第G7周:Semi-Supervised GAN 理论与实战
🍨 本文为🔗365天深度学习训练营 中的学习记录博客
🍦 参考文章:365天深度学习训练营-第G7周:Semi-Supervised GAN 理论与实战(训练营内部成员可读)
🍖 原作者:K同学啊|接辅导、项目定制
🏡 运行环境:
电脑系统:Windows 10
语言环境:python 3.10
编译器:Pycharm 2022.1.1
深度学习环境:Pytorch
目录
一、理论知识讲解
二、代码实现
1、配置代码
2、初始化权重
3、定义算法模型
4、配置模型
5、训练模型
一、理论知识讲解
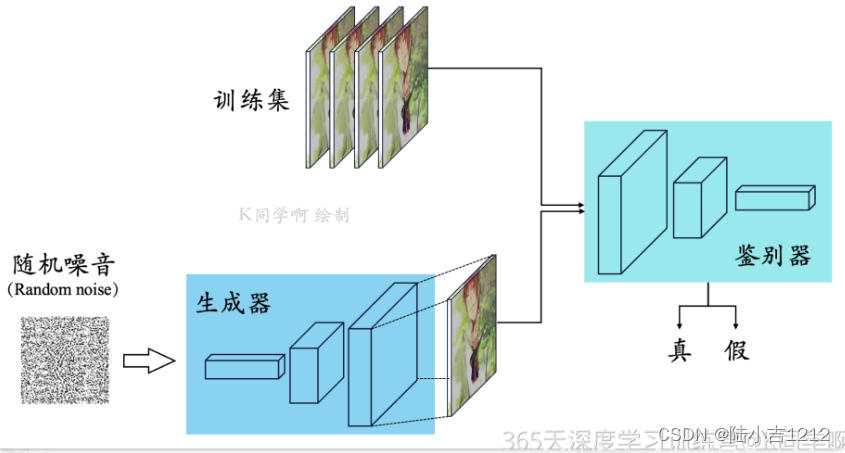
该算法将产生式对抗网络(GAN) 拓展到半监督学习,通过强制判别器D来输出类别标签。我们
在一个数据集上训练一个生成器G以及一个判别器D,输入是N类当中的一个。在训练的时候,判别器D被用于预测输入是属于N+1类中的哪一个,这个N+1是对应了生成器G的输出,这里的判别器
D同时也充当起了分类器C的效果。这种方法可以用于训练效果更好的判别器D,并且可以比普通的GAN产性更加高质量的样本。Semi-Supervised GAN有如下优点:
(1)作者对GANs做了一个新的扩展,允许它同时学习一个生成模型和一个分类器。我们把这个 扩展叫做半监督GAN或SGAN
(2)论文实验结果表明,SGAN在有限数据集比没有生成部分的基准分类器提升了分类性能。
(3)论文实验结果表明,SGAN可以显著地提升生成样本的质量并降低生成器的训练时间。 
二、代码实现
1、配置代码
import argparse
import os
import numpy as np
import mathimport torchvision.transforms as transforms
from torchvision.utils import save_imagefrom torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variableimport torch.nn as nn
import torch.nn.functional as F
import torchos.makedirs("images", exist_ok=True)parser = argparse.ArgumentParser()
parser.add_argument("--n_epochs", type=int, default=2, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--b1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--b2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--n_cpu", type=int, default=2, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--num_classes", type=int, default=10, help="number of classes for dataset")
parser.add_argument("--img_size", type=int, default=32, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--sample_interval", type=int, default=400, help="interval between image sampling")
opt = parser.parse_args(args=[])
print(opt)cuda = True if torch.cuda.is_available() else FalseNamespace(n_epochs=2, batch_size=64, lr=0.0002, b1=0.5, b2=0.999, n_cpu=2, latent_dim=100, num_classes=10, img_size=32, channels=1, sample_interval=400)
2、初始化权重
def weights_init_normal(m):classname = m.__class__.__name__if classname.find("Conv") != -1:torch.nn.init.normal_(m.weight.data, 0.0, 0.02)elif classname.find("BatchNorm") != -1:torch.nn.init.normal_(m.weight.data, 1.0, 0.02)torch.nn.init.constant_(m.bias.data, 0.0)3、定义算法模型
