爬虫项目-爬取股吧(东方财富)评论
1.最近帮别人爬取了东方财富股吧的帖子和评论,网址如下:http://mguba.eastmoney.com/mguba/list/zssh000300
2.爬取字段如下所示:
3.爬虫的大致思路如下:客户要求爬取评论数大于5的帖子,首先获取帖子链接,然后根据链接的列表进行遍历,爬取相应的信息:
4.对于刚入门的朋友可以修改,如下chromedriver的地址,在相关第三方库都安装的情况下运行代码:
5.完整代码如下所示,在修改第二步之后是可以直接运行的,如果不能成功运行可以下面评论,或者私聊我,我会帮你解答。
import csv
import random
import re
import time
from selenium.common.exceptions import TimeoutException, NoSuchElementException
import dateutil.parser as dparser
from random import choice
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECchrome_options = webdriver.ChromeOptions()
# 添加其他选项,如您的用户代理等
# ...# 指定 Chrome WebDriver 的路径
driver = webdriver.Chrome(executable_path='/usr/local/bin/chromedriver', options=chrome_options)
## 时间节点
start_date = dparser.parse('2019-06-01')
## 浏览器设置选项
# chrome_options = Options()
chrome_options.add_argument('blink-settings=imagesEnabled=false')def get_time():'''获取随机时间'''return round(random.uniform(3, 6), 1)def get_user_agent():'''获取随机用户代理'''user_agents = ["Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)","Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)","Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)","Mozilla/5.0 (iPod; U; CPU iPhone OS 2_1 like Mac OS X; ja-jp) AppleWebKit/525.18.1 (KHTML, like Gecko) Version/3.1.1 Mobile/5F137 Safari/525.20","Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Gecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)","Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"]## 在user_agent列表中随机产生一个代理,作为模拟的浏览器user_agent = choice(user_agents)return user_agentdef get_detail_urls_by_keyword(list_url):'''获取包含特定关键字的留言链接'''user_agent = get_user_agent()chrome_options.add_argument('user-agent=%s' % user_agent)drivertemp = webdriver.Chrome(options=chrome_options)drivertemp.maximize_window()drivertemp.get(list_url)# 循环加载页面或翻页,提取包含特定关键字的留言链接comments_link,link,title = [],[],[]page = 1while True:try:next_page_button = WebDriverWait(drivertemp, 30).until(EC.element_to_be_clickable((By.CLASS_NAME, "nextp")))if page >= 2:breakif next_page_button.is_enabled():next_page_button.click()page += 1else:breakexcept TimeoutException:# 当找不到下一页按钮时,抛出TimeoutException,结束循环breaktime.sleep(3)titles = drivertemp.find_elements_by_xpath('//div[@class="title"]')for element in titles:message_id = element.text.strip().split(':')[-1]title.append(message_id)comment = drivertemp.find_elements_by_xpath('//div[@class="reply"]')for element in comment:message_id = element.text.strip().split(':')[-1]comments_link.append(message_id)links = drivertemp.find_elements_by_xpath('//div[@class="title"]//a[@title]')for element in links:href = element.get_attribute("href")link.append(href)drivertemp.quit()return link,comments_link,titlelist_url = "http://mguba.eastmoney.com/mguba/list/zssh000300"
link, comments_link,title = get_detail_urls_by_keyword(list_url)# print(title)
