Apache Flink 1.12.0 on Yarn(3.1.1) 所遇到的問題
Apache Flink 1.12.0 on Yarn(3.1.1) 所遇到的問題
新搭建的FLINK集群出现的问题汇总
1.新搭建的Flink集群和Hadoop集群无法正常启动Flink任务

查看这个提交任务的日志无法发现有用的错误信息。
进一步查看yarn日志:

发现只有JobManager的错误日志出现了如下的错误:/bin/bash: /bin/java: No such file or directory。
正常情况下执行配置完成java之后,执行/bin/java的会出现如下的结果:

根据查到的提示,出现这个情况(/bin/bash: /bin/java: No such file or directory)的原因是软连接的问题。因此需要在每个节点都创建软连接:ls -s /usr/java/jdk1.8.0_221 /bin/java
每个节点创建完软连接之后,再次执行:/bin/java结果如下:

每个节点的软连接已生效,再次提交任务成功。
概要
根據官方文檔配置在 $FLINK_HOME/lib 加入 flink-shaded-hadoop-3-uber-3.1.1.7.1.1.0-565-9.0.jar ,經過驗證,其實這個可以不加,只加上下面的 hadoop classpath 就行。
或者在環境變量配置文件中 加入 hadoop classpath.
## 注意:lib 後面一定要加 *export Hadoop_CLASSPATH=$Hadoop_CLASSPATH:$HADOOP_HOME/lib/*export HADOOP_CLASSPATH=`hadoop classpath`
问题1
启动 yarn-session.sh 出現 Exit code: 127 Stack trace: ExitCodeException exitCode=127,具體的錯誤日誌如下:
2023-11-01 14:26:44,408 ERROR org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Error while running the Flink session.org.apache.flink.client.deployment.ClusterDeploymentException: Couldn't deploy Yarn session clusterat org.apache.flink.yarn.YarnClusterDescriptor.deploySessionCluster(YarnClusterDescriptor.java:411) ~[flink-dist_2.11-1.12.0.jar:1.12.0]at org.apache.flink.yarn.cli.FlinkYarnSessionCli.run(FlinkYarnSessionCli.java:498) ~[flink-dist_2.11-1.12.0.jar:1.12.0]at org.apache.flink.yarn.cli.FlinkYarnSessionCli.lambda$main$4(FlinkYarnSessionCli.java:730) ~[flink-dist_2.11-1.12.0.jar:1.12.0]at java.security.AccessController.doPrivileged(Native Method) ~[?:1.8.0_221]at javax.security.auth.Subject.doAs(Subject.java:422) ~[?:1.8.0_221]at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729) ~[hadoop-common-3.1.1.jar:?]at org.apache.flink.runtime.security.contexts.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41) ~[flink-dist_2.11-1.12.0.jar:1.12.0]at org.apache.flink.yarn.cli.FlinkYarnSessionCli.main(FlinkYarnSessionCli.java:730) [flink-dist_2.11-1.12.0.jar:1.12.0]Caused by: org.apache.flink.yarn.YarnClusterDescriptor$YarnDeploymentException: The YARN application unexpectedly switched to state FAILED during deployment.Diagnostics from YARN: Application application_1617189748122_0017 failed 1 times (global limit =2; local limit is =1) due to AM Container for appattempt_1617189748122_0017_000001 exited with exitCode: 127Failing this attempt.Diagnostics: [2023-11-01 14:26:44.107]Exception from container-launch.Container id: container_1617189748122_0017_01_000001Exit code: 127[2023-11-01 14:26:44.108]Container exited with a non-zero exit code 127. Error file: prelaunch.err.Last 4096 bytes of prelaunch.err :[2023-11-01 14:26:44.109]Container exited with a non-zero exit code 127. Error file: prelaunch.err.Last 4096 bytes of prelaunch.err :For more detailed output, check the application tracking page: http://hadoop001:8088/cluster/app/application_1617189748122_0017 Then click on links to logs of each attempt.. Failing the application.If log aggregation is enabled on your cluster, use this command to further investigate the issue:yarn logs -applicationId application_1617189748122_0017at org.apache.flink.yarn.YarnClusterDescriptor.startAppMaster(YarnClusterDescriptor.java:1078) ~[flink-dist_2.11-1.12.0.jar:1.12.0]at org.apache.flink.yarn.YarnClusterDescriptor.deployInternal(YarnClusterDescriptor.java:558) ~[flink-dist_2.11-1.12.0.jar:1.12.0]at org.apache.flink.yarn.YarnClusterDescriptor.deploySessionCluster(YarnClusterDescriptor.java:404) ~[flink-dist_2.11-1.12.0.jar:1.12.0]... 7 more------------------------------------------------------------The program finished with the following exception:org.apache.flink.client.deployment.ClusterDeploymentException: Couldn't deploy Yarn session clusterat org.apache.flink.yarn.YarnClusterDescriptor.deploySessionCluster(YarnClusterDescriptor.java:411)at org.apache.flink.yarn.cli.FlinkYarnSessionCli.run(FlinkYarnSessionCli.java:498)at org.apache.flink.yarn.cli.FlinkYarnSessionCli.lambda$main$4(FlinkYarnSessionCli.java:730)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:422)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)at org.apache.flink.runtime.security.contexts.