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()self.label_emb = nn.Embedding(opt.num_classes, opt.latent_dim)self.init_size = opt.img_size // 4 # Initial size before upsamplingself.l1 = nn.Sequential(nn.Linear(opt.latent_dim, 128 * self.init_size ** 2))self.conv_blocks = nn.Sequential(nn.BatchNorm2d(128),nn.Upsample(scale_factor=2),nn.Conv2d(128, 128, 3, stride=1, padding=1),nn.BatchNorm2d(128, 0.8),nn.LeakyReLU(0.2, inplace=True),nn.Upsample(scale_factor=2),nn.Conv2d(128, 64, 3, stride=1, padding=1),nn.BatchNorm2d(64, 0.8),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64, opt.channels, 3, stride=1, padding=1),nn.Tanh(),)def forward(self, noise):out = self.l1(noise)out = out.view(out.shape[0], 128, self.init_size, self.init_size)img = self.conv_blocks(out)return imgclass Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()def discriminator_block(in_filters, out_filters, bn=True):"""Returns layers of each discriminator block"""block = [nn.Conv2d(in_filters, out_filters, 3, 2, 1), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25)]if bn:block.append(nn.BatchNorm2d(out_filters, 0.8))return blockself.conv_blocks = nn.Sequential(*discriminator_block(opt.channels, 16, bn=False),*discriminator_block(16, 32),*discriminator_block(32, 64),*discriminator_block(64, 128),)# The height and width of downsampled imageds_size = opt.img_size // 2 ** 4# Output layersself.adv_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, 1), nn.Sigmoid())self.aux_layer = nn.Sequential(nn.Linear(128 * ds_size ** 2, opt.num_classes + 1), nn.Softmax())def forward(self, img):out = self.conv_blocks(img)out = out.view(out.shape[0], -1)validity = self.adv_layer(out)label = self.aux_layer(out)return validity, label4、配置模型
# Loss functions
adversarial_loss = torch.nn.BCELoss()
auxiliary_loss = torch.nn.CrossEntropyLoss()# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()if cuda:generator.cuda()discriminator.cuda()adversarial_loss.cuda()auxiliary_loss.cuda()# Initialize weights
generator.apply(weights_init_normal)
discriminator.apply(weights_init_normal)# Configure data loader
os.makedirs("../../data/mnist", exist_ok=True)
dataloader = torch.utils.data.DataLoader(datasets.MNIST("../../data/mnist",train=True,download=True,transform=transforms.Compose([transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5], [0.5])]),),batch_size=opt.batch_size,shuffle=True,
)# Optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=opt.lr, betas=(opt.b1, opt.b2))FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if cuda else torch.LongTensorDownloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to ../../data/mnist\MNIST\raw\train-images-idx3-ubyte.gzExtracting ../../data/mnist\MNIST\raw\train-images-idx3-ubyte.gz to ../../data/mnist\MNIST\rawDownloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to ../../data/mnist\MNIST\raw\train-labels-idx1-ubyte.gzExtracting ../../data/mnist\MNIST\raw\train-labels-idx1-ubyte.gz to ../../data/mnist\MNIST\rawDownloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to ../../data/mnist\MNIST\raw\t10k-images-idx3-ubyte.gzExtracting ../../data/mnist\MNIST\raw\t10k-images-idx3-ubyte.gz to ../../data/mnist\MNIST\rawDownloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to ../../data/mnist\MNIST\raw\t10k-labels-idx1-ubyte.gzExtracting ../../data/mnist\MNIST\raw\t10k-labels-idx1-ubyte.gz to ../../data/mnist\MNIST\raw
5、训练模型
# ----------
# Training
# ----------for epoch in range(opt.n_epochs):for i, (imgs, labels) in enumerate(dataloader):batch_size = imgs.shape[0]# Adversarial ground truthsvalid = Variable(FloatTensor(batch_size, 1).fill_(1.0), requires_grad=False)fake = Variable(FloatTensor(batch_size, 1).fill_(0.0), requires_grad=False)fake_aux_gt = Variable(LongTensor(batch_size).fill_(opt.num_classes), requires_grad=False)# Configure inputreal_imgs = Variable(imgs.type(FloatTensor))labels = Variable(labels.type(LongTensor))# -----------------# Train Generator# -----------------optimizer_G.zero_grad()# Sample noise and labels as generator inputz = Variable(FloatTensor(np.random.normal(0, 1, (batch_size, opt.latent_dim))))# Generate a batch of imagesgen_imgs = generator(z)# Loss measures generator's ability to fool the discriminatorvalidity, _ = discriminator(gen_imgs)g_loss = adversarial_loss(validity, valid)g_loss.backward()optimizer_G.step()# ---------------------# Train Discriminator# ---------------------optimizer_D.zero_grad()# Loss for real imagesreal_pred, real_aux = discriminator(real_imgs)d_real_loss = (adversarial_loss(real_pred, valid) + auxiliary_loss(real_aux, labels)) / 2# Loss for fake imagesfake_pred, fake_aux = discriminator(gen_imgs.detach())d_fake_loss = (adversarial_loss(fake_pred, fake) + auxiliary_loss(fake_aux, fake_aux_gt)) / 2# Total discriminator lossd_loss = (d_real_loss + d_fake_loss) / 2# Calculate discriminator accuracypred = np.concatenate([real_aux.data.cpu().numpy(), fake_aux.data.cpu().numpy()], axis=0)gt = np.concatenate([labels.data.cpu().numpy(), fake_aux_gt.data.cpu().numpy()], axis=0)d_acc = np.mean(np.argmax(pred, axis=1) == gt)d_loss.backward()optimizer_D.step()batches_done = epoch * len(dataloader) + iif batches_done % opt.sample_interval == 0:save_image(gen_imgs.data[:25], "images/%d.png" % batches_done, nrow=5, normalize=True)print("[Epoch %d/%d] [Batch %d/%d] [D loss: %f, acc: %d%%] [G loss: %f]"% (epoch, opt.n_epochs, i, len(dataloader), d_loss.item(), 100 * d_acc, g_loss.item()))
[Epoch 0/2] [Batch 937/938] [D loss: 1.358861, acc: 50%] [G loss: 0.671799] [Epoch 1/2] [Batch 937/938] [D loss: 1.343094, acc: 50%] [G loss: 0.681119]
相关文章:
第G7周:Semi-Supervised GAN 理论与实战
🍨 本文为🔗365天深度学习训练营 中的学习记录博客 🍦 参考文章:365天深度学习训练营-第G7周:Semi-Supervised GAN 理论与实战(训练营内部成员可读) 🍖 原作者:K同学啊|接…...
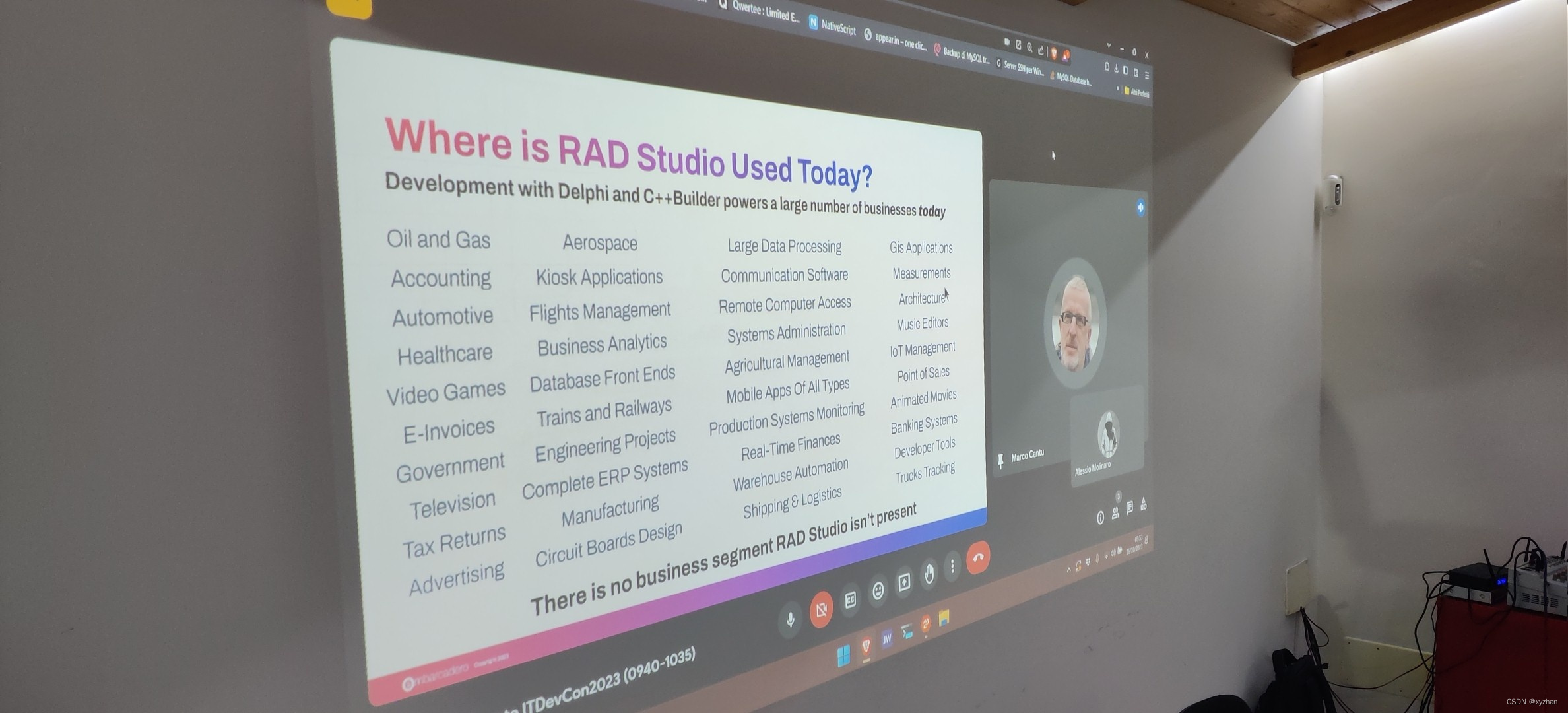
美国Embarcadero产品经理Marco Cantù谈Delphi/C++ Builder目前开发应用领域
美国Embarcadero产品经理Marco Cant 日前在欧洲的一次信息技术会议上谈到了Delphi/C Builder目前开发应用领域:RAD Studio Delphi/C Builder目前应用于哪些开发领域?使用 Delphi 和 CBuilder 进行开发为当今众多企业提供了动力。 航空航天 大型数据采集 …...
【iOS】——知乎日报第三周总结
文章目录 一、获取新闻额外信息二、工具栏按钮的布局三、评论区文字高度四、评论区长评论和短评论的数目显示五、评论区的cell布局问题和评论消息的判断 一、获取新闻额外信息 新闻额外信息的URL需要通过当前新闻的id来获取,所以我将所有的新闻放到一个数组中&…...
leetcode每日一题-周复盘
前言 该系列文章用于我对一周中leetcode每日一题or其他不会的题的复盘总结。 一方面用于自己加深印象,另一方面也希望能对读者的算法能力有所帮助。 该复盘对我来说比较容易的题我会复盘的比较粗糙,反之较为细致 解答语言:Golang 周一&a…...
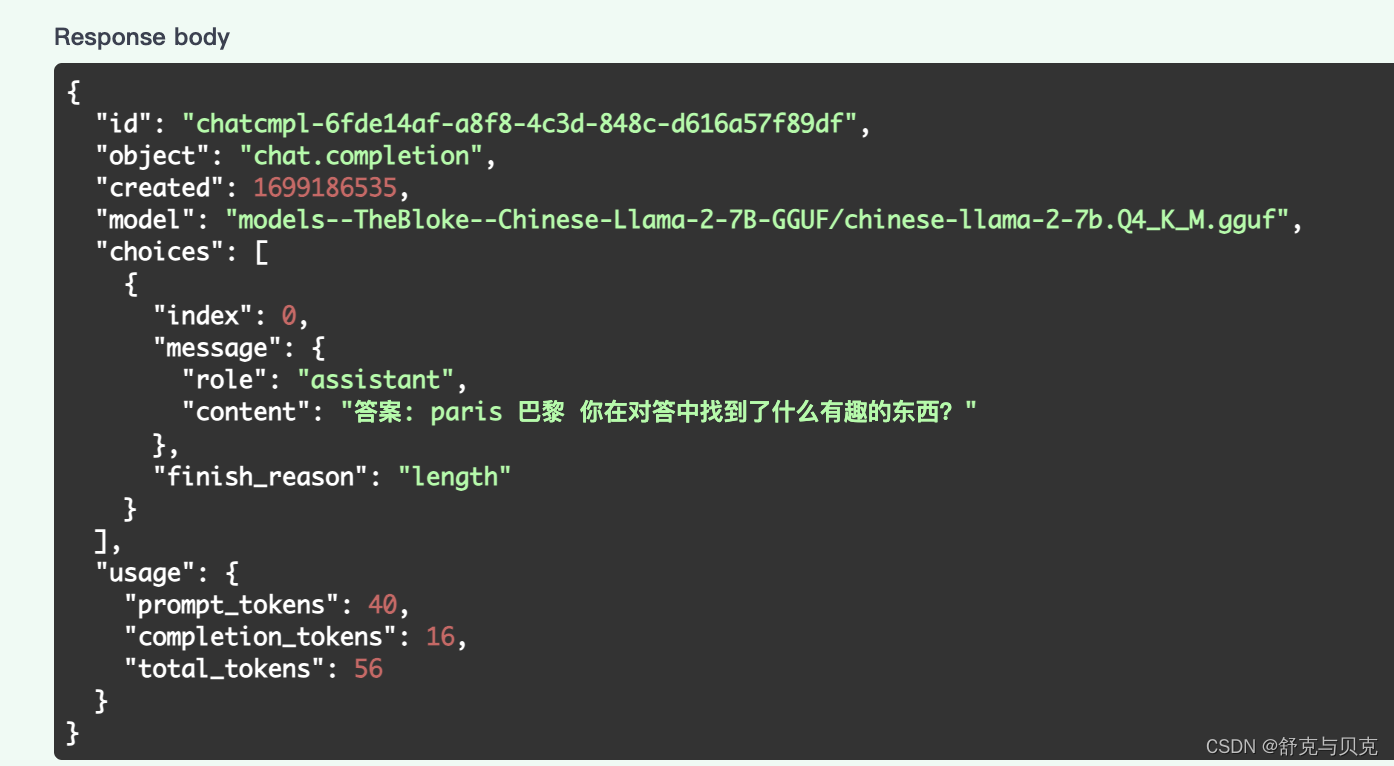
[NLP] LlaMa2模型运行在Mac机器
本文将介绍如何使用llama.cpp在MacBook Pro本地部署运行量化版本的Llama2模型推理,并基于LangChain在本地构建一个简单的文档Q&A应用。本文实验环境为Apple M1 芯片 8GB内存。 Llama2和llama.cpp Llama2是Meta AI开发的Llama大语言模型的迭代版本,…...
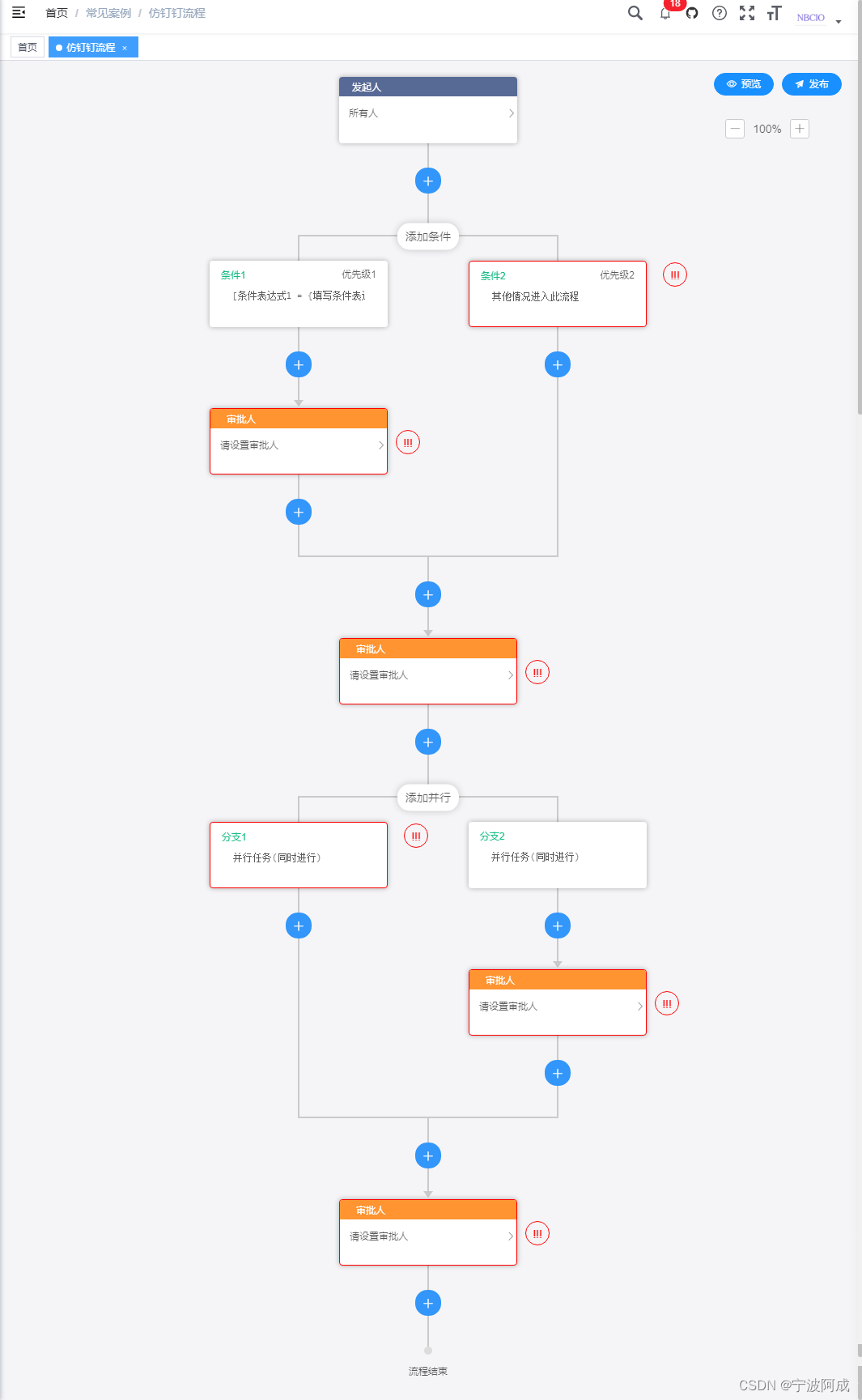
基于若依的ruoyi-nbcio流程管理系统增加仿钉钉流程设计(六)
更多ruoyi-nbcio功能请看演示系统 gitee源代码地址 前后端代码: https://gitee.com/nbacheng/ruoyi-nbcio 演示地址:RuoYi-Nbcio后台管理系统 这节主要讲条件节点与并发节点的有效性检查,主要是增加这两个节点的子节点检查,因为…...

