【强化学习】17 ——DDPG(Deep Deterministic Policy Gradient)
文章目录
- 前言
- DDPG特点
- 随机策略与确定性策略
- DDPG:深度确定性策略梯度
- 伪代码
- 代码实践
前言
之前的章节介绍了基于策略梯度的算法 REINFORCE、Actor-Critic 以及两个改进算法——TRPO 和 PPO。这类算法有一个共同的特点:它们都是在线策略算法,这意味着它们的样本效率(sample efficiency)比较低。本章将要介绍的深度确定性策略梯度(deep deterministic policy gradient,DDPG)算法通过使用离线的数据以及Belllman等式去学习 Q Q Q函数,并利用 Q Q Q函数去学习策略。
DDPG特点
- DDPG是离线学习算法
- DDPG可以在连续的动作空间中进行使用
- Open AI Spinning Up 中的DDPG未实现并行运行
随机策略与确定性策略
首先来回顾一下随机策略与确定性策略相关内容
随机策略
- 离散动作: π ( a ∣ s ; θ ) = exp { Q θ ( s , a ) } ∑ a , exp { Q θ ( s , a ′ ) } \pi(a|s;\theta)=\frac{\exp\{Q_\theta(s,a)\}}{\sum_a,\exp\{Q_\theta(s,a^{\prime})\}} π(a∣s;θ)=∑a,exp{Qθ(s,a′)}exp{Qθ(s,a)},学习出价值函数之后再求取相应的softmax分布
- 连续动作: π ( a ∣ s ; θ ) ∝ exp { ( a − μ θ ( s ) ) 2 } \pi(a|s;\theta)\propto\exp\left\{\left(a-\mu_\theta(s)\right)^2\right\} π(a∣s;θ)∝exp{(a−μθ(s))2},学习出的策略符合高斯分布(均值,方差)
确定性策略
- 离散动作: π ( s ; θ ) = arg max a Q θ ( s , a ) \pi(s;\theta)=\arg\max_aQ_\theta(s,a) π(s;θ)=argmaxaQθ(s,a)策略不可微,但可以通过学习价值函数再求取argmax的方式得到相应的策略
- 连续动作: a = π ( s ; θ ) a=\pi(s;\theta) a=π(s;θ)策略可微,建立相应的函数映射,通过函数求导的方式进行策略学习
那么如何利用确定性策略学习连续动作呢?首先需要一个用于估计价值的Critic模块。 Q w ( s , a ) ≃ Q π ( s , a ) Q^w(s,a)\simeq Q^\pi(s,a) Qw(s,a)≃Qπ(s,a) L ( w ) = E s ∼ ρ π , a ∼ π θ [ ( Q w ( s , a ) − Q π ( s , a ) ) 2 ] L(w)=\mathbb{E}_{s\sim\rho^\pi,a\sim\pi_\theta}\left[\left(Q^w(s,a)-Q^\pi(s,a)\right)^2\right] L(w)=Es∼ρπ,a∼πθ[(Qw(s,a)−Qπ(s,a))2]
