【Apache Flink】Flink DataStream API的基本使用
Flink DataStream API的基本使用
文章目录
- 前言
- 1. 基本使用方法
- 2. 核心示例代码
- 3. 完成工程代码
- pom.xml
- WordCountExample
- 测试验证
- 4. Stream 执行环境
- 5. 参考文档
前言
Flink DataStream API主要用于处理无界和有界数据流 。
无界数据流是一个持续生成数据的数据源,它没有明确的结束点,例如实时的交易数据或传感器数据。这种类型的数据流需要使用Apache Flink的实时处理功能来连续地处理和分析。
有界数据流是一个具有明确开始和结束点的数据集,例如一个文件或数据库表。这种类型的数据流通常在批处理场景中使用,其中所有数据都已经可用,并可以一次性处理。
Flink的DataStream API提供了一套丰富的操作符,如map、filter、reduce、aggregations、windowing、join等,以支持各种复杂的数据处理和分析需求。此外,DataStream API还提供了容错保证,能确保在发生故障时,应用程序能从最近的检查点(checkpoint)恢复,从而实现精确一次(exactly-once)的处理语义。
1. 基本使用方法
-
创建执行环境:
每一个Flink程序都需要创建一个
StreamExecutionEnvironment(执行环境),它可以被用来设置参数和创建从外部系统读取数据的流。final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); -
创建数据流:
你可以从各种数据源中创建数据流,如本地集合,文件,socket等。下面的代码是从本地集合创建数据流的示例:
DataStream<String> dataStream = env.fromElements("hello", "flink"); -
转换操作:
Flink提供了丰富的转换操作,如
map,filter,reduce等。以下代码首先将每个字符串映射为其长度,然后过滤出长度大于5的元素:DataStream<Integer> transformedStream = dataStream.map(s -> s.length()).filter(l -> l > 5); -
数据输出:
Flink支持将数据流输出到各种存储系统,如文件,socket,数据库等。下面的代码将数据流输出到标准输出:
transformedStream.print(); -
执行程序:
将上述所有步骤放在main函数中,并在最后调用
env.execute()方法来启动程序。Flink程序是懒加载的,只有在调用execute方法时才会真正开始执行。env.execute("Flink Basic API Usage");
2. 核心示例代码
使用Flink DataStream API构建一个实时Word Count程序,它会从一个socket端口读取文本数据,统计每个单词的出现次数,并将结果输出到标准输出。
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class WordCountExample {public static void main(String[] args) throws Exception {// 1. 创建执行环境final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2. 创建数据流,从socket接收数据,需要在本地启动一个端口为9000的socket服务器DataStream<String> textStream = env.socketTextStream("localhost", 9000);// 3. 转换操作DataStream<Tuple2<String, Integer>> wordCountStream = textStream.flatMap(new LineSplitter()) // 将文本行切分为单词.keyBy(0) // 按单词分组.sum(1); // 对每个单词的计数求和// 4. 数据输出wordCountStream.print();// 5. 执行程序env.execute("Socket Word Count Example");}// 自定义一个FlatMapFunction,将输入的每一行文本切分为单词,并输出为Tuple2,第一个元素是单词,第二个元素是计数(初始值为1)public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {@Overridepublic void flatMap(String line, Collector<Tuple2<String, Integer>> out) {for (String word : line.split(" ")) {out.collect(new Tuple2<>(word, 1));}}}
}
3. 完成工程代码
下面是一个基于Apache Flink的实时单词计数应用程序的完整工程代码,包括Pom.xml文件和所有Java类。
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.example</groupId><artifactId>flink-wordcount-example</artifactId><version>1.0-SNAPSHOT</version><packaging>jar</packaging><properties><flink.version>1.13.2</flink.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.11</artifactId><version>${flink.version}</version></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.8.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin></plugins></build>
