基于Pytorch框架的LSTM算法(一)——单维度单步滚动预测(2)
#项目说明:
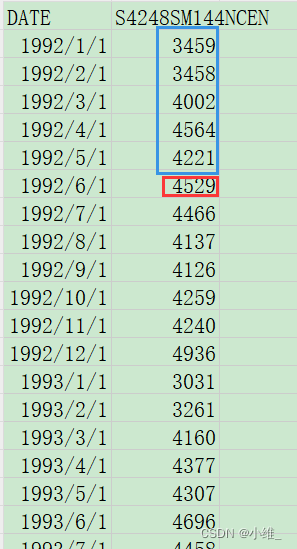
说明:1time_steps=
滚动预测代码
y_norm = scaler.fit_transform(y.reshape(-1, 1))
y_norm = torch.FloatTensor(y_norm).view(-1)# 重新预测
window_size = 12
future = 12
L = len(y)首先对模型进行训练;
然后选择所有数据的后window_size个数据,通过训练,每次通过前window_size个数据预测未来一个数据,之后新预测的一个数据append加到preds中,这样经过循环future次后,通过滚动循环的方式,预测未来future=12天的数据,完成滚动预测。
最后通过可视化查看预测结果。
preds = y_norm[-window_size:].tolist() model.eval()
for i in range(future): seq = torch.FloatTensor(preds[-window_size:])with torch.no_grad():model.hidden = (torch.zeros(1,1,model.hidden_size),torch.zeros(1,1,model.hidden_size)) preds.append(model(seq).item())true_predictions = scaler.inverse_transform(np.array(preds).reshape(-1, 1))x = np.arange('2019-02-01', '2020-02-01', dtype='datetime64[M]').astype('datetime64[D]')plt.figure(figsize=(12,4))
plt.grid(True)
plt.plot(df['S4248SM144NCEN'])
plt.plot(x,true_predictions[window_size:])
plt.show()
完整代码解读:
import torch
import torch.nn as nnfrom sklearn.preprocessing import MinMaxScaler
import time
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltfrom pandas.plotting import register_matplotlib_converters
register_matplotlib_converters()# 导入酒精销售数据
df = pd.read_csv('data\Alcohol_Sales.csv',index_col=0,parse_dates=True)
len(df)df.head() # 观察数据集,这是一个单变量时间序列plt.figure(figsize=(12,4))
plt.grid(True)
plt.plot(df['S4248SM144NCEN'])
plt.show()y = df['S4248SM144NCEN'].values.astype(float)# print(len(y)) #325条数据test_size = 12# 划分训练和测试集,最后12个值作为测试集
train_set = y[:-test_size] #323条数据
test_set = y[-test_size:] #12条数据# print(train_set.shape) #(313,) 一位数组# 归一化至[-1,1]区间,为了获得更好的训练效果
scaler = MinMaxScaler(feature_range=(-1, 1))
#scaler.fit_transform输入必须是二维的,但是train_set却是一个一维,所有实验reshape(-1,1)
train_norm = scaler.fit_transform(train_set.reshape(-1, 1)) #np.reshape(-1, 1) 列=1,行未知# print(train_norm.shape) #(313, 1) 这里将一维数据转化为二维# 转换成 tensor
train_norm = torch.FloatTensor(train_norm).view(-1)
print(train_norm.shape) #torch.Size([313])# 定义时间窗口,注意和前面的test size不是一个概念
window_size = 12# 这个函数的目的是为了从原时间序列中抽取出训练样本,也就是用第一个值到第十二个值作为X输入,预测第十三个值作为y输出,这是一个用于训练的数据点,时间窗口向后滑动以此类推
def input_data(seq,ws): out = []L = len(seq)for i in range(L-ws):window = seq[i:i+ws]label = seq[i+ws:i+ws+1]out.append((window,label)) #将x和y以tensor格式放入到out列表当中, return outtrain_data = input_data(train_norm,window_size)
