diffusers-Load pipelines,models,and schedulers
https://huggingface.co/docs/diffusers/using-diffusers/loading![]() https://huggingface.co/docs/diffusers/using-diffusers/loading
https://huggingface.co/docs/diffusers/using-diffusers/loading
有一种简便的方法用于推理是至关重要的。扩散系统通常由多个组件组成,如parameterized model、tokenizers和schedulers,它们以复杂的方式进行交互。这就是为什么我们设计了DiffusionPipeline,将整个扩散系统的复杂性包装成易于使用的API,同时保持足够的灵活性,以适应其他用例,例如将每个组件单独加载作为构建块来组装自己的扩散系统。
1.Diffusion Pipeline
DiffusionPipeline是扩散模型最简单最通用的方法。
from diffusers import DiffusionPipelinerepo_id = "runwayml/stable-diffusion-v1-5"
pipe = DiffusionPipeline.from_pretrained(repo_id, use_safetensors=True)也可以使用特定的pipeline
from diffusers import StableDiffusionPipelinerepo_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(repo_id, use_safetensors=True)Community pipelines是原始实现不同于DiffusionPipeline,例如StableDiffusionControlNetPipeline.
1.1 local pipeline
from diffusers import DiffusionPipelinerepo_id = "./stable-diffusion-v1-5" # local path
stable_diffusion = DiffusionPipeline.from_pretrained(repo_id, use_safetensors=True)from_pretrained()方法在检测到本地路径时不会下载。
1.2 swap components in a pipeline
可以使用另一个兼容的组件来自定义任何流程的默认组件。定制非常重要,因为:
- 更改调度器对于探索生成速度和质量之间的权衡是重要的。
- 模型的不同组件通常是独立训练的,您可以用性能更好的组件替换掉现有组件。
- 在微调过程中,通常只有一些组件(如UNet或文本编码器)进行训练。
from diffusers import DiffusionPipelinerepo_id = "runwayml/stable-diffusion-v1-5"
stable_diffusion = DiffusionPipeline.from_pretrained(repo_id, use_safetensors=True)
stable_diffusion.scheduler.compatiblesfrom diffusers import DiffusionPipeline, EulerDiscreteScheduler, DPMSolverMultistepSchedulerrepo_id = "runwayml/stable-diffusion-v1-5"
scheduler = EulerDiscreteScheduler.from_pretrained(repo_id, subfolder="scheduler")
stable_diffusion = DiffusionPipeline.from_pretrained(repo_id, scheduler=scheduler, use_safetensors=True)可以将PNDMScheduler更换为EulerDiscreteScheduler,在回传到DiffusionPipeline中。
1.3 safety checker
safety checker可以根据已知的NSFW内容检查生成的输出,
from diffusers import DiffusionPipelinerepo_id = "runwayml/stable-diffusion-v1-5"
stable_diffusion = DiffusionPipeline.from_pretrained(repo_id, safety_checker=None, use_safetensors=True)1.4 reuse components across pipelines
可以在多个pipeline中可以重复使用相同的组件,以避免将权重加载到RAM中2次
from diffusers import StableDiffusionPipeline, StableDiffusionImg2ImgPipelinemodel_id = "runwayml/stable-diffusion-v1-5"
stable_diffusion_txt2img = StableDiffusionPipeline.from_pretrained(model_id, use_safetensors=True)components = stable_diffusion_txt2img.components可以将components传递到另一个pipeline中,无需将权重重新加载到RAM中:
stable_diffusion_img2img = StableDiffusionImg2ImgPipeline(**components)下面的方式更加灵活:
from diffusers import StableDiffusionPipeline, StableDiffusionImg2ImgPipelinemodel_id = "runwayml/stable-diffusion-v1-5"
stable_diffusion_txt2img = StableDiffusionPipeline.from_pretrained(model_id, use_safetensors=True)
stable_diffusion_img2img = StableDiffusionImg2ImgPipeline(vae=stable_diffusion_txt2img.vae,text_encoder=stable_diffusion_txt2img.text_encoder,tokenizer=stable_diffusion_txt2img.tokenizer,unet=stable_diffusion_txt2img.unet,scheduler=stable_diffusion_txt2img.scheduler,safety_checker=None,feature_extractor=None,requires_safety_checker=False,
)1.5 checkpoint variants
以torch.float16保存,节省一半的内存,但是无法训练,EMA不用于推理,用于微调模型。
2. models
from diffusers import UNet2DConditionModelrepo_id = "runwayml/stable-diffusion-v1-5"
model = UNet2DConditionModel.from_pretrained(repo_id, subfolder="unet", use_safetensors=True)所有的权重都存储在一个safetensors中, 可以用.from_single_file()来加载模型。safetensors安全且加载速度快。
2.1 load different stable diffusion formats
.ckpt也可以用from_single_file(),但最好转成hf格式,可以使用diffusers官方提供的服务转:https://huggingface.co/spaces/diffusers/sd-to-diffusers
也可以使用脚本转:https://github.com/huggingface/diffusers/blob/main/scripts/convert_original_stable_diffusion_to_diffusers.py
python ../diffusers/scripts/convert_original_stable_diffusion_to_diffusers.py --checkpoint_path temporalnetv3.ckpt --original_config_file cldm_v15.yaml --dump_path ./ --controlnetA1111 Lora文件,diffusers可以使用load_lora_weights()加载lora模型:
from diffusers import DiffusionPipeline, UniPCMultistepScheduler
import torchpipeline = DiffusionPipeline.from_pretrained("andite/anything-v4.0", torch_dtype=torch.float16, safety_checker=None
).to("cuda")
pipeline.scheduler = UniPCMultistepScheduler.from_config(pipeline.scheduler.config)# uncomment to download the safetensor weights