通过与环境的交互,可以获得状态的总体分布,又因为 a = π ( s ; θ ) a=\pi(s;\theta) a=π(s;θ),因此可以利用链式法则进行求导。首先是 Q Q Q函数对 a a a进行求导( Q Q Q函数通常由网络学习出来,对 a a a向量进行求导相当于是调整相应的梯度以使得获得更大的 Q Q Q值),接着因为 a = π ( s ; θ ) a=\pi(s;\theta) a=π(s;θ),所以 a a a对 π \pi π进行求导。
J ( π θ ) = E s ∼ ρ π [ Q π ( s , a ) ] J(\pi_\theta)=\mathbb{E}_{s\sim\rho^\pi}[Q^\pi(s,a)] J(πθ)=Es∼ρπ[Qπ(s,a)] ∇ θ J ( π θ ) = E s ∼ ρ π [ ∇ θ π θ ( s ) ∇ a Q π ( s , a ) ∣ a = π θ ( s ) ] \nabla_\theta J(\pi_\theta)=\mathbb{E}_{s\sim\rho^\pi}[\nabla_\theta\pi_\theta(s)\nabla_aQ^\pi(s,a)|_{a=\pi_\theta(s)}] ∇θJ(πθ)=Es∼ρπ[∇θπθ(s)∇aQπ(s,a)∣a=πθ(s)]
上式即为确定性策略梯度定理。确定性策略梯度定理的具体证明过程可参考《动手学强化学习》13.5 节。
DDPG:深度确定性策略梯度
在实际应用中,上述的带有神经函数近似器的actor-critic方法在面对有
挑战性的问题时是不稳定的。深度确定性策略梯度(DDPG)给出了在确定性策略梯度(DPG)基础上的解决方法:
• 经验重放(离线策略)
• 目标网络
• 在动作输入前标准化Q网络
• 添加连续噪声
下面我们来看一下 DDPG 算法的细节。DDPG 要用到4个神经网络,其中 Actor 和 Critic 各用一个网络,此外它们都各自有一个目标网络。DDPG 中 Actor 也需要目标网络因为目标网络也会被用来计算目标 Q Q Q值。DDPG 中目标网络的更新与 DQN 中略有不同:在 DQN 中,每隔一段时间将 Q Q Q网络直接复制给目标 Q Q Q网络;而在 DDPG 中,目标 Q Q Q网络的更新采取的是一种软更新(延时更新)的方式,即让目标 Q Q Q网络缓慢更新,逐渐接近网络,其公式为:
ω − ← τ ω + ( 1 − τ ) ω − \omega^-\leftarrow\tau\omega+(1-\tau)\omega^- ω−←τω+(1−τ)ω−
通常 τ \tau τ是一个比较小的数,当 τ = 1 \tau=1 τ=1时,就和 DQN 的更新方式一致了。而目标 μ \mu μ网络(策略网络)也使用这种软更新的方式。
另外,由于 Q Q Q函数存在 Q Q Q值过高估计的问题,DDPG 采用了 Double DQN 中的技术来更新 Q Q Q网络。但是,由于 DDPG 采用的是确定性策略,它本身的探索仍然十分有限。回忆一下 DQN 算法,它的探索主要由 ϵ \epsilon ϵ-贪婪策略的行为策略产生。同样作为一种离线策略的算法,DDPG 在行为策略上引入一个 N \mathcal{N} N随机噪声(原论文使用的是OU噪声,后来许多实验证明高斯噪声具有更好的效果)来进行探索。

