ClickHouse 学习之基础入门(一)
第 1 章 ClickHouse 入 门
ClickHouse 是俄罗斯的 Yandex 于 2016 年开源的列式存储数据库(DBMS),使用 C++ 语言编写,主要用于在线分析处理查询(OLAP),能够使用 SQL 查询实时生成分析数据报告。
1.1 ClickHouse 的特点
1.1.1 列式存储
以下面的表为例:
| Id | Name | Age |
| 1 | 张三 | 18 |
| 2 | 李四 | 22 |
| 3 | 王五 | 34 |
1)采用行式存储时,数据在磁盘上的组织结构为:

好处是想查某个人所有的属性时,可以通过一次磁盘查找加顺序读取就可以。但是当想查所有人的年龄时,需要不停的查找,或者全表扫描才行,遍历的很多数据都是不需要的。
2)采用列式存储时,数据在磁盘上的组织结构为:

这时想查所有人的年龄只需把年龄那一列拿出来就可以了。
3)列式储存的好处:
- 对于列的聚合,计数,求和等统计操作原因优于行式存储。
- 由于某一列的数据类型都是相同的,针对于数据存储更容易进行数据压缩,每一列
选择更优的数据压缩算法,大大提高了数据的压缩比重。
- 由于数据压缩比更好,一方面节省了磁盘空间,另一方面对于 cache 也有了更大的发挥空间。
1.1.2 DBMS 的功能
几乎覆盖了标准SQL 的大部分语法,包括 DDL 和 DML,以及配套的各种函数,用户管理及权限管理,数据的备份与恢复。
1.1.3 多样化引擎
ClickHouse 和 MySQL 类似,把表级的存储引擎插件化,根据表的不同需求可以设定不同的存储引擎。目前包括合并树、日志、接口和其他四大类 20 多种引擎。
1.1.4 高吞吐写入能力
ClickHouse 采用类LSM Tree 的结构,数据写入后定期在后台Compaction。通过类LSM tree 的结构,ClickHouse 在数据导入时全部是顺序 append 写,写入后数据段不可更改,在后台compaction 时也是多个段merge sort 后顺序写回磁盘。顺序写的特性,充分利用了磁盘的吞吐能力,即便在 HDD 上也有着优异的写入性能。
官方公开 benchmark 测试显示能够达到 50MB-200MB/s 的写入吞吐能力,按照每行100Byte 估算,大约相当于 50W-200W 条/s 的写入速度。
1.1.5 数据分区与线程级并行
ClickHouse 将数据划分为多个 partition,每个 partition 再进一步划分为多个 index granularity(索引粒度),然后通过多个CPU 核心分别处理其中的一部分来实现并行数据处理。在这种设计下,单条 Query 就能利用整机所有CPU。极致的并行处理能力,极大的降低了查询延时。
所以,ClickHouse 即使对于大量数据的查询也能够化整为零平行处理。但是有一个弊端就是对于单条查询使用多 cpu,就不利于同时并发多条查询。所以对于高 qps 的查询业务, ClickHouse 并不是强项。
1.1.6 性能对比
某网站精华帖,中对几款数据库做了性能对比。
1)单表查询

2)关联查询

结论: ClickHouse 像很多 OLAP 数据库一样,单表查询速度优于关联查询,而且 ClickHouse的两者差距更为明显。
第 2 章 ClickHouse 的安装
2.1 准备工作
2.1.1 确定防火墙处于关闭状态
# 查看防火墙状态
systemctl status firewalld
# 关闭防火墙
systemctl stop firewalld
提示:生产环境不建议关闭防火墙
2.1.2 CentOS 取消打开文件数限制
1)查看文件数限制
ulimit -a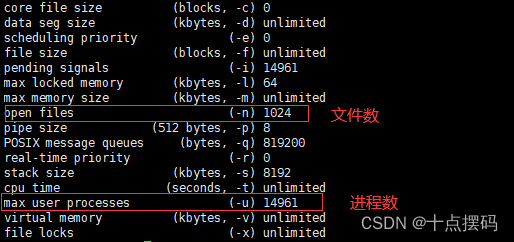
2)在服务器 vim etc/security/limits.conf 文件的末尾加入以下内容
# soft指当前数值,hard指最大数值
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
3)在服务器 vim /etc/security/limits.d/20-nproc.conf 文件的末尾加入以下内容
* soft nproc 131072
* hard nproc 1310724)在服务器 vim /etc/security/limits.d/20-nofile.conf 文件的末尾加入以下内容
* soft nofile 65536
* hard nofile 655365)重新登录即可生效
2.1.3 安装依赖
# 在联网或者有yum源的情况下安装依赖
sudo yum install -y libtool
sudo yum install -y *unixODBC*2.1.4 CentOS 取消 SELINUX
1)修改 vim /etc/selinux/config 中的 SELINUX=disabled
SELINUX=disabled2)临时关闭 SELINUX
# 查看SELINUX状态
getenforce
# 关闭SELINUX
setenforce 02.2 单机安装
官方网址:https://clickhouse.com/
下载地址:https://packages.clickhouse.com/rpm/stable/
2.2.1 创建 clickhouse 目录
在服务器 /opt/software 下创建 clickhouse 目录
cd /opt/software/
mkdir clickhouse2.2.2 上传安装文件
将 ClickHouse 安装文件上传到 clickhouse 目录下

2.2.3 安装
# 安装
sudo rpm -ivh *.rpm
# 查看安装情况
sudo rpm -qa|grep clickhouse2.2.4 修改配置文件
sudo vim /etc/clickhouse-server/config.xml1)把 <listen_host>::</listen_host> 的注释打开,这样的话才能让 ClickHouse 被除本机以外的服务器访问

2)默认的路径配置
在这个文件中,有 ClickHouse 的一些默认路径配置比较重要的,比如数据文件存储路径、日志文件存储路径
数据文件路径:<path>/var/lib/clickhouse/</path>
日志文件路径:<log>/var/log/clickhouse-server/clickhouse-server.log</log>
注意:建议改成服务器磁盘比较充足的磁盘路径
3)修改时区
<timezone>Asia/Shanghai</timezone>
4)添加数据压缩算法
ClickHouse支持多种压缩算法,包括LZ4、LZ4HC、ZSTD、Brotli等。其中,LZ4是ClickHouse默认的压缩算法。
- LZ4:LZ4是一种无损压缩算法,它的压缩速度非常快,但压缩比相对较低。LZ4的压缩原理是将重复的数据块替换为一个标记和重复次数,从而达到压缩的效果。
- LZ4HC:LZ4HC是LZ4的一种高压缩比版本,它的压缩速度相对较慢,但压缩比相对较高。LZ4HC的压缩原理是通过哈希表来查找重复的数据块,从而达到高压缩比的效果。
- ZSTD:ZSTD是一种高压缩比的压缩算法,它的压缩速度相对较慢,但压缩比相对较高。ZSTD的压缩原理是通过字典来查找重复的数据块,从而达到高压缩比的效果。
- Brotli:Brotli是一种高压缩比的压缩算法,它的压缩速度相对较慢,但压缩比相对较高。Brotli的压缩原理是通过有限状态机来查找重复的数据块,从而达到高压缩比的效果。
<compression><case><min_part_size>10000000000</min_part_size><min_part_size_ratio>0.01</min_part_size_ratio><method>lz4</method></case></compression>

2.2.5 启动
# 启动
sudo systemctl start clickhouse-server
# 查看启动的进程
ps -ef|grep clickhouse2.2.6 设置开机自起
# 开机自起,可选
sudo systemctl disable clickhouse-server2.2.7 使用 client 连接 server
clickhouse-client -m [--password]
-m :可以在命令窗口输入多行命令
第 3 章 数据类型
3.1 整形
固定长度的整型,包括有符号整型或无符号整型。
整型范围(-2n-1~2n-1-1):
Int8 - [-128 : 127]
Int16 - [-32768 : 32767]
Int32 - [-2147483648 : 2147483647]
Int64 - [-9223372036854775808 : 9223372036854775807]
无符号整型范围(0~2n-1):
UInt8 - [0 : 255]
UInt16 - [0 : 65535]
UInt32 - [0 : 4294967295]
UInt64 - [0 : 18446744073709551615]
使用场景: 个数、数量、也可以存储型 id。
3.2 浮点型
Float32 - float
Float64 – double

