【RabbitMQ】RabbitMQ 消息的可靠性 —— 生产者和消费者消息的确认,消息的持久化以及消费失败的重试机制
文章目录
- 前言:消息的可靠性问题
- 一、生产者消息的确认
- 1.1 生产者确认机制
- 1.2 实现生产者消息的确认
- 1.3 验证生产者消息的确认
- 二、消息的持久化
- 2.1 演示消息的丢失
- 2.2 声明持久化的交换机和队列
- 2.3 发送持久化的消息
- 三、消费者消息的确认
- 3.1 配置消费者消息确认
- 3.2 演示 none 模式
- 3.3 演示 auto 模式
- 四、消息消费失败的重试机制
- 4.1 本地重试机制
- 4.2 失败消息的处理策略
前言:消息的可靠性问题
在现代分布式应用程序中,消息队列扮演了至关重要的角色,允许系统中的各个组件之间进行异步通信。这种通信模式提供了高度的灵活性和可伸缩性,但也引入了一系列的挑战,其中最重要的之一是消息的可靠性。
首先让我们来了解一下,在消息队列中,消息从生产者发送到交换机,再到队列,最后到消费者,有哪些情况会导致消息的丢失?
-
发送时丢失:
- 生产者发送的消息未送达交换机;
- 消息到达交换机后未到达队列;
-
MQ 宕机,队列中的消息会丢失;
-
消费者接收到消息后未消费就宕机了。
 确保消息队列的可靠性是分布式系统中不可或缺的一部分,因此我们需要采取措施来应对这些挑战。为了解决上述消息可靠性问题,RabbitMQ提供了一系列的机制和最佳实践,以确保消息在整个传递过程中得到妥善处理和保护。
确保消息队列的可靠性是分布式系统中不可或缺的一部分,因此我们需要采取措施来应对这些挑战。为了解决上述消息可靠性问题,RabbitMQ提供了一系列的机制和最佳实践,以确保消息在整个传递过程中得到妥善处理和保护。
本文将深入探讨如何应对这些挑战,介绍消息队列中的关键概念,并详细讨论 RabbitMQ 提供的解决方案,包括生产者消息的确认、消息的持久化、消费者消息的确认以及消息消费失败的重试机制。这些措施将有助于确保消息队列在应用程序中的可靠性和稳定性。
一、生产者消息的确认
1.1 生产者确认机制
RabbitMQ 提供了 publisher confirm 机制,这是一种用于解决消息发送过程中可能出现的丢失问题的机制。当消息发送到 RabbitMQ 后,系统会返回一个结果给消息的发送者,以指示消息的处理状态。这个结果有两种可能的值:
-
publisher-confirm,发送者确认:
- 消息成功投递到交换机,系统返回
ack(确认)。 - 消息未能成功投递到交换机,系统返回
nack(未确认)。
- 消息成功投递到交换机,系统返回
-
publisher-return,发送者回执:
- 消息成功投递到交换机,但是没有成功路由到队列,系统返回
ACK,同时提供路由失败的原因。
- 消息成功投递到交换机,但是没有成功路由到队列,系统返回
这个确认机制的目的是确保消息在发送到消息队列后,发送者能够获得有关消息处理状态的明确反馈,从而可以采取适当的措施,例如重发消息或记录失败信息。
需要注意的是,为了实现这一机制,需要为每条消息设置一个全局唯一的标识符,以便区分不同的消息,避免在确认过程中出现冲突。
例如下图所示:
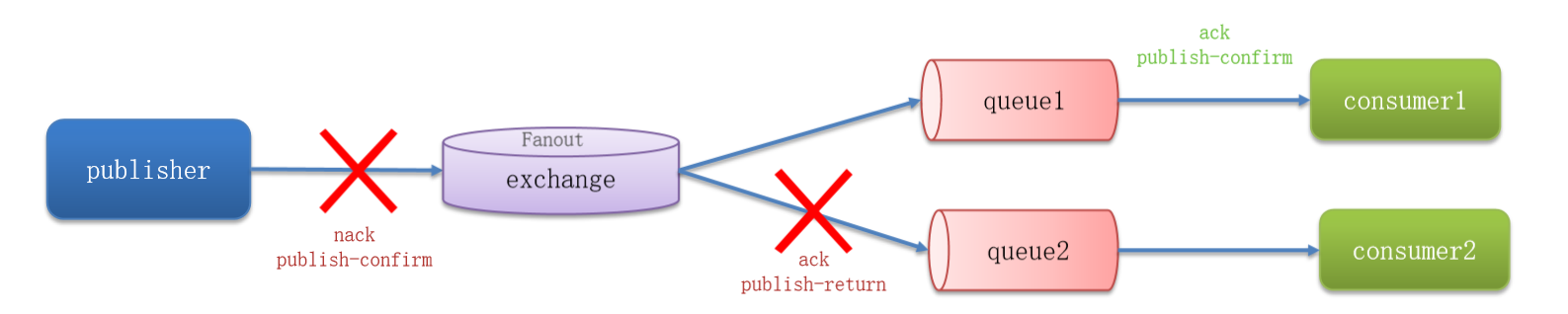
确保消息生产者能够获得有关消息状态的反馈是确保消息可靠性的关键一步,因为它有助于解决消息可能在发送期间丢失的问题。这是构建可靠的消息队列系统中的重要组成部分。
1.2 实现生产者消息的确认
下面将通过一个 Java 的 Spring Boot 项目来演示如何实现生产者消息的确认。这个项目的结构如下:

