试试流量回放,不用人工写自动化测试case了
大家好,我是洋子,接触过接口自动化测试的同学都知道,我们一般要基于某种自动化测试框架,编写自动化case,编写自动化case的依据来源于接口文档,对照接口文档里面的请求参数进行人工添加接口自动化case
其实,对于日常新的服务端需求的迭代,人工一次性补充20个以下接口自动化case,还是可以接受。如果一次性要补充50个以上的接口case,光靠人工去填写就显得非常耗时了
还有一种比较常见的场景,一些老的服务模块需要进行迁移或者是重构,这些老模块本身可能也没有接口文档,业务逻辑也没有改变,如何确保原来业务在迁移后的正确运行非常重要,光靠QA进行接口测试也很难保障迁移后的新服务线上没有问题
为了最大程度的覆盖测试,我们可以通过复制线上流量拷贝到线下生成自动化case进行接口的功能测试以及diff测试,这种技术就叫流量回放
什么是流量回放
流量回放从字面意思理解,流量可以理解成互联网上发送和接收数据的量,由于我们网络通信协议一般都是HTTP请求,前后端交互方式一般通过后端API接口,所以流量的形式可以理解成线上的接口请求数量
而回放就是改变接口请求信息的位置,比如存放在到线下的数据库,Redis,或者分布式大数据集群中,也可以不经过存储进行实时回放,使得我们能够对线上流量进行利用
流量回放再通俗理解成两个字,就是引流
流量回放可以将流量进行拷贝后直接使用,也能把流量放大、流量缩小后使用
流量拷贝指的是将线上正式流量通过改写业务逻辑、tcpcopy、日志回放等方法在线下环境回放,从而达到测试的目的
流量拷贝可以完全模拟线上的流量,从而对复杂的业务场景进行仿真测试,并且不会对线上服务产生影响
一份流量复制多份,每份流量经过修改目的地址后发送到同一台实例上,比如拷贝5份流量到同一台实例,这台实例就能比线上环境同一时间多抗5倍压力,就能实现对线下环境进行压测,这就叫流量放大
那有小伙伴问,能放大,可以缩小吗?当然可以,流量缩小是通过复制部分流量并对其进行处理,以实现流量的缩小。这样做的原因可能是为了减少流量的规模或为了对流量进行进一步的分析和处理
在线下测试中难以覆盖的场景,都可以通过流量拷贝的方式来测试,测试的场景更广泛,覆盖面也更大
业界经验
目前业界也有一些常用的引流解决方案
阿里Doom
Doom是一个将一部分线上真实流量复制并用于自动回归测试的平台。其在应用内部通过aop切面编程方式实现的流量录制和回放功能,由于最底层借助了java的instrument实现aop,因此目前仅支持java应用的接入使用。其原理图如下:

TCPCopy
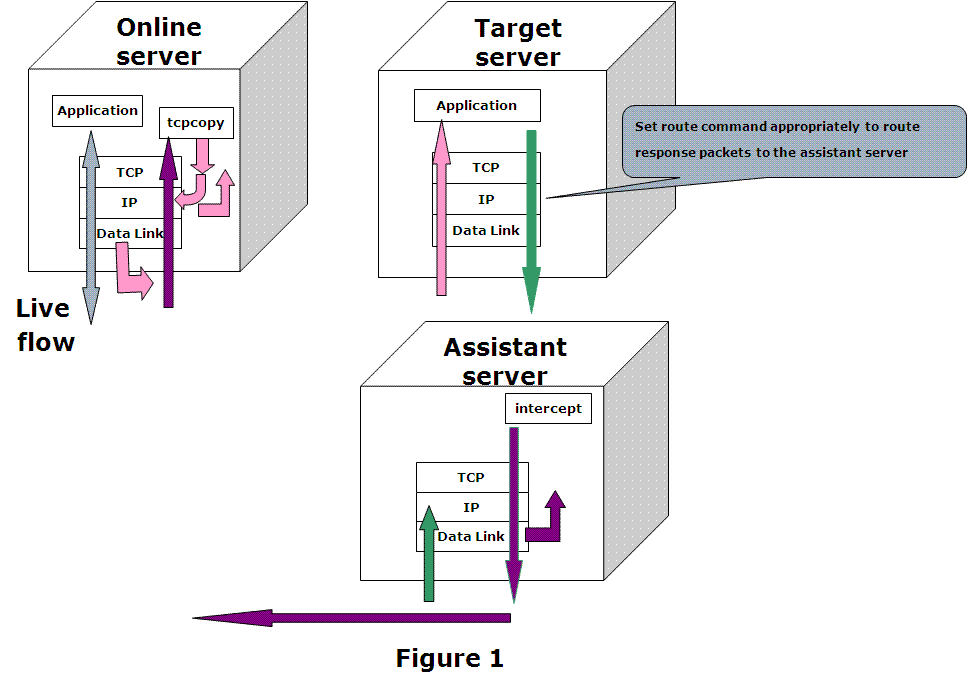
TCPCopy是一种请求复制 (所有基于tcp的packets) 工具,由tcpcopy和intercept组成,其中tcpcopy在线上服务上运行并利用原始socket复制线上流量到测试服务上 (粉红色的线),intercept部署在辅助服务器上,负责接收响应(绿色的线)并回传给tcpcopy (紫色的线),具体见下图:
GoReplay
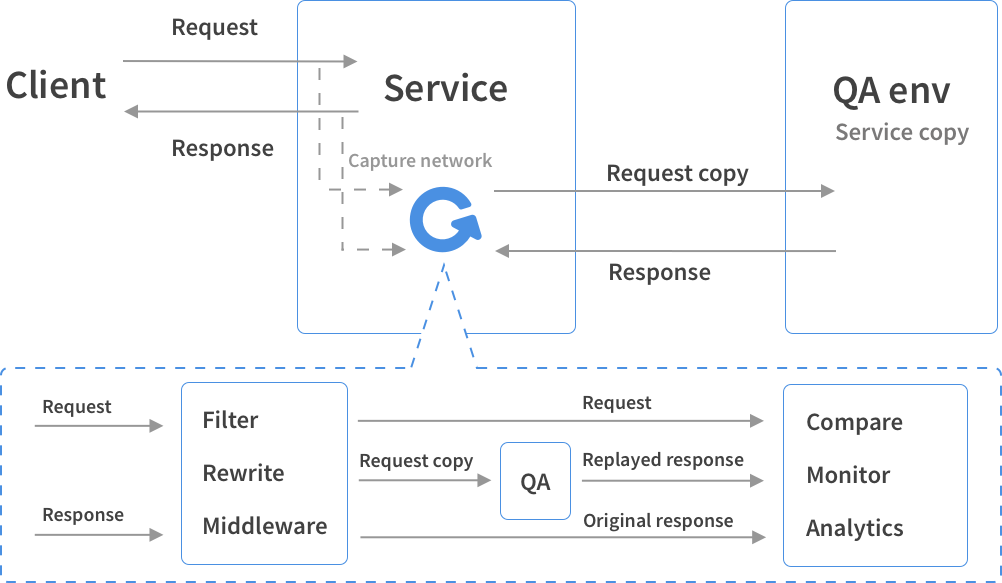
Goreplay是用 Golang开发的 HTTP 实时流量复制工具。支持流量的放大、缩小,频率限制,还支持把请求记录到文件,方便回放和分析,也支持和 ElasticSearch 集成,将流量存入 ES 进行实时分析GoReplay不是代理,而是监听网络接口上的流量,不需要更改生产基础架构,只需与服务相同的计算机上运行 。具体原理见下图
Nginx的ngx_http_mirror_module模块
Nginx 1.13.4 中引入ngx_http_miror_module模块来支持应用层的流量复制。该模块通过mirror配置指令来实现流量复制。如下图,可以通过下面配置来实现复制proxy.local流量到test.local
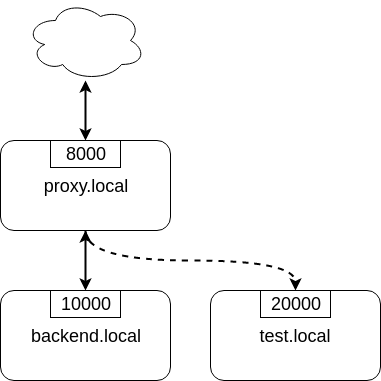
upstream backend {server backend.local:10000;
}upstream test_backend {server test.local:20000;
}server {server_name proxy.local;listen 8000;location / {mirror /mirror;proxy_pass http://backend;}location = /mirror {internal;proxy_pass http://test_backend$request_uri;}
}
其中每一条mirror配置项对应用户请求的一个副本,可以通过配置多次mirror指令来实现“流量放大”的效果。当然,你也可以将多个副本转发给不同的后端目标系统
流量回放的三种方式
从引流自身来看,主要有3种类型,分别是:主路复制、旁路复制、日志回放
主路复制:
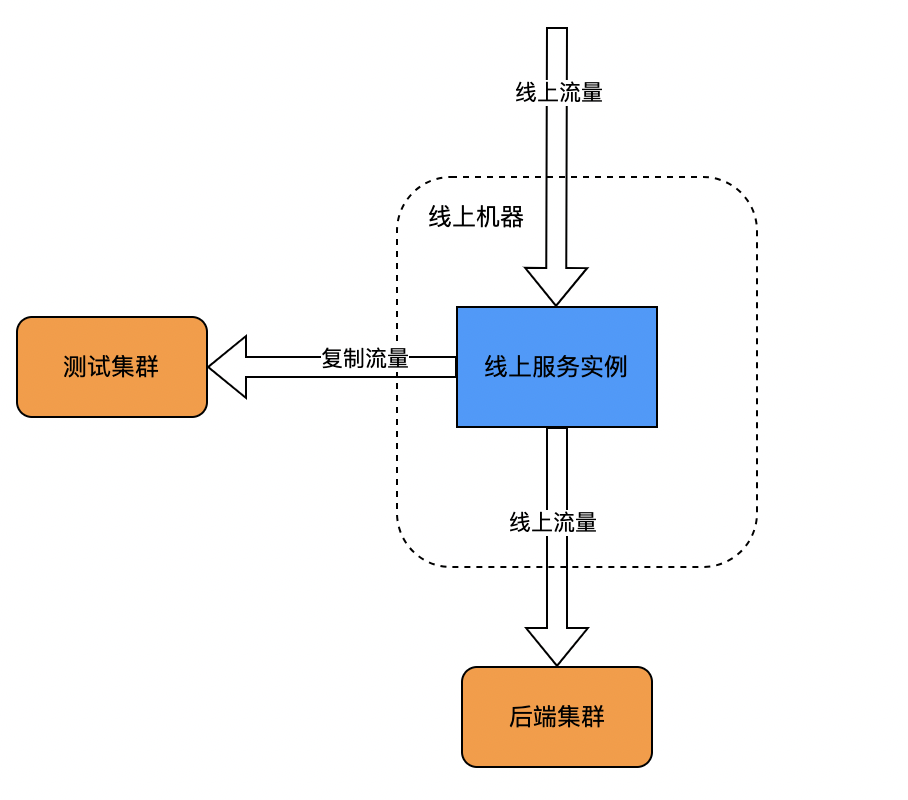
主路复制指的是在调用链中进行流量拷贝。一种是在业务逻辑中进行流量复制,比如在调用API的过程中,由业务方编写代码逻辑记录请求/响应信息内容;另一种是在框架(如阿里的Doom)处理逻辑中进行流量复制。
- 优点: 可以高度结合业务逻辑,实现细粒度定制化流量复制,比如可以只针对某些特征的流量进行复制
- 缺点: 业务逻辑与引流逻辑耦合度较高,功能上相互影响;每个请求都需要进行额外引流处理,对业务流程存在性能影响
旁路复制
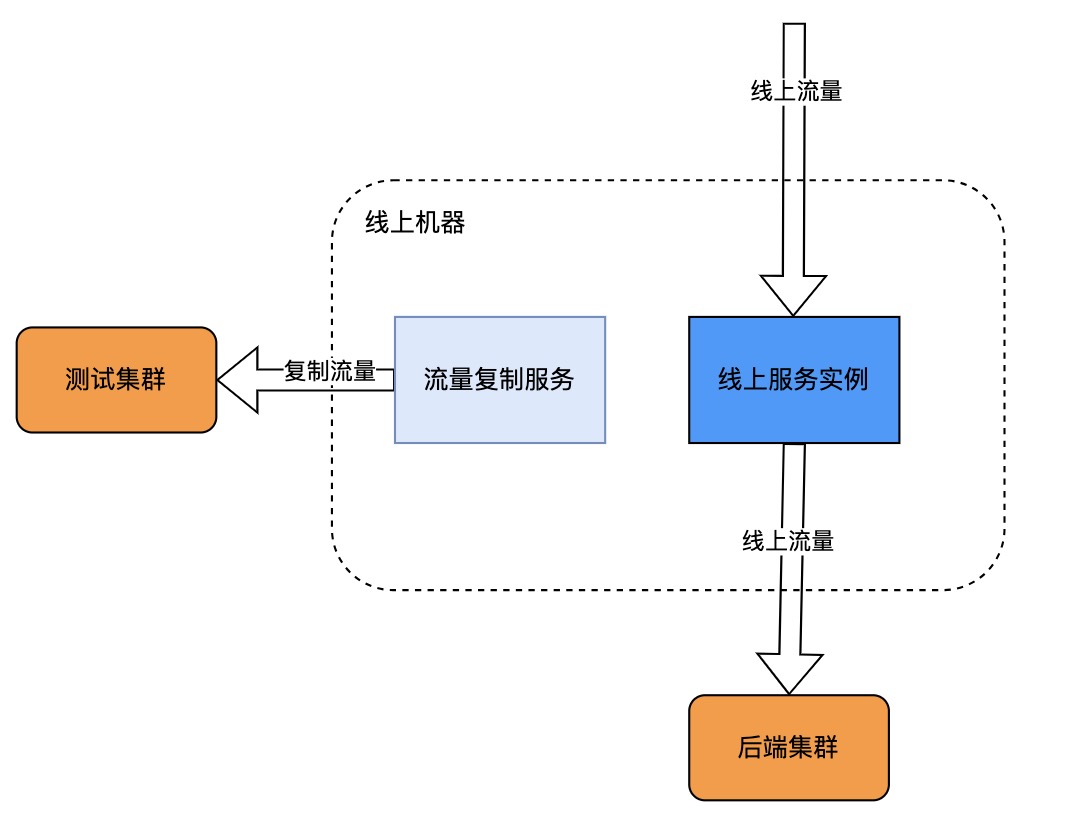
旁路复制一般是由第三方服务在网络协议栈中,监听复制流量,对业务无感。比如TCPCopy,相似的工具还有GoReplay等
- 优点: 与业务解耦,可以独立部署升级引流模块,业务方需关注引流功能实现
- 缺点: 4层网卡层面的网络包抓取后,仍需要进行数据包重组和解析,需要额外的消耗计算资源,往往需要全量抓包解析再进行筛选,无法结合业务逻辑进行定制化的采样
基于网关的业务特点:1) 流量大,无差别的抓包、解包筛选会消耗大量CPU,2) 承接所有产品线的流量,需要提供特定产品线的流量复制能力
特别注意:流量复制是在线上服务上进行的,因此会消耗线上机器的CPU资源,为了不对线上业务带来影响,需要在流量复制时监控线上机器的资源使用,一旦资源消耗太多时需要立即停止流量复制