# print(link)
# print(comments_link)# 示例的 link 和 comments 列表final_link = [] # 用于存储符合条件的链接
final_comments = []
final_title = []
comment_counts = [int(link) for link in comments_link]
# 遍历 link 和 comments 列表,检查 comments 中的元素是否大于 5
for i in range(10,len(link)):if comment_counts[i] > 5:final_link.append(link[i])final_comments.append(comments_link[i])final_title.append(title[i])print(final_title)def get_information(urls):coments_n, date, title, reply, article = [], [], [], [], []for url in urls:'''获取包含特定关键字的留言链接'''user_agent = get_user_agent()chrome_options.add_argument('user-agent=%s' % user_agent)drivertemp = webdriver.Chrome(options=chrome_options)drivertemp.maximize_window()drivertemp.get(url)titles = drivertemp.find_elements_by_xpath('//div[@class="article-head"]//h1[@class="article-title"]')for element in titles:message_id = element.text.strip().split(':')[-1]title.append(message_id)dates = drivertemp.find_elements_by_xpath('//div[@class="article-meta"]//span[@class="txt"]')for element in dates:message_time = element.text.strip()date.append(message_time)articles = drivertemp.find_elements_by_xpath('/html/body/script[20]')for element in articles:message_time = element.get_attribute("text")print(message_time)#match = re.search(r'\"desc\":\"(.*?)\"', message_time)match = re.search(r'(?<=desc:").*?(?=")', message_time)if match:desc = match.group(0)max_line_length = 15desc_lines = [desc[i:i + max_line_length] for i in range(0, len(desc), max_line_length)]desc_text_formatted = "\n".join(desc_lines)article.append(desc_text_formatted)replies = drivertemp.find_elements_by_xpath('//div[@class="short_text"]')Replies = []for element in replies:message_time = element.text.strip().split(':')[-1]Replies.append(message_time)number = len(Replies)coments_n.append(number)Reply = "\n".join([f"{i + 1}. {comment}" for i, comment in enumerate(Replies)])reply.append(Reply)drivertemp.quit()return coments_n , date, title, reply,articlecoments_n, date, title, reply,article = get_information(final_link)print(reply)
print(article)
print(date)# 将这些列表组合成一个包含五个列表的列表
data = list(zip(final_comments, date, title, reply, article))# 指定要保存的CSV文件名
csv_filename = "example3.csv"# 修改字典中的键名称,使其与列名匹配
data = [{"评论数量": c, "日期": d, "帖子标题": t, "帖子的评论": r, "帖子内容": a}for c, d, t, r, a in data
]# 使用csv模块创建CSV文件并写入数据,同时指定列名
with open(csv_filename, 'w', newline='') as csvfile:fieldnames = ["评论数量", "日期", "帖子标题", "帖子的评论", "帖子内容"]writer = csv.DictWriter(csvfile, fieldnames=fieldnames)# 写入列名writer.writeheader()# 写入数据writer.writerows(data)print(f"Data has been written to {csv_filename}")
6.有需要爬取数据的朋友,或者学习技术的朋友都可以联系我,如果觉得对你有帮助,记得点个赞哦!!!!!!
相关文章:
爬虫项目-爬取股吧(东方财富)评论
1.最近帮别人爬取了东方财富股吧的帖子和评论,网址如下:http://mguba.eastmoney.com/mguba/list/zssh000300 2.爬取字段如下所示: 3.爬虫的大致思路如下:客户要求爬取评论数大于5的帖子,首先获取帖子链接,…...

