diffusers-Load adapters
https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters![]() https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters
https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters
有几种训练技术可以个性化扩散模型,生成特定主题的图像或某些风格的图像。每种训练方法都会产生不同类型的适配器。一些适配器会生成全新的模型,而其他适配器只修改较小的一组嵌入或权重。这意味着每个适配器的加载过程也是不同的。
1.Dreambooth
DreamBooth针对一个主题的几张图像微调整个扩散模型,以生成该主题的具有新风格和设置的图像。这种方法是通过在提示中使用一个特殊单词来触发模型学习与主题图像相关联。在所有的训练方法中,DreamBooth生成的文件大小最大(通常为几GB),因为它是一个完整的模型。
from diffusers import AutoPipelineForText2Image
import torchpipeline = AutoPipelineForText2Image.from_pretrained("sd-dreambooth-library/herge-style", torch_dtype=torch.float16).to("cuda")
prompt = "A cute herge_style brown bear eating a slice of pizza, stunning color scheme, masterpiece, illustration"
image = pipeline(prompt).images[0]2.Textual inversion
Textual inversion与DreamBooth非常相似,也可以个性化扩散模型,从仅有的几张图像中生成特定的概念(风格、物体)。这种方法通过训练和寻找新的嵌入来表示在提示中使用特殊单词提供的图像。因此,扩散模型的权重保持不变,而训练过程会生成一个相对较小(几KB)的文件。由于文本反演会创建嵌入,它不能像DreamBooth一样单独使用,需要另一个模型。
from diffusers import AutoPipelineForText2Image
import torchpipeline = AutoPipelineForText2Image.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16).to("cuda")pipeline.load_textual_inversion("sd-concepts-library/gta5-artwork")
prompt = "A cute brown bear eating a slice of pizza, stunning color scheme, masterpiece, illustration, <gta5-artwork> style"
image = pipeline(prompt).images[0]文本反演还可以训练不受欢迎的内容,以创建负向嵌入,防止模型生成具有这些不受欢迎的内容的图像,例如模糊的图像或手上额外的手指。这是一个快速改进提示的简单方法。您也可以使用load_textual_inversion()来加载嵌入,但这次需要两个参数:
weight_name:如果文件以特定名称保存在Diffusers格式中,或者文件存储在A1111格式中,则指定要加载的权重文件。 token:指定在提示中使用的特殊单词,以触发嵌入。
pipeline.load_textual_inversion("sayakpaul/EasyNegative-test", weight_name="EasyNegative.safetensors", token="EasyNegative"
)prompt = "A cute brown bear eating a slice of pizza, stunning color scheme, masterpiece, illustration, EasyNegative"
negative_prompt = "EasyNegative"image = pipeline(prompt, negative_prompt=negative_prompt, num_inference_steps=50).images[0]3.lora
LoRA是一种流行的训练技术,因为它速度快且生成较小的文件大小(几百MB),可以训练模型从仅有的几张图像中学习新的风格。它通过向扩散模型中插入新的权重,然后仅对新的权重进行训练,而不是整个模型。LoRA是一种非常通用的训练技术,可与其他训练方法一起使用。例如,通常使用DreamBooth和LoRA共同训练模型。
from diffusers import AutoPipelineForText2Image
import torchpipeline = AutoPipelineForText2Image.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16).to("cuda")pipeline.load_lora_weights("ostris/super-cereal-sdxl-lora", weight_name="cereal_box_sdxl_v1.safetensors")
prompt = "bears, pizza bites"
image = pipeline(prompt).images[0]load_lora_weights()方法会将LoRA的权重加载到UNet和文本编码器中。这是加载LoRA首选的方式,因为它可以处理以下情况:1.LoRA的权重没有分别给UNet和文本编码器的单独标识符;2.LoRA的权重有单独给UNet和文本编码器的标识符。但是,如果只需要将LoRA的权重加载到UNet中,那么可以使用load_attn_procs()方法。加载jbilcke-hf/sdxl-cinematic-1的LoRA权重:
from diffusers import AutoPipelineForText2Image
import torchpipeline = AutoPipelineForText2Image.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16).to("cuda")
pipeline.unet.load_attn_procs("jbilcke-hf/sdxl-cinematic-1", weight_name="pytorch_lora_weights.safetensors")# use cnmt in the prompt to trigger the LoRA
prompt = "A cute cnmt eating a slice of pizza, stunning color scheme, masterpiece, illustration"
image = pipeline(prompt).images[0]可以传递cross_attention_kwargs={"scale":0.5}来调节lora的权重。
4. load multiple lora
融合权重可以加快推理延迟,因为不需要单独加载基础模型和LoRA!可以使用save_pretrained()保存融合后的管道,以避免每次使用模型时都需要加载和融合权重。
from diffusers import StableDiffusionXLPipeline, AutoencoderKL
import torchvae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16)
pipeline = StableDiffusionXLPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0",vae=vae,torch_dtype=torch.float16,
).to("cuda")pipeline.load_lora_weights("ostris/ikea-instructions-lora-sdxl")
pipeline.fuse_lora(lora_scale=0.7)# to unfuse the LoRA weights
pipeline.unfuse_lora()pipeline.load_lora_weights("ostris/super-cereal-sdxl-lora")
pipeline.fuse_lora(lora_scale=0.7)prompt = "A cute brown bear eating a slice of pizza, stunning color scheme, masterpiece, illustration"
image = pipeline(prompt).images[0]5.PEFT
from diffusers import DiffusionPipeline
import torchpipeline = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16).to("cuda")
pipeline.load_lora_weights("ostris/ikea-instructions-lora-sdxl", weight_name="ikea_instructions_xl_v1_5.safetensors", adapter_name="ikea")
pipeline.load_lora_weights("ostris/super-cereal-sdxl-lora", weight_name="cereal_box_sdxl_v1.safetensors", adapter_name="cereal")pipeline.set_adapters(["ikea", "cereal"], adapter_weights=[0.7, 0.5])prompt = "A cute brown bear eating a slice of pizza, stunning color scheme, masterpiece, illustration"
image = pipeline(prompt, num_inference_steps=30, cross_attention_kwargs={"scale": 1.0}).images[0]kohya and TheLastBen
from diffusers import AutoPipelineForText2Image
import torchpipeline = AutoPipelineForText2Image.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0").to("cuda")
pipeline.load_lora_weights("path/to/weights", weight_name="blueprintify-sd-xl-10.safetensors")# use bl3uprint in the prompt to trigger the LoRA
prompt = "bl3uprint, a highly detailed blueprint of the eiffel tower, explaining how to build all parts, many txt, blueprint grid backdrop"
image = pipeline(prompt).images[0]无法加载LyCORIS
相关文章:
diffusers-Load adapters
https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adaptershttps://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters 有几种训练技术可以个性化扩散模型,生成特定主题的图像或某些风格的图像。每种训练方法都会产…...

