Prometheus接入AlterManager配置企业微信告警(基于K8S环境部署)
文章目录
- 一、创建企业微信机器人
- 二、配置AlterManager告警发送至企业微信
- 三、Prometheus接入AlterManager配置
- 四、部署Prometheus+AlterManager(放到一个Pod中)
- 五、测试告警
注意:请基于 Prometheus+Grafana监控K8S集群(基于K8S环境部署)文章之上做本次实验。
一、创建企业微信机器人
1、创建企业微信机器人
点击登入企业微信网页版:
应用管理 > 机器人 > 创建应用
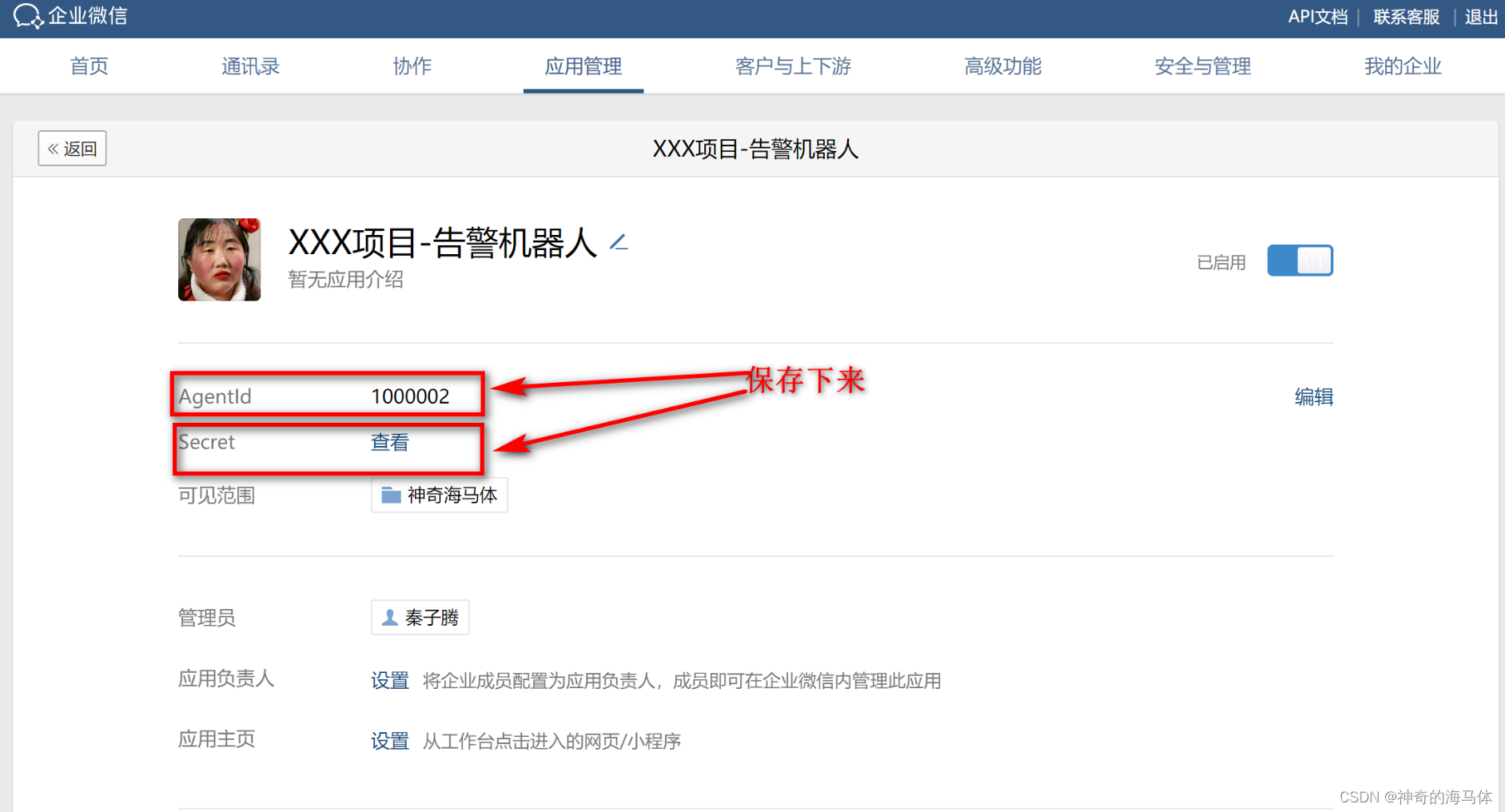
创建好之后如上图,我们获取 点击查看获取 Secret 值。
2、获取企业ID
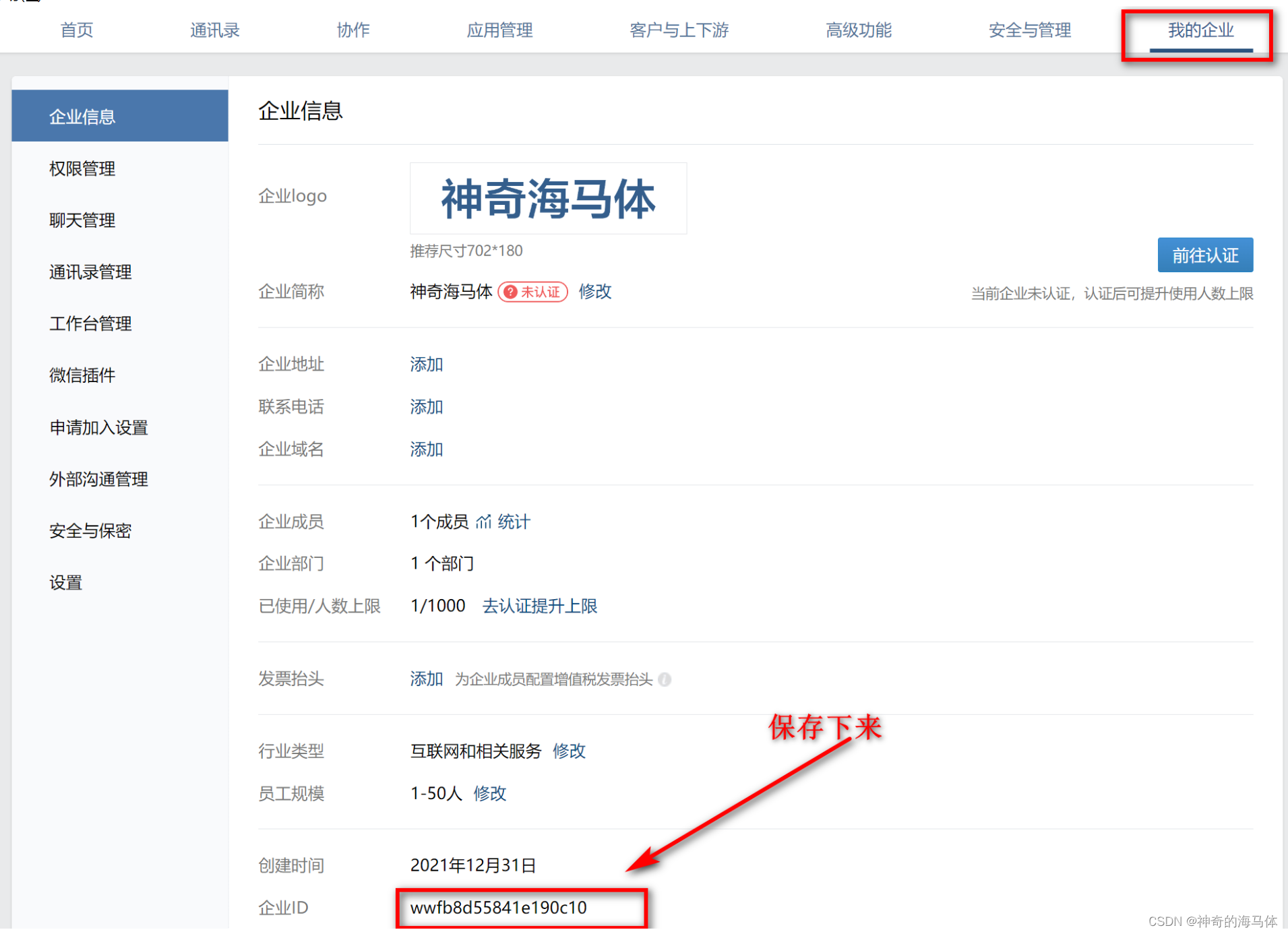
二、配置AlterManager告警发送至企业微信
1、创建AlterManager ConfigMap资源清单
vim alertmanager-cm.yaml
---
kind: ConfigMap
apiVersion: v1
metadata:name: alertmanagernamespace: prometheus
data:alertmanager.yml: |-templates:- '/alertmanager/template/WeChat.tmpl'global:resolve_timeout: 1msmtp_smarthost: 'smtp.163.com:25'smtp_from: '18145536045@163.com'smtp_auth_username: '18145536045@163.com'smtp_auth_password: 'KCGZFUDCCKMNZMKB'smtp_require_tls: falseroute:group_by: [alertname]group_wait: 10sgroup_interval: 10srepeat_interval: 10mreceiver: wechat-001receivers:- name: 'wechat-001'wechat_configs:- corp_id: wwfb8d55841e190c10 # 企业IDto_user: '@all' # 发送所有人agent_id: 1000002 # agentIDapi_secret: wa6kWECFthSpvdhcF-RPgjrIBzUvm-SpqXXXXXXXXXX # secret
执行YAML资源清单:
kubectl apply -f alertmanager-cm.yaml
三、Prometheus接入AlterManager配置
1、创建新的Prometheus ConfigMap资源清单,添加监控K8S集群告警规则
vim prometheus-alertmanager-cfg.yaml
---
kind: ConfigMap
apiVersion: v1
metadata:labels:app: prometheusname: prometheus-confignamespace: prometheus
data:prometheus.yml: |rule_files: - /etc/prometheus/rules.yml # 告警规则位置alerting:alertmanagers:- static_configs:- targets: ["localhost:9093"] # 接入AlterManagerglobal:scrape_interval: 15sscrape_timeout: 10sevaluation_interval: 1mscrape_configs:- job_name: 'kubernetes-node'kubernetes_sd_configs:- role: noderelabel_configs:- source_labels: [__address__]regex: '(.*):10250'replacement: '${1}:9100'target_label: __address__action: replace- action: labelmapregex: __meta_kubernetes_node_label_(.+)- job_name: 'kubernetes-node-cadvisor'kubernetes_sd_configs:- role: nodescheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- action: labelmapregex: __meta_kubernetes_node_label_(.+)- target_label: __address__replacement: kubernetes.default.svc:443- source_labels: [__meta_kubernetes_node_name]regex: (.+)target_label: __metrics_path__replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor- job_name: 'kubernetes-apiserver'kubernetes_sd_configs:- role: endpointsscheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]action: keepregex: default;kubernetes;https- job_name: 'kubernetes-service-endpoints'kubernetes_sd_configs:- role: endpointsrelabel_configs:- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]action: keepregex: true- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]action: replacetarget_label: __scheme__regex: (https?)- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]action: replacetarget_label: __address__regex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2- action: labelmapregex: __meta_kubernetes_service_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_service_name]action: replacetarget_label: kubernetes_name - job_name: 'kubernetes-pods' # 监控Pod配置,添加注解后才可以被发现kubernetes_sd_configs:- role: podrelabel_configs:- action: keepregex: truesource_labels:- __meta_kubernetes_pod_annotation_prometheus_io_scrape- action: replaceregex: (.+)source_labels:- __meta_kubernetes_pod_annotation_prometheus_io_pathtarget_label: __metrics_path__- action: replaceregex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2source_labels:- __address__- __meta_kubernetes_pod_annotation_prometheus_io_porttarget_label: __address__- action: labelmapregex: __meta_kubernetes_pod_label_(.+)- action: replacesource_labels:- __meta_kubernetes_namespacetarget_label: kubernetes_namespace- action: replacesource_labels:- __meta_kubernetes_pod_nametarget_label: kubernetes_pod_name- job_name: 'kubernetes-etcd' # 监控etcd配置scheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ca.crtcert_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.crtkey_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.keyscrape_interval: 5sstatic_configs:- targets: ['16.32.15.200:2379']rules.yml: | # K8S集群告警规则配置文件groups:- name: examplerules:- alert: apiserver的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: apiserver的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: etcd的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: etcd的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: kube-state-metrics的cpu使用率大于80%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%"value: "{{ $value }}%"threshold: "80%" - alert: kube-state-metrics的cpu使用率大于90%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 0for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%"value: "{{ $value }}%"threshold: "90%" - alert: coredns的cpu使用率大于80%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%"value: "{{ $value }}%"threshold: "80%" - alert: coredns的cpu使用率大于90%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%"value: "{{ $value }}%"threshold: "90%" - alert: kube-proxy打开句柄数>600expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kube-proxy打开句柄数>1000expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-schedule打开句柄数>600expr: process_open_fds{job=~"kubernetes-schedule"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-schedule打开句柄数>1000expr: process_open_fds{job=~"kubernetes-schedule"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-controller-manager打开句柄数>600expr: process_open_fds{job=~"kubernetes-controller-manager"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-controller-manager打开句柄数>1000expr: process_open_fds{job=~"kubernetes-controller-manager"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-apiserver打开句柄数>600expr: process_open_fds{job=~"kubernetes-apiserver"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-apiserver打开句柄数>1000expr: process_open_fds{job=~"kubernetes-apiserver"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-etcd打开句柄数>600expr: process_open_fds{job=~"kubernetes-etcd"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-etcd打开句柄数>1000expr: process_open_fds{job=~"kubernetes-etcd"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: corednsexpr: process_open_fds{k8s_app=~"kube-dns"} > 600for: 2slabels:severity: warnning annotations:description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过600"value: "{{ $value }}"- alert: corednsexpr: process_open_fds{k8s_app=~"kube-dns"} > 1000for: 2slabels:severity: criticalannotations:description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过1000"value: "{{ $value }}"- alert: kube-proxyexpr: process_virtual_memory_bytes{job=~"kubernetes-kube-proxy"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: schedulerexpr: process_virtual_memory_bytes{job=~"kubernetes-schedule"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kubernetes-controller-managerexpr: process_virtual_memory_bytes{job=~"kubernetes-controller-manager"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kubernetes-apiserverexpr: process_virtual_memory_bytes{job=~"kubernetes-apiserver"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kubernetes-etcdexpr: process_virtual_memory_bytes{job=~"kubernetes-etcd"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kube-dnsexpr: process_virtual_memory_bytes{k8s_app=~"kube-dns"} > 2000000000for: 2slabels:severity: warnningannotations:description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: HttpRequestsAvgexpr: sum(rate(rest_client_requests_total{job=~"kubernetes-kube-proxy|kubernetes-kubelet|kubernetes-schedule|kubernetes-control-manager|kubernetes-apiservers"}[1m])) > 1000for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): TPS超过1000"value: "{{ $value }}"threshold: "1000" - alert: Pod_restartsexpr: kube_pod_container_status_restarts_total{namespace=~"kube-system|default|monitor-sa"} > 0for: 2slabels:severity: warnningannotations:description: "在{{$labels.namespace}}名称空间下发现{{$labels.pod}}这个pod下的容器{{$labels.container}}被重启,这个监控指标是由{{$labels.instance}}采集的"value: "{{ $value }}"threshold: "0"- alert: Pod_waitingexpr: kube_pod_container_status_waiting_reason{namespace=~"kube-system|default"} == 1for: 2slabels:team: adminannotations:description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}启动异常等待中"value: "{{ $value }}"threshold: "1" - alert: Pod_terminatedexpr: kube_pod_container_status_terminated_reason{namespace=~"kube-system|default|monitor-sa"} == 1for: 2slabels:team: adminannotations:description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}被删除"value: "{{ $value }}"threshold: "1"- alert: Etcd_leaderexpr: etcd_server_has_leader{job="kubernetes-etcd"} == 0for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 当前没有leader"value: "{{ $value }}"threshold: "0"- alert: Etcd_leader_changesexpr: rate(etcd_server_leader_changes_seen_total{job="kubernetes-etcd"}[1m]) > 0for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 当前leader已发生改变"value: "{{ $value }}"threshold: "0"- alert: Etcd_failedexpr: rate(etcd_server_proposals_failed_total{job="kubernetes-etcd"}[1m]) > 0for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 服务失败"value: "{{ $value }}"threshold: "0"- alert: Etcd_db_total_sizeexpr: etcd_debugging_mvcc_db_total_size_in_bytes{job="kubernetes-etcd"} > 10000000000for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}):db空间超过10G"value: "{{ $value }}"threshold: "10G"- alert: Endpoint_readyexpr: kube_endpoint_address_not_ready{namespace=~"kube-system|default"} == 1for: 2slabels:team: adminannotations:description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.endpoint}}不可用"value: "{{ $value }}"threshold: "1"- name: 物理节点状态-监控告警rules:- alert: 物理节点cpu使用率expr: 100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)*100 > 90for: 2slabels:severity: ccriticalannotations:summary: "{{ $labels.instance }}cpu使用率过高"description: "{{ $labels.instance }}的cpu使用率超过90%,当前使用率[{{ $value }}],需要排查处理" - alert: 物理节点内存使用率expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 90for: 2slabels:severity: criticalannotations:summary: "{{ $labels.instance }}内存使用率过高"description: "{{ $labels.instance }}的内存使用率超过90%,当前使用率[{{ $value }}],需要排查处理"- alert: InstanceDownexpr: up == 0for: 2slabels:severity: criticalannotations: summary: "{{ $labels.instance }}: 服务器宕机"description: "{{ $labels.instance }}: 服务器延时超过2分钟"- alert: 物理节点磁盘的IO性能expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高!"description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})"- alert: 入网流量带宽expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 流入网络带宽过高!"description: "{{$labels.mountpoint }}流入网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"- alert: 出网流量带宽expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 流出网络带宽过高!"description: "{{$labels.mountpoint }}流出网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"- alert: TCP会话expr: node_netstat_Tcp_CurrEstab > 1000for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!"description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)"- alert: 磁盘容量expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 磁盘分区使用率过高!"description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"
执行资源清单:
kubectl apply -f prometheus-alertmanager-cfg.yaml
2、由于在prometheus中新增了etcd,所以生成一个etcd-certs,这个在部署prometheus需要
kubectl -n prometheus create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/server.key --from-file=/etc/kubernetes/pki/etcd/server.crt --from-file=/etc/kubernetes/pki/etcd/ca.crt
四、部署Prometheus+AlterManager(放到一个Pod中)
1、在node-1节点创建/data/alertmanager目录,存放alertmanager数据
mkdir /data/alertmanager/template -p
chmod -R 777 /data/alertmanager
2、在node-1节点创建WeChat报警模板
vim /data/alertmanager/template/WeChat.tmpl{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
=========xxx环境监控报警 =========
告警状态:{{ .Status }}
告警级别:{{ .Labels.severity }}
告警类型:{{ $alert.Labels.alertname }}
故障主机: {{ $alert.Labels.instance }} {{ $alert.Labels.pod }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
触发阀值:{{ .Annotations.value }}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
=========xxx环境异常恢复 =========
告警类型:{{ .Labels.alertname }}
告警状态:{{ .Status }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
恢复时间: {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {{ $alert.Labels.instance }}
{{- end }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- end }}
3、删除旧的prometheus deployment资源
kubectl delete deploy prometheus-server -n prometheus
4、创建deployment资源
vim prometheus-alertmanager-deploy.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:name: prometheus-servernamespace: prometheuslabels:app: prometheus
spec:replicas: 1selector:matchLabels:app: prometheuscomponent: server#matchExpressions:#- {key: app, operator: In, values: [prometheus]}#- {key: component, operator: In, values: [server]}template:metadata:labels:app: prometheuscomponent: serverannotations:prometheus.io/scrape: 'false'spec:nodeName: node-1 # 调度到node-1节点serviceAccountName: prometheus # 指定sa服务账号containers:- name: prometheusimage: prom/prometheus:v2.33.5imagePullPolicy: IfNotPresentcommand:- "/bin/prometheus"args:- "--config.file=/etc/prometheus/prometheus.yml"- "--storage.tsdb.path=/prometheus"- "--storage.tsdb.retention=24h"- "--web.enable-lifecycle"ports:- containerPort: 9090protocol: TCPvolumeMounts:- mountPath: /etc/prometheusname: prometheus-config- mountPath: /prometheus/name: prometheus-storage-volume- name: k8s-certsmountPath: /var/run/secrets/kubernetes.io/k8s-certs/etcd/- name: alertmanager#image: prom/alertmanager:v0.14.0image: prom/alertmanager:v0.23.0imagePullPolicy: IfNotPresentargs:- "--config.file=/etc/alertmanager/alertmanager.yml"- "--log.level=debug"ports:- containerPort: 9093protocol: TCPname: alertmanagervolumeMounts:- name: alertmanager-configmountPath: /etc/alertmanager- name: alertmanager-storagemountPath: /alertmanager- name: localtimemountPath: /etc/localtimevolumes:- name: prometheus-configconfigMap:name: prometheus-config- name: prometheus-storage-volumehostPath:path: /datatype: Directory- name: k8s-certssecret:secretName: etcd-certs- name: alertmanager-configconfigMap:name: alertmanager- name: alertmanager-storagehostPath:path: /data/alertmanagertype: DirectoryOrCreate- name: localtimehostPath:path: /usr/share/zoneinfo/Asia/Shanghai
执行YAML资源清单:
kubectl apply -f prometheus-alertmanager-deploy.yaml
查看状态:
kubectl get pods -n prometheus