【Midjourney入门教程2】Midjourney的基础操作和设置
文章目录 Midjourney的常用命令和基础设置1、 /imagine2、 /blend3、 /info4、 /subscribe5、 /settings(Midjourney的基础设置)6、 /shorten 有部分同学说我不想要英文界面的,不要慌: 点击左下角个人信息的设置按钮,找…...

后端使用DES加密,前端解密方法
前言: 现在为了防止用户直接篡改数据会采用加密的方式进行传输,加密的方法有很多种,这篇文章主要讲解下后端使用DES加密的数据传输给前端,前端接收到之后如何去解密。 操作步骤如下: 1.安装crypto-js npm install c…...
chrome 扩展 popup 弹窗的使用
popup的基本使用方法 popup介绍 popup 是点击 browser_action 或者 page_action图标时打开的一个小窗口网页,焦点离开网页就立即关闭,一般用来做一些临时性的交互。 popup配置 V3版本中(V2版本是在 browser_action 中 )&#x…...
Spring Security入门教程,springboot整合Spring Security
Spring Security是Spring官方推荐的认证、授权框架,功能相比Apache Shiro功能更丰富也更强大,但是使用起来更麻烦。 如果使用过Apache Shiro,学习Spring Security会比较简单一点,两种框架有很多相似的地方。 目录 一、准备工作 …...
如何在 Unbuntu 下安装配置 Apache Zookeeper
简介 Zookeeper 是 apache 基金组织下的项目,项目用于简单的监控和管理一组服务,通过简单的接口就可以集中协调一组服务,如配置管理,信息同步,命名,分布式协调。 准备工作 Ubuntu 23.04 或者 20.04访问…...
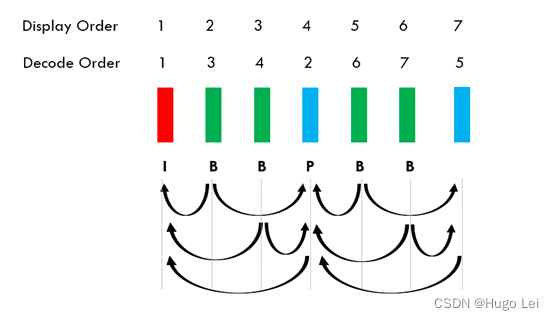
AI视觉领域流媒体知识入门介绍(二):深入理解GOP
GOP(group of pictures) 在流行的视频编码算法中,都包含GOP这个概念,例如MPEG-2, H.264, and H.265。 背景 关于视频存储和传输的“size”: Resolution 分辨率 Uncompressed Bitrate 未压缩时的比特率 1280720 (720p…...
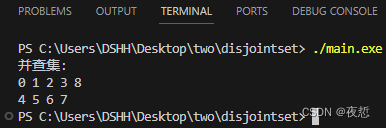
C++ 代码实例:并查集简单创建工具
文章目录 前言代码仓库代码说明main.cppMakefile 结果总结参考资料作者的话 前言 C 代码实例:并查集简单创建工具。 代码仓库 yezhening/Programming-examples: 编程实例 (github.com)Programming-examples: 编程实例 (gitee.com) 代码 说明 简单地创建并查集注…...
Hadoop学习总结(Shell操作)
HDFS Shell 参数 命令参数功能描述-ls查看指定路径的目录结构-du统计目录下所有文件大小-mv移动文件-cp复制文件-rm删除文件 / 空白文件夹-put上传文件-cat查看内容文件-text将源文件输出文本格式-mkdir创建空白文件夹-help帮助 一、ls 命令 ls 命令用于查看指定路径的当前目录…...

LeetCode热题100——链表
链表 1. 相交链表2. 反转链表3. 回文链表4. 环形链表5. 合并两个有序链表 1. 相交链表 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 // 题解:使用A/B循环遍…...

使用C++的QT框架实现贪吃蛇
最近刷抖音经常看到别人使用类似chatGPT的al工具实现这个贪吃蛇游戏,正好我之前也写过,那么今天看看怎么去实现这个简单的游戏 我这边使用的是C的QT框架,当然用哪些框架都可以,主要是逻辑思路 1.生成画布,开始是一些…...

如何发布自己的golang库
如何发布自己的golang库 1、在 github/gitee 上创建一个 public 仓库,仓库名与 go 库名一致,然后将该仓库 clone 到本地。 本文这里使用 gitee。 $ git clone https://gitee.com/zsx242030/goutil.git2、进入项目文件夹,进行初始化。 $ go…...