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41)at org.apache.flink.yarn.cli.FlinkYarnSessionCli.main(FlinkYarnSessionCli.java:730)Caused by: org.apache.flink.yarn.YarnClusterDescriptor$YarnDeploymentException: The YARN application unexpectedly switched to state FAILED during deployment.Diagnostics from YARN: Application application_1617189748122_0017 failed 1 times (global limit =2; local limit is =1) due to AM Container for appattempt_1617189748122_0017_000001 exited with exitCode: 127Failing this attempt.Diagnostics: [2023-11-01 14:26:44.107]Exception from container-launch.Container id: container_1617189748122_0017_01_000001Exit code: 127[2023-11-01 14:26:44.108]Container exited with a non-zero exit code 127. Error file: prelaunch.err.Last 4096 bytes of prelaunch.err :[2023-11-01 14:26:44.109]Container exited with a non-zero exit code 127. Error file: prelaunch.err.Last 4096 bytes of prelaunch.err :For more detailed output, check the application tracking page: http://hadoop001:8088/cluster/app/application_1617189748122_0017 Then click on links to logs of each attempt.. Failing the application.If log aggregation is enabled on your cluster, use this command to further investigate the issue:yarn logs -applicationId application_1617189748122_0017at org.apache.flink.yarn.YarnClusterDescriptor.startAppMaster(YarnClusterDescriptor.java:1078)at org.apache.flink.yarn.YarnClusterDescriptor.deployInternal(YarnClusterDescriptor.java:558)at org.apache.flink.yarn.YarnClusterDescriptor.deploySessionCluster(YarnClusterDescriptor.java:404)... 7 more2023-11-01 14:26:44,415 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cancelling deployment from Deployment Failure Hook2023-11-01 14:26:44,416 INFO org.apache.hadoop.yarn.client.RMProxy [] - Connecting to ResourceManager at hadoop001/192.168.100.100:80322023-11-01 14:26:44,418 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Killing YARN application2023-11-01 14:26:44,429 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Killed application application_1617189748122_00172023-11-01 14:26:44,532 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deleting files in hdfs://hadoop001:8020/user/hadoop/.flink/application_1617189748122_0017.
然後下載具體的 container 日誌:
yarn logs -applicationId application_1617189748122_0017 -containerId container_1617189748122_0017_01_000001 -out /tmp/
查看 container 日誌
LogAggregationType: AGGREGATED====================================================================LogType:jobmanager.errLogLastModifiedTime:Thu Apr 01 14:26:45 +0800 2021LogLength:48LogContents:/bin/bash: /bin/java: No such file or directoryEnd of LogType:jobmanager.err*******************************************************************************End of LogType:jobmanager.out*******************************************************************************Container: container_1617189748122_0017_01_000001 on hadoop001_53613LogAggregationType: AGGREGATED====================================================================
注意日誌中的,找不到 /bin/bash: /bin/java: No such file or directory
[hadoop@hadoop001 bin]$ echo $JAVA_HOME/usr/java/jdk1.8.0_221
然後做一個軟連接
ls -s /usr/java/jdk1.8.0_221 /bin/java
问题2
啟動 yarn-session.sh 出現 Container exited with a non-zero exit code 126,具體的錯誤日誌如下:
org.apache.flink.client.deployment.ClusterDeploymentException: Couldn't deploy Yarn session clusterat org.apache.flink.yarn.YarnClusterDescriptor.deploySessionCluster(YarnClusterDescriptor.java:411)at org.apache.flink.yarn.cli.FlinkYarnSessionCli.run(FlinkYarnSessionCli.java:498)at org.apache.flink.yarn.cli.FlinkYarnSessionCli.lambda$main$4(FlinkYarnSessionCli.java:730)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:422)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1729)at org.apache.flink.runtime.security.contexts.