伪代码


代码实践
import gymnasium as gym
import numpy as np
from tqdm import tqdm
import torch
import torch.nn.functional as F
import utilclass PolicyNet(torch.nn.Module):def __init__(self, state_dim, hidden_dim, action_dim, action_bound):super(PolicyNet, self).__init__()self.fc1 = torch.nn.Linear(state_dim, hidden_dim)self.fc2 = torch.nn.Linear(hidden_dim, action_dim)# action_bound是环境可以接受的动作最大值self.action_bound = action_bounddef forward(self, x):x = F.relu(self.fc1(x))return torch.tanh(self.fc2(x)) * self.action_boundclass QValueNet(torch.nn.Module):def __init__(self, state_dim, hidden_dim, action_dim):super(QValueNet, self).__init__()self.fc1 = torch.nn.Linear(state_dim + action_dim, hidden_dim)self.fc2 = torch.nn.Linear(hidden_dim, hidden_dim)self.fc_out = torch.nn.Linear(hidden_dim, 1)def forward(self, s, a):# 拼接状态和动作cat = torch.cat([s, a], dim=1)x = F.relu(self.fc1(cat))x = F.relu(self.fc2(x))return self.fc_out(x)class DDPG:''' DDPG算法 '''def __init__(self, state_dim, hidden_dim, action_dim, actor_lr, critic_lr, gamma,action_bound, sigma, tau, buffer_size, minimal_size, batch_size, device, numOfEpisodes, env):self.action_dim = action_dimself.actor = PolicyNet(state_dim, hidden_dim, action_dim, action_bound).to(device)self.critic = QValueNet(state_dim, hidden_dim, action_dim).to(device)self.target_actor = PolicyNet(state_dim, hidden_dim, action_dim, action_bound).to(device)self.target_critic = QValueNet(state_dim, hidden_dim, action_dim).to(device)# 初始化目标价值网络并设置和价值网络相同的参数self.target_critic.load_state_dict(self.critic.state_dict())# 初始化目标策略网络并设置和策略相同的参数self.target_actor.load_state_dict(self.actor.state_dict())self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)self.gamma = gammaself.sigma = sigma # 高斯噪声的标准差,均值直接设为0self.tau = tau # 目标网络软更新参数self.device = deviceself.env = envself.numOfEpisodes = numOfEpisodesself.buffer_size = buffer_sizeself.minimal_size = minimal_sizeself.batch_size = batch_sizedef take_action(self, state):state = torch.FloatTensor(np.array([state])).to(self.device)action = self.actor(state).item()# 给动作添加噪声,增加探索action = action + self.sigma * np.random.randn(self.action_dim)return actiondef soft_update(self, net, target_net):for param_target, param in zip(target_net.parameters(), net.parameters()):param_target.data.copy_(param_target.data * (1.0 - self.tau) + param.data * self.tau)def update(self, transition_dict):states = torch.tensor(np.array(transition_dict['states']), dtype=torch.float).to(self.device)actions = torch.tensor(np.array(transition_dict['actions']), dtype=torch.float).view(-1, 1).to(self.device)rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1, 1).to(self.device)next_states = torch.tensor(np.array(transition_dict['next_states']), dtype=torch.float).to(self.device)terminateds = torch.tensor(transition_dict['terminateds'], dtype=torch.float).view(-1, 1).to(self.device)truncateds = torch.tensor(transition_dict['truncateds'], dtype=torch.float).view(-1, 1).to(self.device)q_targets = rewards + self.gamma * (self.target_critic(next_states, self.target_actor(next_states))) * (1 - terminateds + truncateds)critic_loss = torch.mean(F.mse_loss(q_targets, self.critic(states, actions)))self.critic_optimizer.zero_grad()critic_loss.backward()self.critic_optimizer.step()actor_loss = -torch.mean(self.critic(states, self.actor(states)))self.actor_optimizer.zero_grad()actor_loss.backward()self.actor_optimizer.step()self.soft_update(self.actor, self.target_actor) # 软更新策略网络self.soft_update(self.critic, self.target_critic) # 软更新价值网络def DDPGtrain(self):replay_buffer = util.ReplayBuffer(self.buffer_size)returnList = []for i in range(10):with tqdm(total=int(self.numOfEpisodes / 10), desc='Iteration %d' % i) as pbar:for episode in range(int(self.numOfEpisodes / 10)):# initialize statestate, info = self.env.reset()terminated = Falsetruncated = FalseepisodeReward = 0# Loop for each step of episode:while (not terminated) or (not truncated):action = self.take_action(state)next_state, reward, terminated, truncated, info = self.env.step(action)replay_buffer.add(state, action, reward, next_state, terminated, truncated)state = next_stateepisodeReward += reward# 当buffer数据的数量超过一定值后,才进行Q网络训练if replay_buffer.size() > self.minimal_size:b_s, b_a, b_r, b_ns, b_te, b_tr = replay_buffer.sample(self.batch_size)transition_dict = {'states': b_s,'actions': b_a,'next_states': b_ns,'rewards': b_r,'terminateds': b_te,'truncateds': b_tr}self.update(transition_dict)if terminated or truncated:breakreturnList.append(episodeReward)if (episode + 1) % 10 == 0: # 每10条序列打印一下这10条序列的平均回报pbar.set_postfix({'episode':'%d' % (self.numOfEpisodes / 10 * i + episode + 1),'return':'%.3f' % np.mean(returnList[-10:])})pbar.update(1)return returnList
超参数设置参考:
agent = DDPG(state_dim=env.observation_space.shape[0],hidden_dim=256,action_dim=env.action_space.shape[0],actor_lr=3e-4,critic_lr=3e-3,gamma=0.99,action_bound=env.action_space.high[0],sigma=0.01,tau=0.005,buffer_size=10000,minimal_size=1000,batch_size=64,device=device,numOfEpisodes=200,env=env)