#!wget https://civitai.com/api/download/models/19998 -O howls_moving_castle.safetensorspipeline.load_lora_weights(".", weight_name="howls_moving_castle.safetensors")prompt = "masterpiece, illustration, ultra-detailed, cityscape, san francisco, golden gate bridge, california, bay area, in the snow, beautiful detailed starry sky"
negative_prompt = "lowres, cropped, worst quality, low quality, normal quality, artifacts, signature, watermark, username, blurry, more than one bridge, bad architecture"images = pipeline(prompt=prompt,negative_prompt=negative_prompt,width=512,height=512,num_inference_steps=25,num_images_per_prompt=4,generator=torch.manual_seed(0),
).imagesfrom diffusers.utils import make_image_gridmake_image_grid(images, 2, 2)3.scheduler
scheduler没有参数化或训练;由配置文件定义。加载scheduler不会消耗大的内存,并且相同的配置文件可以用于各种不同的scheduler,比如下面的scheduler均可与StableDiffusionPipline兼容。
Diffusion流程本质上是由扩散模型和scheduler组成的集合,它们在一定程度上彼此独立。这意味着可以替换流程的某些部分,其中最好的例子就是scheduler。扩散模型通常只定义从噪声到较少噪声样本的前向传递过程,而调度器定义了整个去噪过程,包括:
去噪步骤是多少?随机的还是确定性的?用什么算法找到去噪样本? 调度器可以非常复杂,并且经常在去噪速度和去噪质量之间进行权衡。
from diffusers import StableDiffusionPipeline
from diffusers import (DDPMScheduler,DDIMScheduler,PNDMScheduler,LMSDiscreteScheduler,EulerDiscreteScheduler,EulerAncestralDiscreteScheduler,DPMSolverMultistepScheduler,
)repo_id = "runwayml/stable-diffusion-v1-5"ddpm = DDPMScheduler.from_pretrained(repo_id, subfolder="scheduler")
ddim = DDIMScheduler.from_pretrained(repo_id, subfolder="scheduler")
pndm = PNDMScheduler.from_pretrained(repo_id, subfolder="scheduler")
lms = LMSDiscreteScheduler.from_pretrained(repo_id, subfolder="scheduler")
euler_anc = EulerAncestralDiscreteScheduler.from_pretrained(repo_id, subfolder="scheduler")
euler = EulerDiscreteScheduler.from_pretrained(repo_id, subfolder="scheduler")
dpm = DPMSolverMultistepScheduler.from_pretrained(repo_id, subfolder="scheduler")# replace `dpm` with any of `ddpm`, `ddim`, `pndm`, `lms`, `euler_anc`, `euler`
pipeline = StableDiffusionPipeline.from_pretrained(repo_id, scheduler=dpm, use_safetensors=True)4.DiffusionPipline explained
作为一个类方法,DiffusionPipeline.from_pretrained()做两件事,1.下载推理所需的权重并缓存,一般存在在.cache文件中,2.将缓存文件中的model_index.json进行实例化。
feature_extractor--CLIPFeatureExtractor(transformers);scheduler--PNDMScheduler;text_encoder--CLIPTextModel(transformers);tokenizer--CLIPTokenizer(transformers);unet--UNet2DConditionModel;vae--AutoencoderKL
{"_class_name": "StableDiffusionPipeline","_diffusers_version": "0.6.0","feature_extractor": ["transformers","CLIPImageProcessor"],"safety_checker": ["stable_diffusion","StableDiffusionSafetyChecker"],"scheduler": ["diffusers","PNDMScheduler"],"text_encoder": ["transformers","CLIPTextModel"],"tokenizer": ["transformers","CLIPTokenizer"],"unet": ["diffusers","UNet2DConditionModel"],"vae": ["diffusers","AutoencoderKL"]
}下面是runway/stable-diffusion-v1-5的文件夹结构:
.
├── feature_extractor
│ └── preprocessor_config.json
├── model_index.json
├── safety_checker
│ ├── config.json
│ └── pytorch_model.bin
├── scheduler
│ └── scheduler_config.json
├── text_encoder
│ ├── config.json
│ └── pytorch_model.bin
├── tokenizer
│ ├── merges.txt
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── vocab.json
├── unet
│ ├── config.json
│ ├── diffusion_pytorch_model.bin
└── vae├── config.json├── diffusion_pytorch_model.bin可以查看组件的属性和配置:
pipeline.tokenizer
CLIPTokenizer(name_or_path="/root/.cache/huggingface/hub/models--runwayml--stable-diffusion-v1-5/snapshots/39593d5650112b4cc580433f6b0435385882d819/tokenizer",vocab_size=49408,model_max_length=77,is_fast=False,padding_side="right",truncation_side="right",special_tokens={"bos_token": AddedToken("<|startoftext|>", rstrip=False, lstrip=False, single_word=False, normalized=True),"eos_token": AddedToken("<|endoftext|>", rstrip=False, lstrip=False, single_word=False, normalized=True),"unk_token": AddedToken("<|endoftext|>", rstrip=False, lstrip=False, single_word=False, normalized=True),"pad_token": "<|endoftext|>",},
)相关文章:
diffusers-Load pipelines,models,and schedulers
https://huggingface.co/docs/diffusers/using-diffusers/loadinghttps://huggingface.co/docs/diffusers/using-diffusers/loading 有一种简便的方法用于推理是至关重要的。扩散系统通常由多个组件组成,如parameterized model、tokenizers和schedulers,…...