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41)at org.apache.flink.yarn.cli.FlinkYarnSessionCli.main(FlinkYarnSessionCli.java:730)Caused by: org.apache.flink.yarn.YarnClusterDescriptor$YarnDeploymentException: The YARN application unexpectedly switched to state FAILED during deployment.Diagnostics from YARN: Application application_1617189748122_0019 failed 1 times (global limit =2; local limit is =1) due to AM Container for appattempt_1617189748122_0019_000001 exited with exitCode: 126Failing this attempt.Diagnostics: [2023-11-01 14:43:23.068]Exception from container-launch.Container id: container_1617189748122_0019_01_000001Exit code: 126[2023-11-01 14:43:23.070]Container exited with a non-zero exit code 126. Error file: prelaunch.err.Last 4096 bytes of prelaunch.err :[2023-11-01 14:43:23.072]Container exited with a non-zero exit code 126. Error file: prelaunch.err.Last 4096 bytes of prelaunch.err :
查看 container 的日誌情況:
[hadoop@hadoop001 flink-1.12.0]$ yarn logs -applicationId application_1617189748122_0019 -show_application_log_info2023-11-01 15:09:07,880 INFO client.RMProxy: Connecting to ResourceManager at hadoop001/192.168.100.100:8032Application State: Completed.Container: container_1617189748122_0019_01_000001 on hadoop001_53613
下載 container 日誌,操作和上面問題 1 一樣。
查看報錯日誌
broken symlinks(find -L . -maxdepth 5 -type l -ls):End of LogType:directory.info*******************************************************************************Container: container_1617189748122_0019_01_000001 on hadoop001_53613LogAggregationType: AGGREGATED====================================================================LogType:jobmanager.errLogLastModifiedTime:Thu Apr 01 14:43:24 +0800 2021LogLength:37LogContents:/bin/bash: /bin/java: Is a directoryEnd of LogType:jobmanager.err*******************************************************************************
注意:/bin/bash: /bin/java: Is a directory ,這個是關鍵日誌,經過排查發現是軟連接出現了錯誤。
[root@hadoop001 bin]# ln -s /usr/java/jdk1.8.0_221/bin/java /bin/java[root@hadoop001 bin]#[root@hadoop001 bin]#[root@hadoop001 bin]# ll /bin/javalrwxrwxrwx 1 root root 31 Apr 1 16:09 /bin/java -> /usr/java/jdk1.8.0_221/bin/java[root@hadoop001 bin]#[root@hadoop001 bin]# /bin/java -versionjava version "1.8.0_221"Java(TM) SE Runtime Environment (build 1.8.0_221-b11)Java HotSpot(TM) 64-Bit Server VM (build 25.221-b11, mixed mode)
验证
啟動 …/bin/yarn-session.sh
如何查看正在运行的Yarn容器的日志??
众所周知,flink on yarn 分为jobmanager的容器和taskmanager的容器。1.yarn application -list2.yarn applicationattempt -list <ApplicationId>3.yarn container -list <Application AttemptId>
到了这个第3步,就能看到每个容器的访问的url ,分别对应着jobmanager的和taskmanager的,但是具体怎么区分是哪个taskmanager的就只能依靠ip去区分。 htpp就用 curl 进行访问,https就用curl -k进行访问。4.访问的结果包含了6种不同类型日志的访问路径:找到我们想看的日志的访问路径,然后访问,访问路径的最后的参数:-start=-4096代表了显示多少日志出来。如果想查看完整的日志,就应该把这个数调的很大5.为了查看方便,应该使用 > 的方式把访问url的日志的结果输出到日志文件中。
FLINK ON YARN提交方式详解
目前自己用到的:yarn-per-job和yarn-applicaiton他们的执行方式是不同的,执行yarn-per-job需要执行flink文件。同样的yarn-application也需要执行flik文件。./flink run -t yarn-per-job -d \
-p 1 \
-ynm test_env_job \
-yD rest.flamegraph.enabled=true \
-yD jobmanager.memory.process.size=1G \
-yD taskmanager.memory.process.size=2G \
-yD taskmanager.numberOfTaskSlots=1 \
-yD env.java.opts="-Denv=test" \
-c com.xingye.demo.TestTimer \
/cgroups_test/test/fk.jar./flink run-application -t yarn-application -d \
-p 5 \
-ynm test_impala_job \
-D rest.flamegraph.enabled=true \
-D jobmanager.memory.process.size=2G \
-D taskmanager.memory.process.size=8G \
-D taskmanager.numberOfTaskSlots=5 \
-c com.xingye.demo.ImpalaDemo1 \
/tmp/test_flink_impala/fk.jar通过两种命令的对比就发现区别:
flink run -t yarn-per-job
flink run-application -t yarn-application还有需要注意的是 -y* 这个参数是特有的使用yarn的时候就能使用的参数,也就是说yarn-per-job能用,yarn-application也能用。-yD和-D动态参数的意思,作用就是覆盖flink-conf.yaml文件中的默认配置。唯一不同的地方就在于-yD只能在使用yarn的时候指定动态参数,不能在其他模式使用比如kubernetes无法使用-yD参数。-D可以在不同的方式下指定动态参数,-D是一种更通用的指定动态参数的方式。总结:yarn-per-job和yarn-application运行的都是同一个文件,相同点在于都能使用yarn模式下特有的-y*的参数,并且都能使用-D动态参数。
相关文章:
Apache Flink 1.12.0 on Yarn(3.1.1) 所遇到的問題
Apache Flink 1.12.0 on Yarn(3.1.1) 所遇到的問題 新搭建的FLINK集群出现的问题汇总 1.新搭建的Flink集群和Hadoop集群无法正常启动Flink任务 查看这个提交任务的日志无法发现有用的错误信息。 进一步查看yarn日志: 发现只有JobManager的错误日志出现了如下的…...
pandas - 数据分组统计
1.分组统计groupby()函数 对数据进行分组统计,主要适用DataFrame对象的groupby()函数。其功能如下。 (1)根据特定条件,将数据拆分成组 (2)每个组都可以独立应用函数(如求和函数sum()࿰…...