5、创建AlterManager SVC资源
vim alertmanager-svc.yaml
---
apiVersion: v1
kind: Service
metadata:labels:name: prometheuskubernetes.io/cluster-service: 'true'name: alertmanagernamespace: prometheus
spec:ports:- name: alertmanagernodePort: 30066port: 9093protocol: TCPtargetPort: 9093selector:app: prometheussessionAffinity: Nonetype: NodePort
执行YAML资源清单:
kubectl apply -f alertmanager-svc.yaml
查看状态:
kubectl get svc -n prometheus

五、测试告警
浏览器访问:http://IP:30066
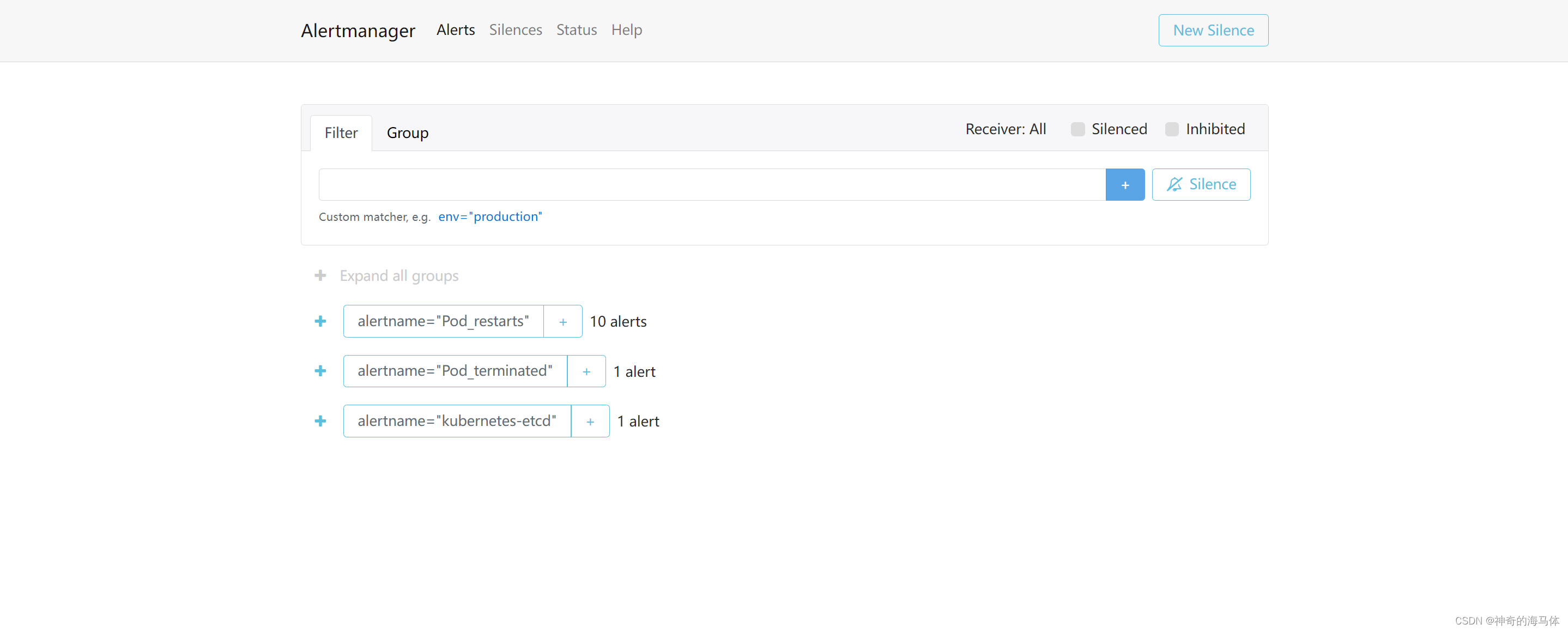
如上图可以看到,Prometheus的告警信息已经发到AlterManager了,AlertManager收到报警数据后,会将警报信息进行分组,然后根据AlertManager配置的 group_wait 时间先进行等待。等wait时间过后再发送报警信息至企业微信!
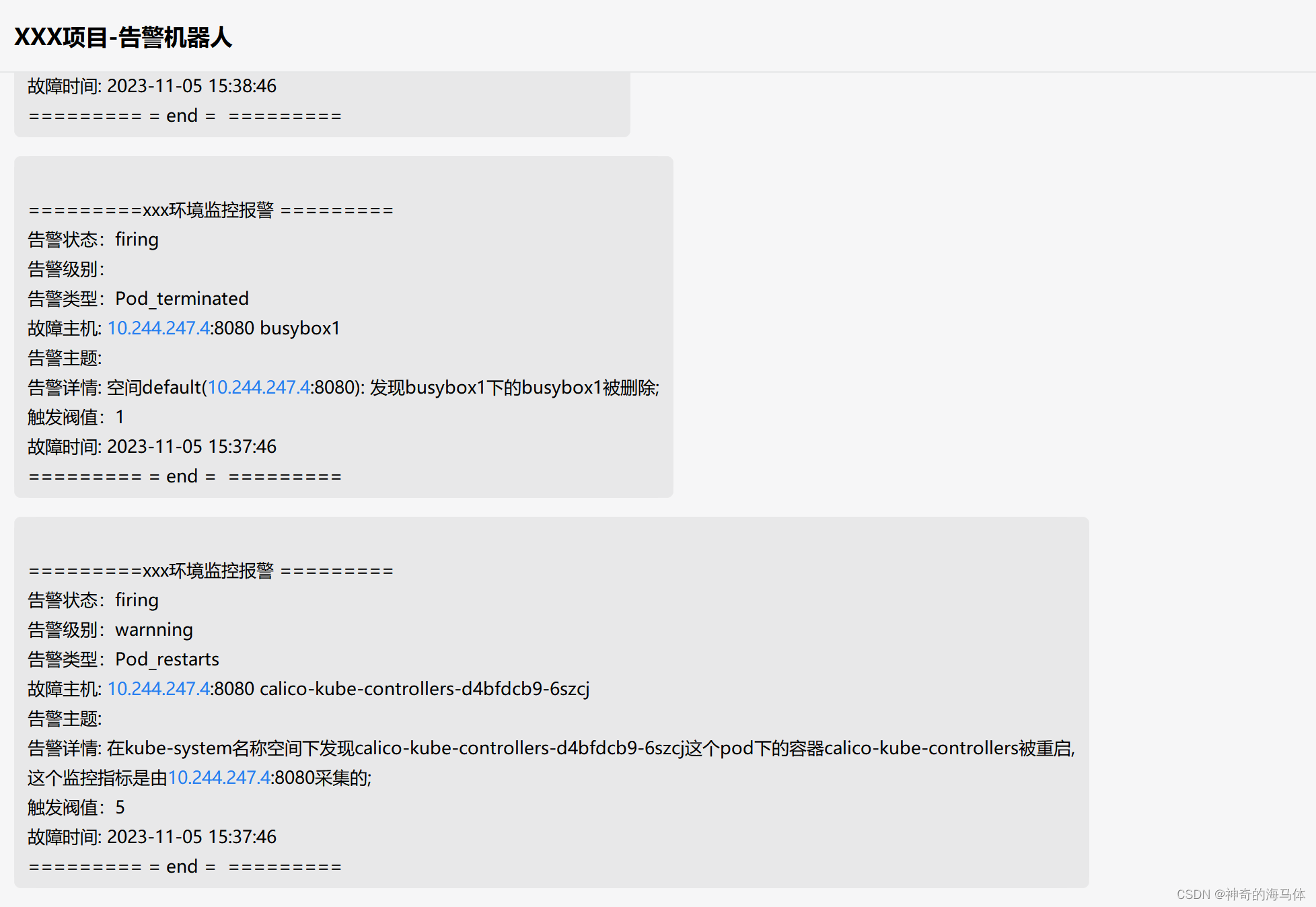
如上图,告警信息已经成功发往企业微信了!!!
相关文章:
Prometheus接入AlterManager配置企业微信告警(基于K8S环境部署)
文章目录 一、创建企业微信机器人二、配置AlterManager告警发送至企业微信三、Prometheus接入AlterManager配置四、部署PrometheusAlterManager(放到一个Pod中)五、测试告警 注意:请基于 PrometheusGrafana监控K8S集群(基于K8S环境部署)文章之上做本次实验。 一、创…...

