数据挖掘题目:根据规则模板和信息表找出R中的所有强关联规则,基于信息增益、利用判定树进行归纳分类,计算信息熵的代码
一、(30分)设最小支持度阈值为0.2500, 最小置信度为0.6500。对于下面的规则模板和信息表找出R中的所有强关联规则:
S∈R,P(S,x )∧ Q(S,y )==> Gpa(S,w ) [ s, c ]
其中,P,Q ∈{ Major, Status ,Age }.
| Major | Status | Age | Gpa | Count |
|---|---|---|---|---|
| Arts | Graduate | Old | Good | 50 |
| Arts | Graduate | Old | Excellent | 150 |
| Arts | Undergraduate | Young | Good | 150 |
| Appl_ | science | Undergraduate | Young | Excellent |
| Science | Undergraduate | Young | Good | 100 |
解答:
样本总数为500,最小支持数为500*0.25 = 125。
在Gpa取不同值的情形下,分别讨论。
(1)Gpa = Good,
| Major | Status | Age | Count |
|---|---|---|---|
| Arts | Graduate | Old | 50 |
| Arts | Undergraduate | Young | 150 |
| Science | Undergraduate | Young | 100 |
频繁1项集L1 = {Major= Arts:200; Status=Undergraduate: 250; Age = Young:250} -----10分
频繁2项集的待选集C2={Major= Arts,Status= Undergraduate:150; Major= Arts,Age=Young:150;Status=Undergraduate, Age=Young:250 }
频繁2项集L2=C2
(2) Gpa = Excellent
| Major | Status | Age | Count |
|---|---|---|---|
| Arts | Graduate | Old | 150 |
| Appl_science | Undergraduate | Young | 50 |
频繁1项集L1 = {Major= Arts:150; Status=Graduate: 150; Age = Old:250}
频繁2项集的待选集C2={Major= Arts,Status= Graduate:150; Major= Arts,Age=Old:150;Status=Graduate, Age=Old:150 }
频繁2项集L2=C2
考察置信度:
Major(S,Arts)^Status(S,Undergraduate)=>Gpa(S,Good) [s=150/500=0.3000, c=150/150=1.0000]
Major(S, Arts)^Age(S,Young)=>Gpa(S, Good)[s=150/500=0.3000, c=150/150=1.0000]
Status(S,Undergraduate)^Age(S,Young)=>Gpa(S,Good) [s=250/500=0.5000, c=250/300=0.8333]
Major(S, Arts)^Status(S,Graduate)=>Gpa(S, Excellent)[s=150/500=0.3000, c=150/200=0.7500]
Major(S, Arts)^Age(S,Old)=>Gpa(S, Excellent)[s=150/500=0.3000, c=150/200=0.7500]
Status(S,Graduate)^Age(S,Old)=>Gpa(S,Excellent) [s=150/500=0.3000, c=150/200=0.7500]
因此,所有强关联规则是:
Major(S,Arts)^Status(S,Undergraduate)=>Gpa(S,Good) [s=150/500=0.3000, c=150/150=1.0000]
Major(S, Arts)^Age(S,Young)=>Gpa(S, Good)[s=150/500=0.3000, c=150/150=1.0000]
Status(S,Undergraduate)^Age(S,Young)=>Gpa(S,Good) [s=250/500=0.5000, c=250/300=0.8333]
Major(S, Arts)^Status(S,Graduate)=>Gpa(S, Excellent)[s=150/500=0.3000, c=150/200=0.7500]
Major(S, Arts)^Age(S,Old)=>Gpa(S, Excellent)[s=150/500=0.3000, c=150/200=0.7500]
Status(S,Graduate)^Age(S,Old)=>Gpa(S,Excellent) [s=150/500=0.3000, c=150/200=0.7500]
二、(30分)设类标号属性 Gpa 有两个不同的值( 即{ Good, Excellent } ), 基于信息增益,利用判定树进行归纳分类。
解答:
定义P: Gpa = Good
N: Gpa = Excellent
任何分割进行前,样本集的熵为:
| p | n | I(p,n) |
|---|---|---|
| 300 | 200 | 0.97095 |