DDPG算法相比之前的在线学习算法,更加稳定,同时收敛速度更快。
深度确定性策略梯度算法(DDPG),它是面向连续动作空间的深度确定性策略训练的典型算法。相比于它的先期工作,即确定性梯度算法(DPG),DDPG 加入了目标网络和软更新的方法,这对深度模型构建的价值网络和策略网络的稳定学习起到了关键的作用。
相关文章:
【强化学习】17 ——DDPG(Deep Deterministic Policy Gradient)
文章目录 前言DDPG特点 随机策略与确定性策略DDPG:深度确定性策略梯度伪代码代码实践 前言 之前的章节介绍了基于策略梯度的算法 REINFORCE、Actor-Critic 以及两个改进算法——TRPO 和 PPO。这类算法有一个共同的特点:它们都是在线策略算法,…...

驱动开发11-2 编写SPI驱动程序-点亮数码管
驱动程序 #include <linux/init.h> #include <linux/module.h> #include <linux/spi/spi.h>int m74hc595_probe(struct spi_device *spi) {printk("%s:%d\n",__FILE__,__LINE__);char buf[]{0XF,0X6D};spi_write(spi,buf,sizeof(buf));return 0; …...

Java使用pdfbox进行pdf和图片之间的转换
简介 pdfbox是Apache开源的一个项目,支持pdf文档操作功能。 官网地址: Apache PDFBox | A Java PDF Library 支持的功能如下图.引入依赖 <dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox-app</artifactId><version>…...
机器学习中的关键组件
机器学习中的关键组件 数据 每个数据集由一个个样本组成,大多时候,它们遵循独立同分布。样本有时也叫作数据点或数据实例,通常每个样本由一组称为特征或协变量的属性组成。机器学习会根据这些属性进行预测,预测得到的称为标签或…...

【JVM】JDBC案例打破双亲委派机制
🐌个人主页: 🐌 叶落闲庭 💨我的专栏:💨 c语言 数据结构 javaEE 操作系统 Redis 石可破也,而不可夺坚;丹可磨也,而不可夺赤。 JVM 打破双亲委派机制(JDBC案例…...
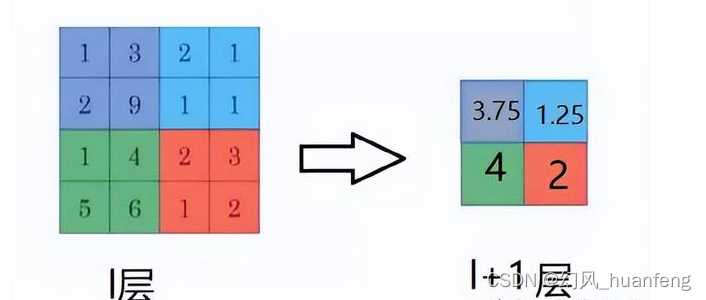
每天五分钟计算机视觉:池化层的反向传播
本文重点 卷积神经网络(Convolutional Neural Network,CNN)作为一种强大的深度学习模型,在计算机视觉任务中取得了巨大成功。其中,池化层(Pooling Layer)在卷积层之后起到了信息压缩和特征提取的作用。然而,池化层的反向传播一直以来都是一个相对复杂和深奥的问题。本…...
Docker的安装、基础命令与项目部署
文章目录 前言一、docker安装与MySQL部署1.Linux环境下docker的安装(1)基于CentOS7(2)基于Ubuntu 二、docker基础1.常见命令(1)快速创建一个mysql容器(MySQL得一键安装)。࿰…...
Nodejs和npm的使用方法和教程
Nodejs简介 Node.js 是一个开源和跨平台的 JavaScript 运行时环境。 它几乎是任何类型项目的流行工具! ( 运行环境,是不是很熟悉,对。就是 java JRE,Java 运行时环境) Node.js 在浏览器之外运行 V8 Java…...

