Java 函数式编程
1.Lambda
1.1 格式
JDK 从 1.8 版本开始支持 Lambda 表达式,通过 Lambda 表达式我们可以将一个函数作为参数传入方法中。在 JDK 1.8 之前,我们只能通过匿名表达式来完成类似的功能,但是匿名表达式比较繁琐,存在大量的模板代码,不利于将行为参数化,而采用 Lamdba 则能很好的解决这个问题。Lambda 表达式的基本语法如下:
(parameters) -> expression或采用花括号的形式:
(parameters) -> { statements; }Lambda 表达式具有如下特点:
可选的参数:不需要声明参数类型,编译器会依靠上下文进行自动推断;
可选的参数圆括号:当且仅当只有一个参数时,包裹参数的圆括号可以省略;
可选的花括号:如果主体只有一个表达式,则无需使用花括号;
可选的返回关键字:如果主体只有一个表达式,则该表达式的值就是整个 Lambda 表达式的返回值,此时不需要使用 return 关键字进行显式的返回。
1.2 行为参数化
上面我们说过,Lambda 表达式主要解决的是行为参数化的问题,而什么是行为参数化?下面给出一个具体的示例:
/*** 定义函数式接口* @param <T> 参数类型*/
@FunctionalInterface
public interface CustomPredicate<T> {boolean test(T t);
}
/*** 集合过滤* @param list 待过滤的集合* @param predicate 函数式接口* @param <T> 集合中元素的类型* @return 满足条件的元素的集合*/
public static <T> List<T> filter(List<T> list, CustomPredicate<T> predicate) {ArrayList<T> result = new ArrayList<>();for (T t : list) {// 将满足条件的元素添加到返回集合中if (predicate.test(t)) result.add(t);}return result;
}针对不同类型的集合,我们可以通过传入不同的 Lambda 表达式作为参数来表达不同的过滤行为,这就是行为参数化:
List<Integer> integers = Arrays.asList(1, 2, 3, 4, 5);
filter(integers, x -> x % 2 == 0); // 过滤出所有偶数List<Employee> employees = Arrays.asList(new Employee("张某", 21, true),new Employee("李某", 30, true),new Employee("王某", 45, false));
filter(employees, employee -> employee.getAge() > 25); // 过滤出所有年龄大于25的员工需要注意的是上面我们声明接口时,使用了 @FunctionalInterface 注解,它表示当前的接口是一个函数式接口。函数式接口就是只含有一个抽象方法的接口;即一个接口不论含有多少个默认方法和静态方法,只要它只有一个抽象方法,它就是一个函数式接口。使用 @FunctionalInterface 修饰后,当该接口有一个以上的抽象方法时,编译器就会进行提醒。
任何使用到函数式接口的地方,都可以使用 Lambda 表达式进行简写。例如 Runnable 接口就是一个函数式接口,我们可以使用 Lambda 表达式对其进行简写:
new Thread(() -> {System.out.println("hello");
});
1.3 方法引用和构造器引用
紧接上面的例子,如果我们需要过滤出所有的正式员工,除了可以写成下面的形式外:
filter(employees, employee -> employee.isOfficial());还可以使用方法引用的形式进行简写:
filter(employees, Employee::isOfficial);除了方法引用外,还可以对构造器进行引用,示例如下:
Stream<Integer> stream = Stream.of(1, 3, 5, 2, 4);
stream.collect(Collectors.toCollection(ArrayList::new)); //等价于 toCollection(()->new ArrayList<>())方法引用和构造器引用的目的都是为了让代码更加的简洁。
2. 函数式接口
通常我们不需要自定义函数式接口,JDK 中内置了大量函数式接口,基本可以满足大多数场景下的使用需求,最基本的四种如下:
2.1. Consumer<T>消费型接口
消费输入的变量,没有返回值:
@FunctionalInterface
public interface Consumer<T> {void accept(T t);...
}2.2 Consumer<T>:供给型接口
供给变量:
@FunctionalInterface
public interface Supplier<T> {T get();
}2.3 Function<T, R>:
对输入类型为 T 的变量执行特定的转换操作,并返回类型为 R 的返回值:
@FunctionalInterface
public interface Function<T, R> {R apply(T t);...
}2.4 Predicate<T>:
判断类型为 T 的变量是否满足特定的条件,如果满足则返回 true,否则返回 false:
@FunctionalInterface
public interface Predicate<T> {boolean test(T t);...
}其他函数式接口都是这四种基本类型的扩展和延伸。以 BiFunction 和 BinaryOperator 接口为例:
BiFunction<T, U, R>:是函数型接口 Function<T, R> 的扩展,Function 只能接收一个入参;而 BiFunction 可以用于接收两个不同类型的入参;
BinaryOperator<T>:是 BiFunction 的一种特殊化情况,即两个入参和返回值的类型均相同,通常用于二元运算。定义如下:
@FunctionalInterface
public interface BiFunction<T, U, R> {R apply(T t, U u);
}@FunctionalInterface
public interface BinaryOperator<T> extends BiFunction<T,T,T> {....
}下面演示一下 BinaryOperator 的用法:
/* 执行归约操作*/
public static <T> T reduce(List<T> list, T initValue, BinaryOperator<T> binaryOperator) {for (T t : list) {initValue = binaryOperator.apply(initValue, t);}return initValue;
}public static void main(String[] args) {List<Integer> integers = Arrays.asList(1, 2, 3, 4, 5);reduce(integers, 0, (a, b) -> a + b); // 求和 输出:15reduce(integers, 1, (a, b) -> a * b); // 求积 输出:120
}3. 创建流
JDK 1.8 中另一个大的改进是引入了流,通过流、Lamda 表达式以及函数式接口,可以高效地完成数据的处理。创建流通常有以下四种方法:
3.1 由值创建
使用静态方法 Stream.of() 由指定的值进行创建:
Stream<String> stream = Stream.of("a", "b", "c", "d");3.2 由集合或数组创建
使用静态方法 Arrays.stream() 由指定的数组进行创建:
String[] strings={"a", "b", "c", "d"};
Stream<String> stream = Arrays.stream(strings);调用集合类的 stream() 方法进行创建:
List<String> strings = Arrays.asList("a", "b", "c", "d");
Stream<String> stream = strings.stream();stream() 方法定义在 Collection 接口中,它是一个默认方法,因此大多数的集合都可以通过该方法来创建流:
public interface Collection<E> extends Iterable<E> {default Stream<E> stream() {return StreamSupport.stream(spliterator(), false);}
}
3.3 由文件创建
try (Stream<String> lines = Files.lines(Paths.get("pom.xml"), StandardCharsets.UTF_8)) {lines.forEach(System.out::println);
} catch (IOException e) {e.printStackTrace();
}3.4 由函数创建
除了以上方法外,还可以通过 Stream.iterate() 和 Stream.generate() 方法来来创建无限流:
Stream.iterate() 接受两个参数:第一个是初始值;第二个参数是一个输入值和输出值相同的函数型接口,主要用于迭代式地产生新的元素,示例如下:
// 依次输出0到9
Stream.iterate(0, x -> x + 1).limit(10).forEach(System.out::print);
Stream.generate() 接收一个供应型函数作为参数,用于按照该函数产生新的元素:
// 依次输出随机数Stream.generate(Math::random).limit(10).forEach(System.out::print);
4. 操作流
4.1 基本操作
当流创建后,便可以利用 Stream 类上的各种方法对流中的数据进行处理,常用的方法如下:
| 操作 | 作用 | 返回类型 | 使用的类型/函数式接口 |
| filter | 过滤符合条件的元素 | Stream<T> | Predicate<T> |
| distinct | 过滤重复元素 | Stream<T> | |
| skip | 跳过指定数量的元素 | Stream<T> | long |
| limit | 限制元素的数量 | Stream<T> | long |
| map | 对元素执行特定转换操作 | Stream<T> | Function<T,R> |
| flatMap | 将元素扁平化后执行特定转换操作 | Stream<T> | Function<T,Stream<R>> |
| sorted | 对元素进行排序 | Stream<T> | Comparator<T> |
| anyMatch | 是否存在任意一个元素能满足指定条件 | boolean | Predicate<T> |
| noneMatch | 是否所有元素都不满足指定条件 | boolean | Predicate<T> |
| allMatch | 是否所有元素都满足指定条件 | boolean | Predicate<T> |
| findAny | 返回任意一个满足指定条件的元素 | Optional<T> | |
| findFirst | 返回第一个满足指定条件的元素 | Optional<T> | |
| forEach | 对所有元素执行特定的操作 | void | Cosumer<T> |
| collect | 使用收集器 | R | Collector<T, A, R> |
| reduce | 执行归约操作 | Optional<T> | BinaryOperator<T> |
| count | 计算流中元素的数量 | long |
注:上表中返回类型为 Stream<T> 的操作都是中间操作,代表还可以继续调用其它方法对流进行处理。返回类型为其它的操作都是终止操作,代表处理过程到此为止。
使用示例如下:
Stream.iterate(0, x -> x + 1) // 构建流.limit(20) // 限制元素的个数.skip(10) // 跳过前10个元素.filter(x -> x % 2 == 0) // 过滤出所有偶数.map(x -> "偶数:" + x) // 对元素执行转换操作.forEach(System.out::println); // 打印出所有元素输出结果如下:shell
偶数:10
偶数:12
偶数:14
偶数:16
偶数:18
上表的 flatMap() 方法接收一个参数,该参数是一个函数型接口 Function<? super T, ? extends Stream<? extends R>> mapper,主要用于将流中的元素转换为 Stream ,从而可以将原有的元素进行扁平化,示例如下:
String[] strings = {"hello", "world"};Arrays.stream(strings).map(x -> x.split("")) // 拆分得到: ['h','e','l','l','o'],['w','o','r','l','d'].flatMap(x -> Arrays.stream(x)) // 将每个数组进行扁平化处理得到:'h','e','l','l','o','w','o','r','l','d'.forEach(System.out::println);而上表的 reduce() 方法则接收两个参数:第一个参数表示执行归约操作的初始值;第二个参数是上文我们介绍过的函数式接口 BinaryOperator<T> ,使用示例如下:
Stream.iterate(0, x -> x + 1).limit(10).reduce(0, (a, b) -> a + b); //进行求和操作
4.2 数值流
上面的代码等效于对 Stream 中的所有元素执行了求和操作,因此我们还可以调用简便方法 sum() 来进行实现,但是需要注意的是 Stream.iterate() 生成流中的元素类型都是包装类型:
Stream<Integer> stream = Stream.iterate(0, x -> x + 1); //包装类型Integer
而 sum() 方法则是定义在 IntStream 上,此时需要将流转换为具体的数值流,对应的方法是 mapToInt():
Stream.iterate(0, x -> x + 1).limit(10).mapToInt(x -> x).sum();类似的方法还有 mapToLong() 和 mapToDouble() 。如果你想要将数值流转换为原有的流,相当于对其中的元素进行装箱操作,此时可以调用 boxed() 方法:
IntStream intStream = Stream.iterate(0, x -> x + 1).limit(10).mapToInt(x -> x);
Stream<Integer> boxed = intStream.boxed();
5.流收集器
5.1 常用流收集器
Stream 中最强大一个终止操作是 collect() ,它接收一个收集器 Collector 作为参数,可以将流中的元素收集到集合中,或进行分组、分区等操作。Java 中内置了多种收集器的实现,可以通过 Collectors 类的静态方法进行调用,常用的收集器如下:
| 工厂方法 | 返回类型 | 用于 |
| toList | List<T> | 把流中所有元素收集到 List 中 |
| toSet | Set<T> | 把流中所有元素收集到 Set 中 |
| toCollection | Collection<T> | 把流中所有元素收集到指定的集合中 |
| counting | Long | 计算流中所有元素的个数 |
| summingInt | Integer | 将流中所有元素转换为整数,并计算其总和 |