I(p,n)=-0.6log2(0.6) –0.4log2(0.4)
= 0.97095
考虑按属性Major分割后的样本的熵
| Major | pi | ni | I(pi,ni) |
|---|---|---|---|
| Arts | 200 | 150 | 0.98523 |
| Appl_science | 0 | 50 | 0 |
| Science | 100 | 0 | 0 |
E(Major) = 350/500*0.98523 = 0.68966
I(p,n)=-(4/7)log2(4/7) –(3/7)log2(3/7) =0.98523
考虑按属性Status分割后的样本的熵
| Status | pi | ni | I(pi,ni) |
|---|---|---|---|
| Graduate | 50 | 150 | 0.81128 |
| Undergraduate | 250 | 50 | 0.65002 |
E(Status) = 200/5000.81128+300/5000.65002 = 0.71452
考虑按属性Age分割后的样本的熵
| Age | pi | ni | I(pi,ni) |
|---|---|---|---|
| Old | 50 | 150 | 0.81128 |
| Young | 250 | 50 | 0.65002 |
E(Age) = E(Status) = 0.71452
各属性的信息增益如下:
Gain(Major) =0.97095-0.68966 = 0.28129
Gain(Status) =Gain(Age) =0.97095-0.71452 = 0.25643
比较后,由于Gain(Major)的值最大,按照最大信息增益原则,按照属性Major的不同取值进行第一次分割.
分割后,按照Major的不同取值,得到下面的3个表:
(1)Major = Arts
| Status | Age | Gpa | Count |
|---|---|---|---|
| Graduate | Old | Good | 50 |
| Graduate | Old | Excellent | 150 |
| Undergraduate | Young | Good | 150 |
考虑按属性Status分割后的样本的熵
| Status | pi | ni | I(pi,ni) |
|---|---|---|---|
| Graduate | 50 | 150 | 0.81128 |
| Undergraduate | 150 | 0 | 0 |
E(Status) = 200/350*0.81128= 0.46359
考虑按属性Age分割后的样本的熵
| Status | pi | ni | I(pi,ni) |
|---|---|---|---|
| Old | 50 | 150 | 0.81128 |
| Young | 150 | 0 | 0 |
E(Age) = E(Status)= 0.46359
由于E(Age) = E(Status),可按照属性Status的不同取值进行第二次分割。分割后,按照Status的不同取值,得到下面的2个表:
(1.1) Status =Graduate
| Age | Gpa | Count |
|---|---|---|
| Old | Good | 50 |
| Old | Excellent | 150 |
由于表中属性Age的取值没有变化,停止分割。按照多数投票原则,该分支可被判定为Gpa=Excellent。
(1.2)Status = Undergraduate
| Status | Age | Gpa | Count |
|---|---|---|---|
| Undergraduate | Young | Good | 150 |
在这种情形下,所有样本的Gpa属性值都相同.停止分割.
(2)Major= Appl_Science
| Status | Age | Gpa | Count |
|---|---|---|---|
| Undergraduate | Young | Excellent | 50 |
在这种情形下,所有样本的Gpa属性值都相同.停止分割.
(3)Major=Science
| Status | Age | Gpa | Count |
|---|---|---|---|
| Undergraduate | Young | Good | 100 |
在这种情形下,所有样本的Gpa属性值都相同.停止分割.
综合以上分析,有以下的判定树:
Major--------- Arts ----------Status-------Graduate ------Excellent
\ ______Undergraduate______Good
_______Appl_Science_______________________Excellent
__________Science______________________Good
小 tricks
计算信息熵的代码
import mathdef entropy(probabilities):total = sum(probabilities)probabilities= [p / total for p in probabilities]entropy = 0for p in probabilities:if p > 0:entropy -= p * math.log2(p)return entropyprobabilities = [100,100,150]#计算100 100 150的信息熵result = entropy(probabilities)
print("信息熵:", result)
相关文章:

数据挖掘题目:根据规则模板和信息表找出R中的所有强关联规则,基于信息增益、利用判定树进行归纳分类,计算信息熵的代码
一、(30分)设最小支持度阈值为0.2500, 最小置信度为0.6500。对于下面的规则模板和信息表找出R中的所有强关联规则: S∈R,P(S,x )∧ Q(S,y )> Gpa…...
Reshape.XL 1.2 for Excel插件 Crack
特征 插件 Reshape.XL 包括 130 个基本可组合功能。使用它们,您可以快速轻松地进行非常复杂的数据转换和处理。它们的架构和基本定义受到 SQL 和 R 语言的强烈启发。 到目前为止,类似的功能只能通过脚本语言供程序员使用。借助 Reshape.XL 插件…...

开发知识点-PHP从小白到拍簧片
从小白到拍簧片 位异或运算(^ )引用符号(&)strlen() 函数base64_encode预定义 $_POST 变量session_start($array);操作符php 命令set_time_limit(7200)isset()PHP 命名空间(namespace)new 实例化类extends 继承 一个类使用另一个类方法error_reporti…...
飞书开发学习笔记(二)-云文档简单开发练习
飞书开发学习笔记(二)-云文档简单开发练习 一.云文档飞书开发环境API 首先还是进入开放平台 飞书开放平台:https://open.feishu.cn/app?langzh-CN 云文档相关API都在“云文档”目录中,之下又有"云空间",“文档”,“电子表格”&a…...
+ Spring相关源码)
设计模式——命令模式(Command Pattern)+ Spring相关源码
文章目录 一、命令模式定义二、例子2.1 菜鸟教程例子2.1.1 定义命令类接口2.1.2 定义命令执行者2.1.3 被处理对象Stock。2.1.4 封装处理Stock的命令 2.2 JDK源码——Runnable2.2.1 命令接口2.2.2 命令处理者2.2.3 命令实现类 2.3 SpringMVC——Controller2.3.1 请求对象 handle…...

[开源]企业级在线办公系统,基于实时音视频完成在线视频会议功能
一、开源项目简介 企业级在线办公系统 本项目使用了SpringBootMybatisSpringMVC框架,技术功能点应用了WebSocket、Redis、Activiti7工作流引擎, 基于TRTC腾讯实时音视频完成在线视频会议功能。 二、开源协议 使用GPL-3.0开源协议 三、界面展示 部分…...

Scala语言用Selenium库写一个爬虫模版
首先,我将使用Scala编写一个使用Selenium库下载yuanfudao内容的下载器程序。 然后我们需要在项目的build.sbt文件中添加selenium的依赖项。以下是添加Selenium依赖项的代码: libraryDependencies "org.openqa.selenium" % "selenium-ja…...
ZZ038 物联网应用与服务赛题第I套
2023年全国职业院校技能大赛 中职组 物联网应用与服务 任 务 书 (I卷) 赛位号:______________ 竞赛须知 一、注意事项 1.检查硬件设备、电脑设备是否正常。检查竞赛所需的各项设备、软件和竞赛材料等; 2.竞赛任务中所使用的各类软件工…...
ClickHouse 学习之基础入门(一)
第 1 章 ClickHouse 入 门 ClickHouse 是俄罗斯的 Yandex 于 2016 年开源的列式存储数据库(DBMS),使用 C 语言编写,主要用于在线分析处理查询(OLAP),能够使用 SQL 查询实时生成分析数据报告。 …...