这个项目有两个模块,其中 consumer 负责对消息的消费,而 publisher 负责发送消息。下面是在 publisher 模块中实现消息确认的具体步骤:
- 在
publisher服务中的application.yml文件中添加如下配置:
spring:rabbitmq:publisher-confirm-type: correlatedpublisher-returns: truetemplate:mandatory: true
对这个配置的详细说明:
publish-confirm-type:开启publisher-confirm功能,这里支持两种类型:simple:同步等待confirm结果,直到超时;correlated:异步回调,定义ConfirmCallback,MQ返回结果时会回调这个ConfirmCallback。
publish-returns:开启publish-return功能,同样是基于callback机制,不过是定义ReturnCallback;template.mandatory:定义消息路由失败时的策略。true,则调用ReturnCallback;false,则直接丢弃消息。
- 给
RabbitTemplate配置ReturnCallback:
@Configuration
@Slf4j
public class CommonConfig implements ApplicationContextAware {@Overridepublic void setApplicationContext(ApplicationContext applicationContext) throws BeansException {// 获取 RabbitTemplate 对象RabbitTemplate rabbitTemplate = applicationContext.getBean(RabbitTemplate.class);// 配置 ReturnCallBackrabbitTemplate.setReturnCallback((message, replyCode, replyText, exchange, routingKey) -> {// 记录日志log.error("消息发送到队列失败,响应码:{},失败原因:{},交换机:{},路由 Key:{},消息:{}",replyCode, replyText, exchange, routingKey, message.toString());// 如果有需要,接下来可以重发消息,或者执行其他通知逻辑});}
}
由于每个 RabbitTemplate 只能配置一个 ReturnCallback,并且 RabbitTemplate 在Spring 中是一个全局对象,因此需要在项目启动过程中配置。
上述代码就是一个 Spring Boot 的配置类,通常用于在项目启动时配置一些全局的设置。在这个配置类中,实现了 ApplicationContextAware 接口,用于获取 Spring 应用上下文(ApplicationContext)对象。主要作用是配置 RabbitMQ 的 ReturnCallback,以处理消息发送到队列失败的情况。
- 发送消息,指定消息的 ID以及消息的
ConfirmCallback
@Test
public void testSendMessage2SimpleQueue() throws InterruptedException {String routingKey = "simple.test";// 1. 准备消息String message = "hello, spring amqp!";// 2. 准备 CorrelationDate// 2.1.消息IDCorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString());// 2.2.准备 ConfirmCallbackcorrelationData.getFuture().addCallback(confirm -> {// 消息发送成功// 判断结果if(confirm != null && confirm.isAck()){// ACKlog.debug("消息投递到交换机成功!消息 ID: {}", correlationData.getId());} else {// NACKlog.error("消息投递到交换机失败!消息 ID: {}", correlationData.getId());}}, throwable -> {// 发送失败// 记录日志log.error("消息发送失败!", throwable);// 重发消息...});// 3. 发送消息rabbitTemplate.convertAndSend("amq.topic", routingKey, message, correlationData);
}
这是一个 Java 测试方法,用于发送消息到 RabbitMQ 队列,并指定消息的 ID 以及 ConfirmCallback(确认回调)。以下是对这段代码的详细解释:
-
testSendMessage2SimpleQueue: 这是一个测试方法,用于演示如何发送消息到名为 “simple.test” 的 RabbitMQ 队列。 -
String routingKey = "simple.test";: 定义了消息的路由键,这是用于将消息路由到特定队列的关键。 -
准备消息:将要发送的消息内容存储在
message变量中。 -
准备
CorrelationData:CorrelationData用于关联消息的 ID。- 使用
UUID.randomUUID().toString()生成一个全局唯一的消息 ID。
-
准备
ConfirmCallback:CorrelationData.getFuture().addCallback(confirm -> { ... }, throwable -> { ... })定义了ConfirmCallback,该回调会在消息的发送状态发生变化时触发。- 在
ConfirmCallback中,判断了消息是否成功投递到交换机:- 如果
confirm不为 null 且confirm.isAck()为true,则表示消息成功到达交换机,记录一条成功的日志。 - 否则,如果消息未成功到达交换机,则记录一条失败的日志。
- 如果
- 在
throwable回调中,处理了发送失败的情况,记录了失败的日志,可以在这里添加重发消息或其他失败处理逻辑。
-
发送消息:
- 使用
rabbitTemplate.convertAndSend("amq.topic", routingKey, message, correlationData);发送消息到 RabbitMQ。 - 参数包括交换机名称、路由键、消息内容和关联的
CorrelationData。
- 使用
这段代码演示了如何发送消息并在消息状态变化时使用 ConfirmCallback 处理消息的确认情况。通过关联消息 ID 和 ConfirmCallback,可以确保消息的可靠性,根据确认情况采取适当的措施。
1.3 验证生产者消息的确认
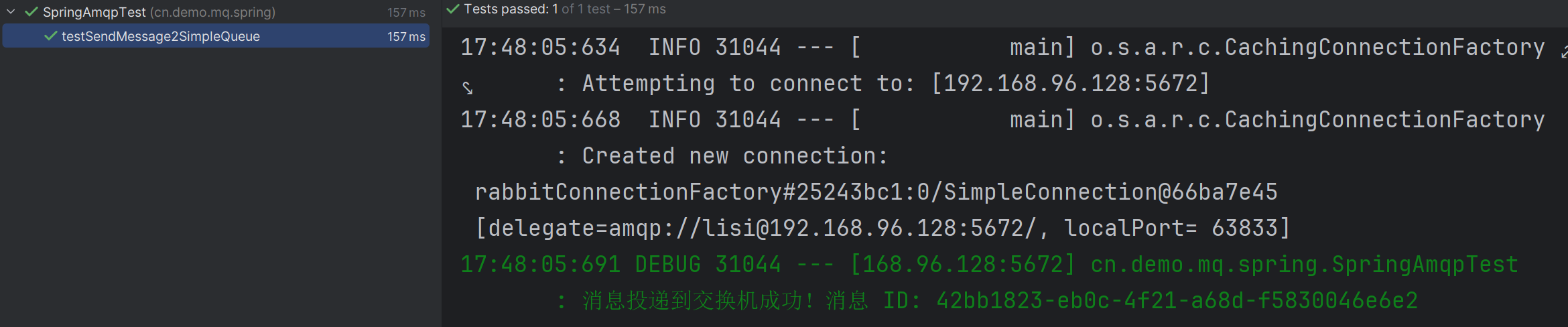
下面通过可以运行上述测试代码来查看生产者的消息确认情况:
- 正常发送消息
直接执行测试方法,可以发现消息成功投递到交换机:
- 发送消息失败
此时,将交换机的名称改成一个错误不存在的:
 然后再次执行测试方法:
然后再次执行测试方法:

发现此时消息投递到交换机失败,说明此时返回的是 NACK,并且提示了错误的原因是找不到名为 aamq.topic的交换机。
- 成功发送消息,但是路由失败
此时将交换机的名称修改回来,但是将路由 Key 修改成错误的:

然后执行测试方法:
 通过输出的日志可以发现,消息成功投递到了交换机,但是由于路由 Key 不正确,导致路由不到
通过输出的日志可以发现,消息成功投递到了交换机,但是由于路由 Key 不正确,导致路由不到 simple,queue,从而触发调用了上文配置的ReturnCallback。
二、消息的持久化
在通过上文的生产者消息确认机制之后,确保了消息能够正确的发送到队列中,但是这并不意味着消息就安全了。因为 RabbitMQ 默认是内存储存的,如果出现了 RabbitMQ 宕机的情况,那么此时队列中的消息还是会丢失。要确保消息能够真正的安全,我们还需要实现消息的持久化。
2.1 演示消息的丢失
例如,现在 simple.queue 中存在 3 条消息:

这些消息是通过 RabbitMQ 自带的交换机 amp.topic 进行转发的:
然后我们重启一下 RabbitMQ 服务,看一看队列中的消息是否还存在:

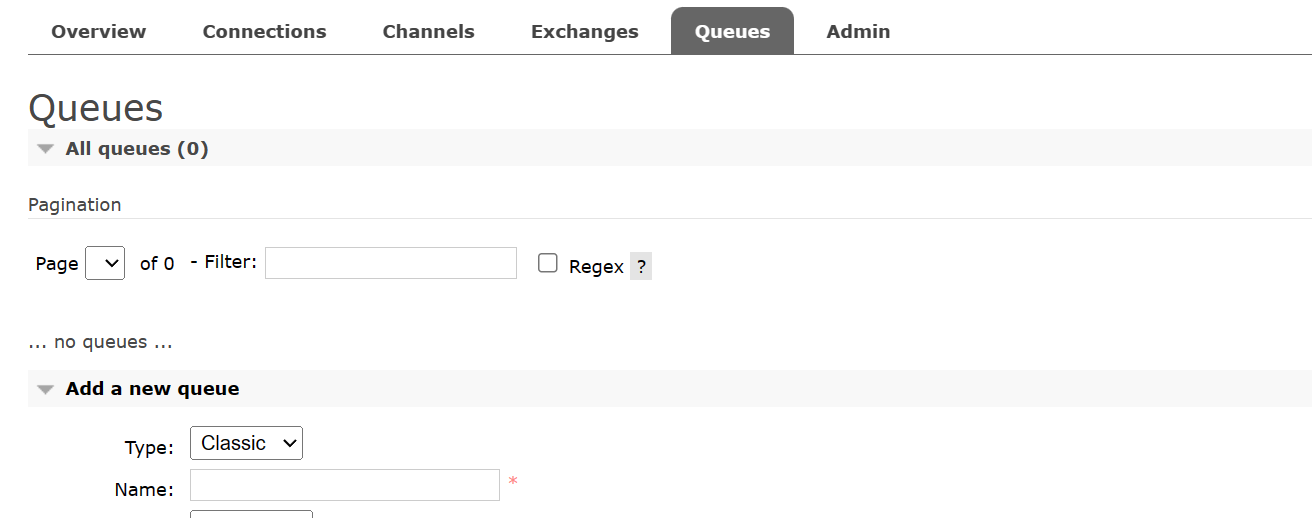
此时我们重新服务 RabbitMQ 的控制台,发现连 simple.queue 都消失了:
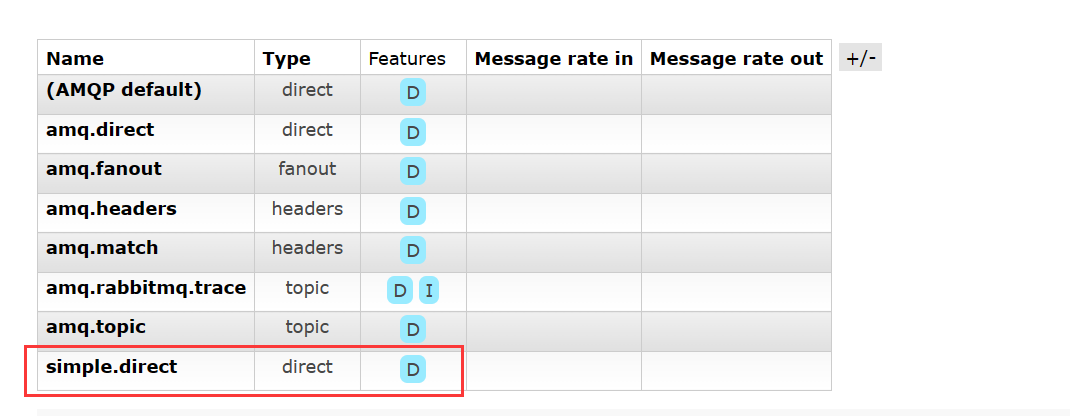
但是RabbitMQ自带的 amp.topic 交换机还存在:
 说明,这个交换机是持久化储存的,如果仔细观察可以发现,这些所有的交换机的
说明,这个交换机是持久化储存的,如果仔细观察可以发现,这些所有的交换机的 Features 都带有一个 D ,即持久化 Durable。
因此要让我们自己创建的队列或者交换机也能持久存在,就可以否选上 Durable 这个选项:

2.2 声明持久化的交换机和队列
通过上文我们知道了可以在 RabbitMQ 的控制台创建交换机和队列的时候可以勾选 Durable 来达到持久化的目的,但是如果使用代码来创建持久化的交换机和队列呢?下面我将使用 Java 代码来演示这个过程:
由于消费者comsumer在启动的时候可以帮我们创建交换机和队列,因此将交换机和队列的声明交给 consumer 来完成。
- 声明持久化的交换机
@Configuration