CVI 串口调试助手
基于Labwindows CVI 2017编写的一个简单的串口调试助手,附带接收一个00–99的两位数并进行波形绘制的功能,编写过程可见:https://blog.csdn.net/Stark_/article/details/129003839 #include <ansi_c.h> #include <rs232.h> #incl…...

【蓝桥杯选拔赛真题48】python最小矩阵 青少年组蓝桥杯python 选拔赛STEMA比赛真题解析
目录 python最小矩阵 一、题目要求 1、编程实现 2、输入输出 二、算法分析...

如何在家庭网络中开启 IPv6内网穿透
随着互联网的不断发展,IPv4地址资源逐渐枯竭,而IPv6作为它的继任者,为网络连接提供了更多的IP地址。启用IPv6对于家庭网络来说变得越来越重要,因为它可以提供更稳定、更安全、更快速的互联网连接。本文将指导如何在家庭网络中启用…...

CodeWhisperer 的安装及体验
CodeWhisperer 是亚马逊出品的一款基于机器学习的通用代码生成器,可实时提供代码建议。类似 Cursor 和 Github Copilot 编码工具。 官网:aws.amazon.com/cn/codewhis… 在编写代码时,它会自动根据您现有的代码和注释生成建议。从单行代码建…...

【C/C++】虚析构和纯虚析构
纯虚析构的问题 多态使用时,如果子类中有属性开辟到堆区,那么父类指针在释放时无法调用到子类的析构代码。 解决方式:将父类中的析构函数改为虚析构或者纯虚析构 虚析构和纯虚析构共性: 可以解决父类指针释放子类对象都需要有…...
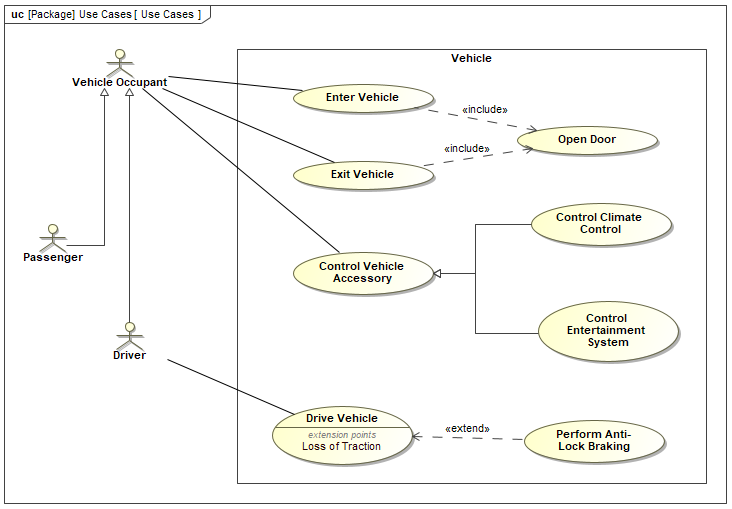
第四章 应用SysML基本特性集的汽车示例 P1|系统建模语言SysML实用指南学习
仅供个人学习记录 汽车模型 主要就是应用练习建模了 Automobile Domain包 用于组织模型的包图 将模型组织入包的包图 需求图捕获汽车规范 汽车规范中包含系统需求的需求图 块定义图定义车辆及其外部环境 汽车域块定义图 用例图表示操作车辆 描述车辆主要功能的用…...

C语言 写一个简易音乐播放器
#include <stdio.h> #include <stdlib.h> #include <stdbool.h> #include <math.h>#define SAMPLE_RATE 44100 // 采样率 #define AMPLITUDE 32767 // 振幅 #define NO_SAMPLES 44100 // 样本数// 声明一个结构体用于表示音符 typedef struct {double …...