HttpClient基本使用
十二、HttpClient 12.1 介绍 HttpClient是Apache Jakarta Common 下的子项目,可以用来提供高效的、最新的、功能丰富的支持HTTP协议的客户端编程工具包,并且它支持HTTP协议最新的版本和建议。 HttpClient作用: 发送HTTP请求接收响应数据 …...
)
力扣:150. 逆波兰表达式求值(Python3)
题目: 给你一个字符串数组 tokens ,表示一个根据 逆波兰表示法 表示的算术表达式。 请你计算该表达式。返回一个表示表达式值的整数。 注意: 有效的算符为 、-、* 和 / 。每个操作数(运算对象)都可以是一个整数或者另一…...
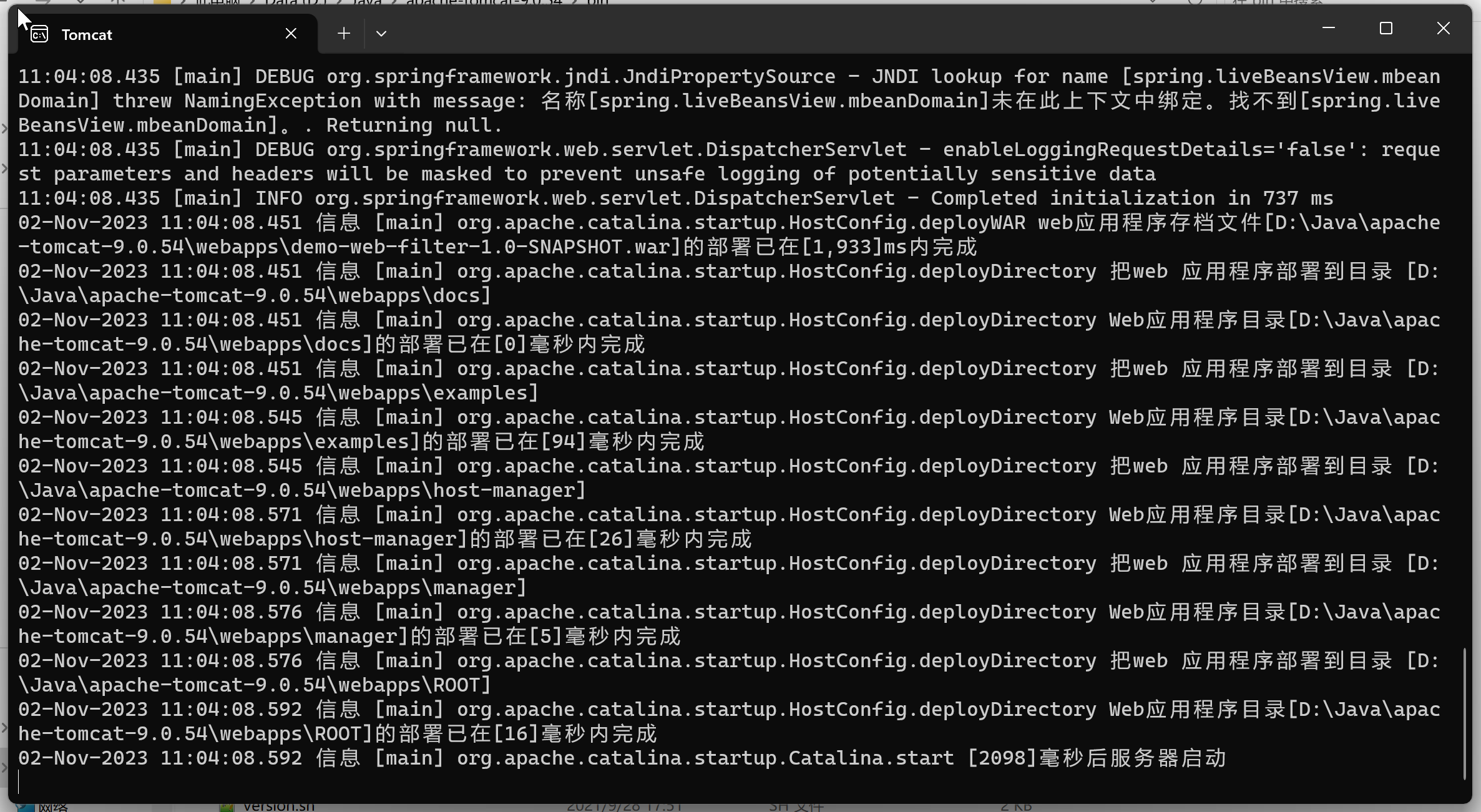
Tomcat运行日志乱码问题/项目用tomcat启动时窗口日志乱码
文章目录 一、问题描述:二、产生原因三、解决方法 一、问题描述: 项目在idea中运行时日志是正常的,用Tomcat启动时发现一大堆看不懂的文字,如 二、产生原因 产生乱码的根本原因就是编码和解码不一致,举个例子就是翻…...

Leetcode—199.二叉树的右视图【中等】
2023每日刷题(十九) Leetcode—199.二叉树的右视图 深度优先遍历实现代码 /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(…...