Git简介和安装
一,Git简介 Git 是一个分布式版本控制工具,通常用来对软件开发过程中的源代码文件进行管理。通过Git 仓库来存储和管理这些文件,Git 仓库分为两种: 本地仓库:开发人员自己电脑上的 Git 仓库 远程仓库:远程…...

思维模型 布里丹毛驴效应
本系列文章 主要是 分享 思维模型,涉及各个领域,重在提升认知。犹豫不决是病,得治~ 1 布里丹毛驴效应的应用 1.1 犹豫不决的产品“施乐 914” 20 世纪 60 年代,美国一家名为施乐(Xerox)的公司…...
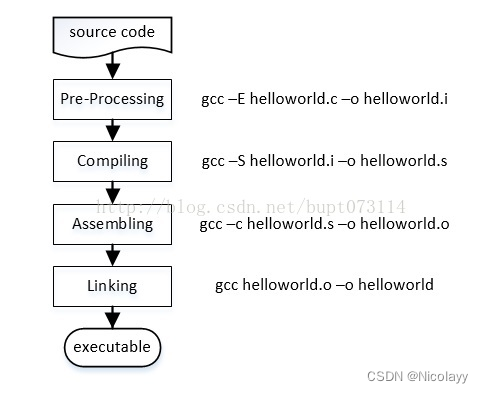
预处理、编译、汇编、链接
1.预处理 宏替换去注释引入头文件 #之后的语句都是预处理语句, #include<iostream> 将该文件的内容拷贝到现有文件中, 2.编译 3.汇编 4.链接 gcc 基于C/C的编译器 补充说明 gcc命令 使用GNU推出的基于C/C的编译器,是开放源代…...

