阿里云安全恶意程序检测
阿里云安全恶意程序检测
- 赛题理解
- 赛题介绍
- 赛题说明
- 数据说明
- 评测指标
- 赛题分析
- 数据特征
- 解题思路
- 数据探索
- 数据特征类型
- 数据分布
- 箱型图
- 变量取值分布
- 缺失值
- 异常值
- 分析训练集的tid特征
- 标签分布
- 测试集数据探索同上
- 数据集联合分析
- file_id分析
- API分析
- 特征工程与基线模型
- 构造特征与特征选择
- 基于数据类型的方法
- 基于多分析视角的方法
- 特征选择
- 构造线下验证集
- 评估穿越
- 训练集和测试集的特征性差异
- 训练集和测试集是分布差异性
- 基线模型
- 特征工程
- 基线构建
- 特征重要性分析
- 模型测试
赛题理解
赛题介绍
赛题说明
本题目提供的数据来自经过沙箱程序模拟运行后的API指令序列,全为Windows二进制可执行程序,经过脱敏处理:样本数据均来自互联网,其中恶意文件的类型有感染型病毒、木马程序、挖矿程序、DDoS 木马、勒索病毒等,数据总计6亿条。
注:什么是沙箱程序?
在计算机安全中,沙箱(Sandbox)是一种用于隔离正在运行程序的安全机制,通常用于执行未经测试或者不受信任的程序或代码,它会为待执行的程序创建一个独立的执行环境,内部程序的执行不会影响到外部程序的运行。
数据说明

评测指标

需特别注意,log 对于小于1的数是非常敏感的。比如log0.1和log0.000 001的单个样本的误差为10左右,而log0.99和log0.95的单个误差为0.1左右。
logloss和AUC的区别:AUC只在乎把正样本排到前面的能力,logloss更加注重评估的准确性。如果给预测值乘以一个倍数,则AUC不会变,但是logloss 会变。
赛题分析
数据特征

本赛题的特征主要是API接口的名称,这是融合时序与文本的数据,同时接口名称基本表达了接口用途。因此,最基本、最简单的特征思路是对所有API数据构造CountVectorizer特征。
说明: CountVectorizer 是属于常见的特征数值计算类,是一个文本特征提取方法。对于每一个训练文本,它只考虑每种词汇在该训练文本中出现的频率。
解题思路
本赛题根据官方提供的每个文件对API的调用顺序及线程的相关信息按文件进行分类,将文件属于每个类的概率作为最终的结果进行提交,并采用官方的logloss作为最终评分,属于典型的多分类问题。
数据探索
数据特征类型
train.info()
train.head(5)
train.describe()
数据分布
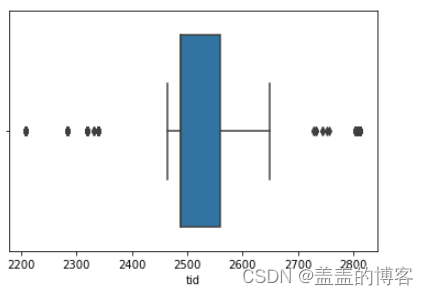
箱型图
#使用箱型图查看单个变量的分布情况。
#取前10000条数据绘制tid变量的箱型图
#os:当数据量太大时,变量可视化取一部分
sns.boxplot(x = train.iloc[:10000]["tid"])
变量取值分布
#用函数查看训练集中变量取值的分布
train.nunique()
缺失值
#查看缺失值
train.isnull().sum()
异常值
#异常值:分析训练集的index特征
train['index'].describe()
分析训练集的tid特征
#分析训练集的tid特征
train['tid'].describe()
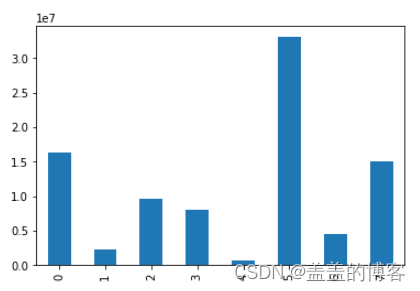
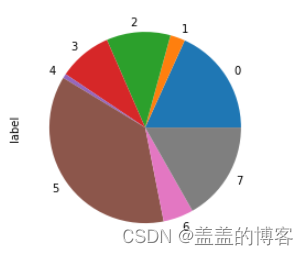
标签分布
#统计标签取值的分布情况
train['label'].value_counts()
直观化:
train['label'].value_counts().sort_index().plot(kind = 'bar')
train['label'].value_counts().sort_index().plot(kind = 'pie')
测试集数据探索同上
数据集联合分析
file_id分析
#对比分析file_id变量在训练集和测试集中分布的重合情况:
train_fileids = train['file_id'].unique()
test_fileids = test['file_id'].unique()
len(set(train_fileids) - set(test_fileids))
API分析
#对比分析API变量在训练集和测试集中分布的重合情况
train_apis = train['api'].unique()
test_apis = test['api'].unique()
set(set(test_apis) - set(train_apis))
特征工程与基线模型
构造特征与特征选择
基于数据类型的方法