微信小程序如何跳转到外部小程序
要在微信小程序中跳转到外部小程序,您可以使用微信小程序提供的 wx.navigateToMiniProgram 方法。以下是实现步骤: 在需要跳转的页面或组件中,编写触发跳转的逻辑,例如点击按钮: 替换 外部小程序的AppID 和 外部小程序…...
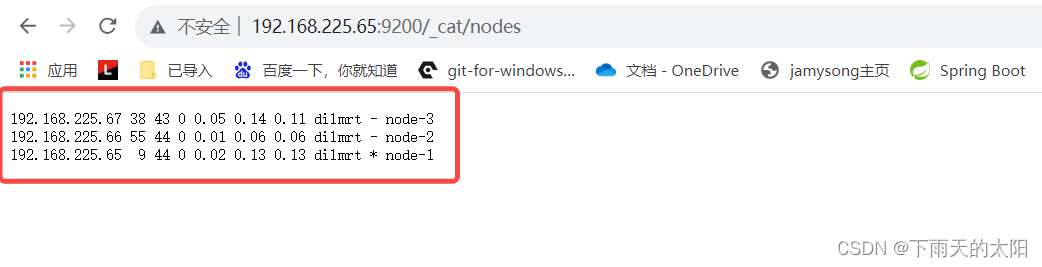
ElasticSearch集群环境搭建
1、准备三台服务器 这里准备三台服务器如下: IP地址主机名节点名192.168.225.65linux1node-1192.168.225.66linux2node-2192.168.225.67linux3node-3 2、准备elasticsearch安装环境 (1)编辑/etc/hosts(三台服务器都执行) vim /etc/hosts 添加如下内…...

[架构之路-250/创业之路-81]:目标系统 - 纵向分层 - 企业信息化的呈现形态:常见企业信息化软件系统 - 企业内的数据与数据库
目录 一、数据概述 1.1 数据 1.2 企业信息系统的数据 1.3 大数据 1.4 数据与程序的分离思想 1.5 数据与程序的分离做法 1.6 数据库的基本概念 1.7 企业数据来源 1.8 企业数据架构 二、常见的数据库类型 2.1 数据库分类 2.1 数据库类型 2.2 常见的数据库类型、应用…...

delaunay和voronoi图 人脸三角剖分
先获取人脸68个特征点坐标,其中使用了官方的预训练模型shape_predictor_68_face_landmarks.dat: import dlib import cv2predictor_path "shape_predictor_68_face_landmarks.dat" png_path "face.jpg"txt_path "points.tx…...
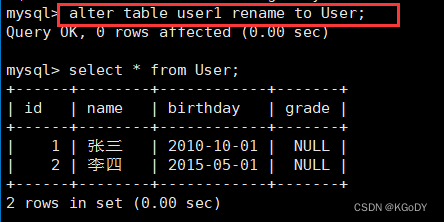
MySQL数据库之表的增删查改
目录 表的操作1.创建表创建表案例 2.查看表结构3.修改表4.删除表 表的操作 1.创建表 语法: CREATE TABLE table_name (field1 datatype,field2 datatype,field3 datatype ) character set 字符集 collate 校验规则 engine 存储引擎;说明: field 表示列…...
Fast R-CNN)
(论文阅读11/100)Fast R-CNN
文献阅读笔记 简介 题目 Fast R-CNN 作者 Ross Girshick 原文链接 https://arxiv.org/pdf/1504.08083.pdf 目标检测系列——开山之作RCNN原理详解-CSDN博客 Fast R-CNN讲解_fast rcnn-CSDN博客 Rcnn、FastRcnn、FasterRcnn理论合集_rcnn fastrcnn fasterrcnn_沫念的博客…...
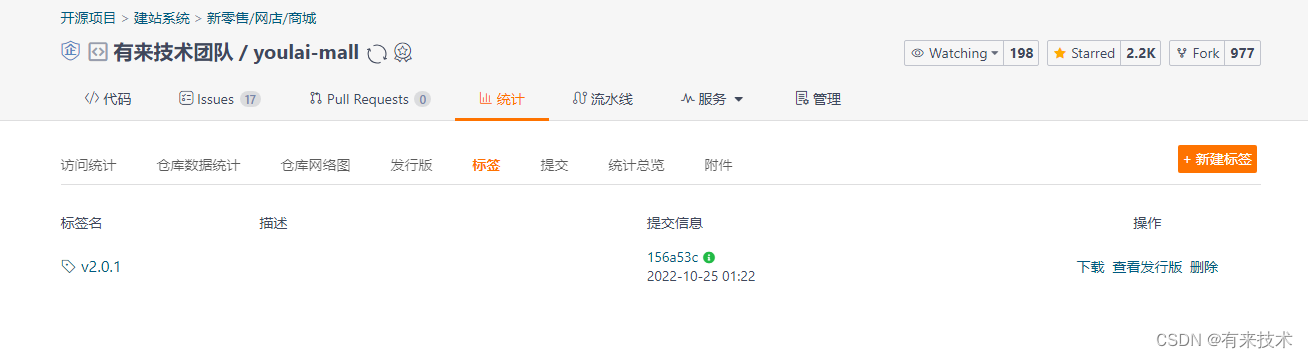
Git 标签(Tag)实战:打标签和删除标签的步骤指南
目录 前言使用 Git 打本地和远程标签(Tag)删除本地和远程 Git 标签(Tag)开源项目标签(Tag)实战打标签删除标签 结语开源微服务商城项目前后端分离项目 前言 在开源项目中,版本控制是至关重要的…...