听GPT 讲Rust源代码--library/std(15)
题图来自 An In-Depth Comparison of Rust and C[1] File: rust/library/std/src/os/wasi/io/fd.rs 文件路径:rust/library/std/src/os/wasi/io/fd.rs 该文件的作用是实现与文件描述符(File Descriptor)相关的操作,具体包括打开文…...
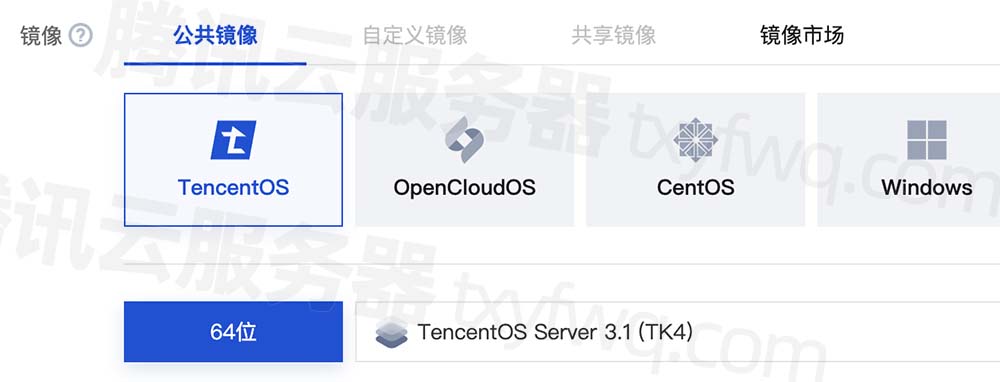
腾讯云CVM服务器操作系统镜像大全
腾讯云CVM服务器的公共镜像是由腾讯云官方提供的镜像,公共镜像包含基础操作系统和腾讯云提供的初始化组件,公共镜像分为Windows和Linux两大类操作系统,如TencentOS Server、Windows Server、OpenCloudOS、CentOS Stream、CentOS、Ubuntu、Deb…...

