计算机毕设 基于大数据的服务器数据分析与可视化系统 -python 可视化 大数据
文章目录
- 0 前言
- 1 课题背景
- 2 实现效果
- 3 数据收集分析过程
- **总体框架图**
- **kafka 创建日志主题**
- **flume 收集日志写到 kafka**
- **python 读取 kafka 实时处理**
- **数据分析可视化**
- 4 Flask框架
- 5 最后
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 基于大数据的服务器数据分析与可视化系统
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:5分
- 创新点:3分
- 界面美化:5分
1 课题背景
基于python的nginx大数据日志分析可视化,通过流、批两种方式,分析 nginx 日志,将分析结果通过 flask + echarts 进行可视化展示
2 实现效果
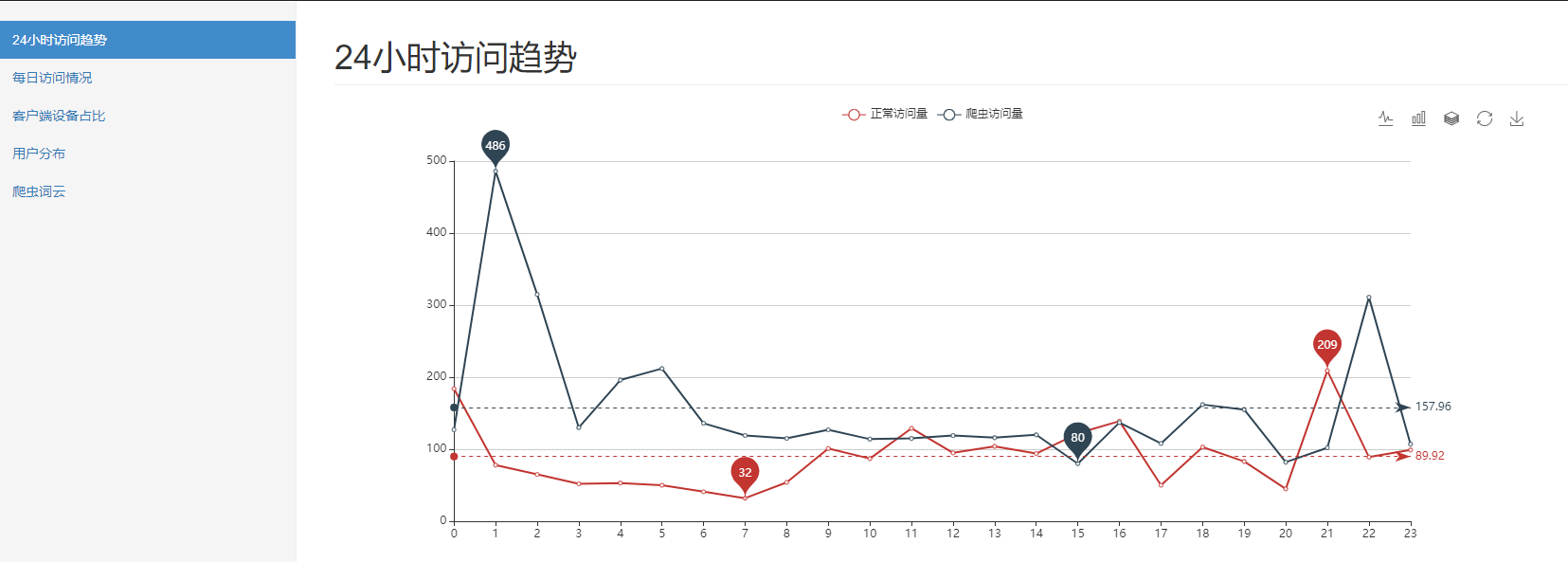
24 小时访问趋势
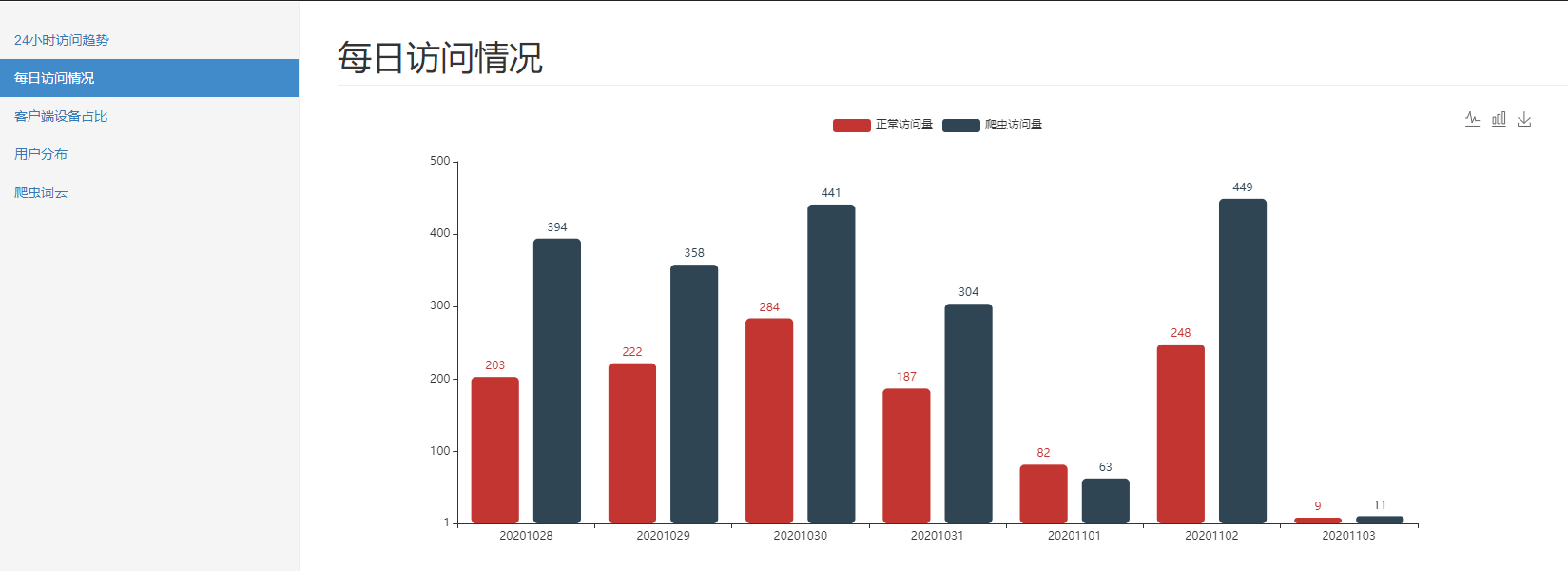
每日访问情况
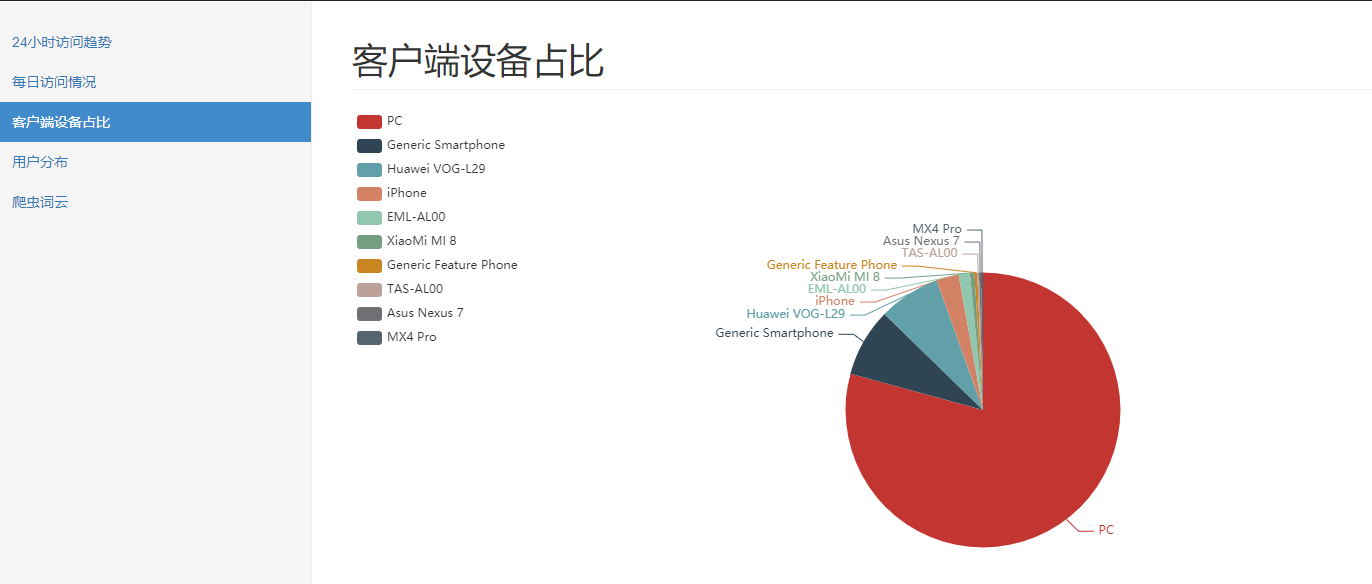
客户端设备占比
用户分布

