18、Flink的SQL 支持的操作和语法
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
18、Flink的SQL 支持的操作和语法
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
22、Flink 的table api与sql之创建表的DDL
24、Flink 的table api与sql之Catalogs(介绍、类型、java api和sql实现ddl、java api和sql操作catalog)-1
24、Flink 的table api与sql之Catalogs(java api操作数据库、表)-2
24、Flink 的table api与sql之Catalogs(java api操作视图)-3
24、Flink 的table api与sql之Catalogs(java api操作分区与函数)-4
26、Flink 的SQL之概览与入门示例
27、Flink 的SQL之SELECT (select、where、distinct、order by、limit、集合操作和去重)介绍及详细示例(1)
27、Flink 的SQL之SELECT (SQL Hints 和 Joins)介绍及详细示例(2)
27、Flink 的SQL之SELECT (窗口函数)介绍及详细示例(3)
27、Flink 的SQL之SELECT (窗口聚合)介绍及详细示例(4)
27、Flink 的SQL之SELECT (Group Aggregation分组聚合、Over Aggregation Over聚合 和 Window Join 窗口关联)介绍及详细示例(5)
27、Flink 的SQL之SELECT (Top-N、Window Top-N 窗口 Top-N 和 Window Deduplication 窗口去重)介绍及详细示例(6)
27、Flink 的SQL之SELECT (Pattern Recognition 模式检测)介绍及详细示例(7)
28、Flink 的SQL之DROP 、ALTER 、INSERT 、ANALYZE 语句
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(1)
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(2)
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
32、Flink table api和SQL 之用户自定义 Sources & Sinks实现及详细示例
41、Flink之Hive 方言介绍及详细示例
42、Flink 的table api与sql之Hive Catalog
43、Flink之Hive 读写及详细验证示例
44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例–网上有些说法好像是错误的
文章目录
- Flink 系列文章
- 一、SQL
- 1、数据类型
- 2、保留关键字
- 二、SQL入门
- 1、Flink SQL环境准备
- 1)、安装Flink及提交任务方式
- 2)、SQL客户端使用介绍
- 3)、简单示例
- 2、Source 表介绍及示例
- 3、连续查询介绍及示例
- 4、Sink 表介绍及示例
本文简单的介绍了SQL和SQL的入门,并以三个简单的示例进行介绍,由于示例涉及到其他的内容,需要了解更深入的内容请参考相关的文章。。
本文依赖flink和kafka、hadoop集群能正常使用。
本文分为2个部分,即介绍了Flink SQL和入门,并提供了完整的可验证通过的示例。
一、SQL
本文描述了 Flink 所支持的 SQL 语言,包括数据定义语言(Data Definition Language,DDL)、数据操纵语言(Data Manipulation Language,DML)以及查询语言。Flink 对 SQL 的支持基于实现了 SQL 标准的 Apache Calcite。
本文列出了目前(截至版本1.17) Flink SQL 所支持的所有语句:
-
SELECT (Queries),具体内容参考文章:27、Flink 的SQL之SELECT (Queries)
-
CREATE TABLE, CATALOG, DATABASE, VIEW, FUNCTION
具体内容参考文章:22、Flink 的table api与sql之创建表的DDL -
DROP TABLE, DATABASE, VIEW, FUNCTION
-
ALTER TABLE, DATABASE, FUNCTION
-
INSERT
-
ANALYZE TABLE
具体内容参考文章:28、Flink 的SQL之DROP 语句、ALTER 语句、INSERT 语句、ANALYZE 语句 -
UPDATE
-
DELETE
-
SQL HINTS
-
DESCRIBE
-
EXPLAIN
-
USE
-
SHOW
-
LOAD
-
UNLOAD
具体内容参考文章: 29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE
1、数据类型
通用类型与(嵌套的)复合类型 (如:POJO、tuples、rows、Scala case 类) 都可以作为行的字段。
复合类型的字段任意的嵌套可被 值访问函数(内置函数) 访问。
通用类型将会被视为一个黑箱,且可以被 用户自定义函数 传递或引用。
对于 DDL 语句而言,我们支持所有在 数据类型 页面中定义的数据类型。
SQL查询不支持部分数据类型(cast 表达式或字符常量值)。
如:STRING, BYTES, RAW, TIME§ WITHOUT TIME ZONE, TIME§ WITH LOCAL TIME ZONE, TIMESTAMP§ WITHOUT TIME ZONE, TIMESTAMP§ WITH LOCAL TIME ZONE, ARRAY, MULTISET, ROW.
更多内容,请参考文章:14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
2、保留关键字
虽然 SQL 的特性并未完全实现,但是一些字符串的组合却已经被预留为关键字以备未来使用。如果你希望使用以下字符串作为你的字段名,请在使用时使用反引号将该字段名包起来(如 value, count )。
A, ABS, ABSOLUTE, ACTION, ADA, ADD, ADMIN, AFTER, ALL, ALLOCATE, ALLOW, ALTER, ALWAYS, AND, ANALYZE, ANY, ARE, ARRAY, AS, ASC, ASENSITIVE, ASSERTION, ASSIGNMENT, ASYMMETRIC, AT, ATOMIC, ATTRIBUTE, ATTRIBUTES, AUTHORIZATION, AVG, BEFORE, BEGIN, BERNOULLI, BETWEEN, BIGINT, BINARY, BIT, BLOB, BOOLEAN, BOTH, BREADTH, BY, BYTES, C, CALL, CALLED, CARDINALITY, CASCADE, CASCADED, CASE, CAST, CATALOG, CATALOG_NAME, CEIL, CEILING, CENTURY, CHAIN, CHAR, CHARACTER, CHARACTERISTICS, CHARACTERS, CHARACTER_LENGTH, CHARACTER_SET_CATALOG, CHARACTER_SET_NAME, CHARACTER_SET_SCHEMA, CHAR_LENGTH, CHECK, CLASS_ORIGIN, CLOB, CLOSE, COALESCE, COBOL, COLLATE, COLLATION, COLLATION_CATALOG, COLLATION_NAME, COLLATION_SCHEMA, COLLECT, COLUMN, COLUMNS, COLUMN_NAME, COMMAND_FUNCTION, COMMAND_FUNCTION_CODE, COMMIT, COMMITTED, CONDITION, CONDITION_NUMBER, CONNECT, CONNECTION, CONNECTION_NAME, CONSTRAINT, CONSTRAINTS, CONSTRAINT_CATALOG, CONSTRAINT_NAME, CONSTRAINT_SCHEMA, CONSTRUCTOR, CONTAINS, CONTINUE, CONVERT, CORR, CORRESPONDING, COUNT, COVAR_POP, COVAR_SAMP, CREATE, CROSS, CUBE, CUME_DIST, CURRENT, CURRENT_CATALOG, CURRENT_DATE, CURRENT_DEFAULT_TRANSFORM_GROUP, CURRENT_PATH, CURRENT_ROLE, CURRENT_SCHEMA, CURRENT_TIME, CURRENT_TIMESTAMP, CURRENT_TRANSFORM_GROUP_FOR_TYPE, CURRENT_USER, CURSOR, CURSOR_NAME, CYCLE, DATA, DATABASE, DATE, DATETIME