基于多分析视角的方法
这是最常见的一种特征构造方法,在所有的基于table 型(结构化数据)的比赛中都会用到。
我们以用户是否会在未来三天购买同一物品为例,来说明此类数据的构建角度:用户长期购物特征,用户长期购物频率;用户短期购物特征,用户近期购物频率;物品受欢迎程度,该物品最近受欢迎程度;
用户对此类产品的喜好特征:用户之前购买该类/该商品的频率等信息;
时间特征:是否到用户发工资的时间段:商品是否为用户的必备品,如洗漱用品、每隔多长时间必买等。
特征选择
特征选择主要包含过滤法、包装法和嵌入法三种,前面已经介绍过。
构造线下验证集
在数据竞赛中,为了防止选手过度刷分和作弊,每日的线上提交往往是有次数限制的。因此,线下验证集的构造成为检验特征工程、模型是否有效的关键。在构造线下验证集时,我们需要考虑以下几个方面的问题。
评估穿越
评估穿越最常见的形式是时间穿越和会话穿越两种。
1.时间穿越
例1: 假设我们需要预测用户是否会去观看视频B,在测试集中需要预测用户8月8日上午10:10点击观看视频B的概率,但是在训练集中已经发现该用户8月8日上午10:09在观看视频A,上午10:11 也在观看视频A,那么很明显该用户就有非常大的概率不看视频B,通过未来的信息很容易就得出了该判断。
例2: 假设我们需要预测用户9月10日银行卡的消费金额,但是在训练集中已经出现了该用户银行卡的余额在9月9日和9月11日都为0,那么我们就很容易知道该用户在9月10日的消费金额是0,出现了时间穿越的消息。
2.会话穿越
以电商网站的推荐为例,当用户在浏览某一个商品时,某个推荐模块会为他推荐多个商品进行展现,用户可能会点击其中的一个或几个。为了描述方便,我们将这些一 次展现中产生的,点击和未点击的数据合起来称为一 次会话(不同于计算机网络中会话的概念)。在上面描述的样本划分方法中,一次会话中的样本可能有一部分被划分到训练集,另一部分被划分到测试集。这样的行为,我们称之为会话穿越。
会话穿越的问题在于,由于一个会话对应的是
一个用户在一次展现中的行为,因此存在较高的相关性,穿越会带来类似上面提到的用练习题考试的问题。此外,会话本身是不可分割的,也就是说,在线上使用模型时,不可能让你先看到一次会话的一部分,然后让你预测剩余的部分,因为会话的展现结果是一次性产生的,一旦产生后,模型就已经无法干预展现的结果了。
3.穿越本质
穿越本质上是信息泄露的问题。无论时间穿越,还是会话穿越,其核心问题都是训练数据中的信息以不同方式、不同程度泄露到了测试数据中。.
训练集和测试集的特征性差异
我们用训练集训练模型,当训练集和测试集的特征分布有差异时,就容易造成模型偏差,导致预测不准确。常见的训练集和测试集的特征差异如下:
数值特征:训练集和测试集的特征分布交叉部分极小;
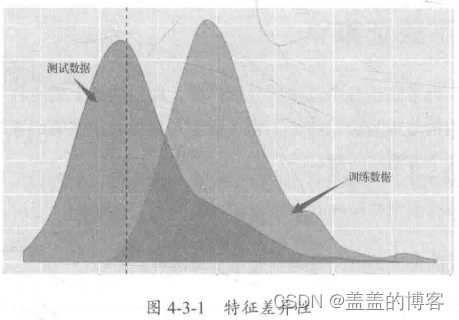
类别特征:测试集中的特征大量未出现在训练集中。例如,在微软的一场比赛中,测试集中的很多版本未出现在训练集中。
在某些极端情况下,训练集中极强的特征会在测试集中全部缺失。
训练集和测试集是分布差异性
训练集和测试集的分布差异性的判断步骤如下:
将训练集的数据标记为label=1,将测试集的数据标记为label= 0。对训练集和测试集做5折的auc交叉验证。如果auc在0.5附近,那么则说明训练集和测试集的分布差异不大:如果auc在0.9附近,那么则说明训练集和测试集的分布差异很大。
基线模型
导包 -> 读取数据 -> 特征工程
特征工程
·利用count()函数和nunique()函数生成特征:反应样本调用api,tid,index的频率信息
def simple_sts_features(df):simple_fea = pd.DataFrame()simple_fea['file_id'] = df['file_id'].unique()simple_fea = simple_fea.sort_values('file_id')df_grp = df.groupby('file_id')simple_fea['file_id_api_count'] = df_grp['api'].count().valuessimple_fea['file_id_api_nunique'] = df_grp['api'].nunique().valuessimple_fea['file_id_tid_count'] = df_grp['tid'].count().valuessimple_fea['file_id_tid_nunique'] = df_grp['tid'].nunique().valuessimple_fea['file_id_index_count'] = df_grp['index'].count().valuessimple_fea['file_id_index_nunique'] = df_grp['index'].nunique().valuesreturn simple_fea
·利用main(),min(),std(),max()函数生成特征:tid,index可认为是数值特征,可提取对应的统计特征。
def simple_numerical_sts_features(df):simple_numerical_fea = pd.DataFrame()simple_numerical_fea['file_id'] = df['file_id'].unique()simple_numerical_fea = simple_numerical_fea.sort_values('file_id')df_grp = df.groupby('file_id')simple_numerical_fea['file_id_tid_mean'] = df_grp['tid'].mean().valuessimple_numerical_fea['file_id_tid_min'] = df_grp['tid'].min().valuessimple_numerical_fea['file_id_tid_std'] = df_grp['tid'].std().valuessimple_numerical_fea['file_id_tid_max'] = df_grp['tid'].max().valuessimple_numerical_fea['file_id_index_mean'] = df_grp['index'].mean().valuessimple_numerical_fea['file_id_index_min'] = df_grp['index'].min().valuessimple_numerical_fea['file_id_index_std'] = df_grp['index'].std().valuessimple_numerical_fea['file_id_index_max'] = df_grp['index'].max().valuesreturn simple_numerical_fea
·利用定义的特征生成函数,并生成训练集和测试集的统计特征。
%%time
#统计api,tid,index的频率信息的特征统计
simple_train_fea1 = simple_sts_features(train)
%%time
simple_test_fea1 = simple_sts_features(test)
%%time
#统计tid,index等数值特征的特征统计
simple_train_fea2 = simple_numerical_sts_features(train)
%%time
simple_test_fea2 = simple_numerical_sts_features(test)
基线构建
获取标签:
#获取标签
train_label = train[['file_id','label']].drop_duplicates(subset=['file_id','label'],keep='first')
test_submit = test[['file_id']].drop_duplicates(subset=['file_id'],keep='first')
训练集和测试集的构建:
#训练集和测试集的构建
train_data = train_label.merge(simple_train_fea1,on = 'file_id',how = 'left')
train_data = train_data.merge(simple_train_fea2,on = 'file_id',how = 'left')test_submit = test_submit.merge(simple_test_fea1,on = 'file_id',how = 'left')
test_submit = test_submit.merge(simple_test_fea2,on = 'file_id',how = 'left')
因为本赛题给出的指标和传统的指标略有不同,所以需要自己写评估指标,这样方便对比线下与线上的差距,以判断是否过拟合、是否出现线上线下不一致的问题等。