私域营销必备:轻松掌握微信CRM管理方法
大家在微信私域营销中都遇到了什么问题? 比如管理时间不够,群发实效性低,自动回复无法适应变化等等。 我们可以利用微信CRM这个工具,轻松解决这些问题。 请问你们最想用这个工具解决什么问题呢? 使用微信CRM不仅可…...

最长回文子串-LeetCode5 动态规划
由于基础还不是很牢固 一时间只能想到暴力的解法: 取遍每个子串 总数量nn-1n-2…1 O(n^2) 判断每个子串是否属于回文串 O(n) 故总时间复杂度为O(n^3) class Solution { public:string longestPalindrome(string s) { int max0;string ret;for(int i0;i<s.size();i)for(int…...

mysql简单备份和恢复
版本:mysql8.0 官方文档 :MySQL :: MySQL 8.0 Reference Manual :: 7 Backup and Recovery 1.物理备份恢复 物理备份是以数据文件形式备份。这种方式效率高点,适合大型数据库备份。物理备份可冷备可热备。 使用mysqlbackup 命令进行物理备…...

JMeter介绍
1. JMeter是什么? 是Apache组织开发基于Java的接口测试工具,性能测试工具 2.JMeter的优缺点 优点: 开源,免费 跨平台 支持多协议 轻量级别 缺点: 不支持IP欺骗 不可验证页面UI 3.JMeter可以用来做什么? …...

flink job同时使用BroadcastProcessFunction和KeyedBroadcastProcessFunction例子
背景: 广播状态可以用于规则表或者配置表的实时更新,本文就是用一个欺诈检测的flink作业作为例子看一下BroadcastProcessFunction和KeyedBroadcastProcessFunction的使用 BroadcastProcessFunction和KeyedBroadcastProcessFunction的使用 1.首先看主流…...

