PyTorch入门学习(十二):神经网络-搭建小实战和Sequential的使用
目录
一、介绍
二、先决条件
三、代码解释
一、介绍
在深度学习领域,构建复杂的神经网络模型可能是一项艰巨的任务,尤其是当您有许多层和操作需要组织时。幸运的是,PyTorch提供了一个方便的工具,称为Sequential API,它简化了神经网络架构的构建过程。在本文中,将探讨如何使用Sequential API构建一个用于图像分类的卷积神经网络(CNN)。接下来将详细探讨每部分代码,并讨论每个组件,并清楚地了解如何在项目中充分利用PyTorch的Sequential API。
二、先决条件
- 对神经网络和PyTorch有基本了解。
- 安装了PyTorch的Python环境。
三、代码解释
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
在此代码片段中,导入了必要的库,包括PyTorch及其用于神经网络操作的模块,以及用于TensorBoard可视化的SummaryWriter。
class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.model1 = Sequential(Conv2d(3, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10),)
Tudui类定义了神经网络模型。并使用Sequential API创建一系列层和操作,而不是逐一定义每个层并分别管理它们。在这种情况下,我们有三个卷积层,每个卷积层后跟一个最大池化层。然后,将输出展平并添加两个全连接(线性)层。这些层是按顺序定义的,使代码更加简明和可读。
def forward(self, x):x = self.model1(x)return x
在forward方法中,通过模型构造函数传递输入张量x。由于层在self.model1中按顺序组织,并不需要在前向传递中单独调用每个层。这简化了代码并增强了其清晰度。
tudui = Tudui()
创建了Tudui模型的一个实例。
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
生成一个形状为(64, 3, 32, 32)的示例输入张量,并将其通过模型传递以获得输出。
writer = SummaryWriter("logs")
writer.add_graph(tudui, input)
writer.close()
为了使用TensorBoard可视化模型的架构和计算图,所以创建了一个SummaryWriter并添加了图形。这一步对于调试和理解数据流经网络的过程非常有价值。
完整代码如下:
"""
输入大小为3*32*32
经过3次【5*5卷积核卷积-2*2池化核池化】操作后,输出为64*4*4大小
展平后为1*1024大小
经过全连接层后输出为1*10
"""
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriterclass Tudui(nn.Module):def __init__(self):super(Tudui,self).__init__()# self.conv1 = Conv2d(3,32,5,padding=2)# # self.maxpool1 = MaxPool2d(2)# # self.conv2 = Conv2d(32,32,5,padding=2)# # self.maxpool2 = MaxPool2d(2)# # self.conv3 = Conv2d(32,64,5,padding=2)# # self.maxpool3 = MaxPool2d(2)# # self.flatten = Flatten()# # self.linear1 = Linear(1024,64)# # self.linear2 = Linear(64,10)
# 构建一个序列化的container,可以把想要在神经网络中添加的操作都放进去,按顺序进行执行。self.model1 =Sequential(Conv2d(3, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10),)"""可以看到上面神经网络进行搭建时非常繁琐,在init中进行了多个操作的定以后需要在forward中逐次进行调用,因此我们使用sequential方法,在init方法中直接定义一个model,然后在下面的forward方法中直接使用一次model即可。"""def forward(self,x):# x = self.conv1(x)# x = self.maxpool1(x)# x = self.conv2(x)# x = self.maxpool2(x)# x = self.conv3(x)# x = self.maxpool3(x)# x = self.flatten(x)# x = self.linear1(x)# x = self.linear2(x)x = self.model1(x)return xtudui = Tudui()
print(tudui)
input = torch.ones((64,3,32,32))
output = tudui(input)
print(output.shape)writer = SummaryWriter("logs")
writer.add_graph(tudui,input)
writer.close()参考资料:
视频教程:PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】
相关文章:
:神经网络-搭建小实战和Sequential的使用)
PyTorch入门学习(十二):神经网络-搭建小实战和Sequential的使用
目录 一、介绍 二、先决条件 三、代码解释 一、介绍 在深度学习领域,构建复杂的神经网络模型可能是一项艰巨的任务,尤其是当您有许多层和操作需要组织时。幸运的是,PyTorch提供了一个方便的工具,称为Sequential API,…...