面试题:有一个 List 对象集合,如何优雅地返回给前端?
文章目录 1.业务背景每个对象里面都带上了重复的一个sessionId数据,我想提出来该怎么办? 2.实体类3.自定义Mapper和xml文件4.Service层5.Controller层 1.业务背景 业务场景中,一个会话中存在多个场景,即一个session_id对应多个sc…...
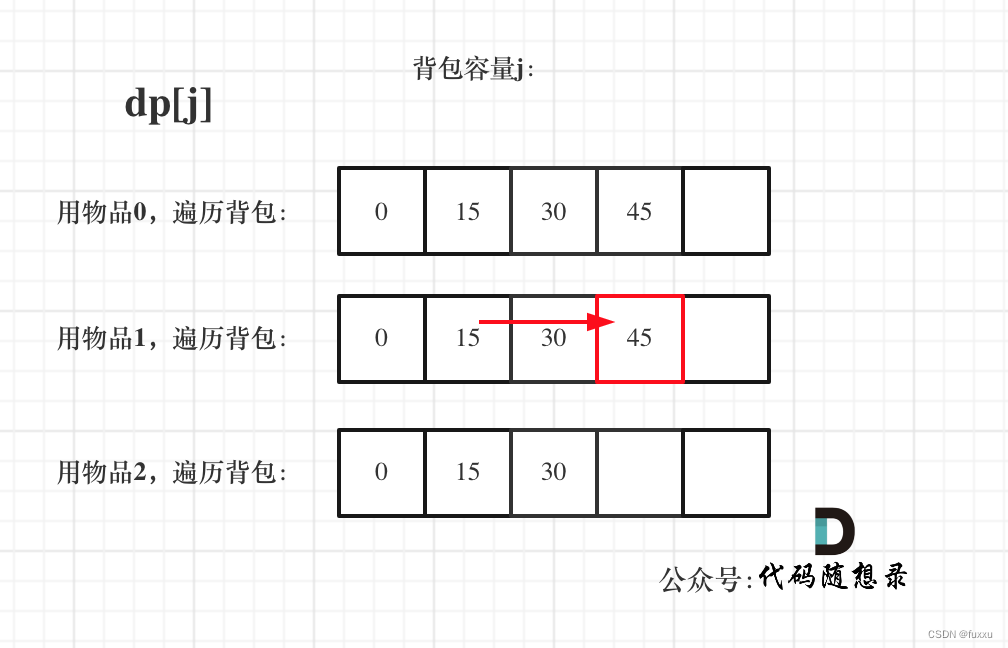
DAY43 完全背包理论基础 + 518.零钱兑换II
完全背包 有N件物品和一个最多能背重量为W的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品都有无限个(也就是可以放入背包多次),求解将哪些物品装入背包里物品价值总和最大。 完全背包和01背包问题唯一不同…...
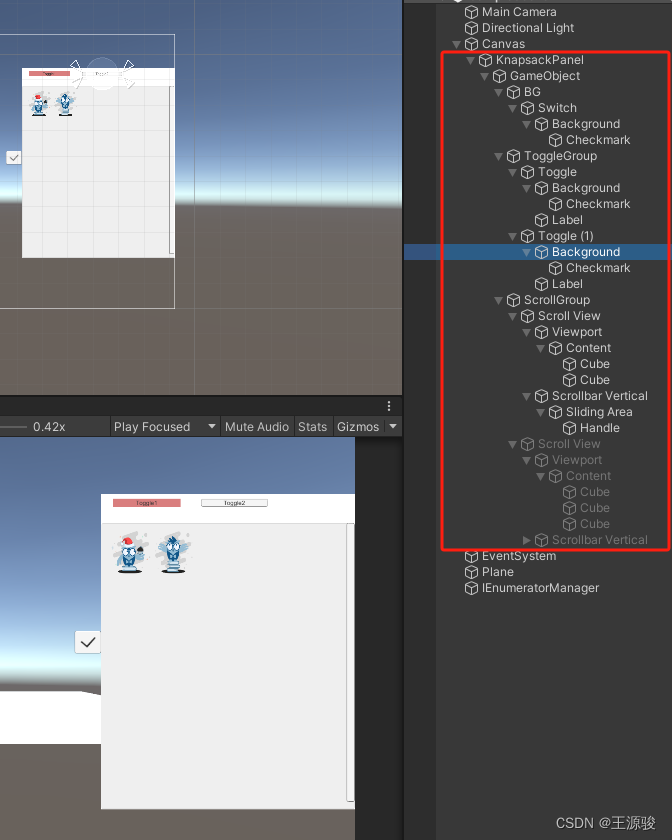
unity 从UI上拖出3D物体,(2D转3D)
效果展示: 2D转3D视频 UI结构 UI组件挂载 UI结构 这个脚本挂载到 3D物体身上 using DG.Tweening; using System.Collections; using System.Collections.Generic; using UnityEngine;public class DragGame : MonoBehaviour {[HideInInspector]public bool isDrag…...

win10pycharm和anaconda安装和环境配置教程
windows10 64位操作系统下系统运行环境安装配置说明 下载和安装Anaconda,链接https://www.anaconda.com/download 下载完后,双击exe文件 将anaconda自动弹出的窗口全部关掉即可,然后配置高级系统变量 根据自己的路径,配置…...