注意:建议尽可能以整数形式存储数据。例如,将固定精度的数字转换为整数值,如时间用毫秒为单位表示,因为浮点型进行计算时可能引起四舍五入的误差。
使用场景:一般数据值比较小,不涉及大量的统计计算,精度要求不高的时候。比如保存商品的重量。
3.3 布尔型
没有单独的类型来存储布尔值。可以使用 UInt8 类型,取值限制为 0 或 1。
3.4 Decimal 型
有符号的浮点数,可在加、减和乘法运算过程中保持精度。对于除法,最低有效数字会被丢弃(不舍入)。
有三种声明:
- Decimal32(s),相当于 Decimal(9-s, s),有效位数为 1~9
- Decimal64(s),相当于 Decimal(18-s, s),有效位数为 1~18
- Decimal128(s),相当于 Decimal(38-s, s),有效位数为 1~38
s 标识小数位
使用场景: 一般金额字段、汇率、利率等字段为了保证小数点精度,都使用 Decimal
进行存储。
3.5 字符串
1)String:字符串可以任意长度的。它可以包含任意的字节集,包含空字节。
2)FixedString(N):固定长度 N 的字符串,N 必须是严格的正自然数。当服务端读取长度小于 N 的字符串时候,通过在字符串末尾添加空字节来达到 N 字节长度。 当服务端读取长度大于 N 的字符串时候,将返回错误消息。与 String 相比,极少会使用 FixedString,因为使用起来不是很方便。
使用场景:名称、文字描述、字符型编码。 固定长度的可以保存一些定长的内容,比
如一些编码,性别等但是考虑到一定的变化风险,带来收益不够明显,所以定长字符串使用意义有限。
3.6 枚举类型
包括 Enum8 和 Enum16 类型。Enum 保存 ‘string’= integer 的对应关系。
Enum8 用 ‘String’= Int8 对描述。
Enum16 用 ‘String’= Int16 对描述。
1)用法演示
创建一个带有一个枚举 Enum8(‘hello’ = 1, ‘world’ = 2) 类型的列
CREATE TABLE t_enum
(`x` Enum8('hello' = 1, 'world' = 2)
)
ENGINE = TinyLog;2)这个 x 列只能存储类型定义中列出的值:’hello’或’world’
INSERT INTO t_enum VALUES ('hello'), ('world'), ('hello');

3)如果尝试保存任何其他值,ClickHouse 抛出异常
INSERT INTO t_enum VALUES('a');
4)如果需要看到对应行的数值,则必须将 Enum 值转换为整数类型
SELECT CAST(x, 'Int8') FROM t_enum;

使用场景:对一些状态、类型的字段算是一种空间优化,也算是一种数据约束。但是实际使用中往往因为一些数据内容的变化增加一定的维护成本,甚至是数据丢失问题。所以谨慎使用
3.7 时间类型
目前 ClickHouse 有三种时间类型
- Date 接受年-月-日的字符串比如 ‘2019-12-16’
- Datetime 接受年-月-日 时:分:秒的字符串比如 ‘2019-12-16 20:50:10’
- Datetime64 接受年-月-日 时:分:秒.亚秒的字符串比如 ‘2019-12-16 20:50:10.66’
日期类型,用两个字节存储,表示从 1970-01-01 (无符号) 到当前的日期值。
3.8 数组
Array(T):由 T 类型元素组成的数组。
T 可以是任意类型,包含数组类型。但不推荐使用多维数组,ClickHouse 对多维数组的支持有限。例如,不能在 MergeTree 表中存储多维数组。
1)创建数组方式 1,使用 array 函数
 2)创建数组方式 2:使用方括号
2)创建数组方式 2:使用方括号

第 4 章 表引擎
4.1 表引擎的使用
表引擎是 ClickHouse 的一大特色。可以说,表引擎决定了如何存储表的数据。包括:
- 数据的存储方式和位置,写到哪里以及从哪里读取数据。
- 支持哪些查询以及如何支持。
- 并发数据访问。
- 索引的使用(如果存在)。
- 是否可以执行多线程请求。
- 数据复制参数。
表引擎的使用方式就是必须显式在创建表时定义该表使用的引擎,以及引擎使用的相关参数。
特别注意:引擎的名称大小写敏感
4.2 TinyLog
以列文件的形式保存在磁盘上,不支持索引,没有并发控制。一般保存少量数据的小表,生产环境上作用有限。
CREATE TABLE t_tinylog
(`id` String,`name` String
)
ENGINE = TinyLog;4.3 Memory
内存引擎,数据以未压缩的原始形式直接保存在内存当中,服务器重启数据就会消失。读写操作不会相互阻塞,不支持索引。简单查询下有非常非常高的性能表现(超过 10G/s)。
一般用到它的地方不多,除了用来测试,就是在需要非常高的性能,同时数据量又不太 大(上限大概 1 亿行)的场景。
4.4 MergeTree
ClickHouse 中最强大的表引擎当属 MergeTree(合并树)引擎及该系列(*MergeTree)中的其他引擎,支持索引和分区,地位可以相当于 innodb 之于 Mysql。
1)建表语句
CREATE TABLE t_order_mt
(`id` UInt32,`sku_id` String,`total_amount` Decimal(16, 2),`create_time` Datetime
)
ENGINE = MergeTree
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id);2)插入数据
INSERT INTO t_order_mt VALUES
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),
(102,'sku_002',600.00,'2020-06-02 12:00:00');MergeTree 其实还有很多参数(绝大多数用默认值即可),但是这三个参数是更加重要的,也涉及了关于 MergeTree 的很多概念。
4.4.1 partition by 分区(可选)
1)作用
分区的目的主要是降低扫描的范围,优化查询速度
2)如果不填
只会使用一个分区。
3)分区目录
MergeTree 是以列文件+索引文件+表定义文件组成的,但是如果设定了分区那么这些文件就会保存到不同的分区目录中。
分区目录文件命名规则:PartitionId_MinBlockNum_MaxBlockNum_Level(分区值_最小分区_最大分区块编号_合并层级)
(1)PartitionId:
- 数据分区 ID 生成规则
- 数据分区规则由分区 ID 决定,分区ID由 PARTITION BY 分区键决定。根据分区键字段类型,ID生成规则可以分为:
a.未定义分区键:没有定义 PARTITION BY ,默认生成一个目录名为 all 的数据分区,所有数据均存放在 all 目录下。
b.整型分区键:分区键为整型,那么直接用该整型值的字符串形式作为分区ID。
c.日期类分区键:分区键为日期类型,或者可以转化成日期类型。
d.其他类型分区键:String、Float 类型等,通过128位的 Hash 算法取其 Hash 值作为分区ID。
(2)MinBlockNum:最小分区块编号,自增类型,从1开始向上递增。每产生一个新的目录分区就向上递增一个数字。
(3)MaxBlockNum:最大分区块编号,新创建的分区 MinBlockNum 等于 MaxBlockNum 的编号。
(4)Level:合并的层级,被合并的次数。合并次数越多,层级值越大。
4)并行
分区后,面对涉及跨分区的查询统计,ClickHouse 会以分区为单位并行处理。
5)数据写入与分区合并
任何一个批次的数据写入都会产生一个临时分区,不会纳入任何一个已有的分区。写入后的某个时刻(大概 10-15 分钟后),ClickHouse 会自动执行合并操作(等不及也可以手动通过 optimize 执行),把临时分区的数据,合并到已有分区中。
OPTIMIZE TABLE xxxx FINAL;
# 只针对某一个分区做合并操作
OPTIMIZE TABLE xxxx PARTITION 'yyyy' FINAL;6)例如
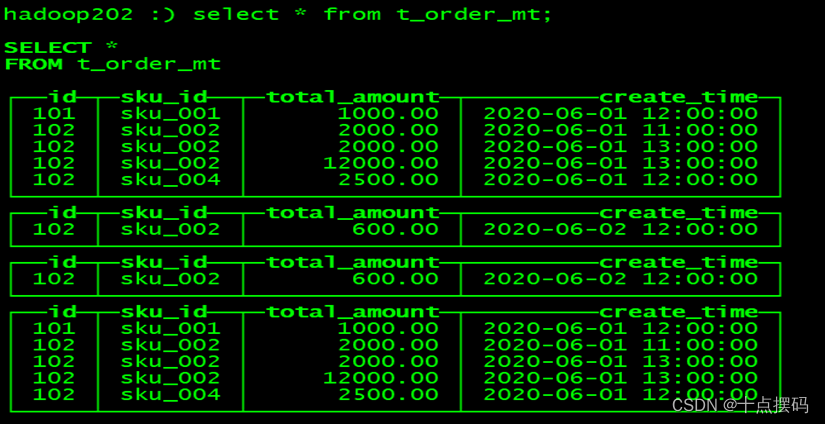
再次执行上面的插入操作
insert into t_order_mt values
(101,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(102,'sku_002',2000.00,'2020-06-01 11:00:00'),
(102,'sku_004',2500.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 13:00:00'),
(102,'sku_002',12000.00,'2020-06-01 13:00:00'),查看数据并没有纳入任何分区
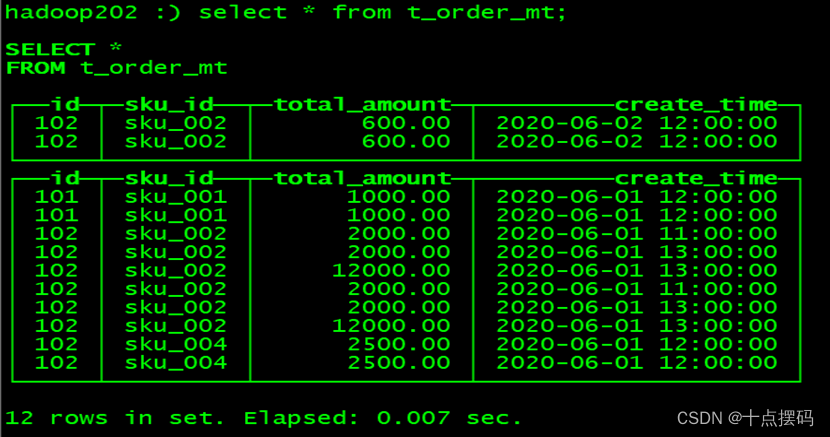
手动 optimize 之后:optimize table t_order_mt final,在查询。
4.4.2 primary key 主键(可选)
ClickHouse 中的主键,和其他数据库不太一样,它只提供了数据的一级索引,但是却不是唯一约束。这就意味着是可以存在相同 primary key 的数据的。
主键的设定主要依据是查询语句中的 where 条件。
根据条件通过对主键进行某种形式的二分查找,能够定位到对应的 index granularity,避免了全表扫描。
index granularity:直接翻译的话就是索引粒度,指在稀疏索引中两个相邻索引对应数据的间隔。ClickHouse 中的 MergeTree 默认是 8192。官方不建议修改这个值,除非该列存在大量重复值,比如在一个分区中几万行才有一个不同数据。
稀疏索引:

稀疏索引的好处就是可以用很少的索引数据,定位更多的数据,代价就是只能定位到索引粒度的第一行,然后再进行进行一点扫描。
4.4.3 order by(必选)
order by 设定了分区内的数据按照哪些字段顺序进行有序保存。
order by 是 MergeTree 中唯一一个必填项,甚至比 primary key 还重要,因为当用户不设置主键的情况,很多处理会依照 order by 的字段进行处理。
要求:主键必须是 order by 字段的前缀字段。
比如:order by 字段是 (id, sku_id) 那么主键必须是 id 或者(id, sku_id)
4.4.4 二级索引
目前在 ClickHouse 的官网上二级索引的功能在 v20.1.2.4 之前是被标注为实验性的,在这个版本之后默认是开启的。
1)老版本使用二级索引前需要增加设置
是否允许使用实验性的二级索引(v20.1.2.4 开始,这个参数已被删除,默认开启)
set allow_experimental_data_skipping_indices=1;2)创建测试表
CREATE TABLE t_order_mt2
(`id` UInt32,`sku_id` String,`total_amount` Decimal(16, 2),`create_time` Datetime,INDEX a total_amount TYPE minmax GRANULARITY 5
)
ENGINE = MergeTree
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id);其中GRANULARITY N 是设定二级索引对于一级索引粒度的粒度。
3)插入数据
INSERT INTO t_order_mt2 VALUES
(101, 'sku_001', 1000.00, '2020-06-01 12:00:00') ,
(102, 'sku_002', 2000.00, '2020-06-01 11:00:00'),
(102, 'sku_004', 2500.00, '2020-06-01 12:00:00'),
(102, 'sku_002', 2000.00, '2020-06-01 13:00:00'),
(102, 'sku_002', 12000.00, '2020-06-01 13:00:00'),
(102, 'sku_002', 600.00, '2020-06-02 12:00:00');4)对比效果
使用下面语句进行测试,可以看出二级索引能够为非主键字段的查询发挥作用。
clickhouse-client [--password] --send_logs_level=trace <<< 'select * from t_order_mt2 where total_amount > toDecimal32(900., 2)';4.4.5 数据 TTL
TTL 即 Time To Live,MergeTree 提供了可以管理数据表或者列的生命周期的功能。
1)列级别 TTL
(1)创建测试表
CREATE TABLE t_order_mt3
(`id` UInt32,`sku_id` String,`total_amount` Decimal(16, 2) TTL create_time + INTERVAL 10 SECOND,`create_time` Datetime
)
ENGINE = MergeTree
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id);(2)插入数据
INSERT INTO t_order_mt3 VALUES
(106, 'sku_001', 1000.00, NOW()),
(107, 'sku_002', 2000.00, NOW()),
(110, 'sku_003', 600.00, NOW() + INTERVAL 10 SECOND);(3)手动合并,查看效果,到期后,指定的字段数据将变为默认值