梳理自动驾驶中的各类坐标系
目录 自动驾驶中的坐标系定义 关于坐标系的定义 几大常用坐标系 世界坐标系 自车坐标系 传感器坐标系 激光雷达坐标系 相机坐标系 如何理解坐标转换 机器人基础中的坐标转换概念 左乘右乘的概念 对左乘右乘的理解 再谈自动驾驶中的坐标转换 本节参考文献 自动驾驶…...
一个可以自动把微信聊天收到的二维码图片实时提取出来并分类的软件
10-1 如果你有需要实时地、自动地把微信各个群收到的二维码图片提取出来的需求,那本文章适合你,本文章的主要内容是教你如何实现自动提取微信收到的二维码图片,助你快速扫码,永远比别人领先一步。 首先需要准备好的材料…...
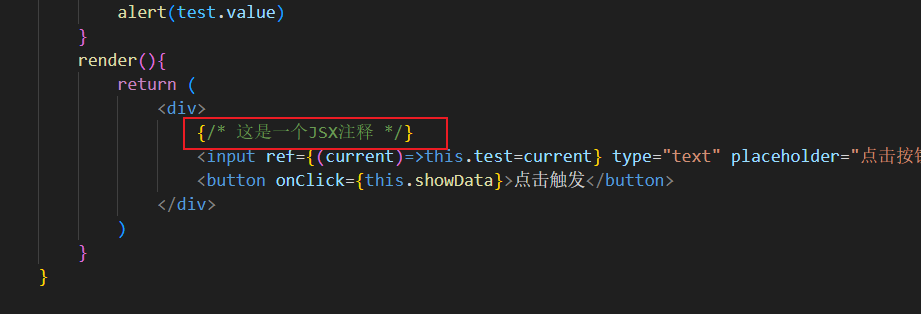
02-React组件与模块