_INTERVAL_CODE, DATETIME_INTERVAL_PRECISION, DAY, DEALLOCATE, DEC, DECADE, DECIMAL, DECLARE, DEFAULT, DEFAULTS, DEFERRABLE, DEFERRED, DEFINED, DEFINER, DEGREE, DELETE, DENSE_RANK, DEPTH, DEREF, DERIVED, DESC, DESCRIBE, DESCRIPTION, DESCRIPTOR, DETERMINISTIC, DIAGNOSTICS, DISALLOW, DISCONNECT, DISPATCH, DISTINCT, DOMAIN, DOUBLE, DOW, DOY, DROP, DYNAMIC, DYNAMIC_FUNCTION, DYNAMIC_FUNCTION_CODE, EACH, ELEMENT, ELSE, END, END-EXEC, EPOCH, EQUALS, ESCAPE, EVERY, EXCEPT, EXCEPTION, EXCLUDE, EXCLUDING, EXEC, EXECUTE, EXISTS, EXP, EXPLAIN, EXTEND, EXTERNAL, EXTRACT, FALSE, FETCH, FILTER, FINAL, FIRST, FIRST_VALUE, FLOAT, FLOOR, FOLLOWING, FOR, FOREIGN, FORTRAN, FOUND, FRAC_SECOND, FREE, FROM, FULL, FUNCTION, FUSION, G, GENERAL, GENERATED, GET, GLOBAL, GO, GOTO, GRANT, GRANTED, GROUP, GROUPING, HAVING, HIERARCHY, HOLD, HOUR, IDENTITY, IMMEDIATE, IMPLEMENTATION, IMPORT, IN, INCLUDING, INCREMENT, INDICATOR, INITIALLY, INNER, INOUT, INPUT, INSENSITIVE, INSERT, INSTANCE, INSTANTIABLE, INT, INTEGER, INTERSECT, INTERSECTION, INTERVAL, INTO, INVOKER, IS, ISOLATION, JAVA, JOIN, K, KEY, KEY_MEMBER, KEY_TYPE, LABEL, LANGUAGE, LARGE, LAST, LAST_VALUE, LATERAL, LEADING, LEFT, LENGTH, LEVEL, LIBRARY, LIKE, LIMIT, LN, LOCAL, LOCALTIME, LOCALTIMESTAMP, LOCATOR, LOWER, M, MAP, MATCH, MATCHED, MAX, MAXVALUE, MEMBER, MERGE, MESSAGE_LENGTH, MESSAGE_OCTET_LENGTH, MESSAGE_TEXT, METHOD, MICROSECOND, MILLENNIUM, MIN, MINUTE, MINVALUE, MOD, MODIFIES, MODULE, MODULES, MONTH, MORE, MULTISET, MUMPS, NAME, NAMES, NATIONAL, NATURAL, NCHAR, NCLOB, NESTING, NEW, NEXT, NO, NONE, NORMALIZE, NORMALIZED, NOT, NULL, NULLABLE, NULLIF, NULLS, NUMBER, NUMERIC, OBJECT, OCTETS, OCTET_LENGTH, OF, OFFSET, OLD, ON, ONLY, OPEN, OPTION, OPTIONS, OR, ORDER, ORDERING, ORDINALITY, OTHERS, OUT, OUTER, OUTPUT, OVER, OVERLAPS, OVERLAY, OVERRIDING, PAD, PARAMETER, PARAMETER_MODE, PARAMETER_NAME, PARAMETER_ORDINAL_POSITION, PARAMETER_SPECIFIC_CATALOG, PARAMETER_SPECIFIC_NAME, PARAMETER_SPECIFIC_SCHEMA, PARTIAL, PARTITION, PASCAL, PASSTHROUGH, PATH, PERCENTILE_CONT, PERCENTILE_DISC, PERCENT_RANK, PLACING, PLAN, PLI, POSITION, POWER, PRECEDING, PRECISION, PREPARE, PRESERVE, PRIMARY, PRIOR, PRIVILEGES, PROCEDURE, PUBLIC, QUARTER, RANGE, RANK, RAW, READ, READS, REAL, RECURSIVE, REF, REFERENCES, REFERENCING, REGR_AVGX, REGR_AVGY, REGR_COUNT, REGR_INTERCEPT, REGR_R2, REGR_SLOPE, REGR_SXX, REGR_SXY, REGR_SYY, RELATIVE, RELEASE, REPEATABLE, RESET, RESTART, RESTRICT, RESULT, RETURN, RETURNED_CARDINALITY, RETURNED_LENGTH, RETURNED_OCTET_LENGTH, RETURNED_SQLSTATE, RETURNS, REVOKE, RIGHT, ROLE, ROLLBACK, ROLLUP, ROUTINE, ROUTINE_CATALOG, ROUTINE_NAME, ROUTINE_SCHEMA, ROW, ROWS, ROW_COUNT, ROW_NUMBER, SAVEPOINT, SCALE, SCHEMA, SCHEMA_NAME, SCOPE, SCOPE_CATALOGS, SCOPE_NAME, SCOPE_SCHEMA, SCROLL, SEARCH, SECOND, SECTION, SECURITY, SELECT, SELF, SENSITIVE, SEQUENCE, SERIALIZABLE, SERVER, SERVER_NAME, SESSION, SESSION_USER, SET, SETS, SIMILAR, SIMPLE, SIZE, SMALLINT, SOME, SOURCE, SPACE, SPECIFIC, SPECIFICTYPE, SPECIFIC_NAME, SQL, SQLEXCEPTION, SQLSTATE, SQLWARNING, SQL_TSI_DAY, SQL_TSI_FRAC_SECOND, SQL_TSI_HOUR, SQL_TSI_MICROSECOND, SQL_TSI_MINUTE, SQL_TSI_MONTH, SQL_TSI_QUARTER, SQL_TSI_SECOND, SQL_TSI_WEEK, SQL_TSI_YEAR, SQRT, START, STATE, STATEMENT, STATIC, STDDEV_POP, STDDEV_SAMP, STREAM, STRING, STRUCTURE, STYLE, SUBCLASS_ORIGIN, SUBMULTISET, SUBSTITUTE, SUBSTRING, SUM, SYMMETRIC, SYSTEM, SYSTEM_USER, TABLE, TABLESAMPLE, TABLE_NAME, TEMPORARY, THEN, TIES, TIME, TIMESTAMP, TIMESTAMPADD, TIMESTAMPDIFF, TIMEZONE_HOUR, TIMEZONE_MINUTE, TINYINT, TO, TOP_LEVEL_COUNT, TRAILING, TRANSACTION, TRANSACTIONS_ACTIVE, TRANSACTIONS_COMMITTED, TRANSACTIONS_ROLLED_BACK, TRANSFORM, TRANSFORMS, TRANSLATE, TRANSLATION, TREAT, TRIGGER, TRIGGER_CATALOG, TRIGGER_NAME, TRIGGER_SCHEMA, TRIM, TRUE, TYPE, UESCAPE, UNBOUNDED, UNCOMMITTED, UNDER, UNION, UNIQUE, UNKNOWN, UNNAMED, UNNEST, UPDATE, UPPER, UPSERT, USAGE, USER, USER_DEFINED_TYPE_CATALOG, USER_DEFINED_TYPE_CODE, USER_DEFINED_TYPE_NAME, USER_DEFINED_TYPE_SCHEMA, USING, VALUE, VALUES, VARBINARY, VARCHAR, VARYING, VAR_POP, VAR_SAMP, VERSION, VIEW, WEEK, WHEN, WHENEVER, WHERE, WIDTH_BUCKET, WINDOW, WITH, WITHIN, WITHOUT, WORK, WRAPPER, WRITE, XML, YEAR, ZONE