2)表级 TTL
下面的这条语句是数据会在 create_time 之后 10 秒丢失。
ALTER TABLE t_order_mt3 MODIFY TTL create_time + INTERVAL 10 SECOND;涉及判断的字段必须是 Date 或者 Datetime 类型,推荐使用分区的日期字段。
能够使用的时间周期:
- SECOND
- MINUTE
- HOUR
- DAY
- WEEK
- MONTH
- QUARTER
- YEAR
4.5 ReplacingMergeTree
ReplacingMergeTree 是 MergeTree 的一个变种,它存储特性完全继承 MergeTree,只是多了一个去重的功能。 尽管 MergeTree 可以设置主键,但是 primary key 其实没有唯一约束的功能。如果你想处理掉重复的数据,可以借助这个 ReplacingMergeTree。
4.5.1 去重时机
数据的去重只会在合并的过程中出现。合并会在未知的时间在后台进行,所以你无法预先作出计划。有一些数据可能仍未被处理。
4.5.2 去重范围
如果表经过了分区,去重只会在分区内部进行去重,不能执行跨分区的去重。
所以 ReplacingMergeTree 能力有限, ReplacingMergeTree 适用于在后台清除重复的数据以节省空间,但是它不保证没有重复的数据出现。
4.5.3 案例演示
1)创建表
CREATE TABLE t_order_rmt
(`id` UInt32,`sku_id` String,`total_amount` Decimal(16, 2),`create_time` Datetime
)
ENGINE = ReplacingMergeTree(create_time)
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id);ReplacingMergeTree() 填入的参数为版本字段,重复数据保留版本字段值最大的。
如果不填版本字段,默认按照插入顺序保留最后一条。
2)向表中插入数据
INSERT INTO t_order_rmt VALUES
(101, 'sku_001', 1000.00, '2020-06-01 12:00:00'),
(102, 'sku_002', 2000.00, '2020-06-01 11:00:00'),
(102, 'sku_004', 2500.00, '2020-06-01 12:00:00'),
(102, 'sku_002', 2000.00, '2020-06-01 13:00:00'),
(102, 'sku_002', 12000.00, '2020-06-01 13:00:00'),
(102, 'sku_002', 600.00, '2020-06-02 12:00:00');3)重复再插入一次,执行第一次查询
SELECT * FROM t_order_rmt;
4)手动合并
OPTIMIZE TABLE t_order_rmt FINAL;5)再执行一次查询
SELECT * FROM t_order_rmt;
4.5.4 通过测试得到结论
- 实际上是使用 order by 字段作为唯一键
- 去重不能跨分区
- 只有同一批插入(新版本)或合并分区时才会进行去重
- 认定重复的数据保留,取版本字段值最大的
- 如果版本字段相同则按插入顺序保留最后一笔
4.6 SummingMergeTree
对于不查询明细,只关心以维度进行汇总聚合结果的场景。如果只使用普通的MergeTree的话,无论是存储空间的开销,还是查询时临时聚合的开销都比较大。
ClickHouse 为了这种场景,提供了一种能够“预聚合”的引擎 SummingMergeTree
4.6.1 案例演示
1)创建表
CREATE TABLE t_order_smt
(`id` UInt32,`sku_id` String,`total_amount` Decimal(16, 2),`create_time` Datetime
)
ENGINE = SummingMergeTree(total_amount)
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id);2)插入数据
INSERT INTO t_order_smt VALUES
(101, 'sku_001', 1000.00, '2020-06-01 12:00:00'),
(102, 'sku_002', 2000.00, '2020-06-01 11:00:00'),
(102, 'sku_004', 2500.00, '2020-06-01 12:00:00'),
(102, 'sku_002', 2000.00, '2020-06-01 13:00:00'),
(102, 'sku_002', 12000.00, '2020-06-01 13:00:00'),
(102, 'sku_002', 600.00, '2020-06-02 12:00:00');3)重复再插入一次,执行第一次查询
SELECT * FROM t_order_smt;
4)手动合并
OPTIMIZE TABLE t_order_smt FINAL;5)在执行一次查询
select * from t_order_smt;
4.6.2 通过结果可以得到以下结论
- 以 SummingMergeTree()中指定的列作为汇总数据列
- 可以填写多列必须数字列,如果不填,以所有非维度列且为数字列的字段为汇总数据列
- 以 order by 的列为准,作为维度列
- 其他的列按插入顺序保留第一行
- 不在一个分区的数据不会被聚合
- 只有在同一批次插入(新版本)或分片合并时才会进行聚合
4.6.3 开发建议
设计聚合表的话,唯一键值、流水号可以去掉,所有字段全部是维度、度量或者时间戳。
4.6.4 问题
能不能直接执行以下 SQL 得到汇总值
SELECT total_amount FROM XXX WHERE province_name = '' AND create_date = 'xxx'不行,可能会包含一些还没来得及聚合的临时明细
如果要是获取汇总值,还是需要使用 sum 进行聚合,这样效率会有一定的提高,但本身 ClickHouse 是列式存储的,效率提升有限,不会特别明显。
SELECT SUM(total_amount) FROM XXX WHERE province_name = '' AND create_date = 'xxx'第 5 章 SQL 操 作
基本上来说传统关系型数据库(以 MySQL 为例)的 SQL 语句,ClickHouse 基本都支持,这里只介绍 ClickHouse 与标准 SQL(MySQL)不一致的地方。
5.1 Insert
与标准 SQL(MySQL)基本一致
1)标准
INSERT INTO [table_name] VALUES (...), (...)2)从表到表的插入
INSERT INTO [table_name] SELECT a,b,c FROM [table_name_2]
5.2 Update 和 Delete
ClickHouse 提供了 Delete 和 Update 的能力,这类操作被称为 Mutation 查询,它可以看做 Alter 的一种。
虽然可以实现修改和删除,但是和一般的 OLTP 数据库不一样,Mutation 语句是一种很“重”的操作,而且不支持事务。
“重”的原因主要是每次修改或者删除都会导致放弃目标数据的原有分区,重建新分区。所以尽量做批量的变更,不要进行频繁小数据的操作。
1)删除操作
ALTER TABLE t_order_smt DELETE WHERE sku_id = 'sku_001';
2)修改操作
ALTER TABLE t_order_smt UPDATE total_amount = toDecimal32(2000.00, 2) WHERE id = 102;
由于操作比较“重”,所以 Mutation 语句分两步执行,同步执行的部分其实只是进行新增数据新增分区和并把旧分区打上逻辑上的失效标记。直到触发分区合并的时候,才会删除旧数据释放磁盘空间,一般不会开放这样的功能给用户,由管理员完成。
问题:如何实现高性能 update 和 delete ?
回答:在创建表时,添加两个标记字段,如下所示:
CREATE TABLE A
(a xxx,b xxx,c xxx,_sign UInt8,_version UInt32
)那么,对于更新操作,则相当于是插入一条新的数据,此时 _version + 1,查询的时候加上一个过滤条件(WHERE _version最大)进行查询。
对于删除操作,通过 _sign(0表示未删除,1表示已删除),同时 _version + 1,查询的时候加上一个过滤条件(WHERE _sign = 0 AND _version最大)进行查询。
那么如果时间久了,数据膨胀了怎么办?可以提供类似合并的机制,定期把过期数据进行清除。
5.3 查询操作
ClickHouse 基本上与标准 SQL 差别不大,但也有一些区别,如果按照标准SQL写, 不支持的ClickHouse 会在底层转换成
- 支持子查询
- 支持 CTE(Common Table Expression 公用表表达式 with 子句)
- 支持各种 JOIN,但是 JOIN 操作无法使用缓存,所以即使是两次相同的 JOIN 语句,ClickHouse 也会视为两条新 SQL
- 支持窗口函数
- 支持自定义函数
- GROUP BY 操作增加了 with rollup\with cube\with total 用来计算小计和总计。
5.3.1 插入数据
-- 清空数据
ALTER TABLE t_order_mt DELETE WHERE 1 = 1;
-- 插入数据
INSERT INTO t_order_mt VALUES
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),
(101,'sku_002',2000.00,'2020-06-01 12:00:00'),
(103,'sku_004',2500.00,'2020-06-01 12:00:00'),
(104,'sku_002',2000.00,'2020-06-01 12:00:00'),
(105,'sku_003',600.00,'2020-06-02 12:00:00'),
(106,'sku_001',1000.00,'2020-06-04 12:00:00'),
(107,'sku_002',2000.00,'2020-06-04 12:00:00'),
(108,'sku_004',2500.00,'2020-06-04 12:00:00'),
(109,'sku_002',2000.00,'2020-06-04 12:00:00'),
(110,'sku_003',600.00,'2020-06-01 12:00:00');5.3.2 count 查询
select count() from t_order_mt5.3.3 分组查询
select
sku_id,
any(id),
any(total_amount),
any(formatDateTime(toDateTime(create_time),'%Y-%m-%d %R:%S')) AS create_time
from t_order_mt
group by sku_id
order by id注意:
- 如果分组后想返回其他字段,必须用 any 函数,意思是返回第一个遇到的值,类似MySQL默认返回第一次遇到的值,还有其他函数,比如:anyHeavy(使用选择一个频繁出现的值),anyLast(选择遇到的最后一个值)等。
- 如果想格式化日期,可以使用 formatDateTime(toDateTime(create_time),'%Y-%m-%d %R:%S')
5.3.4 使用 with
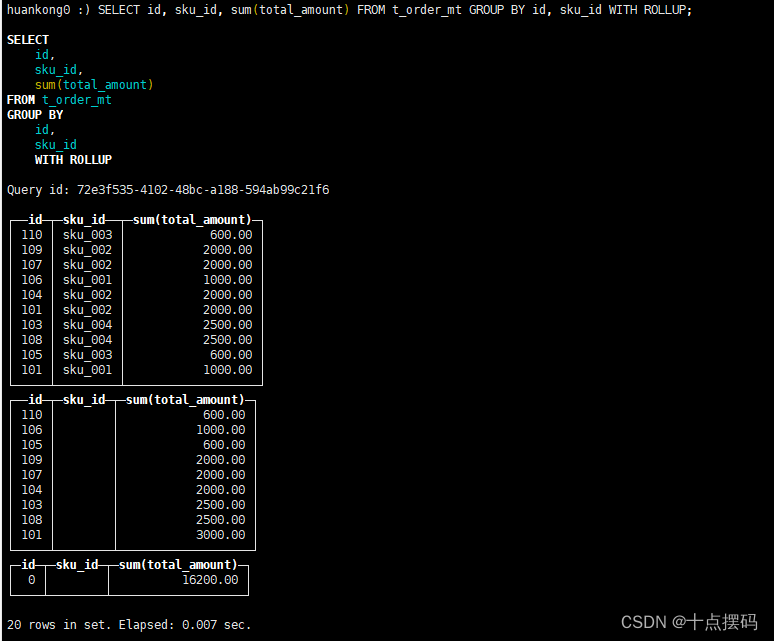
1)with rollup:从右至左去掉维度进行小计
SELECT id, sku_id, sum(total_amount) FROM t_order_mt GROUP BY id, sku_id WITH ROLLUP;
2)with cube : 从右至左去掉维度进行小计,再从左至右去掉维度进行小计
SELECT id, sku_id, sum(total_amount) FROM t_order_mt GROUP BY id, sku_id WITH CUBE;
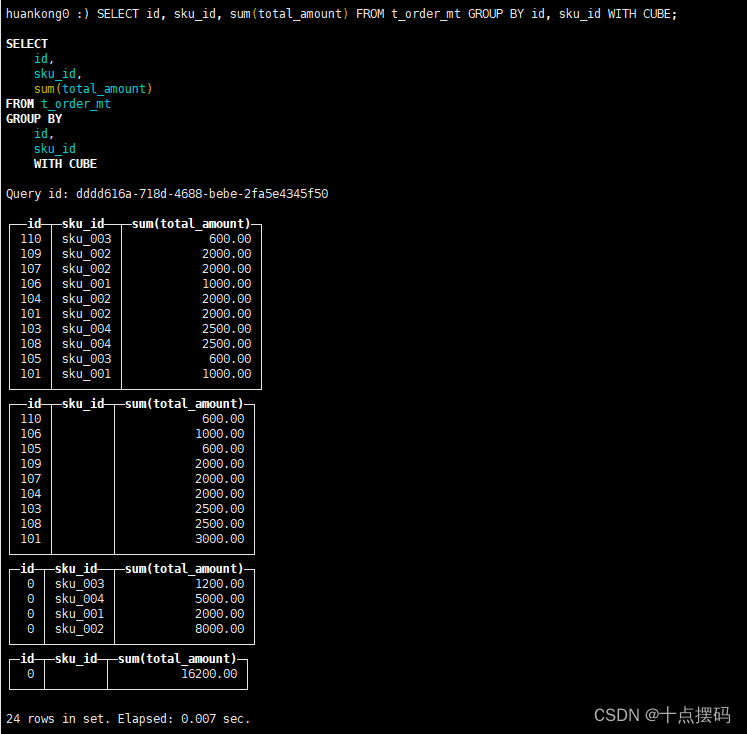
3)with totals: 只计算合计
SELECT id, sku_id, sum(total_amount) FROM t_order_mt GROUP BY id, sku_id WITH TOTALS;