番茄小说下载器终极指南:三步打造你的私人数字图书馆
番茄小说下载器终极指南:三步打造你的私人数字图书馆 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾在深夜追更小说时突然断网?或者想在地铁上继续阅读却发…...

Spring AI生产环境 Checklist:20条黄金法则
前言 本文总结Spring AI生产环境部署的最佳实践,涵盖配置、安全、监控、性能四大维度,每条都是实战经验。 一、配置管理(5条) 1. API Key必须通过环境变量注入 # ✅ 推荐 spring:ai:openai:api-key: ${OPENAI_API_KEY}# ❌ 禁…...

2026年房建工程管理软件选购指南:7款主流工具横向对比,助你找到最适合的那一款
2025年,房建行业整体营收下滑5.62%,净利润降幅超20%,利润空间持续收窄。越来越多施工企业意识到,精细化管理是穿越周期的唯一路径。然而,数据孤岛、多分包协同混乱、合规要求升级,让选对一款工程管理软件变…...

免费解密网易云音乐NCM格式:ncmdumpGUI完整使用指南
免费解密网易云音乐NCM格式:ncmdumpGUI完整使用指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否在网易云音乐下载了喜欢的歌曲ÿ…...

如何查阅与分析Taotoken平台提供的详细用量账单
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何查阅与分析Taotoken平台提供的详细用量账单 对于使用大模型API的开发者与团队而言,清晰、准确地掌握资源消耗与成本…...

RT-DETRv2训练自定义数据集的排坑全记录
RT-DETRv2训练自定义数据集的排坑全记录 最近在使用lyuwenyu/RT-DETR的PyTorch版本训练自定义缺陷检测数据集,从启动报错到成功训练,踩了不少典型的“新手坑”,这里把完整的排坑过程和解决方案整理出来,帮大家一次性避坑ÿ…...

你的Nmap脚本库该更新了!手把手教你管理、调试与编写自定义NSE脚本
从使用者到创造者:Nmap脚本引擎(NSE)深度管理指南 在渗透测试和安全评估领域,Nmap早已超越了简单的端口扫描工具定位,其强大的脚本引擎(NSE)使其成为网络安全专业人员的瑞士军刀。但大多数用户仅停留在基础脚本调用层面,未能充分释…...

英语发音宝库:11万+单词MP3音频一键获取指南
英语发音宝库:11万单词MP3音频一键获取指南 【免费下载链接】English-words-pronunciation-mp3-audio-download Download the pronunciation mp3 audio for 119,376 unique English words/terms 项目地址: https://gitcode.com/gh_mirrors/en/English-words-pronu…...

ETS2LA:卡车模拟游戏中的自动化路径跟随系统如何让你轻松驾驭长途运输?
ETS2LA:卡车模拟游戏中的自动化路径跟随系统如何让你轻松驾驭长途运输? 【免费下载链接】Euro-Truck-Simulator-2-Lane-Assist Plugin based interface program for ETS2/ATS. 项目地址: https://gitcode.com/gh_mirrors/eur/Euro-Truck-Simulator-2-L…...

Steam创意工坊下载终极指南:无需Steam账号也能畅玩海量模组
Steam创意工坊下载终极指南:无需Steam账号也能畅玩海量模组 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL WorkshopDL是一款跨平台Steam创意工坊下载工具ÿ…...