[C++ 中]:6.类和对象下(static成员 + explicit +友元函数 + 内部类 + 编译器优化)
(static成员 explicit 友元函数 内部类 编译器优化) 一.static 成员:1.概念引入:1-1:定义全局变量记录个数? 2.如果有多个类需要分开去记录类对象的个数?2-1:可不可以声明成员变量解决&#…...

ONES Design UI 组件库环境搭建
这个 ONES Design UI 组件库 是基于 Ant Design 的 React UI 组件库,主要用于企业级研发管理工具的研发。 首先用 React 的脚手架搭建一个项目: npx create-react-app my-app cd my-app目前 ONES Design UI 组件库 托管在 ONES 私有的 npm 仓库上, 因此…...

支付宝AI布局: 新产品助力小程序智能化,未来持续投入加速创新
支付宝是全球领先的独立第三方支付平台,致力于为广大用户提供安全快速的电子支付/网上支付/安全支付/手机支付体验,及转账收款/水电煤缴费/信用卡还款/AA收款等生活服务应用。 支付宝不仅是一个支付工具,也是一个数字生活平台,通过…...
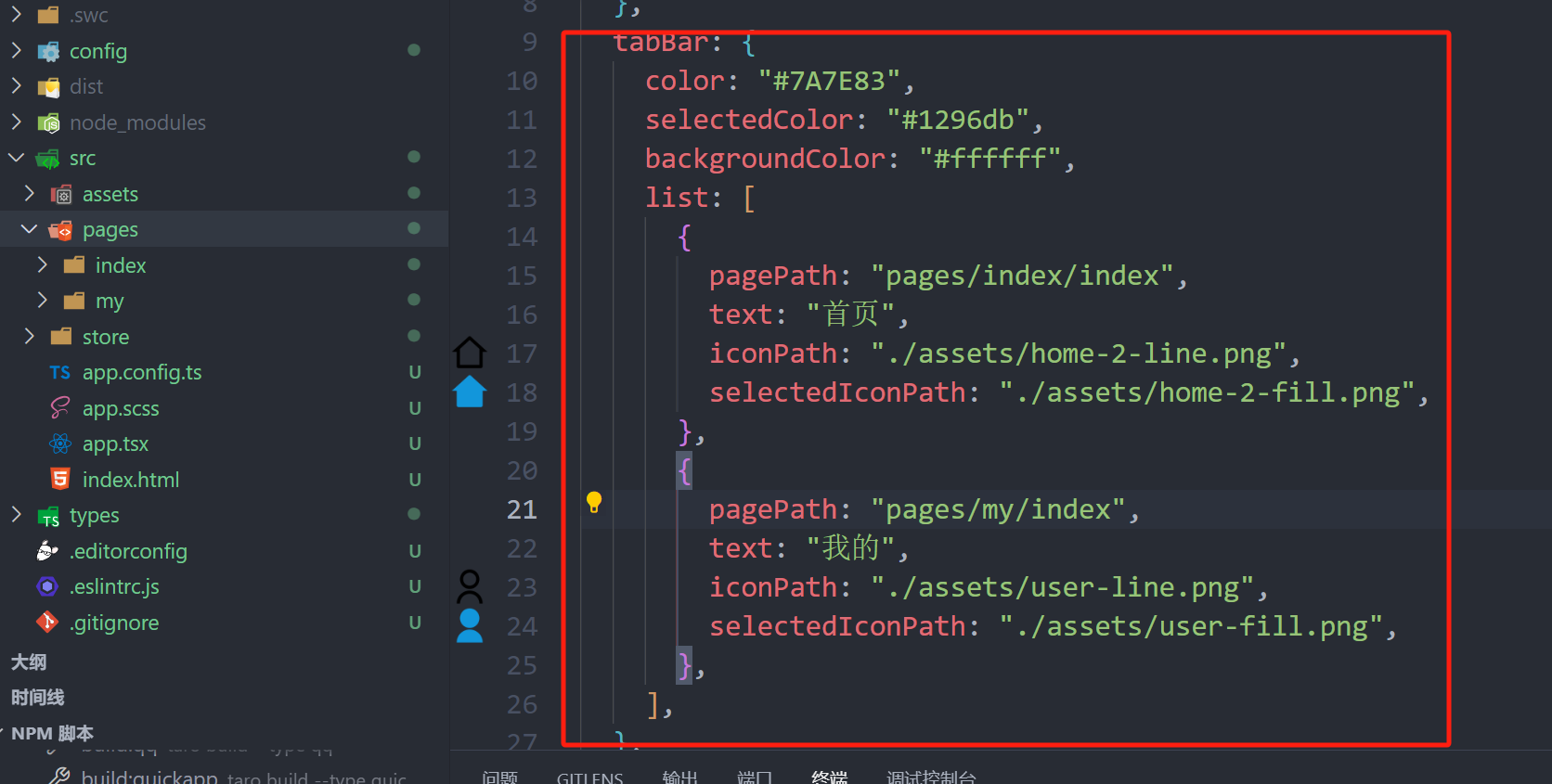
taro全局配置页面路由和tabBar页面跳转
有能力可以看官方文档:Taro 文档 页面路由配置,配置在app.config.ts里面的pages里: window用于设置小程序的状态栏、导航条、标题、窗口背景色,其配置项如下: tabBar配置:如果小程序是一个多 tab 应用&…...