组件与模块 前期准备 安装React官方浏览器调试工具,浏览器扩展搜索即可 比如红色的React就是本地开发模式 开启一个用React写的网站,比如美团 此时开发状态就变成了蓝色 组件也能解析出来 何为组件&模块 模块,简单来说就是JS代…...
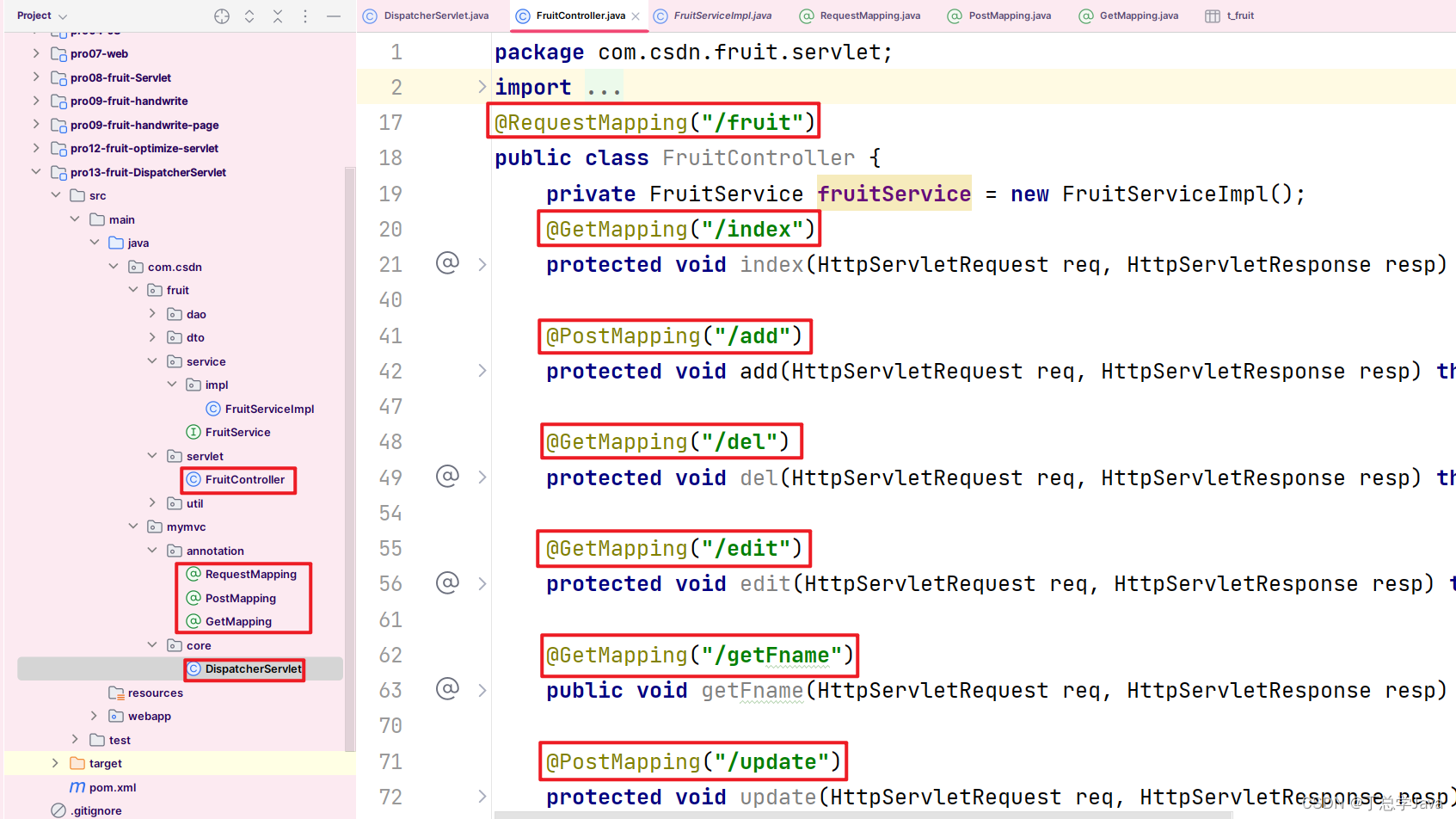
项目实战:新增@RequestMapping和@GetMapping和@PostMapping三个注解
1、RequestMapping package com.csdn.mymvc.annotation; import java.lang.annotation.*; Target(ElementType.TYPE) Retention(RetentionPolicy.RUNTIME) Inherited public interface