</project>
WordCountExample
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class WordCountExample {public static void main(String[] args) throws Exception {// 1. 创建执行环境final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2. 创建数据流,从socket接收数据,需要在本地启动一个端口为9000的socket服务器DataStream<String> textStream = env.socketTextStream("localhost", 9000);// 3. 转换操作DataStream<Tuple2<String, Integer>> wordCountStream = textStream.flatMap(new LineSplitter()) // 将文本行切分为单词.keyBy(0) // 按单词分组.sum(1); // 对每个单词的计数求和// 4. 数据输出wordCountStream.print();// 5. 执行程序env.execute("Socket Word Count Example");}// 自定义一个FlatMapFunction,将输入的每一行文本切分为单词,并输出为Tuple2,第一个元素是单词,第二个元素是计数(初始值为1)public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {@Overridepublic void flatMap(String line, Collector<Tuple2<String, Integer>> out) {for (String word : line.split(" ")) {out.collect(new Tuple2<>(word, 1));}}}
}
现在,你可以使用Maven编译并运行这个程序。在启动程序之前,你需要在本地启动一个端口为9000的Socket服务器。这可以通过使用Netcat工具 (nc -lk 9000) 或者其他任何能打开端口的工具实现。然后,你可以输入文本行,Flink程序会统计每个单词出现的次数,并实时打印结果。
测试验证
用py在本地启动一个socket服务器,监听9000端口,
python比较简单实现一个socket通信 。写一个Python来验证上面写的例子。
import socketserver_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind(("localhost", 9000))
server_socket.listen(1)print("Waiting for connection...")
client_socket, client_address = server_socket.accept()
print("Connected to:", client_address)while True:data = input("Enter text: ")client_socket.sendall(data.encode())
运行Flink程序和Python socket服务器,然后在Python程序中输入文本, 会看到Flink程序实时统计每个单词出现的次数并输出到控制台。
4. Stream 执行环境
开发学习过程中,不需要关注。每个 Flink 应用都需要有执行环境,在该示例中为 env。流式应用需要用到 StreamExecutionEnvironment。
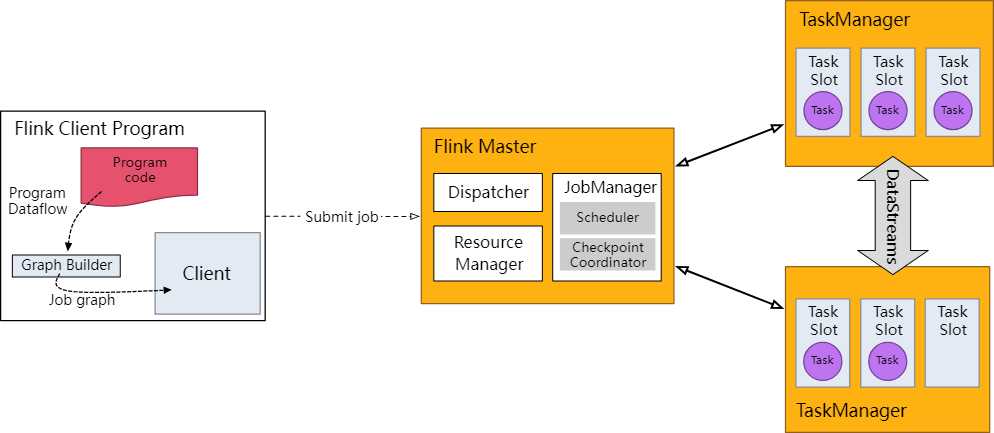
DataStream API 将你的应用构建为一个 job graph,并附加到 StreamExecutionEnvironment 。当调用 env.execute() 时此 graph 就被打包并发送到 JobManager 上,后者对作业并行处理并将其子任务分发给 Task Manager 来执行。每个作业的并行子任务将在 task slot 中执行。
注意,如果没有调用 execute(),应用就不会运行。
Flink runtime: client, job manager, task managers
此分布式运行时取决于你的应用是否是可序列化的。它还要求所有依赖对集群中的每个节点均可用。
5. 参考文档
https://nightlies.apache.org/flink/flink-docs-release-1.18/zh/docs/learn-flink/datastream_api/
相关文章:
【Apache Flink】Flink DataStream API的基本使用
Flink DataStream API的基本使用 文章目录 前言1. 基本使用方法2. 核心示例代码3. 完成工程代码pom.xmlWordCountExample测试验证 4. Stream 执行环境5. 参考文档 前言 Flink DataStream API主要用于处理无界和有界数据流 。 无界数据流是一个持续生成数据的数据源࿰…...