二、SQL入门
Flink SQL 使得使用标准 SQL 开发流应用程序变的简单。如果你曾经在工作中使用过兼容 ANSI-SQL 2011 的数据库或类似的 SQL 系统,那么就很容易学习 Flink。
1、Flink SQL环境准备
1)、安装Flink及提交任务方式
参考文章:
1、Flink1.12.7或1.13.5详细介绍及本地安装部署、验证
2、Flink1.13.5二种部署方式(Standalone、Standalone HA )、四种提交任务方式(前两种及session和per-job)验证详细步骤
2)、SQL客户端使用介绍
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
3)、简单示例
Flink SQL>SET execution.result-mode=tableau;Flink SQL> show databases;
+------------------+
| database name |
+------------------+
| default_database |
+------------------+
1 row in setFlink SQL> use default_database;
[INFO] Execute statement succeed.Flink SQL> show tables;
Empty setFlink SQL> SELECT 'Hello World';
+----+--------------------------------+
| op | _o__c0 |
+----+--------------------------------+
| +I | Hello World |
+----+--------------------------------+
Received a total of 1 row
Flink SQL> show functions;
Hive Session ID = 5d34cbf8-5984-4ec0-8527-e06a948ad7ca
+--------------------------------+
| function name |
+--------------------------------+
| ! |
| != |
| $sum0 |
| % |
| & |
| * |
| + |
| - |
| / |
| < |
| <= |
| <=> |
| <> |
| = |
| == |
| > |
| >= |
| IFNULL |
| SOURCE_WATERMARK |
| TYPEOF |
| ^ |
| _legacy_grouping__id |
| abs |
| acos |
| add_months |
| aes_decrypt |
| aes_encrypt |
| and |
| array |
| array_contains |
| as |
| asc |
| ascii |
| asin |
| assert_true |
| assert_true_oom |
| at |
| atan |
| atan2 |
| avg |
| base64 |
| between |
| bigint |
| bin |
| binary |
| bloom_filter |
| boolean |
| bround |
| cardinality |
| cardinality_violation |
| case |
| cast |
| cbrt |
| ceil |
| ceiling |
| char |
| charLength |
| char_length |
| character_length |
| chr |
| coalesce |
| collect |
| collect_list |
| collect_set |
| compute_stats |
| concat |
| concat_ws |
| context_ngrams |
| conv |
| corr |
| cos |
| cosh |
| cot |
| count |
| covar_pop |
| covar_samp |
| crc32 |
| create_union |
| currentDate |
| currentRange |
| currentRow |
| currentRowTimestamp |
| currentTime |
| currentTimestamp |
| current_authorizer |
| current_database |
| current_groups |
| current_user |
| date |
| dateFormat |
| date_add |
| date_format |
| date_sub |
| datediff |
| day |
| dayofmonth |
| dayofweek |
| decimal |
| decode |
| degrees |
| desc |
| distinct |
| div |
| divide |
| double |
| e |
| element |
| elt |
| encode |
| encryptphonenumber |
| end |
| enforce_constraint |
| equals |
| exp |
| explode |
| extract |
| extract_union |
| factorial |
| field |
| find_in_set |
| flatten |
| float |
| floor |
| floor_day |
| floor_hour |
| floor_minute |
| floor_month |
| floor_quarter |
| floor_second |
| floor_week |
| floor_year |
| format_number |
| fromBase64 |
| from_unixtime |
| from_utc_timestamp |
| get |
| get_json_object |
| get_splits |
| greaterThan |
| greaterThanOrEqual |
| greatest |
| grouping |
| hash |
| hex |
| histogram_numeric |
| hour |
| if |
| ifThenElse |
| in |
| in_bloom_filter |
| in_file |
| index |
| initCap |
| initcap |
| inline |
| instr |
| int |
| internal_interval |
| interval_day_time |
| interval_year_month |
| isFalse |
| isNotFalse |
| isNotNull |
| isNotTrue |
| isNull |
| isTrue |
| isfalse |
| isnotfalse |
| isnotnull |
| isnottrue |
| isnull |
| istrue |
| java_method |
| json_tuple |
| last_day |
| lcase |
| least |
| length |
| lessThan |
| lessThanOrEqual |
| levenshtein |
| like |
| likeall |
| likeany |
| ln |
| localTime |
| localTimestamp |
| locate |
| log |
| log10 |
| log2 |
| logged_in_user |
| lower |
| lowerCase |
| lpad |
| ltrim |
| map |
| map_keys |
| map_values |
| mask |
| mask_first_n |
| mask_hash |
| mask_last_n |
| mask_show_first_n |
| mask_show_last_n |
| matchpath |
| max |
| md5 |
| min |
| minus |
| minusPrefix |
| minute |
| mod |
| month |
| months_between |
| murmur_hash |
| named_struct |
| negative |
| next_day |
| ngrams |
| noop |
| noopstreaming |
| noopwithmap |
| noopwithmapstreaming |
| not |
| notBetween |
| notEquals |
| nullif |
| nvl |
| octet_length |
| or |
| over |
| overlay |
| parse_url |
| parse_url_tuple |
| percentile |
| percentile_approx |
| pi |
| plus |
| pmod |
| posexplode |
| position |