public class CommonConfig {@Beanpublic DirectExchange simpleDirect(){// DirectExchange的构造方法有三个参数:交换机名称、是否持久化、当没有 queue 与其绑定时是否自动删除return new DirectExchange("simple.direct", true, false);}
}
- 声明持久化的队列持久化
@Configuration
public class CommonConfig {// ...@Beanpublic Queue simpleQueue(){// 使用QueueBuilder构建队列,其中使用 durable 方法就是持久化的return QueueBuilder.durable("simple.queue").build();}
}
当完成了上面两步之后,我们可以启动 consumer 服务:

此时,我们发现成功创建了simple.direct交换机和 simple.queue 队列,并且它们都是持久的。然后停止consumer 服务,在 RabbitMQ 的控制台中向 simple.queue 添加一条消息:

然后再次重启 RabbitMQ 服务,发现刚才创建的交换机和队列都还在,但是消息却没有了:
 因为我刚才添加的是非持久化的消息:
因为我刚才添加的是非持久化的消息:

2.3 发送持久化的消息
同样,在控制台添加消息的时候可以设置消息的持久化和非持久化,下面让我来演示然后在使用 Java 代码发送持久化的消息:
@Test
public void testDurableMessage() {// 1. 准备消息Message message = MessageBuilder.withBody("hello, simple.queue".getBytes(StandardCharsets.UTF_8)).setDeliveryMode(MessageDeliveryMode.PERSISTENT).build();// 2. 发送消息rabbitTemplate.convertAndSend("simple.queue", message);
}
在发送持久化的消息需要使用MessageBuilder来构建消息,其中withBody用于指定消息体;setDeliveryMode用来设置消息的发送类型,可以是持久化的,也可以是非持久化的;build 与构建消息。
完成上述代码之后,我们可以执行这个测试方法:
查看 RabbitMQ 的控制台,发现成功发送了消息,并且其中的 delivery_mode 为 2,代表的就是持久化:

再次重启 RabbitMQ 服务:

