Elasticsearch 8.X 如何生成 TB 级的测试数据 ?
1、实战问题
我只想插入大量的测试数据,不是想测试性能,有没有自动办法生成TB级别的测试数据?
有工具?还是说有测试数据集之类的东西?
——问题来源于 Elasticsearch 中文社区
https://elasticsearch.cn/question/13129
2、问题解析
其实类似的问题之前在社群也经常被问到。实战业务场景中在没有大规模数据之前,可能会构造生成一些模拟数据,以实现性能测试等用途。
真实业务场景一般不愁数据的,包含但不限于:
生成数据
业务系统产生数据
互联网、设备等采集生成的数据
其他产生数据的场景.....
回归问题,Elasticsearch 8.X 如何构造呢?
社群达人死敌wen大佬给出的方案:两个 sample data的index来回reindex,一次操作数据量翻倍。
实际,死敌 wen 大佬指的是如下三部分的样例数据。
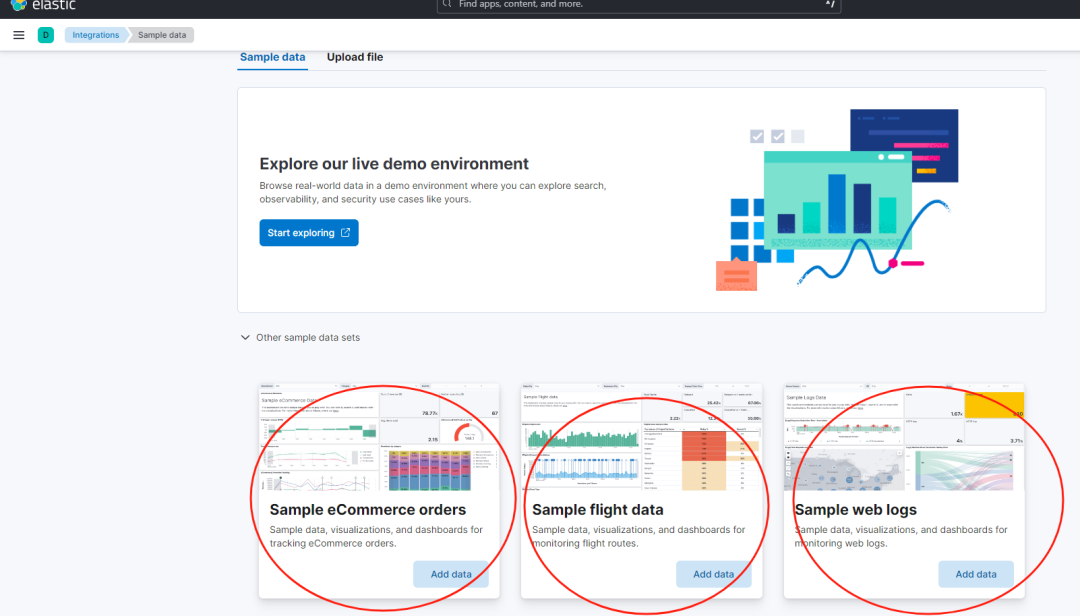
那么有没有其他的解决方案呢?本文给出两种方案。