5.4 alter 操作
同 MySQL 的修改字段基本一致
5.4.1 新增字段
ALTER TABLE tableName ADD COLUMN newcolname String AFTER col1;
5.4.2 修改字段类型
ALTER TABLE tableName MODIFY COLUMN newcolname String;5.4.3 删除字段
ALTER TABLE tableName DROP COLUMN newcolname;5.5 导出数据
clickhouse-client --query "select * from t_order_mt where create_time='2020-06-01 12:00:00'" --format CSVWithNames> /opt/module/data/rs1.csv更多支持格式参考:https://clickhouse.com/docs/en/interfaces/formats/
第 6 章 副本
副本的目的主要是保障数据的高可用性,即使一台 ClickHouse 节点宕机,那么也可以从其他服务器获得相同的数据。
6.1 副本写入流程

6.2 配置步骤
1)启动 zookeeper 集群
2)在 hadoop102 的 /etc/clickhouse-server/config.d 目录下创建一个名为 metrika.xml 的配置文件,内容如下:
<?xml version="1.0"?>
<yandex><zookeeper-servers><node index="1"><host>hadoop102</host><port>2181</port></node><node index="2"><host>hadoop103</host><port>2181</port></node><node index="3"><host>hadoop104</host><port>2181</port></node></zookeeper-servers>
</yandex>注:也可以不创建外部文件,直接在 config.xml 中指定<zookeeper>
提示:这里用三台机器作为集群,分别为hadoop102 、hadoop103 和 hadoop104
3)同步到 hadoop103 和 hadoop104 上
4)在 hadoop102 的/etc/clickhouse-server/config.xml 中增加
<zookeeper incl="zookeeper-servers" optional="true" />
<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>
5)同步到 hadoop103 和 hadoop104 上,然后分别在 hadoop102、hadoop103 和 hadoop104 上重启 ClickHouse 服务
注意:因为修改了配置文件,如果以前启动了服务需要重启
sudo clickhouse restart注意:我们演示副本操作只需要在 hadoop102 和 hadoop103 两台服务器即可,上面的操作,我们 hadoop104 可以你不用同步,我们这里为了保证集群中资源的一致性,做了同
步。
6)在 hadoop102 和 hadoop103 上分别建表
副本只能同步数据,不能同步表结构,所以我们需要在每台机器上自己手动建表
① hadoop102
CREATE TABLE t_order_rep2
(`id` UInt32,`sku_id` String,`total_amount` Decimal(16, 2),`create_time` Datetime
)
ENGINE = ReplicatedMergeTree('/clickhouse/table/01/t_order_rep', 'rep_102')
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id);② hadoop103
CREATE TABLE t_order_rep2
(`id` UInt32,`sku_id` String,`total_amount` Decimal(16, 2),`create_time` Datetime
)
ENGINE = ReplicatedMergeTree('/clickhouse/table/01/t_order_rep', 'rep_103')
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id);③ hadoop104
CREATE TABLE t_order_rep2
(`id` UInt32,`sku_id` String,`total_amount` Decimal(16, 2),`create_time` Datetime
)
ENGINE = ReplicatedMergeTree('/clickhouse/table/01/t_order_rep', 'rep_104')
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id);参数解释:
在 ReplicatedMergeTree 中,
第一个参数是分片的 zk_path 一般按照:/clickhouse/table/{shard}/{table_name} 的格式写,如果只有一个分片就写 01 即可。
第二个参数是副本名称,相同的分片副本名称不能相同。
7)在 hadoop102 上执行 insert 语句
INSERT INTO t_order_rep2 VALUES
(101,'sku_001',1000.00,'2020-06-01 12:00:00'),
(102,'sku_002',2000.00,'2020-06-01 12:00:00'),
(103,'sku_004',2500.00,'2020-06-01 12:00:00'),
(104,'sku_002',2000.00,'2020-06-01 12:00:00'),
(105,'sku_003',600.00,'2020-06-02 12:00:00');8)在 hadoop103 上执行 select,可以查询出结果,说明副本配置正确
SELECT * FROM t_order_rep2;
第 7 章 分片集群
副本虽然能够提高数据的可用性,降低丢失风险,但是每台服务器实际上必须容纳全量数据,对数据的横向扩容没有解决。
要解决数据水平切分的问题,需要引入分片的概念。通过分片把一份完整的数据进行切分,不同的分片分布到不同的节点上,再通过 Distributed 表引擎把数据拼接起来一同使用。
Distributed 表引擎本身不存储数据,有点类似于 MyCat 之于 MySql,成为一种中间件,通过分布式逻辑表来写入、分发、路由来操作多台节点不同分片的分布式数据。
注意:ClickHouse 的集群是表级别的,实际企业中,大部分做了高可用,但是没有用分片,避免降低查询性能以及操作集群的复杂性。
7.1 集群写入流程(3 分片 2 副本共 6 个节点)