11.1 Linux 设备树
一、什么是设备树? 设备树(Device Tree),描述设备树的文件叫做 DTS(DeviceTree Source),这个 DTS 文件采用树形结构描述板级设备,也就是开发板上的设备信息: 树的主干就是系统总线, IIC 控制器、 GPIO 控制…...

万宾科技管网水位监测助力智慧城市的排水系统
以往如果要了解城市地下排水管网的水位变化,需要依靠人工巡检或者排查的方式,这不仅加大了人员的工作量,而且也为市政府带来了更多的工作难题。比如人员监管监测不到位或无法远程监控等情况,都会降低市政府对排水管网的管理能力&a…...
Glide transform CircleCrop()圆图,Kotlin
Glide transform CircleCrop()圆图,Kotlin import android.os.Bundle import android.widget.ImageView import androidx.appcompat.app.AppCompatActivity import com.bumptech.glide.load.resource.bitmap.CircleCropclass MainActivity : AppCompatActivity() {o…...
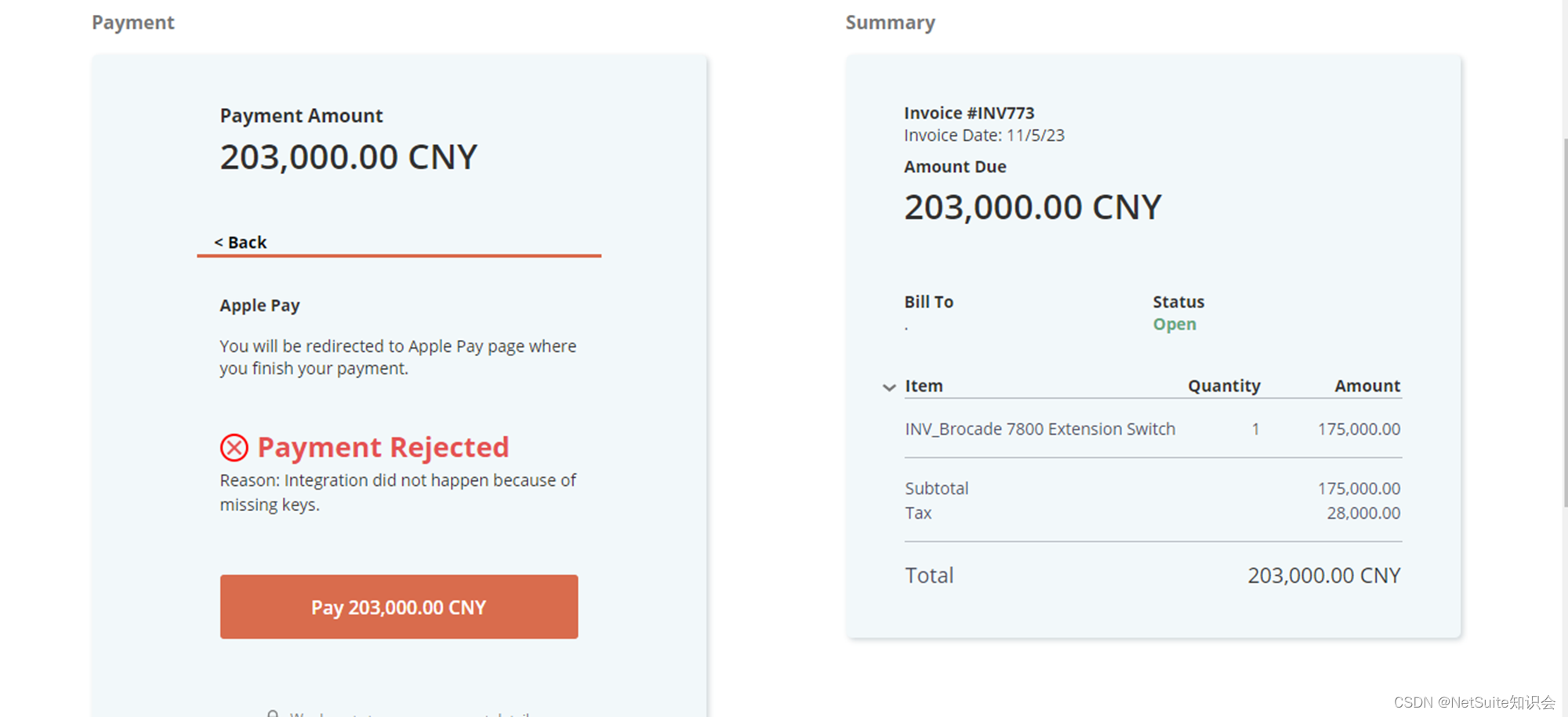
从NetSuite Payment Link杂谈财务自动化、数字化转型
最近在进行信息化的理论学习,让我有机会跳开软件功能,用更加宏大的视野,来审视我们在哪里,我们要到哪去。 在过去20多年,我们的财务软件经历了电算化、网络化、目前处于自动化、智能化阶段。从NetSuite这几年的功能发…...
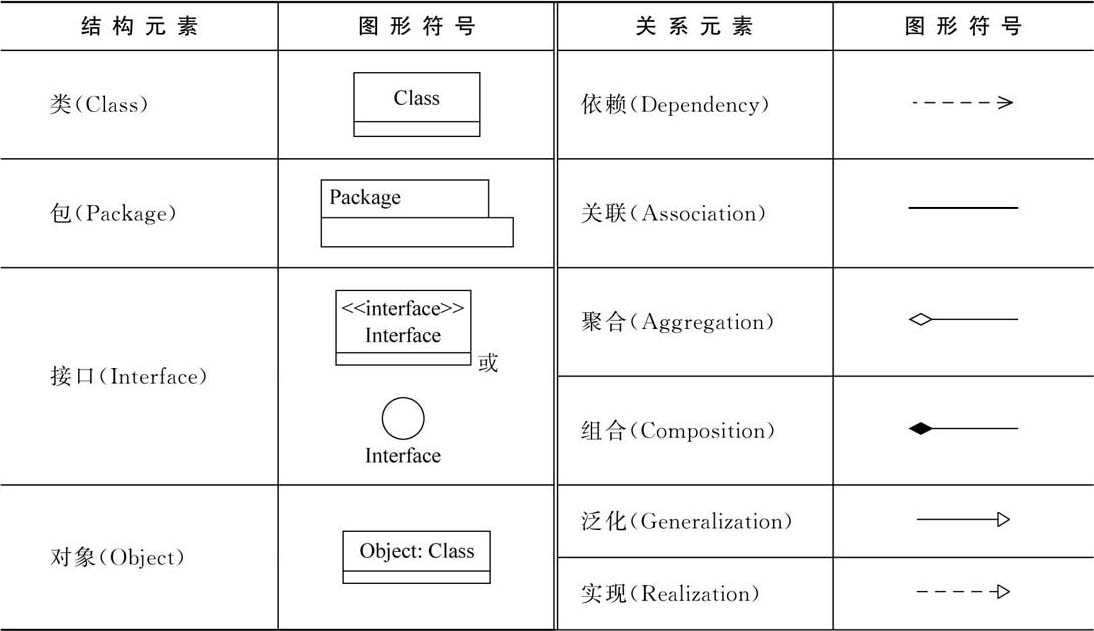
1.UML面向对象类图和关系
文章目录 4种静态结构图类图类的表示类与类之间的关系依赖关系(Dependency)关联关系(Association)聚合(Aggregation)组合(Composition)实现(Realization)继承/泛化(Inheritance/Generalization)常用的UML工具reference欢迎访问个人网络日志🌹🌹知行空间🌹🌹 4种静态结构…...