3、方案一、elasticsearch-faker 构造数据
3.0 elasticsearch-faker 工具介绍
elasticsearch-faker 是一个用于为 Elasticsearch 生成虚假数据的命令行工具。
它通过模板来定义将要生成的数据结构,并在模板中使用占位符来表示动态内容,比如随机用户名、数字、日期等。
这些占位符将由 Faker 库提供的随机生成数据填充。执行时,该工具会根据指定的模板生成文档,并将它们上传到 Elasticsearch 索引中,用于测试和开发,以检验 Elasticsearch 查询和聚合的功能。
3.1 第一步:安装工具集
https://github.com/thombashi/elasticsearch-faker#installation
pip install elasticsearch-faker
3.2 第二步:制作启动脚本 es_gen.sh
#!/bin/bash# 设置环境变量
export ES_BASIC_AUTH_USER='elastic'
export ES_BASIC_AUTH_PASSWORD='psdXXXXX'
export ES_SSL_ASSERT_FINGERPRINT='XXddb83f3bc4f9bb763583d2b3XXX0401507fdfb2103e1d5d490b9e31a7f03XX'# 调用 elasticsearch-faker 命令生成数据
elasticsearch-faker --verify-certs generate --doc-template doc_template.jinja2 https://172.121.10.114:9200 -n 1000同时,编辑模版文件 doc_template.jinja2。
模版如下所示:
{"name": "{{ user_name }}","userId": {{ random_number }},"createdAt": "{{ date_time }}","body": "{{ text }}","ext": "{{ word }}","blobId": "{{ uuid4 }}"
}3.3 第三步:执行脚本 es_gen.sh
[root@VM-0-14-centos elasticsearch-faker]# ./es_gen.sh
document generator #0: 100%|███████████████████████████████████████████████████████████████████████████████████████████| 1000/1000 [00:00<00:00, 1194.47docs/s]
[INFO] generate 1000 docs to test_index[Results]
target index: test_index
completed in 10.6 secs
current store.size: 0.8 MB
current docs.count: 1,000
generated store.size: 0.8 MB
average size[byte]/doc: 831
generated docs.count: 1,000
generated docs/secs: 94.5
bulk size: 200
3.4 第4步:查看导入数据结果, kibana 查看。

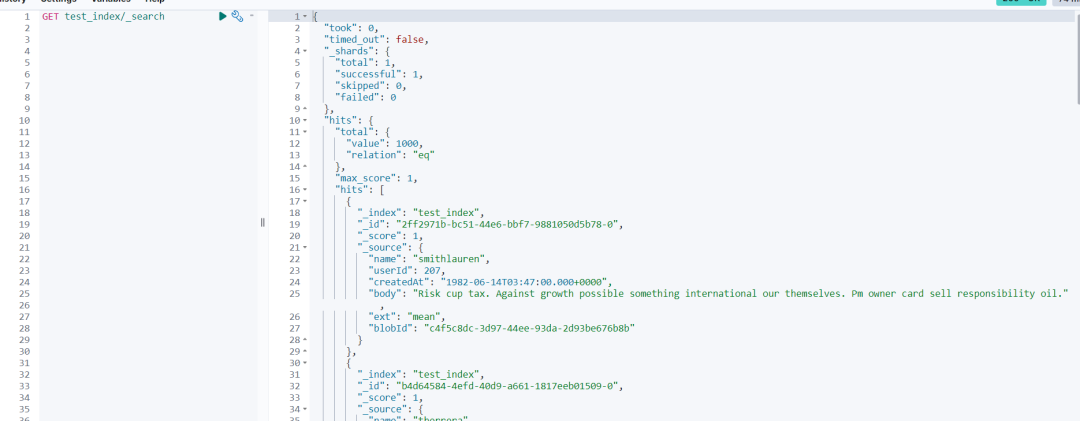
"hits": [{"_index": "test_index","_id": "2ff2971b-bc51-44e6-bbf7-9881050d5b78-0","_score": 1,"_source": {"name": "smithlauren","userId": 207,"createdAt": "1982-06-14T03:47:00.000+0000","body": "Risk cup tax. Against growth possible something international our themselves. Pm owner card sell responsibility oil.","ext": "mean","blobId": "c4f5c8dc-3d97-44ee-93da-2d93be676b8b"}},{4、使用 Logstash generator 插件生成随机样例数据

