使用 Python 进行自然语言处理第 4 部分:文本表示

一、说明
二、文本表示
- 文本数据以字母、单词、符号、数字或所有这些的集合的形式存在。例如“印度”、“、”、“Covid19”等。
- 在我们将机器学习/深度学习算法应用于文本数据之前,我们必须以数字形式表示文本。单个单词和文本文档都可以转换为浮点数向量。
- 将标记、句子表示为数值向量的过程称为“嵌入”,这些向量的多维空间称为嵌入空间。
- 循环神经网络、长短期记忆网络、变形金刚等深度神经网络架构需要以固定维数值向量的形式输入文本。
2.1 一些术语:
- 文档:文档是许多单词的集合。
- 词汇:词汇是文档中唯一单词的集合。
- Token:Token是离散数据的基本单位。它通常指单个单词或标点符号。
- 语料库:语料库是文档的集合。
- 上下文:单词/标记的上下文是文档中左右围绕该单词/标记的单词/标记。
- 向量嵌入:基于向量的文本数字表示称为嵌入。例如,word2vec 或 GLoVE 是基于语料库统计的无监督方法。像tensorflow和keras这样的框架支持“嵌入层”。
2.2 文本表示应具有以下属性:
- 它应该唯一地标识一个单词(必须是双射)
- 应捕捉单词之间的形态、句法和语义相似性。相关词在欧德空间中应该比不相关词更接近出现。
- 这些表示应该可以进行算术运算。
- 通过表示,计算单词相似性和关系等任务应该很容易。
- 应该很容易从单词映射到其嵌入,反之亦然。
2.3 文本表示的一些突出技术:
- 一次性编码
- 词袋模型 — CountVectorizer 和带有 n 元语法的 CountVectorizer
- Tf-Idf模型
- Word2Vec 嵌入
- 手套包埋
- 快速文本嵌入
- ChatGPT 和 BERT 等 Transformer 使用自己的动态嵌入。
一热编码:
这是将文本表示为数值向量的最简单技术。每个单词都表示为由 0 和 1 组成的唯一“One-Hot”二进制向量。对于词汇表中的每个唯一单词,向量包含一个 1,其余所有值为 0,向量中 1 的位置唯一标识一个单词。
例子:
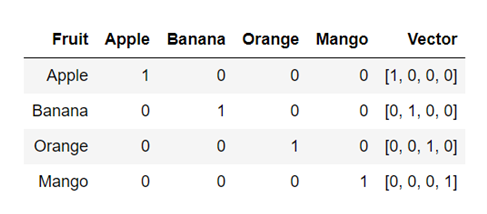
单词 Apple、Banana、Orange 和 Mango 的 OneHot 向量示例
from sklearn.preprocessing import OneHotEncoder
import nltk
from nltk import word_tokenize
document = "The rose is red. The violet is blue."
document = document.split()
tokens = [doc.split(" ") for doc in document]wordids = {token: idx for idx, token in enumerate(set(document))}
tokenids = [[wordids[token] for token in toke] for toke in tokens]onehotmodel = OneHotEncoder()
vectors = onehotmodel.fit_transform(tokenids)
print(vectors.todense())2.4 词袋表示:CountVectorizer
请参阅此处的详细信息:https ://en.wikipedia.org/wiki/Bag-of-words_model
词袋 (BoW) 是一种无序的文本表示形式,用于描述文档中单词的出现情况。它具有文档中已知单词的词汇表以及已知单词存在的度量。词袋模型不包含有关文档中单词的顺序或结构的任何信息。
维基百科的例子:
文档1:约翰喜欢看电影。玛丽也喜欢电影。
文件2:玛丽也喜欢看足球比赛。
词汇1:“约翰”、“喜欢”、“去”、“看”、“电影”、“玛丽”、“喜欢”、“电影”、“太”
词汇2:“玛丽”、“也”、“喜欢”、“去”、“看”、“足球”、“游戏”
BoW1 = {“约翰”:1,“喜欢”:2,“观看”:1,“观看”:1,“电影”:2,“玛丽”:1,“太”:1};
BoW2 = {“玛丽”:1,“也”:1,“喜欢”:1,“到”:1,“观看”:1,“足球”:1,“游戏”:1};
Document3 是 document1 和 document2 的并集(包含文档 1 和文档 2 中的单词)
文件3:约翰喜欢看电影。玛丽也喜欢电影。玛丽还喜欢看足球比赛。
BoW3: {“约翰”:1、“喜欢”:3、“观看”:2、“观看”:2、“电影”:2、“玛丽”:2、“太”:1、“也”:1 ,“足球”:1,“游戏”:1}
让我们编写一个函数来在用向量表示文本之前对其进行预处理。
# This process_text() function returns list of cleaned tokens of the text
import numpy
import re
import string
import unicodedata
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
stop_words = stopwords.words('english')