日志回放
日志回放有点类似旁路复制,但是不再监听网络协议请求,而是在线上服务实例放一个log agent,通过它来将日志转存到大数据分布式集群当中
使用日志回放的前提是,业务代码逻辑当中需要打印的日志,需要包括接口的请求参数,URL,Body,请求方式等必要的接口信息,如果没有打印接口信息的日志,则无法进行日志回放
所以要采取这种回放方式,第一步就是需要开发去协助规范日志
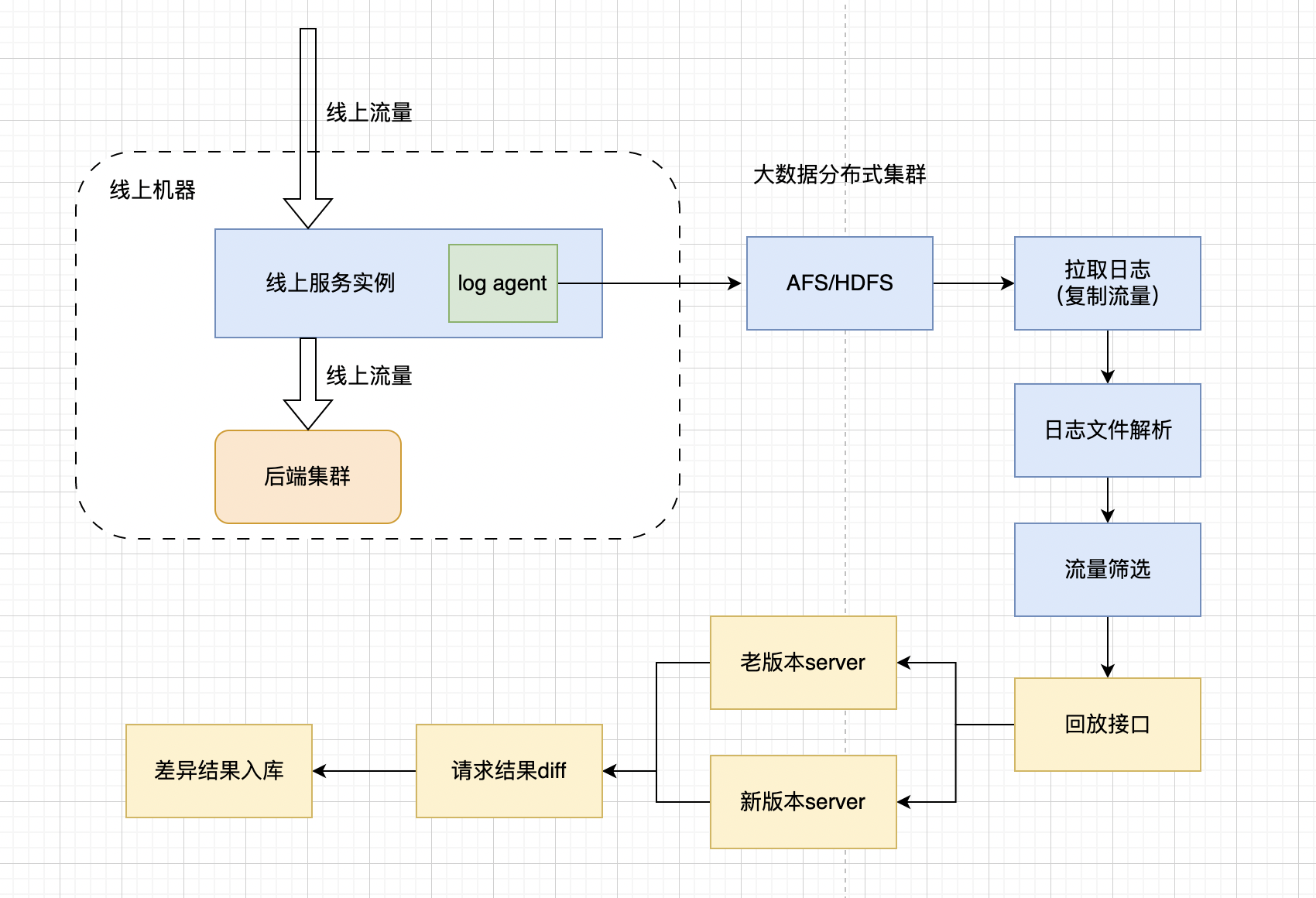
在HDFS/AFS集群当中存放日志以后,就能部署一个hadoop client 用来拉取集群上的日志,并对日志进行处理,解析出接口请求信息,有必要时需要对流量进行筛选后,再进行回放
下面分享一个使用Python多进程,解析日志获取流量的demo程序
假设现在已经从集群上拉下了日志,日志目录结构如下:
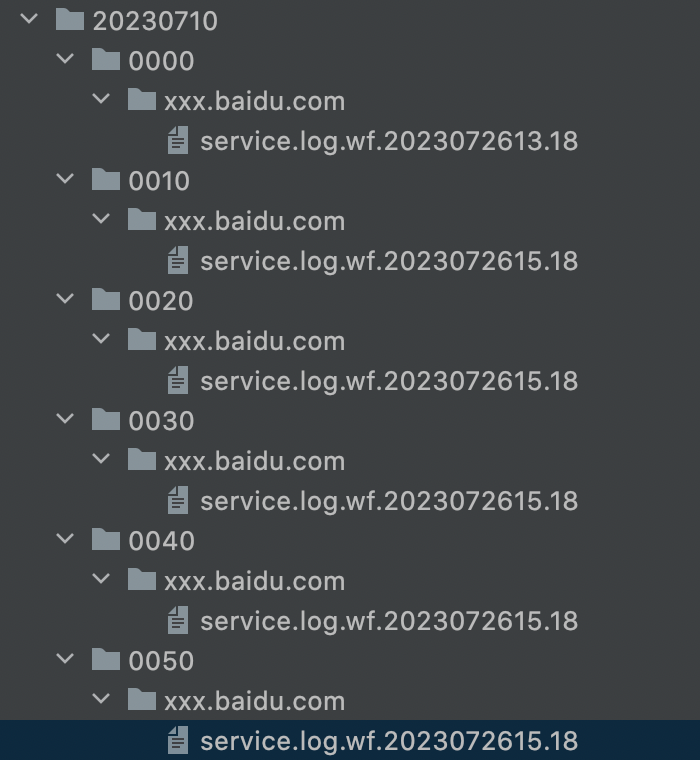
每一条日志文件service.log.wf.2023072615.18里面的内容为:一行接着一行的warning日志,部分warning日志带有接口信息
WARNING 24762924 20230726 13:00:24 Present.php:44 qa_traffic_playback: {"request_method":"POST","service_method":"getUserInfo","path":"\/service\/test?ngscfr=getUserInfo_10.221.110.27_fm_smallapp&method=getUserInfo&format=php&ie=utf-8","query":{"ngscfr":"getUserInfo_10.221.110.27_fm_smallapp","method":"getUserInfo","format":"php","ie":"utf-8"},"post":{"account_id":"59","account_type":"1","user_id":"123456","method":"getUserInfo","format":"php","ie":"utf-8","service_array_key":"a:0:{}","tb_sig":"7f2fcc8b398ca16979"}}
WARNING 24762924 20230726 13:00:24 Present.php:44 qa_traffic_playback: {"request_method":"POST","service_method":"getUserInfo","path":"\/service\/test?ngscfr=getUserInfo_10.221.110.27_fm_smallapp&method=getUserInfo&format=php&ie=utf-8","query":{"ngscfr":"getUserInfo_10.221.110.27_fm_smallapp","method":"getUserInfo","format":"php","ie":"utf-8"},"post":{"account_id":"59","account_type":"1","user_id":"56789","method":"getUserInfo","format":"php","ie":"utf-8","service_array_key":"a:0:{}","tb_sig":"7f2fcc8b398ca16979"}}
import os
import re
import json
