【C++】map set
map & set
- 一、关联式容器
- 二、键值对
- 三、树形结构的关联式容器
- 1. set
- (1)set 的介绍
- (2)set 的使用
- 2. multiset
- 3. map
- (1)map 的介绍
- (2)map 的使用
- 4. multimap
- 四、map 和 set 的练习
- 1. 前K个高频单词
- 2. 两个数组的交集
一、关联式容器
我们在前面已经接触过 STL 中的部分容器,比如:vector、list、deque、等,这些容器统称为序列式容器(一级容器),因为其底层为线性序列的数据结构,里面存储的是元素本身。
那什么是关联式容器?它与序列式容器有什么区别?关联式容器也是用来存储数据的,与序列式容器不同的是,其里面存储的是 <key, value> 结构的键值对,在数据检索时比序列式容器效率更高。
二、键值对
用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量 key 和 value,key 代表键值,value 表示与 key 对应的信息。比如:现在要建立一个英汉互译的字典,那该字典中必然有英文单词与其对应的中文含义,而且,英文单词与其中文含义是一一对应的关系,即通过该应该单词,在词典中就可以找到与其对应的中文含义。
SGI-STL中关于键值对的定义:
template <class T1, class T2>struct pair{typedef T1 first_type;typedef T2 second_type;T1 first;T2 second;pair(): first(T1()), second(T2()){}pair(const T1& a, const T2& b): first(a), second(b){}};
三、树形结构的关联式容器
根据应用场景的不同,STL 总共实现了两种不同结构的管理式容器:树型结构与哈希结构。树型结构的关联式容器主要有四种:map、set、multimap、multiset;这四种容器的共同点是:使用平衡搜索树(即红黑树) 作为其底层结果,容器中的元素是一个有序的序列。下面一依次介绍每一个容器。
1. set
(1)set 的介绍
首先我们可以看一下 set 的文档介绍:set 文档介绍.
简单概括:
-
set 是按照一定次序存储元素的容器
-
在 set 中,元素的 value 也标识它(value就是 key,类型为 T),并且每个 value 必须是唯一的。
set 中的元素不能在容器中修改(元素总是const),但是可以从容器中插入或删除它们。 -
set 在底层是用二叉搜索树(红黑树)实现的。
注意:
- 与 map/multimap 不同,map/multimap 中存储的是真正的键值对 <key, value>,set 中只放 value,但在底层实际存放的是由 <value, value> 构成的键值对。
- set 中插入元素时,只需要插入 value 即可,不需要构造键值对。
- set 中的元素不可以重复 (因此可以使用set进行去重) ;
- 使用 set 的迭代器遍历 set 中的元素,可以得到有序序列;
- set 中的元素默认按照小于来比较;
- set 中查找某个元素,时间复杂度为:O(logN).
(2)set 的使用
在使用之前我们先看一下 set 的模板参数列表:
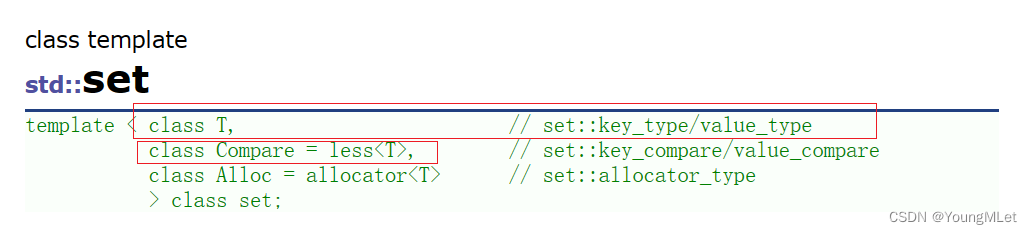
其中:
- T: set 中存放元素的类型,实际在底层存储 <value, value> 的键值对。
- Compare:仿函数,set 中元素默认按照小于来比较
- Alloc:set 中元素空间的管理方式,使用STL提供的空间配置器管理
- insert
下面我们简单插入几个元素并打印出来:
void test1(){set<int> s;s.insert(2);s.insert(6);s.insert(1);s.insert(4);s.insert(9);s.insert(9);s.insert(9);s.insert(0);for (auto& e : s){cout << e << " ";}cout << endl;}
由于 set 底层有迭代器,所以可以使用范围 for. 运行结果如下:
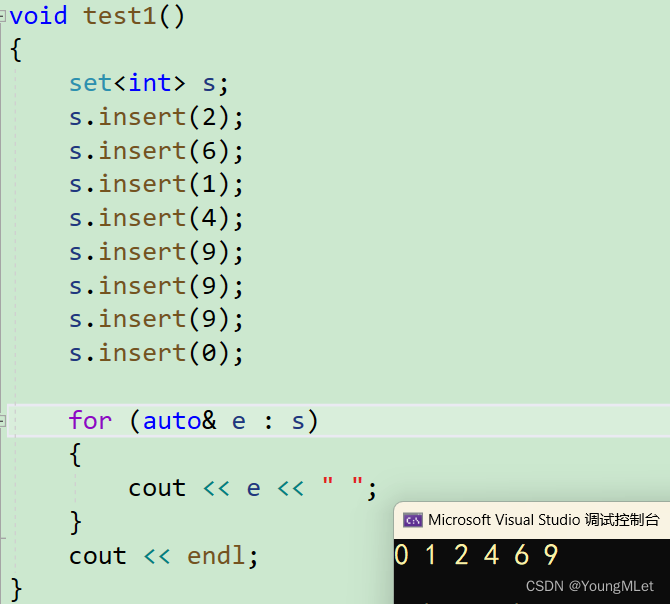
我们看到 set 打印出来是有序的并且去重了;在这里我们可以看一下 insert 的返回值:
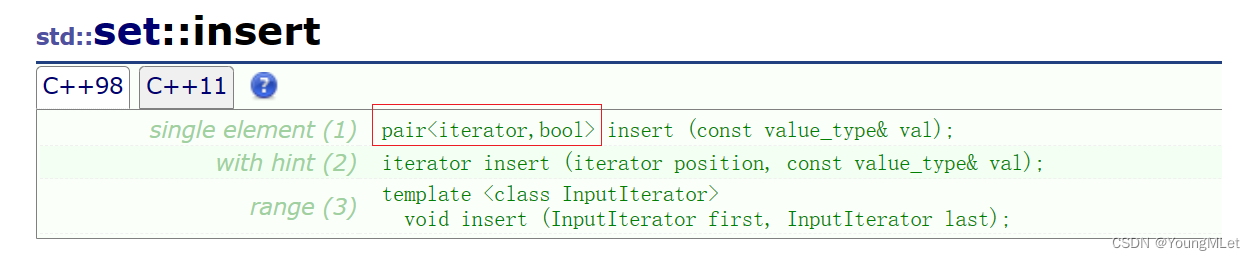
如上图,当我们插入的是一个值的时候,它的返回值是一个 pair 类型的键值对,所以我们可以简单用一个 pair 类型的变量接收,观察它对应的数据,如下:
void test1(){set<int> s;s.insert(2);s.insert(6);s.insert(1);s.insert(4);s.insert(9);s.insert(0);pair<set<int>::iterator, bool> it1 = s.insert(9);cout << *(it1.first) << " ";cout << it1.second<< endl;pair<set<int>::iterator, bool> it2 = s.insert(10);cout << *(it2.first) << " ";cout << it2.second << endl;}
如上代码,我们在已经有 9 的 s 中再次插入 9,我们观察它的返回值中的 first 和 second;然后我们插入 s 中没有的 10,继续观察;结果如下:
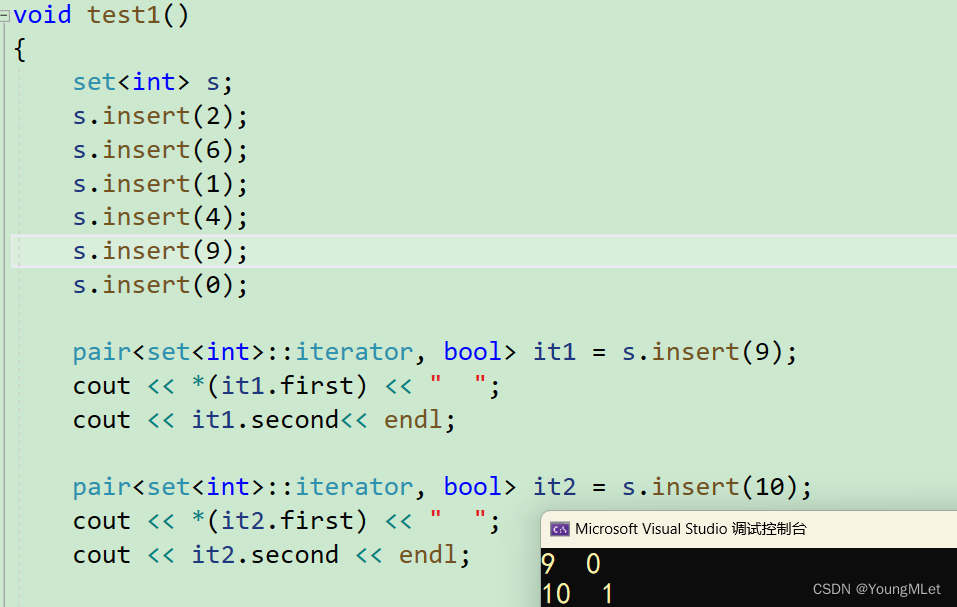
如上图,我们看到插入已有元素后,因为返回的 first 是个迭代器,所以需要解引用才能得到里面的值,里面的值给我们返回了已经存在的 9;而 second 返回了 0 即 false,代表插入失败。
插入没有的元素的时候 first 返回的是新插入的值所在节点的迭代器;second 则是 1,即 true,代表插入成功。
- erase