| averagingInt | Double | 将流中所有元素转换为整数,并计算其平均值 |
| summarizingInt | IntSummaryStatistics | 将流中所有元素转换为整数,并返回统计结果,包含最大值、最小值、 总和与平均值等信息 |
| joining | String | 将流中所有元素转换为字符串,并使用给定连接符进行连接 |
| maxBy | Optional<T> | 查找流中最大元素的 Optional |
| minBy | Optional<T> | 查找流中最小元素的 Optional |
| reducing | 规约操作产生的类型 | 对流中所有元素执行归约操作 |
| collectingAndThen | 转换返回的类型 | 先把流中所有元素收集到指定的集合中,再对集合执行特定的操作 |
| groupingBy | Map<K,List<T>> | 对流中所有元素执行分组操作 |
| partitionBy | Map<Boolean,List<T>> | 对流中所有元素执行分区操作 |
使用示例如下:
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 4, 5, 6); stream.collect(Collectors.toSet()); // [1, 2, 3, 4, 5, 6]
stream.collect(Collectors.toList()); // [1, 2, 3, 4, 4, 5, 6]
stream.collect(Collectors.toCollection(ArrayList::new)); // [1, 2, 3, 4, 4, 5, 6]
stream.collect(Collectors.counting()); // 7 等效于 stream.count();
stream.collect(Collectors.summarizingInt(x -> x)); // IntSummaryStatistics{count=7, sum=25, min=1, average=3.571429, max=6}
stream.collect(Collectors.maxBy((Integer::compareTo))); // Optional[6]
stream.collect(Collectors.reducing(1, (a, b) -> a * b)); // 等效于 stream.reduce(1, (a, b) -> a * b);
collect(Collectors.collectingAndThen(Collectors.toSet(), Set::size)); // 先把所有元素收集到Set中,再计算Set的大小注意:以上每个终止操作只能单独演示,因为对一个流只能执行一次终止操作。并且执行完终止操作后,就不能再对这个流进行任何操作,否则将抛出 java.lang.IllegalStateException: stream has already been operated upon or closed 的异常。
5.2 分组收集器
分组收集器可以实现类似数据库 groupBy 子句的功能。假设存在如下员工信息:
Stream<Employee> stream = Stream.of(new Employee("张某", "男", "A公司", 20),new Employee("李某", "女", "A公司", 30),new Employee("王某", "男", "B公司", 40),new Employee("田某", "女", "B公司", 50));
public class Employee {private String name;private String gender;private String company;private int age;@Overridepublic String toString() {return "Employee{" + "name='" + name + '\'' + '}';}
}此时如果需要按照公司进行分组,则可以使用 groupingBy() 收集器:
stream.collect(Collectors.groupingBy(Employee::getCompany));对应的分组结果如下:
{ B公司=[Employee{name='王某'}, Employee{name='田某'}], A公司=[Employee{name='张某'}, Employee{name='李某'}]
}如果想要计算分组后每家公司的人数,还可以为 groupingBy() 传递一个收集器 Collector 作为其第二个参数,调用其重载方法:
stream.collect(Collectors.groupingBy(Employee::getCompany, Collectors.counting()));对应的结果如下:
{B公司=2, A公司=2
} 因为第二个参数是一个 Collector,这意味着你可以再传入一个分组收集器来完成多级分组,示例如下:
stream.collect(Collectors.groupingBy(Employee::getCompany, Collectors.groupingBy(Employee::getGender)));先按照公司分组,再按照性别分组,结果如下:
{ B公司={女=[Employee{name='田某'}], 男=[Employee{name='王某'}]}, A公司={女=[Employee{name='李某'}], 男=[Employee{name='张某'}]}
}除此之外,也可以通过代码块来自定义分组条件,示例如下:
Map<String, List<Employee>> collect = stream.collect(Collectors.groupingBy(employee -> {if (employee.getAge() <= 30) {return "青年员工";} else if (employee.getAge() < 50) {return "中年员工";} else {return "老年员工";}
}));对应的分组结果如下:
{
中年员工=[Employee{name='王某'}],
青年员工=[Employee{name='张某'}, Employee{name='李某'}],
老年员工=[Employee{name='田某'}]
} 5.3 分区
分区是分组的一种特殊情况,即将满足指定条件的元素分为一组,将不满足指定条件的元素分为另一组,两者在使用上基本类似,示例如下:
stream.collect(Collectors.partitioningBy(x -> "A公司".equals(x.getCompany())));对应的分区结果如下:
{false=[Employee{name='王某'}, Employee{name='田某'}], true=[Employee{name='张某'}, Employee{name='李某'}]
} 6. 并行流
想要将普通流转换为并行流非常简单,只需要调用 Stream 的 parallel() 方法即可:
stream.parallel();
此时流中的所有元素会被均匀的分配到多个线程上进行处理。并行流内部使用的是 ForkJoinPool 线程池,它默认的线程数量就是处理器数量,可以通过 Runtime.getRuntime().availableProcessors() 来查看该值,通常不需要更改。
当前也没有办法为某个具体的流指定线程数量,只能通过修改系统属性 java.util.concurrent.ForkJoinPool.common.parallelism 的值来改变所有并行流使用的线程数量,示例如下:
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism","12"); 如果想将并行流改回普通的串行流,则只需要调用 Stream 的 sequential() 方法即可:
stream.sequential();
相关文章:

Java 函数式编程
1.Lambda 1.1 格式 JDK 从 1.8 版本开始支持 Lambda 表达式,通过 Lambda 表达式我们可以将一个函数作为参数传入方法中。在 JDK 1.8 之前,我们只能通过匿名表达式来完成类似的功能,但是匿名表达式比较繁琐,存在大量的模板代码&…...
类的成员函数总结
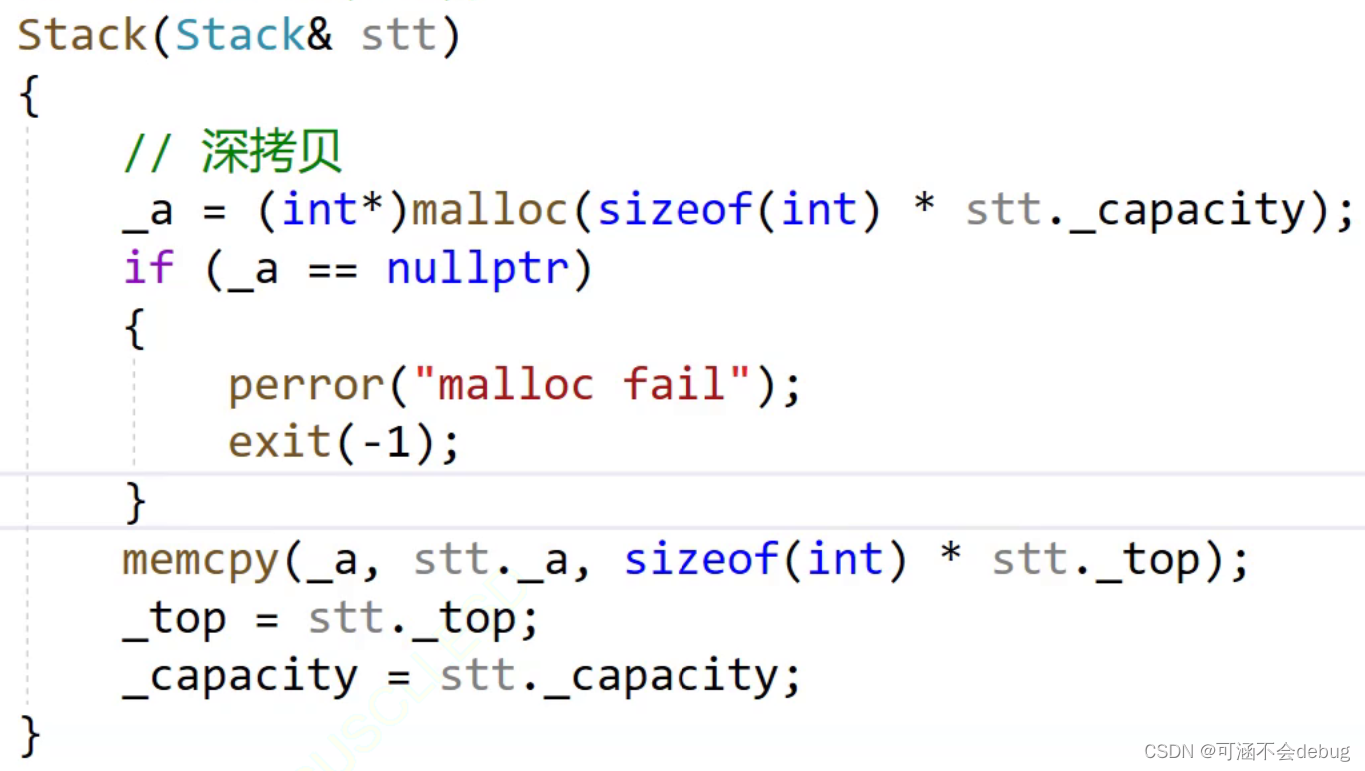
前言: 如果一个类中什么成员都没有,简称为空类。 空类中真的什么都没有吗?并不是,任何类在什么都不写时,编译器会自动生成以下6个默认成员函数。 默认成员函数:用户没有显式实现,编译器会生成的…...