机器学习---支持向量机的初步理解
1. SVM的经典解释 改编自支持向量机解释得很好 |字节大小生物学 (bytesizebio.net) 话说,在遥远的从前,有一只贪玩爱搞破坏的妖怪阿布劫持了善良美丽的女主小美,智勇双全 的男主大壮挺身而出,大壮跟随阿布来到了妖怪的住处&…...

【unity实战】Unity实现2D人物双击疾跑
最终效果 前言 我们要实现的功能是双击疾跑,当玩家快速地按下同一个移动键两次时能进入跑步状态 我假设快速按下的定义为0.2秒内,按下同一按键两次 简单的分析一下需求,实现它的关键在于获得按键按下的时间,我们需要知道第一次…...

Spring面试题:(二)基于xml方式的Spring配置
xml配置Bean的常见属性 id属性 name属性 scope属性 lazy-init属性 init-method属性和destroy属性 initializingBean方法 Bean实例化方式 ApplicationContext底层调用BeanFactory创建Bean,BeanFactory可以利用反射机制调用构造方法实例化Bean,也可采用工…...
XR Interaction ToolKit
一、简介 XR Interaction Toolkit是unity官方的XR交互工具包。 官方XRI示例地址:https://github.com/Unity-Technologies/XR-Interaction-Toolkit-Examples 2023.3.14官方博客,XRIT v2.3 https://blog.unity.com/engine-platform/whats-new-in-xr-int…...

spring-boot中实现分片上传文件
一、上传文件基本实现 1、前端效果图展示,这里使用element-ui plus来展示样式效果 2、基础代码如下 <template><div><el-uploadref"uploadRef"class"upload-demo":limit"1":on-change"handleExceed":auto-…...
【ICN综述】信息中心网络隐私安全
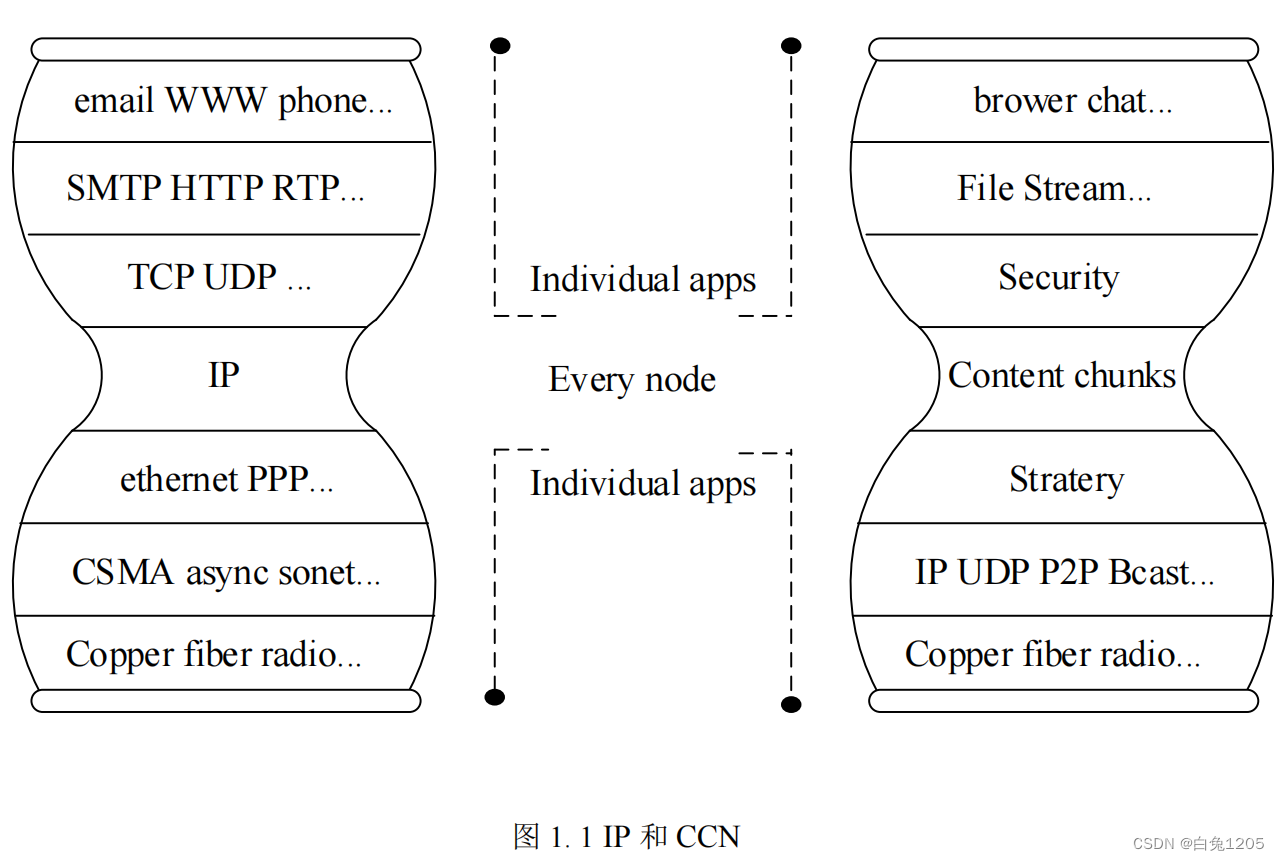
ICN基本原理: 信息中心网络也是需要实现在不可信环境下可靠的信息交换和身份认证 信息中心网络采用以数据内容为中心的传输方式代替现有IP 网络中以主机为中心的通信方式,淡化信息数据物理或逻辑位置的重要性,以内容标识为代表实现数据的查找…...