4.1 准备环境
确保你的环境中已经安装了 Elasticsearch 8.X 和 Logstash 8.X。Elasticsearch 应该配置正确,并且运行在 HTTPS 上。
另外,确保 Elasticsearch 的相关证书已经正确配置在 Logstash 中。
4.2 生成样例数据
我们将使用 Logstash 的 generator 输入插件来创建数据,并使用 ruby 过滤器插件来生成 UUID 和随机字符串。
4.3 Logstash 配置
创建一个名为 logstash-random-data.conf 的配置文件,并填入以下内容:
input {generator {lines => ['{"regist_id": "UUID", "company_name": "RANDOM_COMPANY", "regist_id_new": "RANDOM_NEW"}']count => 10codec => "json"}
}filter {ruby {code => 'require "securerandom"event.set("regist_id", SecureRandom.uuid)event.set("company_name", "COMPANY_" + SecureRandom.hex(10))event.set("regist_id_new", SecureRandom.hex(10))'}
}output {elasticsearch {hosts => ["https://172.121.110.114:9200"]index => "my_log_index"user => "elastic"password => "XXXX"ccacert => "/www/elasticsearch_0810/elasticsearch-8.10.2/config/certs/http_ca.crt"}stdout { codec => rubydebug }
}4.4 分析配置文件
1.Input
a.generator 插件用于生成事件流。
b.lines 包含一个 JSON 字符串模板,它定义了每个事件的结构。
c.count 指定了要生成的文档数量。
d.codec 设置为 json 以告诉 Logstash 期望的输入格式。
2.Filter
a.ruby 过滤器用于执行 Ruby 代码。
b.代码片段内生成了一个 UUID 作为 regist_id。
c.company_name 和 regist_id_new 使用随机十六进制字符串填充。
3.Output
a.指定 Elasticsearch 的主机、索引、用户认证信息及证书。
b.stdout 输出用于调试,它会输出 Logstash 处理后的事件。
4.5 运行 Logstash
将配置文件保存后,在终端运行以下命令以启动 Logstash 并生成数据:
$ bin/logstash -f logstash-random-data.conf执行结果如下:
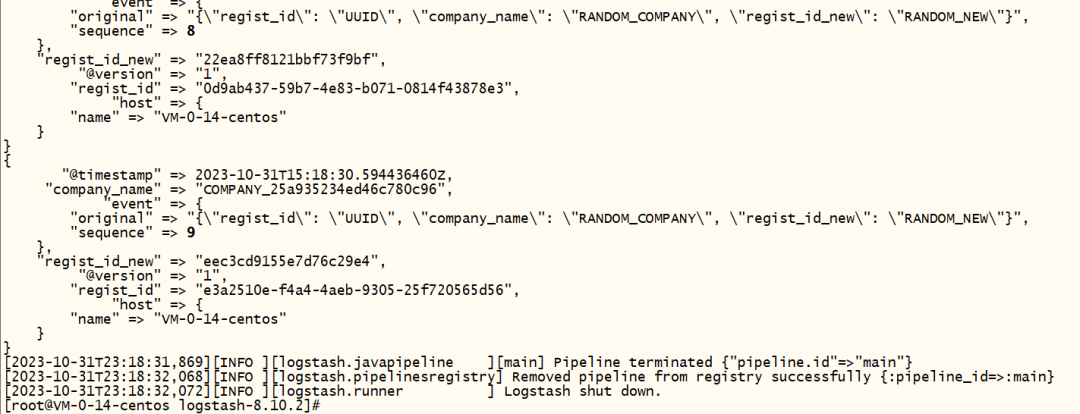
kibana 查看数据结果如下:
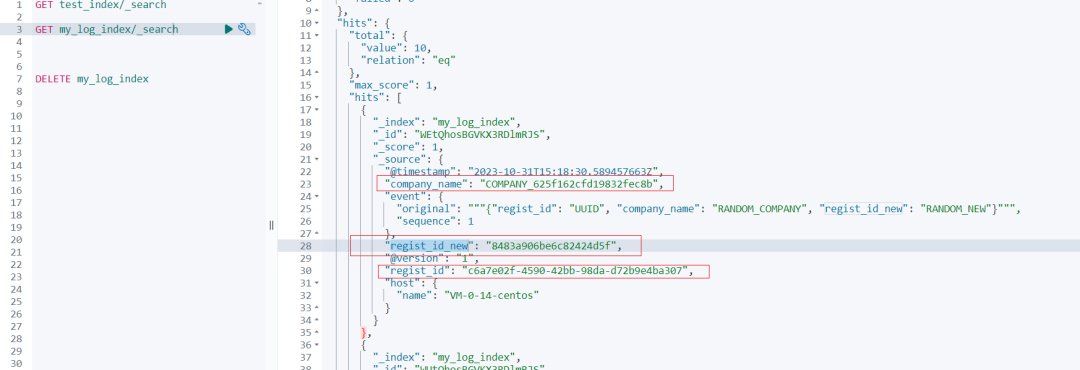
借助 Logstash,我们可以轻松生成大量的随机样例数据,用于 Elasticsearch 的测试和开发。这种方法不仅高效,而且可以灵活地根据需求生成各种格式的数据。
5、小结
上述的验证都是使用 Elasticsearch 8.10.2 版本验证通过的。
其实除了文章给出的两种方案外,还有很多其他的方案,比如:esrally 生成测试数据、借助 Python 的 Faker 实现样例数据构造,Common Crawl、Kaggle 等网站提供大型的公共数据集,可以作为测试数据的来源。
大家有没有遇到类似问题,是如何实现的?欢迎留言交流。
推荐阅读
全网首发!从 0 到 1 Elasticsearch 8.X 通关视频
重磅 | 死磕 Elasticsearch 8.X 方法论认知清单
如何系统的学习 Elasticsearch ?
那些 ChatGPT4 也搞不定的 Elasticsearch 问题,请抛给我们!