import multiprocessingdef parse_log_file(log_file):log_entries = []with open(log_file, 'r') as file:for line in file:if '{"request_method"' in line:# 使用正则表达式匹配 JSON 字典pattern = re.compile(r'{.*?}}')match = pattern.search(line)if match:json_dict = match.group()print("json_dict",json_dict)# 解析 JSON 字典data = json.loads(json_dict)print("data",data)print("解析 JSON 字典",json_dict)return log_entriesdef process_directory(directory, results_dict):log_files = []for root, dirs, files in os.walk(directory):for file in files:if file.startswith('service_present.log.wf'):log_file = os.path.join(root, file)log_files.append(log_file)# 在这里处理每个匹配到的日志文件print("log_files B", log_file)parsed_entries=[]for log_file in log_files:parsed_entries += parse_log_file(log_file)results_dict[directory] = parsed_entriesif __name__ == '__main__':root_directory = '/home/work/' # 指定根目录results = multiprocessing.Manager().dict()processes = []for subdir in os.listdir(root_directory):directory = os.path.join(root_directory, subdir)if os.path.isdir(directory):process = multiprocessing.Process(target=process_directory, args=(directory, results))processes.append(process)process.start()for process in processes:process.join()for directory, entries in results.items():print(f'Directory: {directory}')for entry in entries:print(entry)解释一下这个程序,process_directory方法用来遍历日志目录,获取日志文件的绝对路径,parse_log_file方法用来解析日志文件,利用正则表达式提取出日志里面含接口信息的Json字符串,并转化为字典存放,这段代码片段还有可以优化的地方,因为存在在字典非常占用内容,如果接口信息过多,可能会出现内存占用过高的情况,这时候可以选择将接口信息存入数据库或者Redis
最后再提一嘴,在实际应用过程当中,我们可能还要利用算法进行流量筛选,经过初筛和精筛拿到指定的流量,另外还需要统计回放下来的流量覆盖率,这样才能比较准确的衡量流量的覆盖程度
相关文章:
试试流量回放,不用人工写自动化测试case了
大家好,我是洋子,接触过接口自动化测试的同学都知道,我们一般要基于某种自动化测试框架,编写自动化case,编写自动化case的依据来源于接口文档,对照接口文档里面的请求参数进行人工添加接口自动化case 其实…...