此时发现刚才的消息并没有丢失,至此我们就完成了持久化消息的发送,进一步确保了消息的可靠性。另外,其实在使用 Spring AMQP 创建的交换机,队列和发送的消息都是持久化的。
三、消费者消息的确认
3.1 配置消费者消息确认
RabbitMQ 同样也支持消费者确认机制,即当消费者处理消息后可以向 MQ 发送 ack 回执,当 MQ 收到 ack 回执后才会删除该消息。而Spring AMQP 则允许配置三种确认模式:
manual:在代码中手动 ack,需要在业务代码结束后,调用Spring AMQP 提供的 API 发送 ack,但是这种情况存在代码侵入的问题。auto:基于 AOP 自动发送 ack,由 Spring 监测listener代码是否出现异常,没有异常则返回 ack;抛出异常则返回 nack;none:关闭 ack,MQ 假定消费者获取消息后会成功处理,因此消息投递后立即被删除。
实现消费者的确认机制的方式就是是修改application.yml文件,添加下面配置:
spring:rabbitmq:listener:simple:prefetch: 1acknowledge-mode: auto # none,关闭ack;manual,手动ack;auto:自动 ack
3.2 演示 none 模式
此时,我们将消费者的确认模式改为 none:

消息处理逻辑:
@Slf4j
@Component
public class SpringRabbitListener {@RabbitListener(queues = "simple.queue")public void listenSimpleQueue(String msg) {System.out.println("消费者接收到simple.queue的消息:【" + msg + "】");// 模拟异常System.out.println(1/0);log.info("消费者处理消息成功!");}
}
在这里,使用 System.out.println(1/0)来模拟异常的产生。
此时,在 simple.queue 中存在一条消息:

然后,我们将断点设置到如下位置:
 调试运行,可以发现,在
调试运行,可以发现,在 none 模式下,只有消费者接收到了消息,RabbitMQ 就会立即删除队列中的消息。

在这种none模式下,队列中的消息并不可靠,当消费者消费消息失败的时候不应该理解删除,而是应该重新发送或者采取其他措施来保证消息的可靠性。
3.3 演示 auto 模式
接下来让我们演示一下 auto 模式:

同样在simple.queue中准备一条消息:
 然后调试运行刚才的代码:
然后调试运行刚才的代码:
此时发现consumer成功接收到了消息:
 并且,此时
并且,此时 simple.queue 中消息的状态变成了 Unacked:

如果,此时放行代码,发现消费者还是会继续接收到这条消息:

此时,如果取消断点,并放开代码,会发现此时的消费者就会一直死循环的接收到这条消息。
通过上面的演示可以发现,尽管在 auto 模式下保证了消息的不丢失,但是此时如果消费者出现了异常,就会死循环的接收并尝试处理同一条消息。面对这个问题,还需要采取其他措施来进行处理,例如下文消费者消费失败的重试机制。
四、消息消费失败的重试机制
4.1 本地重试机制
当消费者出现异常后,消息会不断 requeue(重新入队)到队列,再重新发送给消费者,然后再次异常,再次 requeue,无限循环,导致 MQ的消息处理的压力大大提高,给 MQ 服务器带来不必要的压力:

我们可以利用 Spring 的 retry 机制,在消费者出现异常时利用本地重试,而不是无限制的 requeue 到 MQ 队列,使用这个重试机制需要在 application.yml 添加如下配置:
spring:rabbitmq:listener:simple:retry:enabled: true # 开启消费者失败重试initial-interval: 1000 # 初识的失败等待时长为1秒multiplier: 1 # 失败的等待时长倍数,下次等待时长 = multiplier * last-intervalmax-attempts: 3 # 最大重试次数stateless: true # true无状态;false 有状态。如果业务中包含事务,这里改为 false
完成了上面的配置之后,再次重启 consumer :


发现,消费者在本地重试了三次,最终还是失败,然后就放弃重试,并且simple.queue 中的消息也删除了。
4.2 失败消息的处理策略
在开启重试模式后,重试次数耗尽,如果消息依然失败,则需要有 MessageRecoverer 接口来处理,它包含三种不同的实现:
RejectAndDontRequeueRecoverer:重试次数耗尽后,直接reject,丢弃消息,这是默认采取的方式;ImmediateRequeueMessageRecoverer:重试次数耗尽后,返回 nack,消息重新入队;RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机。
下面演示一下 RepublishMessageRecoverer 处理模式:
- 首先,定义接收失败消息的交换机、队列及其绑定关系:
@Bean
public DirectExchange errorMessageExchange() {return new DirectExchange("error.direct");
}@Bean
public Queue errorQueue() {return new Queue("error.queue", true);
}@Bean
public Binding errorBinding() {return BindingBuilder.bind(errorQueue()).to(errorMessageExchange()).with("error");
}- 然后,定义
RepublishMessageRecoverer:
@Bean
public MessageRecoverer republishMessageRecoverer(RabbitTemplate rabbitTemplate) {return new RepublishMessageRecoverer(rabbitTemplate, "error.direct", "error");
}
当我们注册了 RepublishMessageRecoverer Bean 对象之后,就会自动覆盖 Spring 提供的默认的 RejectAndDontRequeueRecoverer 的 Bean 对象。
当完成了上述的所有配置之后,首先在 simple.queue 中准备一条消息,然后再启动 consumer:

最终发现,处理失败的消息最终转发到了 error.queue 队列了。
相关文章:
【RabbitMQ】RabbitMQ 消息的可靠性 —— 生产者和消费者消息的确认,消息的持久化以及消费失败的重试机制
文章目录 前言:消息的可靠性问题一、生产者消息的确认1.1 生产者确认机制1.2 实现生产者消息的确认1.3 验证生产者消息的确认 二、消息的持久化2.1 演示消息的丢失2.2 声明持久化的交换机和队列2.3 发送持久化的消息 三、消费者消息的确认3.1 配置消费者消息确认3.2…...