| positive |
| pow |
| power |
| printf |
| proctime |
| quarter |
| radians |
| rand |
| randInteger |
| rangeTo |
| reflect |
| reflect2 |
| regexp |
| regexpExtract |
| regexpReplace |
| regexp_extract |
| regexp_replace |
| regr_avgx |
| regr_avgy |
| regr_count |
| regr_intercept |
| regr_r2 |
| regr_slope |
| regr_sxx |
| regr_sxy |
| regr_syy |
| reinterpretCast |
| repeat |
| replace |
| replicate_rows |
| restrict_information_schema |
| reverse |
| rlike |
| round |
| row |
| rowtime |
| rpad |
| rtrim |
| second |
| sentences |
| sha |
| sha1 |
| sha2 |
| sha224 |
| sha256 |
.................
至此,我们的环境都准备好了。
2、Source 表介绍及示例
与所有 SQL 引擎一样,Flink 查询操作是在表上进行。与传统数据库不同,Flink 不在本地管理静态数据;相反,它的查询在外部表上连续运行。
Flink 数据处理流水线开始于 source 表。source 表产生在查询执行期间可以被操作的行;它们是查询时 FROM 子句中引用的表。这些表可能是 Kafka 的 topics,数据库,文件系统,或者任何其它 Flink 知道如何消费的系统。
可以通过 SQL 客户端或使用环境配置文件来定义表。SQL 客户端支持类似于传统 SQL 的 SQL DDL 命令。标准 SQL DDL 用于创建,修改,删除表。
Flink 支持不同的连接器和格式相结合以定义表。相关内容在本Flink专栏中均有介绍,请参考:alanchanchn的专栏-Flink专栏
下面是一个示例,定义一个以 CSV 文件作为存储格式的 source 表。由于Flink创建表涉及较多的内容,关于下面的示例请参考文章:16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
Flink SQL> show catalogs;
Hive Session ID = 008f6263-1b8e-4eb7-b034-a2c8651809f1
+------------------+
| catalog name |
+------------------+
| alan_hivecatalog |
| default_catalog |
+------------------+
2 rows in setFlink SQL> use catalog default_catalog;
Hive Session ID = 1b1a3fb2-e303-4c2a-bfc8-5f38c47aa0f6
[INFO] Execute statement succeed.Flink SQL> show databases;
+------------------+
| database name |
+------------------+
| default_database |
+------------------+
1 row in setFlink SQL> use default_database;
[INFO] Execute statement succeed.Flink SQL> show tables;
Empty setFlink SQL> CREATE TABLE alan_first_table (
> t_id BIGINT,
> t_name STRING,
> t_balance DOUBLE,
> t_age INT
> ) WITH (
> 'connector' = 'filesystem',
> 'path' = 'hdfs://HadoopHAcluster/flinktest/firstdemo/',
> 'format' = 'csv'
> );
[INFO] Execute statement succeed.Flink SQL> show tables;
+------------------+
| table name |
+------------------+
| alan_first_table |
+------------------+
1 row in set
---能查出来数据是有前提的,那就是在创建表之前,我已经在hdfs://HadoopHAcluster/flinktest/firstdemo目录下上传了5个文件,每个文件一条数据
[alanchan@server4 testdata]$ hadoop fs -ls hdfs://HadoopHAcluster/flinktest/firstdemo
Found 5 items
-rw-r--r-- 3 alanchan supergroup 15 2023-09-07 10:24 hdfs://HadoopHAcluster/flinktest/firstdemo/dim_user1.txt
-rw-r--r-- 3 alanchan supergroup 19 2023-09-07 10:24 hdfs://HadoopHAcluster/flinktest/firstdemo/dim_user2.txt
-rw-r--r-- 3 alanchan supergroup 22 2023-09-07 10:24 hdfs://HadoopHAcluster/flinktest/firstdemo/dim_user3.txt
-rw-r--r-- 3 alanchan supergroup 20 2023-09-07 10:24 hdfs://HadoopHAcluster/flinktest/firstdemo/dim_user4.txt
-rw-r--r-- 3 alanchan supergroup 24 2023-09-07 10:24 hdfs://HadoopHAcluster/flinktest/firstdemo/dim_user5.txtFlink SQL> select * from alan_first_table;
+----+----------------------+--------------------------------+--------------------------------+-------------+
| op | t_id | t_name | t_balance | t_age |
+----+----------------------+--------------------------------+--------------------------------+-------------+
| +I | 5 | alan_chan_chn | 52.23 | 38 |
| +I | 3 | alanchanchn | 32.23 | 28 |
| +I | 1 | alan | 12.23 | 18 |
| +I | 4 | alan_chan | 12.43 | 29 |
| +I | 2 | alanchan | 22.23 | 10 |
+----+----------------------+--------------------------------+--------------------------------+-------------+
Received a total of 5 rows---带条件查询
Flink SQL> select * from alan_first_table where t_balance >=20;
+----+----------------------+--------------------------------+--------------------------------+-------------+
| op | t_id | t_name | t_balance | t_age |
+----+----------------------+--------------------------------+--------------------------------+-------------+
| +I | 3 | alanchanchn | 32.23 | 28 |
| +I | 2 | alanchan | 22.23 | 10 |
| +I | 5 | alan_chan_chn | 52.23 | 38 |
+----+----------------------+--------------------------------+--------------------------------+-------------+
Received a total of 3 rows可以从该表中定义一个连续查询,当新行可用时读取并立即输出它们的结果。
3、连续查询介绍及示例