Mxnet框架使用
目录 1.mxnet推理API 2.MXNET模型转ONNX 3.运行示例 1.mxnet推理API # 导入 MXNet 深度学习框架 import mxnet as mx if __name__ __main__:# 指定预训练模型的 JSON 文件json_file resnext50_32x4d # 指定模型的参数文件params_file resnext50_32x4d-0000.params # 使…...

每个程序员都应该自己写一个的:socket包装类
每个程序员都应该有自己的网络类。 下面是我自己用的socket类,支持所有我自己常用的功能,支持windows和unix/linux。 目录 客户端 服务端 非阻塞 获取socket信息 完整代码 客户端 作为socket客户端,只需要如下几个功能: //…...

JMeter:断言之响应断言
一、断言的定义 断言用于验证取样器请求或对应的响应数据是否返回了期望的结果。可以是看成验证测试是否预期的方法。 对于接口测试来说,就是测试Request/Response,断言即可以针对Request进行,也可以针对Response进行。但大部分是对Respons…...
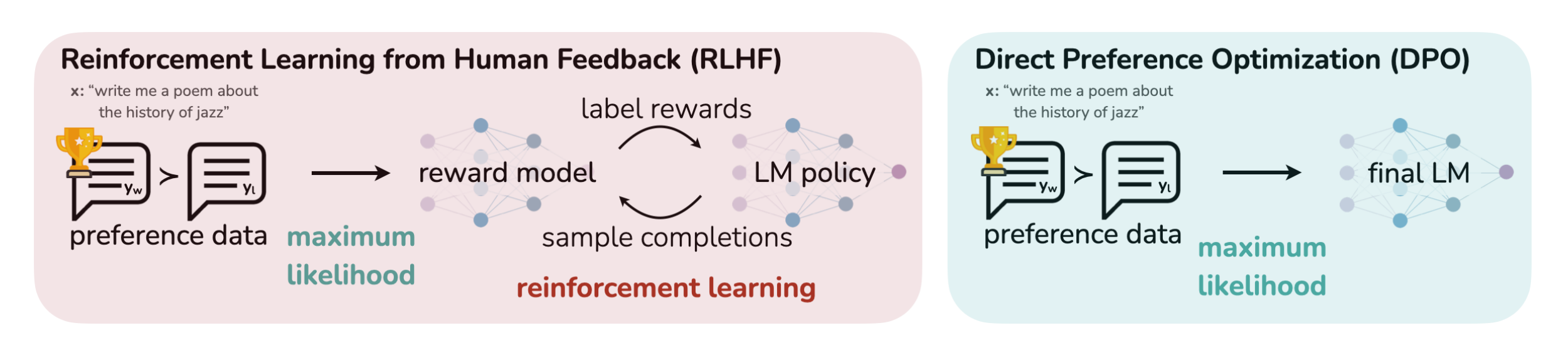
RLHF的替代算法之DPO原理解析:从Zephyr的DPO到Claude的RAILF
前言 本文的成就是一个点顺着一个点而来的,成文过程颇有意思 首先,如上文所说,我司正在做三大LLM项目,其中一个是论文审稿GPT第二版,在模型选型的时候,关注到了Mistral 7B(其背后的公司Mistral AI号称欧洲…...
U盘显示无媒体怎么办?方法很简单
当出现U盘无媒体情况时,您可以在磁盘管理工具中看到一个空白的磁盘框,并且在文件资源管理器中不会显示出来。那么,导致这种问题的原因是什么呢?我们又该怎么解决呢? 导致U盘无媒体的原因是什么? 当您遇到上…...
进销存管理系统如何提高供应链效率?
供应链和进销存系统之间有着密切的联系。进销存系统是供应链管理的一部分,用于跟踪和管理产品的采购、库存和销售。进销存管理是供应链管理的核心流程之一,它有助于提高效率、降低成本、增加盈利,同时确保客户满意度,这对于企业的…...