lemmatizer = WordNetLemmatizer()def process_text(text):# Remove non-ASCII characterstext = unicodedata.normalize('NFKD', text).encode('ascii', 'ignore').decode('utf-8', 'ignore')# Remove words not starting with alphabetstext = re.sub(r'[^a-zA-Z\s]', '', text)# Remove punctuation markstext = text.translate(str.maketrans('', '', string.punctuation))#Convert to lower casetext = text.lower()# Remove stopwordstext = " ".join([word for word in str(text).split() if word not in stop_words])# Lemmatizetext = " ".join([lemmatizer.lemmatize(word) for word in text.split()])return text接下来,我们使用 Sklearn 库中的 CountVectorizer 将预处理后的文本转换为词袋表示。
#https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html
#https://stackoverflow.com/questions/27697766/understanding-min-df-and-max-df-in-scikit-countvectorizer
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
import nltk
document = ["The", "rose", "is", "red", "The", "violet", "is", "blue"] #, "This is some text, just for demonstration"]processed_document = [process_text(item) for item in document]
processed_document = [x for x in processed_document if x != '']
print(processed_document)bow_countvect = CountVectorizer(min_df = 0., max_df = 1.)matrix = bow_countvect.fit_transform(processed_document)
matrix.toarray()
vocabulary = bow_countvect.get_feature_names_out()
print(matrix)
matrix.todense()2.5 词袋表示:n-grams
Simpe Bag-of-words 模型不存储有关单词顺序的信息。n-gram 模型可以存储这些空间信息。
单词/标记被称为“gram”。n-gram 是出现在文本文档中的一组连续的 n-token。
一元词表示 1 个单词,二元词表示两个词,三元词表示一组 3 个词……
例如对于文本(来自维基百科):
文档1:约翰喜欢看电影。玛丽也喜欢电影。
二元模型将文本解析为以下单元,并像简单的 BoW 模型一样存储每个单元的术语频率。
[“约翰喜欢”、“喜欢”、“看”、“看电影”、“玛丽喜欢”、“喜欢电影”、“也看电影”,]
Bag-of-word 模型可以被认为是 n-gram 模型的特例,其中 n=1
#https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html
from sklearn.feature_extraction.text import CountVectorizerdocument = ["The rose is red.", "The violet is blue.", "This is some text, just for demonstration"]
ngram_countvect = CountVectorizer(ngram_range = (2, 2), stop_words = 'english')
#ngram_range paramenter to count vectorizer indicates the lower and upper boundary of the range of n-values for
#different word n-grams or char n-grams to be extracted. All values of n such such that min_n <= n <= max_n will be used.
#For example an ngram_range of (1, 1) means only unigrams, (1, 2) means unigrams and bigrams, and (2, 2) means only bigrams.matrix = ngram_countvect.fit_transform(document)
vocabulary = ngram_countvect.get_feature_names_out()
matrix.todense()三、Tf-Idf 矢量化器:术语频率 — 逆文档频率
可以在这里找到 TF-IDF 矢量器的非常好的解释
- 文档“d”中术语/单词“w”的 Tf-Idf 分数 tfidf(w,D) 是两个指标的乘积:术语频率 (tf) 和逆文档频率 (idf)。即 tfidf(w, d, C) = tf(w,d)*idf(w,d,C)
- 其中w是术语或单词,d是文档,C是包含总共N个文档(包括文档d)的语料库。