密钥管理系统功能及作用简介 安当加密
密钥管理系统的功能主要包括密钥生成、密钥注入、密钥备份、密钥恢复、密钥更新、密钥导出和服务,以及密钥的销毁等。 密钥生成:通过输入一到多组的密钥种子,按照可再现或不可再现的模式生成所需要的密钥。一般采用不可再现模式作为密钥生成…...

vue中watch属性的用法
在Vue中,watch属性用于监听一个数据的变化,并且在数据变化时执行一些操作。它可以观察一个具体的数据对象,从而在该数据对象发生变化时触发对应的回调函数。 使用watch属性的步骤如下: 在Vue实例中添加一个watch对象 new Vue({…...

Redis-使用java代码操作Redis
🏅我是默,一个在CSDN分享笔记的博主。📚📚 🌟在这里,我要推荐给大家我的专栏《Linux》。🎯🎯 🚀无论你是编程小白,还是有一定基础的程序员,这…...
0基础学习PyFlink——事件时间和运行时间的窗口
大纲 定制策略运行策略Reduce完整代码滑动窗口案例参考资料 在 《0基础学习PyFlink——时间滚动窗口(Tumbling Time Windows)》一文中,我们使用的是运行时间(Tumbling ProcessingTimeWindows)作为窗口的参考时间: reducedkeyed.window(TumblingProcess…...

Git Rebase 优化项目历史
在软件开发过程中,版本控制是必不可少的一环。Git作为当前最流行的版本控制系统,为开发者提供了强大的工具来管理和维护代码历史。git rebase是其中一个高级特性,它可以用来重新整理提交历史,使之更加清晰和线性。本文将详细介绍g…...

两种MySQL OCP认证应该如何选?