RequestMapping {String value(); }2、PostMapping package com.csdn.mymvc.annotation; im…...
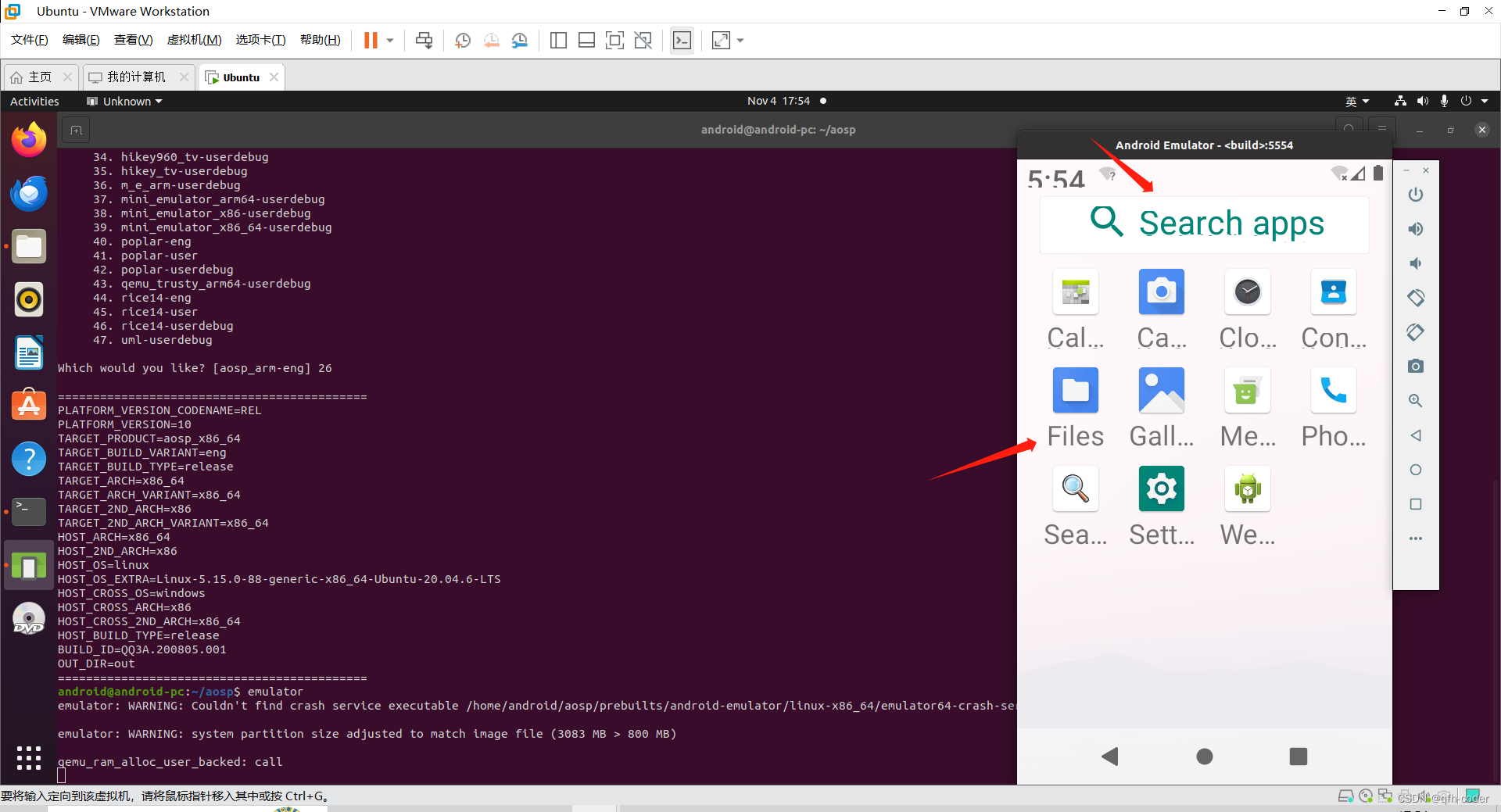
基于AOSP源码Android-10.0.0_r41分支编译,framework开发,修改系统默认字体大小
文章目录 基于AOSP源码Android-10.0.0_r41分支编译,framework开发,修改系统默认字体大小 基于AOSP源码Android-10.0.0_r41分支编译,framework开发,修改系统默认字体大小 主要修改一个地方就行 代码源码路径 frameworks/base/co…...
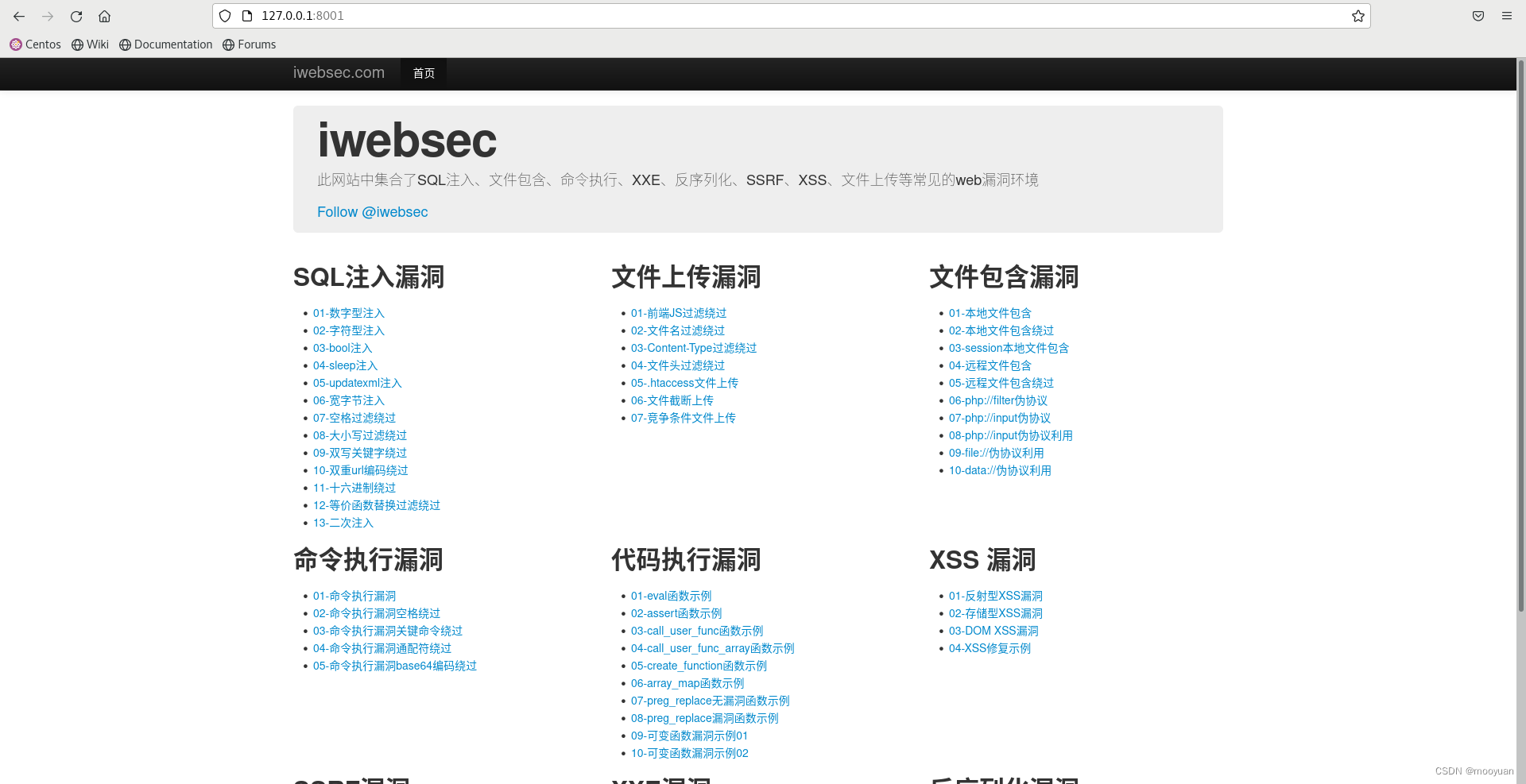