- 词频 tf(w,d) 是文档 d 中单词 w 的频率。术语频率可以根据文档的长度进行调整(出现的原始计数除以文档中的单词数),它可以是对数缩放频率(例如 log(1 + 原始计数)),也可以是布尔频率(例如,如果该术语在文档中出现,则为 1;如果该术语在文档中未出现,则为 0)。
- 文档频率:是一个术语/单词 w 在一组 N 个文档(语料库)中出现的频率。逆文档频率是衡量一个词在语料库中的常见或罕见程度的指标。更少的是 IDF,更常见的是这个词,反之亦然。单词的 IDF 是通过将语料库中的文档总数除以包含该单词的文档数量的对数来计算的。逆文档频率是术语/单词信息量的度量。频繁出现的单词信息量较少。单词的逆文档频率是在一组文档(语料库)中计算的。
from sklearn.feature_extraction.text import TfidfVectorizerdocument = ["The rose is red.", "The violet is blue.", "This is some text, just for demonstration"]tf_idf = TfidfVectorizer(min_df = 0., max_df = 1., use_idf = True)
tf_idf_matrix = tf_idf.fit_transform(document)
tf_idf_matrix = tf_idf_matrix.toarray()
tf_idf_matrix四、词嵌入
上述文本表示方法通常不能捕获单词的语义和上下文。为了克服这些限制,我们使用嵌入。嵌入是通过训练庞大数据集的模型来学习的。这些嵌入通过考虑句子中的相邻单词以及句子中单词的顺序来捕获单词的上下文。三个著名的词嵌入是:Word2Vec、GloVe、FastText
词向量
- 是一个在巨大文本语料库上训练的无监督模型。它创建单词的词汇表以及表示词汇表的向量空间中单词的分布式连续密集向量表示。它捕获上下文和语义的相似性。
- 我们可以指定词嵌入向量的大小。向量总数本质上就是词汇表的大小。
- Word2Vec中有两种不同的模型架构类型——CBOW(连续词袋)模型、Skip Gram模型
CBOW 模型 - 尝试根据源上下文单词预测当前目标单词。Skip Gram 模型尝试预测给定目标单词的源上下文单词。
from gensim.models import word2vec
import nltk
document = ["The rose is red.", "The violet is blue.", "This is some text, just for demonstration"]tokenized_corpus = [nltk.word_tokenize(doc) for doc in document]
#parameters of word2vec model
# feature_size : integer : Word vector dimensionality
# window_context : integer : The maximum distance between the current and predicted word within a sentence.(2, 10)
# min_word_count : integer : Ignores all words with total absolute frequency lower than this - (2, 100)
# sample : integer : The threshold for configuring which higher-frequency words are randomly downsampled. Highly influencial. - (0, 1e-5)
# sg: integer: Skip-gram model configuration, CBOW by defaultwordtovector = word2vec.Word2Vec(tokenized_corpus, window = 3, min_count = 1, sg = 1)
print('Embedding of the word blue')
print(wordtovector.wv['blue'])print('Size of Embedding of the word blue')
print(wordtovector.wv['blue'].shape)如果您希望查看词汇表中的所有向量,请使用以下代码:
#All the vectors for all the words in our input text
words = wordtovector.wv.index_to_key
wvs = wordtovector.wv[words]
wvs或者将它们转换为 pandas 数据框
import pandas as pd
df = pd.DataFrame(wvs, index = words)
df五、GloVe库(手套)
- 全局向量 (GloVe) 是一种为 Word2Vec 等单词生成密集向量表示的技术。它首先创建一个由(单词,上下文)对组成的巨大的单词-上下文共现矩阵。该矩阵中的每个元素代表上下文中单词的频率。可以应用矩阵分解技术来近似该矩阵。由于 Glove 是在 globar 词-词共现矩阵上进行训练的,因此它使我们能够拥有一个具有有意义的子结构的向量空间。
- Spacy 库支持 GloVe 嵌入。为了使用英语嵌入,我们需要下载管道“en_core_web_lg”,这是大型英语语言管道。我们使用 SpaCy 得到标准的 300 维 GloVe 词向量。
import spacy