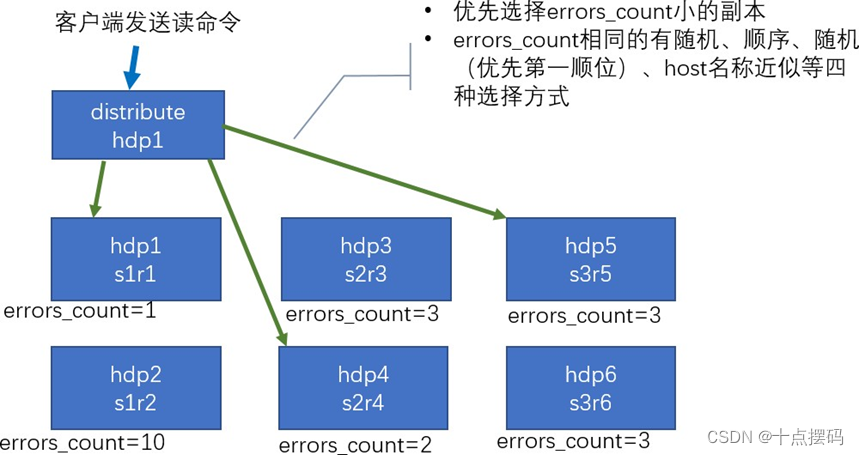
7.2 集群读取流程(3 分片 2 副本共 6 个节点)
7.3 分片 2 副本共 6 个节点集群配置(供参考)
配置的位置还是在之前的/etc/clickhouse-server/config.d/metrika.xml,内容如下
<yandex><remote_servers><!-- 集群名称--><gmall_cluster><!--集群的第一个分片--><shard><internal_replication>true</internal_replication><!--该分片的第一个副本--><replica><host>hadoop101</host><port>9000</port></replica><!--该分片的第二个副本--><replica><host>hadoop102</host><port>9000</port></replica></shard><!--集群的第二个分片--><shard><internal_replication>true</internal_replication><!--该分片的第一个副本--><replica><host>hadoop103</host><port>9000</port></replica><!--该分片的第二个副本--><replica><host>hadoop104</host><port>9000</port></replica></shard><!--集群的第三个分片--><shard><internal_replication>true</internal_replication><!--该分片的第一个副本--><replica><host>hadoop105</host><port>9000</port></replica><!--该分片的第二个副本--><replica><host>hadoop106</host><port>9000</port></replica></shard></gmall_cluster></remote_servers>
</yandex>注意:也可以不创建外部文件,直接在 config.xml 的 <remote_servers> 中指定
7.4 配置三节点版本集群及副本
7.4.1 集群及副本规划(2 个分片,只有第一个分片有副本)

| hadoop102 | hadoop103 | hadoop104 |
| <macros> <shard>01</shard> <replica>rep_1_1</replica> </macros> | <macros> <shard>01</shard> <replica>rep_1_2</replica> </macros> | <macros> <shard>02</shard> <replica>rep_2_1</replica> </macros> |
7.4.2 配置步骤
1)在 hadoop102 的 /etc/clickhouse-server/config.d 目录下创建 metrika-shard.xml 文件
<?xml version="1.0"?>
<yandex><remote_servers><!-- 集群名称--><gmall_cluster><!--集群的第一个分片--><shard><internal_replication>true</internal_replication><!--该分片的第一个副本--><replica><host>hadoop102</host><port>9000</port></replica><!--该分片的第二个副本--><replica><host>hadoop103</host><port>9000</port></replica></shard><!--集群的第二个分片--><shard><internal_replication>true</internal_replication><!--该分片的第一个副本--><replica><host>hadoop104</host><port>9000</port></replica></shard></gmall_cluster></remote_servers><zookeeper-servers><node index="1"><host>hadoop102</host><port>2181</port></node><node index="2"><host>hadoop103</host><port>2181</port></node><node index="3"><host>hadoop104</host><port>2181</port></node></zookeeper-servers><macros><!--不同机器放的分片数不一样--><shard>01</shard><!--不同机器放的副本数不一样--><replica>rep_1_1</replica></macros>
</yandex>注意:也可以不创建外部文件,直接在 config.xml 的 <remote_servers> 中指定
2)将 hadoop102 的 metrika-shard.xml 同步到 103 和 104
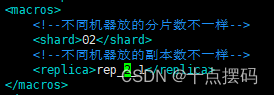
3)修改 103 和 104 中 metrika-shard.xml 宏的配置
(1)103
sudo vim /etc/clickhouse-server/config.d/metrika-shard.xml
(2)104
sudo vim /etc/clickhouse-server/config.d/metrika-shard.xml
4)在 hadoop102 上修改 /etc/clickhouse-server/config.xml

5)同步 /etc/clickhouse-server/config.xml 到 103 和 104
sudo vim /etc/clickhouse-server/config.xml
6)重启三台服务器上的 ClickHouse 服务
sudo clickhouse restart
ps -ef |grep click7)在 hadoop102 上执行建表语句
- 会自动同步到 hadoop103 和 hadoop104 上
- 集群名字要和配置文件中的一致
- 分片和副本名称从配置文件的宏定义中获取
CREATE TABLE st_order_mt ON CLUSTER gmall_cluster
(`id` UInt32,`sku_id` String,`total_amount` Decimal(16, 2),`create_time` Datetime
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/st_order_mt', '{replica}')
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY id
ORDER BY (id, sku_id);
可以到 hadoop103 和 hadoop104 上查看表是否创建成功


8)在 hadoop102 上创建 Distribute 分布式表
CREATE TABLE st_order_mt_all2 ON CLUSTER gmall_cluster
(`id` UInt32,`sku_id` String,`total_amount` Decimal(16, 2),`create_time` Datetime
)
ENGINE = Distributed(gmall_cluster, default, st_order_mt, hiveHash(sku_id));参数含义:
Distributed(集群名称,库名,本地表名,分片键)
分片键必须是整型数字,所以用 hiveHash 函数转换,也可以 rand()

9)在 hadoop102 上插入测试数据
INSERT INTO st_order_mt_all2 VALUES
(201,'sku_001',1000.00,'2020-06-01 12:00:00') ,
(202,'sku_002',2000.00,'2020-06-01 12:00:00'),
(203,'sku_004',2500.00,'2020-06-01 12:00:00'),
(204,'sku_002',2000.00,'2020-06-01 12:00:00'),
(205,'sku_003',600.00,'2020-06-02 12:00:00');10)通过查询分布式表和本地表观察输出结果
注意:分布式表管理不同分片时需要知道用户名和密码,如果 clickhouse 的用户设置了密码,则需要在分片配置中添加上密码。
错误信息:DB::Exception: Received from hadoop104:9000. DB::Exception: default: Authentication failed: password is incorrect or there is no user with such name.
<replica><host>hadoop102</host><port>9000</port><user>default</user><password>abc123</password>
</replica>(1)分布式表
SELECT * FROM st_order_mt_all;
(2)本地表
select * from st_order_mt;
(3)观察数据的分布
| st_order_mt_all |
|

| hadoop102: st_order_mt |
|
| hadoop103: st_order_mt |
|
| hadoop104: st_order_mt |
|


7.5 项目为了节省资源,就使用单节点,不用集群
相关文章:
ClickHouse 学习之基础入门(一)
第 1 章 ClickHouse 入 门 ClickHouse 是俄罗斯的 Yandex 于 2016 年开源的列式存储数据库(DBMS),使用 C 语言编写,主要用于在线分析处理查询(OLAP),能够使用 SQL 查询实时生成分析数据报告。 …...

HttpClient基本使用
十二、HttpClient 12.1 介绍 HttpClient是Apache Jakarta Common 下的子项目,可以用来提供高效的、最新的、功能丰富的支持HTTP协议的客户端编程工具包,并且它支持HTTP协议最新的版本和建议。 HttpClient作用: 发送HTTP请求接收响应数据 …...
)
力扣:150. 逆波兰表达式求值(Python3)
题目: 给你一个字符串数组 tokens ,表示一个根据 逆波兰表示法 表示的算术表达式。 请你计算该表达式。返回一个表示表达式值的整数。 注意: 有效的算符为 、-、* 和 / 。每个操作数(运算对象)都可以是一个整数或者另一…...
Tomcat运行日志乱码问题/项目用tomcat启动时窗口日志乱码
文章目录 一、问题描述:二、产生原因三、解决方法 一、问题描述: 项目在idea中运行时日志是正常的,用Tomcat启动时发现一大堆看不懂的文字,如 二、产生原因 产生乱码的根本原因就是编码和解码不一致,举个例子就是翻…...