基于STC12C5A60S2系列1T 8051单片机EEPROM应用
基于STC12C5A60S2系列1T 8051单片机EEPROM应用 STC12C5A60S2系列1T 8051单片机管脚图STC12C5A60S2系列1T 8051单片机I/O口各种不同工作模式及配置STC12C5A60S2系列1T 8051单片机I/O口各种不同工作模式介绍STC12C5A60S2系列1T 8051单片机EEPROM介绍基于STC12C5A60S2系列1T 8051单…...

手撕排序之直接选择排序
前言: 直接选择排序是排序中比较简单的排序,同时也是时间复杂度不是很优的排序。 思想: 本文主要讲解直接选择排序的优化版本。 我们经过一次遍历直接将该数列中最大的和最小的值挑选出来,如果是升序,就将最小的和…...

洛谷 P1359 租用游艇
题目链接 P1359 租用游艇 普及 题目描述 长江游艇俱乐部在长江上设置了 n n n 个游艇出租站 1 , 2 , 3 , . . . , n 1,2,3,...,n 1,2,3,...,n,游客可在这些游艇出租站租用游艇,并在下游的任何一个游艇出租站归还游艇。游艇出租站 i i i 到游艇出租站…...

springboot中没有主清单属性解决办法
在执行一个 spring boot 启动类时,提示 没有主清单属性 一般这个问题是没加 spring-boot-maven-plugin 插件的问题,但是项目中已经加了 <build><plugins><plugin><groupId>org.springframework.boot</groupId><artifa…...

C/C++ static关键字详解(最全解析,static是什么,static如何使用,static的常考面试题)
目录 一、前言 二、static关键字是什么? 三、static关键字修饰的对象是什么? 四、C 语言中的 static 🍎static的C用法 🍉static的重点概念 🍐static修饰局部变量 💦static在修饰局部变量和函数的作用 &a…...
windwos10搭建我的世界服务器,并通过内网穿透实现联机游戏Minecraft
文章目录 1. Java环境搭建2.安装我的世界Minecraft服务3. 启动我的世界服务4.局域网测试连接我的世界服务器5. 安装cpolar内网穿透6. 创建隧道映射内网端口7. 测试公网远程联机8. 配置固定TCP端口地址8.1 保留一个固定tcp地址8.2 配置固定tcp地址 9. 使用固定公网地址远程联机 …...