#关于LGB的自定义评估指标的书写
def lgb_logloss(preds,data):labels_ = data.get_label()classes_ = np.unique(labels_)preds_prob = []for i in range(len(classes_)):preds_prob.append(preds[i * len(labels_):(i+1)*len(labels_)])preds_prob_ = np.vstack(preds_prob)loss = []for i in range(preds_prob_.shape[1]): #样本个数sum_ = 0for j in range(preds_prob_.shape[0]): #类别个数pred = preds_prob_[j,i] #第i个样本预测为第j类的概率if j == labels_[i]:sum_ += np.log(pred)else:sum_ += np.log(1 - pred)loss.append(sum_)return 'loss is: ',-1 * (np.sum(loss) / preds_prob_.shape[1]),False线下验证:
train_features = [col for col in train_data.columns if col not in ['label','file_id']]
train_label = 'label'
使用5折交叉验证,采用LGB模型:
%%timefrom sklearn.model_selection import StratifiedKFold,KFold
params = {'task':'train','num_leaves':255,'objective':'multiclass','num_class':8,'min_data_in_leaf':50,'learning_rate':0.05,'feature_fraction':0.85,'bagging_fraction':0.85,'bagging_freq':5,'max_bin':128,'random_state':100
}folds = KFold(n_splits=5,shuffle=True,random_state = 15) #n_splits = 5定义5折
oof = np.zeros(len(train))predict_res = 0
models = []
for fold_, (trn_idx,val_idx) in enumerate(folds.split(train_data)):print("fold n°{}".format(fold_))trn_data = lgb.Dataset(train_data.iloc[trn_idx][train_features],label = train_data.iloc[trn_idx][train_label].values)val_data = lgb.Dataset(train_data.iloc[val_idx][train_features],label = train_data.iloc[val_idx][train_label].values)clf = lgb.train(params,trn_data,num_boost_round = 2000,valid_sets = [trn_data,val_data],verbose_eval = 50,early_stopping_rounds = 100,feval = lgb_logloss)models.append(clf)
特征重要性分析
#特征重要性分析
feature_importance = pd.DataFrame()
feature_importance['fea_name'] = train_features
feature_importance['fea_imp'] = clf.feature_importance()
feature_importance = feature_importance.sort_values('fea_imp',ascending = False)
plt.figure(figsize = [20,10,])
sns.barplot(x = feature_importance['fea_name'],y = feature_importance['fea_imp'])