民安:专业在线教育平台客户满意度调查的引领者
在当今的在线教育市场中,客户满意度已成为衡量平台竞争力的关键因素。为了准确了解客户的需求和反馈,某在线教育企业委托民安智库(专业市场调查公司)对其进行全面的客户满意度调查。 此次调查旨在了解客户对在线教育平台的服务质…...

浅谈新能源汽车充电桩的选型与安装
叶根胜 安科瑞电气股份有限公司 上海嘉定201801 摘要:电动汽车的大力发展和推广是国家为应对日益突出的燃油供需矛盾和环境污染,加强生态环境保护和治理而开发新能源和清洁能源的措施之一,加快了电动汽车的发展。如今,电动汽车已…...

FFmpeg系列索引
第一章 初识FFmpeg https://blog.csdn.net/huantianxidi/article/details/134130159 第二章 ffplay是什么 https://blog.csdn.net/huantianxidi/article/details/134151043...

AWS组件使用
kafka或kinesis 做数据收集 S3redshift 做数仓 EMR做计算 RDS做数据市场 AWS Glue / AWS Data Pipeline 做数据集成 这些组件配合起来,几乎可以做各种方式的数据分析 kinesis还是比较推荐,延迟时间可以配置的算是实时的,而且功能会多一点&am…...

DALLE 3技术分析 - 训练方式/模型结构
DALLE 3技术分析 - 训练方式/模型结构 1. 引言: 从 DALLE 3 开发者技术轨迹中,以及模型的演示视频,我们可以推导 DALLE 3 模型的某些架构信息。 2. DALLE 2 的评价: DALLE 2 的性能不佳,主要归因于 CLIP 模型的限制。 CLIP 在为后续的 diffus…...

Go的自定义错误
在上一篇教程中,我们了解了 Go 中的错误表示以及如何处理标准库中的错误。我们还学习了如何从错误中提取更多信息。 本教程介绍如何创建我们自己的自定义错误,我们可以在函数和包中使用这些错误。我们还将使用标准库所采用的相同技术来提供有关自定义错…...
SpringBoot集成Dubbo
在SpringMVC中Dubbo的使用https://tiantian.blog.csdn.net/article/details/134194696?spm1001.2014.3001.5502 阿里巴巴提供了Dubbo集成SpringBoot开源项目。(这个.....) 地址GitHub https://github.com/apache/dubbo-spring-boot-project 查看入门教程 反正是pilipala一大…...
利用shp文件构建mask【MATLAB和ARCGIS】两种方法
1 ARCGIS (推荐!!!-速度很快) 利用Polygon to Raster 注意:由于我们想要的mask有效值是1,在进行转换的时候,注意设置转换字段【Value field】 【Value field】通过编辑shp文件属性表…...
Luminar Neo Mac/Windows中文版:引领AI图像编辑的革命性时代
Luminar Neo运用先进的AI技术,能够自动化地完成许多繁琐的编辑任务,如色彩校正、噪点消除、人脸识别等。这不仅大大提高了工作效率,同时也降低了对专业知识和技能的要求。无论你是专业摄影师,还是摄影爱好者,甚至是一个…...
远程设备常用工具:向日葵、Todesk
其实按理说远程工具例如向日葵、Todesk如果是计算机专业、计算机从业者是必须知道的一个东西,但是在大学期间身边知道的人是少之又少的。 向日葵、Todesk工具的优势:方便、快捷、速度快等等我就不过多阐述了 PS:现在我就是在学校用远程写这篇 很多时候…...