面试问题?
1.面向对象的特征? 2.开放闭合 3.java中的泛型可以用基本类型吗? 4.重载和重写的区别? 5.string、stringbuffer、stringbuilder? 6.单例模式的实现方式有哪几种? 7.volicate除了保证 8.sy是重量级锁还是轻量级锁ÿ…...

pytorch 笔记:PAD_PACKED_SEQUENCE 和PACK_PADDED_SEQUENCE
1 PACK_PADDED_SEQUENCE 1.0 功能 将填充的序列打包成一个更加紧凑的形式这样RNN、LSTM和GRU等模型可以更高效地处理它们,因为它们可以跳过不必要的计算 1.2 基本使用方法 torch.nn.utils.rnn.pack_padded_sequence(input, lengths, batch_firstFalse, enforce_…...
Ubuntu 创建用户
在ubuntu系统中创建用户,是最基本的操作。与centos7相比,有较大不同。 我们通过案例介绍,讨论用户的创建。 我们知道,在linux中,有三类用户:超级管理员 root 具有完全权限;系统用户 bin sys a…...

华为政企路由器产品集
产品类型产品型号产品说明 maintainProductA821 E_2*10GE/GE/FE(o)8*GE/FE(o)8*GE/FE(e),1*交流电源华为企业云端NetEngine A800 E综合业务一体化接入路由器是华为公司面向云时代推出的一款产品,用于企业快速接入网络,具备易部署、易运维、高性能、高…...
性能测试知多少---了解前端性能
我的上一篇博文中讲到了响应时间,我们在做性能测试时,能过工具可以屏蔽客户端呈现时间,通过局域网的高宽带可以忽略数据传输速度的障碍。这并不是说他们不会对系统造成性能影响。相反,从用户的感受来看,虽然传输速度受…...

Docker-compose容器群集编排管理工具
目录 Docker-compose 1、Docker-compose 的三大概念 2、YAML文件格式及编写注意事项 1)使用 YAML 时需要注意下面事项 2)ymal文件格式 3)json格式 3、Docker Compose配置常用字段 4、Docker-compose的四种重启策略 5、Docker Compose…...

Python 深度学习导入的一些包的说明
Python 深度学习导入的一些包的说明 这段代码导入了一些Python库和模块,并定义了一些数据转换操作。 from future import print_function, division:这是一个Python 2和Python 3兼容性的导入语句。它确保在Python 2中使用Python 3的print函数和除法运算符…...

劲升逻辑与安必快、鹏海运于进博会签署合作协议,助力大湾区外贸高质量发展
新中经贸与投资论坛签约现场 中国上海,2023 年 11 月 6 日——第六届进博会期间,由新加坡工商联合总会主办的新中经贸与投资论坛在上海同期举行。跨境贸易数字化领域的领导者劲升逻辑与安必快科技(深圳)有限公司(简称…...
hivesql,sql 函数总结:
1、NVL函数与Coalesce差异 -- select nvl(null,8); -- 结果是 8 -- select nvl(,7); -- 结果是"" -- select coalesce(null,null,9); -- 结果是 9 -- select coalesce("",null,9); -- 结果是 "" 1.2、 NVL函数与Coalesce差异 …...