很多同学都找姚远老师说要参加MySQL OCP认证培训,但绝大部分同学并不知道MySQL OCP认证有两种,以MySQL 8.0为例。 一种是管理方向,叫:Oracle Certified Professional, MySQL 8.0 Database Administrator(我考试的比较…...
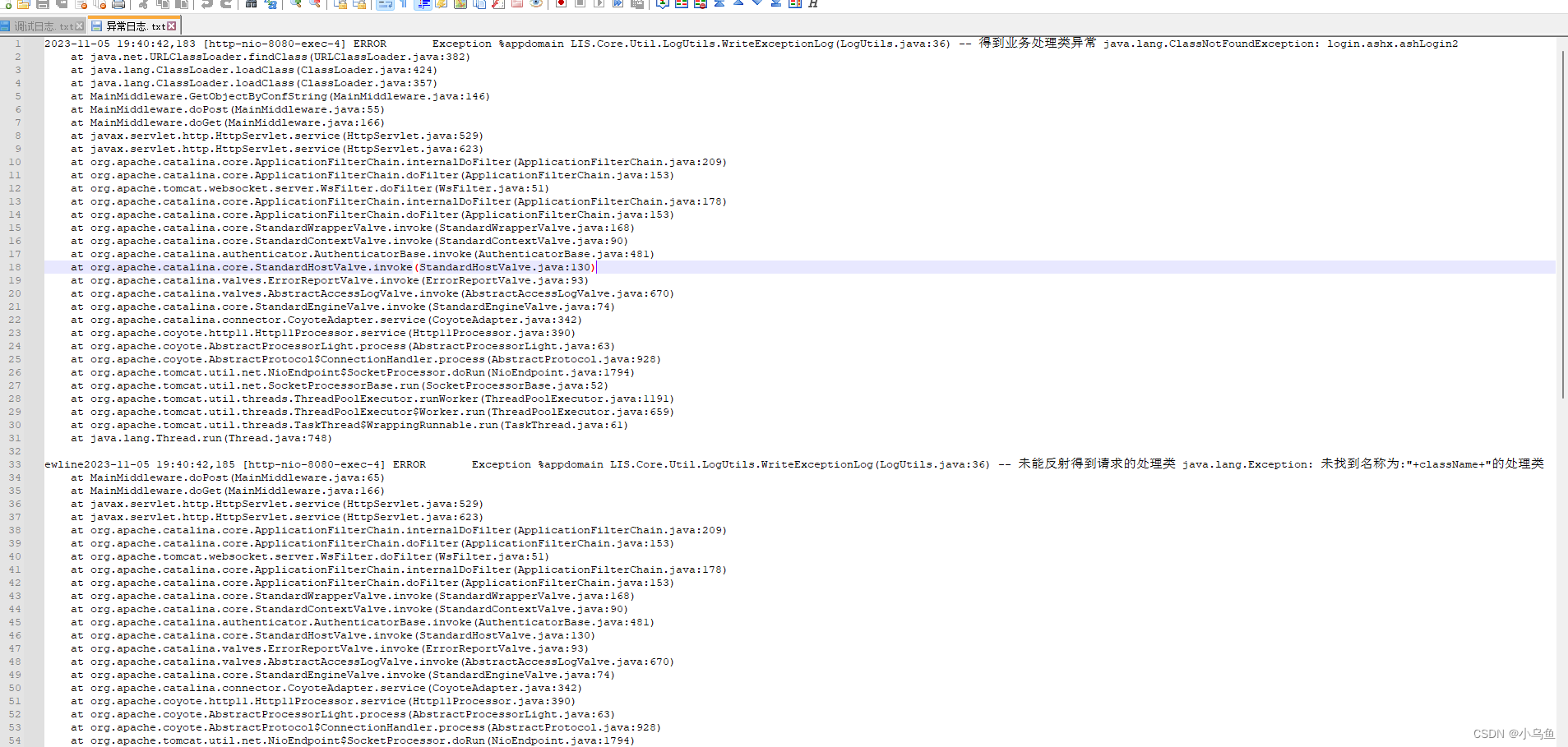
Java用log4j写日志
日志可以方便追踪和调试问题,以前用log4net写日志,换Java了改用log4j写日志,用法和log4net差不多。 到apache包下载下载log4j的包,解压后把下图两个jar包引入工程 先到网站根下加一个log4j2.xml的配置文件来配置日志的格式和参…...
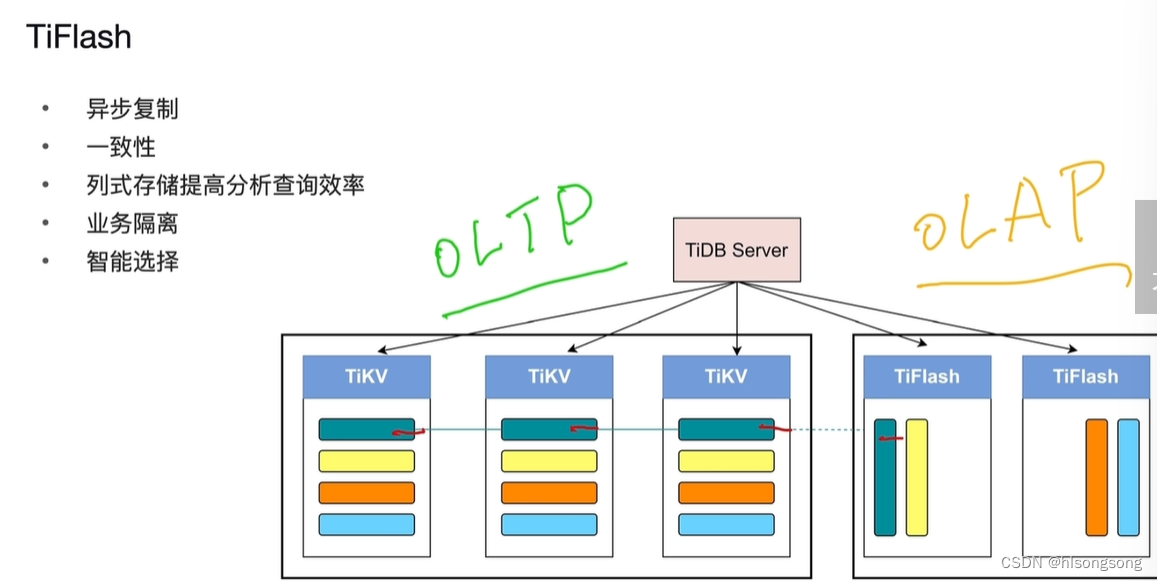
PCTA认证考试-01_TiDB数据库架构概述
TiDB 数据库架构概述 一、学习目标 理解 TiDB 数据库整体结构。了解 TiDB Server,TiKV,TiFlash 和 PD 的主要功能。 二、TiDB 体系架构 1. TiDB Server 2. TiKV OLTP 3. Placement Driver 4. TiFlash OLAP OLTPOLAPHTAP...
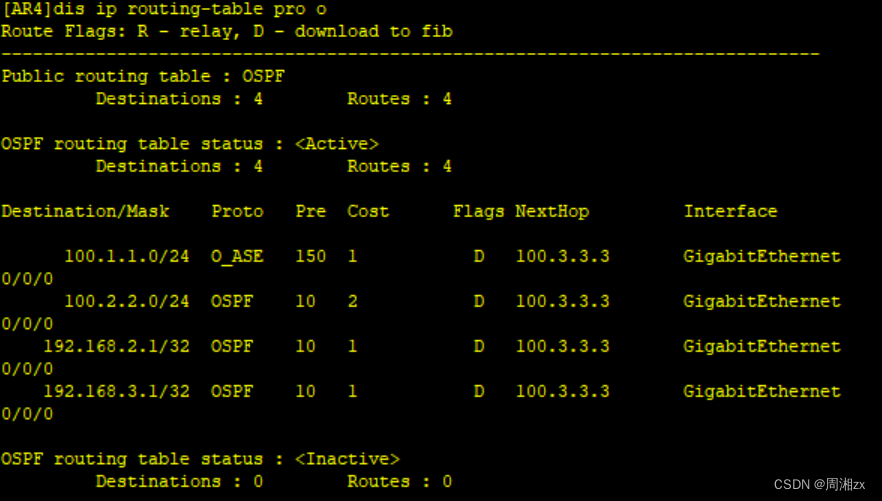
路由过滤路由引入
目录 一、实验拓扑 二、实验需求 三、实验步骤 1、配置IP地址 2、配置RIP和OSPF 3、配置路由引入 4、使用路由过滤,使 R4 无法学到 R1 的业务网段路由,要求使用 prefix-list 进行匹配 5、OSPF 区域中不能出现 RIP 协议报文 一、实验拓扑 二、实…...