len(train_data) # 等于325(原始数据集长度)-12(测试集长度)-12(时间窗口)class LSTMnetwork(nn.Module):def __init__(self,input_size=1,hidden_size=100,output_size=1):super().__init__()self.hidden_size = hidden_size# 定义LSTM层self.lstm = nn.LSTM(input_size,hidden_size)# 定义全连接层self.linear = nn.Linear(hidden_size,output_size)# 初始化h0,c0self.hidden = (torch.zeros(1,1,self.hidden_size),torch.zeros(1,1,self.hidden_size))def forward(self,seq):# 前向传播的过程是输入->LSTM层->全连接层->输出# https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html?highlight=lstm#torch.nn.LSTM# 在观察查看LSTM输入的维度,LSTM的第一个输入input_size维度是(L, N, H_in), L是序列长度,N是batch size,H_in是输入尺寸,也就是变量个数# LSTM的第二个输入是一个元组,包含了h0,c0两个元素,这两个元素的维度都是(D∗num_layers,N,H_out),D=1表示单向网络,num_layers表示多少个LSTM层叠加,N是batch size,H_out表示隐层神经元个数'''pytorch中LSTM输入为[time_step,batch,feature],这里窗口time_step=12,feature=1[1维数据],batch我们这里设置为1所以使用seq.view(len(seq),1,-1)将tensor[12]数据转化为tensor[12,1,1]'''lstm_out, self.hidden = self.lstm(seq.view(len(seq),1,-1), self.hidden) # print(lstm_out) #torch.Size([12, 1, 100]) [time_step,batch,hidden] # print(lstm_out.view(len(seq),-1)) #[12,100]pred = self.linear(lstm_out.view(len(seq),-1)) # print(pred) #torch.Size([12, 1])return pred[-1] # 输出只用取最后一个值torch.manual_seed(101)
model = LSTMnetwork()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)epochs = 100
start_time = time.time()
for epoch in range(epochs):for seq, y_train in train_data:# 每次更新参数前都梯度归零和初始化optimizer.zero_grad()model.hidden = (torch.zeros(1,1,model.hidden_size),torch.zeros(1,1,model.hidden_size))y_pred = model(seq)loss = criterion(y_pred, y_train)loss.backward()optimizer.step()print(f'Epoch: {epoch+1:2} Loss: {loss.item():10.8f}')print(f'\nDuration: {time.time() - start_time:.0f} seconds')future = 12# 选取序列最后12个值开始预测
preds = train_norm[-window_size:].tolist()# 设置成eval模式
model.eval()
# 循环的每一步表示向时间序列向后滑动一格
for i in range(future):seq = torch.FloatTensor(preds[-window_size:]) #第下一次循环的时候,seq总是能取到后12个数据,因此及时后面用pred.append()也还是每次用到最新的预测数据完成下一次的预测。with torch.no_grad():model.hidden = (torch.zeros(1,1,model.hidden_size),torch.zeros(1,1,model.hidden_size))"""item理解:取出张量具体位置的元素元素值,并且返回的是该位置元素值的高精度值,保持原元素类型不变;必须指定位置即:原张量元素为整形,则返回整形,原张量元素为浮点型则返回浮点型,etc."""# print(model(seq),model(seq).item()) #tensor([0.1027]), tensor([0.1026])preds.append(model(seq).item()) #每循环一次,这里会将新的预测值添加到pred中,# 逆归一化还原真实值