Leetcode—199.二叉树的右视图【中等】
2023每日刷题(十九) Leetcode—199.二叉树的右视图 深度优先遍历实现代码 /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(…...

微信小程序如何跳转到外部小程序
要在微信小程序中跳转到外部小程序,您可以使用微信小程序提供的 wx.navigateToMiniProgram 方法。以下是实现步骤: 在需要跳转的页面或组件中,编写触发跳转的逻辑,例如点击按钮: 替换 外部小程序的AppID 和 外部小程序…...
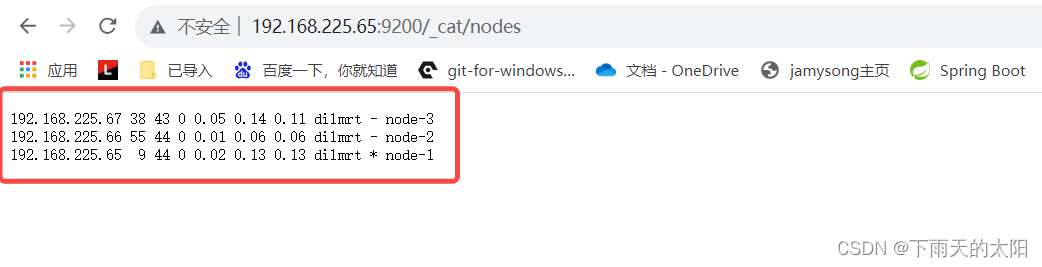
ElasticSearch集群环境搭建
1、准备三台服务器 这里准备三台服务器如下: IP地址主机名节点名192.168.225.65linux1node-1192.168.225.66linux2node-2192.168.225.67linux3node-3 2、准备elasticsearch安装环境 (1)编辑/etc/hosts(三台服务器都执行) vim /etc/hosts 添加如下内…...

[架构之路-250/创业之路-81]:目标系统 - 纵向分层 - 企业信息化的呈现形态:常见企业信息化软件系统 - 企业内的数据与数据库
目录 一、数据概述 1.1 数据 1.2 企业信息系统的数据 1.3 大数据 1.4 数据与程序的分离思想 1.5 数据与程序的分离做法 1.6 数据库的基本概念 1.7 企业数据来源 1.8 企业数据架构 二、常见的数据库类型 2.1 数据库分类 2.1 数据库类型 2.2 常见的数据库类型、应用…...

delaunay和voronoi图 人脸三角剖分
先获取人脸68个特征点坐标,其中使用了官方的预训练模型shape_predictor_68_face_landmarks.dat: import dlib import cv2predictor_path "shape_predictor_68_face_landmarks.dat" png_path "face.jpg"txt_path "points.tx…...
MySQL数据库之表的增删查改
目录 表的操作1.创建表创建表案例 2.查看表结构3.修改表4.删除表 表的操作 1.创建表 语法: CREATE TABLE table_name (field1 datatype,field2 datatype,field3 datatype ) character set 字符集 collate 校验规则 engine 存储引擎;说明: field 表示列…...
Fast R-CNN)
(论文阅读11/100)Fast R-CNN
文献阅读笔记 简介 题目 Fast R-CNN 作者 Ross Girshick 原文链接 https://arxiv.org/pdf/1504.08083.pdf 目标检测系列——开山之作RCNN原理详解-CSDN博客 Fast R-CNN讲解_fast rcnn-CSDN博客 Rcnn、FastRcnn、FasterRcnn理论合集_rcnn fastrcnn fasterrcnn_沫念的博客…...
Git 标签(Tag)实战:打标签和删除标签的步骤指南
目录 前言使用 Git 打本地和远程标签(Tag)删除本地和远程 Git 标签(Tag)开源项目标签(Tag)实战打标签删除标签 结语开源微服务商城项目前后端分离项目 前言 在开源项目中,版本控制是至关重要的…...
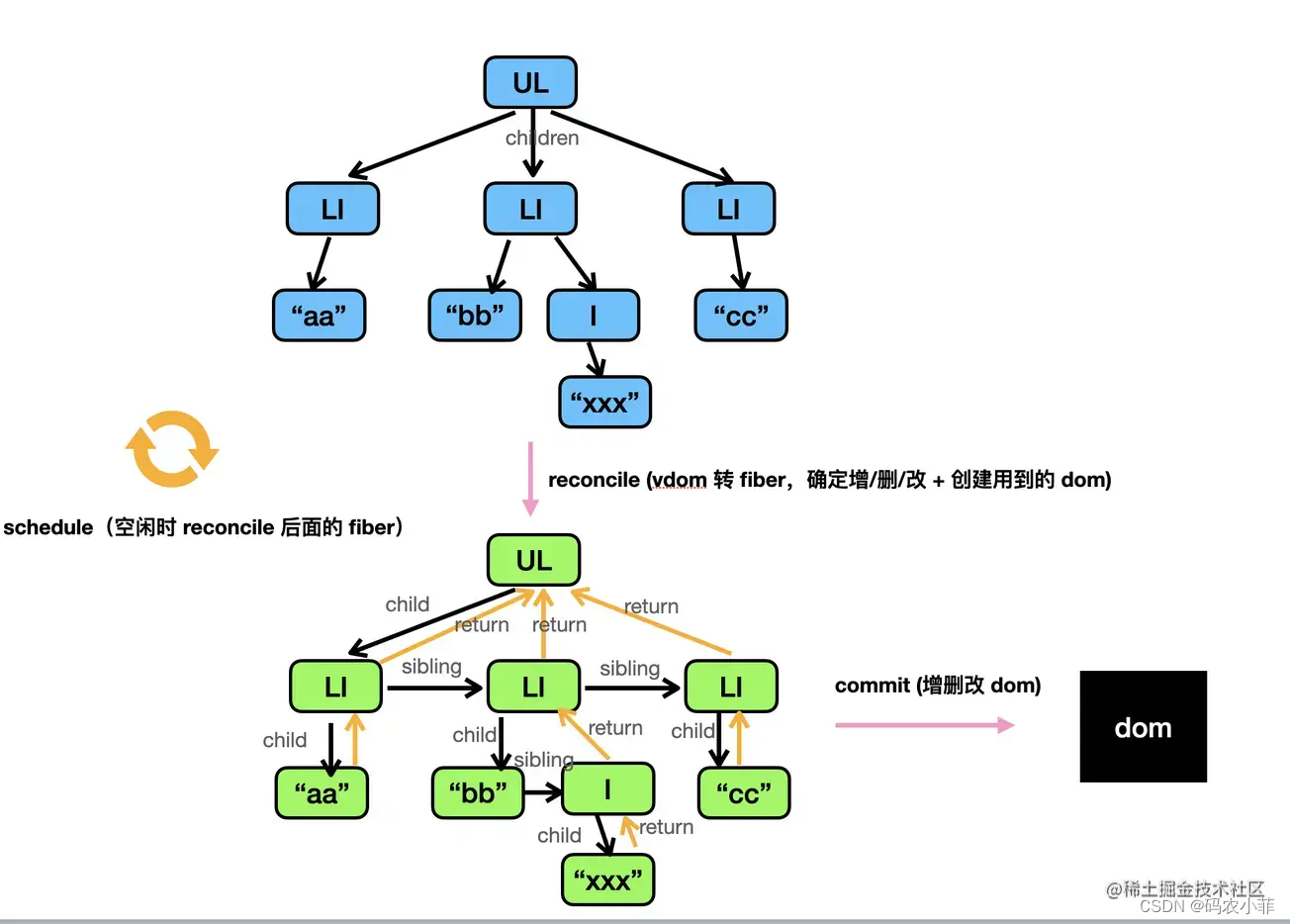
React 底层 Fiber 架构 简单理解
一、 背景 JS 是引擎是单线程运行的;严格来说,JS 引擎和页面渲染引擎在同一渲染线程,两者互斥。那么就会遇到这样的一种情况:当前面一个任务长期霸占CPU,后面啥事也干不了,浏览器卡死,造成极差…...
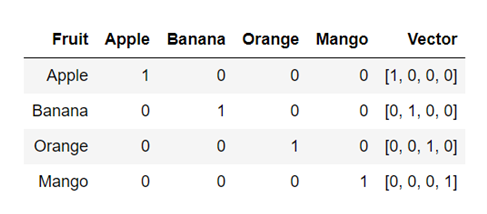
使用 Python 进行自然语言处理第 4 部分:文本表示
一、说明 本文是在 2023 年 3 月为 WomenWhoCode 数据科学跟踪活动发表的系列文章中。早期的文章位于:第 1 部分(涵盖 NLP 简介)、第 2 部分(涵盖 NLTK 和 SpaCy 库)、第 2 部分(涵盖NLTK和SpaCy库…...
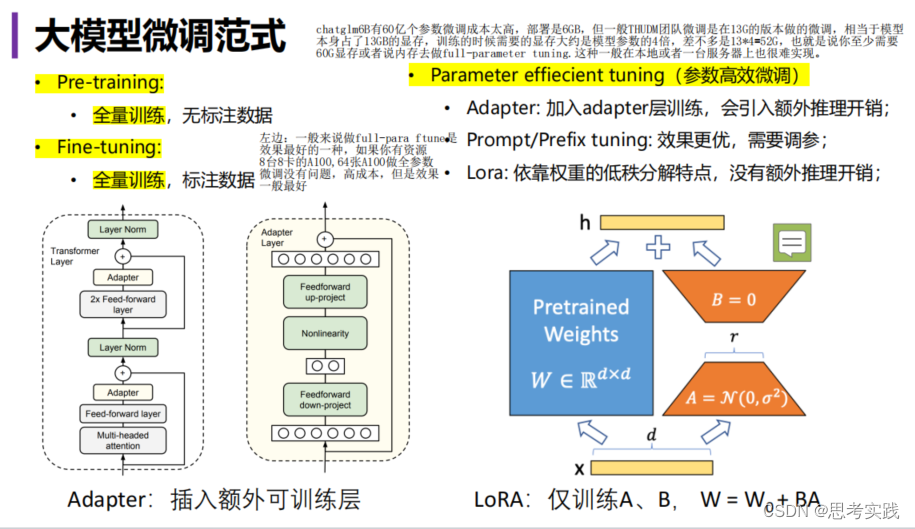
【LLM】大语言模型高效微调方案Lora||直击底层逻辑
大白话: DL的本质就是矩阵的乘法,就能实现LLM, 假设两个矩阵都很大,一个mxn,一个nxd的矩阵,m,n,d这几个数字可能几千甚至上万的场景,计算起来代价很大,如果我们可以small 这些数字,缩小到10甚至5这样的s…...