Linux shell编程学习笔记20:case ... esac、continue 和break语句
一、case ... esac语句说明 在实际编程中,我们有时会请到多条件多分支选择的情况,用if…else语句来嵌套处理不烦琐,于是JavaScript等语言提供了多选择语句switch ... case。与此类似,Linux Shell脚本编程中提供了case...in...esa…...

树莓派4无法进入桌面模式(启动后出现彩色画面,然后一直黑屏,但是可以正常启动和ssh)
本文记录了这段比较坎坷的探索之路,由于你的问题不一定是我最终解决方案的,可能是前面探索路上试过的,所以建议按顺序看排除前置问题。 双十一又买了个树莓派 4B,插上之前树莓派 4B 的 TF 卡直接就能使用(毕竟是一样规…...

花草世界生存技能
多菌灵 杀菌常用 阿维菌素 杀虫常用 除蚜虫 吡虫啉 有毒性 内吸性(植物吸收) 苦参碱 无毒,中药提取 内吸性药 吡虫啉,噻虫嗪、啶虫脒、苦参碱 栀子花 春秋花后修剪 牡丹 秋冬种植; 洛阳产地; 肥料 …...
执行npm install时老是安装不成功node-sass的原因和解决方案
相信你安装前端项目所需要的依赖包(npm install 或 yarn install)时,有可能会出现如下报错: D:\code\**project > yarn install ... [4/4] Building fresh packages... [-/6] ⠁ waiting... [-/6] ⠂ waiting... [-/6] ⠂ wai…...