爬虫词云

3 数据收集分析过程
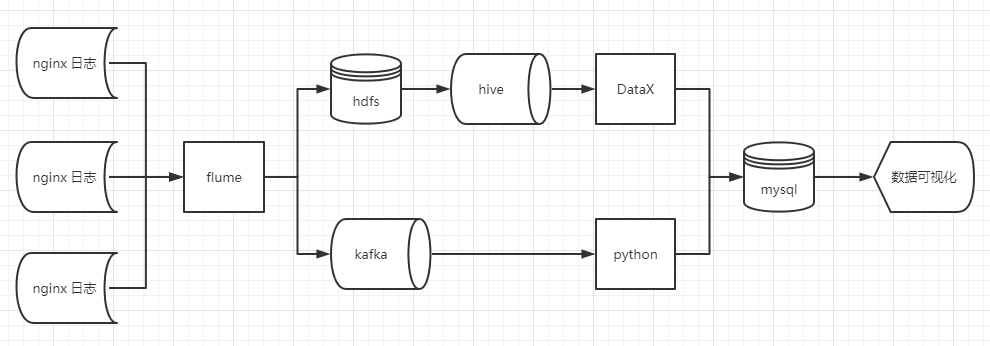
总体框架图
kafka 创建日志主题
# 创建主题
kafka-topics --bootstrap-server gfdatanode01:9092 --create --replication-factor 3 --partitions 1 --topic nginxlog
flume 收集日志写到 kafka
创建 flume 到 kafka 的配置文件 flume_kafka.conf,配置如下
a1.sources = s1
a1.channels = c1
a1.sinks = k1 a1.sources.s1.type=exec
a1.sources.s1.command=tail -f /var/log/nginx/access.log
a1.sources.s1.channels=c1 #设置Kafka接收器
a1.sinks.k1.type= org.apache.flume.sink.kafka.KafkaSink
#设置Kafka地址
a1.sinks.k1.brokerList=172.16.122.23:9092
#设置发送到Kafka上的主题
a1.sinks.k1.topic=nginxlog
#设置序列化方式
a1.sinks.k1.serializer.class=kafka.serializer.StringEncoder
a1.sinks.k1.channel=c1 a1.channels.c1.type=memory
a1.channels.c1.capacity=10000
a1.channels.c1.transactionCapacity=100
启动 flume
flume-ng agent -n a1 -f flume_kafka.conf
python 读取 kafka 实时处理
通过 python 实时处理 nginx 的每一条日志数据,然后写到 mysql 。
from kafka import KafkaConsumerservers = ['172.16.122.23:9092', ]
consumer = KafkaConsumer(bootstrap_servers=servers,auto_offset_reset='latest', # 重置偏移量 earliest移到最早的可用消息,latest最新的消息,默认为latest
)
consumer.subscribe(topics=['nginxlog'])
for msg in consumer:info = re.findall('(.*?) - (.*?) \[(.*?)\] "(.*?)" (\\d+) (\\d+) "(.*?)" "(.*?)" .*', msg.value.decode())log = NginxLog(*info[0])log.save()
数据分析可视化
-- 用户分布
select province, count(distinct remote_addr) from fact_nginx_log where device <> 'Spider' group by province;-- 不同时段访问情况
select case when device='Spider' then 'Spider' else 'Normal' end, hour(time_local), count(1)
from fact_nginx_log
group by case when device='Spider' then 'Spider' else 'Normal' end, hour(time_local);-- 最近7天访问情况
select case when device='Spider' then 'Spider' else 'Normal' end, DATE_FORMAT(time_local, '%Y%m%d'), count(1)
from fact_nginx_log
where time_local > date_add(CURRENT_DATE, interval - 7 day)
group by case when device='Spider' then 'Spider' else 'Normal' end, DATE_FORMAT(time_local, '%Y%m%d');-- 用户端前10的设备
select device, count(1)
from fact_nginx_log
where device not in ('Other', 'Spider') -- 过滤掉干扰数据
group by device
order by 2 desc
limit 10-- 搜索引擎爬虫情况
select browser, count(1) from fact_nginx_log where device = 'Spider' group by browser;
最后,通过 pandas 读取 mysql,经 ironman 进行可视化展示。
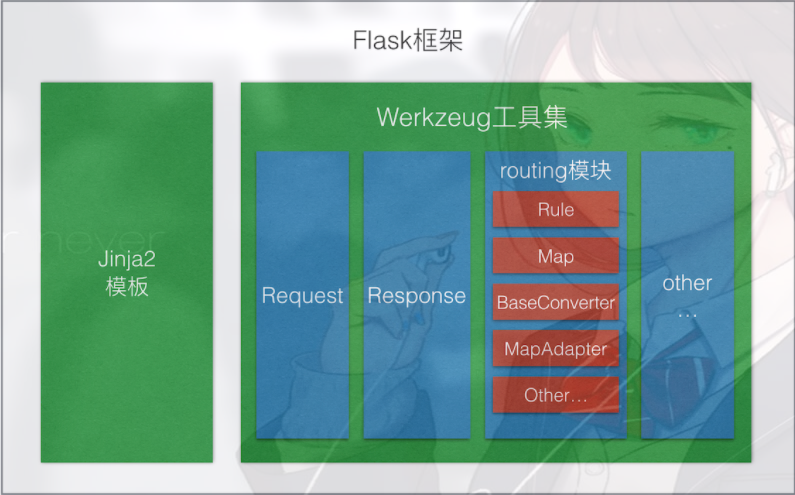