更短时间更快习得更多干货!
中国50%+Elastic认证专家出自于此!

比同事抢先一步学习进阶干货!
相关文章:
Elasticsearch 8.X 如何生成 TB 级的测试数据 ?
1、实战问题 我只想插入大量的测试数据,不是想测试性能,有没有自动办法生成TB级别的测试数据?有工具?还是说有测试数据集之类的东西?——问题来源于 Elasticsearch 中文社区https://elasticsearch.cn/question/13129 2…...
汽车标定技术(四)--问题分析:多周期测量时上位机显示异常
目录 1.问题现象 2.数据流分析 3.代码分析 3.1 AllocDAQ 3.2 AllocOdt 3.3 AllocOdtEntry 4.根因分析及解决方法 4.1 根因分析 4.2 解决方案 1.问题现象 在手撸XCP代码时, DAQ的实现是一大头痛的事情。最初单周期实现还好一点,特别是…...
Flink SQL时间属性和窗口介绍
(1)概述 时间属性(time attributes),其实就是每个表模式结构(schema)的一部分。它可以在创建表的 DDL 里直接定义为一个字段,也可以在 DataStream 转换成表时定义。 一旦定义了时间…...
Tomcat免安装版修改标题名称和进程
tomcat免安装版启动后闪退问题 问题描述 在官网下载的tomcat免安装版的你安装完环境后发现启动闪退,tomcat启动依赖环境是JDK,所以需要tomcat对应版本的JDK支持。 tomcat8官网下载地址:https://tomcat.apache.org/ JDK环境官网下载地址&…...

vim搜索、替换tab
bibtex 中的缩进可能不一致,强迫症犯了想将: 缩进空格改 tab;行首的多个 tab 改为单个 参考 [1],空格换 tab 可以: :set noexpandtab :%retab!行首的多个 tab 换单个: :%s/^\t\/\t/gReferences Replac…...