【MongoDB】集群搭建实战 | 副本集 Replica-Set | 分片集群 Shard-Cluster | 安全认证
文章目录 MongoDB 集群架构副本集主节点选举原则搭建副本集主节点从节点仲裁节点 连接节点添加副本从节点添加仲裁者节点删除节点 副本集读写操作副本集中的方法 分片集群分片集群架构目标第一个副本集第二个副本集配置集初始化副本集路由集添加分片开启分片集合分片删除分片 安…...
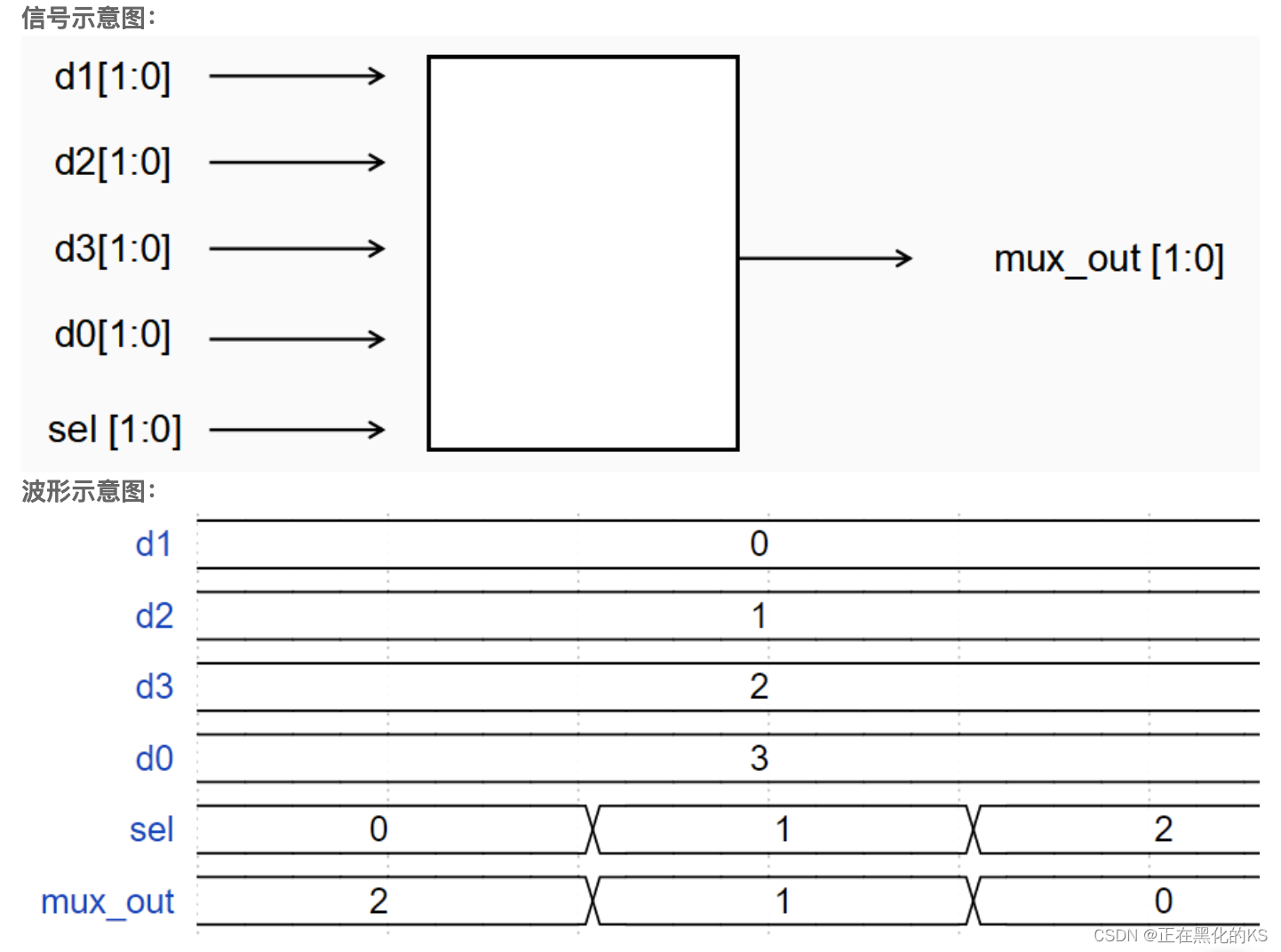
「Verilog学习笔记」四选一多路器
专栏前言 本专栏的内容主要是记录本人学习Verilog过程中的一些知识点,刷题网站用的是牛客网 分析 通过波形示意图我们可以发现,当sel为0,1,2时,输出mux_out分别为d3,d2,d1,那么sel3…...
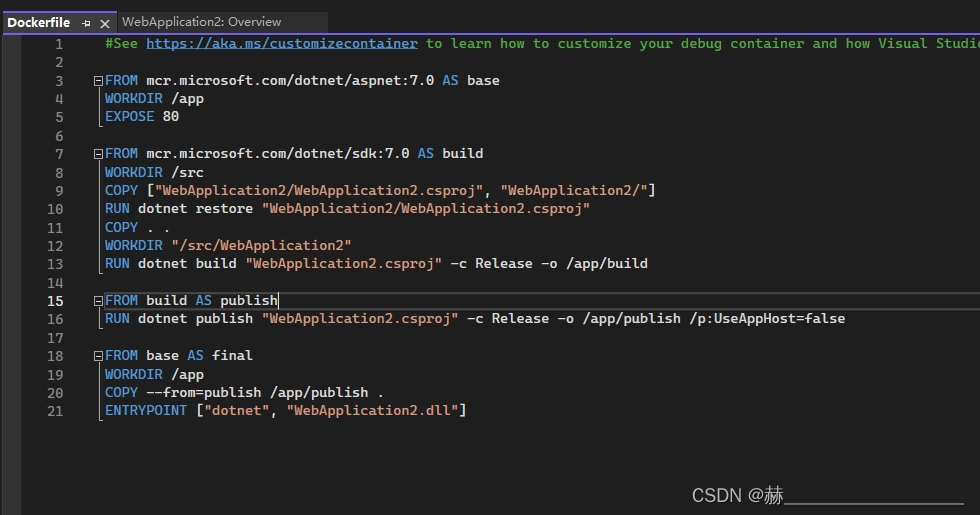
asp.net 创建docker容器
首先创建asp.net web api 创建完成后如下图 添加docker支持 添加docker支持 添加linux docker支持...

