工具 最近在GitHub上看到一个挺有意思的项目,叫 QSEEKING/copaw-code 。乍一看这个标题,可能会有点摸不着头脑,“copaw”是什么?但结合“code”和项目托管在QSEEKING这个组织…...

药物发现自动化:FEP计算工作流引擎faah的设计原理与实战
1. 项目概述:一个面向药物发现的自动化工作流引擎 最近在药物研发的自动化工具领域,一个名为 kiron0/faah 的项目引起了我的注意。这并非一个简单的脚本集合,而是一个设计精巧、旨在为药物发现中的自由能微扰计算提供端到端自动化解决方案的…...

Apache Burr框架:构建可观测有状态数据应用的核心原理与实践
1. 项目概述:一个用于构建和评估数据产品的Python框架如果你正在处理数据密集型应用,比如推荐系统、个性化广告或者任何需要根据用户行为实时调整策略的场景,你肯定遇到过这样的困境:模型训练和离线评估做得再好,一旦上…...