由运行结果可以看出:
(1) API的调用次数和API的调用类别数是最重要的两个特征,即不同的病毒常常会调用不同的API,而且由于有些病毒需要复制自身的原因,因此调用API的次数会明显比其他不同类别的病毒多。
(2)第三到第五强的都是线程统计特征,这也较为容易理解,因为木马等病毒经常需要通过线程监听一些内容,所以在线程等使用上会表现的略有不同。
模型测试
#模型测试
pred_res = 0
fold = 5
for model in models:pred_res += model.predict(test_submit[train_features]) * 1.0 /fold
test_submit['prob0'] = 0
test_submit['prob1'] = 0
...
test_submit[['prob0','prob1','prob2','prob3','prob4','prob5','prob6','prob7']] = pred_res
test_submit[['file_id','prob0','prob1','prob2','prob3','prob4','prob5','prob6','prob7']].to_csv('baseline.csv',index = None)
相关文章:
阿里云安全恶意程序检测
阿里云安全恶意程序检测 赛题理解赛题介绍赛题说明数据说明评测指标 赛题分析数据特征解题思路 数据探索数据特征类型数据分布箱型图 变量取值分布缺失值异常值分析训练集的tid特征标签分布测试集数据探索同上 数据集联合分析file_id分析API分析 特征工程与基线模型构造特征与特…...
Xcode中如何操作Git
👨🏻💻 热爱摄影的程序员 👨🏻🎨 喜欢编码的设计师 🧕🏻 擅长设计的剪辑师 🧑🏻🏫 一位高冷无情的编码爱好者 大家好,我是全栈工…...
浅述边缘计算场景下的云边端协同融合架构的应用场景示例
云计算正在向一种更加全局化的分布式节点组合形态进阶,而边缘计算是云计算能力向边缘侧分布式拓展的新触角。随着城市建设进程加快,海量设备产生的数据,若上传到云端进行处理,会对云端造成巨大压力。如果利用边缘计算来让云端的能…...

C++中禁止在栈中实例化的类
C中禁止在栈中实例化的类 栈空间通常有限。如果您要编写一个数据库类,其内部结构包含数 TB 数据,可能应该禁止在栈上实例化它,而只允许在自由存储区中创建其实例。为此,关键在于将析构函数声明为私有的: class Monst…...