虽然最初设计时没有考虑流语义,但 SQL 是用于构建连续数据流水线的强大工具。Flink SQL 与传统数据库查询的不同之处在于,Flink SQL 持续消费到达的行并对其结果进行更新。
一个连续查询永远不会终止,并会产生一个动态表作为结果。动态表是 Flink 中 Table API 和 SQL 对流数据支持的核心概念。
连续流上的聚合需要在查询执行期间不断地存储聚合的结果。例如,假设你需要从传入的数据流中计算每个部门的员工人数。查询需要维护每个部门最新的计算总数,以便在处理新行时及时输出结果。
关于连续查询更多的内容,参考文章:15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
下面的示例说明:
1、在flink创建一张表,提交连续查询的任务(其实就是一个查询session,动态显示表内的数据)
2、为方便模拟,使用kafka作为消息源,即表的连接类型为kafka,也即需要有kafka的运行环境
3、sql客户端的环境与本文上述示例一致
4、关于该示例更多的信息参考:16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
Flink SQL> CREATE TABLE alanchan_kafka_table (
> `id` INT,
> name STRING,
> age INT,
> balance DOUBLE
> ) WITH (
> 'connector' = 'kafka',
> 'topic' = 't_kafka_source',
> 'scan.startup.mode' = 'earliest-offset',
> 'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
> 'format' = 'csv'
> );
[INFO] Execute statement succeed.Flink SQL> show tables;
+----------------------+
| table name |
+----------------------+
| alan_first_table |
| alanchan_kafka_table |
+----------------------+
2 rows in set
-----kafka一条一条写入数据,下文中的查询结果会根据kafka中发送的消息逐条展示出来------
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic t_kafka_source
>1,alan,15,100
>2,alanchan,20,200
>3,alanchanchn,25,300
>4,alan_chan,30,400
>5,alan_chan_chn,50,45
>Flink SQL> select * from alanchan_kafka_table;
+----+-------------+--------------------------------+-------------+--------------------------------+
| op | id | name | age | balance |
+----+-------------+--------------------------------+-------------+--------------------------------+
| +I | 1 | alan | 15 | 100.0 |
| +I | 2 | alanchan | 20 | 200.0 |
| +I | 3 | alanchanchn | 25 | 300.0 |
| +I | 4 | alan_chan | 30 | 400.0 |
| +I | 5 | alan_chan_chn | 50 | 45.0 |4、Sink 表介绍及示例
当运行此查询时,SQL 客户端实时但是以只读方式提供输出。存储结果,作为报表或仪表板的数据来源,需要写到另一个表。这可以使用 INSERT INTO 语句来实现。本节中引用的表称为 sink 表。INSERT INTO 语句将作为一个独立查询被提交到 Flink 集群中。
------创建数据源表,该表不能查询
Flink SQL> CREATE TABLE source_table (
> userId INT,
> age INT,
> balance DOUBLE,
> userName STRING
> ) WITH (
> 'connector' = 'datagen',
> 'rows-per-second'='100',
> 'fields.userId.kind'='sequence',
> 'fields.userId.start'='1',
> 'fields.userId.end'='1000',
>
> 'fields.balance.kind'='random',
> 'fields.balance.min'='1',
> 'fields.balance.max'='100',
>
> 'fields.age.min'='1',
> 'fields.age.max'='1000',
>
> 'fields.userName.length'='10'
> );
[INFO] Execute statement succeed.
----创建sink表,hdfs文件夹不需要手动创建,flink会自己创建
Flink SQL> CREATE TABLE alan_sink_table (
> t_id BIGINT,
> t_name STRING,
> t_balance DOUBLE,
> t_age INT
> ) WITH (
> 'connector' = 'filesystem',
> 'path' = 'hdfs://HadoopHAcluster/flinktest/firstsinkdemo/',
> 'format' = 'csv'
> );
[INFO] Execute statement succeed.
------批量插入sink表,也可以是动态的,但需要设置数据刷新频率,否则查不到结果,该事情在本Flink专栏中有说明
------此处也是提交一个flink任务,此处用的是yarn-session模式
Flink SQL> INSERT INTO alan_sink_table
> SELECT userId ,userName,balance,age FROM source_table;Job ID: c2e1985745c5c938c56e26f8efe5a8db------查询结果如下
Flink SQL> select * from alan_sink_table;+----+----------------------+--------------------------------+--------------------------------+-------------+
| op | t_id | t_name | t_balance | t_age |
+----+----------------------+--------------------------------+--------------------------------+-------------+
| +I | 1 | d0c7d38b94 | 31.52935530019297 | 802 |
| +I | 2 | b880adc262 | 45.43292342494475 | 556 |
| +I | 3 | e1ce373b2e | 39.595138772111014 | 459 |
| +I | 4 | 3bd1242679 | 78.58761035208113 | 585 |
| +I | 5 | 88ba47bb2b | 4.870598793833649 | 508 |
| +I | 6 | 72bdba9132 | 48.33565877511729 | 115 |
| +I | 7 | 0fa82976d1 | 52.6978279057911 | 353 |
| +I | 8 | 8d546bab93 | 20.403401648898576 | 391 |
| +I | 9 | 9eb957d512 | 82.16967630094122 | 323 |
| +I | 10 | 5423755f01 | 49.12646233699912 | 769 |
| +I | 11 | da6c7936ea | 16.877530563314846 | 687 |
| +I | 12 | 3ef87eb75a | 68.65154273578702 | 434 |
| +I | 13 | e08320e927 | 8.403066874855323 | 292 |
| +I | 14 | 03e1ccfc69 | 98.61326426348097 | 653 |
......
+----+----------------------+--------------------------------+--------------------------------+-------------+
Received a total of 1000 rows提交后,它将运行并将结果直接存储到 sink 表中,而不是将结果加载到系统内存中。
以上,简单的介绍了SQL和SQL的入门,并以三个简单的示例进行介绍,由于示例涉及到其他的内容,需要了解更深入的内容请参考相关的文章。
相关文章:

18、Flink的SQL 支持的操作和语法
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

泛微OA_lang2sql 任意文件上传漏洞复现
简介 泛微OA E-mobile系统 lang2sql接口存在任意文件上传漏洞,由于后端源码中没有对文件没有校验,导致任意文件上传。攻击者可利用该参数构造恶意数据包进行上传漏洞攻击。 漏洞复现 FOFA语法: title"移动管理平台-企业管理" 页…...
Rust编程基础核心之所有权(上)
1.什么是所有权? Rust 的核心功能(之一)是 所有权(ownership)。虽然该功能很容易解释,但它对语言的其他部分有着深刻的影响。 所有程序都必须管理其运行时使用计算机内存的方式。一些语言中具有垃圾回收机制&#x…...

优化改进YOLOv5算法之添加DCNv3模块,有效提升目标检测效果
目录 前言 1 DCNv3原理 1.1 DCNv2 1.2 DCNv3 1.3 模型架构 2 YOLOv5算法中加入DCNv3模块...

VSCode 连接不上 debian 的问题
之前一台笔记本上安装了 debian12,当时用 vscode 是可以连接上的,但今天连接突然就失败了,失败信息是这样的: 查看失败信息 因为 debian 是自动获取 ip 地址的,以前能连接上时,ip 地址是 104,然…...
【ElasticSearch系列-06】Es集群架构的搭建以及集群的核心概念
ElasticSearch系列整体栏目 内容链接地址【一】ElasticSearch下载和安装https://zhenghuisheng.blog.csdn.net/article/details/129260827【二】ElasticSearch概念和基本操作https://blog.csdn.net/zhenghuishengq/article/details/134121631【三】ElasticSearch的高级查询Quer…...

软考高级系统架构设计师系列案例考点专题六:面向服务架构设计
软考高级系统架构设计师系列案例考点专题六:面向服务架构设计 一、面向服务架构设计内容大纲二、SOA概述和发展三、SOA和微服务的区别四、SOA的参考架构五、SOA主要协议和规范六、SOA设计标准和原则七、SOA设计模式八、SOA构建和实施一、面向服务架构设计内容大纲 SOA概述和发…...

【入门Flink】- 07Flink DataStream API【万字篇】
DataStream API 是 Flink 的核心层 API。一个 Flink 程序,其实就是对DataStream的各种转换。 代码基本上都由以下几部分构成: 执行环境(Execution Environment) 1)创建执行环境StreamExecutionEnvironment StreamExe…...

AI:55-基于深度学习的人流量检测
🚀 本文选自专栏:AI领域专栏 从基础到实践,深入了解算法、案例和最新趋势。无论你是初学者还是经验丰富的数据科学家,通过案例和项目实践,掌握核心概念和实用技能。每篇案例都包含代码实例,详细讲解供大家学习。 📌📌📌在这个漫长的过程,中途遇到了不少问题,但是…...

node版本管理工具nvm
node版本管理工具nvm 要在本地拥有多个 Node.js 版本,并根据不同的环境切换不同的 Node.js 版本,你可以使用工具如 nvm(Node Version Manager)来管理和切换 Node.js 版本。 以下是关于如何使用这两个工具的简要说明:…...

stable-diffusion-webui安装Wav2Lip
常见错误 1.错误:Torch is not able to use GPU; add --skip-torch-cuda-test to COMMANDLINE_ARGS variable to disable this check 修改代码: launch_utils.py 删除三个地方:...
Nacos-2.2.2源码修改集成高斯数据库GaussDB,postresql
一 ,下载代码 Release 2.2.2 (Apr 11, 2023) alibaba/nacos GitHub 二, 执行打包 mvn -Prelease-nacos -Dmaven.test.skiptrue -Drat.skiptrue clean install -U 或 mvn -Prelease-nacos ‘-Dmaven.test.skiptrue’ ‘-Drat.skiptrue’ clean instal…...