4 Flask框架
简介
Flask是一个基于Werkzeug和Jinja2的轻量级Web应用程序框架。与其他同类型框架相比,Flask的灵活性、轻便性和安全性更高,而且容易上手,它可以与MVC模式很好地结合进行开发。Flask也有强大的定制性,开发者可以依据实际需要增加相应的功能,在实现丰富的功能和扩展的同时能够保证核心功能的简单。Flask丰富的插件库能够让用户实现网站定制的个性化,从而开发出功能强大的网站。
本项目在Flask开发后端时,前端请求会遇到跨域的问题,解决该问题有修改数据类型为jsonp,采用GET方法,或者在Flask端加上响应头等方式,在此使用安装Flask-CORS库的方式解决跨域问题。此外需要安装请求库axios。
Flask框架图
相关代码
import os
import syssys.path.append(os.path.dirname(os.path.abspath(__file__)) + '/../')from flask import Flask, render_template
from ironman.data import SourceData
from ironman.data_db import SourceDataapp = Flask(__name__)source = SourceData()@app.route('/')
def index():return render_template('index.html')@app.route('/line')
def line():data = source.linexAxis = data.pop('legend')return render_template('line.html', title='24小时访问趋势', data=data, legend=list(data.keys()), xAxis=xAxis)@app.route('/bar')
def bar():data = source.barxAxis = data.pop('legend')return render_template('bar.html', title='每日访问情况', data=data, legend=list(data.keys()), xAxis=xAxis)@app.route('/pie')
def pie():data = source.piereturn render_template('pie.html', title='客户端设备占比', data=data, legend=[i.get('name') for i in data])@app.route('/china')
def china():data = source.chinareturn render_template('china.html', title='用户分布', data=data)@app.route('/wordcloud')
def wordcloud():data = source.wordcloudreturn render_template('wordcloud.html', title='爬虫词云', data=data)if __name__ == "__main__":app.run(host='127.0.0.1', debug=True)
5 最后
相关文章:
计算机毕设 基于大数据的服务器数据分析与可视化系统 -python 可视化 大数据
文章目录 0 前言1 课题背景2 实现效果3 数据收集分析过程**总体框架图****kafka 创建日志主题****flume 收集日志写到 kafka****python 读取 kafka 实时处理****数据分析可视化** 4 Flask框架5 最后 0 前言 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升&a…...
初识rust
调试下rust 的执行流程 参考: 认识 Cargo - Rust语言圣经(Rust Course) 新建一个hello world 程序: fn main() {println!("Hello, world!"); }用IDA 打开exe,并加载符号: 根据字符串找到主程序入口: 双击…...
shiro-cve2016-4437漏洞复现
一、漏洞特征 Apache Shiro是一款开源强大且易用的Java安全框架,提供身份验证、授权、密码学和会话管理。Shiro框架直观、易用,同时也能提供健壮的安全性。 因为在反序列化时,不会对其进行过滤,所以如果传入恶意代码将会造成安全问题 在 1.2.4 版本前, 加…...
【MongoDB-Redis-MySQL-Elasticsearch-Kibana-RabbitMQ-MinIO】Java全栈开发软件一网打尽
“Java全栈开发一网打尽:在Windows环境下探索技术世界的奇妙之旅” 前言 全栈开发是一项复杂而令人兴奋的任务,涵盖了从前端到后端、数据库到可视化层、消息队列到文件存储的广泛领域。本文将带您深入探讨在Windows环境下进行全栈开发的过程࿰…...