java高级之单元测试、反射
1、Junit测试工具 Test定义测试方法 1.被BeforeClass标记的方法,执行在所有方法之前 2.被AfterCalss标记的方法,执行在所有方法之后 3.被Before标记的方法,执行在每一个Test方法之前 4.被After标记的方法,执行在每一个Test方法之后 public …...

MSQL系列(十三) Mysql实战-left/right/inner join 使用详解及索引优化
Mysql实战-left/right/inner join 使用详解及索引优化 前面我们讲解了BTree的索引结构,也详细讲解下Join的底层驱动表 选择原理,今天我们来了解一下为什么会出现内连接外连接,两种连接方式,另外实战一下内连接和几种最常用的join…...

前端面试题之HTML篇
1、src 和 href 的区别 具有src的标签有:script、img、iframe 具有href的标签有:link、a 区别 src 是source的缩写。表示源的意思,指向资源的地址并下载应用到文档中。会阻塞文档的渲染,也就是为什么js脚本放在底部而不是头部的…...

Django ORM:数据库操作的Python化艺术
Django的对象关系映射器(ORM)是其核心功能之一,允许开发者使用Python代码来定义、操作和查询数据库。这篇文章将带你深入了解Django ORM的强大之处,从基本概念到高级查询技巧,提供丰富的示例帮助你掌握使用Django ORM进…...

react受控组件与非受控组件
React中的组件可以分为受控组件和非受控组件: 受控组件:受控组件是指组件的值受到React组件状态的控制。通常在组件中,我们会通过state来存储组件的值,然后再将state的值传递给组件的props,从而实现组件的双向数据绑定…...

小米产品面试题:淘宝为何需要确认收货?京东为何不需要?
亲爱的小米粉丝们,大家好!我是小米,一个热爱技术、热衷于分享的小编。今天,我要和大家聊聊一个有趣的话题:为什么淘宝购物需要确认收货,而京东不需要?这可是一个让很多人纳闷的问题,…...
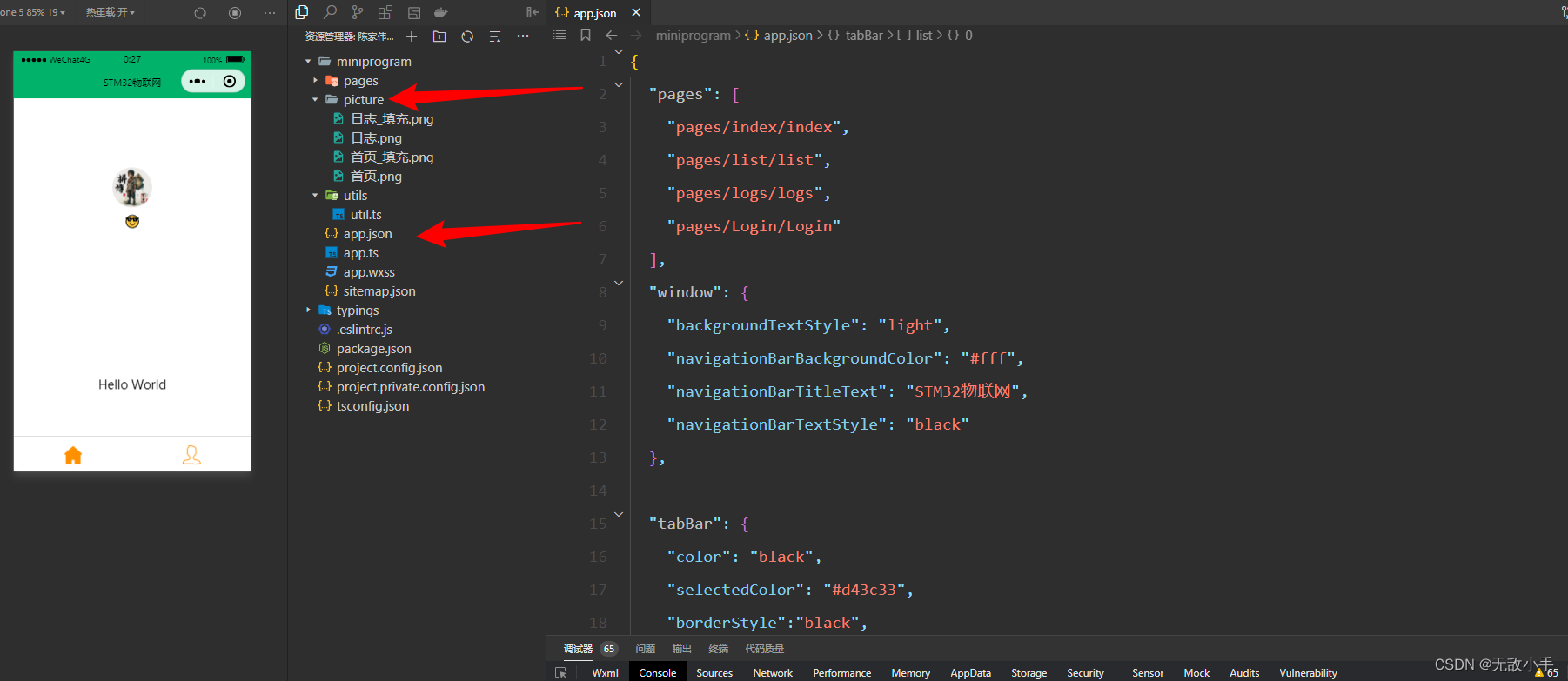
(1)上位机底部栏 UI如何设置
上位机如果像设置个多页面切换: 位置: 代码如下: "tabBar": {"color": "black","selectedColor": "#d43c33","borderStyle":"black","backgroundColor": …...