视频剪辑技巧:批量合并视频,高效省时,添加背景音乐提升品质
随着社交媒体的兴起,视频制作越来越受到人们的关注。掌握一些视频剪辑技巧,可以让我们轻松地制作出令人惊艳的视频。本文将介绍一种高效、省时的视频剪辑技巧,帮助您批量合并视频、添加背景音乐,并提升视频品质。现在一起来看看云…...

数据可视化篇——pyecharts模块
在之前的文章中我们已经介绍过爬虫采集到的数据用途之一就是用作可视化报表,而pyecharts作为Python中可视化工具的一大神器必然就受到广大程序员的喜爱。 一、什么是Echarts? ECharts 官方网站 : https://echarts.apache.org/zh/index.html ECharts 是…...

Python--快速入门二
Python--快速入门二 1.Python数据类型 1.可以通过索引获取字符串中特定位置的字符: a "Hello" print(a[3]) 2.len函数获取字符串的长度: a "Hello" print(a) print(len(a)) 3.空值类型表示完全没有值: 若不确定当…...
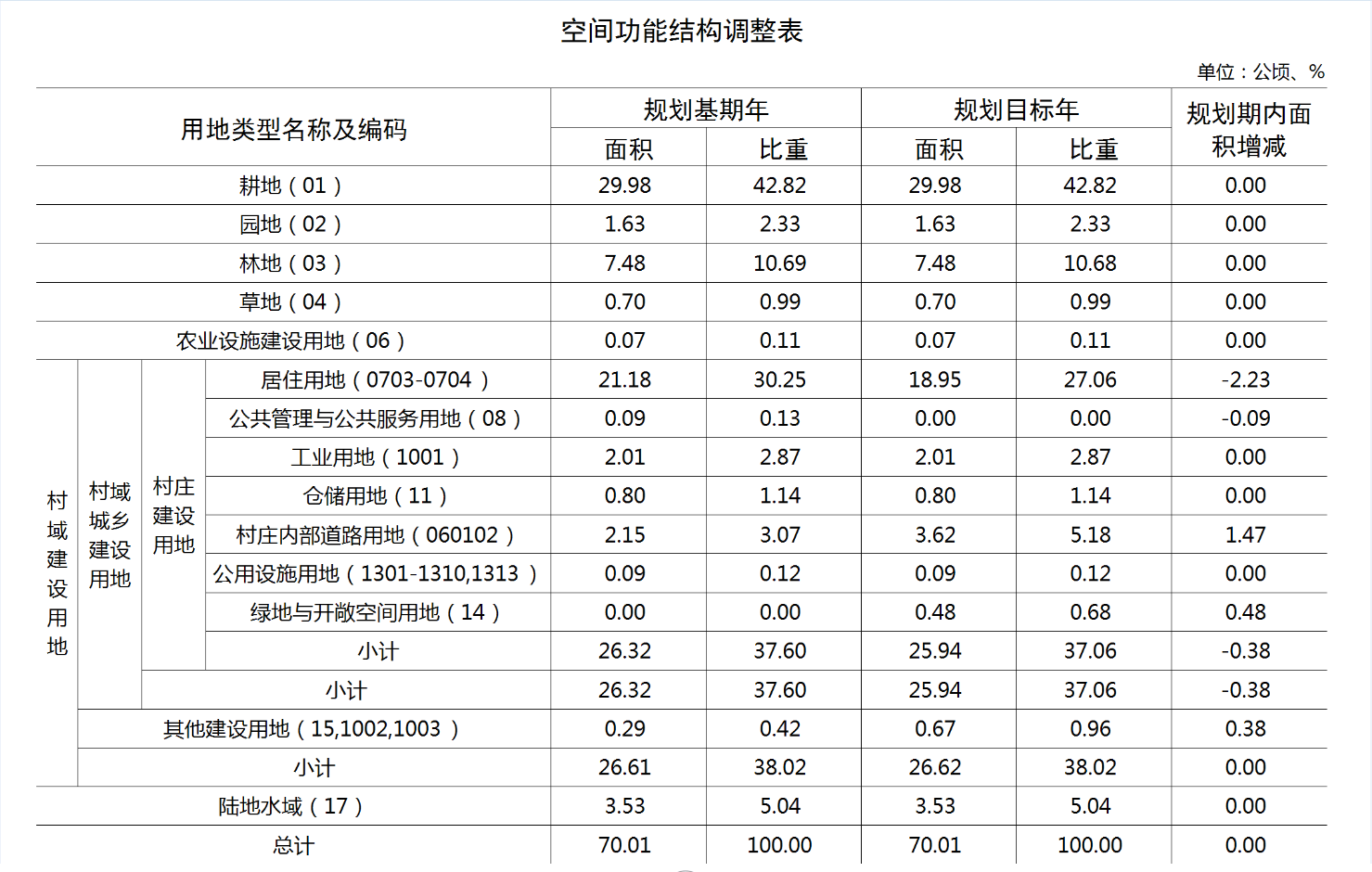
【ArcGIS Pro二次开发】(74):Python、C#实现Excel截图导出图片
以村庄规划制图为例,通过对现状和规划用地的统计,生成Excel格式的【空间功能结构调整表】后,需要进一步将表格导出成图片,并嵌入到图集中,这样可以实现全流程不用手动参与,让制图的流程完全自动化。 关于E…...

74HC138逻辑芯片
文章目录 74系列逻辑芯片——74HC138基础信息描述特征应用范围 功能信息封装引脚基本电路 扩展性能分析 74系列逻辑芯片——74HC138 基础信息 描述 74HC138器件设计用于需要极短传播延迟时间的高性能存储器解码或数据路由应用;在高性能存储系统中,可使用…...
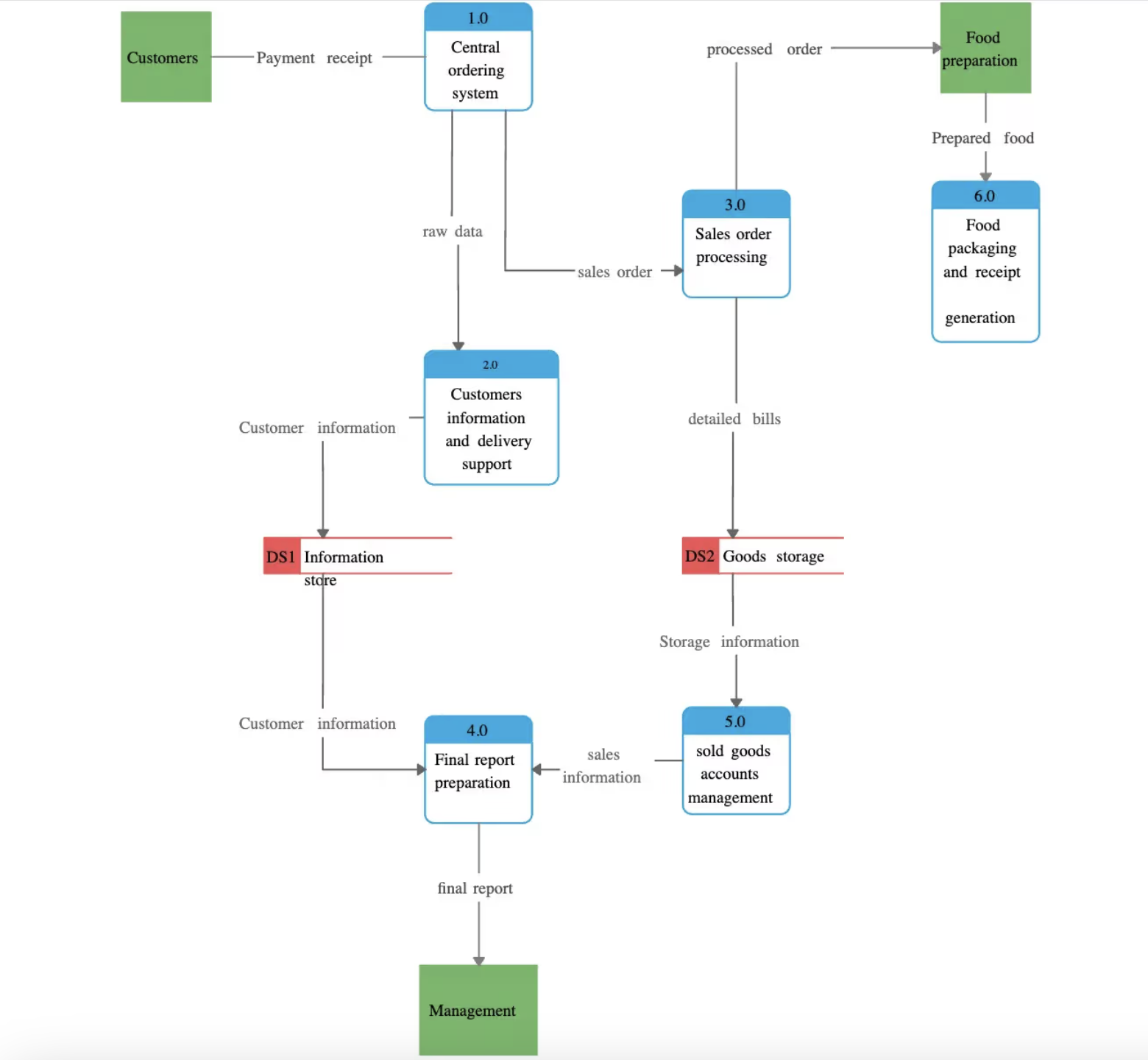
【架构图解】API架构图解:如何以图表形式展现复杂系统
文章目录 前言序列图组件图数据流程图结论 前言 架构图是链接到 API 的不同组件/服务如何相互交互的直观表示。 当需要理解 API 的架构并将其传达给不同的利益相关者(包括其他开发人员、项目经理和客户)时,这些图表非常有用。 图表/视觉效…...
D-link未授权访问以及远程代码执行
随便输入一个错误密码,会跳转到页面: /page/login/login.html?errorfail继续访问有效页面漏洞url: /Admin.shtml然后访问管理页面去更改管理密码 直接构造payload访问漏洞url: /cgi-bin/execute_cmd.cgi?cmdid执行命令&#…...