true_predictions = scaler.inverse_transform(np.array(preds[window_size:]).reshape(-1, 1))# 对比真实值和预测值
plt.figure(figsize=(12,4))
plt.grid(True)
plt.plot(df['S4248SM144NCEN'])
x = np.arange('2018-02-01', '2019-02-01', dtype='datetime64[M]').astype('datetime64[D]')plt.plot(x,true_predictions)
plt.show()# 放大看
fig = plt.figure(figsize=(12,4))
plt.grid(True)
fig.autofmt_xdate()plt.plot(df['S4248SM144NCEN']['2017-01-01':])
plt.plot(x,true_predictions)
plt.show()# 重新开始训练
epochs = 100
# 切回到训练模式
model.train()
y_norm = scaler.fit_transform(y.reshape(-1, 1))
y_norm = torch.FloatTensor(y_norm).view(-1)
all_data = input_data(y_norm,window_size)start_time = time.time()for epoch in range(epochs):for seq, y_train in all_data: optimizer.zero_grad()model.hidden = (torch.zeros(1,1,model.hidden_size),torch.zeros(1,1,model.hidden_size))y_pred = model(seq)loss = criterion(y_pred, y_train)loss.backward()optimizer.step()print(f'Epoch: {epoch+1:2} Loss: {loss.item():10.8f}')print(f'\nDuration: {time.time() - start_time:.0f} seconds')# 重新预测
window_size = 12
future = 12
L = len(y)preds = y_norm[-window_size:].tolist()model.eval()
for i in range(future): seq = torch.FloatTensor(preds[-window_size:])with torch.no_grad():model.hidden = (torch.zeros(1,1,model.hidden_size),torch.zeros(1,1,model.hidden_size)) preds.append(model(seq).item())true_predictions = scaler.inverse_transform(np.array(preds).reshape(-1, 1))x = np.arange('2019-02-01', '2020-02-01', dtype='datetime64[M]').astype('datetime64[D]')plt.figure(figsize=(12,4))
plt.grid(True)
plt.plot(df['S4248SM144NCEN'])
plt.plot(x,true_predictions[window_size:])
plt.show()代码说明:代码中包含了训练、测试和预测。但没有对该模型进行评估。
相关文章:
基于Pytorch框架的LSTM算法(一)——单维度单步滚动预测(2)
#项目说明: 说明:1time_steps滚动预测代码 y_norm scaler.fit_transform(y.reshape(-1, 1)) y_norm torch.FloatTensor(y_norm).view(-1)# 重新预测 window_size 12 future 12 L len(y)首先对模型进行训练; 然后选择所有数据的后wind…...
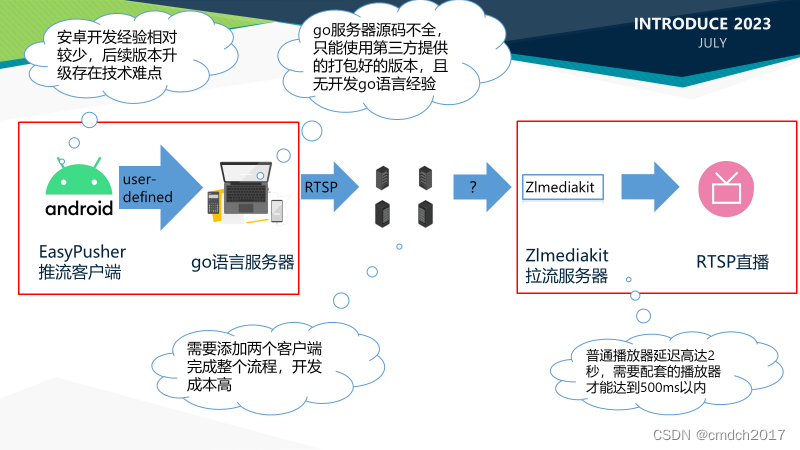
安全操作(安卓推流)程序
★ 安全操作项目 项目描述:安全操作项目旨在提高医疗设备的安全性,特别是在医生离开操作屏幕时,以减少非授权人员的误操作风险。为实现这一目标,我们采用多层次的保护措施,包括人脸识别、姿势检测以及二维码识别等技术…...
【STM32】Systick定时器
一、STM32的5种定时器简介 1.独立看门狗(IWDG) VS 窗口看门狗(WWDG) 1.独立看门狗(IWDG) 独立看门狗:当没有到设定时间之前,给它喂了狗,就会回到初始值。 2.窗口看门狗…...