数据中心系统解决方案
设计思路 系统设计过程中充分考虑各个子系统的信息共享要求,对各子系统进行结构化和标准化设计,通过系统间的各种联动方式将其整合成一个有机的整体,使之成为一套整体的、全方位的数据中心大楼综合管理系统,达到人防、物防和技防…...
服务器开设新账户,创建账号并设置密码
实验室又进新同学了,服务器开设新账号搞起来 1、创建用户: 在root权限下,输入命令useradd -m 用户名,如下 sudo useradd -m yonghuming 2、设置密码: 输入命令passwd 用户名 回车,接着输入密码操作&…...

【C++】关于构造函数后面冒号“:“的故事------初始化列表(超详细解析,小白一看就懂)
目录 一、前言 二、 初始化的概念区分 三、初始化列表 (重点) 💦初始化列表的概念理解 💦初始化列表的注意事项 四、共勉 一、前言 在之前的博客学习中,我们已经学习了【C】的六大默认成员函数 ,想必大…...
)
【Shell 系列教程】shell基本运算符(四)
文章目录 往期回顾关系运算符布尔运算符逻辑运算符字符串运算符文件测试运算符其他检查符: 往期回顾 【Shell 系列教程】shell介绍(一)【Shell 系列教程】shell变量(二)【Shell 系列教程】shell数组(三&am…...

MongoDB安装及开发系例全教程
一、系列文章目录 一、MongoDB安装教程—官方原版 二、MongoDB 使用教程(配置、管理、监控)_linux mongodb 监控 三、MongoDB 基于角色的访问控制 四、MongoDB用户管理 五、MongoDB基础知识详解 六、MongoDB—Indexs 七、MongoDB事务详解 八、MongoDB分片教程 九、Mo…...
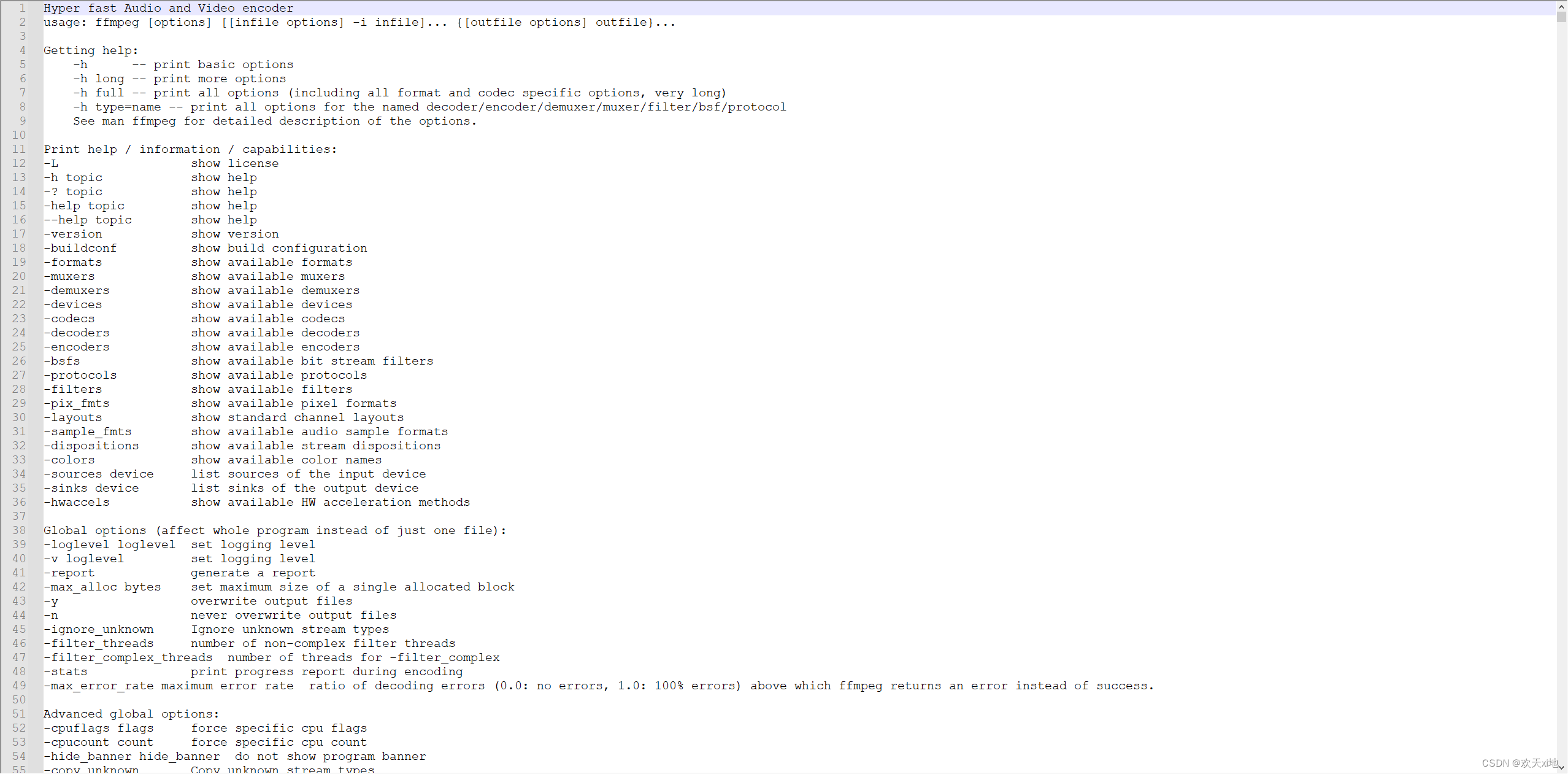
ffmpeg命令帮助文档
一:帮助文档的命令格式 ffmpeg -h帮助的基本信息ffmpeg -h long帮助的高级信息ffmpeg -h full帮助的全部信息 ffmpeg的命令使用方式:ffmpeg [options] [[infile options] -i infile] [[outfile options] outfile] 二:将帮助文档输出到文件 …...