import nltknlp = spacy.load('en_core_web_lg')total_vectors = len(nlp.vocab.vectors)
print('Total word vectors:', total_vectors)document = ["The rose is red.", "The violet is blue.", "This is some text, just for demonstration"]
tokenized_corpus = [nltk.word_tokenize(doc) for doc in document]vocab = list(set([word for wordlist in tokenized_corpus for word in wordlist]))glovevectors = np.array([nlp(word).vector for word in vocab])#Spacy's nlp pipeline has the vectors for these words
glove_vec_df = pd.DataFrame(glovevectors, index=vocab)
glove_vec_df如果您想查看单词“violet”的手套向量,请使用代码
glove_vec_df.loc['violet']希望查看所有词汇向量?
glovevectors使用 TSNE 可视化数据点
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
tsne = TSNE(n_components = 2, random_state = 42, n_iter = 250, perplexity = 3)
tsneglovemodel = tsne.fit_transform(glovevectors)
labels = vocab
plt.figure(figsize=(12, 6))
plt.scatter(tsneglovemodel[:, 0], tsneglovemodel[:, 1], c='red', edgecolors='r')
for label, x, y in zip(labels, tsneglovemodel[:, 0], tsneglovemodel[:, 1]):
plt.annotate(label, xy=(x+1, y+1), xytext=(0, 0), textcoords='offset points')六 快速文本
FastText 在 Wikipedia 和 Common Crawl 上进行了训练。它包含在 Wikipedia 和 Crawl 上训练的 157 种语言的词向量。它还包含语言识别和各种监督任务的模型。您可以在 gensim 库中试验 FastText 向量。
import warnings
warnings.filterwarnings("ignore")from gensim.models.fasttext import FastText
import nltk
document = ["The rose is red.", "The violet is blue.", "This is some text, just for demonstration"]
tokenized_corpus = [nltk.word_tokenize(doc) for doc in document]fasttext_model = FastText(tokenized_corpus, window = 5, min_count = 1, sg = 1)import warnings
warnings.filterwarnings("ignore")from gensim.models.fasttext import FastText
import nltk
document = ["The rose is red.", "The violet is blue.", "This is some text, just for demonstration"]
tokenized_corpus = [nltk.word_tokenize(doc) for doc in document]fasttext_model = FastText(tokenized_corpus, window = 5, min_count = 1, sg = 1)print('Embedding')
print(fasttext_model.wv['blue'])print('Embedding Shape')
print(fasttext_model.wv['blue'].shape)要查看词汇表中单词的向量,您可以使用此代码
words_fasttext = fasttext_model.wv.index_to_key
wordvectors_fasttext = fasttext_model.wv[words]
wordvectors_fasttext在本系列的下一篇文章中,我们将介绍文本分类。
相关文章:
使用 Python 进行自然语言处理第 4 部分:文本表示
一、说明 本文是在 2023 年 3 月为 WomenWhoCode 数据科学跟踪活动发表的系列文章中。早期的文章位于:第 1 部分(涵盖 NLP 简介)、第 2 部分(涵盖 NLTK 和 SpaCy 库)、第 2 部分(涵盖NLTK和SpaCy库…...
【LLM】大语言模型高效微调方案Lora||直击底层逻辑
大白话: DL的本质就是矩阵的乘法,就能实现LLM, 假设两个矩阵都很大,一个mxn,一个nxd的矩阵,m,n,d这几个数字可能几千甚至上万的场景,计算起来代价很大,如果我们可以small 这些数字,缩小到10甚至5这样的s…...