百万套行泊一体量产定点,中国市场「开启」智驾高低速集成
进入2023年,席卷中国市场的行泊一体概念方案进入定点、量产交付的第一波高峰期。这套方案,以高性价比、硬件复用、高低速智驾集成的模式,备受市场青睐。 本周,纵目科技宣布,Amphiman3000行泊一体产品获得长安汽车旗下…...
Gopro hero5运动相机格式化后恢复案例
Gopro运动相机以稳定著称,旗下的Hero系列销售全球。下面我们来看一个Hero5格式化后拍了少量素材的恢复案例。 故障存储:64G MicroSD卡 Exfat文件系统 故障现象: 64G的卡没备份数据时做了格式化操作又拍了一条,发现数据没有备份,客户自行使…...

Microsoft Dynamics 365 CE 扩展定制 - 6. 增强代码
在本章中,我们将介绍以下内容: 使用三层模式重构插件用QueryExpressions替换LINQ数据访问层记录自定义项中的错误将插件转换为自定义工作流活动单元测试插件业务逻辑使用内存上下文对插件进行单元测试端到端集成测试插件分析插件构建通用读取审核插件利用CRM Online实现跨来源…...

基于libopenh264 codec的svc分层流实现方案
OpenH264 http://www.openh264.org/ 是标准的H.264 encoder/decoder. ffmpeg已经集成libopenh264,但不支持svc特性。 openh264 encoder支持svc特性: 1. 时域4层:Temporal scalability up to 4 layers in a dyadic hierarchy 2. 空域4层&#…...

为机器学习算法准备数据(Machine Learning 研习之八)
本文还是同样建立在前两篇的基础之上的! 属性组合实验 希望前面的部分能让您了解探索数据并获得洞察力的几种方法。您发现了一些数据怪癖,您可能希望在将数据提供给机器学习算法之前对其进行清理,并且发现了属性之间有趣的相关性,…...

基于Python OpenCV的金铲铲自动进游戏、D牌...
基于Python OpenCV的金铲铲自动进游戏、D牌... 1. 自动点击进入游戏1.1 环境准备1.2 功能实现2. 自动D牌3. 游戏结束自动退1. 自动点击进入游戏 PS: 本测试只用于交流学习OpenCV的相关知识,不能用于商业用途,后果自负。 1.1 环境准备 需要金铲铲在win10的模拟器,我们这里选…...

c++中httplib使用
httplib文件链接:百度网盘 请输入提取码 提取码:kgnq json解析库:百度网盘 请输入提取码 提取码:oug0 一、获取token 打开postman, 在body这个参数中点击raw,输入用户名和密码 然后需要获取到域名和地址。 c++代码如下: #include "httplib.h" #in…...
Vite 的基本原理,和 webpack 在开发阶段的比较
目录 1,webpack 的流程2,Vite 的流程简单编译 3,总结 主要对比开发阶段。 1,webpack 的流程 开发阶段大致流程:指定一个入口文件,对相关的模块(js css img 等)先进行打包࿰…...
[开源]免费开源MES系统/可视化数字大屏/自动排班系统
开源系统概述: 万界星空科技免费MES、开源MES、商业开源MES、市面上最好的开源MES、MES源代码、免费MES、免费智能制造系统、免费排产系统、免费排班系统、免费质检系统、免费生产计划系统。 万界星空开源MES制造执行系统的Java开源版本。开源mes系统包括系统管理…...

python如何使用gspread读取google在线excel数据?
一、背景 公司使用google在线excel管理测试用例,为了方便把手工测试用到的测试数据用来做自动化用例测试数据,所以就想使用python读取在线excel数据,通过数据驱动方式,完成自动化回归测试,提升手动复制,粘…...
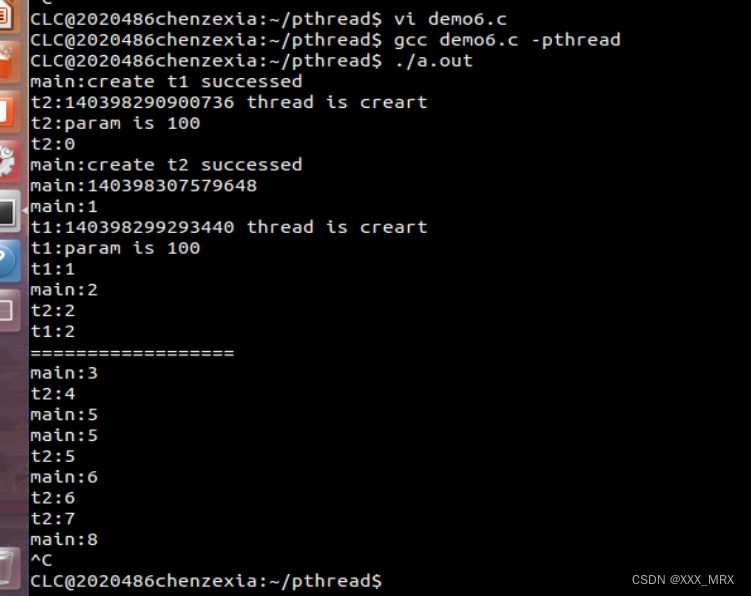
线程同步——互斥量解锁、解锁
类似与进程间通信信号量的加锁解锁。 对互斥量进行加锁后,任何其他试图在此对互斥量加锁的线程都会被阻塞,直到当前线程释放该互斥锁。如果释放互斥锁时有多个线程被阻塞,所有在该互斥锁上的阻塞线程都会变成可运行状态,第一个变…...