Linux项目自动化构建工具-make/Makefile使用
make/Makefile使用介绍 make是一个命令makefile是一个在当前目录下存在的一个具有特定格式的文本文件 下面我们设计一个场景,实现make命令对我们code.c文件进行编译和删除。 1 #include<stdio.h> 2 3 int main() 4 { 5 printf("hello,world!…...
【React】03.脚手架的进阶应用
文章目录 暴露webpack配置暴露前后的区别config文件夹:scripts文件夹:package.json 常见的配置修改1.把sass改为less2.配置别名3.修改域名和端口号4.修改浏览器兼容5.处理Proxy跨域 2023年最新珠峰React全家桶【react基础-进阶-项目-源码-淘系-面试题】 …...
WPF开源控件HandyControl——零基础教程
学习Handycontrol的过程中,为后边快速开发,写的零基础教程,尽量看完就可以实践! 参考教程 中文文档:欢迎使用HandyControl | HandyOrg Github代码:https://github.com/HandyOrg/HandyControl 使用教程:WPF-HandyControl安装和使用 - 掘金 安装配置教程 创建wpf项目 …...
chinese-stable-diffusion中文场景文生图prompt测评集合
腾讯混元大模型文生图操作指南.dochttps://mp.weixin.qq.com/s/u0AGtpwm_LmgnDY7OQhKGg腾讯混元大模型再进化,文生图能力重磅上线,这里是一手实测腾讯混元的文生图在人像真实感、场景真实感上有比较明显的优势,同时,在中国风景、动…...

K-均值聚类算法
K-均值聚类算法是一种常用的无监督学习算法,目的是将一组数据点分为 K 个聚类。它的主要思想是通过迭代的方式不断调整聚类中心的位置,使得数据点与最近的聚类中心之间的距离最小。 算法步骤如下: 初始化 K 个聚类中心,可以随机…...

Xbox漫游指南
以Xbox series s为例 开机启动 用手柄连接,注意两颗电池要方向相反插入,虽然里面2个插槽长一样; Xbox APP极其难用,放弃,直接用手柄连接 转区 只需要一个空U盘,大小不限制,格式化为NTPS格式…...

降低毕业论文写作压力的终极指南
亲爱的同学们,时光荏苒,转眼间你们即将踏入毕业生的行列。毕业论文作为本科和研究生阶段的重要任务,不仅是对所学知识的综合运用,更是一次对自己学术能力和专业素养的全面考验。然而,论文写作常常伴随着压力和焦虑&…...
 与SELECT COUNT( 1 ) 区别)
SELECT COUNT( * ) 与SELECT COUNT( 1 ) 区别
在 SQL 中,SELECT COUNT(*) 和 SELECT COUNT(1) 都用于统计符合条件的行数,但它们在具体实现和效率上有一些区别。 SELECT COUNT(*):这是一种常见且通用的写法,它会统计所有符合查询条件的行数,包括所有列,…...