ZooKeeper监控
ZooKeeper Monitor Guide Zookeeper集群进行监控,发现的方案有三种: JMXzookeeper exporterZK Monitor(Since 3.6.0)采用JMX 进行监控,可获取到的指标项不够丰富。Zookeeper Exporter监控可获得的指标项亦不太够丰富。从3.6.0之后,Zookeeper自带的Monitor结合Prometheus、…...

lua # 获取table数组长度
目录 实测结果展示 情况分类 数组开始索引与数组长度 数组元素中间有nil 数组最后的元素为nil...
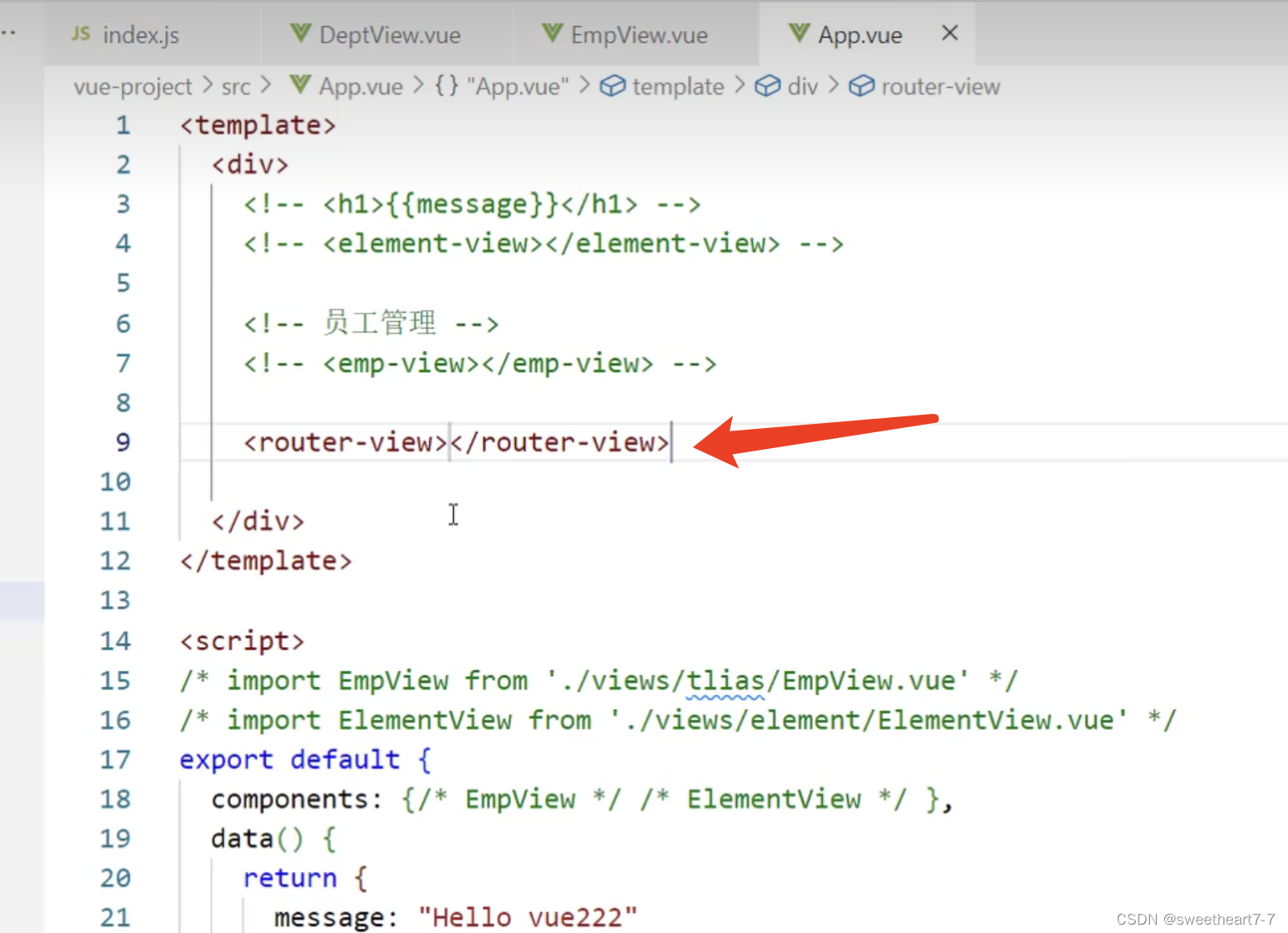
前端框架Vue学习 ——(七)Vue路由(Vue Router)
文章目录 Vue路由使用场景Vue Router 介绍Vue Router 使用 Vue路由使用场景 使用场景:如下图,点击部门管理的时候显示部门管理的组件,员工管理的时候显示员工管理的组件。 前端路由:指的是 URL 中的 hash(#号)与组件之间的对应关…...
2023-2024-1高级语言程序设计-一维数组
7-1 逆序输出数组元素的值 从键盘输入n个整数存入一维数组中,然后将数组元素的值逆序输出。 输入格式: 第一行输入整数个数n; 第二行输入n 个整数,数据之间以空格隔开。 输出格式: 逆序输出数组元素的值,每个数据之后跟一个空…...
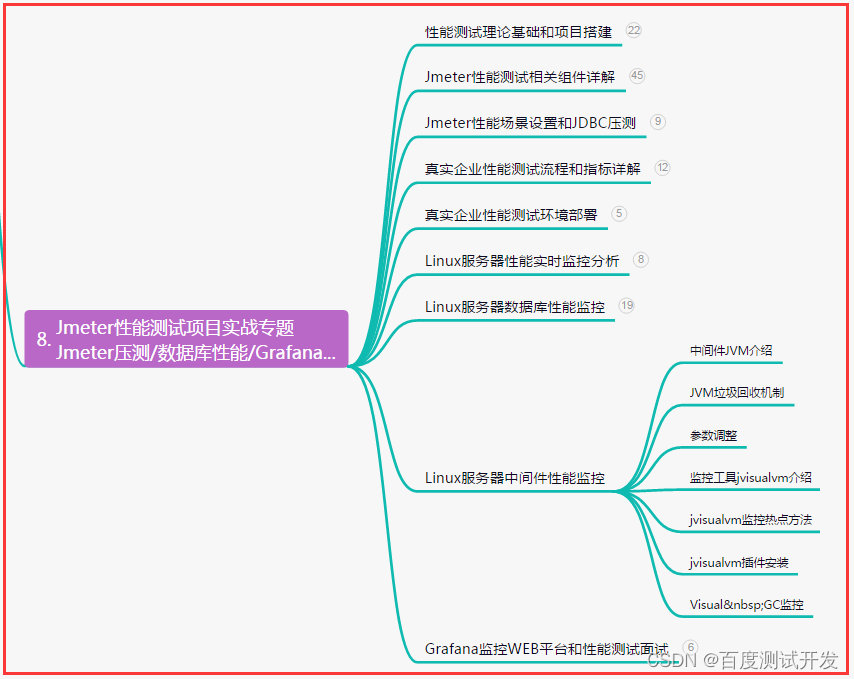
史上最全,从初级测试到高级测试开发面试题汇总,冲击大厂年50w+
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 接口测试面试相关…...