回归预测 | Matlab实现SO-CNN-SVM蛇群算法优化卷积神经网络-支持向量机的多输入单输出回归预测
Matlab实现SO-CNN-SVM蛇群算法优化卷积神经网络-支持向量机的多输入单输出回归预测 目录 Matlab实现SO-CNN-SVM蛇群算法优化卷积神经网络-支持向量机的多输入单输出回归预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.SO-CNN-SVM蛇群算法优化卷积神经网络-支持向量…...
【原创】java+swing+mysql校园共享单车管理系统设计与实现
摘要: 校园共享单车作为一种绿色、便捷的出行方式,在校园内得到了广泛的应用。然而,随着单车数量的增加,管理难度也不断加大。如何提高单车的利用率和管理效率,成为校园共享单车发展面临的重要问题。本文针对这一问题…...
(自适应手机端)响应式新闻博客知识类pbootcms网站模板 自媒体运营博客网站源码下载
(自适应手机端)响应式新闻博客知识类pbootcms网站模板 自媒体运营博客网站源码下载 带后台系统PbootCMS内核开发的网站模板,该模板适用于新闻博客网站、自媒体运营网站等企业,当然其他行业也可以做,只需要把文字图片换成其他行业的即可&#…...
SystemC入门完整编写示例:全加器测试平台
导读: 本文将完整演示基于systemC编写一个全加器的测试平台。具体内容包括:激励平台,监控平台,待测单元的编写,波形文件读取。 1,main函数模块 搭建一个测试平台主要由:Driver, Monitor, DUT(design under …...

动手学深度学习:2.线性回归pytorch实现
动手学深度学习:2.线性回归pytorch实现 1.手动构造数据集2.小批量读取数据集3.定义模型和损失函数4.初始化模型参数5.小批量随机梯度下降优化算法6.训练完整代码Q&A 1.手动构造数据集 import torch from torch.utils import data from d2l import torch as d2l…...