中国多主数据库:压强投入,期待破茧
拿破仑曾说:“战争的艺术就是在某一点上集中最大优势兵力”,强调了力量集中的重要性。 如今,国际形势风云变幻,西方世界对中国的围剿不再仅仅体现在军事和地缘政治上,而更多表现在经济与科技上。在科技领域࿰…...

JavaScript在ES6及后续新增的常用新特性
JavaScript经历了不同标本的迭代,在不断完善中会添加不同的新特性来解决前一个阶段的瑕疵,让我们开发更加便捷与写法更加简洁! 1、箭头函数: 箭头函数相比传统的函数语法,具有更简洁的语法、没有自己的this值、不会绑…...
试试流量回放,不用人工写自动化测试case了
大家好,我是洋子,接触过接口自动化测试的同学都知道,我们一般要基于某种自动化测试框架,编写自动化case,编写自动化case的依据来源于接口文档,对照接口文档里面的请求参数进行人工添加接口自动化case 其实…...

密钥管理系统功能及作用简介 安当加密
密钥管理系统的功能主要包括密钥生成、密钥注入、密钥备份、密钥恢复、密钥更新、密钥导出和服务,以及密钥的销毁等。 密钥生成:通过输入一到多组的密钥种子,按照可再现或不可再现的模式生成所需要的密钥。一般采用不可再现模式作为密钥生成…...

vue中watch属性的用法
在Vue中,watch属性用于监听一个数据的变化,并且在数据变化时执行一些操作。它可以观察一个具体的数据对象,从而在该数据对象发生变化时触发对应的回调函数。 使用watch属性的步骤如下: 在Vue实例中添加一个watch对象 new Vue({…...

Redis-使用java代码操作Redis
🏅我是默,一个在CSDN分享笔记的博主。📚📚 🌟在这里,我要推荐给大家我的专栏《Linux》。🎯🎯 🚀无论你是编程小白,还是有一定基础的程序员,这…...
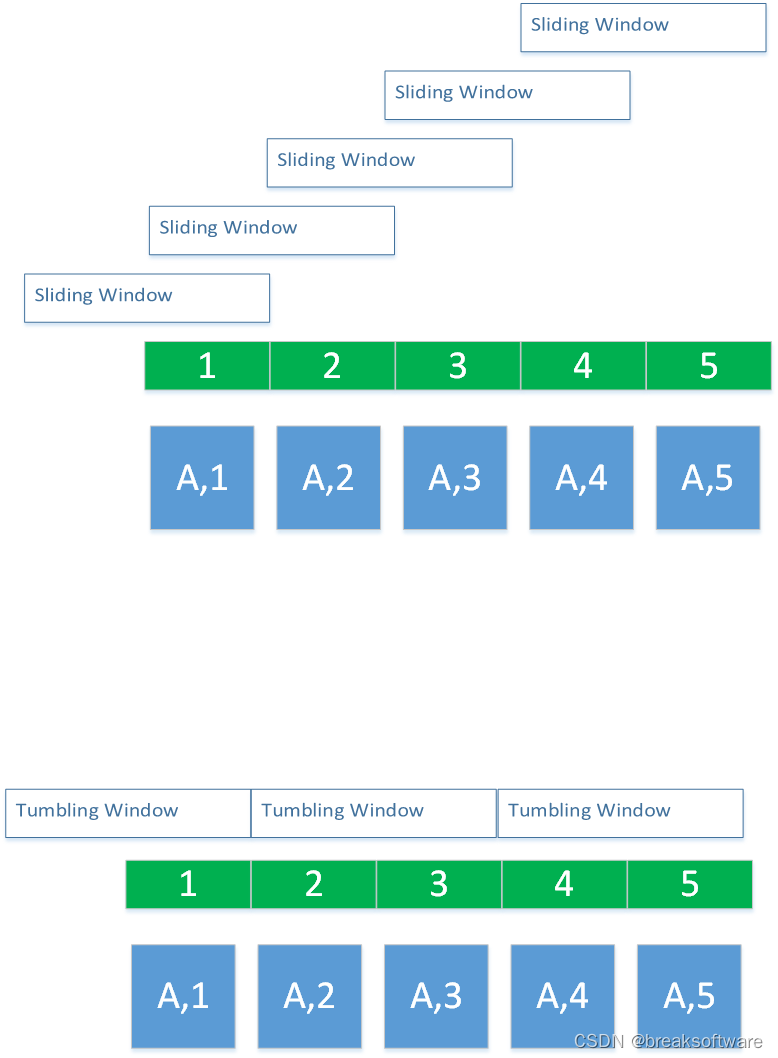
0基础学习PyFlink——事件时间和运行时间的窗口
大纲 定制策略运行策略Reduce完整代码滑动窗口案例参考资料 在 《0基础学习PyFlink——时间滚动窗口(Tumbling Time Windows)》一文中,我们使用的是运行时间(Tumbling ProcessingTimeWindows)作为窗口的参考时间: reducedkeyed.window(TumblingProcess…...

Git Rebase 优化项目历史
在软件开发过程中,版本控制是必不可少的一环。Git作为当前最流行的版本控制系统,为开发者提供了强大的工具来管理和维护代码历史。git rebase是其中一个高级特性,它可以用来重新整理提交历史,使之更加清晰和线性。本文将详细介绍g…...