Qt for Android代码中输出日志
#include <QtDebug>qInfo() << "hello"; 如上,加入头文件(注意:这里的头文件是QtDebug,不是QDebug,也不知道啥时候改的,也不知道有啥区别,先这样吧)后使用qI…...

力扣刷题-二叉树-二叉树的递归遍历
本文讲解二叉树的前序遍历、后序遍历、中序遍历。 思路 每次写递归,都按照这三要素来写,可以保证大家写出正确的递归算法! 确定递归函数的参数和返回值: 确定哪些参数是递归的过程中需要处理的,那么就在递归函数里加…...

VX-3R APRS发射试验
VX-3R本身是不带APRS功能的,不过可能通过外加TNC实现APRS功能。 有大佬已经用Arduino实现了相应的发射功能: https://github.com/handiko/Arduino-APRS 我要做的,就是简单修改一下代码,做一个转接板。 YEASU官方没有给出VX-3R的音…...

JAVA毕业设计109—基于Java+Springboot+Vue的宿舍管理系统(源码+数据库)
基于JavaSpringbootVue的宿舍管理系统(源码数据库)109 一、系统介绍 本系统前后端分离 本系统分为学生、宿管、超级管理员三种角色 1、用户: 登录、我的宿舍、申请调宿、报修申请、水电费管理、卫生检查、个人信息修改。 2、宿管: 登录、用户管理…...

CMU/MIT/清华/Umass提出生成式机器人智能体RoboGen
文章目录 导读1. Introduction2. 论文地址3. 项目主页4. 开源地址5. RoboGen Pipeline6. Experimental Results作者介绍Reference 导读 CMU/MIT/清华/Umass提出的全球首个生成式机器人智能体RoboGen,可以无限生成数据,让机器人7*24小时永不停歇地训练。…...
STM32:AHT20温湿度传感器驱动程序开发
注:温湿度传感器AHT20数据手册.pdf http://www.aosong.com/userfiles/files/AHT20%E4%BA%A7%E5%93%81%E8%A7%84%E6%A0%BC%E4%B9%A6(%E4%B8%AD%E6%96%87%E7%89%88)%20B1.pdf 一、分析AHT数据手册文档 (1).准备工作 1.新建工程。配置UART2 2.配置I2C1为I2C标准模式&…...

【Linux】第七站:vim的使用以及配置
文章目录 一、vim1.vim的介绍2.vim基本使用3.vim的命令模式常用命令4.底行模式 二、vim的配置 一、vim 1.vim的介绍 vim编辑器,用来文本编写,可以写代码 它是一个多模式的编辑器 它有很多的模,不过我们暂时先只考虑这三种模式 命令模式插入模…...