数据结构(c语言版) 顺序表
代码 #include <stdio.h> #include <stdlib.h>typedef int E; //这里我们的元素类型就用int为例吧,先起个别名//定义结构体 struct List{E * array;int capacity; //数组的容量int size; };//给结构体指针起别名 typedef struct List * ArrayLis…...
)
Springboot 集成 RocketMq(入门)
1.RocketMq安装部署 Linux 安装 RocketMq-CSDN博客 2.添加依赖包 <dependency><groupId>org.apache.rocketmq</groupId><artifactId>rocketmq-spring-boot-starter</artifactId><version>2.2.3</version> </dependency> 3.配…...
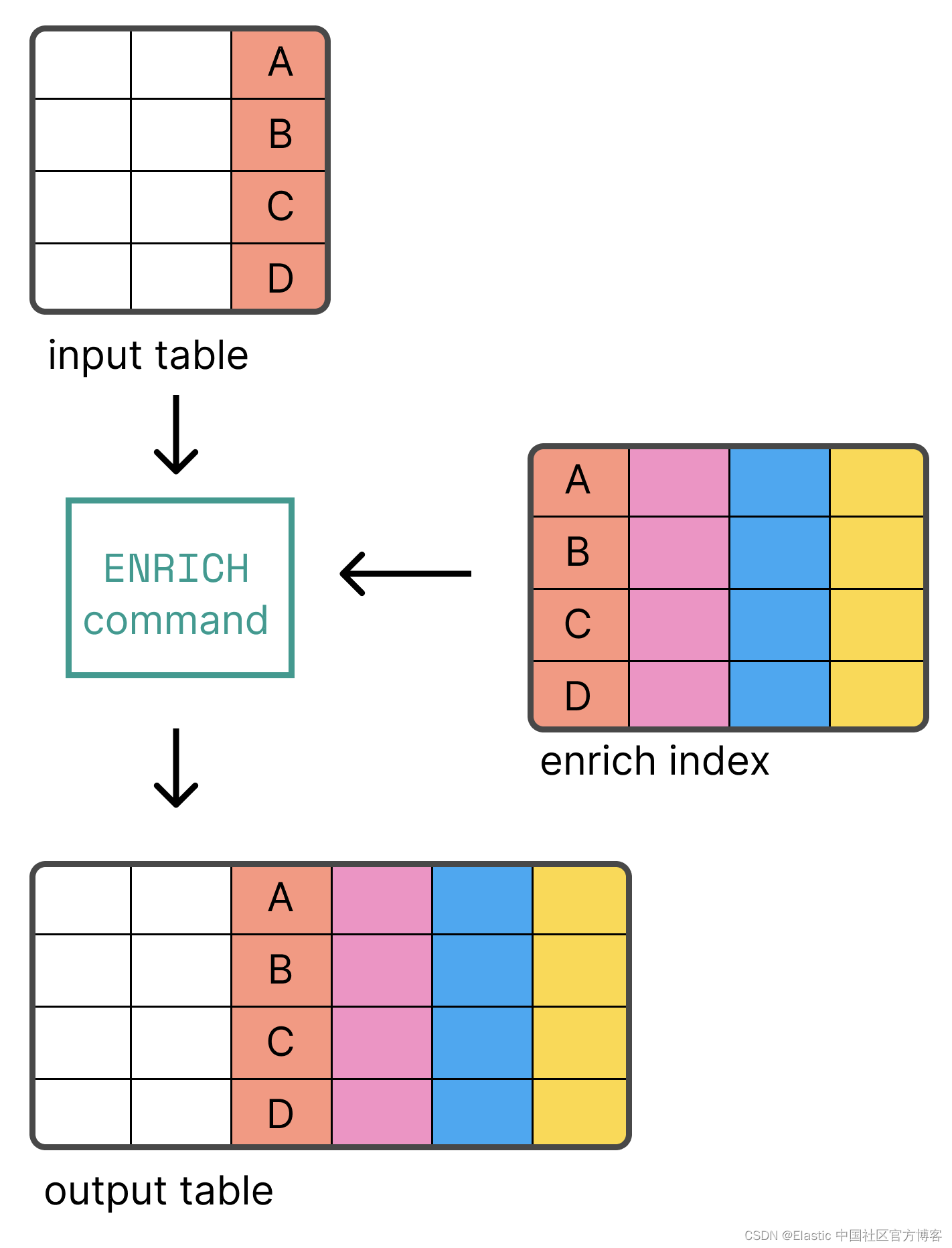
Elasticsearch:ES|QL 中的数据丰富
在之前的文章 “Elasticsearch:ES|QL 查询语言简介”,我有介绍 ES|QL 的 ENRICH 处理命令。ES|QL ENRICH 处理命令在查询时将来自一个或多个源索引的数据与 Elasticsearch 丰富索引中找到的字段值组合相结合。这个有点类似于关系数据库查询中所使用的 jo…...