用AI魔法打败AI魔法
全文均为AI创作。 此为内容创作模板,在发布之前请将不必要的内容删除当前,AI技术的广泛应用为社会公众提供了个性化智能化的信息服务,也给网络诈骗带来可乘之机,如不法分子通过面部替换语音合成等方式制作虚假图像、音频、视频仿…...

Java 中的final:不可变性的魔法之旅
🎏:你只管努力,剩下的交给时间 🏠 :小破站 Java 中的final:不可变性的魔法之旅 前言第一:了解final变量第二:final方法第三:final类第四:final参数第五&#…...

Alfred 5 for mac(最好用的苹果mac效率软件)中文最新版
Alfred 5 Mac是一款非常实用的工具,它可以帮助用户更加高效地使用Mac电脑。用户可以学会使用快捷键、全局搜索、快速启动应用程序、使用系统维护工具、快速复制粘贴文本以及自定义设置等功能,以提高工作效率。 Alfred for Mac 的一些主要功能包括&#…...

常见的Python解释器,你了解多少?
Python,作为一种解释型编程语言,它的运行过程也遵循“程序源码—>解释器(字节码)—>虚拟机(可执行文件)”的流程。 在编写Python程序时,是在扩展名为.py的文件中进行编写,.py…...
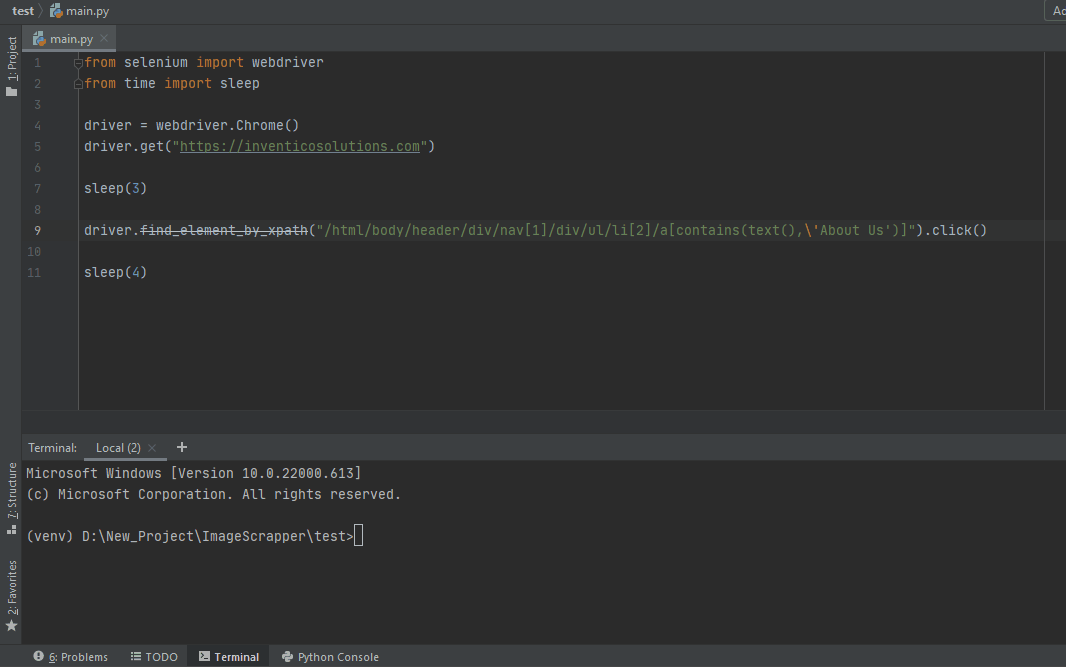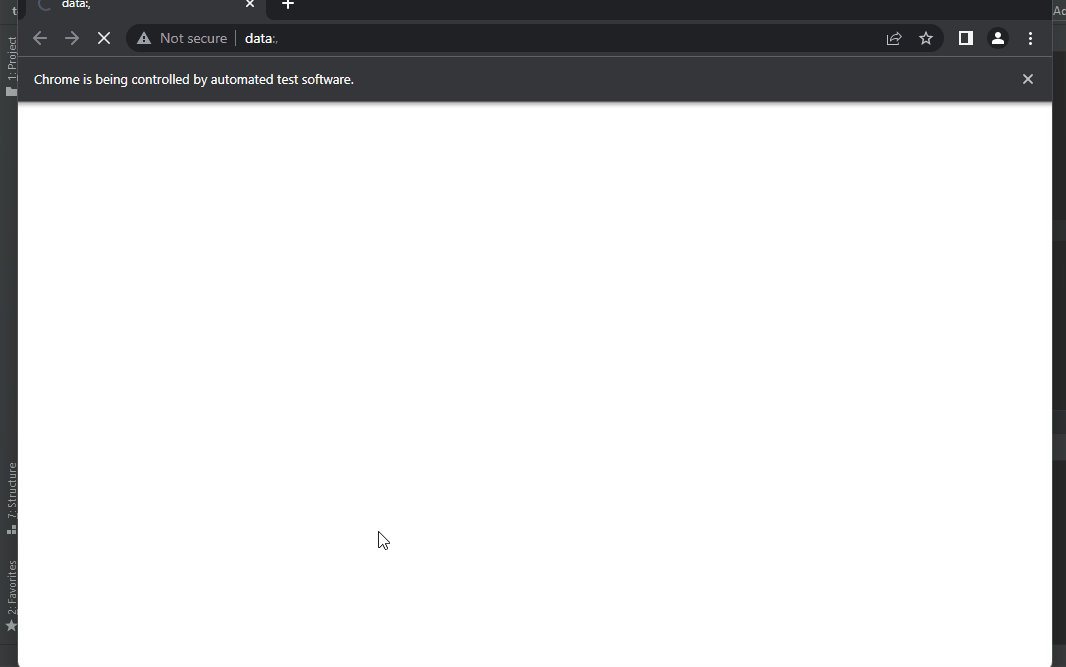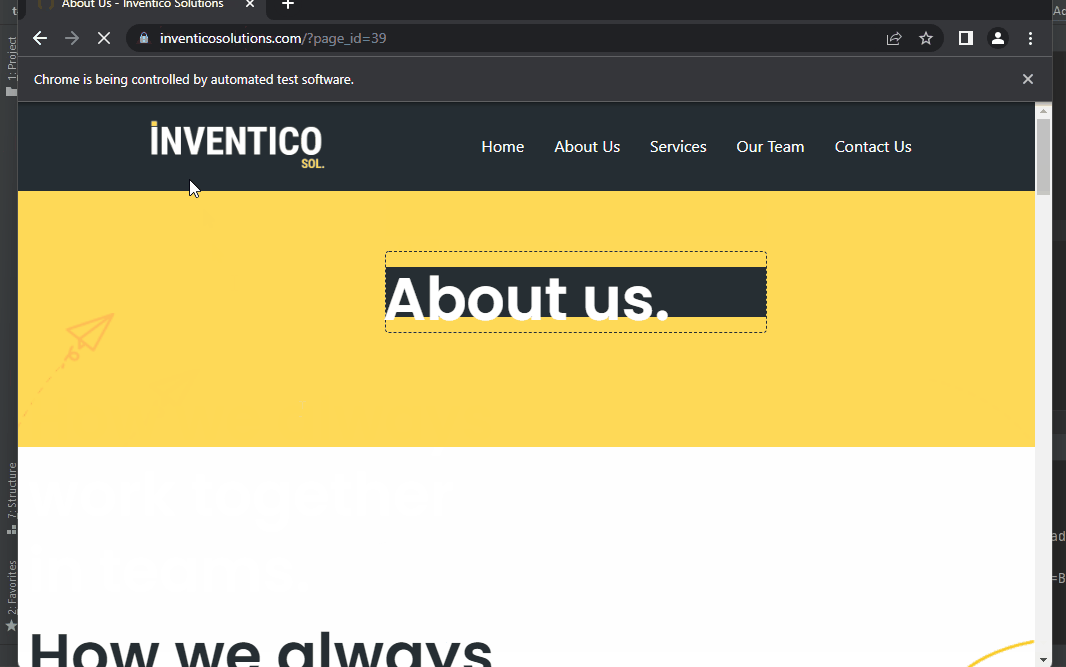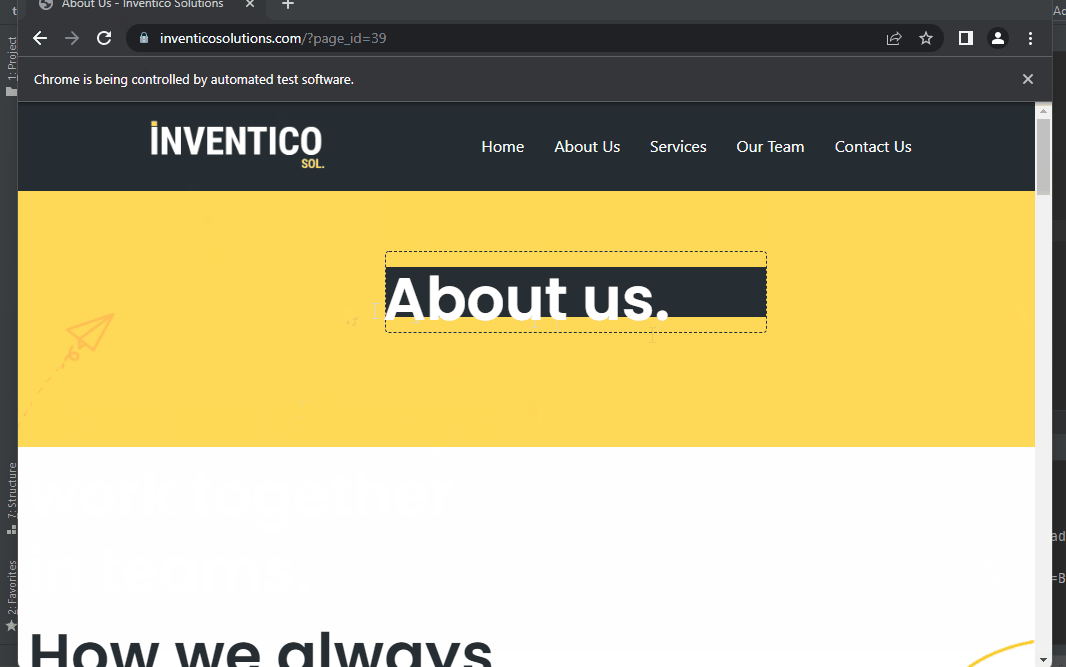
在 Python 中使用 Selenium 按文本查找元素
我们将通过示例介绍在Python中使用selenium通过文本查找元素的方法。 在 Python 中使用 Selenium 按文本查找元素 软件测试是检查应用程序是否满足用户需求的技术。 该技术有助于使应用程序成为无错误的应用程序。 软件测试可以手动完成,也可以通过某些软件完成。…...
被隐藏或遮挡如何恢复?)
【Notepad++】搜索返回窗口(find result)被隐藏或遮挡如何恢复?
Notepad 搜索返回窗口被隐藏或遮挡如何恢复 1:F72:F12恢复之后可以多看一些Notepad中快捷键的使用,以备不时之需。 1:F7 打开任意文件,搜索任意内容,按F7,焦点切换到Find result。 按AltSpace,出现小窗口点击"移动…...