汇编-算术运算符
下面给出了一些有效表达式和它们的值:...
线性代数 第六章 二次型
一、矩阵表示 称为二次型的秩。只含有变量的平方项,所有混合项系数全是零,称为标准形;平方项的系数为1、-1或0,称为规范形。 二次型的标准形不唯一,可以用不用的坐标变换化二次型为标准形;二次型的规范形唯…...
leetCode 213. 打家劫舍 II + 动态规划 + 从记忆化搜索到递推 + 空间优化
关于此题我的往期文章,动规五部曲详解篇: leetCode 213. 打家劫舍 II 动态规划 房间连成环怎么偷呢?_呵呵哒( ̄▽ ̄)"的博客-CSDN博客https://heheda.blog.csdn.net/article/details/133409962213. 打家劫舍 II - 力扣&#x…...
网络编程套接字(二)
目录 简单的TCP网络程序服务端创建套接字服务端绑定服务端监听服务端获取连接服务端处理请求单执行流服务器的弊端 多进程版TCP网络程序捕捉SIGCHLD信号让孙子进程提供服务多线程版的TCP网络程序客户端创建套接字客户端链接服务器客户端发起请求 线程池版的TCP网络程序 简单的T…...
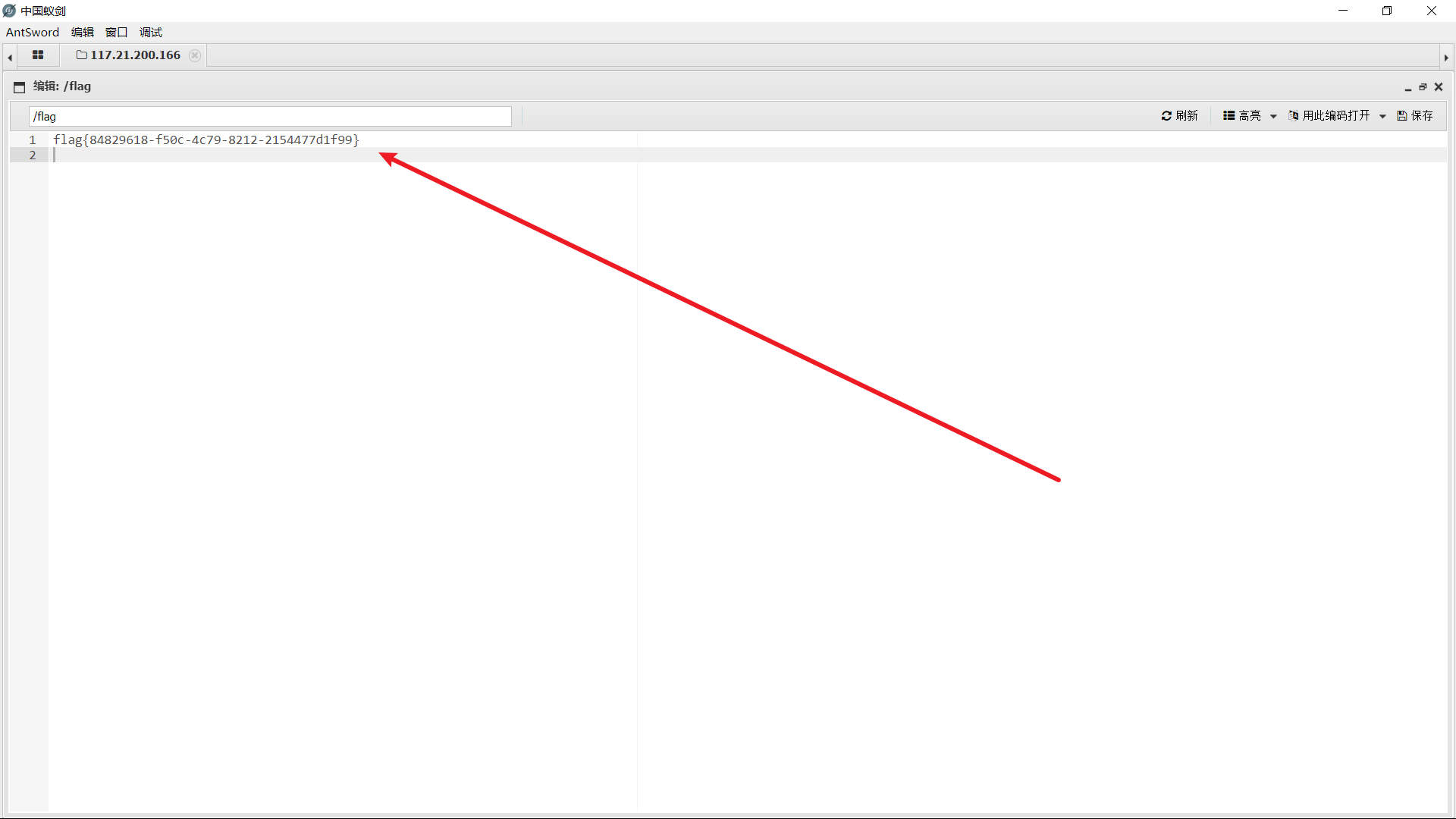
[极客大挑战 2019]Knife 1(两种解法)
题目环境: 这道题主要考察中国菜刀和中国蚁剑的使用方法 以及对PHP一句话木马的理解 咱们先了解一下PHP一句话木马,好吗? **eval($_POST["Syc"]);** **eval是PHP代码执行函数,**把字符串按照 PHP 代码来执行。 $_POST P…...
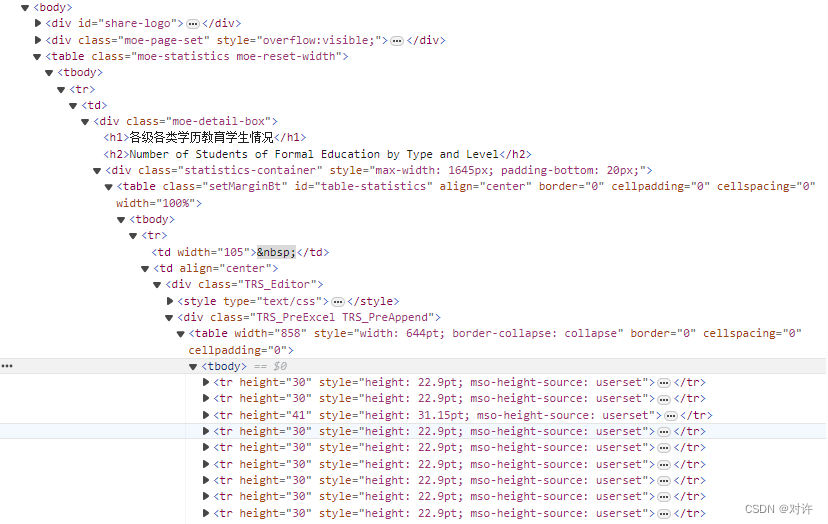
国家统计局教育部各级各类学历教育学生情况数据爬取
教育部数据爬取 1、数据来源2、爬取目标3、网页分析4、爬取与解析5、如何使用Excel打开CSV1、数据来源 国家统计局:http://www.stats.gov.cn/sj/ 教育部:http://www.moe.gov.cn/jyb_sjzl/ 数据来源:国家统计局教育部文献教育统计数据2021年全国基本情况(各级各类学历教育学…...