两种MySQL OCP认证应该如何选?
很多同学都找姚远老师说要参加MySQL OCP认证培训,但绝大部分同学并不知道MySQL OCP认证有两种,以MySQL 8.0为例。 一种是管理方向,叫:Oracle Certified Professional, MySQL 8.0 Database Administrator(我考试的比较…...
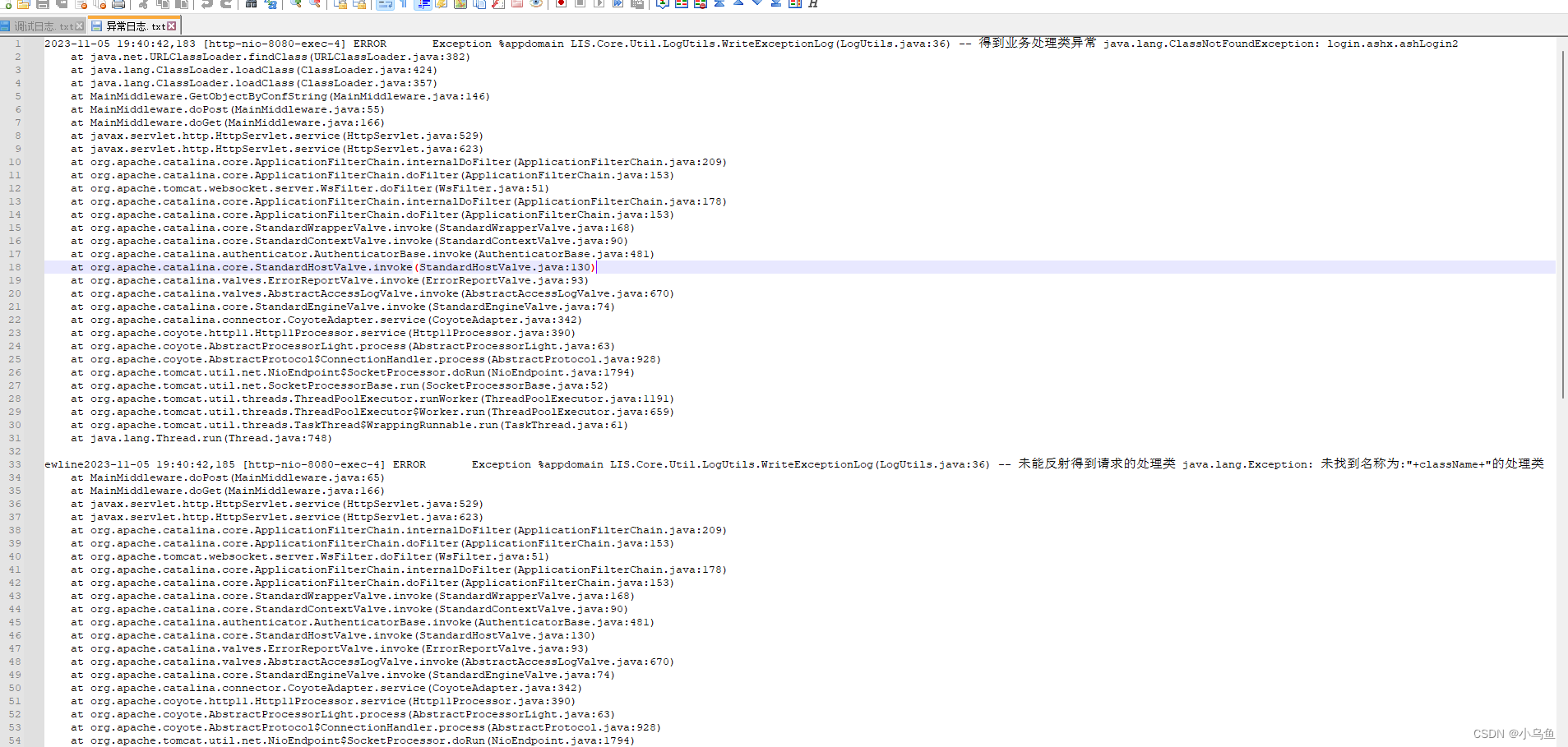
Java用log4j写日志
日志可以方便追踪和调试问题,以前用log4net写日志,换Java了改用log4j写日志,用法和log4net差不多。 到apache包下载下载log4j的包,解压后把下图两个jar包引入工程 先到网站根下加一个log4j2.xml的配置文件来配置日志的格式和参…...
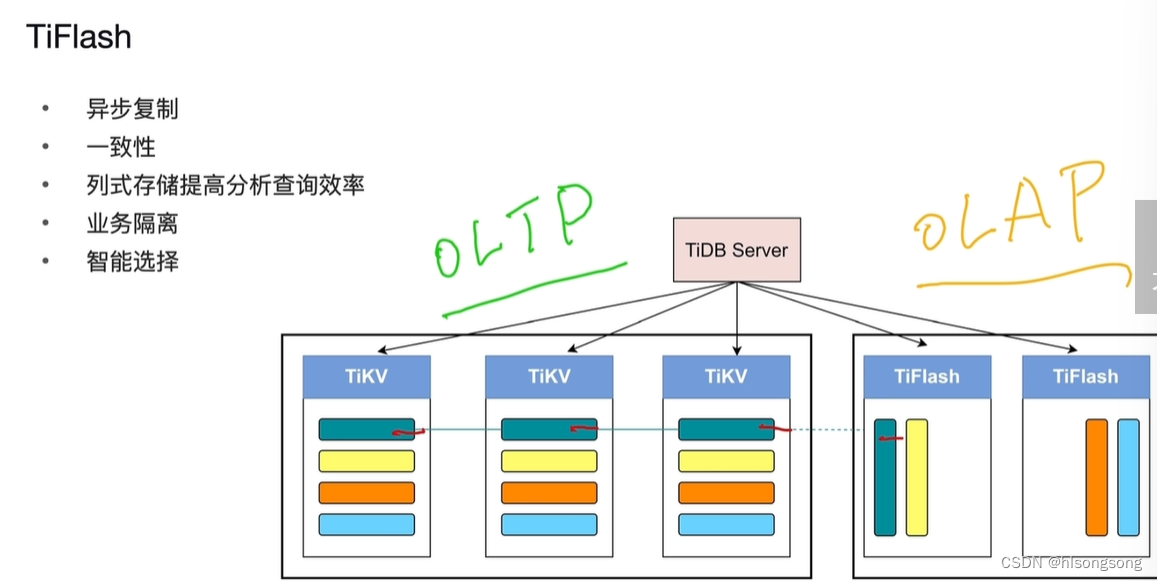
PCTA认证考试-01_TiDB数据库架构概述
TiDB 数据库架构概述 一、学习目标 理解 TiDB 数据库整体结构。了解 TiDB Server,TiKV,TiFlash 和 PD 的主要功能。 二、TiDB 体系架构 1. TiDB Server 2. TiKV OLTP 3. Placement Driver 4. TiFlash OLAP OLTPOLAPHTAP...