删除和我们往常用的差不多,直接删除需要删除的元素即可;注意删除成功返回 1;删除失败返回 0;
也可以直接给迭代器的位置直接删除,没有返回值。
如下代码:
void test1(){set<int> s;s.insert(2);s.insert(6);s.insert(1);s.insert(4);s.insert(9);s.insert(0);// 打印删除前for (auto& e : s){cout << e << " ";}cout << endl;// 打印删除结果cout << s.erase(1) << endl;cout << s.erase(20) << endl;// 打印删除后for (auto& e : s){cout << e << " ";}cout << endl;}
结果如下:

- find

如上图我们看到,find 的返回值是 iterator,那么返回的是哪个位置的迭代器呢?我们继续看它的返回值:

如上,如果找到这个元素,则返回这个元素所以在位置的迭代器;否则返回 end() 位置。可以如下使用:
void test2(){set<int> s;s.insert(2);s.insert(6);s.insert(1);s.insert(4);s.insert(9);s.insert(0);set<int>::iterator it = s.find(6);if (it != s.end()){s.erase(it);}for (auto& e : s){cout << e << " ";}cout << endl;}
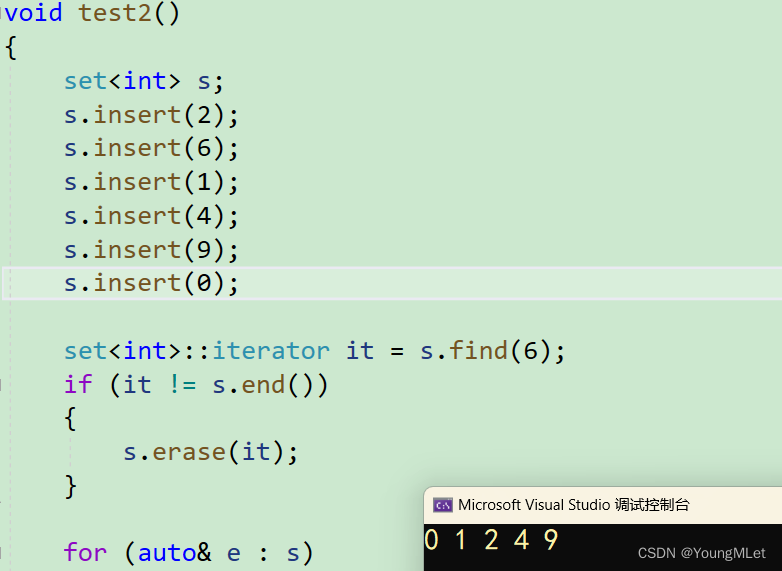
- count

count 返回值就是统计这个元素出现多少次,但是 set 的一个特性是去重,所以返回值只有 1 和 0;所以一般用来判断在不在;如下:
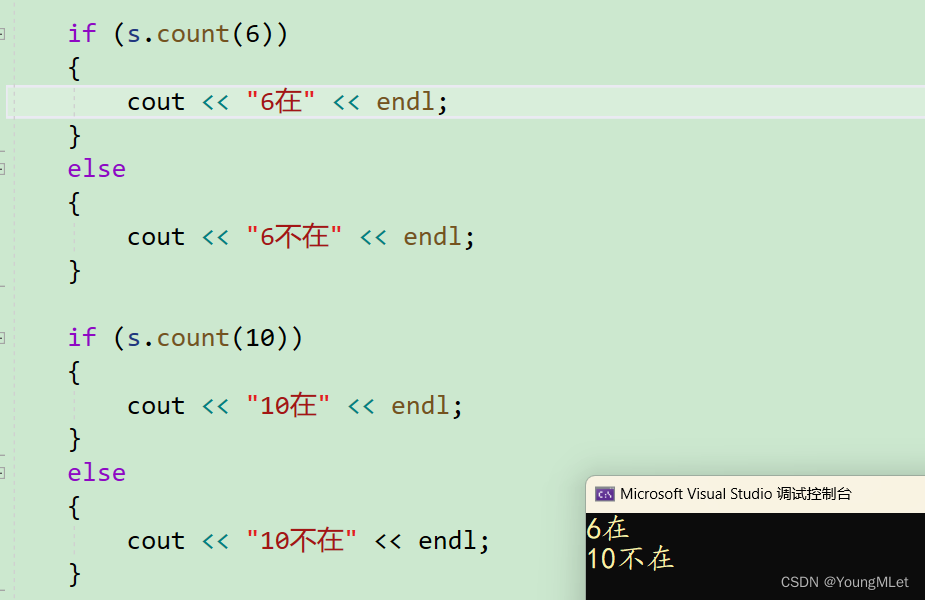
void test2(){set<int> s;s.insert(2);s.insert(6);s.insert(1);s.insert(4);s.insert(9);s.insert(0);if (s.count(6)){cout << "6在" << endl;}else{cout << "6不在" << endl;}if (s.count(10)){cout << "10在" << endl;}else{cout << "10不在" << endl;}}
- lower_bound 和 upper_bound
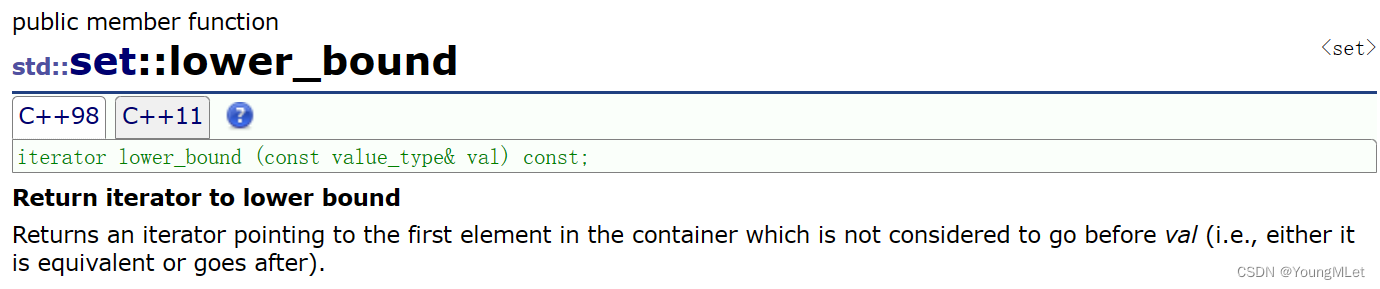
- lower_bound 是返回一个 >= val 值位置的 iterator ;
- upper_bound 是返回一个 > val 值位置的 iterator ;
使用如下:
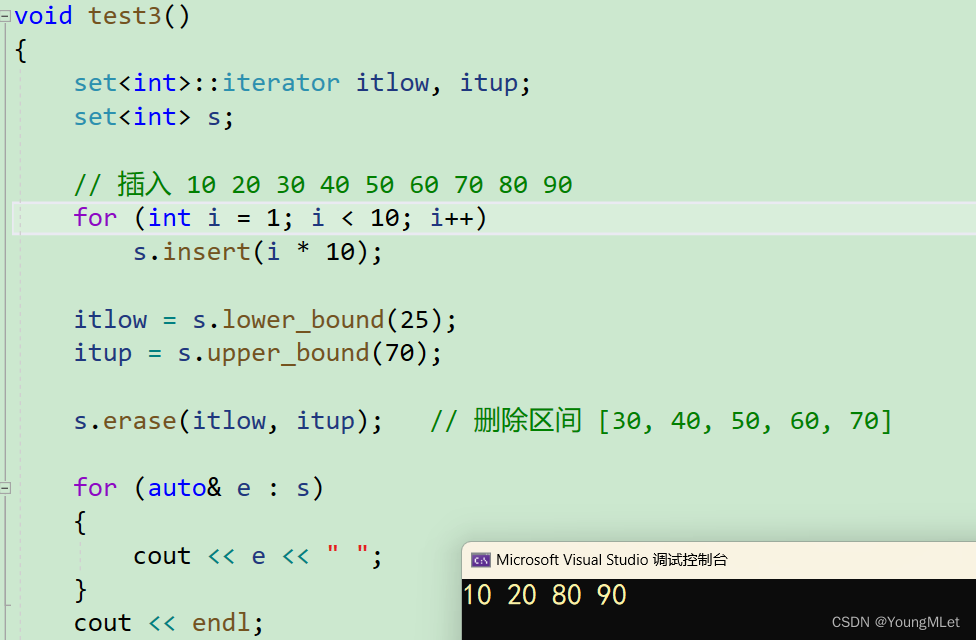
void test3(){set<int>::iterator itlow, itup;set<int> s;// 插入 10 20 30 40 50 60 70 80 90for (int i = 1; i < 10; i++) s.insert(i * 10); itlow = s.lower_bound(25);itup = s.upper_bound(70);s.erase(itlow, itup); // 删除区间 [30, 40, 50, 60, 70]for (auto& e : s){cout << e << " ";}cout << endl;}
结果如下:
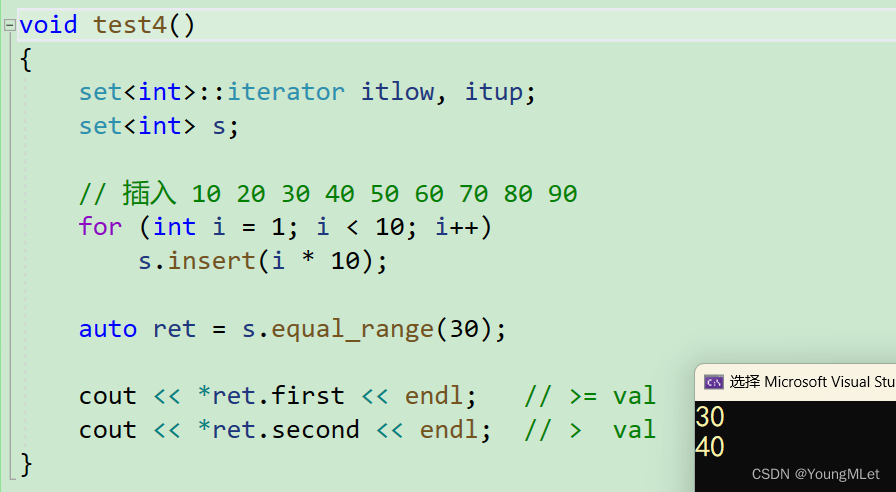
- equal_range