一文读懂ARM安全性架构和可信系统构建要素
一文读懂ARM安全性架构和可信系统构建要素 所谓可信系统(trusted system),即能够用于保护密码和加密密钥等资产(assets)免受一系列的可信攻击,防止其被复制、损坏或不可用(unavailable…...
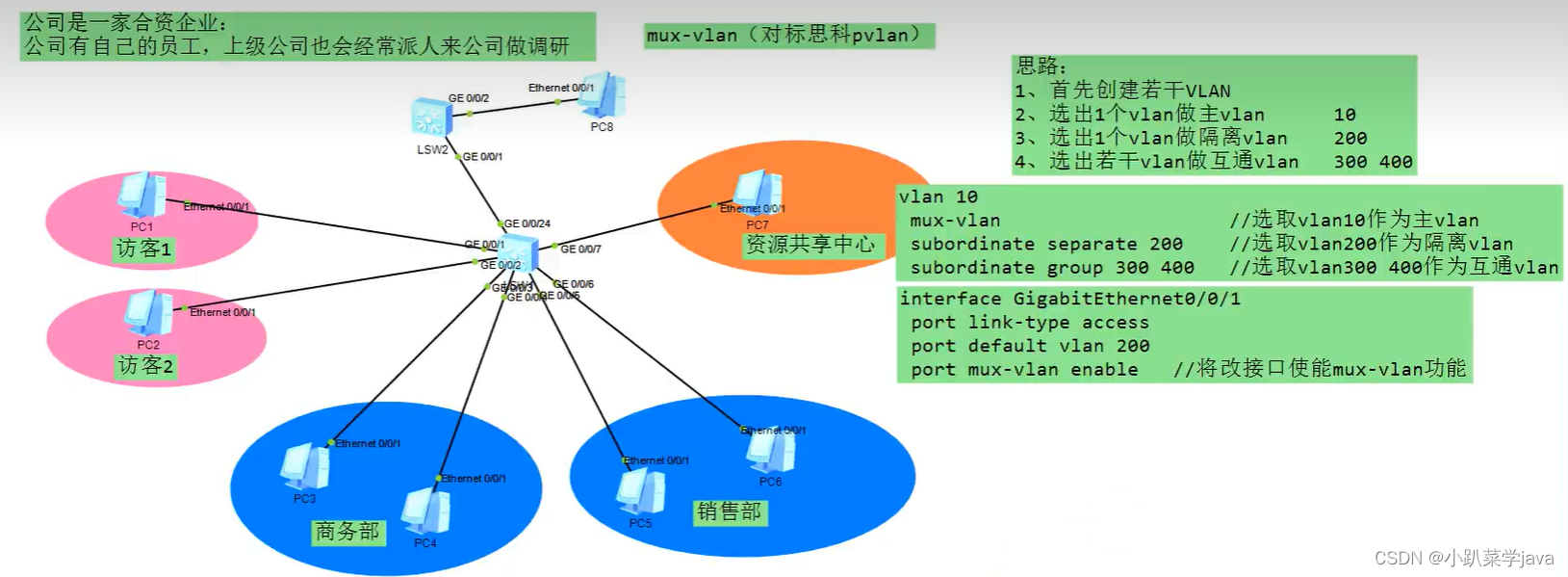
Voice vlan、ICMP、单臂路由、mux-vlan
目录 一,Voice VLAN Voice vlan配置命令 一,问:已知网络中一台服务器的IP地址,如何找到这太服务器在哪台交换机的哪个接口上编辑 思路: 二,ICMP协议 三,ICMP案例分析编辑 四…...
 理解select和epoll的使用)
TCP IP 网络编程(七) 理解select和epoll的使用
文章目录 理解select函数select函数的功能和调用顺序设置文件描述符设置监视范围及超时select函数调用示例 优于select的epoll基于select的I/O复用速度慢实现epoll时必要的函数和结构体epoll_createepoll_ctlepoll_wait基于epoll的服务器端 边缘触发和水平触发 理解select函数 …...

Linux accept和FD_xxx的使用
Linux socket accept功能的作用是在服务器端等待并接受客户端的连接请求。当有客户端尝试连接服务器时,服务器调用accept函数来接受该连接请求,并创建一个新的socket来与该客户端进行通信。 具体来说,accept函数被动监听客户端的三次握手连接…...
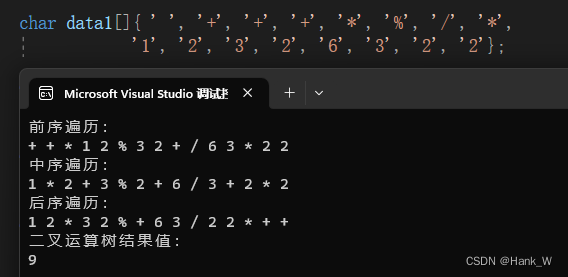
树结构及其算法-二叉运算树
目录 树结构及其算法-二叉运算树 C代码 树结构及其算法-二叉运算树 二叉树的应用实际上相当广泛,例如表达式之间的转换。可以把中序表达式按运算符优先级的顺序建成一棵二叉运算树(Binary Expression Tree,或称为二叉表达式树)…...

vue的rules验证失效,部分可以部分又失效的原因
vue的rules验证失效,部分可以部分又失效的原因 很多百度都有,但是我这里遇到了一个特别的,那就是prop没有写全,导致验证某一个失效 例子: 正常写法 el-form-item....多个省略<el-form-item label"胶币" prop"cost"><el-input v-model"form.…...

c#字符串转整数类型
将字符串转换为整数类型。为了方便,C#提供了一个内置的方法TryParse来实现这个功能 字符串(String):表示一串字符的数据类型。整数(Integer):表示不带小数点的数字。解析(Parsing&a…...