力扣第97题:多数元素
第一部分:问题描述 给定一个大小为 n 的数组 nums ,返回其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。 你可以假设数组是非空的,并且给定的数组总是存在多数元素。 示例 1: 输入:nums = [3,2,3] 输出:3 示例 2: 输入:nums = [2,2,1,1,1…...

利用Google Earth与KML技术高效提取数字高程等高线
1. 从零开始认识数字高程与KML技术 数字高程模型(DEM)就像给地球表面拍了一张"立体照片",它能精确记录每个位置的海拔高度。我第一次接触DEM数据时,被它的实用性震惊了——从洪水模拟到城市规划,再到手机导…...

5 款主流开源 SDD 框架深度体验与 PK
强大的 AI Coding 似乎无时无刻不在制造新的焦虑:程序员、IDE、甚至软件工程都不再被需要,“会说话就会开发软件”。这是极端且不负责任的。毕竟,还有更多需要逻辑严密的商业软件系统。 强如 OpenAI,在使用Codex开发内部系统时依…...

ONNX Runtime性能优化:InferenceSession.run函数的高效使用技巧
1. ONNX Runtime与InferenceSession.run函数基础 ONNX Runtime是一个高性能的推理引擎,专门用于部署ONNX格式的机器学习模型。在实际应用中,模型的推理性能往往直接影响整个系统的响应速度和资源利用率。而InferenceSession.run函数正是这个过程中的核心…...

FramePack视频扩散技术探索:从原理到实践的全流程指南
FramePack视频扩散技术探索:从原理到实践的全流程指南 【免费下载链接】FramePack Lets make video diffusion practical! 项目地址: https://gitcode.com/gh_mirrors/fr/FramePack 副标题:如何解决AI舞蹈视频创作中的效率与质量平衡问题 FrameP…...

苹果手机用微信,这 8 个设置赶紧关!隐私正在泄露
文章目录前言第一道门:别让陌生人在你家门口"数地砖"第二道门:给你的手机号穿上"隐身衣"第三道门:清理那些"寄生"在你账号上的第三方第四道门:关掉"附近的人",拒绝被"雷…...

CentOS 7.6 下 OpenGauss 6.0 极简版安装踩坑实录:从用户权限到远程连接的全流程避坑
CentOS 7.6 下 OpenGauss 6.0 极简版安装实战:从权限配置到远程访问的深度排坑指南 国产数据库的崛起让OpenGauss逐渐成为企业级应用的新选择。但初次部署时,从用户权限到环境变量配置的每个环节都可能成为"拦路虎"。本文将带你穿越安装全流程…...

Super Qwen Voice World生产环境部署:Docker镜像构建与GPU透传配置
Super Qwen Voice World生产环境部署:Docker镜像构建与GPU透传配置 1. 引言 想象一下,你开发了一个超酷的复古像素风语音设计工具,用户只需要输入文字和语气描述,就能生成各种情绪饱满的AI配音。这个工具在本地测试时运行完美&a…...

Redis如何断开主从同步关系_使用REPLICAOF NO ONE命令将从节点提升为独立主节点
执行REPLICAOF NO ONE后从节点未真正独立,因状态切换有延迟、需确认同步完成、配置文件残留、版本兼容性(4.x用SLAVEOF)、集群模式不支持、提升后写入风险及原主无感知。执行 REPLICAOF NO ONE 后从节点没真正“独立”?命令本身没…...

专业级硬件控制方案深度解析:如何用GHelper实现华硕笔记本高效优化
专业级硬件控制方案深度解析:如何用GHelper实现华硕笔记本高效优化 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TU…...