Implementing class错误解决
最近在使用IDEASmart Tomcat启动项目时,报以下错误: Injection of resource dependencies failed; nested exception is java.lang.IncompatibleClassChangeError: Implementing class根据网上结论加上我这里的原因,总共以下几个方面&#x…...
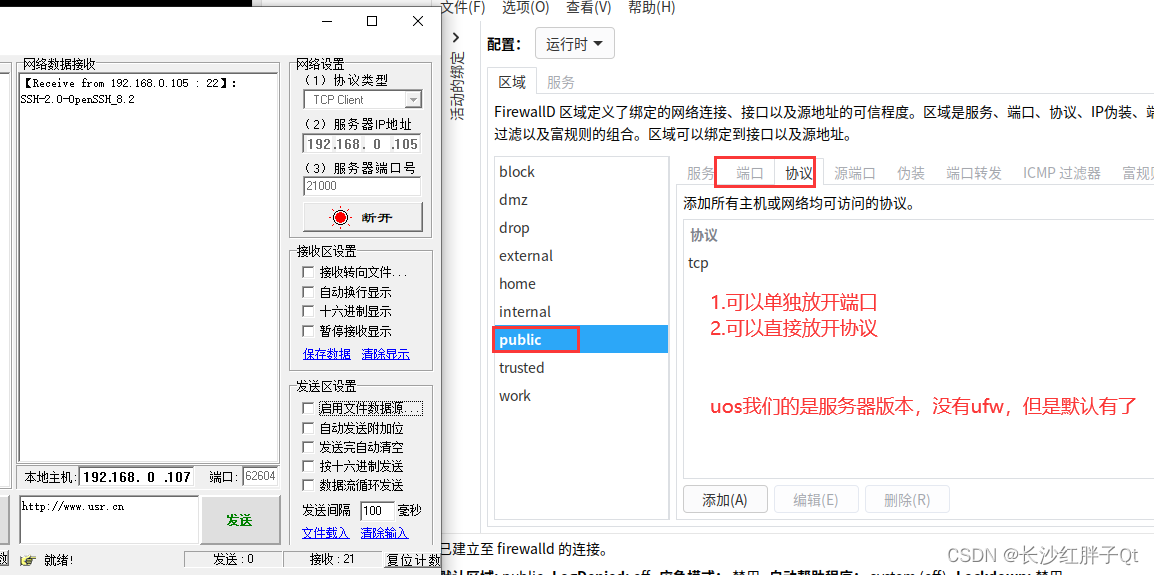
关于 国产系统UOS系统Qt开发Tcp服务器外部连接无法连接上USO系统 的解决方法
若该文为原创文章,转载请注明原文出处 本文章博客地址:https://hpzwl.blog.csdn.net/article/details/134254817 红胖子(红模仿)的博文大全:开发技术集合(包含Qt实用技术、树莓派、三维、OpenCV、OpenGL、ffmpeg、OSG、单片机、软…...
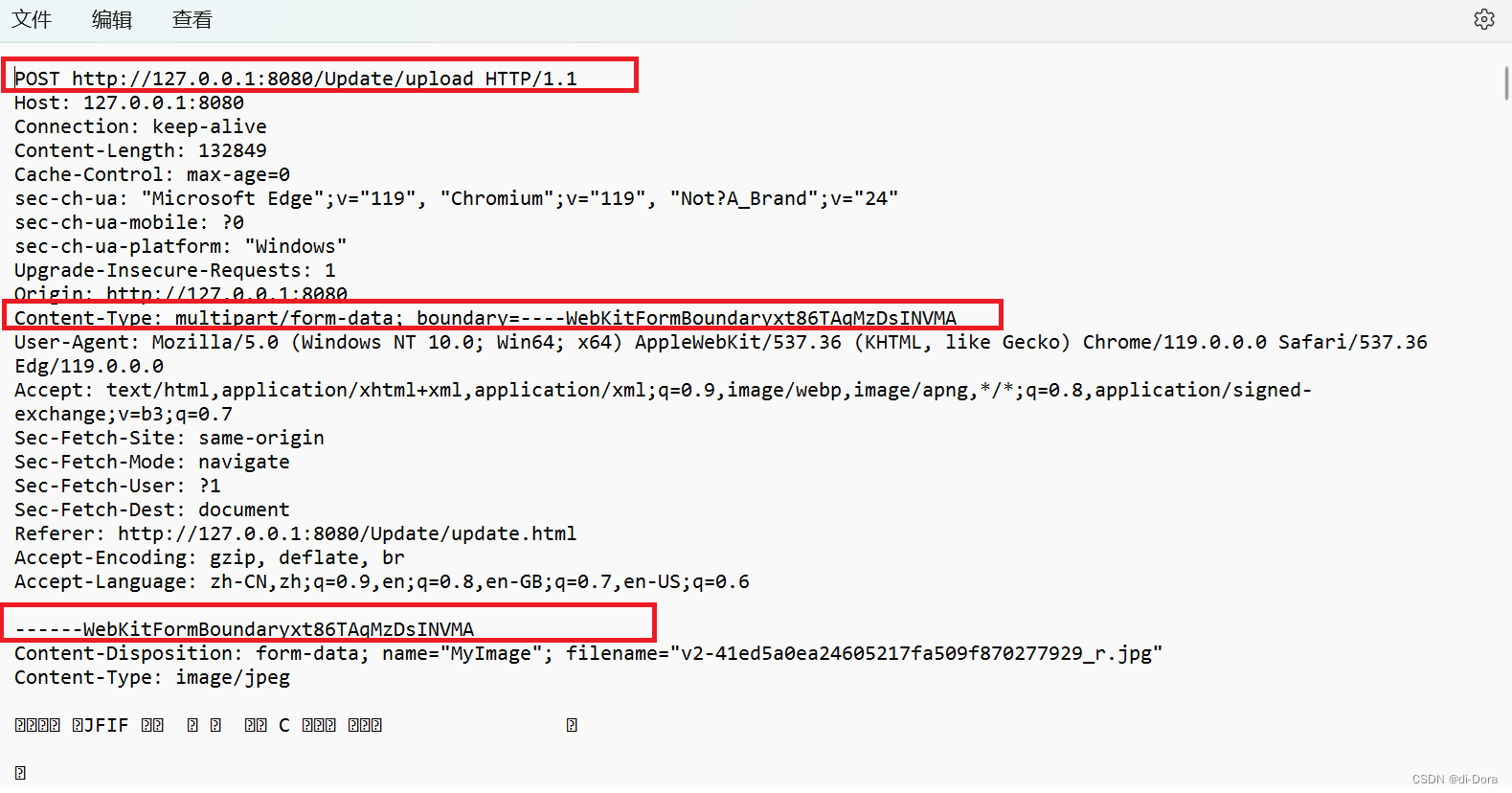
初阶JavaEE(15)(Cookie 和 Session、理解会话机制 (Session)、实现用户登录网页、上传文件网页、常用的代码片段)
接上次博客:初阶JavaEE(14)表白墙程序-CSDN博客 Cookie 和 Session 你还记得我们之前提到的Cookie吗? Cookie是HTTP请求header中的一个属性,是一种用于在浏览器和服务器之间持久存储数据的机制,允许网站…...