如何再kali中下载iwebsec靶场
这个靶场有三种搭建方法: 第一种是在线靶场:http://www.iwebsec.com:81/ 第二种是虚拟机版本的,直接下载到本地搭建 官网地址下载:http://www.iwebsec.com/ 而第三种就是利用docker搭建这个靶场,我这里是用kali进行…...
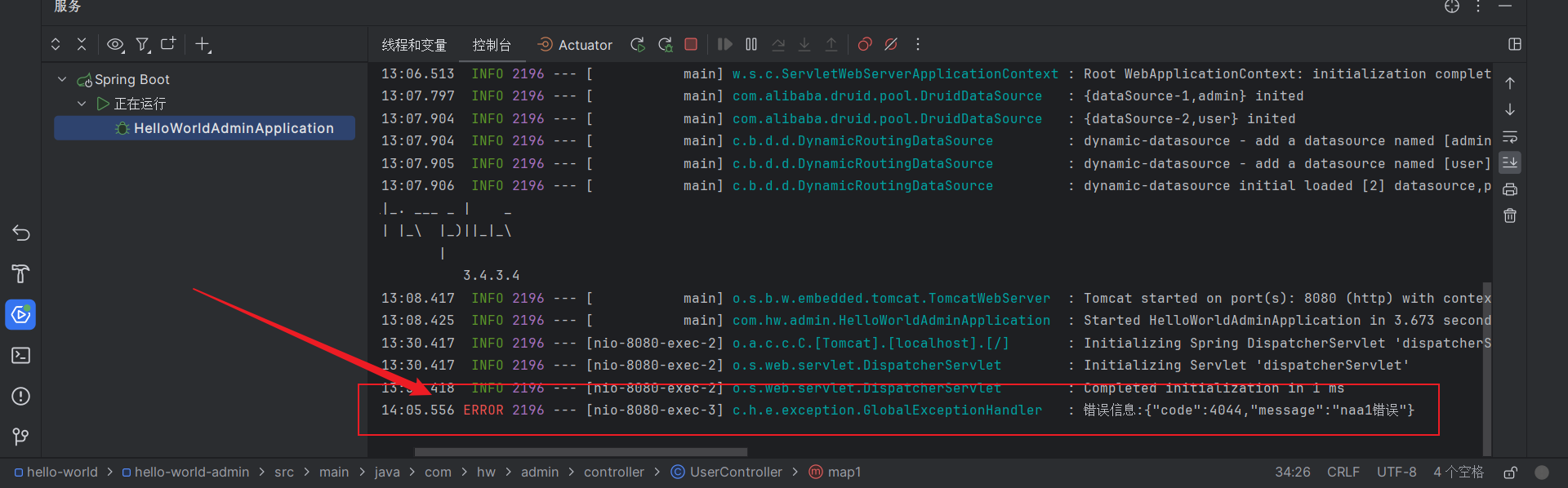
Spring Boot 使用断言抛出自定义异常,优化异常处理机制
文章目录 什么是断言?什么是异常?基于断言实现的异常处理机制创建自定义异常类创建全局异常处理器创建自定义断言类创建响应码类创建工具类测试效果 什么是断言? 实际上,断言(Assertion)是在Java 1.4 版本…...