mysql、clickhouse时间日期加法
mysql 在’2023-10-27 23:59:59’上增加5秒: SELECT DATE_ADD(2023-10-27 23:59:59, INTERVAL 5 second);clickhouse SELECT date_add(SECOND, 3, toDate(2018-01-01 00:00:00));clickhouse时间按秒、分、时、日、月、年作差 按秒: SELECT dateDiff…...

21.合并两个有序链表
#include <iostream>struct ListNode {int val;ListNode* next;ListNode(int x) : val(x), next(nullptr) {} };class Solution { public:ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {ListNode dummy ListNode(-1); // 创建一个虚拟节点作为头节点ListNode* …...

thinkphp漏洞复现
thinkphp漏洞复现 ThinkPHP 2.x 任意代码执行漏洞Thinkphp5 5.0.22/5.1.29 远程代码执行ThinkPHP5 5.0.23 远程代码执行ThinkPHP5 SQL Injection Vulnerability && Sensitive Information Disclosure VulnerabilityThinkPHP Lang Local File Inclusion ThinkPHP 2.x 任…...
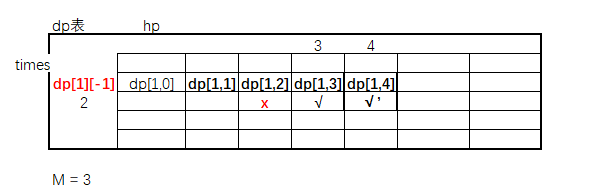
暴力递归转动态规划(十三)
题目 给定3个参数,N,M,K 怪兽有N滴血,等着英雄来砍自己 英雄每一次打击,都会让怪兽流失[0~M]的血量 到底流失多少?每一次在[0~M]上等概率的获得一个值 求K次打击之后,英雄把怪兽砍死的概率。 暴…...
java EE 进阶
java EE 主要是学框架(框架的使用,框架的原理) 框架可以说是实现了部分功能的半成品,还没装修的毛坯房,然后我们再自己打造成自己喜欢的成品 这里学习四个框架 : Spring ,Spring Boot, Spring MVC, Mybatis JavaEE 一定要多练习,才能学好 Maven 目前我们主要用的两个功能: …...
)
模板进阶(C++初阶结束)
1.非类型模板参数模板参数分为类型形参和非类型形参类型形参:出现在模板参数列表中,跟class或者typename之类的参数类型名称非类型形参:就是用一种常量作为类(函数)模板的一个参数,在类(函数&am…...
:API调用失败率<0.8%的私有化部署方案首次公开)
Sora 2国内可用性深度测评(2024Q2最新版):API调用失败率<0.8%的私有化部署方案首次公开
更多请点击: https://intelliparadigm.com 第一章:ChatGPT Sora 2视频生成怎么用 Sora 2 并非 OpenAI 官方发布的模型——截至目前(2024年中),OpenAI 仅公开了 Sora(初代)的演示能力࿰…...

OpenClaw智能体引导基准测试:本地LLM多步骤任务执行能力评估
1. 项目概述:一个专为LLM智能体设计的“开箱即用”能力基准测试 如果你最近在关注本地大语言模型(LLM)和智能体(Agent)的进展,可能会发现一个现象:很多模型在标准问答或代码生成任务上表现不错…...

【Perplexity Pro深度评测】:20年AI工具实战专家拆解3大隐藏成本与5个被忽略的高阶功能值不值得?
更多请点击: https://intelliparadigm.com 第一章:Perplexity Pro订阅值不值得 核心能力对比:免费版 vs Pro版 Perplexity Pro 提供实时联网搜索、多文件上传解析(PDF/DOCX/CSV)、无限次深度追问及自定义AI工作区等关…...
、node = MyNode() 、rclpy.spin(node))
[具身智能-670]:ROS2 Node内部的工作原理:rclpy.init()、node = MyNode() 、rclpy.spin(node)
一、三个函数的一句话功能rclpy.init()初始化 ROS2 全局系统(上下文、信号处理、DDS)。node MyNode()创建节点对象,注册名字,分配通信句柄,不创建线程。rclpy.spin(node)进入主线程死循环,不断检查消息 / …...

OpenClaw本地控制台:一站式图形化管理AI助手工作流
1. 项目概述:一个为本地OpenClaw工作流量身打造的控制台如果你和我一样,在Windows上折腾过OpenClaw,那你肯定经历过这种“精神分裂”式的管理体验:想启动服务,得切到终端敲命令;要改个模型配置,…...

工业 AI 赋能采购:智能供应商匹配重构招标流程
Q1:传统企业采购招标,供应商对接与筛选存在哪些固有痛点?传统工业企业采购招标模式高度依赖人工经验,存在三大核心痛点:供应商资源固化:每次招标都需从零手动联络供应商,仅依靠采购人员个人记忆…...
核心算法,搞定面试高频考点)
C++数据结构进阶|排序:吃透O(n log n)核心算法,搞定面试高频考点
文章目录 前言 一、希尔排序(Shell Sort)—— 插入排序的进阶优化版 二、快速排序(Quick Sort)—— C面试手写高频,实际开发首选 三、归并排序(Merge Sort)—— 稳定排序的核心选择 四、堆排…...

利用Taotoken的API兼容性将现有基于OpenAI的应用快速迁移上线
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken的API兼容性将现有基于OpenAI的应用快速迁移上线 对于已经投入开发并依赖OpenAI官方API的应用,切换到新的…...

AMD Ryzen硬件调试终极指南:深入SMU Debug Tool的完整实战应用
AMD Ryzen硬件调试终极指南:深入SMU Debug Tool的完整实战应用 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...