MsgPack和Protobuf
MsgPack可以在C下序列化类,Protobuf只能在C#下序列化类 Cocos Creator安装msgpack-lite 项目文件夹执行 rpm -i msgpack-lite...
自定义类型联合体
目录 联合体联合体类型的声明联合体的特点相同成员的结构体和联合体对比联合体大小的计算联合体的应用联合的一个练习 感谢各位大佬对我的支持,如果我的文章对你有用,欢迎点击以下链接 🐒🐒🐒 个人主页 🥸🥸…...
)
【Shell 系列教程】Shell printf 命令( 六)
文章目录 往期回顾Shell printf 命令printf 的转义序列 往期回顾 【Shell 系列教程】shell介绍(一)【Shell 系列教程】shell变量(二)【Shell 系列教程】shell数组(三)【Shell 系列教程】shell基本运算符&a…...

2022年电工杯数学建模B题5G网络环境下应急物资配送问题求解全过程论文及程序
2022年电工杯数学建模 B题 5G网络环境下应急物资配送问题 原题再现: 一些重特大突发事件往往会造成道路阻断、损坏、封闭等意想不到的情况,对人们的日常生活会造成一定的影响。为了保证人们的正常生活,将应急物资及时准确地配送到位尤为重要…...

git reflog 恢复git reset --hard 回退的内容
首先使用 git reflog 查看处理的历史,历史是由新到旧排列的,找到回退前的commit的id,找的过程可以只关注HEAD的部分,HEAD括号中的值越大越旧,越小越新。 找到后执行以下命令 git reset --hard 你的commit_id 然后…...

kali Linux中更换为阿里镜像源
准备: kali Linux 阿里源链接 deb kali安装包下载_开源镜像站-阿里云 kali-rolling main non-free contrib deb-src kali安装包下载_开源镜像站-阿里云 kali-rolling main non-free contrib 配置: 打开kali 终端输入:sudo nano /etc/apt…...

【每日一题】移除链表元素(C语言)
移除链表元素,链接奉上 目录 思路:代码实现:链表题目小技巧: 思路: 在正常情况: 下我们移除链表元素时,需要该位置的前结点与后节点, 在特别情况时: 例如 我们发现&…...

stm32 ADC
目录 简介 stm32的adc 框图 ①电压输入范围 ②输入通道 编辑③ADC通道 ④ADC触发 ⑤ADC中断 ⑥ADC数据 ⑦ADC时钟 ADC的四种转换模式 hal库代码 标准库代码 简介 自然界的信号几乎都是模拟信号,比如光亮、温度、压力、声音,而为了方便存储、…...
linux网络服务综合项目
前期环境配置 #主要写了192.168.146.130的代码,131的配置代码和其一样 [rootserver ~]# nmtui #通过图形化界面修改ens160的ip 192.168.146.130 [rootserver ~]# hostnamectl set-hostname Server-Web #修改130主机名…...
----数组--移除元素(三))
每日一题(LeetCode)----数组--移除元素(三)
每日一题(LeetCode)----数组–移除元素(三) 1.题目([283. 移动零](https://leetcode.cn/problems/sqrtx/)) 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 请…...

AI:57-基于机器学习的番茄叶部病害图像识别
🚀 本文选自专栏:AI领域专栏 从基础到实践,深入了解算法、案例和最新趋势。无论你是初学者还是经验丰富的数据科学家,通过案例和项目实践,掌握核心概念和实用技能。每篇案例都包含代码实例,详细讲解供大家学习。 📌📌📌在这个漫长的过程,中途遇到了不少问题,但是…...
人工智能-深度学习计算:层和块
我们关注的是具有单一输出的线性模型。 在这里,整个模型只有一个输出。 注意,单个神经网络 (1)接受一些输入; (2)生成相应的标量输出; (3)具有一组相关 参数…...

Linux第一个小程序进度条
缓冲区 在写进度条程序之前我们需要介绍一下缓冲区,缓冲区有两种,输入和输出缓冲区,这里主要介绍输出缓冲区。在我们用C语言写代码时,输出一些信息,实际上是先输出到输出缓冲区里,然后才输出到我们的显…...

JavaEE平台技术——预备知识(Maven、Docker)
JavaEE平台技术——预备知识(Maven、Docker) 1. Maven2. Docker 在观看这个之前,大家请查阅前序内容。 😀JavaEE的渊源 😀😀JavaEE平台技术——预备知识(Web、Sevlet、Tomcat) 1. M…...