如上图介绍,equal_range 是返回一个 pair 类型,是一个范围的边界,该范围包括 s 中与 val 等价的所有元素。使用如下:
void test4(){set<int> s;// 插入 10 20 30 40 50 60 70 80 90for (int i = 1; i < 10; i++)s.insert(i * 10);auto ret = s.equal_range(30);cout << *ret.first << endl; // >= valcout << *ret.second << endl; // > val}
结果如下:
2. multiset
multiset 文档介绍
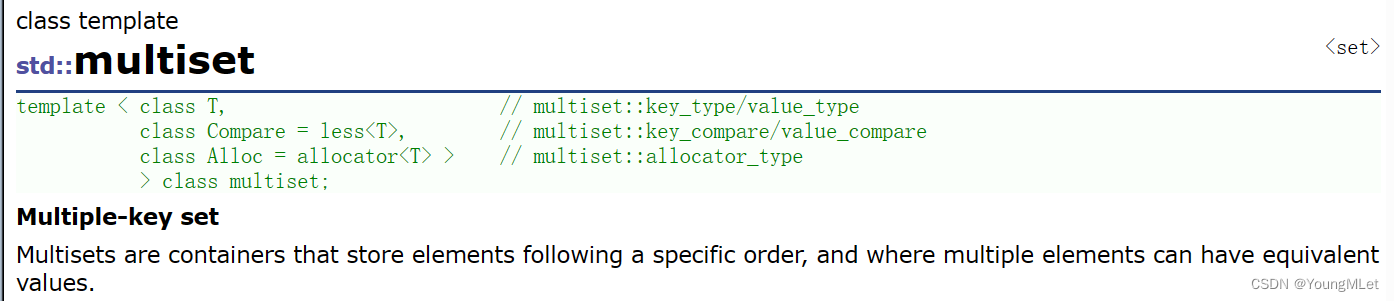
multiset 是按照特定顺序存储元素的容器,其中元素是可以重复的;它与 set 的区别就是 multiset 可以插入重复的元素。
- multiset 的使用
multiset 的许多接口都与 set 重复,所以它们的用法大体一致;
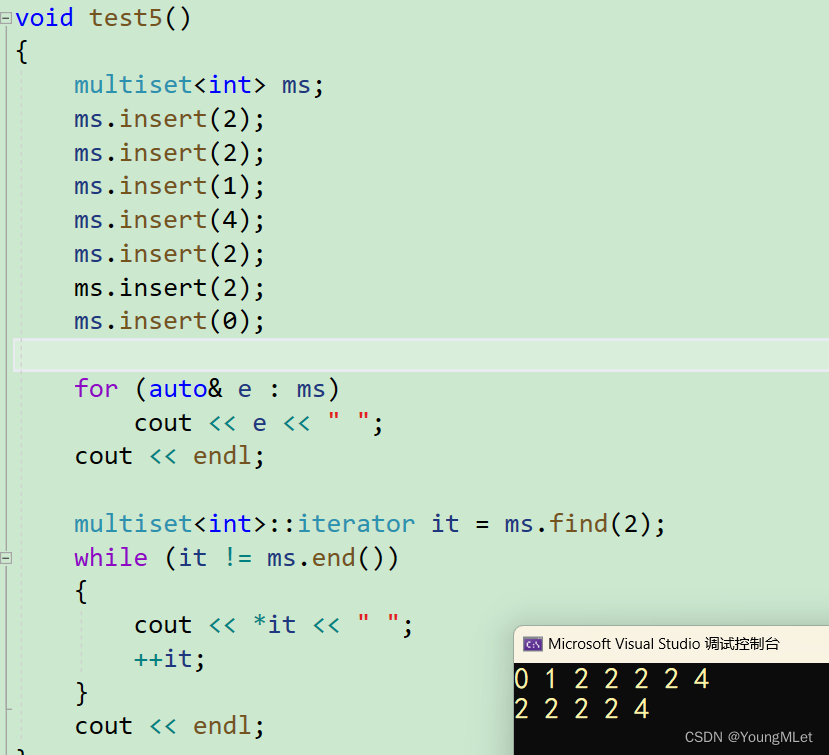
在这就介绍一下 find,如果有多个 val ,find 返回中序的第一个 val.
如下段代码:
void test5(){multiset<int> ms;ms.insert(2);ms.insert(2);ms.insert(1);ms.insert(4);ms.insert(2);ms.insert(2);ms.insert(0);for (auto& e : ms)cout << e << " ";cout << endl;multiset<int>::iterator it = ms.find(2);while (it != ms.end()){cout << *it << " ";++it;}cout << endl;}
结果如下,说明 find 是返回中序的第一个2:
3. map
(1)map 的介绍
我们先看一下 map 的文档介绍:map 文档介绍 .

简单概括:
- map 是关联容器,它按照特定的次序(按照 key 来比较)存储由键值 key 和值 value 组合而成的元素。
- 在 map 中,键值 key 通常用于排序和唯一地标识元素,而值value 中存储与此键值 key 关联的内容。键值 key 和值 value 的类型可能不同,并且在 map 的内部,key 与 value 通过成员类型 value_type 绑定在一起,为其取别名称为 pair:
typedef pair<const key, T> value_type; 如下图,是文档内容的截取:

- 在内部,map 中的元素总是按照键值 key 进行比较排序的。
- map 中通过键值访问单个元素的速度通常比 unordered_map 容器慢,但 map 允许根据顺序对元素进行直接迭代(即对map中的元素进行迭代时,可以得到一个有序的序列)。
- map 支持下标访问符,即在
[]中放入 key,就可以找到与 key 对应的 value。 - map 通常被实现为二叉搜索树(更准确的说:平衡二叉搜索树(红黑树))。
(2)map 的使用
- insert
因为 map 插入的是一对键值对,所以需要以 pair 的形式插入;我们先看一下 pair 的文档介绍:pair 文档介绍
其中它的构造函数如下:
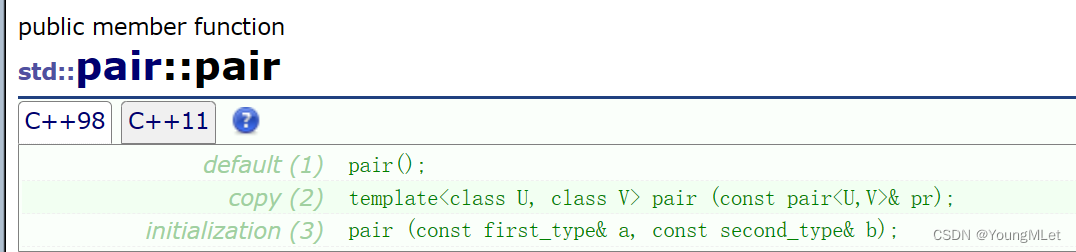
但是我们习惯用以下这个接口初始化一个键值对对象:make_pair,如下:
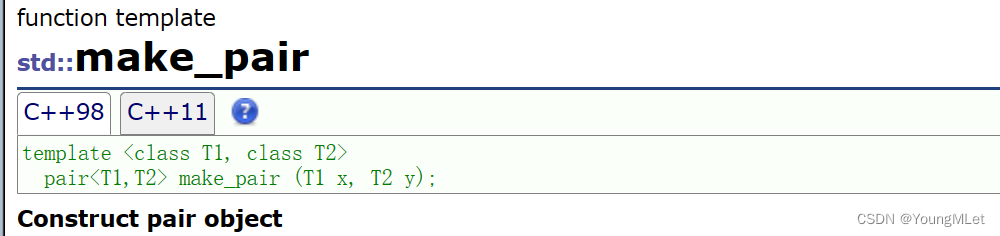