[python 刷题] 1248 Count Number of Nice Subarrays
[python 刷题] 1248 Count Number of Nice Subarrays 题目如下: Given an array of integers nums and an integer k. A continuous subarray is called nice if there are k odd numbers on it. Return the number of nice sub-arrays. 这道题和 1343 Number of S…...
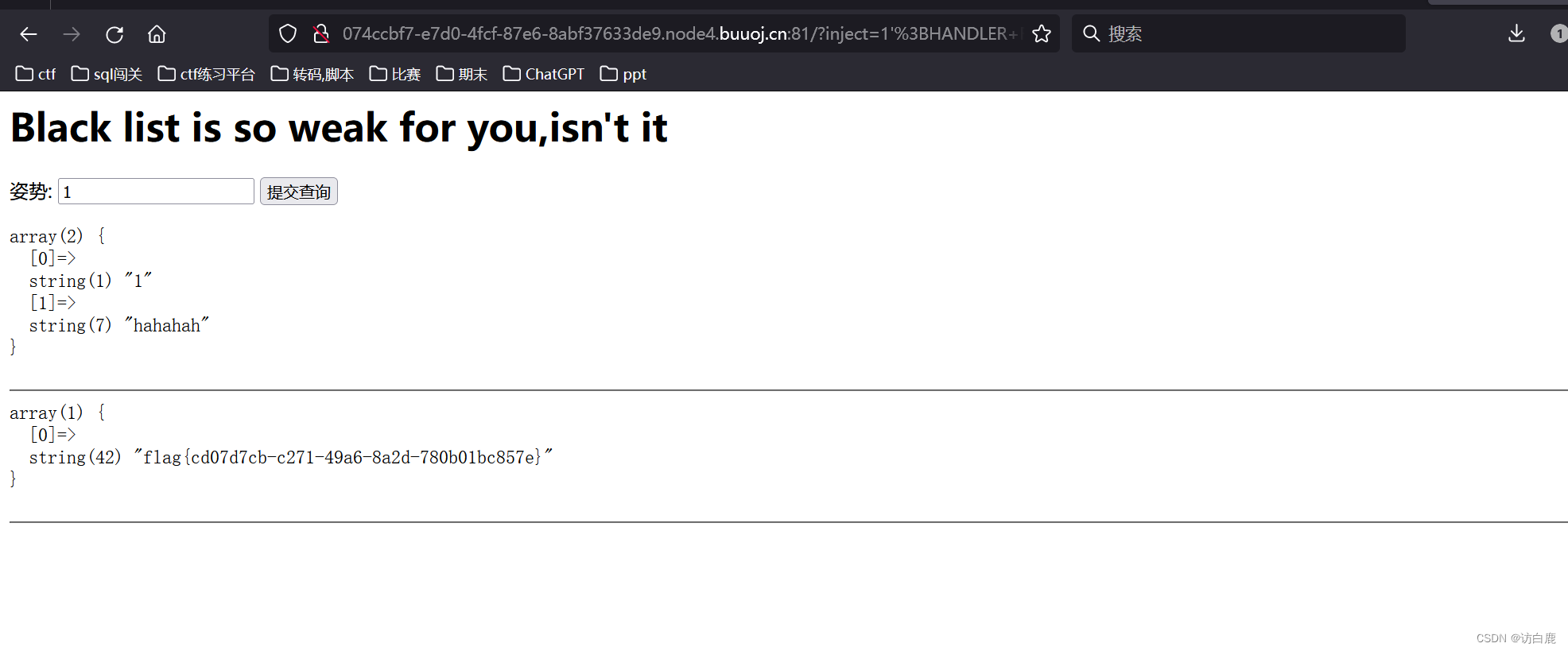
堆叠注入 [GYCTF2020]Blacklist1
打开题目 判断注入点 输入1,页面回显 输入1 页面报错 输入 1 # 页面正常,说明是单引号的字符型注入 我们输入1; show databases; # 说明有6个数据库 1; show tables; # 说明有三个表 我们直接查看FlagHere的表结构 1;desc FlagHere;# 发…...

算法:Java构建二叉树并递归实现二叉树的前序、中序、后序遍历
先自定义一下二叉树的类: // Definition for a binary tree node. public class TreeNode {int val;TreeNode left;TreeNode right;TreeNode() {}TreeNode(int val) { this.val val; }TreeNode(int val, TreeNode left, TreeNode right) {this.val val;this.left…...

既然有了字节流,为什么还要有字符流?
字符流和字节流之间的区别主要在于它们处理数据的方式和用途: 字节流:字节流以字节为单位进行数据的读取和写入,适用于处理二进制数据,如图像、音频和视频文件。字节流是处理底层数据的理想选择,它不会对数据进行编码…...