【ChatOCR】OCR+LLM定制化关键信息抽取(附开源大语言模型汇总整理)
目录 背景技术方案存在的问题及解决思路关键信息提取结果其他解决方案替换文心一言LangChain大型多模态模型(Large Multimodal Model, LMM) 开源大模型汇总LLaMA —— Meta 大语言模型Stanford Alpaca —— 指令调优的 LLaMA 模型Lit-LLaMA —— 基于 na…...

【位运算】XOR Construction—CF1895D
XOR Construction—CF1895D 参考文章 翻译 题目要求构造一个长度为 n n n 的数组 b b b,满足以下条件: 数组 b b b 中包含从 0 0 0 到 n − 1 n-1 n−1 的每个整数,且每个整数仅出现一次;对于 i i i 从 1 1 1 到 n − …...

性能实测:登临Goldwasser V2加速卡跑YOLOv5s,对比CPU看速度提升多少?
登临Goldwasser V2加速卡YOLOv5s实测:从环境配置到性能对比的全流程拆解 当目标检测任务遇上边缘计算场景,算力与能效的平衡往往成为工程落地的关键瓶颈。上周在部署某工业园区安防系统时,我们尝试用登临科技的Goldwasser V2加速卡运行YOLOv5…...

新手友好:告别visio下载烦恼,用快马AI代码学画架构图
作为一个刚接触编程的新手,想要画个简单的系统架构图却卡在了Visio下载和操作上,这种经历我太熟悉了。最近发现用代码直接画图其实没那么难,特别是在InsCode(快马)平台上尝试后,发现整个过程意外地顺畅。这里分享下我的学习过程&a…...

终极指南:如何快速配置Cubism.js连接Ganglia数据源实现系统监控可视化
终极指南:如何快速配置Cubism.js连接Ganglia数据源实现系统监控可视化 【免费下载链接】cubism Cubism.js: A JavaScript library for time series visualization. 项目地址: https://gitcode.com/gh_mirrors/cu/cubism Cubism.js是一款强大的JavaScript时间…...

nginx-proxy-automation升级与迁移指南:平滑过渡到新版本
nginx-proxy-automation升级与迁移指南:平滑过渡到新版本 【免费下载链接】nginx-proxy-automation Automated docker nginx proxy integrated with letsencrypt. 项目地址: https://gitcode.com/gh_mirrors/ng/nginx-proxy-automation nginx-proxy-automati…...

claude加持快马平台:三步生成你的第一个博客网站原型
最近想快速搭建一个个人博客网站的原型,用来验证一些内容创作的想法。作为一个前端开发新手,我尝试了在InsCode(快马)平台上使用Claude模型来生成代码,整个过程出乎意料地顺畅。下面记录下我的实践过程,或许对同样想快速实现原型的…...

无需安装插件,用快马平台5分钟构建你的第一个ai生成web应用原型
最近在尝试快速验证一些产品想法时,发现了一个特别实用的方法:用InsCode(快马)平台5分钟就能搭建出可交互的Web应用原型。相比传统开发方式,这种无需安装任何插件、直接在浏览器里完成所有操作的方式,真的能节省大量时间。 为什么…...

如何用BiliTools实现B站视频智能学习:从信息焦虑到知识掌控的转变
如何用BiliTools实现B站视频智能学习:从信息焦虑到知识掌控的转变 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliT…...
)
华为防火墙IPsec点对点配置实战:从零到通的完整流程(附常见错误排查)
华为防火墙IPsec点对点配置实战:从零到通的完整流程(附常见错误排查) 在当今企业网络架构中,跨地域分支机构之间的安全通信已成为刚需。IPsec VPN凭借其强大的加密能力和标准化协议支持,成为构建安全通道的首选方案。华…...

从单人到派对:Nucleus Co-op如何让你的电脑变身多人游戏主机
从单人到派对:Nucleus Co-op如何让你的电脑变身多人游戏主机 【免费下载链接】splitscreenme-nucleus Nucleus Co-op is an application that starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirro…...

手把手教程:Qwen-Image快速部署,小白也能轻松玩转AI绘画
手把手教程:Qwen-Image快速部署,小白也能轻松玩转AI绘画 1. 教程介绍 今天我们要一起探索的是阿里云通义千问团队推出的Qwen-Image图像生成模型。这个模型最大的特点就是能精准理解你的文字描述,生成包含复杂文本的高质量图像。想象一下&am…...