flask踩坑集锦
很久之前用过flask,那时候是跟着教程,教程怎么做我就怎么做,没有仔细考虑过。 现在是全靠文档和搜索一步一步搭建,忘了很多东西,就碰了很多壁,浅浅记录一下子。 1.Jinja2的模板继承,是指抽出每…...
VulnHub jarbas
🍬 博主介绍👨🎓 博主介绍:大家好,我是 hacker-routing ,很高兴认识大家~ ✨主攻领域:【渗透领域】【应急响应】 【python】 【VulnHub靶场复现】【面试分析】 🎉点赞➕评论➕收藏…...

基因预测软件prodigal的使用
Prodigal是一款常用的基因预测软件,可以用于预测原核生物基因组中的开放阅读框(ORF),并根据不同的编码调用方式(如起始密码子和终止密码子)对其进行注释。 以下是使用Prodigal进行基因预测的步骤ÿ…...

工业自动化通信选型指南:为什么HSLCommunication比传统Modbus更适合你的项目?
工业自动化通信协议深度解析:HSLCommunication如何重塑设备互联标准 在工业4.0时代背景下,设备间的实时数据交互已成为智能制造系统的生命线。作为系统架构师,我曾参与多个大型自动化项目,亲眼见证过通信协议选型不当导致的产线瘫…...

颠覆认知:重新定义CPU性能边界的智能优化指南
颠覆认知:重新定义CPU性能边界的智能优化指南 【免费下载链接】CPUDoc 项目地址: https://gitcode.com/gh_mirrors/cp/CPUDoc 当我们谈论电脑性能时,大多数人会想到升级硬件或超频,但真正的性能瓶颈往往藏在系统调度的细节里。本文将…...

【深度解析】二维半导体晶体管:突破摩尔定律的下一代集成电路核心
1. 二维半导体晶体管的崛起:摩尔定律的终结者? 当硅基芯片的制程工艺逼近1纳米物理极限时,整个集成电路行业都在寻找"后硅时代"的突破口。我第一次在实验室见到二硫化钼(MoS2)晶体管时,那片厚度不…...

NASA Earthdata保姆级教程:手把手教你用矩形框批量下载MODIS和VIIRS遥感数据
NASA Earthdata零基础实战:从注册到批量下载MODIS/VIIRS遥感数据的完整指南 第一次接触NASA Earthdata网站时,面对满屏的专业术语和复杂操作界面,大多数科研新手都会感到手足无措。作为全球最大的对地观测数据平台之一,Earthdata…...

利用GCC特性实现MCU固件版本号的绝对地址存储
1. 为什么需要绝对地址存储版本号 在嵌入式开发中,固件版本号是一个看似简单却至关重要的信息。想象一下你正在调试一台远程设备,突然发现它运行的是旧版本固件,但翻遍整个代码库都找不到版本号定义在哪里——这种场景我遇到过不止一次。传统…...

Windows Defender Remover:彻底解决Windows安全组件冲突与性能瓶颈的终极方案
Windows Defender Remover:彻底解决Windows安全组件冲突与性能瓶颈的终极方案 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitc…...

AI音频分离效率提升指南:Demucs多轨道提取技术实战
AI音频分离效率提升指南:Demucs多轨道提取技术实战 【免费下载链接】demucs Code for the paper Hybrid Spectrogram and Waveform Source Separation 项目地址: https://gitcode.com/gh_mirrors/de/demucs 在数字音频处理领域,高质量音频分离技术…...

实战指南:利用快马平台,无需下载qoderwork即可构建Vue3库存管理系统
最近在做一个库存管理系统的需求,发现很多开发者都在找qoderwork这类代码生成工具。但实际用下来发现,这类工具生成的代码往往需要二次修改,而且下载安装过程也挺麻烦的。后来尝试了InsCode(快马)平台,发现它不仅能直接生成可运行…...

手把手教你用Stable Diffusion v1.5:从安装到生成第一张AI图片
手把手教你用Stable Diffusion v1.5:从安装到生成第一张AI图片 1. 引言 你是否曾经想过,只需输入一段文字描述,就能让AI自动生成一张精美的图片?Stable Diffusion v1.5作为AI图像生成领域的经典模型,让这个梦想变成了…...

GPU与CPU差异分析
在人工智能、高性能计算和图形渲染等领域的快速发展推动下,GPU与CPU这两种处理器架构正经历前所未有的变革与融合。本文将从基本概念、架构差异、应用场景及未来发展趋势等维度,系统分析GPU与CPU的协同关系与各自优势,为读者提供全面的技术洞察。 一、基本概念与历史演进 …...