C++入门学习(1)命名空间和输入输出
前言 在C语言和基本的数据结构学习之后,我们终于迎来了期待已久的C啦!C发明出来的意义就是填补一些C语言的不足,让我们更加方便的写代码,所以今天我们就来讲一下C语言不足的地方和在C中的解决办法! 一、命名空间 在学习…...

AI:58-基于深度学习的猫狗图像识别
🚀 本文选自专栏:AI领域专栏 从基础到实践,深入了解算法、案例和最新趋势。无论你是初学者还是经验丰富的数据科学家,通过案例和项目实践,掌握核心概念和实用技能。每篇案例都包含代码实例,详细讲解供大家学习。 📌📌📌在这个漫长的过程,中途遇到了不少问题,但是…...
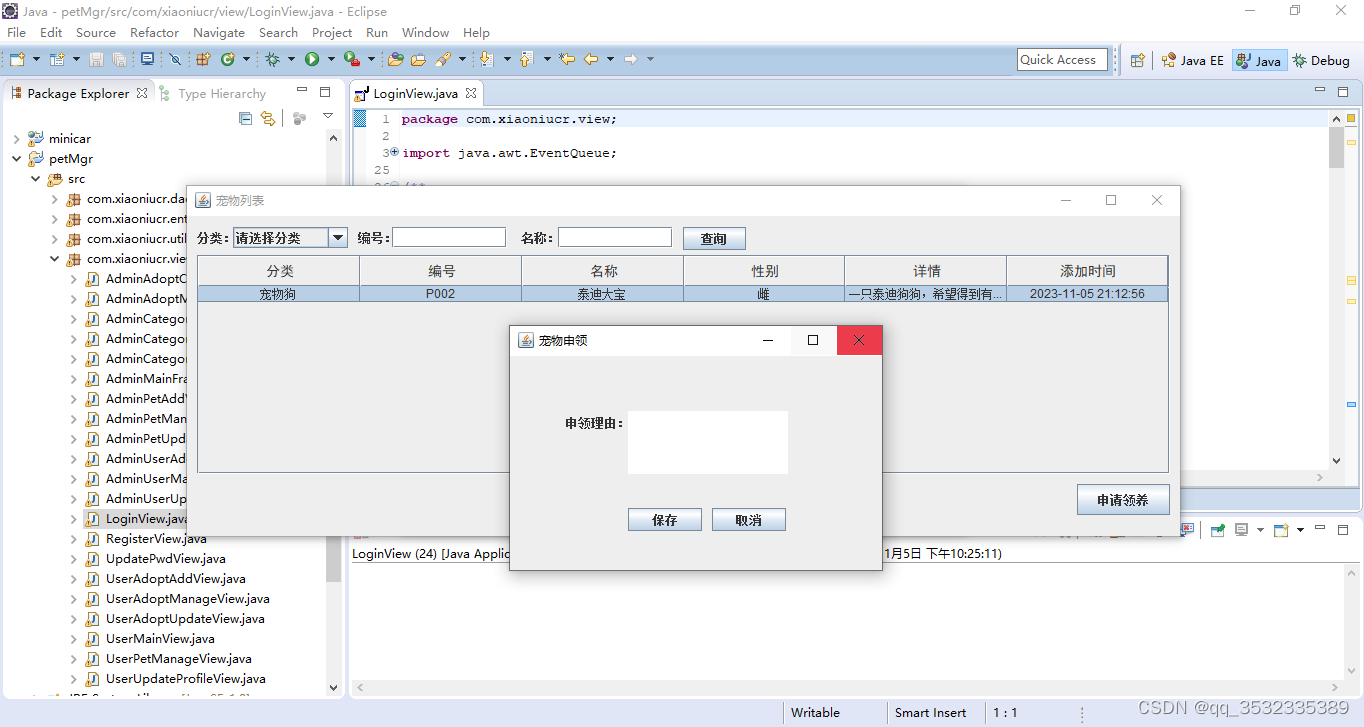
【原创】java+swing+mysql宠物领养管理系统设计与实现
摘要: 生活中,有很多被人遗弃的宠物,这些宠物的处理成为了一个新的难题。生活中也有许多人喜欢养宠物,为了方便大家进行宠物领养,提高宠物领养管理的效率和便利性。本文针对这一问题,提出设计和实现一个基…...