JAVA小说小程序系统是怎样开发的
随着移动互联网的普及,小说阅读已经成为人们休闲娱乐的重要方式之一。为了满足广大读者的需求,我们开发了一款基于JAVA编程语言的小说小程序系统。本系统旨在提供一种便捷、高效、有趣的阅读体验,让用户能够随时随地阅读最新、最热门的小说。…...
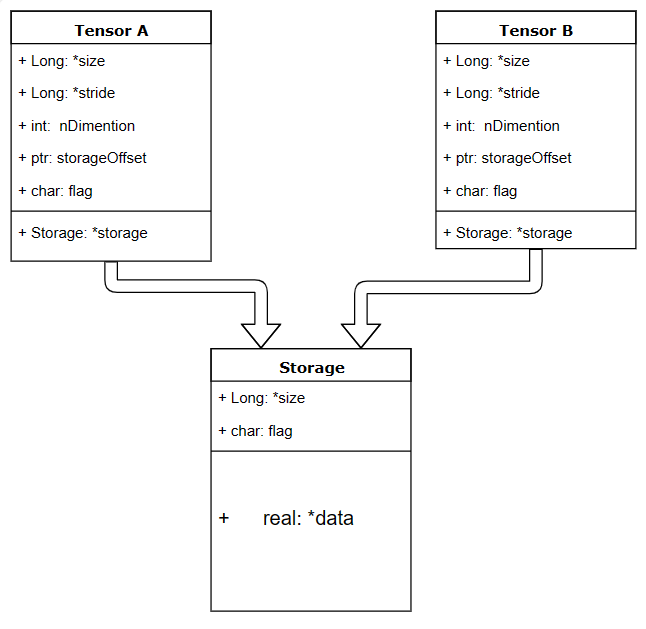
【深度学习】pytorch——Tensor(张量)详解
笔记为自我总结整理的学习笔记,若有错误欢迎指出哟~ pytorch——Tensor 简介创建Tensortorch.Tensor( )和torch.tensor( )的区别torch.Tensor( )torch.tensor( ) tensor可以是一个数(标量)、一维数组(向量)、二维数组&…...
装修服务预约小程序的内容如何
大小装修不断,市场中大小品牌也比较多,对需求客户来说,可以线下咨询也可以线上寻找品牌,总是可以找到满意的服务公司,而对装修公司来说如今线下流量匮乏,很多东西也难以通过线下方式承载,更需要…...