DeepSeek代码质量评估实战手册:7步完成从混沌到可度量的质变跃迁
更多请点击: https://kaifayun.com 第一章:DeepSeek代码质量评估的底层逻辑与核心价值 DeepSeek代码质量评估并非简单地统计行数或检测语法错误,而是基于多维语义理解构建的推理系统。其底层逻辑融合了静态分析、符号执行与大语言模型生成式…...

自制射频功率计:基于AD8317芯片,成本43欧元实现1MHz-10GHz测量
1. 项目概述:为什么我要亲手打造一台射频功率计在无人机和模型飞行器的圈子里,尤其是在我们荷兰FMS Spaarnwoude俱乐部,合规飞行是头等大事。我给我的八轴飞行器加装了云台相机和图传系统,工作在5.8GHz频段。根据本地法规…...

为Alchitry Au FPGA开发板外接JTAG接口的完整指南
1. 项目概述与核心价值如果你正在使用基于Xilinx Artix-7 FPGA的Alchitry Au或Au开发板,并且已经厌倦了每次调试或烧录都要依赖板载的USB-JTAG桥接芯片,或者你的项目已经将板载USB接口挪作他用,那么为你的开发板外接一个独立的JTAG调试器&…...

13456
12356...

MBTI性格测试
简介 MBTI(Myers‑Briggs Type Indicator,迈尔斯‑布里格斯类型指标)是基于荣格心理类型理论发展出的性格类型工具,由凯瑟琳库克布里格斯及其女儿伊莎贝尔布里格斯迈尔斯创建。它通过四对偏好维度将个体的认知与行为倾向归纳为 16…...

MySQL GROUP BY 原理与优化
我刚工作的时候,有次统计每个用户的订单总金额,写了 SELECT user_id, SUM(amount) FROM orders GROUP BY user_id,结果执行了 60 秒还没出结果。DBA 帮我一看执行计划,发现没走索引,导致 Using temporary(用…...

谷氨酸发酵过程的软测量建模【附模型】
✨ 长期致力于软测量、谷氨酸发酵、动力学模型、支持向量机、高斯过程、变量选择、异常状态研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)多阶段高斯…...

工业云脑:06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例
06 现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例 今天第九篇06小节——现在就能干:树莓派边缘盒子+PLC,10分钟缺陷检测小案例。新手照着做10分钟就能跑起来,老手一看就知道这玩意儿省了多少钱。以前想上AI检测,得花几万块买专业边缘盒子;现在?树莓派5(RPi 5)…...

基于Max78000与规则引导的音频数据集构建:边缘AI声音识别实战
1. 项目概述:当边缘AI遇见棕榈树里的“窃听者”在边缘计算和物联网设备大行其道的今天,我们常常面临一个核心矛盾:一方面,我们希望设备足够“聪明”,能实时识别并响应特定的声音模式,比如工厂里高压阀门的异…...

AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸
AutoWall终极指南:如何在Windows上轻松设置炫酷动态壁纸 【免费下载链接】AutoWall 🌌 Live wallpapers on Windows 7/8/10/11 using open-source wallpaper engine 项目地址: https://gitcode.com/gh_mirrors/au/AutoWall 厌倦了千篇一律的静态桌…...