所以我们插入的时候可以以如下两种方式插入:
void test6(){map<string, string> dict;dict.insert(pair<string, string>("insert", "插入"));dict.insert(make_pair("string", "字符串"));map<string, string>::iterator it = dict.begin();while (it != dict.end()){cout << (*it).first << ":" << (*it).second << endl;//cout << it->first << ":" << it->second << endl;++it;}}
因为 iterator 迭代器封装的是一个个节点,所以解引用得到的是一个 pair 类型的键值对,所以解引用后使用 . 指定访问 first 还是 second;而 -> 我们在 list 部分讲过,当节点中存的类型是自定义类型的时候,我们使用 -> 就可以方便一点进行指定元素的访问,而 pair 正好就是自定义类型,所以用 -> 访问更方便。
注意,这里的是省略了一个 ->,实际上 it->first 就是 it.operator->()->first;其中 it.operator->() 是取到 pair 的地址,再使用 -> 即可进行指定元素访问。
然后其它接口的使用和 set 的用法差不多,只是 map 的类型变成了 pair 而已;所以其它接口不再进行介绍,下面开始介绍 map 中的最重要的接口:operator[].
- operator[]
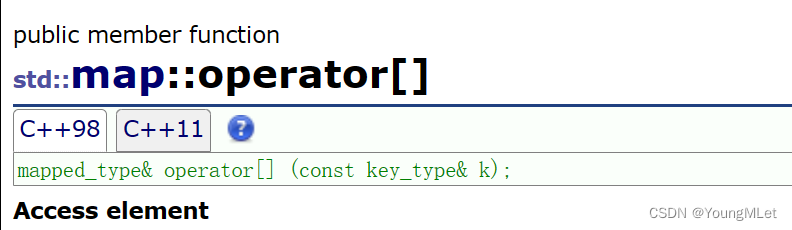
如上图和下图,operator[] 的返回值是 pair 的第二个模板参数:

我们先看一下 operator[] 的使用,如下段代码:
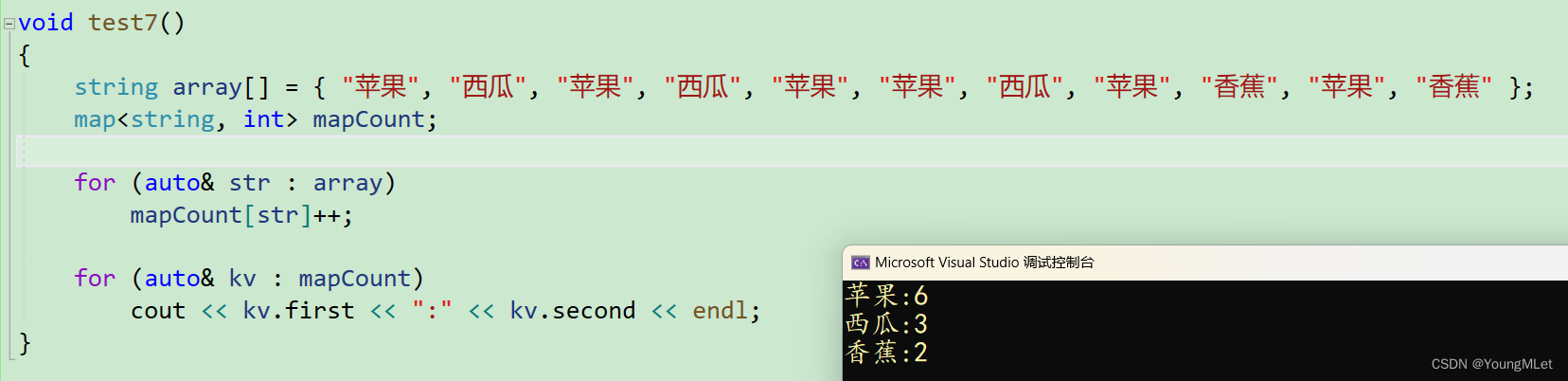
void test7(){string array[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };map<string, int> mapCount;for (auto& str : array)mapCount[str]++;for (auto& kv : mapCount)cout << kv.first << ":" << kv.second << endl;}
结果如下:
实际上,调用 operator[] 就是在调用:(*((this->insert(make_pair(k,mapped_type()))).first)).second
如下图是原文档的解释:

分析如下:

其中 mapped_type 是 map 模板中的第二个模板参数类型,mapped_type() 则是默认构造的匿名对象,所以我们传 int 类型的时候,如果 key 在 map 中没有,则初始化为 0;如果有则返回 key 对应的 value;所以当我们 ++ 的时候,就可以统计次数,其实 ++ 就是作用到 pair 的 value 上。
总结:
- map 中的的元素是键值对
- map 中的 key 是唯一的,并且不能修改
- 默认按照小于的方式对 key 进行比较
- map 中的元素如果用迭代器去遍历,可以得到一个有序的序列
- map 的底层为平衡搜索树(红黑树),查找效率比较高 O(logN).
- 支持
[]操作符,operator[]中实际进行插入查找;
4. multimap
我们可以看一下文档介绍:multimap 文档介绍
multimap 和 map 的唯一不同就是:map 中的 key 是唯一的,而multimap 中 key 是可以重复的。
multimap 的使用可以参考 map,功能都是类似的,这里不再作介绍;
注意:
- multimap 中的 key 是可以重复的。
- multimap 中的元素默认将 key 按照小于来比较
- multimap 中没有重载 operator[] 操作,因为 key 是可以重复的,如果此时有多个 key,就不知道返回哪个 key 对应的 value了;而且当有 key 的时候,再来一个 key,就不知道是查找还是修改了。
- 使用时与map包含的头文件相同:
四、map 和 set 的练习
1. 前K个高频单词
题目链接 -> Leetcode -692.前K个高频单词
Leetcode -692.前K个高频单词
题目:给定一个单词列表 words 和一个整数 k ,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序。
示例 1:
输入 : words = [“i”, “love”, “leetcode”, “i”, “love”, “coding”], k = 2
输出 : [“i”, “love”]
解析 : “i” 和 “love” 为出现次数最多的两个单词,均为2次。
注意,按字母顺序 “i” 在 “love” 之前。
示例 2:
输入 : [“the”, “day”, “is”, “sunny”, “the”, “the”, “the”, “sunny”, “is”, “is”] , k = 4
输出 : [“the”, “is”, “sunny”, “day”]
解析 : “the”, “is”, “sunny” 和 “day” 是出现次数最多的四个单词,
出现次数依次为 4, 3, 2 和 1 次。
注意:
1 <= words.length <= 500
1 <= words[i] <= 10
words[i] 由小写英文字母组成。
k 的取值范围是[1, 不同 words[i] 的数量]
思路是先将 words 中的内容放入 map 中统计次数,再放入优先级队列中按照 cmp 方式进行比较确认优先级;其中 cmp 方法是次数多的优先,如果次数多的就按照字典顺序比较;代码如下:
class Solution {public:// 仿函数,按照 pair 中的 second 比较,降序;如果 second 相等,按照字典顺序排序class cmp{public:bool operator()(const pair<string, int>& p1, const pair<string, int>& p2){return p1.second < p2.second || (p1.second == p2.second && p1.first > p2.first);}};vector<string> topKFrequent(vector<string>& words, int k){priority_queue<pair<string, int>, vector<pair<string, int>>, cmp> pq;map<string, int> mp;// 先放入 map 中统计次数for (auto& str : words)mp[str]++;// 再放入优先级队列中for (auto& str : mp)pq.push(str);// 取优先级队列的前 k 个vector<string> ret;while (k--){ret.push_back(pq.top().first);pq.pop();}return ret;}};
2. 两个数组的交集
题目链接 -> Leetcode -349.两个数组的交集
Leetcode -349.两个数组的交集
题目:给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。
示例 1:
输入:nums1 = [1, 2, 2, 1], nums2 = [2, 2]
输出:[2]
示例 2:
输入:nums1 = [4, 9, 5], nums2 = [9, 4, 9, 8, 4]
输出:[9, 4]
解释:[4, 9] 也是可通过的
提示:
1 <= nums1.length, nums2.length <= 1000
0 <= nums1[i], nums2[i] <= 1000
思路是将两个数组分别放入 set 中,然后使用双指针找交集; 具体思路如下代码:
class Solution {public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2){// 将 nums1 和 nums2 分别放入 set 中set<int> s1(nums1.begin(), nums1.end());set<int> s2(nums2.begin(), nums2.end());// 使用双指针的思路// 两个值相等则是交集,同时++;// 两个值不相等则小的那个++;// 直到其中一个结束vector<int> ret;set<int>::iterator it1 = s1.begin(), it2 = s2.begin();while (it1 != s1.end() && it2 != s2.end()){if (*it1 == *it2){ret.push_back(*it1);++it1, ++it2;}else if (*it1 < *it2){++it1;}else{++it2;}}return ret;}};
相关文章:
【C++】map set
map & set 一、关联式容器二、键值对三、树形结构的关联式容器1. set(1)set 的介绍(2)set 的使用 2. multiset3. map(1)map 的介绍(2)map 的使用 4. multimap 四、map 和 set 的…...