前端js实现井字游戏和版本号对比js逻辑【适用于vue和react】
// 实现 compareVersion 方法,用于比较两个版本号(version1、version2) * 如果version1 > version2,返回1; * 如果version1 < version2,返回-1; * 其他情况,返回0。 * 版本号规…...

unity 通过Andriod arr 访问 手机自带的浏览器
unity 通过Andriod arr 访问 手机自带的浏览器 using System.Collections; using System.Collections.Generic; using System.IO; using UnityEngine; using UnityEngine.UI;public class OpenURL : MonoBehaviour {public Button button;string url "http://192.168.1.…...

MySQL -- 索引
MySQL – 索引 文章目录 MySQL -- 索引一、索引简介1.简介2.索引效率的案例 二、认识磁盘1.磁盘2.结论3.磁盘随机访问(Random Access)与连续访问(Sequential Access) 三、MySQL 与磁盘交互基本单位1.基本单位2.MySQL中的数据管理 五、索引的理解1.索引案例2.单页mysql page3.管…...
)
23ccpc(最长上升子序列题解)
你原本有一个 1 到 n 的排列但是不慎地你遗忘了它但是你记得以 第i个位置 结尾的最长上升子序 列的长度数组 an 现在希望你能够构造一个符合条件的排列 p 如果不存在符合上述条件的排列 p 则输出 −1。 这里定义以 第i位置 结尾的最长上升子序列的长度为符合…...

BUUCTF easycap 1
BUUCTF:https://buuoj.cn/challenges 题目描述: 下载附件,解压得到一个.pcap文件。 密文: 解题思路: 1、这道题和它的名字一样,真的很easy。双击easycap.pcap文件,打开Wireshark。在Wireshark中…...
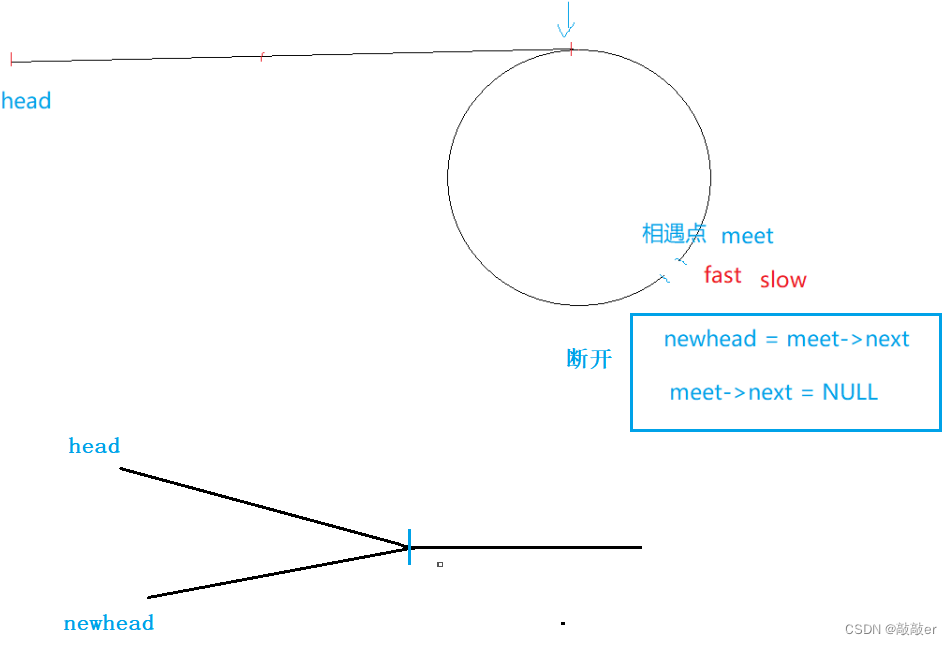
[LeetCode]-160. 相交链表-141. 环形链表-142.环形链表II-138.随机链表的复制
目录 160.相交链表 题目 思路 代码 141.环形链表 题目 思路 代码 142.环形链表II 题目 思路 代码 160.相交链表 160. 相交链表 - 力扣(LeetCode)https://leetcode.cn/problems/intersection-of-two-linked-lists/description/ 题目 给你两个…...