【linux编程】linux文件IO高级I/O函数介绍和代码示例
Linux文件IO高级I/O函数用法是指如何使用这些函数来实现高效和灵活的文件读写操作,它们包括以下几类: 分散读和集中写:readv和writev函数可以一次性地从一个文件描述符读取或写入多个缓冲区,而不需要多次调用read或write函数。这样可以减少系统调用的开销,提高I/O效率。存…...

jQuery获取地址栏GET参数值
jQuery获取地址栏GET参数值 封装方法: window.location 是获取当前页面地址 // 获取地址栏参数 function GetUrlString(name){var reg new RegExp("(^|&)" name "([^&]*)(&|$)");var r window.location.search.substr(1).match…...

JAVA应用中线程池设置多少合适?
目录 1、机器配置: 2、核心线程数 3、最大线程数多少合适? 4、理论基础 5、测试验证 一个线程跑满一个核心的利用率 6个线程 12 个线程:所有核的cpu利用率都跑满 有io操作 6、计算公式 7、决定最大线程数的流程: 1、机器…...

.Net Core 3.1 解决数据大小限制
微软官网文档上对.NET Core3.1解决数据大小限制有详细的介绍。下面是根据自己的情况进行的总结,我们可以把.Core项目部署在IIS上,也可以利用Kestrel进行部署。这两种方式处理数据大小限制的方式不一样,具体如下: 一、部署在IIS上…...

【音视频 | opus】opus编码的Ogg封装文件详解
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 🤣本文内容🤣&a…...

小说下载器终极指南:一站式解决100+网站小说保存难题
小说下载器终极指南:一站式解决100网站小说保存难题 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 在数字阅读时代,你是否曾因小说突然下架、网站404或网络中…...

从Gamma函数到泊松分布:一个概率论中的含参量积分实用案例解析
Gamma函数与泊松分布:概率论中的数学之美 在数据科学和机器学习的实践中,概率分布构成了建模的基石。当我们深入探究这些分布背后的数学原理时,Gamma函数以其优雅的性质和广泛的应用脱颖而出。它不仅连接了离散与连续概率世界,更在…...

为Alchitry Au FPGA开发板外接JTAG接口的完整指南
1. 项目概述与核心价值如果你正在使用基于Xilinx Artix-7 FPGA的Alchitry Au或Au开发板,并且已经厌倦了每次调试或烧录都要依赖板载的USB-JTAG桥接芯片,或者你的项目已经将板载USB接口挪作他用,那么为你的开发板外接一个独立的JTAG调试器&…...

解决Claude Code Token不足问题并享受Taotoken活动价
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code Token不足问题并享受Taotoken活动价 应用场景类,聚焦于使用Claude Code时遇到Token配额紧张的开发者&…...

荣耀出征官方网站下载正版手游 翅膀养成细节玩法全方位讲解
玩荣耀出征的玩家都清楚,翅膀不仅是角色的颜值象征,更是提升整体战力的核心途径。很多新手玩家只顾着升级、刷装备,完全忽略翅膀养成,导致等级很高但战力始终上不去。还有不少玩家胡乱合成、盲目进阶,浪费了大量稀有翅…...

GEO生成引擎优化:当AI成为信息分发的主角,品牌如何抢占对话窗口?
当用户不再"搜索-浏览",而是直接"AI提问-获取答案",传统SEO的逻辑正在被彻底改写。2026年,GEO(Generative Engine Optimization,生成式引擎优化)已经从概念走向规模化落地。本文从技术…...

论文写作效率翻倍?okbiye 毕业论文 AI 功能全解析:从需求到终稿的规范路径
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 一、从界面看本质:okbiye 毕业论文 AI 写作的设计逻辑 打开 okbiye 的毕业论文 AI 写作页面,首先能感受到的是清晰的…...
原理与ScalableHD架构优化实践)
超维计算(HDC)原理与ScalableHD架构优化实践
1. 超维计算(HDC)基础解析超维计算(Hyperdimensional Computing, HDC)是一种受大脑信息处理机制启发的计算范式,其核心思想是用高维随机向量(通常称为超向量或HV)来表示和处理信息。与传统神经网…...

风控系统如何全维度识别爬虫:IP、账号与行为的协同决策机制
1. 这不是“反爬失败”,而是风控系统在对你做全维度画像你写完一段 requests BeautifulSoup 的代码,本地跑通了,开开心心部署到服务器,结果第二天早上发现:所有请求返回 403,日志里全是空响应;…...
)
Claude端到端测试设计终极清单:覆盖17类非功能需求(含延迟敏感度分级、幻觉熔断阈值、多轮对话状态持久化验证)
更多请点击: https://kaifayun.com 第一章:Claude端到端测试设计的演进逻辑与核心范式 Claude端到端测试并非静态产物,而是随模型能力边界拓展、交互场景复杂化及可靠性要求升级而持续演化的工程实践。其演进逻辑根植于三个关键张力…...