正点原子嵌入式linux驱动开发——Linux Regmap驱动
在前面学习I2C和SPI驱动的时候,针对I2C和SPI设备寄存器的操作都是通过相关的API函数进行操作的。这样Linux内核中就会充斥着大量的重复、冗余代码,但是这些本质上都是对寄存器的操作,所以为了方便内核开发人员统一访问I2C/SPI设备的时候&…...
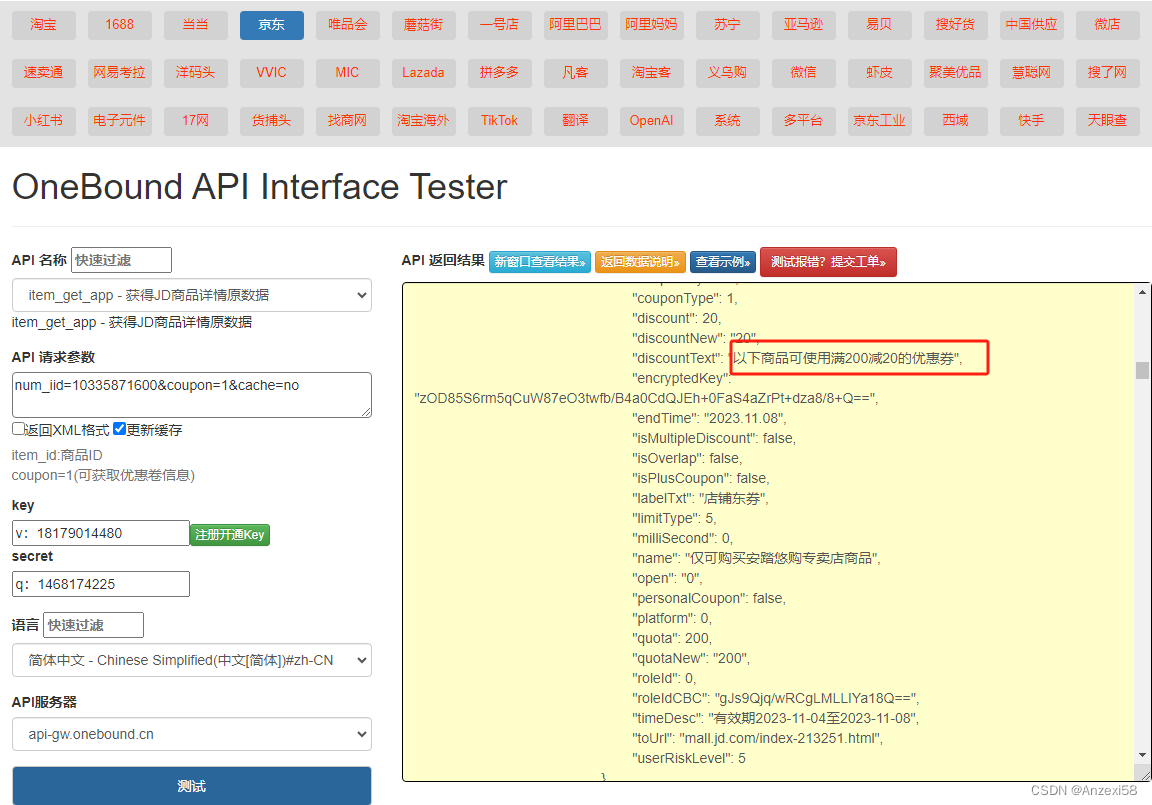
京东商品详情API,页面信息采集,优惠券信息获取
京东开放平台提供了API接口来访问京东商品详情。通过这个接口,您可以获取到商品的详细信息,如商品名称、价格、库存量、描述等。额外还附加一个优惠券信息接口。代码如下: 京东获得JD商品详情 API 优惠券接口 公共参数 名称类型必须描述keyString是调…...
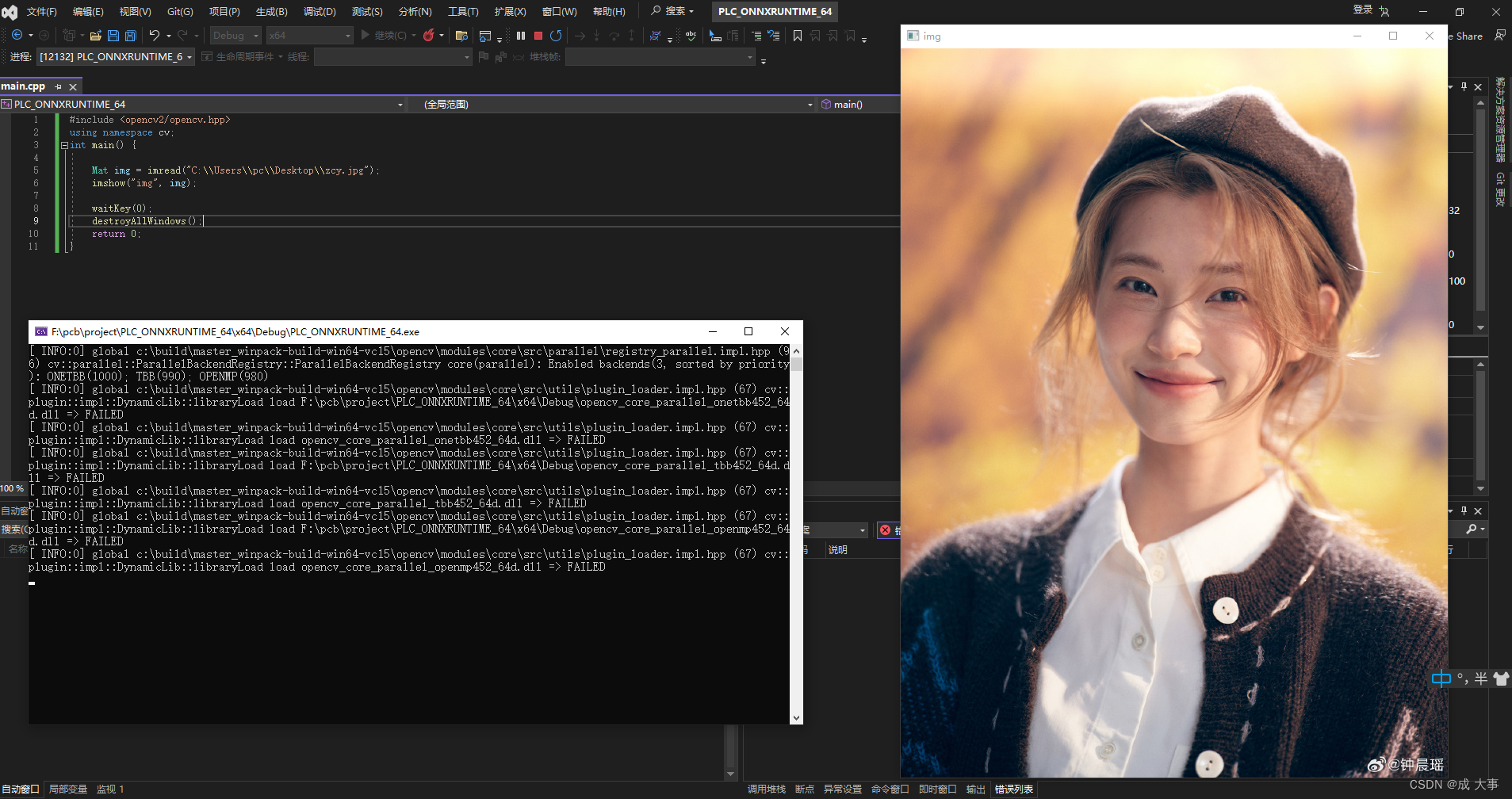
Visual Studio 2022 + OpenCV 4.5.2 安装与配置教程
目录 OpenCV的下载与配置Visual Studio 2022的配置新建工程新建文件新建项目属性表环境配置测试先写一个输出将OpenCV的动态链接库添加到项目的 x64 | Debug下测试配置效果 Other OpenCV的下载与配置 参考这个OpenCV的下载与环境变量的配置: Windows10CLionOpenCV4…...
)
docker 安装 mysql (单体架构)
文章归档:https://www.yuque.com/u27599042/coding_star/nckzqa73g47hgz3x 查询 MySQL 镜像 docker search mysql拉取 MySQL 镜像 docker pull mysql在宿主机创建映射目录 mkdir -p \ /home/docker/mysql/log \ /home/docker/mysql/data \ /home/docker/mysql/co…...
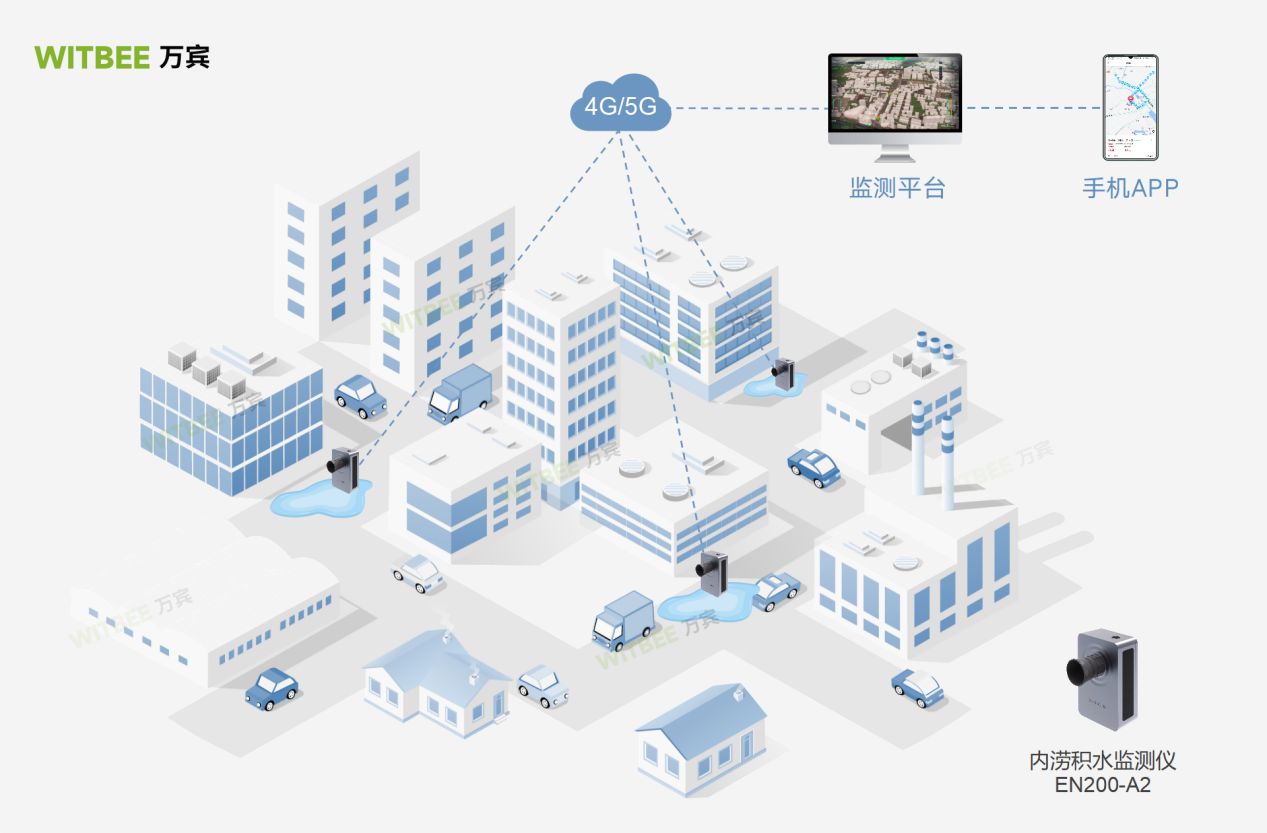
城市内涝怎么预警?万宾科技内涝积水监测仪
在城市运行过程中,城市内涝问题频繁出现,影响城市管理水平的提升,也会进一步减缓城市基础设施建设。尤其近几年来,城市内涝灾害频繁出现,在沿海地区内涝所带来的安全隐患成为城市应急管理部门的心头大患。城市内涝的背…...
Spring基础(2):放弃XML,走向注解
上一篇并没有实际地带大家去看源码,而是介绍了两个概念: BeanDefinitionBeanPostProcessor 当然,我介绍得非常笼统,不论是BeanDefinition还是BeanPostProcessor其实都有着较为复杂的继承体系,种类也很多。作为Spring…...