vue基于ElementUI/Plus自定义的一些组件
vue3-my-ElementPlus 源码请到GitHub下载使用MyTable、MySelect、MyPagination 置顶|Top | 使用案例: 1.0 定义表格数据(测试使用) data() {return {tableData: [],value:[],valueList: [],}; },// 构造表格测试数据// 1 第一行…...

Allegro等长设置翻车实录:拓扑模板法的3个坑与手工PinPair的救赎
Allegro等长设计避坑指南:从拓扑模板到精准PinPair的实战演进在高速PCB设计中,等长匹配如同精密钟表里的齿轮啮合,差之毫厘便可能导致整个系统时序崩塌。当设计从简单的点对点结构升级到多负载复杂拓扑时,Allegro用户常陷入两种典…...

机器学习与深度学习在地球物理勘探中的应用:基于电阻率数据预测极化率模型
1. 项目概述与核心价值在花岗岩这类地质条件复杂的地区搞勘探,最头疼的就是地下情况“看不清”。传统的电阻率(ERT)和激发极化(IP)联合反演,就像用一把刻度模糊的尺子去量一块表面坑洼不平的石头——面对高…...

智能检索新范式,让AIAgent自主决策,提升RAG效率100%!
市面上的 RAG 系统,不管叫什么名字,本质上只有两种做法: 第一种,一次性检索。把用户的 query 向量化,从语料库里捞出 Top-K 个文档片段,拼成一个大 prompt 塞给模型。GraphRAG、HippoRAG、LightRAG 都属于…...

照着用就行:2026 最新降AIGC软件测评与推荐
2026年真正好用的AI论文降重与改写工具,核心看降重效果、去AI味、格式保留、学术适配四大指标。综合实测,千笔AI、ThouPen、豆包、DeepSeek、Grammarly 是当前最值得推荐的梯队,覆盖从免费到付费、从中文到英文、从文科到理工的全场景需求。 …...

华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate
华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zen…...

为什么软件开发偏爱 Linux?深度剖析 Linux 相较于 Windows 的核心优势
引言 在软件开发的世界里,一个有趣的现象是:无论是大型互联网公司的服务器集群,还是资深程序员的个人开发机,Linux 操作系统的身影无处不在。与之形成鲜明对比的是,尽管 Windows 在个人消费市场占据绝对主导地位&…...
)
CentOS服务器上VNC连接失败?手把手教你排查并修复个人端口问题(附重启命令)
CentOS服务器VNC连接故障深度排查指南:从原理到实战当你在深夜赶项目时,突然发现VNC连接不上服务器,那种焦虑感我深有体会。去年参与半导体器件仿真项目时,我也曾被这个问题困扰整整两天。本文将分享一套经过实战检验的排查方法论…...

Graphin高级应用:结合GISDK构建配置化图分析模块的完整指南
Graphin高级应用:结合GISDK构建配置化图分析模块的完整指南 【免费下载链接】Graphin 🌌 A React toolkit for graph visualization based on G6. 项目地址: https://gitcode.com/gh_mirrors/gr/Graphin 在当今数据驱动的时代,图可视化…...

Unity项目实战:用TriLib插件动态加载FBX模型,5分钟搞定外部资源读取
Unity项目实战:用TriLib插件高效加载外部FBX模型的完整指南在VR展示、产品配置器等需要动态加载用户上传模型的场景中,如何快速实现外部FBX文件的读取是许多Unity开发者面临的挑战。传统的手动导入方式不仅效率低下,更无法满足运行时动态加载…...

Python Android打包终极指南:5个实战技巧解决移动开发痛点
Python Android打包终极指南:5个实战技巧解决移动开发痛点 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android Python-for-Android(简称p4…...