基于可解释机器学习的城市人口流动空间降尺度分析实践
1. 项目概述:从宏观到微观,解码城市脉搏在城市的肌理中,人口的流动如同血液的循环,承载着经济活力、社会互动与空间结构的全部信息。无论是城市规划师优化公交线路,还是商业分析师评估店铺选址,亦或是公共卫…...

超低功耗电池电压监控电路设计:从LM324到LPV324的硬件方案优化
1. 项目概述与核心需求解析在捣鼓各种电池供电的电子设备时,无论是自己做的无线传感器节点、便携式小工具,还是给孩子改装的玩具,有一个问题总是绕不开:你怎么知道电池快没电了?总不能每次都等到设备彻底罢工ÿ…...

还在手动触发Lindy子任务?这6个隐藏API+3个低代码集成技巧,今天就能上线全自动流水线
更多请点击: https://kaifayun.com 第一章:Lindy多步骤任务自动化的价值与演进路径 Lindy效应指出,一项技术的预期剩余寿命与其当前已存在时间正相关;在自动化领域,Lindy原则催生了对“经久验证、语义稳定、可组合性强…...

如何精准识别高校院所与企业之间的潜在合作机会?
核心要点 传统“相亲角”式校企对接效率低下,根源在于科研供给与市场需求间的信息断层,必须转向以数据驱动、模型研判为核心的精准识别机制,才能将模糊的产学研线索转化为可落地的合作机会。精准识别合作机会的关键在于分拆为“供给侧”与“需…...

别再手动重写了!用Matlab R2020b把算法打包成DLL,在Visual Studio 2017里直接调用
从Matlab到C的无缝衔接:算法封装与DLL调用的高效实践 在工程开发中,我们常常面临一个经典困境:算法原型已经用Matlab验证通过,却需要在C项目中重新实现。这不仅浪费时间,还可能引入新的错误。本文将介绍一种更聪明的做…...

UE4.26实战:用蒙太奇和根运动实现角色‘钻洞’翻滚,解决碰撞体鬼畜问题
UE4.26实战:蒙太奇与根运动实现角色钻洞翻滚的工程化解决方案在横版过关或潜行类游戏开发中,角色穿越低矮空间的动画实现往往面临两大技术痛点:动画过渡生硬导致的"鬼畜"现象,以及碰撞体未同步调整引发的物理系统冲突。…...

fail2ban日志地理标签实战:MaxMind本地库+GeoLite2威胁溯源
1. 这不是“加个地图插件”那么简单:为什么地理标签是日志分析的临门一脚你有没有翻过服务器的/var/log/auth.log或 Nginx 的error.log?密密麻麻全是 IP 地址、时间戳、失败原因——Failed password for root from 192.168.3.11 port 54212 ssh2…...

猫抓:5步掌握网页资源嗅探工具,轻松下载全网视频
猫抓:5步掌握网页资源嗅探工具,轻松下载全网视频 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 还在为网页上的精彩视频无…...

为什么选择 Telerik UI for UWP?10个理由让你的Windows应用开发效率倍增
为什么选择 Telerik UI for UWP?10个理由让你的Windows应用开发效率倍增 【免费下载链接】UI-For-UWP Telerik UI for Universal Windows Platform (UWP) is no longer supported. 项目地址: https://gitcode.com/gh_mirrors/ui/UI-For-UWP 如果你正在开发Wi…...
)
手把手教你用CentOS 7搭建Fog Project网络克隆服务器(含DHCP/TFTP配置避坑指南)
CentOS 7实战:企业级Fog Project网络克隆系统部署全攻略当企业IT部门需要同时为数十台甚至上百台计算机部署操作系统时,传统的光盘或U盘安装方式显然效率低下。这正是Fog Project大显身手的场景——一个开源的网络克隆与系统部署解决方案。本文将带您从零…...