【线性代数】分块矩阵总结
...
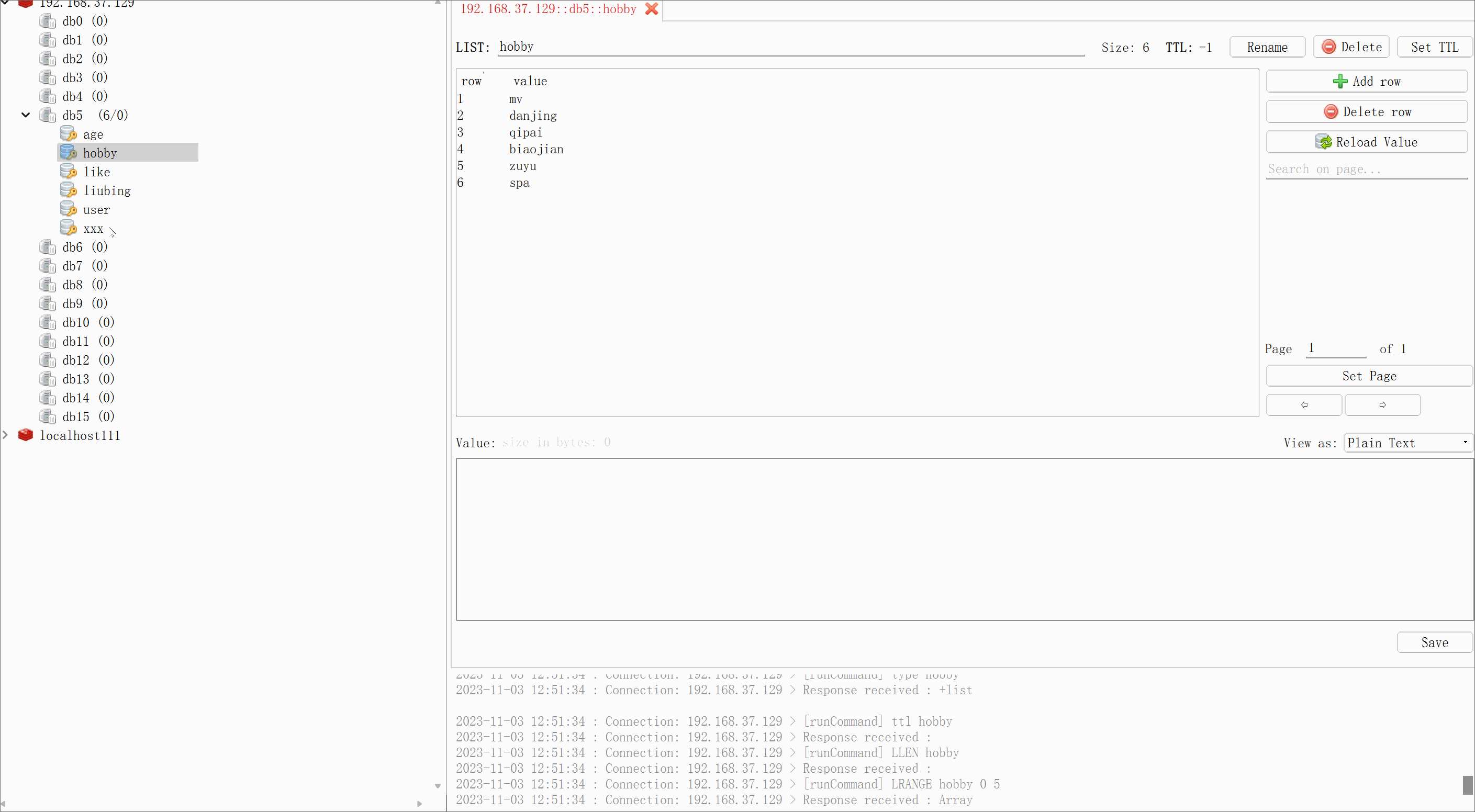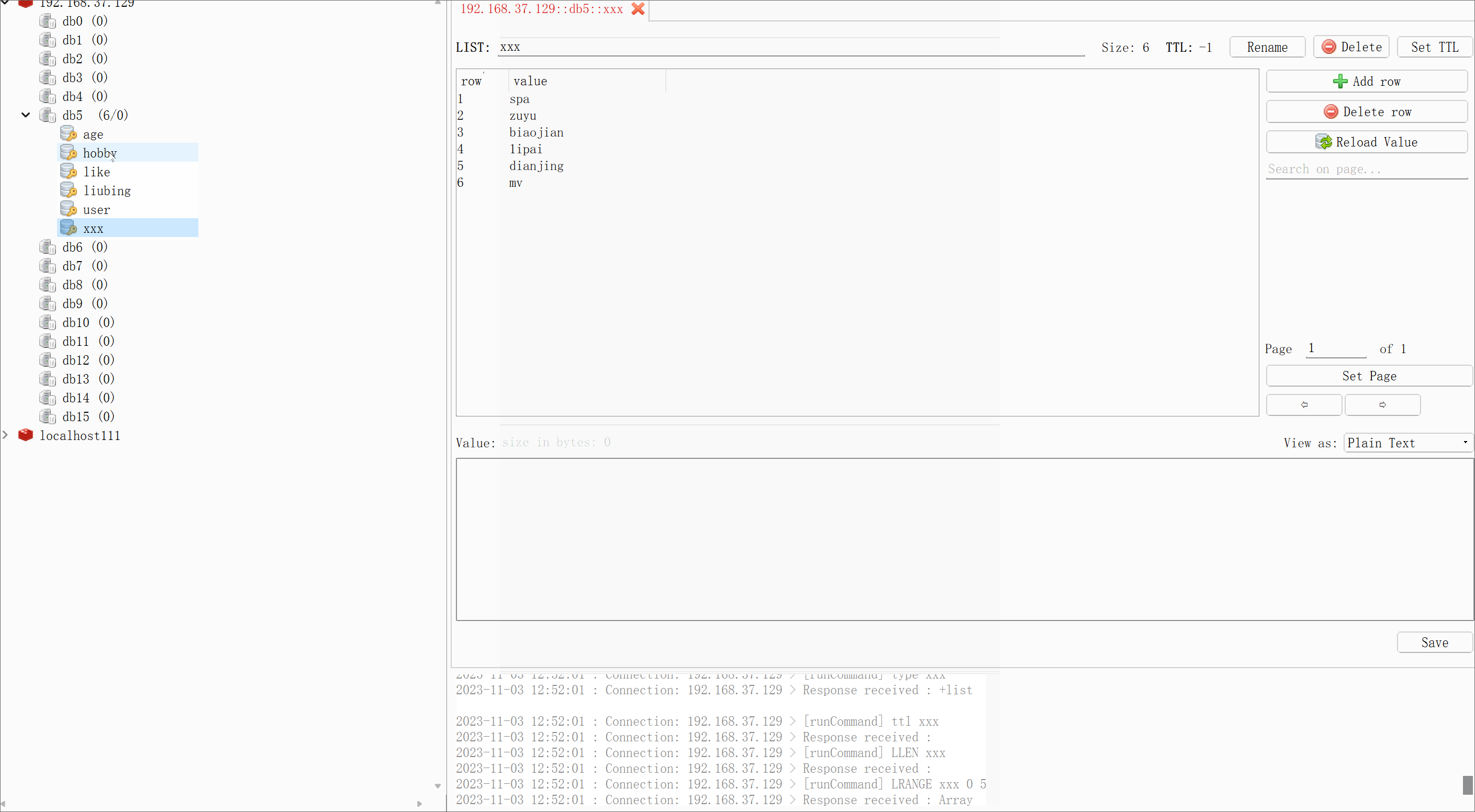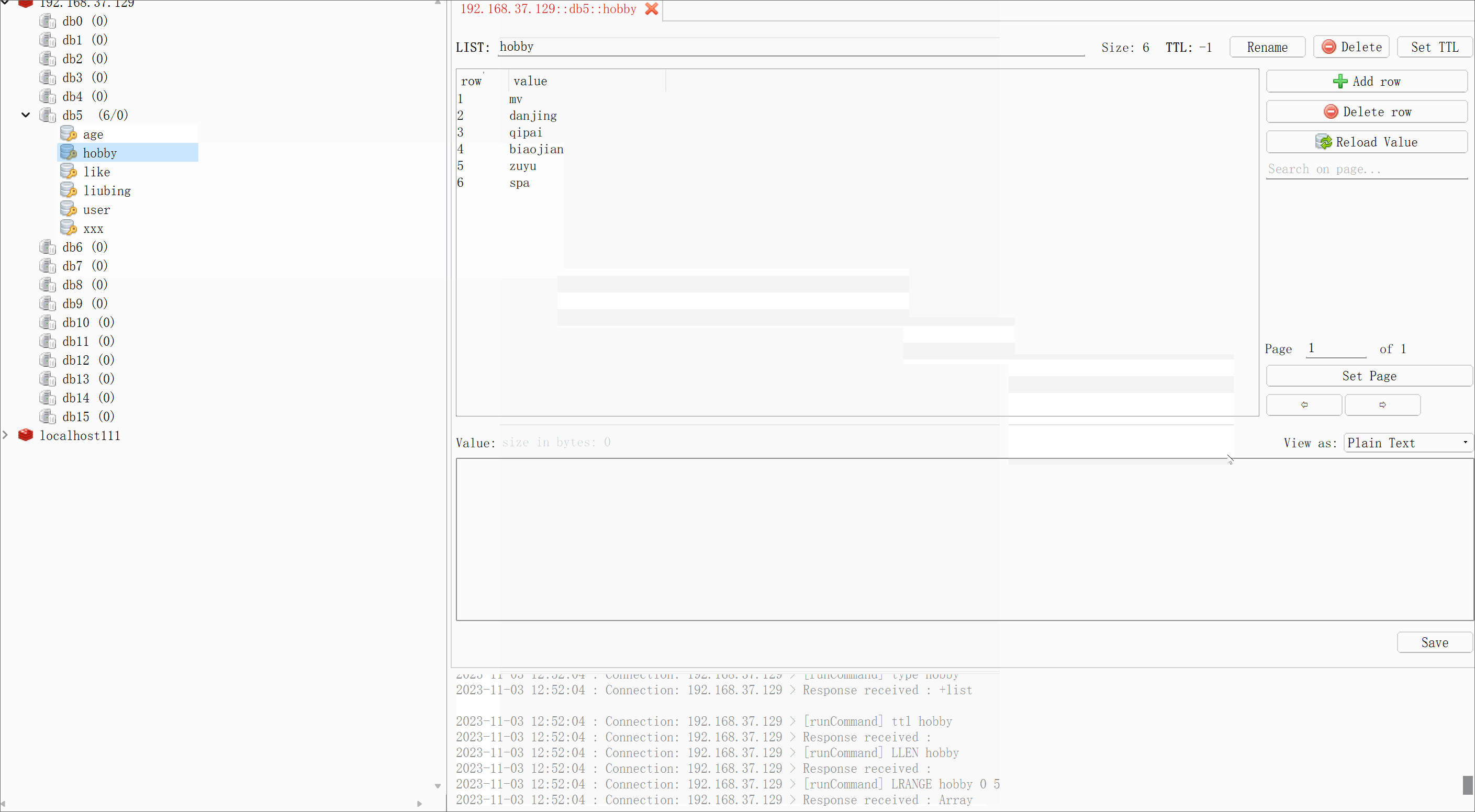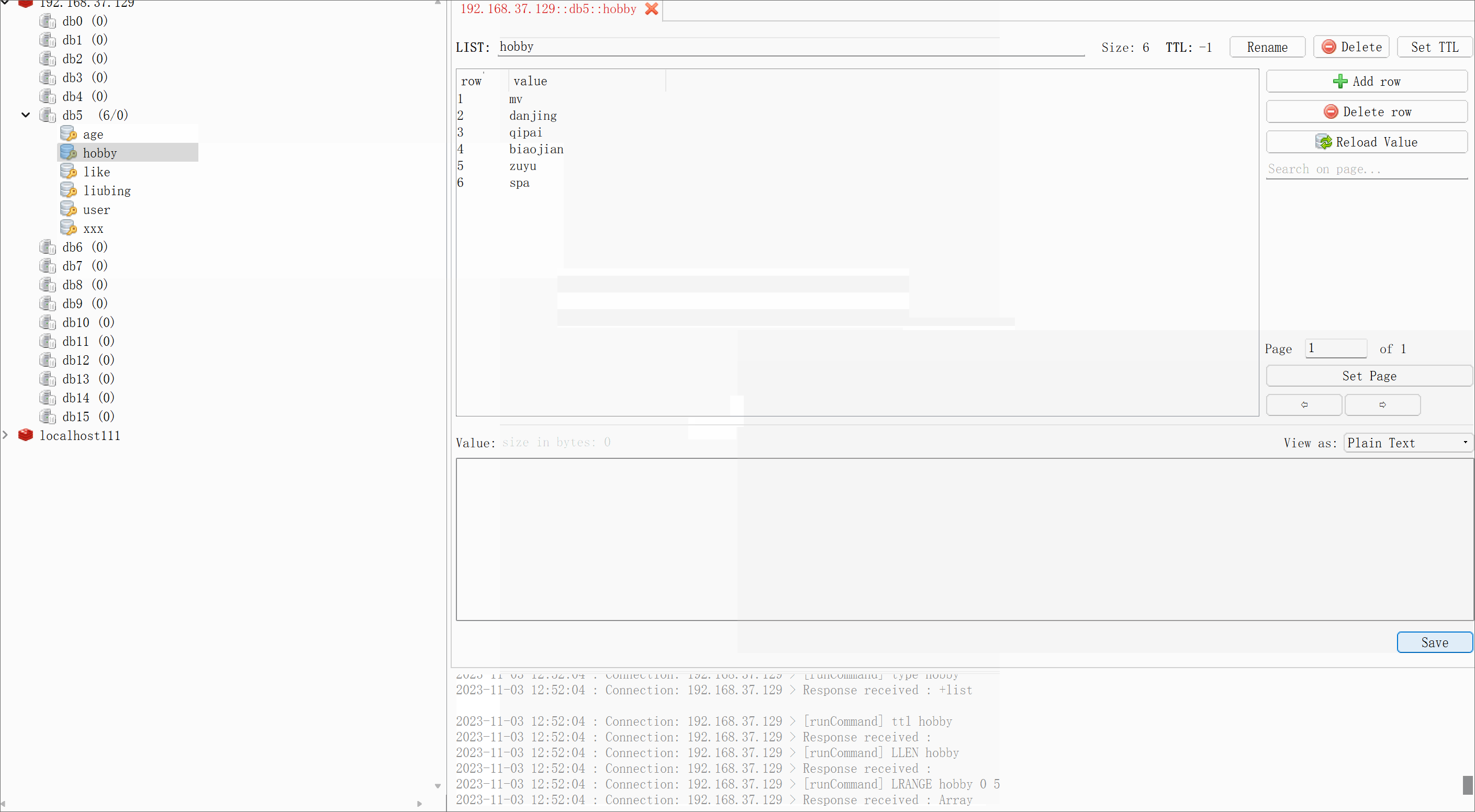
Redis-命令操作Redis->redis简介,redis的安装(Linux版本windows版本),redis的命令
redis简介redis的安装(Linux版本&windows版本)redis的命令 1.redis简介 Redis是一个开源(BSD许可),内存存储的数据结构服务器,可用作数据库,高速缓存和消息队列代理。 它支持字符串、哈…...