虚拟机Linux-Centos系统网络配置常用命令+Docker 的常用命令
目录 1、虚拟机Linux-Centos系统网络配置常用命令2、Docker 的常用命令2.1 安装docker步骤命令2.2 在docker容器中安装和运行mysql 2、dockerfile关键字区别(ADD/COPY,CMD/ENTRYPOINT) 1、虚拟机Linux-Centos系统网络配置常用命令 进入网络配置文件目录 cd /etc/sysconfig/ne…...

数据分析相关知识整理_--秋招面试版
一、关于sql语句(常问) 1)sql写过的复杂的运算 聚合函数,case when then end语句进行条件运算,字符串的截取、替换,日期的运算,排名等等;行列转换; eg:行列转换 SELE…...

HMM与LTP词性标注之命名实体识别与HMM
文章目录 知识图谱介绍NLP应用场景知识图谱(Neo4j演示)命名实体识别模型架构讲解HMM与CRFHMM五大要素(两大状态与三大概率)HMM案例分享HMM实体识别应用场景代码实现 知识图谱介绍 NLP应用场景 图谱的本质,就是把自然…...

Sui发布RPC2.0 Beta,拥抱GraphQL并计划弃用JSON-RPC
为了解决现有RPC存在的许多已知问题,Sui正在准备推出一个基于GraphQL的新RPC服务,名为Sui RPC 2.0。GraphQL是一种开源数据查询和操作语言,旨在简化需要复杂数据查询的API和服务。 用户目前可以访问Sui主网和测试网网络的Beta版本的只读快照…...

设计模式—结构型模式之桥接模式
设计模式—结构型模式之桥接模式 将抽象与实现解耦,使两者都可以独立变化。 在现实生活中,某些类具有两个或多个维度的变化,如图形既可按形状分,又可按颜色分。如何设计类似于 Photoshop 这样的软件,能画不同形状和不…...

【RabbitMQ】RabbitMQ 消息的堆积问题 —— 使用惰性队列解决消息的堆积问题
文章目录 一、消息的堆积问题1.1 什么是消息的堆积问题1.2 消息堆积的解决思路 二、惰性队列解决消息堆积问题2.1 惰性队列和普通队列的区别2.2 惰性队列的声明方式2.3 演示惰性队列接收大量消息2.4 惰性队列的优缺点 一、消息的堆积问题 1.1 什么是消息的堆积问题 消息的堆积…...
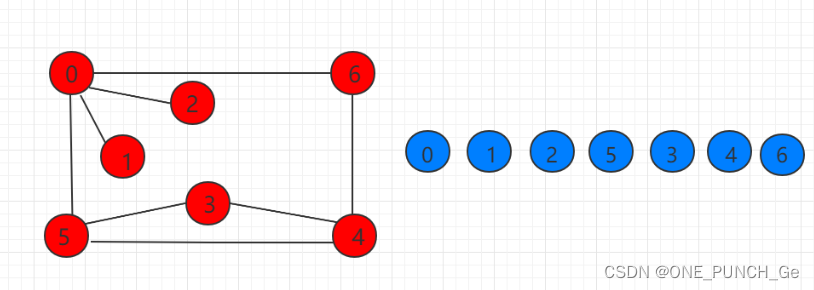
深度优先遍历与连通分量
深度优先遍历(Depth First Search)的主要思想是首先以一个未被访问过的顶点作为起始顶点,沿当前顶点的边走到未访问过的顶点。当没有未访问过的顶点时,则回到上一个顶点,继续试探别的顶点,直至所有的顶点都被访问过。 下图示例的…...