【LeetCode】118. 杨辉三角
118. 杨辉三角 难度:简单 题目 给定一个非负整数 *numRows,*生成「杨辉三角」的前 numRows 行。 在「杨辉三角」中,每个数是它左上方和右上方的数的和。 示例 1: 输入: numRows 5 输出: [[1],[1,1],[1,2,1],[1,3,3,1],[1,4,6,4,1]]示例…...
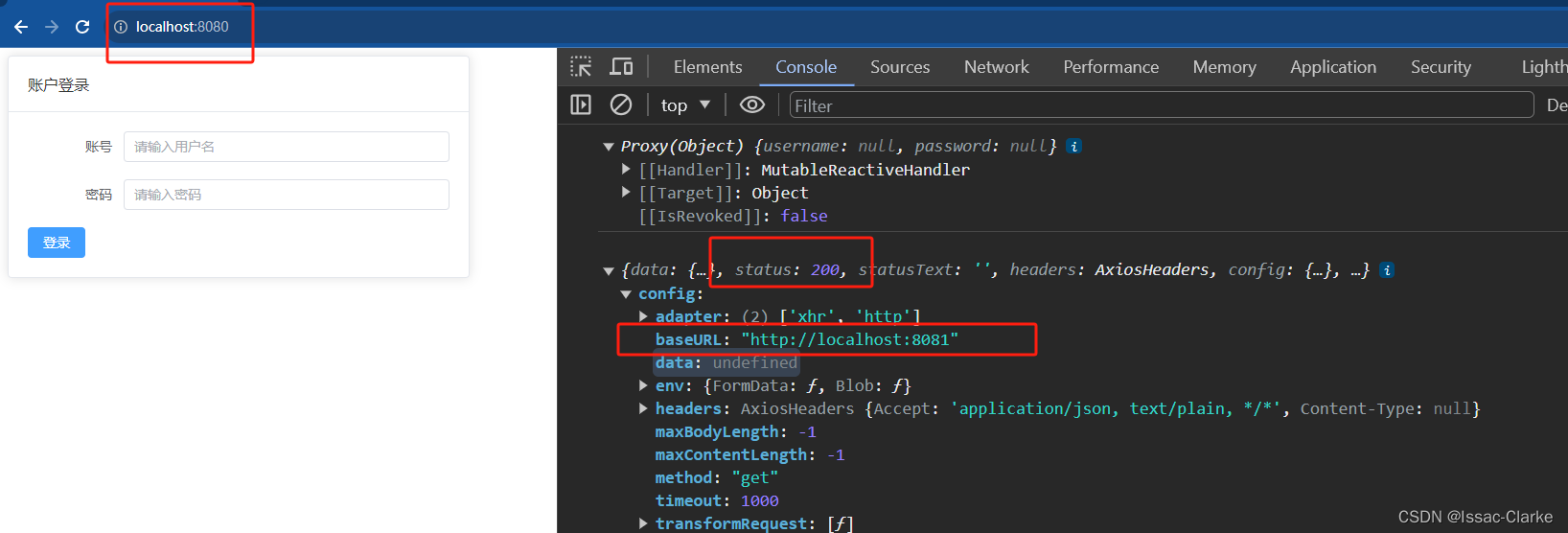
【Vue.js】Vue3全局配置Axios并解决跨域请求问题
系列文章目录 文章目录 系列文章目录背景一、部署Axios1. npm 安装 axios2. 创建 request.js,创建axios实例3. 在main.js中全局注册axios4. 在页面中使用axios 二、后端解决跨域请求问题方法一 解决单Contoller跨域访问方法二 全局解决跨域问题 背景 对于前后端分离…...