17、Python虚拟环境:为何要用虚拟环境、如何使用virtualenv
文章目录 在Python开发中,虚拟环境是一个独立的目录树,可以在其中安装Python模块。每个虚拟环境都有自己的Python二进制文件和一组安装的库。使用虚拟环境的主要原因是为了避免项目间的依赖冲突,允许每个项目有其特定的依赖,而不影响全局安装的模块。 为何要用虚拟环境 依…...

elasticSearch 接口实现查询热词统计
前面讲过使用elasticsearch可视化工具可以直接写语法查询如下: GET robot-demand/_search { "size":10, //查询多少条数据 "aggs":{ "hot_words":{ "terms":{ "field": "title" } }…...

10年测试经验分享:新手如何找到适合自己的软件测试项目?
每一个测试新手(特别是自学测试的人)来说,往往不知道到哪里去找项目练手,这应该是最大的困扰了。 实话讲,这个目前没有非常好的、直接的解决办法,不过在这我可以结合我自己之前的一些工作经历,…...

【MySQL】查询语句
文章目录 选择语句 / 子句比较运算符AND,OR,NOT运算符IN运算符BETWEEN运算符LIKE运算符REGEXP运算符 选择语句 / 子句 USE:选择使用的databaseSELECT:选择查询的列FROM:选择查询的表WHERE:条件查询ORDER B…...

金蝶云星空的网络控制设置
文章目录 金蝶云星空的网络控制设置说明网控参数加入网络控制清除网络控制清除网络控制(单个)清除网络控制(批量)清除网络控制(批量,参数是拼接好的业务对象) 金蝶云星空的网络控制设置 说明 …...
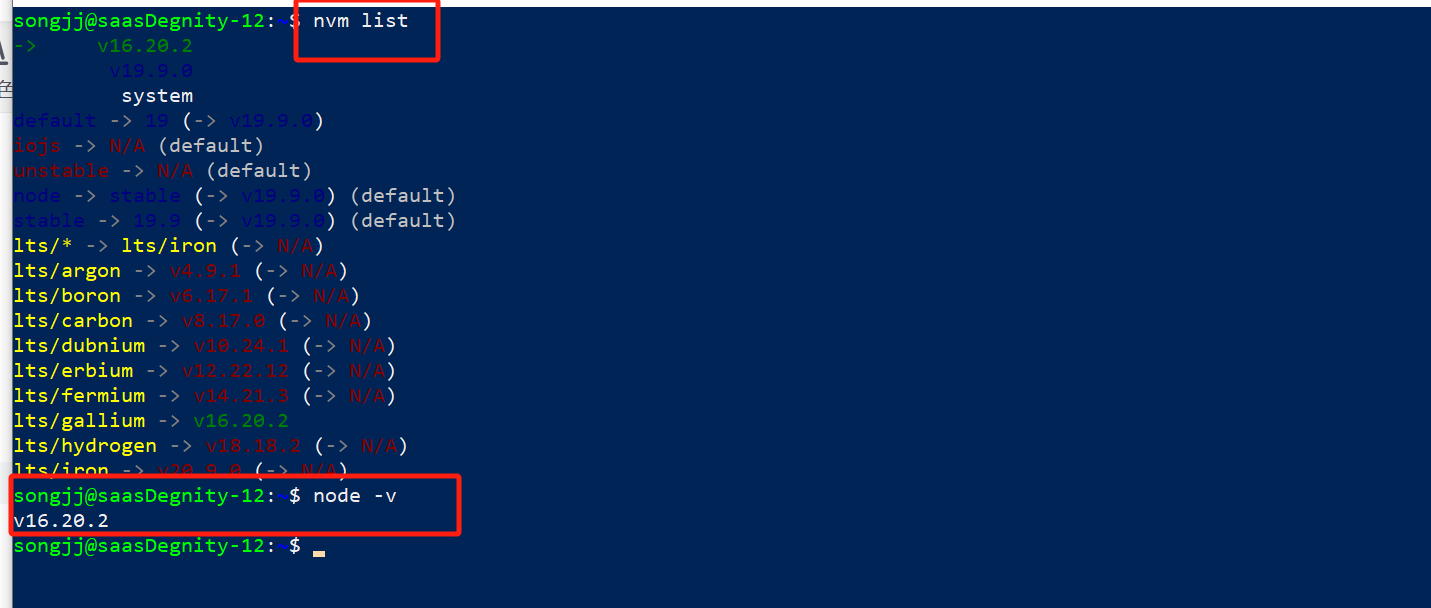
linux服务器国内源安装nvm,又快又方便
国内安装nvm的话,如果你的服务器不能访问github,那么使用gitee快速安装还是很方便的: # 能方位github的话,使用这条命令 curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.2/install.sh | bash# 不能访问github的话…...
noip模拟赛多校第八场 T3 遥控机器人 (最短路 + 技巧拆点)
题面 简要题意: 给你一个 n n n 个点 m m m 条边的图。边 i i i 有颜色 c i c_i ci。你可以选择一些边改变它们的颜色成为区间 [ 1 , m ] [1, m] [1,m] 中的任意颜色,改变一条边 i i i 一次的代价是 w i w_i wi。询问你能否在一些改变…...

高防IP的原理
高防IP,把域名解析到高防IP上(web事务只要把域名指向高防IP 即可。非web事务,把事务IP换成高防IP即可)一起在高防IP上设置转发规矩;所有公网流量都会走高防IP,通过端口协议转发的方法将用户的拜访通过高防IP转发到源站IP,一起将歹…...

Apache Doris (五十一): Doris数据缓存
🏡 个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Clickhouse 技术-CSDN博客 🚩 私聊博主:加入大数据技术讨论群聊,获取更多大数据资料。 🔔 博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频 目录 1....

一、配置环境
一、配置Java环境 确保安装了Java开发工具包(JDK),并且设置了JAVA_HOME环境变量。 二、配置FFmpeg环境 如果使用了FFmpeg相关的功能,需要确保系统中已经安装了FFmpeg,并且设置了FFMPEG_HOME环境变量。 ffmpeg安装教…...

各种 sql 语句
sql 语句: SELECT max(val) as level_max_val from (select greatest(level1,level2,level3,level4,level5,level6,level7,level8,level9,level10) as val from kbt_2020cv52_data) k;...

从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器
从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器计算流体力学(CFD)的魅力在于它将抽象的数学方程转化为可执行的代码,让流体运动的奥秘在计算机中重现。对于已经掌握流体力学理论的中高级学习者来说&am…...

新手村任务:成为一个架构师需要哪些装备?
新手村任务:成为一个架构师需要哪些装备? 一、前言 如果你刚入行不久,想成为一名架构师,那这篇文章就是为你写的。 我们把成为架构师比作一个RPG游戏,你是主角,需要收集各种装备、刷经验、升级技能。 新手村的第一个任务就是:了解你需要哪些装备。 二、架构师技能树…...
:数组排序、去重、查找)
数组专项(一):数组排序、去重、查找
大家好,欢迎来到《算法面试60讲(2026最新版全真题带解析)》第19篇!上一篇我们彻底吃透了字符串专项的核心难点——BF暴力匹配与KMP高效匹配算法,搞定了字符串模块面试最难的算法考点。从本节课开始,我们正式进入算法面试第一高频模块:数组专项。 在算法面试中,数组是出…...

Jupyter Notebook里跑argparse脚本总报错?一个空列表参数搞定ipykernel_launcher.py error
Jupyter Notebook中argparse报错的终极解决方案:空列表参数实战解析在数据科学和机器学习的工作流中,Jupyter Notebook因其交互式特性成为众多研究者的首选工具。然而,当我们尝试在Notebook中运行那些原本为命令行设计的Python脚本时…...

UE5 Cesium项目里,如何把默认的飞行Pawn换成建筑漫游Pawn?保姆级迁移教程
UE5 Cesium项目建筑漫游Pawn迁移实战:从飞行模式到精细化浏览的完整指南当你在UE5中结合Cesium插件构建数字孪生场景时,DynamicPawn提供的全球飞行体验令人印象深刻。但当视角聚焦到单体建筑或室内空间时,那种仿佛操控无人机般的操作方式就显…...

如何永久保存微信聊天记录?WeChatMsg终极数据导出指南
如何永久保存微信聊天记录?WeChatMsg终极数据导出指南 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeCha…...

清华大学学位论文LaTeX模板:30分钟快速排版终极指南
清华大学学位论文LaTeX模板:30分钟快速排版终极指南 【免费下载链接】thuthesis LaTeX Thesis Template for Tsinghua University 项目地址: https://gitcode.com/gh_mirrors/th/thuthesis 还在为论文格式烦恼吗?清华大学官方LaTeX模板thuthesis让…...

收藏2026版|大模型应用开发入门全攻略,小白程序员转行AI避坑学习指南
打算踏入大模型领域、转行AI赛道的新手与程序员,正式规划学习路径前,务必先吃透AI应用开发工程师的岗位定位与工作内容。清晰认知岗位核心价值,才能规避无效学习,精准找准发力方向。2026年大模型技术全面迈入商业化落地阶段&#…...

终极解决方案:彻底解决UE4SS DLL劫持导致的系统级应用程序启动错误
终极解决方案:彻底解决UE4SS DLL劫持导致的系统级应用程序启动错误 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/r…...

5大核心功能掌握HandheldCompanion:Windows掌机终极控制伴侣
5大核心功能掌握HandheldCompanion:Windows掌机终极控制伴侣 【免费下载链接】HandheldCompanion ControllerService 项目地址: https://gitcode.com/gh_mirrors/ha/HandheldCompanion 你是否正在寻找一款能够彻底改变Windows掌机游戏体验的控制软件…...