easypoi 导出Excel 使用总结
easypoi 导出Excel 导出Excel需要设置标题,且标题是多行,标题下面是列表头 设置表格标题 ExportParams headExportParams new ExportParams();StringBuilder buffer new StringBuilder("");buffer.append("1、课程名称:....…...
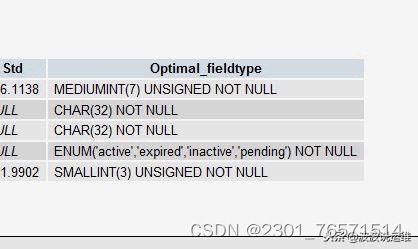
MySQL性能优化的最佳20条经验
概述 关于数据库的性能,这并不只是DBA才需要担心的事。当我们去设计数据库表结构,对操作数据库时(尤其是查表时的SQL语句),我们都需要注意数据操作的性能。下面讲下MySQL性能优化的一些点。 1. 为查询缓存优化你的查询 大多数的MySQL服务器…...
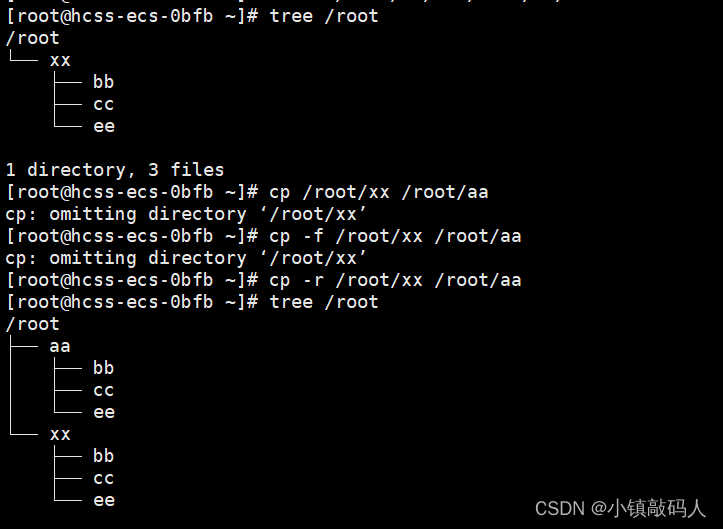
【Liunx基础】之指令(一)
【Liunx基础】之指令(一) 1.ls指令2.pwd命令3.cd指令4.touch指令5.mkdir指令(重要)6.rmdir指令与rm指令(重要)7.man指令(重要)8.cp指令(重要) 📃博客主页: 小…...

jQuery案例专题
jQuery案例专题 本学期主要担任的课程是js和jQuery,感觉用到的有一些案例挺有意思的,就对其进行了一下整理。 目录: 电影院的幕帘特效 手风琴特效 星光闪烁 网页轮播图 1.电影院的幕帘特效代码如下 html <!DOCTYPE html > <html…...

【Linux】服务器间免登陆访问
准备两台服务器,服务器A,服务器B 在服务器A中实现免登陆服务器B 进入服务器A操作 进入目录/root/.ssh cd /root/.ssh秘钥对使用默认文件名 生成秘钥对,在输入秘钥文件时直接回车则会使用默认文件名:id_rsa ssh-keygen -t rsa…...
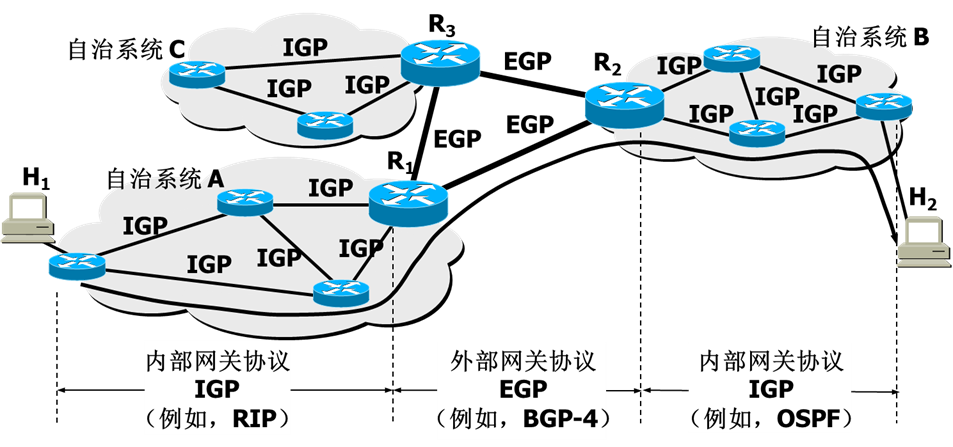
【信息安全原理】——IP及路由安全(学习笔记)
目录 🕒 1. IPv4协议及其安全性分析🕒 2. IPsec(IP Security)🕘 2.1 IPsec安全策略🕤 2.1.1 安全关联(Security Association, SA)🕤 2.1.2 安全策略(Security…...