Python基础入门例程42-NP42 公式计算器(运算符)
最近的博文: Python基础入门例程41-NP41 二进制位运算(运算符)-CSDN博客 Python基础入门例程40-NP40 俱乐部的成员(运算符)-CSDN博客 Python基础入门例程39-NP39 字符串之间的比较(运算符)-C…...

C#的LINQ to XML 类中使用最多的三个类:XElement、XAttribute 和 XDocument
目录 一、XElement 类 1.使用 XElement 类创建一个 xml 文档 (1)示例源码 (2)xml文件 2.使用LINQ to SQL或者LINQ to Object获取数据源 (1)示例源码 (2)xml文件 3.XElement …...

2023软考-系统架构师一日游
上周六(11月4号)参见了软考,报的系统架构师,今年下半年是第一次推行机考,简单来分享下大致流程,至于考试难度、考点什么的,这个网上有很多专门研究这些的机构,本人无权发言。考试的经…...

维乐 Prevail Glide带你做破风王者,无阻前行!
对于自行车骑手来说,需要应对的问题有很多,其中最大的问题之一,就是「风阻」。风阻永远都是你越反抗越强,因此为了克服风阻的力量,时间久了,身体自然会造成一定程度的损伤。如何才能调整前行的步伐…...

企业通配符SSL证书的特点
企业通配符SSL证书是一种数字证书,其可以用于保护多个企业网站,对网站传输信息进行加密服务。这种证书通常适用于拥有多个子域名或二级域名的企事业单位。今天就随SSL盾小编了解企业通配符SSL证书的相关信息。 1. 保护所有域名和子域名:企业通…...

1.2 HTML5
一.HTML5 简介 1.什么是HTML5 HTML5是新一代的 HTML 标准,2014年10月由万维网联盟( W3C)完成标准制定。官网地址: w3c提供:HTML StandardWHATWG提供: HTML Standard HTML5在狭义上是指新—代的 HTML 标准,在广义上是指:整个前端。 2.HTML…...

一个例子!教您彻底理解索引的最左匹配原则!
最左匹配原则的定义 简单来讲:在联合索引中,只有左边的字段被用到,右边的才能够被使用到。我们在建联合索引的时候,区分度最高的在最左边。 简单的例子 创建一个表 CREATE TABLE user ( id INT NOT NULL AUTO_INCREMENT, code…...

Docker容器技术实战4
11、docker安全 proc未被隔离,所以在容器内和宿主机上看到的东西是一样的 容器资源控制 cpu资源限制 top命令,查看cpu使用率 ctrlpq防止退出回收,容器会直接调用cgroup,自动创建容器id的目录 cpu优先级设定 测试时只保留一个cpu…...

vue3中使用better-scroll
文章目录 需求分析安装htmlcssjs 需求分析 假设现在有这么一个需求,页面顶部有几个tabs导航,每一个tab下都有一个可以滑动的切换按钮。咱们就可以引入better-scroll来实现这个需求。 安装 首先下载better-scroll npm install better-scroll/core --…...