Qt for Android代码中输出日志
#include <QtDebug>qInfo() << "hello"; 如上,加入头文件(注意:这里的头文件是QtDebug,不是QDebug,也不知道啥时候改的,也不知道有啥区别,先这样吧)后使用qI…...

力扣刷题-二叉树-二叉树的递归遍历
本文讲解二叉树的前序遍历、后序遍历、中序遍历。 思路 每次写递归,都按照这三要素来写,可以保证大家写出正确的递归算法! 确定递归函数的参数和返回值: 确定哪些参数是递归的过程中需要处理的,那么就在递归函数里加…...

VX-3R APRS发射试验
VX-3R本身是不带APRS功能的,不过可能通过外加TNC实现APRS功能。 有大佬已经用Arduino实现了相应的发射功能: https://github.com/handiko/Arduino-APRS 我要做的,就是简单修改一下代码,做一个转接板。 YEASU官方没有给出VX-3R的音…...

JAVA毕业设计109—基于Java+Springboot+Vue的宿舍管理系统(源码+数据库)
基于JavaSpringbootVue的宿舍管理系统(源码数据库)109 一、系统介绍 本系统前后端分离 本系统分为学生、宿管、超级管理员三种角色 1、用户: 登录、我的宿舍、申请调宿、报修申请、水电费管理、卫生检查、个人信息修改。 2、宿管: 登录、用户管理…...

CMU/MIT/清华/Umass提出生成式机器人智能体RoboGen
文章目录 导读1. Introduction2. 论文地址3. 项目主页4. 开源地址5. RoboGen Pipeline6. Experimental Results作者介绍Reference 导读 CMU/MIT/清华/Umass提出的全球首个生成式机器人智能体RoboGen,可以无限生成数据,让机器人7*24小时永不停歇地训练。…...

如何快速编辑虚幻引擎游戏存档?uesave-rs终极指南
如何快速编辑虚幻引擎游戏存档?uesave-rs终极指南 【免费下载链接】uesave Rust library and CLI to read and write Unreal Engine save files 项目地址: https://gitcode.com/gh_mirrors/ue/uesave 你是否曾经想修改游戏存档却无从下手?当面对虚…...

太空算力产业正崛起
未来,渔民只需通过手机App向卫星发起查询,卫星便可借助高光谱相机精准定位金枪鱼位置,再通过在轨“智慧大脑”分析处理,将鱼群坐标、渔具使用建议及销售渠道指导等实用信息,精准传回渔民手中。这一充满“黑科技”色彩的…...

AudioSwitch:一键管理Windows音频设备,告别繁琐系统设置
AudioSwitch:一键管理Windows音频设备,告别繁琐系统设置 【免费下载链接】AudioSwitch Switch between default audio input or output change volume 项目地址: https://gitcode.com/gh_mirrors/au/AudioSwitch 音频设备切换是Windows用户经常遇…...

python高校学生党员信息管理系统_829h59n3
目录同行可拿货,招校园代理 ,本人源头供货商项目背景核心功能技术实现项目特点应用价值项目技术支持源码获取详细视频演示 :同行可合作点击我获取源码->获取博主联系方式->进我个人主页-->同行可拿货,招校园代理 ,本人源头供货商 项目背景 高校学生党员信…...

Diablo Edit2:10分钟掌握暗黑破坏神2存档修改终极指南
Diablo Edit2:10分钟掌握暗黑破坏神2存档修改终极指南 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 厌倦了在暗黑破坏神2中反复刷装备?想要快速测试新build却不想花费40小…...

利用Taotoken模型广场为不同AI应用场景挑选最合适的模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken模型广场为不同AI应用场景挑选最合适的模型 在构建AI驱动的应用时,一个常见的挑战是如何为不同的功能模块…...
)
智慧养老平台|基于SprinBoot+vue的智慧养老平台系统(源码+数据库+文档)
智慧养老平台 目录 基于SprinBootvue的外贸平台系统 一、前言 二、系统设计 三、系统功能设计 前台 后台 管理员功能 老人功能 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大厂码…...

别再傻傻分不清了!GIS新手必看:WGS84和UTM到底怎么选?附QGIS/ArcGIS实操对比
GIS坐标系选择指南:WGS84与UTM的核心差异与实战决策 刚接触地理信息系统(GIS)时,坐标系的选择往往令人困惑。为什么同样的位置数据,在不同坐标系下显示的数值完全不同?为什么测量同一个区域的面积会得到差异巨大的结果?…...
)
从一次‘迷路’说起:手把手调试LTE终端TAU失败问题(附Wireshark抓包分析)
从一次‘迷路’说起:手把手调试LTE终端TAU失败问题(附Wireshark抓包分析) 清晨的地铁站里,一位工程师盯着手机屏幕上反复跳出的"无服务"提示皱起眉头——这已经是本周第三次收到用户投诉在A区到B区的通勤路上出现信号中…...
如何用TranslucentTB实现Windows任务栏透明化:3分钟完成桌面美化终极指南
如何用TranslucentTB实现Windows任务栏透明化:3分钟完成桌面美化终极指南 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你是…...