JAVA七种常见排序算法
前言: 排序算法在计算机科学中扮演着至关重要的角色,它们用于将无序数据变为有序数据,以便更有效地检索和处理信息。不同的排序算法适用于不同的情况,因此了解它们的工作原理和性能特点对于选择正确的算法至关重要。本文提供的Jav…...

高质量绝世玄幻小说,情节引人入胜,一读成痴的绝佳选择
《我有一个修仙世界》 在这个高科技后修仙时代,主角拥有资源丰富的原始修仙世界。他需要不断地探索、发掘、修炼,才能成为真正的修仙者。这是一本充满想象力和创意的小说。 《长生武道:从五禽养生拳开始》 林轩修炼养生类功法,通过…...

Flask三种添加路由的方法
Flask 是一个流行的 Python Web 框架,它提供了多种方法来添加路由。路由是将 URL 映射到特定函数的过程,它是构建 Web 应用程序的基础。本文将介绍 Flask 中几种常用的路由添加方法,并附带代码示例。 方法一:使用装饰器 from flas…...

基于layui的select选择框修改为多选框
layui-xm-select 的功能强大,可多选、可下拉树、下拉日期多选、下拉折叠面板、下拉穿梭框、级联模式。 首先在引用layui css和js 的基础上,再引用js:layui-xm-select layui-xm-select点击下载地址 基本使用 第一步: 下载 第二步: 引入 layu…...
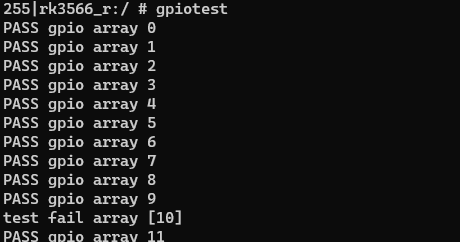
【技术分享】RK356X Android 使用 libgpiod 测试gpio
前言 libgpiod 是用于与 Linux GPIO 字符设备交互的 C 库和工具库;此项目包含六种命令行工具(gpiodetect、gpioinfo、gpioset、gpioget、gpiomon),使用这些工具可以在命令行设置和获取GPIO的状态信息;在程序开发中也可…...
)
代碼隨想錄算法訓練營|第五十九天|647. 回文子串、7516.最长回文子序列、动态规划总结篇。刷题心得(c++)
目录 讀題 647. 回文子串 看完代码随想录之后的想法 516.最长回文子序列 看完代码随想录之后的想法 647. 回文子串 - 實作 思路 動態規劃思路 雙指針思路 Code 動態規劃思路 雙指針思路 516.最长回文子序列 - 實作 思路 Code 动态规划 - 總結 動態規劃基礎 動…...

Qt封装的Halcon显示控件,支持ROI绘制
前言 目前机器视觉ROI交互控件在C#上做的比较多,而Qt上做的比较少,根据作者 VSQtHalcon——显示图片,实现鼠标缩放、移动图片的文章,我在显示和移动控件的基础上,增加了ROI设置功能,并封装成了一个独立的Q…...

基于深度学的图像修复 图像补全 计算机竞赛
1 前言 🔥 优质竞赛项目系列,今天要分享的是 基于深度学的图像修复 图像补全 该项目较为新颖,适合作为竞赛课题方向,学长非常推荐! 🧿 更多资料, 项目分享: https://gitee.com/dancheng-se…...

vue3框架全局修改样式(字体颜色以及初始化定义基础elemplent颜色)
问题1、全局修改vue管理系统框架的字体颜色(index.scss目录下修改) 问题2、vue3中使用elemplent-plus中的el-select组件,默认选中二级或三级的一个数据,没有显示label只显示了id 问题如下 原因是因为 这个属性为true了࿰…...