RK3568禁用调试口改成普通口
RK3568共10个串口,需要用到8个串口,无耐其他UART都被外设复用了,只好将调试口也拿出来作为普通口,方法:禁用调试口、增加UART2 1. vi kernel/arch/arm64/boot/dts/rockchip/OK3568-C-linux.dts 2. #include &quo…...

腾讯云CVM服务器标准型S5、SA3、S6详细介绍
腾讯云CVM服务器标准型实例的各项性能参数平衡,标准型云服务器适用于大多数常规业务,例如:web网站及中间件等,常见的标准型云服务器有CVM标准型S5、S6、SA3、SR1、S5se等规格,腾讯云服务器网txyfwq.com来详细说下云服务…...
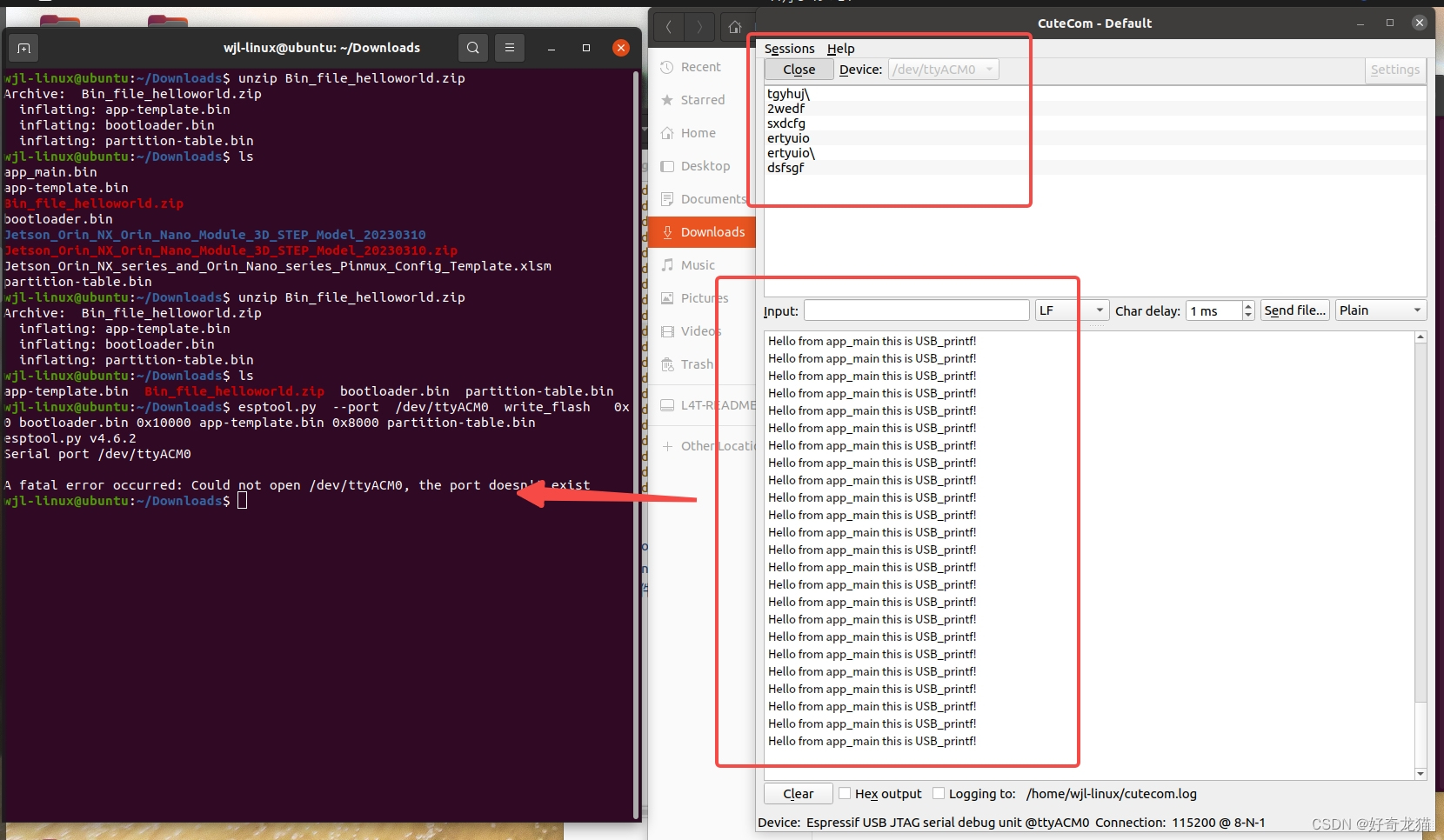
【PC电脑windows环境下-[jetson-orin-NX]Linux环境下-下载工具esptool工具使用-相关细节-简单样例-实际操作】
【PC电脑windows环境下-[jetson-orin-NX]Linux环境下-下载工具esptool工具使用-相关细节-简单样例-实际操作】 1、概述2、实验环境3、 物品说明4-2、自我总结5、本次实验说明1、准备样例2、设置芯片3、编译4、下载5、验证 (1)windows环境下进行烧写1、下…...