【车载开发系列】CRC循环冗余校验码原理
【车载开发系列】CRC循环冗余校验码原理 CRC循环冗余校验码原理 【车载开发系列】CRC循环冗余校验码原理一. CRC算法原理二. 生成多项式三. 多项式与其对应代码四. CRC码校验原理1)发送端2)接收端 五. CRC码原理方法1)发送端生成CRC码方法2&a…...
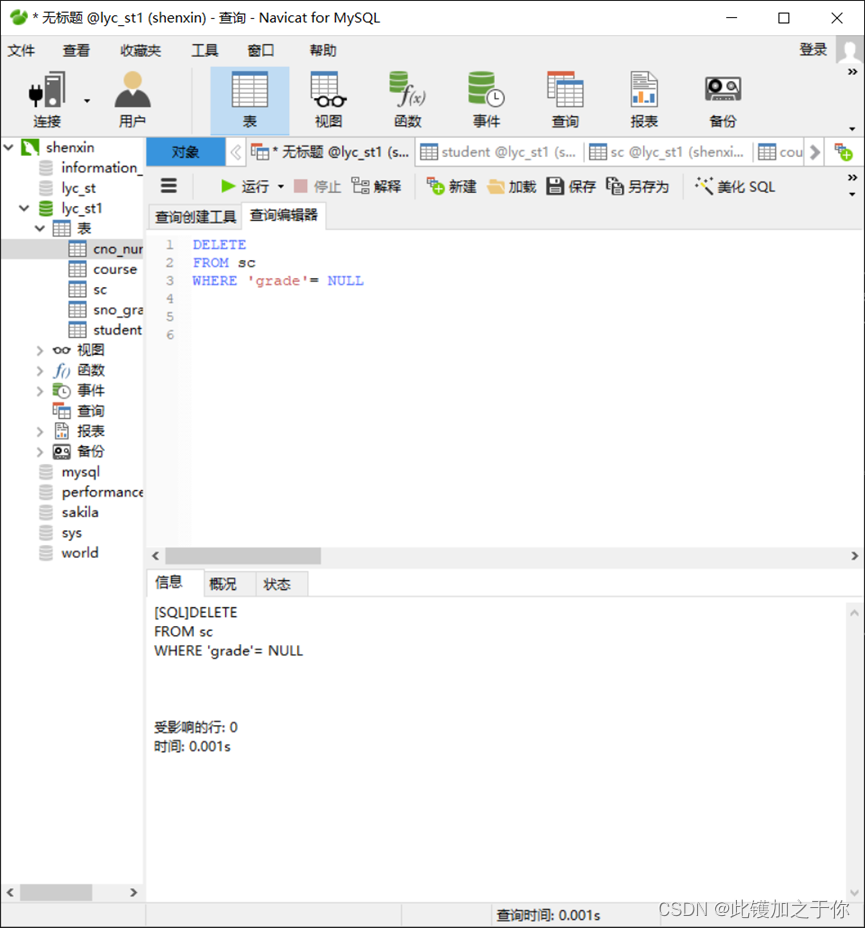
数据库实验:SQL的数据更新
目录 实验目的实验内容实验要求实验步骤实验过程总结 再次书接上文,sql基础的增删改查 实验目的 (1) 掌握DBMS的数据查询功能 (2) 掌握SQL语言的数据更新功能 实验内容 (1) update 语句用于对表进行更新 (2) delete 语句用于对表进行删除 (3) insert 语句用于对表…...
3.线性神经网络-3GPT版
#pic_center R 1 R_1 R1 R 2 R^2 R2 目录 知识框架No.1 线性回归基础优化算法一、线性回归1、买房案例2、买房模型简化3、线性模型4、神经网络5、损失函数6、训练数据7、参数学习8、显示解9、总结 二、 基础优化算法1、梯度下降2、学习率3、小批量随机梯度下降4、批量大小5、…...