重要的linux指令
系统管理命令 切换用户 su 用户名管理员身份运行 sudo 命令实时显示进程信息(linux下任务管理器) top查看进程信息(ps) ps -efps -ef | grep 进程名 ps -aux | grep 进程名参数说明e 显示所有进程f 全格式a 显示所有程序u 以用户为主的格式来显示程序状况x 显示无控制终端…...

delphi7安装并使用皮肤控件
1、下载控件 我已经上传到云盘,存储位置 2、下载后并解压。 3、打开dephi7,File-Open,打开路径D:\LC\Desktop\vclskin2_XiaZaiBa\d7, 然后将 D:\LC\Desktop\vclskin2_XiaZaiBa\d7文件夹中所有后缀.dcu的文件复制粘贴到delphi安装路…...

安徽省黄山景区免9天门票为哪般?
今日浑浑噩噩地睡了大半天,强撑起身子写网文......可是,题材不好选,本“人民体验官”只得推广人民日报官方微博文化产品《这两个月“黄山每周三免门票”》。 图:来源“人民体验官”推广平台 因年事渐高,又有未愈的呼吸…...

C语言数组内存布局解析:从连续存储到性能优化实践
1. 项目概述:从内存视角重新认识C语言数组很多C语言初学者,包括一些已经工作一两年的朋友,对数组的理解可能还停留在“一组连续的同类型变量”这个层面。这没错,但如果你只看到这一层,写代码时就容易踩坑,尤…...

B站视频转文字终极指南:如何用AI工具3步搞定视频内容整理
B站视频转文字终极指南:如何用AI工具3步搞定视频内容整理 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 你是否曾为了一段精彩的B站课程内容反复…...

C语言-函数的调用
目录: 一、函数名作为函数的输入参数 二、回调函数 1、回调函数的引入 2、回调与普通函数的调用 3、回调函数的作用 4、回调函数的程序编写 一、函数名作为函数的输入参数 函数参数传递分为两种,一种是值传递,一种是地址传递。一般我们…...

通俗易懂的C++前缀和与差分算法图文示例详解
1、前缀和 前缀和是指某序列的前n项和,可以把它理解为数学上的数列的前n项和,而差分可以看成前缀和的逆运算。合理的使用前缀和与差分,可以将某些复杂的问题简单化。 2、前缀和算法有什么好处? 先来了解这样一个问题:…...

抖音批量下载神器:一键保存多个创作者的所有视频作品
抖音批量下载神器:一键保存多个创作者的所有视频作品 【免费下载链接】douyinhelper 抖音批量下载助手 项目地址: https://gitcode.com/gh_mirrors/do/douyinhelper 在当前短视频内容爆炸的时代,抖音汇聚了无数创意视频和优质内容。无论是学习舞蹈…...

如何彻底解决C盘空间不足问题:Windows Cleaner开源工具终极指南
如何彻底解决C盘空间不足问题:Windows Cleaner开源工具终极指南 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否曾因C盘爆红而束手无策…...

监控页面明明越来越多,为什么值班时还是看不清问题?
很多团队把监控系统搭起来以后,都会经历一个很典型的落差。 平时看,采集对象越来越全,图表越来越多,主机、数据库、中间件、网络也都接进来了;可一到值班现场,业务一说“接口变慢了”,排障同学打…...
从NeoPixel到CircuitPython:打造智能LED眼镜的完整硬件与软件实践
1. 项目概述 如果你对可穿戴电子设备、酷炫的LED光效以及用代码创造物理交互感兴趣,那么这个项目绝对能让你兴奋起来。今天要分享的,是如何亲手制作一副灵感来源于电子音乐人REZZ标志性风格的NeoPixel LED眼镜。这不仅仅是一个简单的焊接和组装教程&…...

Hi3516DV300鸿蒙时钟应用开发:从环境搭建到驱动调试全流程
1. 项目概述:从零到一,在Hi3516DV300上跑通一个鸿蒙时钟最近在捣鼓OpenHarmony,手头正好有一块海思的Hi3516DV300开发板。这块板子性能不错,带屏显,很适合做点有意思的应用。我琢磨着,与其跑个现成的Demo&a…...
)
STM32F429三重ADC+DMA实战:从CubeMX配置到7.2MHz采样率代码调试全流程(避坑指南)
STM32F429三重ADCDMA极限采样实战:从CubeMX配置到7.2MHz数据采集全解析 在工业测量、医疗设备或高频信号分析领域,对高速数据采集的需求日益增长。当常规的单ADC方案无法满足采样率要求时,STM32F429的三重ADC交替采样模式配合DMA传输…...