【jvm】虚拟机之本地方法栈
目录 一、说明二、注意 一、说明 1. Java虚拟机栈用于管理Javaj法的调用,而本地方法栈用于管理本地方法的调用。 2. 本地方法栈,也是线程私有的。 3. 允许被实现成固定或者是可动态扩展的内存大小。 (在内存溢出方面是相同) 4. 如果线程请求分…...
)
『CV学习笔记』图像超分辨率等图像处理任务中的评价指标PSNR(峰值信噪比)
图像超分辨率等图像处理任务中的评价指标PSNR(峰值信噪比) 文章目录 一. PSNR(峰值信噪比)1.1. 定义1.2. 作用1.3. 例子1.4 . PSNR评价标准二. 参考文献一. PSNR(峰值信噪比) 1.1. 定义 峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)是图像超分辨率等图像处理任务中常用的一…...
)
【51nod 连续区间】 题解(序列分治)
题目描述 区间内的元素元素排序后 任意相邻两个元素值差为 1 1 1 的区间称为“连续区间”。 如 3 , 1 , 2 3,1,2 3,1,2 是连续区间, 3 , 1 , 4 3,1,4 3,1,4 不是连续区间。 给出一个 1 ∼ n 1 \sim n 1∼n 的排列,问有多少连续区间。 …...

10.30校招 实习 内推 面经
绿*泡*泡: neituijunsir 交流裙 ,内推/实习/校招汇总表格 1、校招|极目智能2024届校招 校招|极目智能2024届校招 2、校招|杭州极弱磁场国家重大科技基础设施研究院2024秋季校园招聘正式启动! 校招&…...

相比typescript,python的动态类型有什么优缺点?
以下是Python的动态类型相对于TypeScript的静态类型的一些优缺点: 1、Python的动态类型优点: 更灵活:Python的动态类型允许你在运行时更灵活地改变变量的类型,这对于快速原型设计和快速开发非常有帮助。 代码更简洁:…...

5种B站资源管理痛点解决方案:BiliTools跨平台工具高效管理指南
5种B站资源管理痛点解决方案:BiliTools跨平台工具高效管理指南 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTool…...

5962-88769022A,兼容LSTTL/TTL/CMOS逻辑与6.4mA驱动能力的防抖动逻辑门光耦
简介今天我要向大家介绍的是 Broadcom 的光电耦合器——5962-88769022A。它的每一条通道都由一颗AlGaAs发光二极管和一颗带有迟滞阈值的高增益光子探测器组成。当输入端接收到2mA到8mA的微小电流时,LED便会发光。而接收端的探测器不仅负责捕捉光信号,其内…...

ui-ux设计新手福音:用快马生成可运行代码,直观掌握pro-max级界面构建
作为一个刚接触UI/UX设计的新手,我常常被各种设计规范和交互逻辑搞得晕头转向。直到发现了InsCode(快马)平台,它让我通过可运行的代码示例,直观理解了专业级界面构建的全过程。今天就用一个用户登录注册界面的案例,分享我的学习心…...

通义千问3-Embedding-4B一键部署:5分钟搭建知识库向量化服务
通义千问3-Embedding-4B一键部署:5分钟搭建知识库向量化服务 1. 为什么选择Qwen3-Embedding-4B 1.1 模型核心优势 Qwen3-Embedding-4B是阿里通义千问系列中专注于文本向量化的4B参数双塔模型,具有以下突出特点: 高效能低消耗:…...

Docker+宝塔:零基础在Mac上快速搭建PHP开发环境
1. 为什么选择Docker宝塔组合? 作为一个在Mac上折腾过各种开发环境的老手,我强烈推荐Docker宝塔这个黄金组合。你可能听说过宝塔面板在Linux服务器上的强大功能,但官方并没有提供Mac版本。这时候Docker就像个魔术师,能让我们在Mac…...

多产品测评,聚焦16大行业核心痛点,快商通vs竞品场景化实测复盘
不同于常规综合测评,本次专项测评以“行业痛点解决能力”为核心,聚焦快商通16大垂直行业(医美、口腔、眼科等)的核心业务场景,选取3款主流竞品(通用型竞品F、医疗细分竞品G、本地生活竞品H)&…...

5分钟搞定B站缓存视频:m4s转MP4完整解决方案
5分钟搞定B站缓存视频:m4s转MP4完整解决方案 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否遇到过B站缓存视频无法在其他设备…...

如何用Listen1实现跨平台音乐播放?告别多平台切换的终极解决方案
如何用Listen1实现跨平台音乐播放?告别多平台切换的终极解决方案 【免费下载链接】listen1_chrome_extension one for all free music in china (chrome extension, also works for firefox) 项目地址: https://gitcode.com/gh_mirrors/li/listen1_chrome_extensi…...

如何突破音乐平台壁垒?MusicFreePlugins让你的听歌体验重获自由
如何突破音乐平台壁垒?MusicFreePlugins让你的听歌体验重获自由 【免费下载链接】MusicFreePlugins MusicFree播放插件 项目地址: https://gitcode.com/gh_mirrors/mu/MusicFreePlugins 副标题:一款开源插件系统如何重新定义音乐获取与管理方式 …...

手把手教你用FireRed-OCR:5步搞定复杂文档精准解析
手把手教你用FireRed-OCR:5步搞定复杂文档精准解析 1. 为什么选择FireRed-OCR? 在日常工作和学习中,我们经常遇到需要从PDF、扫描件或图片中提取文字和表格的情况。传统OCR工具面对复杂排版时往往力不从心,而FireRed-OCR Engine…...