Linux 内核中根据文件inode号获取其对应的struct inode
文章目录 前言一、简介二、iget_locked2.1 简介2.2 内核中使用2.3 LKM demo 三、ext4_iget3.1 简介3.2 LKM demo 前言 文件inode号和struct inode结构体请参考: Linux文件路径,目录项,inode号关联 Linux文件系统 struct inode 结构体解析 一…...
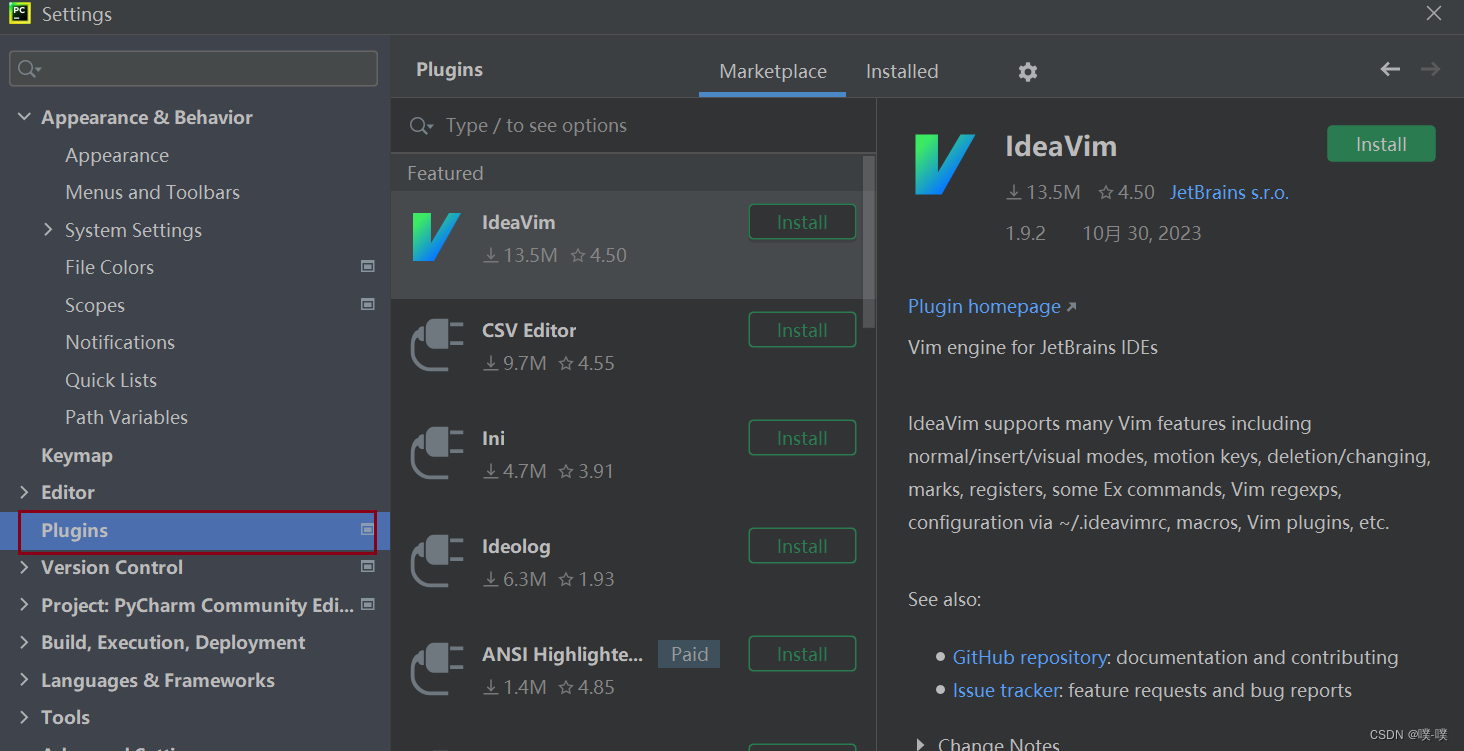
Pycharm-community-2021版安装和配置
一、下载Pycharm-community-2021 1.从官网下载pycharm-community Pycharm 版本官网 二、安装PyCharm 1.打开下载完成的安装包,点击Next 2.安装PyCharm到其他位置,点击Next 3.一定把更新PATH变量勾上,可以创建桌面快捷方式,创建关联,最后…...
飞书开发学习笔记(一)-应用创建和测试
飞书开发学习笔记(一)-应用创建和测试 一.前言 现在大企业用的办公IM软件中,飞书是口碑最好的,不得不说,字节在开发产品方面,确实有自己独到的竞争力,比如说抖音、头条、飞书。在办公会议和云文档的体验上,其它的办公…...

【Mybatis小白从0到90%精讲】12:Mybatis删除 delete, 推荐使用主键删除!
文章目录 前言XML映射文件方式推荐使用主键删除注解方式工具类前言 在实际开发中,我们经常需要删除数据库中的数据,MyBatis可以使用XML映射文件或注解来编写删除(delete)语句,下面是两种方法的示例。 XML映射文件方式 Mapper: int delete(int id);Mapper.xml:...

RocketMQ批量发送消息❓
优点: 批量发送消息可以提高rocketmq的生产者性能和吞吐量。 使用场景: 发送大量小型消息时;需要降低消息发送延迟时;需要提高生产者性能时; 注意事项: 消息列表的大小不能超过broker设置的最大消息大小;消息列表…...

一键同步chromedriver版本
ChromeDriver是一个控制Chrome浏览器的驱动程序,它和Selenium一起被广泛用于Web自动化测试。然而,随着Chrome版本的升级,我们需要不断更新ChromeDriver以保持其与Chrome的兼容性。这个过程既费时又繁琐,而且对于非技术人员来说可能…...
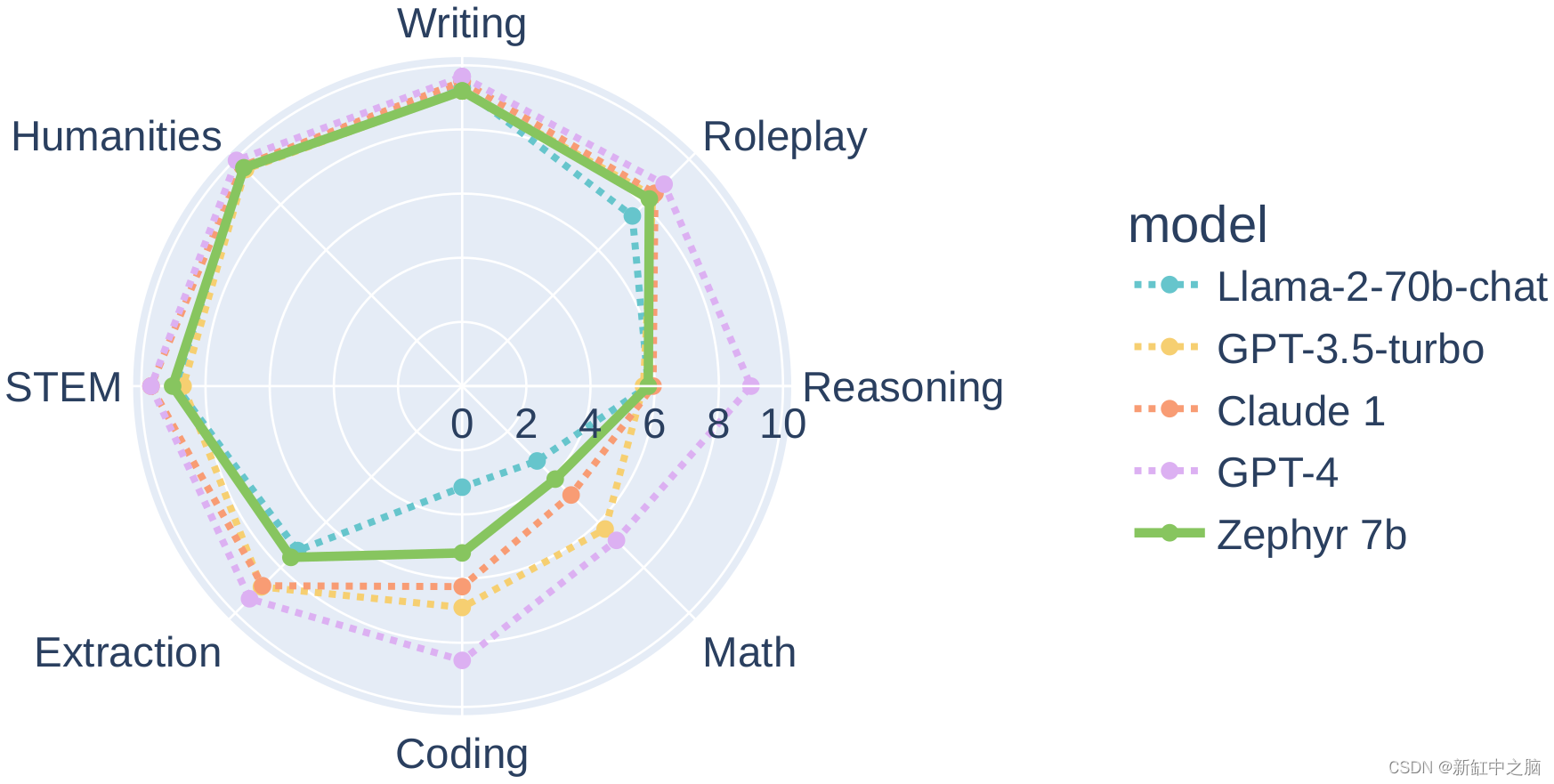
Zephyr-7B-β :类GPT的高速推理LLM
Zephyr 是一系列语言模型,经过训练可以充当有用的助手。 Zephyr-7B-β 是该系列中的第二个模型,是 Mistralai/Mistral-7B-v0.1 的微调版本,使用直接偏好优化 (DPO) 在公开可用的合成数据集上进行训练 。 我们发现,删除这些数据集的…...