【k8s】pod进阶
一、资源限制 1、资源限制的概念 当定义 Pod 时可以选择性地为每个容器设定所需要的资源数量。 最常见的可设定资源是 CPU 和内存大小,以及其他类型的资源。 当为 Pod 中的容器指定了 request 资源时,调度器就使用该信息来决定将 Pod 调度到哪个节点上…...
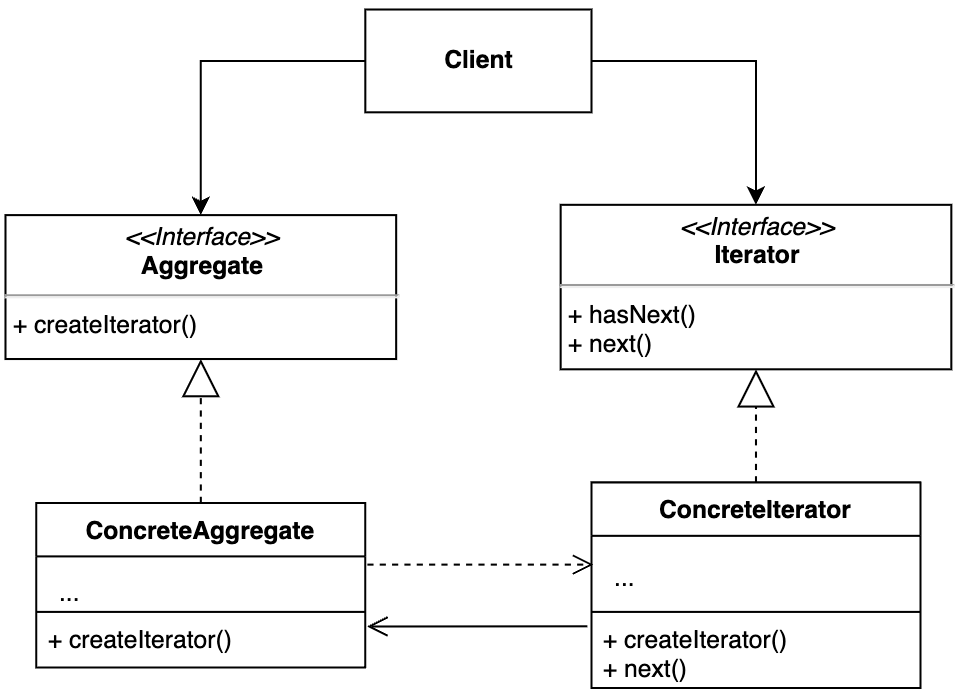
【设计模式】第18节:行为型模式之“迭代器模式”
一、简介 迭代器模式(Iterator Design Pattern),也叫作游标模式(Cursor Design Pattern)。 在通过迭代器来遍历集合元素的同时,增加或者删除集合中的元素,有可能会导致某个元素被重复遍历或遍…...