大语言模型对齐技术 最新论文及源码合集(外部对齐、内部对齐、可解释性)
大语言模型对齐(Large Language Model Alignment)是利用大规模预训练语言模型来理解它们内部的语义表示和计算过程的研究领域。主要目的是避免大语言模型可见的或可预见的风险,比如固有存在的幻觉问题、生成不符合人类期望的文本、容易被用来执行恶意行为等。 从必…...

x264交叉编译(ubuntu+arm)
1.下载源码 https://code.videolan.org/videolan/x264 在windows下解压;复制到ubuntu; 2.进入源码文件夹-新建脚本文件 touch sp_run.sh 3.在sp_run.sh文件中输入 #!/bin/sh./configure --prefix/home/alientek/sp_test/x264/sp_install --enable-…...

SpringMVC 处理后端日期格式
通过扩展Spring MVC框架的消息转化器 在WebMvcConfiguration中扩展SpringMVC的消息转换器,统一对日期类型进行格式处理 WebMvcConfiguration /*** 扩展Spring MVC框架的消息转化器* param converters*/protected void extendMessageConverters(List<HttpMessag…...

OpenClaw技能安装失败全解析:从依赖冲突到网络问题的系统性解决方案
1. 项目概述:当技能“卡住”时,我们遇到了什么?最近在折腾OpenClaw这类开源AI助手平台时,不少朋友都踩进了同一个坑:从官方市场或者第三方渠道找到了心仪的技能(Skill),点击“安装”…...

开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南
开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发…...

【python】ImportError: DLL load failed while importing QtWidgets: 找不到指定的程序。重新安装后搞定
文章目录前言一、PyQt6引用后报错二、使用步骤总结前言 想做个好看的界面,引用了PyQt6,却产生了新问题。 pip install pyqt6-tools,优先做这个动作进行修复。 一、PyQt6引用后报错 python里引用: from PyQt6.QtWidgets import…...

多模型聚合平台如何助力网站AIB测试与选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 多模型聚合平台如何助力网站AIB测试与选型 对于网站产品经理而言,首页文案的生成质量直接影响用户的第一印象和转化率。…...
)
DeepSeek安全测试辅助Prompt工程白皮书(含17个CVE靶场验证指令模板)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek安全测试辅助 DeepSeek系列大模型在代码生成、漏洞模式识别与安全上下文理解方面展现出独特优势,可作为安全测试工程师的智能协作者。其对OWASP Top 10、CWE分类体系及常见PoC结构具…...

终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接
终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在数字化制造和工程设计领域,STL到STEP转换已成为连接3D…...
)
【独家首发】DeepSeek官方未公开的集成测试Checklist(含23项生产环境准入阈值与压测基线)
更多请点击: https://codechina.net 第一章:DeepSeek集成测试方案 DeepSeek模型的集成测试需覆盖推理服务稳定性、多模态输入兼容性、上下文长度边界及API协议一致性四大核心维度。测试环境基于Kubernetes集群部署,采用PrometheusGrafana监控…...

别再只会用spline了!MATLAB csape函数详解:从自然边界到夹持边界的实战选择
MATLAB csape函数深度解析:从自然边界到夹持边界的工程实践 在工程仿真和科学计算领域,数据插值是一个永恒的话题。当我们面对一组离散的实验数据或仿真结果时,如何构建一条光滑的曲线来准确反映数据背后的物理规律?这个问题困扰…...

开源吉他谱编辑神器TuxGuitar:从新手到专业编曲的完整指南
开源吉他谱编辑神器TuxGuitar:从新手到专业编曲的完整指南 【免费下载链接】tuxguitar Open source guitar tablature editor 项目地址: https://gitcode.com/gh_mirrors/tu/tuxguitar 想要免费创作专业的吉他乐谱吗?TuxGuitar这款开源吉他谱编辑…...

SSH 远程连接效率提升:5个你可能不知道的实用技巧
SSH 是后端开发中最常用的远程连接工具之一。但大多数人只用 ssh userhost 连上去就完了,其实 SSH 还有很多隐藏技巧可以大幅提升效率。1. 使用配置文件简化连接每次敲一长串 ssh user192.168.1.100 -p 2222 太麻烦了。只需在 ~/.ssh/config 里加上:Host…...