Python学习笔记--类的继承
七、类的继承 1、定义类的继承 说到继承,你一定会联想到继承你老爸的家产之类的。 类的继承也是一样。 比如有一个旧类,是可以算平均数的。然后这时候有一个新类,也要用到算平均数,那么这时候我们就可以使用继承的方式。新类继…...

全自动批量AI改写文章发布软件【软件脚本+技术教程】
项目原理: 利用AI工具将爆款文章改写发布到平台上流量变现,通过播放量赚取收益 软件功能: 1.可以根据你选的文章领域,识别你在网站上抓取的文章链接进来自动洗稿生成过原创的文章,自动配图 2.同时还可以将管理的账号导入进脚本软…...
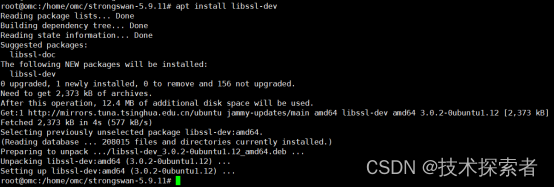
strongswan:configure: error: OpenSSL Crypto library not found
引子 在配置strongswan时,有时会遇到以下错误(其实所有需要openssl的软件configure时都有可能遇到该问题): configure: error: OpenSSL Crypto library not found 解决方法 crypto是什么呢? 是OpenSSL 加密库(lib), 这个库需要op…...
)
保姆级教程:在ArcGIS Pro插件中集成你的自定义工具箱(以‘消除重复要素’为例)
从脚本到按钮:ArcGIS Pro插件开发实战指南 在GIS日常工作中,我们常常会遇到一些重复性的数据处理任务。比如数据质检环节的"消除重复要素"操作,虽然可以通过Python脚本实现,但每次都需要打开IDE或Python窗口执行代码&am…...

2026在线测评系统十大量表对比:信效度与场景全解析
【30s 核心摘要】2026 年在线测评成人才管理刚需,信效度与场景适配成选型核心。本文聚焦十大量表,从信度、效度、适配场景等维度深度对比,重点解析问卷星、北森、金数据等主流平台的量表能力与落地效果,为企业、高校及机构提供科学…...

基于Arduino的模块化DIY智能时钟:从RTC到RGB LED的完整实现
1. 项目概述:打造一台高度可定制的DIY RGB LED时钟如果你和我一样,对市面上千篇一律的电子钟感到审美疲劳,同时又对Arduino和电子DIY充满热情,那么这个项目可能就是为你准备的。我们不是在简单地组装一个套件,而是在亲…...

全链路压测实战:双十一级别的流量,我是这样扛住的
作为一名在质量保障领域摸爬滚打多年的测试工程师,我深知传统的单接口压测在如今分布式架构下的无力感。当业务流量达到双十一这种脉冲式、高并发的级别时,任何一个非核心链路上的“短板”都可能引发系统性的雪崩。全链路压测不再是选择题,而…...
)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)第一次戴上Meta Quest 3时,那种虚拟与现实交织的震撼感至今难忘。但作为开发者,更让我着迷的是如何让虚拟物体在真实空间中"记住"…...

CSharpVerbalExpressions常见问题解答:解决开发者遇到的10个典型挑战
CSharpVerbalExpressions常见问题解答:解决开发者遇到的10个典型挑战 【免费下载链接】CSharpVerbalExpressions 项目地址: https://gitcode.com/gh_mirrors/cs/CSharpVerbalExpressions CSharpVerbalExpressions是一个强大的C#库,它通过类自然语…...

如何用WaveTools终极优化《鸣潮》游戏性能:从卡顿到丝滑的完整指南
如何用WaveTools终极优化《鸣潮》游戏性能:从卡顿到丝滑的完整指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 如果你正在玩《鸣潮》却频繁遭遇帧率波动、画面卡顿或操作延迟,那…...

Awoo Installer:让Switch游戏安装变得简单高效的终极解决方案
Awoo Installer:让Switch游戏安装变得简单高效的终极解决方案 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 厌倦了繁琐的Switch游戏安…...

密码学入门:区块链中的密码学原理
密码学入门:区块链中的密码学原理 大家好,我是欧阳瑞(Rich Own)。今天想和大家聊聊密码学这个重要话题。作为一个Web3探索者,密码学是区块链的基础。今天就来分享一下区块链中常用的密码学原理。 为什么密码学很重要&a…...

动物森友会岛屿设计终极指南:用Happy Island Designer打造梦想岛屿
动物森友会岛屿设计终极指南:用Happy Island Designer打造梦想岛屿 【免费下载链接】HappyIslandDesigner "Happy Island Designer (Alpha)",是一个在线工具,它允许用户设计和定制自己的岛屿。这个工具是受游戏《动物森友会》(Anim…...