LAMMPS并行计算深度剖析:如何利用MPI实现大规模模拟
LAMMPS并行计算深度剖析:如何利用MPI实现大规模模拟 【免费下载链接】lammps Public development project of the LAMMPS MD software package 项目地址: https://gitcode.com/gh_mirrors/la/lammps LAMMPS(Large-scale Atomic/Molecular Massiv…...
)
SOONet视频时序定位入门必看:3步完成本地Web服务搭建(含A100适配说明)
SOONet视频时序定位入门必看:3步完成本地Web服务搭建(含A100适配说明) 1. 引言:让AI帮你从长视频里“找片段” 你有没有过这样的经历?面对一个长达几小时的会议录像、教学视频或者家庭录像,只想快速找到其…...

探索16极18槽轴向磁通永磁电机:基于Maxwell的模型解析
基于maxwell的16极18槽轴向磁通永磁电机模型,功率1500w,外径190mm。 输出转矩3.7Nm.可用于轴向电机设计学习。 大致参数波形见图。最近在研究轴向磁通永磁电机,今天和大家分享基于Maxwell搭建的一款16极18槽轴向磁通永磁电机模型,这款电机功率…...

Cogito-v1-preview-llama-3B应用探索:建筑行业BIM文档智能摘要系统
Cogito-v1-preview-llama-3B应用探索:建筑行业BIM文档智能摘要系统 1. 引言:建筑行业的文档挑战与AI机遇 建筑行业每天产生海量的BIM文档——设计图纸、施工方案、材料清单、进度报告,这些文档往往长达数百页,工程师和项目经理需…...

Z-Image-Turbo-rinaiqiao-huiyewunv应用场景:二次元IP定制化绘图、同人创作、角色设定图生成
Z-Image Turbo (辉夜大小姐-日奈娇)在二次元IP定制化绘图中的应用实践 1. 项目背景与核心价值 二次元文化爱好者经常面临一个共同挑战:如何快速生成符合特定角色设定的高质量图像。传统绘图软件学习成本高,而通用AI绘图工具又难以精准还原角色特征。Z-…...

CSS如何实现文字加粗而不改变宽度_利用text-shadow模拟加粗
会,text-shadow模拟加粗因软边阴影导致文字模糊,尤其小字号或Retina屏;需设blur-radius为0,用多方向1px硬边阴影(如-1px 0 0, 1px 0 0等)并启用GPU加速。text-shadow模拟加粗会导致文字模糊?会&…...

MMC整流器平均值模型simulink仿真,19电平,采用交流电流内环,直流电压外环控制,双二...
MMC整流器平均值模型simulink仿真,19电平,采用交流电流内环,直流电压外环控制,双二阶广义积分器锁相环,PI解耦环流抑制器,调制方式为最近电平逼近调制,完美运行。 波形一二为直流侧电压电流&…...

【需求改变与测试如何】
需求一旦修改,测试该如何进行呢? 最近面临的项目,经过很多次需求更改或者是前期没有需求,实际操作起来,让人很是头疼,恰到也看到大家也有着相同的讨论。 来源于微信公众号:测试论道学习&#x…...

Windows垄断之殇:用户自由的终结,第八章:组合模式 - 整体部分的统一大师。
Windows 原罪:技术垄断与用户自由的剥夺 微软Windows操作系统长期占据市场主导地位,其封闭的生态系统和强制性更新策略对用户选择权造成严重限制。系统强制捆绑IE浏览器并打压竞争对手的行为,直接导致互联网早期创新停滞。 安全漏洞与隐私侵犯…...

TypeScript + Cloudflare 全家桶部署项目全流程
我的项目技术栈是 TypeScript Cloudflare 全家桶(Workers, KV, DB, Pages)。基于现在的架构,我整理了一份**“从本地到边缘”的部署清单**。这套流程主要依赖 Wrangler CLI(Cloudflare 的官方命令行工具)来完成。 以下…...