【数据结构】单链表OJ题
前言: 本节博客将讲解单链表的反转,合并有序链表,寻找中间节点及约瑟夫问题 文章目录 一、反转链表二、合并有序链表三、链表的中间结点四、环形链表的约瑟夫问题 一、反转链表 要反转链表,我们需要遍历链表并改变每个节点的 next 指针&#…...

智能工厂架构
引:https://www.bilibili.com/video/BV1Vs4y167Kx/?spm_id_from=333.788&vd_source=297c866c71fa77b161812ad631ea2c25 智能工厂框架 智能工厂五层系统框架 MES 数据共享 <...

思源宋体TTF完全指南:7种字重免费使用,打造专业中文排版
思源宋体TTF完全指南:7种字重免费使用,打造专业中文排版 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 还在为中文排版找不到合适的免费字体而烦恼吗ÿ…...

写论文缺参考文献?教你一招最快的反向查文献
写文献综述、毕业论文、科研报告时,你是不是也常遇到这些难题:观点明明写得很清楚,却找不到权威文献支撑;文献综述凑不够篇幅,论据来源不充分;逐篇翻数据库筛选文献太耗时,引文格式排版还总出错…...

ESXi 8.0U3i 新版本深度解析|官方原版核心优势 + 部署指南,稳定运维首选
随着企业虚拟化、私有云部署需求的不断升级,一款稳定、安全、可追溯的底层虚拟化系统,成为数据中心、机房运维与合规生产的核心诉求。VMware ESXi 8.0U3i(版本 8.0U3i-25205845)作为 8.0 系列 2026 年最新推出的稳定版本ÿ…...

Honey Select 2汉化补丁:3分钟快速安装与完整功能指南
Honey Select 2汉化补丁:3分钟快速安装与完整功能指南 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为Honey Select 2的日文界面而烦恼吗&…...

Elk内存管理深度解析:如何在100字节RAM上运行JavaScript
Elk内存管理深度解析:如何在100字节RAM上运行JavaScript 【免费下载链接】elk A low footprint JavaScript engine for embedded systems 项目地址: https://gitcode.com/gh_mirrors/elk/elk Elk是一个为嵌入式系统设计的超轻量级JavaScript引擎,…...

终极Fansly下载指南:5步快速掌握高效内容保存技巧
终极Fansly下载指南:5步快速掌握高效内容保存技巧 【免费下载链接】fansly-downloader Easy to use fansly.com content downloading tool. Written in python, but ships as a standalone Executable App for Windows too. Enjoy your Fansly content offline anyt…...

小学期学习报告-1
通过B站视频学习之后,我掌握冰设计出了555方波发生电路和低通滤波器,通过示波器可以看到,已经除了稳定的方波和正弦波 在这个过程中,根据公式T0.7*( R12R2)*C1,多次调整并得出稳定波形ÿ…...

IDEA项目乱码终结指南:从UTF-8全局设置到.properties文件特殊处理
IDEA项目乱码终结指南:从UTF-8全局设置到.properties文件特殊处理 在Java开发中,编码问题就像一颗定时炸弹,随时可能在最意想不到的时刻引爆。特别是当项目涉及多语言支持、团队协作或接手遗留代码时,乱码问题往往成为开发者挥之不…...

LyricsX终极指南:如何在macOS上免费获得完美歌词同步体验
LyricsX终极指南:如何在macOS上免费获得完美歌词同步体验 【免费下载链接】LyricsX 🎶 Ultimate lyrics app for macOS. 项目地址: https://gitcode.com/gh_mirrors/ly/LyricsX 你是否厌倦了在不同音乐播放器间切换时手动搜索歌词?Lyr…...

独立开发者应对Claude Code封号风险的备用方案与接入实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者应对Claude Code封号风险的备用方案与接入实践 对于依赖Claude Code进行日常开发的独立开发者或小型团队而言࿰…...