UE5 BaseEditorSettings.ini加载原理与配置生效机制
1. 为什么你改了BaseEditorSettings.ini却没生效?——从UE5编辑器启动流程讲起很多人在UE5项目里折腾半天,把BaseEditorSettings.ini文件翻来覆去改了十几遍,重启编辑器后发现:缩放比例还是不对、网格间距没变、甚至“启用实时预览…...

三十岁想从零转行现实吗?带你分辨真正有前景的好工作
我是29岁那年,完成从转行裸辞副业的职业转型。 如果你把职业生涯看成是从现在开始30岁,到你退休那年,中间这么漫长的30年,那么30岁转行完全来得及…...

ESP32多任务水位监测:从Arduino到ESP-IDF的FreeRTOS实战
1. 项目概述:从Arduino到ESP-IDF的跃迁去年我在做毕业设计时,为了搭建一个ESP32的传感器节点演示程序,第一次深入使用了FreeRTOS。那段时间,我几乎天天和任务调度、队列、信号量打交道,从最初的一头雾水到后来能流畅地…...

为什么软件开发偏爱 Linux?深度剖析 Linux 相较于 Windows 的核心优势
引言 在软件开发的世界里,一个有趣的现象是:无论是大型互联网公司的服务器集群,还是资深程序员的个人开发机,Linux 操作系统的身影无处不在。与之形成鲜明对比的是,尽管 Windows 在个人消费市场占据绝对主导地位&…...

打造XBEE封装BLE112蓝牙模块:硬件设计、射频布局与调试全攻略
1. 项目概述:为什么我们需要一个“XBEE格式”的蓝牙模块?在嵌入式开发和物联网项目中,无线通信模块的选择往往决定了项目的成败。对于很多工程师和创客来说,Silicon Labs(芯科科技)的BLE112/113模块是蓝牙4…...

yolo视频识别 车辆速度估计识别 yolo11视频实时速度测量与测速估计
文章目录YOLOv11:视频实时速度测量与测速估计一、YOLOv11概述二、速度测量原理三、距离测量方法四、应用场景五、实践案例以下是关于使用YOLOv11进行视频实时速度测量与测速估计的介绍: YOLOv11:视频实时速度测量与测速估计 随着计算机视觉…...

如何用WaveTools终极优化《鸣潮》游戏性能:从卡顿到丝滑的完整指南
如何用WaveTools终极优化《鸣潮》游戏性能:从卡顿到丝滑的完整指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 如果你正在玩《鸣潮》却频繁遭遇帧率波动、画面卡顿或操作延迟,那…...

统信UOS浏览器书签同步难题?一招搞定所有新用户默认书签配置
统信UOS浏览器书签批量配置:系统管理员的高效部署指南在企业或教育机构的IT运维工作中,统信UOS作为国产操作系统的代表,其浏览器书签的统一管理常常成为系统管理员面临的挑战。想象一下,每当有新员工入职或学生入学,都…...

基于Max78000与规则引导的音频数据集构建:边缘AI声音识别实战
1. 项目概述:当边缘AI遇见棕榈树里的“窃听者”在边缘计算和物联网设备大行其道的今天,我们常常面临一个核心矛盾:一方面,我们希望设备足够“聪明”,能实时识别并响应特定的声音模式,比如工厂里高压阀门的异…...

告别多头对接!DMXAPI 为企业打造国产大模型 “统一入口”
一、企业 AI 落地的普遍痛点:被接口和平台消耗的成本在企业数字化转型的浪潮中,AI 大模型已经成为标配,但很多企业在落地时,都会陷入一个共同的困境:为了满足不同业务场景的需求,需要同时对接 DeepSeek、阿…...