【笔试题】位运算
记录一些常见的位运算题: 1、实现对一个8bit数据(unsigned char类型)的指定位(例如第n位)置0或者置1操作,并保持其他地位不变。 unsigned char reg;/* 对第n位置0 */ reg &~ (1 << n);/* 对第n位…...

别再死记硬背了!用Multisim仿真+图解,5分钟搞懂三极管共射放大电路工作原理
用Multisim仿真图解5分钟掌握三极管共射放大电路三极管共射放大电路是电子技术中最基础也最关键的电路之一,但传统教材中复杂的公式推导和静态图解往往让初学者望而生畏。本文将带你用Multisim仿真软件,通过可视化的方式直观理解电路工作原理,…...

2026 新视角:化妆品开发的底层逻辑,做好一款产品,从选对原料开始
在化妆品研发链条中,配方架构、生产工艺、包装设计固然重要,但决定一款产品上限的,永远是原料。一款稳定、安全、表现优异的护肤成品,离不开纯净、达标、批次一致的优质原料。对于品牌方、配方师、代工企业而言,原料不…...
上午题回忆与解析(非标答版))
2026上半年数据库系统工程师(软考)上午题回忆与解析(非标答版)
本文为考后回忆整理,非官方标准答案,旨在为考后对答案及下半年备考的同学提供参考。题目顺序和表述可能与原卷有出入,欢迎在评论区指正、补充。📊 整体考情分析 刚结束的2026年上半年数据库系统工程师考试,上午题的风格…...

电容损坏深度诊断,从外观到 ESR精准区分容衰与漏电
在 PCB 故障中,电容损坏占比超 40%,是当之无愧的 “头号杀手”。很多工程师仅靠 “鼓包漏液” 判断电容好坏,殊不知80% 的电容损坏是隐性的—— 外观平整但容值衰减、ESR 升高、轻微漏电,导致供电不稳、系统重启、噪声增大&#x…...

HDI 高密度互连板阶数的深度理解
一、概述高密度互连板(High Density Interconnector, HDI)是通过激光微孔技术和逐层积层工艺实现高密度布线的印制电路板。其阶数划分是行业内统一的技术标准,核心依据为独立积层压合次数与配套激光盲孔制程次数,而非单面层数或钻…...

论文写作效率翻倍?okbiye 毕业论文 AI 功能全解析:从需求到终稿的规范路径
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 一、从界面看本质:okbiye 毕业论文 AI 写作的设计逻辑 打开 okbiye 的毕业论文 AI 写作页面,首先能感受到的是清晰的…...

基于MAX78000的离线鸟类声音识别:边缘AI从数据到部署全流程解析
1. 项目概述:当边缘AI“听懂”鸟鸣在野外生态监测或自家后院观鸟时,你是否有过这样的经历:听到一阵清脆或婉转的鸟鸣,却完全不知道是哪位“歌唱家”在表演?传统的鸟类识别依赖专家经验和图鉴比对,不仅门槛高…...

如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析
如何在3分钟内为任何活动搭建专业级滚动抽奖系统?Magpie-LuckyDraw全平台开源方案深度解析 【免费下载链接】Magpie-LuckyDraw 🏅A fancy lucky-draw tool supporting multiple platforms💻(Mac/Linux/Windows/Web/Docker) 项目地址: https…...

5A智慧景区建设|对标一流!巨有科技打造数智化标杆景区
5A级景区是中国旅游的最高标准,代表着服务与管理的顶尖水平。随着5A评审标准日益严苛,“智慧化”已成为核心硬性指标。然而,不少景区的智慧化建设陷入“重硬件、轻整合”的误区,系统林立、数据孤岛,投入巨大却效果不佳…...

Xia Sql插件:可调试的SQL注入决策引擎
1. 这不是又一个“自动扫SQL”的插件,而是把渗透工程师的判断逻辑塞进了Burp里你有没有过这种经历:在Burp Proxy里看着一堆GET参数、POST JSON、Cookie字段,心里清楚“这里大概率能注入”,但手动拼payload试了七八轮,还…...