FCEUX终极指南:从怀旧游戏到专业调试的完整NES模拟器教程
FCEUX终极指南:从怀旧游戏到专业调试的完整NES模拟器教程 【免费下载链接】fceux FCEUX, a NES Emulator 项目地址: https://gitcode.com/gh_mirrors/fc/fceux FCEUX是一款功能强大的开源NES模拟器,让你在现代电脑上完美重温经典红白机游戏。无论…...

MCP Server生产级配置:Playwright与LLM集成的避坑指南
1. 这不是又一个“Playwright入门教程”,而是一份能直接塞进CI流水线的MCP Server生产级配置实录你有没有遇到过这样的场景:团队刚决定用AI驱动自动化测试,技术选型会上大家一致看好Playwright MCP(Model Context Protocol&#…...

30岁裸辞后,我用两个月拿下AI应用认证,现在OFFER选择困难症犯了
30岁裸辞那天,我最怕的不是没收入,而是突然发现:过去积累的经验,正在被AI重新定价。以前会写方案、做表格、跟项目,算是职场硬通货;到了2026年,招聘JD里开始频繁出现AI工具应用、智能工作流、Pr…...

亚马逊卖家公开信息数据提取:反爬攻防战与 Python 批量采集实战
摘要: 批量获取亚马逊(Amazon)第三方卖家的商业名称、信用代码和注册地址等信息,对于跨境 B2B 拓客和供应链分析具有重要意义。然而,亚马逊的 Cloudflare 盾和 Robot 验证码构成了极高的反爬门槛。本文将深度解析亚马逊…...

告别拍脑袋规划!用ArcGIS做绿道选线:如何科学量化坡度、水域、道路成本并加权计算
科学规划绿道的ArcGIS高阶技法:从成本栅格构建到最优路径生成绿道规划从来不是简单的"两点之间直线最短",而是需要综合考虑地形、生态、人文等多维因素的复杂决策过程。传统规划中常见的"拍脑袋"决策方式,往往导致建成后…...

基于MaixCam的延时摄影系统:从硬件选型到Python编程全解析
1. 项目概述:用MaixCam打造你的专属延时摄影工坊延时摄影,这个听起来有点专业、甚至带点“魔法”色彩的词,其实离我们并不遥远。想想看,把一朵花从含苞到绽放的几天时间,压缩成十几秒的惊艳绽放;或者把一座…...

打不开JupyterLab
因为安装某些依赖导致JupyterLab的依赖被动升级或降级,从而影响了JupyterLab的运行,此时可以SSH登录到实例,然后输入jupyter-lab命令进行确认,如果执行命令报错则说明是此问题,那么可以通过pip install jupyterlab再次…...

双稳健机器学习:用正交性与交叉拟合解决因果推断中的ML偏差
1. 项目概述:当机器学习遇见因果推断的“干扰”难题在实证研究的日常工作中,我们常常面临一个核心矛盾:我们真正关心的,往往只是一个或几个关键参数——比如一项政策对就业率的平均影响(平均处理效应,ATE&a…...

Adobe-GenP 3.0:轻松激活Adobe全家桶的完整指南
Adobe-GenP 3.0:轻松激活Adobe全家桶的完整指南 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP 3.0是一款专为Adobe Creative Cloud系列软件…...

利用 Taotoken 多模型能力为智能客服场景提供备份路由
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用 Taotoken 多模型能力为智能客服场景提供备份路由 智能客服系统是许多企业与用户交互的关键入口,其响应能力和服务…...