手把手教你改造10块钱的USBASP烧录器,让它兼容Arduino IDE和AVRDUDESS
10元USBASP烧录器改造实战:解锁Arduino与AVRDUDESS全兼容方案 从闲置到全能:低成本硬件改造的价值探索 在电子制作和嵌入式开发领域,专业烧录工具往往价格不菲。但你可能不知道,手头那台吃灰的"智峰"版USBASP烧录器&…...

月度补丁如何落地?Claude Code 在商业项目中实现版本追新的 4 步更新机制
1. 月度补丁不是“一键升级”,而是四次有节奏的上下文重校准 大多数人把 Claude Code 的月度补丁理解成“换了个模型版本号”——就像给手机系统点一下“更新”。我去年在三个中型商业项目里连续踩了这个坑:每次新补丁发布后,团队反馈“AI 写的代码变奇怪了”,review 通过…...

产品经理必懂的博弈论:如何用帕累托最优和纳什均衡设计用户激励与平台规则
产品经理必懂的博弈论:如何用帕累托最优和纳什均衡设计用户激励与平台规则 在互联网产品的世界里,每天都有无数场看不见的博弈正在上演——司机与乘客的匹配、商家与消费者的互动、创作者与平台的共生。这些看似复杂的商业行为背后,往往遵循着…...

OpenPnP玩家必看:深度解析松下DP102传感器与贴片机真空系统的联动原理与调优
OpenPnP系统集成实战:DP102负压传感器与真空控制回路的科学调优 在DIY贴片机的世界里,OpenPnP系统就像一位不知疲倦的指挥家,而DP102负压传感器则是这支精密乐队中的关键乐手。当吸嘴与元器件相遇的瞬间,背后是一场由气压数据驱动…...

探索中医数字化:基于深度学习的舌苔检测项目推荐
探索中医数字化:基于深度学习的舌苔检测项目推荐 【下载地址】基于深度学习的舌苔检测毕设留档 本项目是针对中医领域中舌象分析的一项研究,通过应用深度学习技术来实现自动的舌苔检测。随着人工智能在医疗健康领域的深入发展,利用计算机视觉…...

AM62A1-Q1汽车视觉处理器:低功耗、高集成度的车载视觉解决方案
1. 项目概述:为什么我们需要一颗“小而美”的汽车视觉处理器?最近在做一个车载环视和DMS(驾驶员监控系统)的预研项目,客户对成本和功耗卡得非常死,但功能要求却一点没降:需要同时处理1到2路摄像…...
)
Overleaf实战:手把手教你用LaTeX制作符合A4排版要求的跨页长表格(含完整代码)
Overleaf实战:LaTeX跨页长表格的终极解决方案 当你正在撰写一篇包含大量数据的学术论文或技术手册时,那些横跨多页的表格往往会成为格式噩梦。表格在页面底部被生硬截断,表头在后续页面消失,页码引用混乱——这些问题不仅影响阅读…...

Nintendo Switch文件管理终极指南:NSC_BUILDER如何成为你的游戏库管家
Nintendo Switch文件管理终极指南:NSC_BUILDER如何成为你的游戏库管家 【免费下载链接】NSC_BUILDER Nintendo Switch Cleaner and Builder. A batchfile, python and html script based in hacbuild and Nuts python libraries. Designed initially to erase title…...

微信好友关系检测工具完整指南:如何快速发现谁删除了你
微信好友关系检测工具完整指南:如何快速发现谁删除了你 【免费下载链接】WechatRealFriends 微信好友关系一键检测,基于微信ipad协议,看看有没有朋友偷偷删掉或者拉黑你 项目地址: https://gitcode.com/gh_mirrors/we/WechatRealFriends …...

Avogadro 2:解决跨平台化学建模可视化挑战的开源方案
Avogadro 2:解决跨平台化学建模可视化挑战的开源方案 【免费下载链接】avogadroapp Avogadro is an advanced molecular editor designed for cross-platform use in computational chemistry, molecular modeling, bioinformatics, materials science, and related…...